
© victor zastolskiy, 123RF
Nie war es einfacher, IT-Services in die Cloud auszulagern. Einer der größten Anbieter dafür ist Amazon Web Services. Das Linux-Magazin traf den Chefarchitekten der Plattform, Glenn Gore, zum Gespräch über Entwicklungsstrategie, Datensicherheit, Chaos-Tests und das Verhältnis zu Open Source und Linux.
Amazon Web Services, kurz AWS, gehört zu den fünf größten Anbietern von Clouddienstleistungen weltweit. Die Cloud-Computing-Plattform entstand vor über 20 Jahren, um eine flexibel skalierbare Datenbank- und Speicherlösung für die Onlinehandel-Plattform Amazon zu schaffen. Verkaufskampagnen wie der in den USA übliche Schwarze Freitag (Black Friday) oder der Cyber Monday belasteten die Seiten des Onlinehändlers extrem. Darauf musste das Unternehmen reagieren und baute in Vor-Cloud-Zeiten umfangreiche Kapazitäten auf.
Aus den Erkenntnissen, die Amazon dabei gewann, entwickelte es seine Clouddienste. Seit 2006 stellt es sie anderen Unternehmen zur Verfügung, die sich so nicht mit dem Aufbau entsprechender Infrastrukturen herumschlagen müssen. Zudem sah Amazon bereits das enorme geschäftliche Potenzial der Cloud.
Die Datenbankdienste waren nur der Anfang. Insgesamt mehr als 90 verschiedene Dienste in der Cloud, von Speicherplatz bis hin zu künstlicher Intelligenz und maschinellem Lernen, bieten die Amazon Web Services aktuell an (Abbildung 1). Dazu gehört auch Rechenzeit in der Cloud – von der kurzfristig nutzbaren virtuellen Maschine bis hin zu GPU-basierten Hochleistungsrechnern.
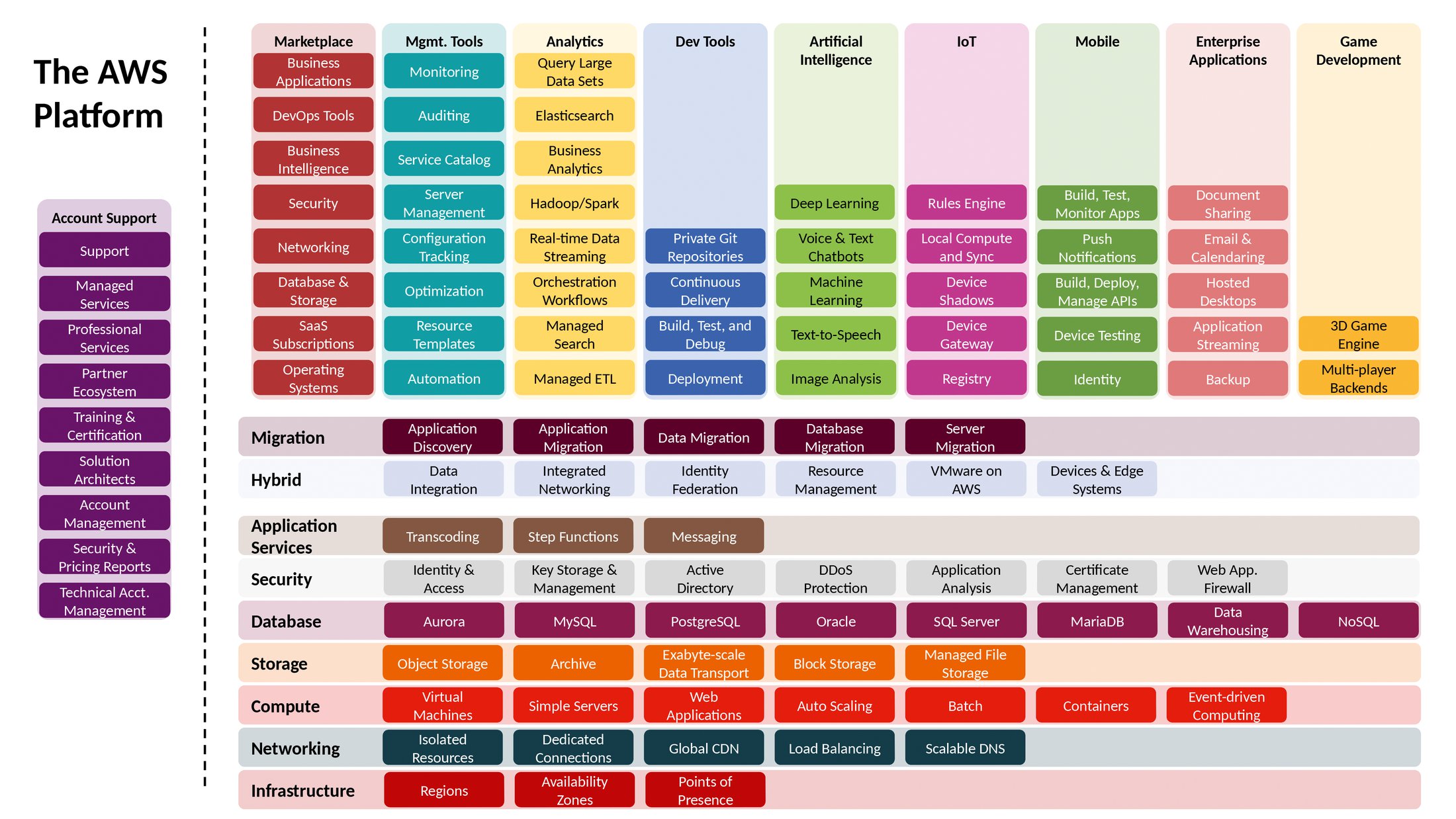
Abbildung 1: Alle diese Services bietet AWS gegenwärtig an.
Hoch profitabel in der Cloud
Heute generiert AWS mehrere Milliarden US-Dollar Umsatz außerhalb des eigentlichen Amazon-Universums aus Handel und Unterhaltung. Es erzielte allein im dritten Quartal 2017 Einnahmen von 4,8 Milliarden US-Dollar. In Deutschland nutzen nach Amazon-Angaben mehr als zwei Drittel der im DAX 30 gelisteten Unternehmen die Web Services.
Die AWS-Rechenzentren sind weltweit verteilt [1]. Sie werden in derzeit 16 Regionen mit 44 Availability Zones unterteilt (Abbildung 2). Dabei umfasst eine Region mehrere Rechenzentren, die in einer Metropolzone um eine Stadt herum gruppiert sind. Jede Region besteht wiederum aus zwei bis fünf so genannten Availabilitiy Zones (Verfügbarkeitszonen).
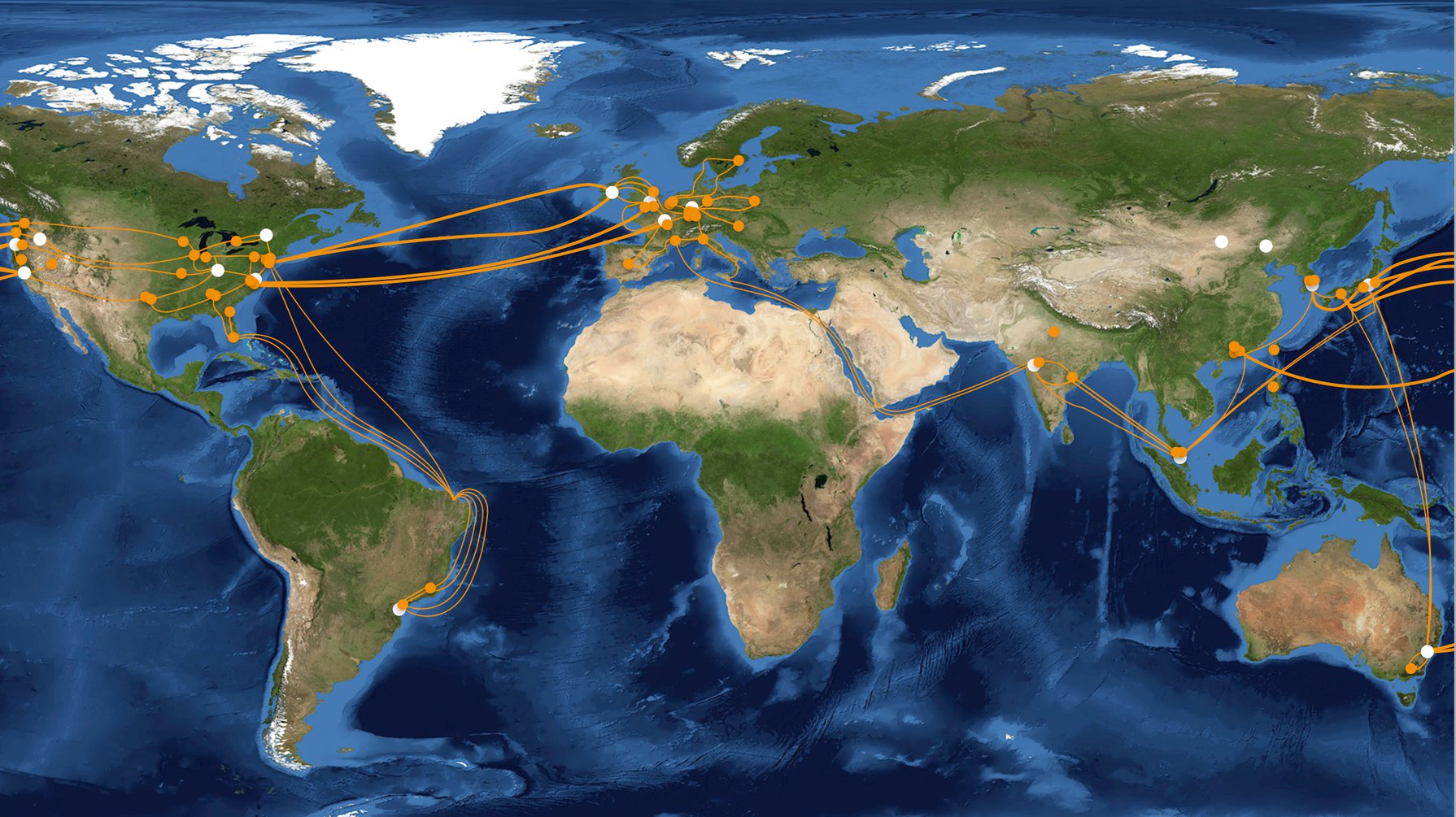
Abbildung 2: Weltweit verteilt: Amazons AWS-Rechenzentren befinden sich an 16 Standorten verteilt über alle fünf Kontinente.
Innerhalb einer solchen Zone gibt es mehrere Rechenzentren, die nah beieinanderliegen und ähnliche Bedingungen haben, etwa dieselben Netzwerk- und Energie-Anbieter oder geologische Bedingungen, und daher auch ähnlichen Risiken ausgesetzt sind. Dieses Konzept soll dafür sorgen, dass ein Ereignis – statistisch gesehen – nur eine Availabilitiy Zone gleichzeitig betrifft.
Thema Datenschutz
Überall auf der Welt sorgt sich AWS um den Datenschutz. “In keinem Land der Erde habe ich bisher gehört: Privatsphäre ist uns egal”, meint AWS-Chefarchitekt Glenn Gore im Gespräch mit dem Linux-Magazin. AWS verfolge weltweit eine einheitliche Strategie, die der Datensicherheit höchste Priorität einräumt. Dem Kunden soll es egal sein können, wo ein Rechenzentrum angesiedelt ist. Kein Unberechtigter dürfe Zugriff auf die Daten haben. Deutschland und Europa mit ihren strengen Vorschriften und Gesetzen seien da vorbildhaft. So habe man bereits Teile der kommenden europäischen Datenschutz-Grundverordnung (GDPR) umgesetzt oder die eigenen Services daraufhin überprüft.
Jegliche Verantwortung für die Datensicherheit übernimmt AWS dabei jedoch nicht: “Wir ziehen eine rote Linie, bis wohin unsere Verantwortung geht. Alles darüber liegt beim Kunden”, erklärt Glenn Gore. In Verantwortung von AWS seien die technischen Komponenten: die Sicherheit der virtuellen Maschinen, die des Hypervisors, das Netzwerk.
“Der Kunde selbst hat aber auch Verantwortung für seine Anwendung und für die Absicherung seiner Daten.” AWS helfe den Kunden dabei – unter anderem mit seinen Best-Practice-Beispielen, mit Sicherheitszertifizierungen oder speziellen Trainings. Glenn Gore: “Wir wollen erreichen, dass der Kunde in der Lage ist, sich genauso abzusichern, wie wir es uns selbst vorgeben.”
Gore bringt es auf eine einfache Formel: “Verschlüssle alles!” Denn wenn die Daten einmal verschlüsselt seien, habe nur noch der Kunde Zugriff darauf – keine andere Instanz, weder AWS selbst noch gegebenenfalls bösartige Angreifer oder staatliche Stellen. Gore betont, der Kunde müsse aber auch darauf achten, wem er Zugriff gewähre und wie er die Schlüssel manage.
Die Verschlüsselung der Daten sei auch wichtig, weil es aufgrund der verteilten Strukturen und der fortschreitenden globalisierten Wirtschaft heute kaum mehr möglich sei, Daten gezielt ausschließlich in einem Land der Erde abzulegen. Dennoch könnten bei AWS die Kunden entscheiden, in welchen Regionen ihre Daten zu speichern sind, und diese gezielt auf drei Rechenzentren verteilen.
Die Pizza als Modell
Bei der Entwicklung pflegt AWS einen eigenen Stil. Glenn Gore beschreibt ihn als “Two Pizza Team”-Konzept. Danach sollten an einem Teilprojekt nur so viele arbeiten, wie von zwei (großen) Pizzas satt werden. In der Regel seien das sieben bis zehn Programmierer. Grundvoraussetzung: Die Teile sind entsprechend dimensioniert. Dafür teilt die Firma hochkomplexe Projekte mit oft mehr als hundert Entwicklern in Chunks auf. Jeder dieser Chunks wird explizit beschrieben: Was soll das Software-Teilstück können? Wie wird es angesprochen? Jedes API, über das Software mit anderen Bestandteilen kommuniziert, ist vorab verbindlich festgelegt. So versuche man, Inkompatibilitäten bereits vor Entwicklungsstart zu vermeiden.
Innerhalb des Chunk kann das Team selbst entscheiden, welche Technologien es wählt. Eine exotische oder experimentelle Programmiersprache? Ist dem Team überlassen. Hauptsache ist, die Software funktioniert am Ende: “Die Verantwortung dafür liegt ganz beim Team.” So verfahre man seit mehr als zehn Jahren, und das Verfahren habe dafür gesorgt, dass die Plattform – trotz des enormen Wachstums – stabil geblieben sei.
Aus der Freiheit der Entwickler entstanden etliche Innovationen, die AWS heute auf beinahe 100 Services haben anwachsen lassen. Dazu beigetragen haben auch die Kunden, so Gore: “Unsere Entwicklung wird von den Kunden getrieben. Sie sorgten in der Vergangenheit für 90 Prozent der Feature-Updates.”
Dabei sind die Entwicklungen bei AWS sehr speziell – bei Hard- wie bei Software. Ohne sich in die Karten schauen zu lassen, beschreibt Glenn Gore, dass fast jedes Stück Software und ein Großteil der Hardware individuell für AWS produziert wird. Dank Partnerschaften mit Intel und anderen Chip-Größen habe man auch Zugriff auf die neuesten Technologien. Die Kehrseite sei, so Gore, dass Bereiche abseits der standardisierten Schnittstellen kaum passend für andere Unternehmen sind (Abbildung 3).

Abbildung 3: Dieser Chip wurde speziell für Amazon designt und hergestellt.
Als Beispiel dafür, wie anders man sei, beschreibt Gore die unternehmenseigenen Umspannwerke für die Rechenzentren. Normalerweise würden diese Einrichtungen so geplant, dass sie ausfallsicher um jeden Preis seien. AWS hingegen sei es wichtiger, dass die Rechenzentren keinen Schaden nehmen. Wenn etwas schiefgehe, dann führen sie halt das Umspannwerk herunter und ein anderes springe ein, erklärt Glenn Gore: “Selbst wenn es abbrennt. Das ist o.k. Wir haben alles so designt, dass unsere Systeme weiterarbeiten. Hauptsache ist: Der Kunde merkt nichts. Er bezahlt schließlich dafür, dass die Systeme und Services laufen.”
Ähnlich sieht es bei der Vernetzung der Standorte, der Availability Zones, aus. Sie seien so designt, dass es möglichst zu keinen Ausfallzeiten komme. Tausende von Glasfaserleitungen verbinden die Standorte, was nebenbei für hervorragende geringe Latenz sorgt, so Gore.
Chaos mit System
Ausfälle vermeiden – das ist das Credo der Weiterentwicklung bei AWS und spiegelt sich in den Stresstest- und Entwicklungsstrategien wider. Hierbei folgt das Unternehmen dem Beispiel von Netflix und setzt auf “Chaos Engineering”. Das bedeutet so viel wie: Egal was ausfällt, das Gesamtsystem läuft weiter.
Was alles kaputtgehen kann, zeigt der Chaos Monkey [2]. Die Open-Source-Software simuliert salopp gesprochen einen Affen, der durch die Rechenzentren marodiert und wahllos Rechner und Dienste zerstört. Der Störenfried zieht da eine Baugruppe aus dem Rack, dort ein paar Kabel. Virtuelle Maschinen versagen, Container stürzen ab. Schlimmstenfalls fällt ein Rechenzentrum ganz aus.
Was der Chaos Monkey anfasst, wissen die Tester vorher nicht. “Wir bei Amazon nutzen diese Testmethoden schon lange. Schalten Dinge aus und wieder an, und das ganz ohne Vorwarnung. Es ist egal, was der Chaos Monkey ausgeschaltet hat. Der Service, den der Kunde nutzt, läuft weiter”, beschreibt Glenn Gore. Die jüngste Neuentwicklung dieser Resilienztests, die Tester und Entwickler bei AWS einsetzen, ist das IBM-Tool Gremlin ([3], [4]). Sie können mit dem in Python geschriebenen Tool beispielsweise Ausfälle von Webservern, Datenbanken und anderen Bestandteilen der Mikroarchitektur simulieren (Abbildung 4).
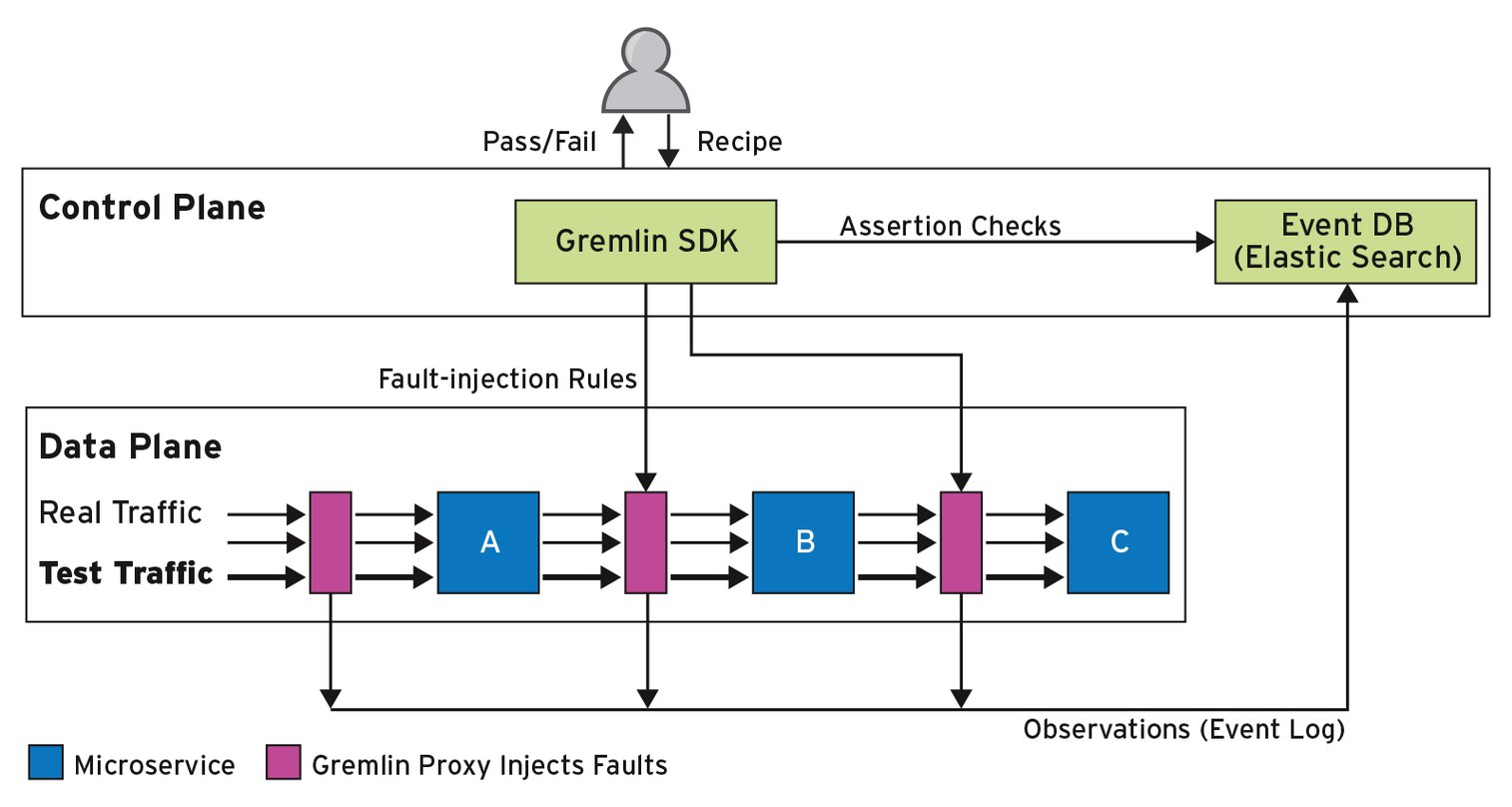
Abbildung 4: Simuliert Ausfälle: Das Resilienz-Tool Gremlin testet Microservices auf Herz und Nieren, indem es gezielt und nicht vorhersehbar Fehler einschmuggelt.
“Das passiert mittlerweile nicht mehr nur in der Entwicklung, sondern wir nutzen diese Test auch in produktiven Umgebungen.” Glenn Gore beschreibt das Beispiel einer australischen Bank. Die habe ihre Website von selbst betriebenen Rechenzentren zu AWS migriert. Dabei seien auch die Verlässlichkeitstests zum Einsatz gekommen. “Überraschenderweise konnten die Verantwortlichen mit Hilfe der neuen Architektur und nach den Tests die Zahl der genutzten Instanzen um 90 Prozent reduzieren.” Das klappt, so Gore, weil Instanzen binnen kürzester Zeit neu gestartet und wieder gekappt werden können.
Weitere Betriebssicherheit bringen Amazons verteilte Rechenzentren. “Früher hat man gesagt: Ein Server für alles. Und diesen Server sichere ich bestmöglich ab, koste es, was es wolle”, fasst Gore die Erfahrungen mit dieser Strategie zusammen. “Jetzt setzt sich die Erkenntnis durch, dass es um einiges effektiver ist, das Risiko mit Hilfe einer verteilten Infrastruktur zu beherrschen.” Zwar sei ein einzelner Server einfacher zu managen, doch könnten selbst kleinere Fehler dieses Servers schnell zu einem Totalausfall führen. In Cloudsetups hingegen würden bei kleinen Engpässen einfach neue Instanzen mit voller Kapazität aufgerufen.
Linux ja, aber …
Nach dem Einsatz von GNU/Linux und anderer quelloffener freier Software gefragt, antwortet Glenn Gore sofort: “Wir sind große Fans von Linux und Open Source. Viele unserer Technologien bei Amazon basieren auf den fundamentalen Konzepten der Community.” Außerdem würden die Kunden vor allem wegen der dann fehlenden Lizenzkosten immer häufiger zu quelloffener Software wechseln: “Sie fragen sich, warum soll ich dafür zahlen?”
Wo konkret allerdings Linux-Systeme bei AWS im Einsatz seien, lässt Glenn Gore offen: “Wir legen unsere Spezifikationen nicht offen.” Er begründet das damit, dass sich AWS mittlerweile so weit von den ursprünglichen Softwareprojekten entfernt habe, dass diese kaum noch erkennbar seien. Ähnlich wie bei der Hardware sei die Software so weit spezialisiert, dass niemand anderes als AWS selbst etwas damit anfangen könne: “Beispiel S3”, setzt Glenn Gore an, “S3 wird beispielsweise über drei Rechenzentren realisiert. Dabei kommen Hunderte und Aberhunderte von Servern zum Einsatz, um die Basis-Kapazitäten für all die Dinge, die für S3 notwendig sind, aufzubauen. Wer sonst als wir kann so etwas sinnvoll einsetzen?”
Deshalb steuere man eher weniger zur Open-Source-Community bei. “Es ist einfach nicht sinnvoll, aus unseren Services einzelne Komponente zu nehmen und sie unter einer Open-Source-Lizenz zu veröffentlichen. Sie sind einfach zu speziell. Wo wir aber können, steuern wir unseren Anteil zur Open-Source-Welt bei.” Er wolle nicht den Eindruck entstehen lassen, man teile nicht, betont Glenn Gore. Bei AWS pflege man eine Kultur der Wiederverwendung von Code-Bestandteilen. Doch was intern genutzt werde, sei extrem spezialisiert und angepasst – daher die Zurückhaltung bei der Veröffentlichung von Code.
Erfahrung dagegen teile man sehr wohl, und zwar häufig. AWS-Engineering-Teams besuchen demnach regelmäßig Konferenzen und andere Industrieveranstaltungen und geben weiter, was sie etwa bei Containerisierung oder beim High Performance Computing gelernt haben. Zudem beteilige sich AWS an internationalen Standardisierungsgremien wie der Cloud Native Computing Foundation (CNCF) und anderen.
Hauptzweck der Standardisierungsgremien sind einheitliche, gut dokumentierte Schnittstellen. Die sind für Glenn Gore maßgeblich. Dem Kunden sei es doch mehr oder weniger egal, welcher Anbieter hinter einem Dienst stehe. Vielmehr müssen Kunden die Anbieter problemlos wechseln können: “Sie müssen sich ja fragen: Ich nutze sehr spezielle AWS-Technologien. Schließe ich mich damit zu sehr ein?”
Ein gutes Beispiel sei Objektverwaltung. Intern arbeiten die Lösungen alle sehr verschieden. Aber an der Schnittstelle, und das sei dem Kunden wichtig, bliebe es bei vier Funktionen: “Ich schreibe ein Objekt, ich lese ein Objekt, ich lösche ein Objekt oder ich ändere ein Objekt. Egal welche Dienste ich nutze, vielleicht brauche ich einen Konverter, aber die Grundfunktionen bleiben die gleichen.” Deswegen seien klar definierte Schnittstellen so wichtig für gute Architekturen. Eine Sache, die ihm als Software-Architekten besonders am Herzen liege.
Lessons learned
Mit über zwanzig Jahren Erfahrung als Entwickler, Chief Technical Officer und Software Architekt sind es für Glenn Gore vier Ratschläge, die er Administratoren und Entwicklern mitgeben möchte. Zuallererst rät er: Mach es einfach. Kompliziert werden die Systeme von ganz allein. Deswegen sei es wichtig, einzelne Lösungen und Komponenten schlank und elegant zu halten. Dazu passt der zweite Rat: Brich komplexe Projekte in lösbare kleinere Komponenten auf. Für diese Bestandteile müsse man als Entwickler dann auch die volle Verantwortung für die Funktionsfähigkeit übernehmen, so der dritte Rat. Die könnten die Anwender oder jene Teams, die mit den Bestandteilen arbeiteten, nicht übernehmen.
Allerdings würden dort die Fehler auftreten. “Erwartet nicht, dass sich jemand um Fehler in eurem Code kümmern wird. Sie werden vielleicht einen Workaround schreiben. Doch der löst nicht das zugrunde liegende Problem.” Deswegen sei es wichtig, dass die Verantwortung beim Entwickler beziehungsweise dem Team bleibt und diese das Problem lösen.
Und viertens: Erfasse und kontrolliere einfach alles und kontinuierlich. Die entstehenden Daten speichern sei heute die kleinste Herausforderung und koste nicht mehr viel. Aus den gesammelten Daten jedoch ließen sich so viele Erkenntnisse ableiten, so Gore: “Wenn ich etwas in einem Diagramm zeigen kann, sollte ich auch die Daten entsprechend aufzeichnen und das Diagramm erstellen.” So könne man unter anderem die Fehlersuche deutlich beschleunigen.
Infos
-
Globale AWS-Infrastruktur: https://aws.amazon.com/de/about-aws/global-infrastructure/
-
Chaos-Monkey-Stresstest: https://github.com/Netflix/SimianArmy/wiki/Chaos-Monkey
-
Beschreibung Gremlin-Resilienztest: https://developer.ibm.com/open/2016/06/06/systematically-resilience-testing-of-microservices-with-gremlin/
-
Github Gremlin-Resilienztest: https://github.com/ResilienceTesting/gremlinsdk-python

Der Australier Glenn Gore startete seine Karriere beim Internetprovider Oz Mail. Dort lernte er in den 90er Jahren, als das World Wide Web gerade erst loslegte, die technologischen Grundlagen und wie man Internet-Anwendungen skaliert. Später arbeitete er für den damals weltgrößten Netzwerkbetreiber UUNET sowie als Chief Technology Officer für den größten australischen Webhoster Web Central. Bei Amazon Web Services war Gore auf mehreren Positionen tätig, zuletzt als Head of Architecture für die Regionen Asia Pacific und EMEA. Heute ist er als Chief Architect verantwortlich für die Erarbeitung von architektonischen Best-Practice-Lösungen und die Arbeit mit Großkunden. Er war beteiligt an Projekten mit Facebook, Twitter und der NASA.





