
© Sergii Muzhchil, 123RF
Weil die Cloud omnipräsent ist, meinen einige Unternehmen, dass es ein Kinderspiel sei, ihre Geschäftsanwendungen zu Amazon, Google, Microsoft und Co. auszulagern. Tatsächlich lauern auf dem Weg nach oben tückische Fallwinde gerade abseits der Technologie.
Schenkt man den einschlägigen Werbeanzeigen Glauben, dann ist es kinderleicht, die Dienste von Cloudanbietern wie Amazon [1], Google [2], Microsoft [3] & Co. zu nutzen. Zugleich suggeriert das Marketing der Firmen, der Weg in die Wolke sei völlig unkompliziert. Tatsächlich präsentiert sich der Wechsel in die Cloud häufig als mehrdimensionale Herausforderung. Der Artikel beleuchtet einige der Hürden, legt den Fokus aber auf die nicht-technische Seite.
Ein wolkiger Begriff
Was die Cloud genau ist, darüber streiten Experten [4]. Der Artikel versteht darunter das Bereitstellen von Kapazitäten zum Speichern, Transportieren und Verarbeiten von Daten über Dritte, im Wolken-Jargon: Storage, Network und Compute. Diese Arbeitsdefinition beansprucht allerdings keine Universalität.
Warum nur?
Unternehmen, die in die Cloud wollen, sollten vor dem Umstieg eine Reihe von Fragen klären. Unter anderem jene, welche Probleme der lokalen IT-Infrastruktur die Wolke lösen soll. Wie sehen die Erwartungen aus, welche Ziele soll der Umstieg erfüllen? Welche Kriterien sind wichtig? Lassen sich diese Kriterien messen und wie erfolgt die Messung? Was passiert, wenn sich die Erwartungen nicht erfüllen? Was sind die Kriterien für den Ausstieg? Doch damit nicht genug. Nur wenige denken über eine Alternative für den Fall nach, dass die Cloudauslagerung nicht funktioniert wie erwartet, geplant oder erwünscht.
Für eine professionelle Beurteilung sind also einige Recherchen nötig. Unter anderem gilt es, die Mythen der höheren Geschwindigkeit und der stark verringerten Kosten in der Cloud genau zu prüfen – wenigstens für den eigenen Use Case. Die Hoffnung, dass sich kaputte Geschäftsprozesse außerhalb der eigenen IT-Infrastruktur auf magische Weise reparieren, sind bestenfalls kühn, aber wohl eher verfehlt.
Der folgende Text wirft aus vier Perspektiven einen Blick hinter die Kulissen einer Migration in die Cloud, um die Frage zu klären: Should I stay or should I go?
Die Software-Seite
Eine offensichtliche Frage ist die nach der Software. Sie verlangt nach einer Unterteilung. In Betracht ziehen muss die IT-Abteilung einmal die Geschäftsapplikation an sich, also die Software, mit der die Firma Geld verdient. Ein zweiter Blick muss jener Software gelten, die hinter den Kulissen werkelt. Welche Techniken kommen hier zum Einsatz, wenn es um Aktualisierung, Verfügbarkeit oder den normalen Betrieb geht?
Bei den Geschäftsanwendungen gibt es prinzipiell zwei Kategorien: Die Software ist eine Eigenentwicklung, oder sie stammt von einem Drittanbieter. Im zweiten Fall gilt es zu prüfen, ob die Verträge einen Betrieb außerhalb der bisherigen IT-Landschaft erlauben, und wenn ja, in welchem Umfang.
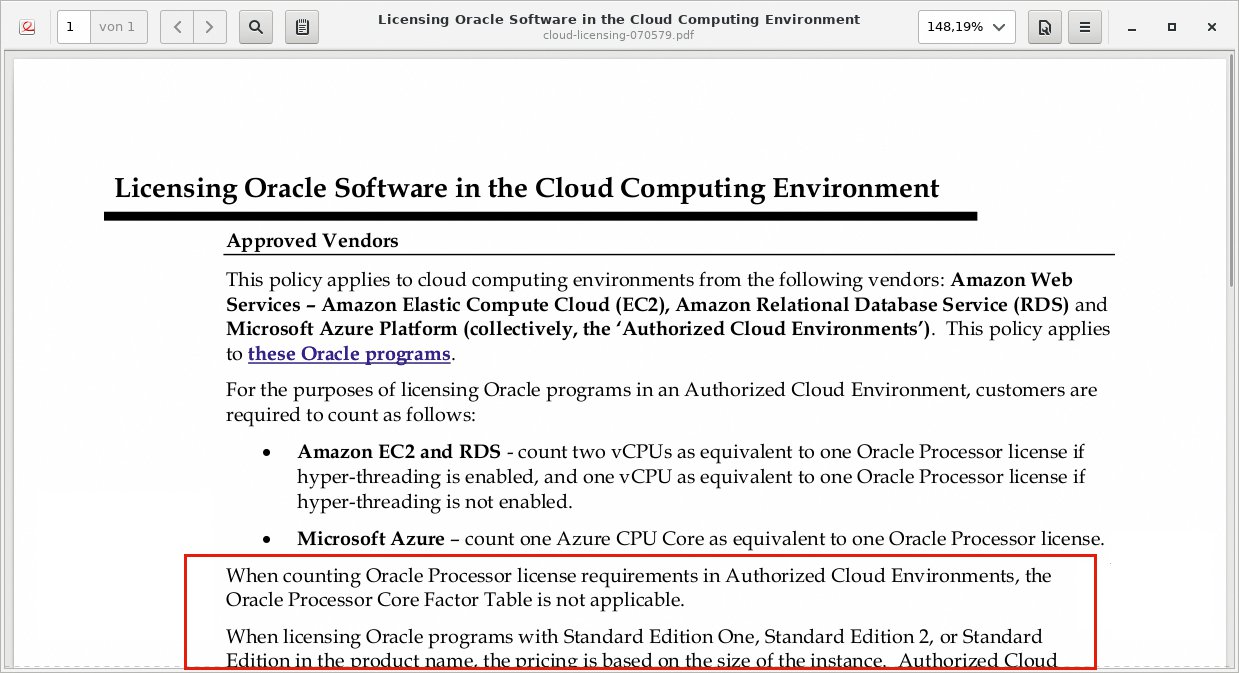
Abbildung 1: Bei Oracle kosten virtuelle CPUs in der Cloud doppelt so viel wie physische.
Beschränken sich die Lizenz oder das Abo beispielsweise auf Deutschland, die EU oder andere geografische Regionen oder Gerichtsbarkeiten? Kann es zum Problem werden, dass Mitarbeiter des Cloudbetreibers nahezu unbeschränkten Zugriff auf die verwendete Infrastruktur haben? Ändern sich die Preise durch den externen Einsatz (Abbildung 1)? Deckt der Hersteller den Betrieb auf vorwiegend virtueller Infrastruktur ab? Diese Fragen ließen sich fortsetzen und berühren hier nur die berühmte Spitze des Eisberges.
Eigenbau
Wer seine Geschäftsanwendung selbst schreibt, lächelt vielleicht über die meisten der eben genannten Aspekte, die Gesamtsituation bleibt aber komplex. Die zentralen Fragen lauten: Läuft die Software auch in der Wolke und was tut das Unternehmen, wenn dies nicht der Fall sein sollte? Ein allgemein gültiges Rezept gibt es in diesem Fall nicht.
Es gibt Befürworter des so genannten Lift and Shift. Dabei läuft die Anwendung einfach unverändert auf der neuen Infrastruktur. Das ist in vielen Fällen prinzipiell möglich, denn die großen Cloudanbieter erfüllen fast jede Anforderung: Sie stellen virtuelle oder physikalische Infrastruktur bereit, bieten eine variable Menge an CPUs und RAM an, Windows oder Linux, verschiedene Grafikprozessoren und so weiter.
Gegner dieses Ansatzes argumentieren, dass ein Unternehmen auf diese Weise viele Vorteile der Wolke aufgibt. Zudem muss es sich Herausforderungen stellen, die sich mit einer Neuentwicklung umgehen ließen. Als Beispiele dafür lässt sich das Steuern und Verwalten der Geschäftsapplikation nennen. So skaliert ein interaktiver Ansatz – womöglich noch über ein GUI – außerhalb der eigenen IT-Umgebung häufig schlechter und verursacht gar unnötige Kosten. Ein weiterer Aspekt ist der Umgang mit den Daten, doch dazu später mehr.
Ein wesentlicher Punkt für den Betrieb in der Cloud ist die Erwartung an die Infrastruktur beziehungsweise die vertraglich zugesicherte Leistung. Nur selten greift ein Cloudnutzer auf eine komplett physikalisch separierte Hardware zurück. Lässt sich dies für CPU, Arbeitsspeicher und eventuell den Storage noch umsetzen, ist der Kunde spätestens im Netzwerk nicht mehr allein unterwegs.
Verfügbarkeit
Ein anderer Aspekt ist die Zuverlässigkeit der Infrastruktur. Hier gilt es, das Kleingedruckte des Cloudanbieters genau zu studieren. Abbildung 2 zeigt einen Auszug der Dienstleistungsbeschreibung für Compute von AWS [5]. Der gezeigte Ausschnitt umfasst auch die Definition von Regionen und Availability Zones (AZ). Wer genau hinschaut, der erkennt, dass der Ausfall einer AZ aus AWS-Sicht noch keine Verletzung der Dienstleistungsvereinbarung darstellt, dafür müssten es schon zwei sein.
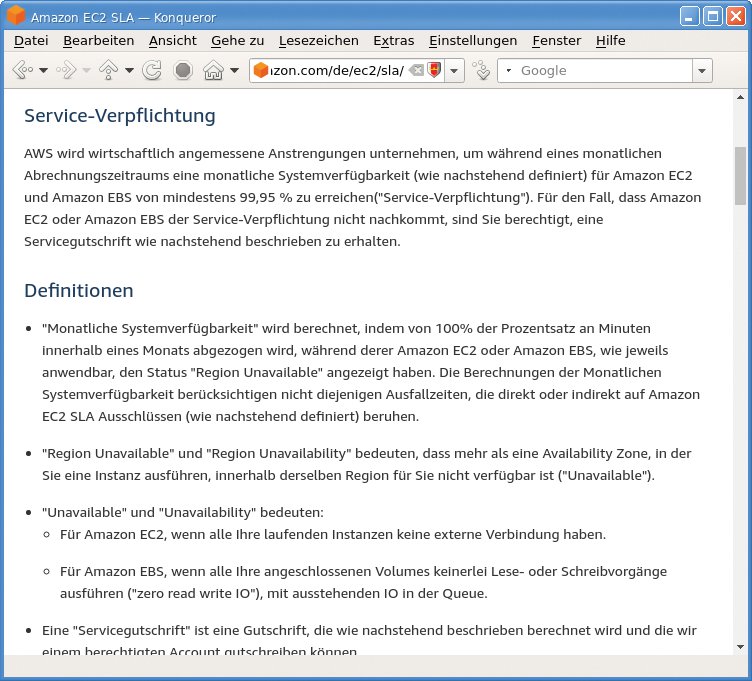
Abbildung 2: Auszug aus der Dienstleistungsbeschreibung für den EC-Service von AWS.
Diese Situation ist fatal, wenn die zuständige Region klein ist. London beispielsweise verfügt nur über zwei AZs (Abbildung 3). AWS verletzt hier seine Service-Verpflichtung erst, wenn die gesamte Region ausfällt. Das kann ins Auge gehen, wenn die Software das Land nicht verlassen darf – mit reinen AWS-Mitteln würde die Geschäftsanwendung dadurch am Boden liegen.
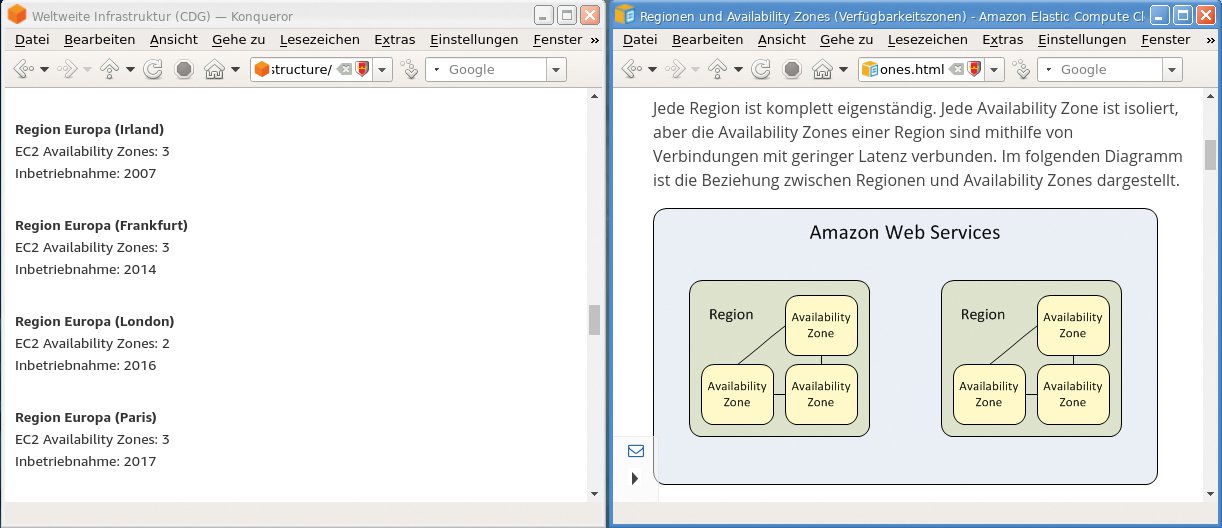
Abbildung 3: Amazons Konzept von Regionen und Availability Zones (AZ) in AWS sollte der Neukunde genau studieren.
Typischerweise sind die Erwartungen an die Infrastruktur der eigenen IT deutlich höher. Zwei kleine Rechenzentren (RZ), die nahe beieinander stehen, entsprechen quasi der AWS-Region London. Normalerweise stellt der Ausfall eines RZ kein vernachlässigbares Ereignis dar.
Anpassung ist Pflicht
Es hat sich bewährt, formalisiert zu überprüfen, ob sich eine Software oder ein Software-Anbieter für die Cloud eignen. Dazu generiert der Kunde einen Anforderungskatalog. Der sollte unter anderem die Fragen umfassen, die dieses Kapitel bereits erwähnt hat. Ebenso gehört dazu eine Auswahl an möglichen Antworten und deren Bewertung. Das kann im einfachsten Fall ein Papierformular oder die Vorlage einer Tabellenkalkulation sein. Diese helfen dann dabei, sowohl vorhandene als auch neu zu beschaffende Software zu bewerten.
Je nach Anbieter kann sich der Anforderungskatalog auch auf den Anwendungshersteller fokussieren und nicht auf die Anwendung selbst. Wichtig ist, dass der Admin beim Bewerten keine Ausnahme macht und möglichst objektive – wenn auch firmenspezifische – Kriterien im Katalog stehen. Dieses Verfahren lässt sich übrigens prima verallgemeinern und auch auf Zulieferer, Geschäftspartner und Cloudanbieter ausweiten.
Die hier dargestellten Herausforderungen sollen Leser nicht entmutigen, sondern dazu ermuntern, das Thema gründlich vorzubereiten. Wie eingangs erwähnt macht die Software nur eine Dimension aus, eine zweite bilden die Daten.
Daten: Das neue Öl
Auch Daten gibt es in verschiedenen Formen. Bei der selbst entwickelten Anwendung gilt es womöglich, geistiges Eigentum zu schützen. Dazu zählen beispielsweise implementierte Algorithmen oder Verfahren. Wie oben angedeutet können Mitarbeiter des Cloudanbieters prinzipiell auf die Infrastruktur zugreifen. Außerdem stellt sich die Frage, wie sehr ein Unternehmen der Mandantenfähigkeit einer verwendeten Cloudtechnologie vertrauen kann.
Bei Software von Drittanbietern liegt die Sache etwas einfacher. Hier dürfen die Admins davon ausgehen, dass die Cloud-tauglichen Lizenzen, Support-Verträge und Abos dieses Problem vollständig adressieren.
Eine zweite Kategorie von Daten umfasst jene Informationen, die die eigene Anwendung empfängt, verarbeitet und weitergibt. Die stammen womöglich von der eigenen Firma oder von Kunden und Partnern. Dazu zählen auch Daten über den Aufbau, die Konfiguration und die Topologie der Infrastruktur sowie der darüberliegenden Schichten.
Unabhängig davon stellt sich auch die Frage, welche Daten schützenswert sind. Das ist selten eine binäre Entscheidung, sondern benötigt typischerweise mindestens drei Kategorien. Demnach ist der Zugriff auf die Daten (a) für die gesamte Öffentlichkeit, (b) nur für die eigenen Kunden und Geschäftspartner oder (c) nur für die eigene Firma oder Teile der Belegschaft vorgesehen. Weitere Abstufungen sind nicht ungewöhnlich.
Auch die Natur der Daten spielt eine Rolle. Enthalten sie personenbezogene Informationen? Wenn ja, welche Gesetze gilt es zu beachten. Kenner der Szene denken wahrscheinlich sofort an die neue EU-Regulierung zum allgemeinen Datenschutz (General Data Protection Regulation, GDPR, [6]), die im Mai 2018 in Kraft tritt. Sind Kreditkarten-Informationen im Spiel, ruft das sofort den PCI-DSS (Payment Card Industry Data Security Standard, [7]) auf den Plan.
Im Angesicht solcher Industriestandards und Gesetze muss sich das wechselwillige Unternehmen klar machen, welche Verantwortung der Cloudanbieter übernimmt und wo sie endet, wie er die Cloud absichert und wie die Verpflichtungen der eigenen IT aussehen.
Abbildung 4 zeigt den Fall PCI-DSS beim Einsatz von AWS als Dienstleister [8]. Die Beschreibungen von “Sicherheit der Cloud an sich” und “Sicherheit innerhalb der Cloud” sind schlüssig und lassen sich einfach merken. Gibt es neben diesen Standards noch vertragliche Vereinbarungen oder länderspezifische Gesetze, die das Verarbeiten, Übermitteln oder Lagern von bestimmten Informationen regeln? Die erfordern womöglich eine weitere Art der Datenklassifikation.
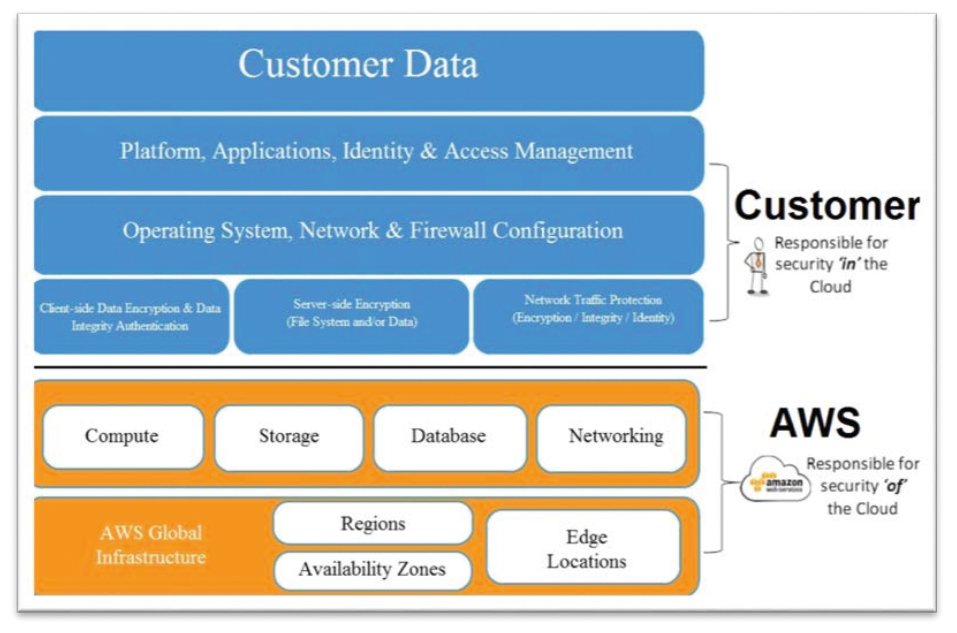
Abbildung 4: Verantwortungsbereiche für AWS und deren Nutzer für den Fall PCI-DSS. © Amazon.com
Auch das weiter oben genannte Thema Verfügbarkeit kann hier eine Rolle spielen. Sollten etwa Probleme im Cloudrechenzentrum in Deutschland auftreten, findet eine Wiederherstellung dann in Frankreich, China oder den USA statt? Was tun, wenn die Daten das Land nicht verlassen dürfen, wie im oben geschilderten Fall der AWS-Region London?
Auch die Menge an Daten will einkalkuliert sein. In der heimischen IT fallen fast keine Kosten für den Datentransfer an. Das macht Einsparungen oder Überlegungen in diese Richtung eigentlich gegenstandslos. Das ändert sich, wenn die Daten in die Wolke fließen oder aus ihr heraus, denn dies erfordert eine gründliche Analyse dieser Transitinformationen. Letztere stellt sich gerade in gewachsenen Umgebungen mitunter als sehr aufwändig heraus. Zudem lässt sich der Datenverkehr anschließend eigentlich nicht reduzieren, ohne Prozesse oder Arbeitsabläufe zu ändern.
Die Analyse wirkt sich mitunter auch auf die verwendete Software aus. Im ungünstigsten Fall muss die IT-Abteilung viele Sachen auf den Kopf stellen, wenn der Betrieb in der Cloud Kosten einsparen und nicht erhöhen soll. Die Frage nach dem Design der Datenverarbeitung ist daher auch ein wichtiger Punkt im erwähnten Anforderungskatalog.
Im Vergleich zur Migration der Software sind die Vorarbeiten zur Migration von Daten (Kategorisierung, Typisierung, Datenfluss-Analyse) eine Mammut-Aufgabe und zugleich zwingend notwendig, bevor es weiter in Richtung Wolke geht.
Es gibt zudem eine Verbindung zum Kapitel Software. Wer seine Anwendungen selbst schreibt, könnte überlegen, die Datenanalyse und zugehörige Kartografie quasi einzubauen. Ein vorhandenes Inventar der Software (Stichwort: CMDB, Configuration Management Database, [9]) sollte diese neuen Informationen ebenfalls enthalten. Zugleich helfen die Cloudanbieter und andere Dienstleister in solchen Fällen nur bedingt weiter, da viel firmeninternes Wissen nötig ist.
OSI-Schicht Nummer acht
Nach Software und Daten folgt nun der vielleicht heikelste Aspekt beim Weg in die Wolke – der Mensch. Steht die Infrastruktur in der Cloud, sind es nicht mehr die eigenen Mitarbeiter, die Firmware-Upgrades für die Hardware übernehmen, Kabel verlegen und das Blech ins Rack schrauben. Wer überwacht die Kühlung oder erledigt das Zoning?
Ein paar traditionelle Jobs einer IT-Landschaft fallen also weg. Das sieht auch auf den höheren Schichten im Technologie-Stapel nicht besser aus. Die Clouddienstleister bieten vorgefertigte Abbilder für verschiedene Linux-Distributionen und Windows-Versionen. Die Gebühren dafür sind Teil des Gesamtpakets. Das traditionelle Beschaffen von Betriebssystemen wird überflüssig.
Diese Veränderungen erklären die Skepsis oder vielleicht sogar Sorgen, die den Weg in die Wolke begleiten. Mit Software oder Dekreten lässt sich diese Herausforderung nicht lösen. Vielmehr muss das Management die IT oder sogar die gesamte Firma neu organisieren, denn ein Infrastruktur-zentrierter Ansatz funktioniert dann nicht mehr, diese Aufgaben sind künftig ausgelagert.
Es gibt hier prinzipiell zwei Herangehensweisen. Die erste lagert die Aktivitäten zur Cloud in ein neues Unternehmen aus. Das erleichtert es, neue Prozesse, Herangehensweisen und Prozeduren aufzusetzen, ohne Rücksicht auf Altlasten. So eine Aufteilung hat aber ihren Preis. Da ist einmal organisatorischer Mehraufwand, etwa im Personalwesen. Schlimmer ist allerdings das Risiko, eine Art Zwei-Klassen-Gesellschaft aufzubauen. Drin ist nur, wer im Cloudteam arbeitet. Traditionelle IT gilt dann eher als uncool und vom Aussterben bedroht.
Herangehensweise Nummer zwei krempelt die Organisationsstruktur um. Idealerweise ähneln die Schnittstellen zur eigenen Infrastruktur denen der Clouddienstleister. Der Fokus verschiebt sich in Richtung der Geschäftsanwendung und des Kunden. Die interne IT befolgt gleiche oder zumindest ähnliche Prinzipien wie Amazon & Co. Es gibt also AZs, Regionen und so weiter.
Eine solche Reorganisation ist aber auch kein Pappenstiel – selbst wenn die Nachteile der ersten Herangehensweise hier weniger ins Gewicht fallen. Beide Varianten eröffnen aber die Möglichkeit, neue oder angepasste Prozesse und Arbeitsabläufe zu installieren. Sie erlauben es, Sysadmins in Cloudingenieure, Datenbank-Admins in Data Scientists, Anwendungsverwalter in Automatisierungsspezialisten zu verwandeln. Kurzum: Alte Rollen und Position fallen weg, neue, zukunftsorientierte, entstehen.

Abbildung 5: Die bimodale IT nach Gartner ist bloß eine der Methoden, um die IT neu zu organisieren.
Im Umfeld des beschriebenen Dilemmas haben sich einige Ansätze, Praktiken und Methoden etabliert. Da sind die bimodale IT (Abbildung 5, [10]), Devops, IT der zwei Geschwindigkeiten oder auch Lean und Agile. Diese Vielfalt an Lösungsvorschlägen suggeriert, dass die Transformation einfach ist und es nur auf die richtigen Werkzeuge ankommt. Tatsächlich ist genau das Gegenteil der Fall. Im Zentrum steht der Mensch, stehen die Mitarbeiter, Kollegen und auch die Chefs und Vorgesetzten.
Fazit
An dieser Stelle schließt sich der Kreis zum Beginn dieses Artikels. Welche Probleme der bisherigen IT-Infrastruktur soll die Cloud lösen? Welche Erwartungen gibt es? Welche Ziele will man erreichen? Tiefgreifende Änderungen lassen sich in Unternehmen einfacher umsetzen, wenn die Notwendigkeit und die Hintergründe klar sind und quer durch die Organisation Befürworter finden.
Der Weg in die Cloud ist also gangbar, aber mit nicht zu unterschätzenden Herausforderungen gespickt. Die Beweggründe sollten daher wasserdicht und nachvollziehbar sein. Das beginnt bei der eigenen Belegschaft, schließt aber auch Partner, Dienstleister und Kunden mit ein. Das Verwalten von Software und Daten in der Cloud erfordert Veränderungen, Anpassung und einiges an Hausaufgaben. Auch neue Prozesse, Arbeitsabläufe und Herangehensweisen gehören dazu. Das Wissen und die gesammelten Erfahrungen beim Betrieb einer eigenen IT-Landschaft sind dabei nützlich. Zentrale Komponente ist und bleibt aber die eigene Belegschaft.
Infos
- Amazon Web Services: http://aws.amazon.com/de/
- Google-Cloud-Plattform: http://cloud.google.com/?hl=de
- Microsoft Azure: http://azure.microsoft.com/de-de/
- Cloud in der Wikipedia: http://de.wikipedia.org/wiki/Cloud_Computing
- AWS SLA: http://aws.amazon.com/de/ec2/sla/
- GDPR: http://www.eugdpr.org
- PCI-DSS: http://www.pcisecuritystandards.org
- AWS und PCI-DSS: http://d0.awsstatic.com/whitepapers/compliance/AWS_Anitian_Wookbook_PCI_Cloud_Compliance.pdf
- Configuration Management Database:http://de.wikipedia.org/wiki/Configuration_Management_Database
- Bimodale IT: http://www.gartner.com/it-glossary/bimodal/





