
Hochperformanten Code zu schreiben, den nur Eingeweihte zu würdigen wissen, ist für Entwickler ein bisschen so, wie für Formel-1-Testpiloten mit einem neuen Motor den Rundenrekord auf dem Nürburgring zu knacken. Doch oft endet der Tuningversuch in der Leitplanke.
Zehn Tipps für C++-Programmierer, die guten Code produzieren wollen, hatte diese Serie vor vier Folgen postuliert (Abbildung 1). Diesmal widmet sie sich einem trügerischen Ehrgeiz, dem schon viele Performance-Junkies erlegen sind: Sie optimieren einen Code-Abschnitt mit viel Aufwand und Enthusiasmus, um das letzte Quäntchen Laufzeitvorteil herauszukitzeln. Dabei geht ihnen aber der Blick für das große Ganze verloren, weshalb sie an den falschen Stellschraube drehen oder – wie in der folgenden Fallstudie – in die falsche Richtung.

Abbildung 1: Der fünfte Leitsatz für C++-Programmierer mahnt das große Bild im Auge zu behalten.
Als Studienobjekt soll das Singleton Pattern [1] dienen. Dieses Erzeugungsmuster stellt sicher, dass nur eine Instanz eines Objekts existiert (oder dass eine Unterklassenbildung ein einziges Objekt spezialisiert). Etwa die Hälfte der Entwicklergemeinde setzt das Pattern gerne ein, bei anderen genießt es den Ruf als Anti-Pattern. Dieser Artikel will die Diskussion darum nicht weiter anfachen, sondern das Singleton Pattern als Demonstrationsobjekt für überambitionierte Performance-Optimierung heranziehen.
Klassisch angerührt
Die Herausforderung für den Programmierer eines Multithreading-Programms, in dem er das Singleton Pattern implementiert, ist es, das Singleton-Objekt Thread-sicher zu initialisieren. In modernem C++ wird er dieser Aufgabe schnell und elegant mit Hilfe von Locks gerecht. Listing 1 zeigt das Ergebnis.
Listing 1
Singleton Pattern mit einem Lock
01 mutex myMutex;
02
03 class MySingleton{
04 public:
05 static MySingleton& getInstance(){
06 lock_guard<mutex> myLock(myMutex);
07 if( !instance ) instance= new MySingleton();
08 return *instance;
09 }
10 private:
11 MySingleton()= default;
12 ~MySingleton()= default;
13 MySingleton(const MySingleton&)= delete;
14 MySingleton& operator=(const MySingleton&)= delete;
15 static MySingleton* instance;
16 };
17 MySingleton* MySingleton::instance= nullptr;
Das Lock in Zeile 6 stellt klassisch sicher, dass nur genau eine Instanz der Klasse »MySingleton« erzeugbar ist. In bekannter Manier besitzt das Singleton einen privaten Konstruktor und Destruktor (Zeile 11 und 12) sowie einen Kopierkonstruktor (Zeile 13) und einen Copy-Zuweisungsoperator (Zeile 14), die beide auf »delete« gesetzt sind. Damit lässt sich das Singleton nur durch die statische Methode »getInstance()« in Zeile 5 erzeugen und nicht kopieren oder zuweisen.
Ist diese klassische Implementierung Thread-sicher? Ja, ist sie. Ist sie performant? Nein, denn ein teures Lock (in Zeile 6) schützt jeden Zugriff auf das Singleton-Objekt. Das passiert sogar, wenn der Zugriff auf das Singleton lesend erfolgt. Dabei ist der Lese-Zugriff per se Thread-sicher, lediglich das Initialisieren des Objekts benötigt einen Schutz.
Langsamer geht’s nicht
Um festzustellen, wie teuer die aufwändige Synchronisation zustehen kommt, ist das Programm in Listing 2 entstanden. Es implementiert in den Zeilen 44 bis 47 vier Promises und Futures. Die Promises rufen jeweils in einem separaten Thread die Funktion »getTime()« auf. Der »getTime()«-Körper in den Zeilen 32 bis 40 verwendet zehn Millionen Mal das Singleton (Zeile 36). Der erste Aufruf initialisiert das Singleton. Zum Abschluss addiert Zeile 44 die Ausführungszeit der vier Promises mit Hilfe ihrer assoziierten Futures und gibt sie aus.
Listing 2
Singleton Pattern anwenden
01 #include <chrono>
02 #include <iostream>
03 #include <future>
04 #include <mutex>
05
06 constexpr auto tenMill = 10000000;
07
08 std::mutex myMutex;
09
10 class MySingleton{
11 public:
12 static MySingleton& getInstance(){
13 std::lock_guard<std::mutex> myLock(myMutex);
14 if ( !instance ){
15 instance = new MySingleton();
16 }
17 volatile int dummy{};
18 return *instance;
19 }
20 private:
21 MySingleton() = default;
22 ~MySingleton() = default;
23 MySingleton(const MySingleton&) = delete;
24 MySingleton& operator=(const MySingleton&) = delete;
25
26 static MySingleton* instance;
27 };
28
29
30 MySingleton* MySingleton::instance = nullptr;
31
32 std::chrono::duration<double> getTime(){
33
34 auto begin = std::chrono::system_clock::now();
35 for ( size_t i = 0; i <= tenMill; ++i){
36 MySingleton::getInstance();
37 }
38 return std::chrono::system_clock::now() - begin;
39
40 }
41
42 int main(){
43
44 auto fut1= std::async(std::launch::async, getTime);
45 auto fut2= std::async(std::launch::async, getTime);
46 auto fut3= std::async(std::launch::async, getTime);
47 auto fut4= std::async(std::launch::async, getTime);
48
49 auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
50
51 std::cout << total.count() << std::endl;
52 }
Eine Feinheit: Da sich der Artikel an der Performance abarbeitet, hat der Autor Listing 2 mit maximaler Optimierung, also mit »-O3«, übersetzt. Leider würde der Optimierer nun aber den Aufruf des Singleton in Zeile 36 wegoptimieren. Diesen kontraproduktiven Effekt verhindert vorausschauend Zeile 17 mit der zusätzlichen »volatile«-Variablen.
Es wird Zeit, nach der erreichbaren Laufzeit zu schauen: Ausgeführt auf einem Desktop-PC mit vier Kernen benötigt das Programm gut 12 Sekunden (Abbildung 2). Das ist wirklich Schneckentempo.
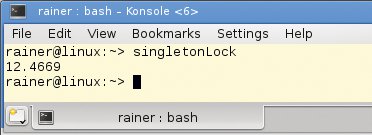
Abbildung 2: Ausgabe von Listing 2 mit der Lock-gesicherten Singleton-Implementierung aus Listing 1.
Doppelt hält nicht länger
Da sich alle weiteren Variationen und Anwendungen des Singleton Pattern lediglich in der Funktion »getInstance()« unterscheiden, konzentrieren sich die weiteren Mühen um Geschwindigkeit auf diese Funktion. Der erste Optimierungsversuch des Singleton Pattern benutzt das berühmt-berüchtigte Double-checked Locking Pattern. Berühmt-berüchtigt ist die doppelt überprüfte Sperrung, da ihre ursprüngliche Implementierung sich als nicht Thread-sicher erwies [2].
Die »getInstance()«-Funktion in Listing 3 stellt den Kern der Double-checked Locking Pattern vor. An die Stelle eines teuren Lock setzt Zeile 2 einen billigen Zeigervergleich. Nur wenn dieser Vergleich einen Nullzeiger zurückgibt, findet das teure Locken des Singleton-Objekts statt (Zeile 3). Da zwischen dem Zeigervergleich in Zeile 2 und dem Lock in Zeile 3 ein anderer Thread in der Zwischenzeit das Singleton-Objekt bereits initialisiert haben könnte, ist ein zweiter Zeigervergleich in Zeile 4 notwendig. Damit ist der Name geklärt: Zweimal gecheckt und einmal gelockt oder auch Double-checked Locking Pattern.
Listing 3
Mit Double-checked Locking Pattern
01 static MySingleton& getInstance(){
02 if ( !instance ){ // check
03 lock_guard<mutex> myLock(myMutex); // lock
04 if( !instance ) instance= new MySingleton(); // check
05 return *instance;
06 }
07 }
Der Ansatz wirkt clever. Man ahnt es aber bereits: Er ist nicht Thread-sicher. Das Problem ist, dass der Aufruf »instance= new MySingleton()« in Zeile 4 nicht atomar ist und genau betrachtet aus mindestens drei Schritten besteht:
1. Allokiere Speicher für »MySingleton()«.
2. Erzeuge das »MySingleton()«-Objekt im Speicher.
3. Verweise »instance« auf das »MySingleton()«-Objekt.
Diese Reihenfolge sichern aber weder der Compiler noch der Prozessor zu. Ihnen ist es beim Optimieren erlaubt, die Schritte etwa in der Abfolge 1, 3 und 2 auszuführen. In der Konsequenz allokiert das System zuerst den Speicher und lässt dann »instance« auf ein nicht initialisiertes Singleton-Objekt verweisen.
Versucht genau zu diesem Zeitpunkt ein anderer Thread auf das Singleton-Objekt zuzugreifen, ergibt der Zeigervergleich in Zeile 2 »true«. Der andere Thread meint, auf einem fertig initialisierten Singleton-Objekt zu agieren. Die Konsequenz ist ebenso simpel wie untragbar: Das Programmverhalten ist undefiniert.
Auf die Reihe gebracht
Listing 4 zeigt nun einen neuen Versuch, der beweist, dass sich mit C++11 das Double-checked Locking Pattern auch korrekt funktionierend, also Thread-sicher implementieren lässt. Der Code ist aber alles andere als leichte Kost.
Listing 4
Singleton Pattern mit atomaren Variabeln
01 static MySingleton* getInstance(){
02 MySingleton* sin = instance.load();
03 if (!sin){
04 std::lock_guard<std::mutex> myLock(myMutex);
05 sin = instance.load(std::memory_order_relaxed);
06 if(!sin){
07 sin = new MySingleton();
08 instance.store(sin);
09 }
10 }
11 volatile int dummy{};
12 return sin;
13 }
Im Gegensatz zu dem Versuch eben garantiert die Implementierung, dass der Ausdruck »sin = new MySingleton()« in Zeile 7 vor dem Speicherbefehl »instance.store(sin)« in der Zeile 8 steht. Die Zusicherung speist sich aus der sequenziellen Konsistenz, dem Standardverhalten für Operationen auf atomaren Variablen. Sie garantiert, dass jeder Thread seine Befehle in der Reihenfolge ausführt, in der sie im Sourcecode stehen. Details zum C++-Speichermodell hatte schon der Artikel [3] zusammengetragen.
Das zusätzliche Laden des Singleton-Objekts in Zeile 5 ist notwendig, da zwischen dem ersten Laden des Objekts in Zeile 3 und dem Setzen des Lock in Zeile 4 ein anderer Thread das Singleton-Objekt modifiziert haben könnte.
Abbildung 3 beantwortet die in Tuning-Kreisen naheliegende Frage, wie sich der Aufwand in der Praxis widerspiegelt: ein Turboboost! Die Applikation ist durch die Umstellung auf atomare Variablen um den Faktor 140 schneller geworden.
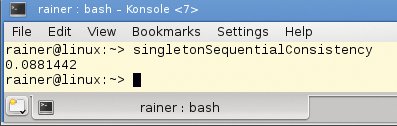
Abbildung 3: Benchmark-Ergebnisse der Variante mit atomaren Variablen und sequenzieller Konsistenz.
Das Letzte herausquetschen
Kaum zu glauben, aber das Gewinde der Performance-Schraube bietet noch Raum für ein paar Umdrehungen. Den zu nutzen wird aber – um im Bild zu bleiben – ein ziemliches Gewürge. Denn dieser letzte Optimierungsversuch bricht mit der sequenziellen Konsistenz und überfordert die natürliche Intuition des normalen Programmierers. Listing 5 gehört somit in der Domäne der absoluten Experten und verwendet die Acquire-Release-Semantik [3].
Listing 5
Singleton mit atomaren Variabeln und Acquire-Release-Semantik
01 static MySingleton* getInstance(){
02 MySingleton* sin = instance.load(std::memory_order_acquire);
03 if (!sin){
04 std::lock_guard<std::mutex> myLock(myMutex);
05 sin = instance.load(std::memory_order_relaxed);
06 if (!sin){
07 sin = new MySingleton();
08 instance.store(sin, std::memory_order_release);
09 }
10 }
11 volatile int dummy{};
12 return sin;
13 }
Das Lesen des Singleton-Objekts in Zeile 2 ist eine so genannte Acquire-Operation; das Schreiben des Objekts in Zeile 8 eine Release-Operation. Beide Operationen finden auf derselben atomaren Variablen »instance« statt. Entscheidend ist hier, dass der C++11-Standard zusichert, dass sich die Acquire-Operation mit der Release-Operation auf derselben atomaren Variablen synchronisiert.
Zudem etabliert die Acquire-Release-Semantik eine Ordnungsbedingung. Die besagt, dass das laufende Programm Lese- und Schreiboperation nicht vor eine Acquire-Operation und Lesen und Schreiben nicht hinter eine Release-Operation verschieben darf. Das ist die minimale Bedingung, um die Funktion »getInstance()« Thread-sicher zu gestalten. Es stellt sicher, dass »sin = new MySingleton()« in Zeile 7 stets vor dem Schreiben und dass »if (sin)« nach dem Lesen des Singleton-Objekts stattfindet.
Abbildung 4 beantwortet wieder die Reality-Check-Frage, ob der schwierig zu schreibende Code tatsächlich schneller unterwegs ist, sich also die minimale Synchronisation der »getInstance()«-Funktion auszahlt. Und tatsächlich: Die Acquire-Release-Semantik macht die Applikation nochmals um den Faktor 1,3 schneller – gegenüber der ersten Version mit Lock um nahezu den Faktor 200.
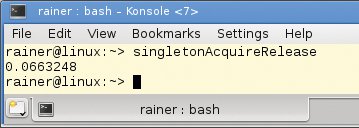
Abbildung 4: Laufzeitmessung der Variante mit atomaren Variablen und Acquire-Release-Semantik.
Nie auf Biegen und Brechen
Dieser Artikel könnte hier zu Ende gehen mit der Erkenntnis: Wer lange genug an seiner Implementierung herumschraubt, erhöht die Chance, zu performantem Code zu kommen. Doch der Artikel geht noch weiter und wendet sich dabei wieder eleganterem Code zu, der ein Singleton Pattern Thread-sicher implementiert: dem Meyers-Singleton [4], benannt nach Scott Meyers. Listing 6 zeigt das in Kürze und Klarheit kaum zu überbietende Ergebnis. Der C++-Standard sichert dabei zu, statische Variablen mit Blockgültigkeit Thread-sicher zu erzeugen. Genau so eine statische Variable mit Blockgültigkeit ist »instance«.
Listing 6
Meyers-Singleton
01 static MySingleton& getInstance(){
02 static MySingleton instance;
03 volatile int dummy{};
04 return instance;
05 }
Da bleibt nur die Gretchenfrage dieses Artikels ein letztes Mal zu beantworten, wie steht es um die Performance? Die Zahlen in Abbildung 5 sprechen eine deutliche Sprache. Das Meyers-Singleton ist etwa um den Faktor 1,5 schneller als die bisher schnellste Singleton-Version, die atomare Variablen mit Acquire-Release-Semantik einsetzt.
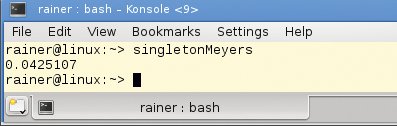
Abbildung 5: Ergebnisse der 40 Millionen gleichzeitigen Aufrufe implementiert als Meyers-Singleton.
Wenn das nicht ernüchternd und zufriedenstellend zugleich ist: Die eleganteste und einfachste Implementierung ist zugleich die schnellste. Darüber hinaus zeigt die Fallstudie schön, dass äußerste Optimierung nicht automatisch zum schnellsten Code führt, aber fast immer zu schwer verständlichem.
Wie geht’s weiter?
“Vermeide undefiniertes Verhalten” – unter diesem Motto wird der nächste C++-Artikel stehen. Denn sobald ein Programm undefiniertes Verhalten zu zeigen beginnt, sind keine verlässlichen Aussagen zu seinem Ergebnis möglich.
Infos
-
Singleton Pattern: https://de.wikipedia.org/wiki/Singleton_(Entwurfsmuster)
-
Double-checked locking Pattern: https://www.cs.umd.edu/~pugh/java/memoryModel/DoubleCheckedLocking.html
-
Rainer Grimm, “Der Vertrag”: https://www.linux-magazin.de/Ausgaben/2014/06/C-11
-
Scott Meyers: https://en.wikipedia.org/wiki/Scott_Meyers
Der Autor

Rainer Grimm ist Trainer für C++ und Python. Seine Bücher “C++11 für Programmierer”, “C++”, “C++11-Standardbibliothek” sowie “The C++ Standard Library” sind bei O’Reilly und Leanpub erschienen.





