
© Nikola Nikolovski, 123RF
Daten auf AWS S3 sitzen dort nicht zwangsläufig fest. Wer sie wiederhaben will, kann sie mit ein bisschen Python-Schmiermittel auf einen Rutsch abpumpen.
Auf EC2-Instanzen oder AWS-Lambda-Servern produzierte Daten landen oft in Amazons Storage-Lösung S3. Handelt es sich um viele Kleinstdateien, von denen der Kunde nur eine Auswahl lokal braucht, artet das Herunterladen per Browser schnell zu einer hakeligen Arbeit aus. Zum Glück bietet der Geräteschuppen von Amazon mit »awscli« und »boto3« aber Python-Libraries als Rüssel zum programmierten Abpumpen.
Auf der Kommandozeile kopiert das Python-Tool »aws« S3-Dateien aus der Cloud auf den lokalen Rechner. Der Admin installiert es mittels
pip3 install --user awscli
und richtet es dann für die entsprechende AWS-Zone unter Angabe von Username und Passwort ein. Er erhält einen Access-Token, den »aws« in »~/.aws/credentials« abspeichert und von da an nicht mehr nach dem Passwort fragt [1].
Daten liegen als Objekte unter String-Schlüsseln in S3. Enthält ein Bucket »prosnapshot« unter dem Schlüssel »hello.mp4« ein Video »video.mp4«, holt es der Admin auf der Kommandozeile mit dem Kommando
aws s3 cp s3://prosnapshot/ hello.mp4 video.mp4
von der Cloud auf die lokale Festplatte (Abbildung 1).
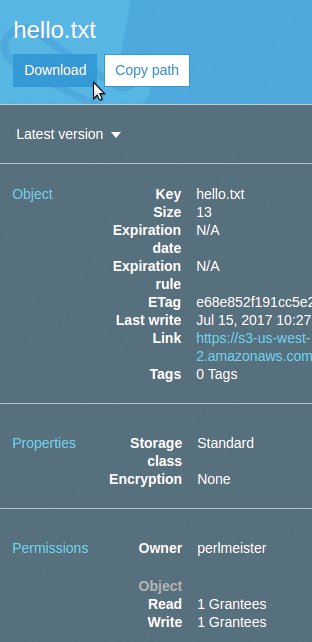
Abbildung 1: Der Browser holt ausgewählte S3-Dateien von der Cloud auf die Festplatte.
Das Tool »aws« nutzt hierzu die Python-Bibliothek »botocore«, auf die auch ein weiteres Programmier-SDK namens »boto3« aufsetzt, mit dem sich Skripte zur Automatisierung des Pumpprozesses schreiben lassen [2]. Der Befehl
pip3 install --user boto3
installiert das SDK auf dem System.
Ordnung
Listing 1 zieht mit »boto3« eine einzelne S3-Datei aus der Cloud ab. S3 kennt in Rohform keine Folder-Strukturen, sondern legt Daten unter beliebigen Schlüsseln ab. Doch bietet das Browser-Interface die Option, in einem Bucket neue Ordner mit Unterordnern in beliebiger Tiefe anzulegen und mit Dateien zu füllen (Abbildung 2).
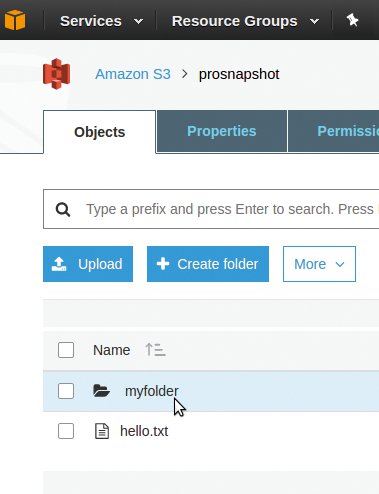
Abbildung 2: Im Browser erscheinen Unter-verzeichnisse, die S3 später einfach in den Schlüssel zu einem Storage-Objekt einarbeitet.
Unter der Haube bildet S3 diese Ordner als Schlüssel mit Dateipfaden nach Unix-Art nach.
Listing 1
hello-read.py
1 #!/usr/bin/python3
2 import boto3
3
4 s3 = boto3.resource('s3')
5 bucket = s3.Bucket('prosnapshot')
6 bucket.download_file('hello.txt', 'hello-down.txt')
So lässt sich zum Beispiel die Datei »hello.txt« mit dem Kommando
$ aws s3 cp s3://prosnapshot/myfolder/hello.txt hello.txt download: s3://prosnapshot/myfolder/hello.txt to ./hello.txt
aus dem Ordner »myfolder« im Bucket »prosnapshot« von S3 abziehen.
Noch einmal mit Schmackes
Wer allerdings gleich alle Dateien in einem S3-Bucket (Abbildung 3) auf einen Rutsch absaugen möchte, verfällt vielleicht auf die Idee, diese einfach wie in Listing 2 mit »objects.all()« aufzulisten und abzuarbeiten. Das funktioniert mit Buckets mit bis zu 1000 Objekten tadellos, doch da das darunterliegende REST-Interface nur maximal 1000 Ergebnisse liefert, hört die Schleife beim 1001sten Objekt auf.
Listing 2
s3-all.py
1 #!/usr/bin/python3
2 import boto3
3
4 s3 = boto3.resource('s3')
5 bucket = s3.Bucket('prosnapshot')
6
7 for obj in bucket.objects.all():
8 print(obj)
Abbildung 3: Alle Dateien liegen in einem S3-Bucket.
Zur Lösung des Dilemmas bietet »boto3« so genannte Paginatoren, die maximal 1000 Objekte holen, sich den Offset merken und folgende Daten nachholen, bis der Bucket aufgearbeitet ist. Listing 3 holt alle Dateien eines Buckets aus der Cloud. Ihre Schlüssel interpretiert es als Unix-Pfade und speichert den Inhalt der zurückkommenden Objekte in lokalen Dateien mit identischen Namen ab.
Listing 3
s3-export.py
01 #!/usr/bin/python3
02 import boto3
03 import os
04
05 def s3pump(path,bucket):
06 dir=os.path.dirname(path)
07 if dir and not os.path.exists(dir):
08 os.makedirs(dir)
09 if os.path.basename(path):
10 bucket.download_file(path,path)
11
12 bname='prosnapshot'
13 client = boto3.client('s3')
14 bucket = boto3.resource('s3').Bucket(bname)
15
16 pgnr = client.get_paginator('list_objects')
17 page_it = pgnr.paginate(Bucket=bname)
18
19 for page in page_it:
20 if page.get('Contents') is not None:
21 for file in page.get('Contents'):
22 s3pump(file.get('Key'), bucket)
Datenhighway?
Bei großen S3-Buckets mit Daten im Multi-Terabyte-Bereich kann sich das Abpumpen abhängig von der Internetverbindung hinziehen oder sich ganz verbieten. Für diese Fälle bietet Amazon den Export per Sneakernet an: Kunden senden ihre Festplatte oder Storage-Appliance zu Amazon, das diese füllt und per Post zurückschickt [3]. (uba)
Infos
-
Michael Schilli, “Neue Heimat”, Amazon Web Services einrichten: Linux-Magazin 02/17, S. 88, https://www.linux-magazin.de/Ausgaben/2017/02/Snapshot
-
AWS SDK Python (Boto3) Dokumentation: http://boto3.readthedocs.io/en/latest/
-
Create Your First Amazon S3 Export Job:http://docs.aws.amazon.com/AWSImportExport/latest/DG/GSCreateSampleS3ExportRequest.html





