
© aberration, 123RF
Auf Brautschau nach einer möglichst ganzheitlichen Alternative zu Amazons As-a-Service-Universum kommt niemand umhin, die Attraktivität von Open Stack zu bemerken. Oder ist das zu hoch gestapelt?
AWS soll es nicht sein, seine Funktionen möchte man aber doch nutzen und sie auch den eigenen Cloudanwendern zur Verfügung stellen? Dann bietet sich ein anderer und zugegebenermaßen deutlich beschwerlicherer Weg an: Mit Open Stack lassen sich Cloud-Computing-Umgebungen bauen, die zumindest auf dem Papier ähnliche Funktionen wie AWS anbieten. Aber funktioniert das wirklich? Wo nimmt der Admin in solchen Setups Abstriche in Kauf? Wie hoch ist der Aufwand? Solchen Fragen geht das Linux-Magazin in diesem Artikel nach.
Installationsaufwand
Wer als Kunde AWS-Dienste in Anspruch nehmen möchte, ist schnell am Ziel: Nach dem Anlegen eines AWS-Benutzerkontos geht es im Grunde direkt los. Bei einer eigenen Open-Stack-Cloud ist das Prozedere naturgemäß umfangreicher. Für einfache Endanwender lohnt sich der Aufwand kaum, sehr wohl aber für Anbieter von IT-Produkten und ISPs: Eine laufende Open-Stack-Cloud lässt sich mit ihren verschiedenen Diensten prima als Amazon-Ersatz vermarkten.
In den vergangenen Jahren hat sich aber auch einiges getan, sodass Open Stack heute nicht mehr ganz so viele Schmerzen verursacht wie in der Vergangenheit. Trotzdem: Wer auf der grünen Wiese mit der Planung eines Open-Stack-Setups beginnt, hat viel Arbeit vor sich und muss Mühe sowie Zeit investieren. Die Distributionen von Red Hat, Suse, Canonical oder Mirantis helfen zweifellos dabei, alles im erträglichen Rahmen zu halten. Sie täuschen aber auch nicht darüber hinweg, dass Open Stack hochkomplex ist und vermutlich bleiben wird.
Die beliebteste Dienstleistung auf AWS ist die Virtualisierung namens EC2. Sie ist im Grunde bis heute der Kern des AWS-Geschäfts geblieben, und das ungeachtet der verschiedenen “as a Service”-Angebote, die Amazon sukzessive verfügbar macht. Wenn Open Stack also überhaupt als AWS-Ersatz antreten möchte, muss es diese Dienstleistung ebenfalls anbieten.
Dreh- und Angelpunkt: Virtualisierung
Das ist bei Open Stack ganz eindeutig der Fall: Im Grunde ist Virtualisierung sogar der Open-Stack-Ursprung. Daran erinnert schon die Open-Stack-Geschichte: Als 2010 die Nasa eine Lösung suchte, um ihren Mitarbeitern Computing-Dienstleistungen zentral verfügbar zu machen, entstand eine Kooperation mit dem Hoster Rackspace. Das war die Keimzelle, aus der sich später Open Stack als Projekt entwickelte.
Grundsätzlich gilt: Der Kern von Open Stack, namentlich die Komponenten Keystone, Glance, Neutron, Cinder, Nova und Horizon, sind im Wesentlichen dazu da, um Virtualisierung zu ermöglichen. Nova ist die VM-Verwaltung selbst, sodass diesem Programm eine besondere Bedeutung zukommt: Es läuft auf allen Servern der Open-Stack-Installation, die Computing-Knoten sind, und startet dort auf zentralen Zuruf hin VMs oder löscht sie wieder. Nova unterstützt mehrere Hypervisor-Arten, sodass neben dem Linux-Klassiker KVM auch Xen und sogar der Microsoft-Hypervisor Hyper-V zum Einsatz kommen können. Letzteres lässt sich in AWS gar nicht so leicht bewerkstelligen, sodass Open Stack hier sogar Vorteile gegenüber AWS bietet.
Auch bei weiteren Faktoren schneidet Open Stack im direkten Vergleich mit EC2 in Sachen Virtualisierung gut ab. Amazon etwa bietet Regions an, um die eigene virtualisierte Umgebung auf mehrere geografische Regionen aufzuteilen und so die Effekte von Ausfällen möglichst gering zu halten. Open Stack kennt das Konzept von Regions ebenfalls, sodass Anbieter diese Funktion an ihre Kunden weitergeben können. Wie bei AWS sind Regions in Open Stack unabhängig voneinander: Geht eine Region offline, sind andere nicht automatisch mit weg.
Aus Anbietersicht ist das übrigens sehr wichtig: Regelmäßig steht das Thema Region beim Verfassen von Cloud-SLAs im Mittelpunkt. Amazon etwa garantiert Kunden lediglich, dass sie zu einem Zeitpunkt x in der Lage sind, in einer der AWS-Regionen virtuelle Maschinen zu starten. Das Region-Feature von Open Stacks Nova macht das auch auf Open Stack möglich.
Fertige Images
Ein zentraler Baustein für den Erfolg von EC2 in AWS ist die Möglichkeit, entsprechend vorbereitete Betriebssystem-Abbilder zu hinterlegen, die sich für neue VMs nutzen lassen. Diese Aufgabe übernimmt in Open Stack Glance: Der Anwender hinterlegt hier Images in verschiedenen Formaten, die prominentesten sind Qcow2, VMware oder AMI. Er kann anschließend neue VMs nach Belieben auf der Basis jener Abbilder starten.
Metadaten lassen sich mit den Images ebenfalls verknüpfen. Sie bestimmen das Verhalten der Images pro VM. Apropos bestimmen: Direkt von AWS kopiert hat Open Stack das Prinzip von Cloud-Init. Wer sich schon mal mit VMs in Clouds beschäftigt hat, ist diesem Werkzeug wahrscheinlich bereits begegnet: »cloud-init« ist im Grunde nicht viel mehr als ein kleines Skript, das beim Start des Systems losläuft und sich vom Metadaten-Server der Cloud spezifische Informationen wie den Namen der eigenen VM holt. Anschließend konfiguriert es die VM entsprechend.
Mittels »cloud-init« lassen sich etwa auch SSH-Schlüssel in eine VM integrieren, sodass für diesen Zweck kein entsprechend vorbereitetes Abbild angelegt sein muss. In Open-Stack-Clouds funktioniert »cloud-init« genauso wie in AWS, denn einen entsprechenden Metadaten-Dienst gibt es hier ebenfalls. Der Übergang von EC2 zu einer Open-Stack-Cloud funktioniert so beinahe nahtlos.
Zentrale Benutzerverwaltung
Massiv ausgebaut hat Amazon in den vergangenen Jahren die Nutzerverwaltung sowie die Granularität, mit der sich einzelnen Nutzern Zugriffsrechte geben oder entziehen lassen. Hier kann Open Stack nicht mithalten, denn die von AWS gebotene Detailtiefe gepaart mit dem dort vorhandenen Komfort hat Open Stack nicht im Programm (Abbildung 1). Ganz ohne Nutzerverwaltung kommt aber auch Open Stack nicht aus: Keystone bietet die Verwaltung von Nutzern, Projekten und Rollen, die Zugriffsrechte von Nutzern in Projekten regeln.
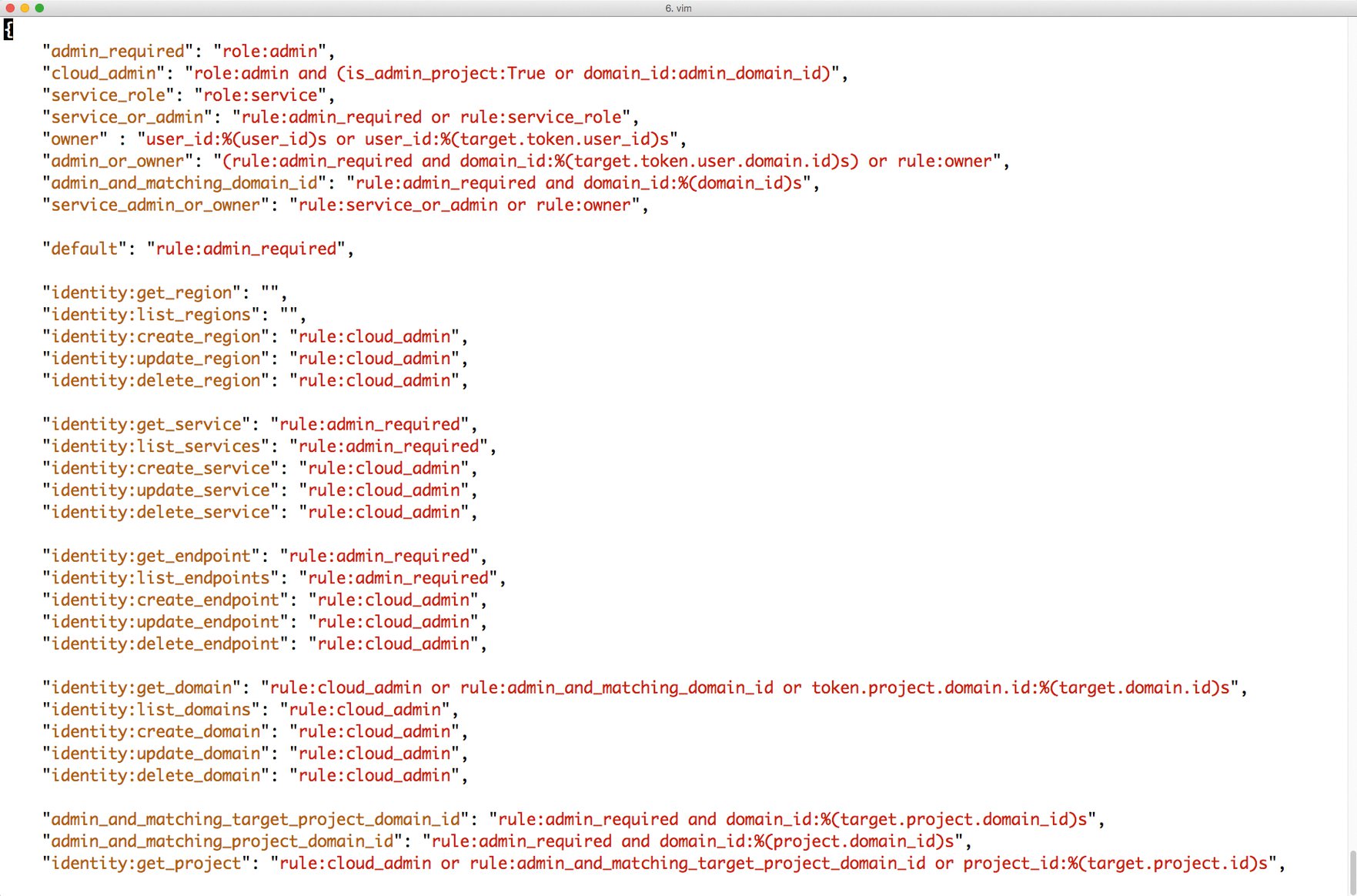
Abbildung 1: Während AWS mit einer umfangreichen Policy-Engine glänzt, die sich über ACLs grafisch steuern lässt, ist bei Open Stack Handarbeit angesagt.
Zugriff per GUI oder API
Eine Gemeinsamkeit von AWS und Open Stack ist hingegen, dass beide Zugriff sowohl per grafischer Oberfläche als auch per API-Aufruf ermöglichen (Abbildung 2). In der Entwicklung der freien Cloudumgebung haben die Open-Stack-Entwickler beinahe in jeder Release die API-Fähigkeiten der Software erweitert, sodass alle von den Komponenten unterstützten Operationen per API-Aufruf durchführbar sind. Das Dashboard – Open Stack Horizon – ist eine Alternative für weniger erfahrene Nutzer, die auf die Vorteile einer grafischen Oberfläche nicht verzichten und sich ihre VMs lieber klicken wollen (Abbildung 3).
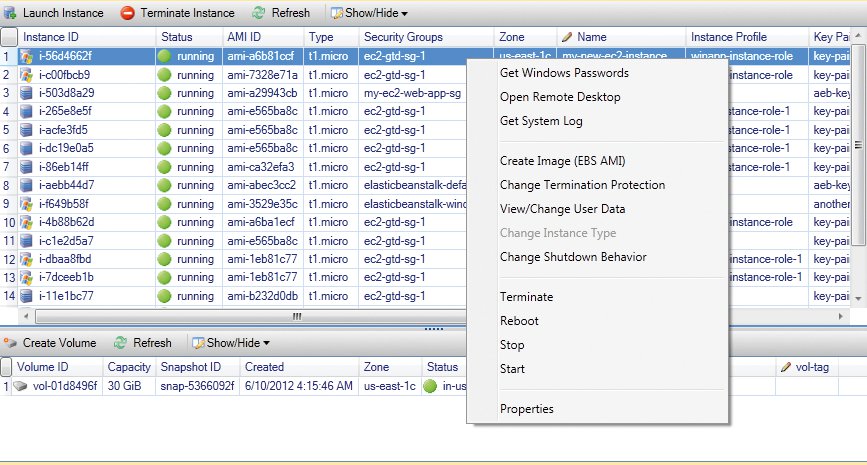
Abbildung 2: Amazon erlaubt den Zugriff auf seine AWS-Dienste entweder per API oder per GUI.
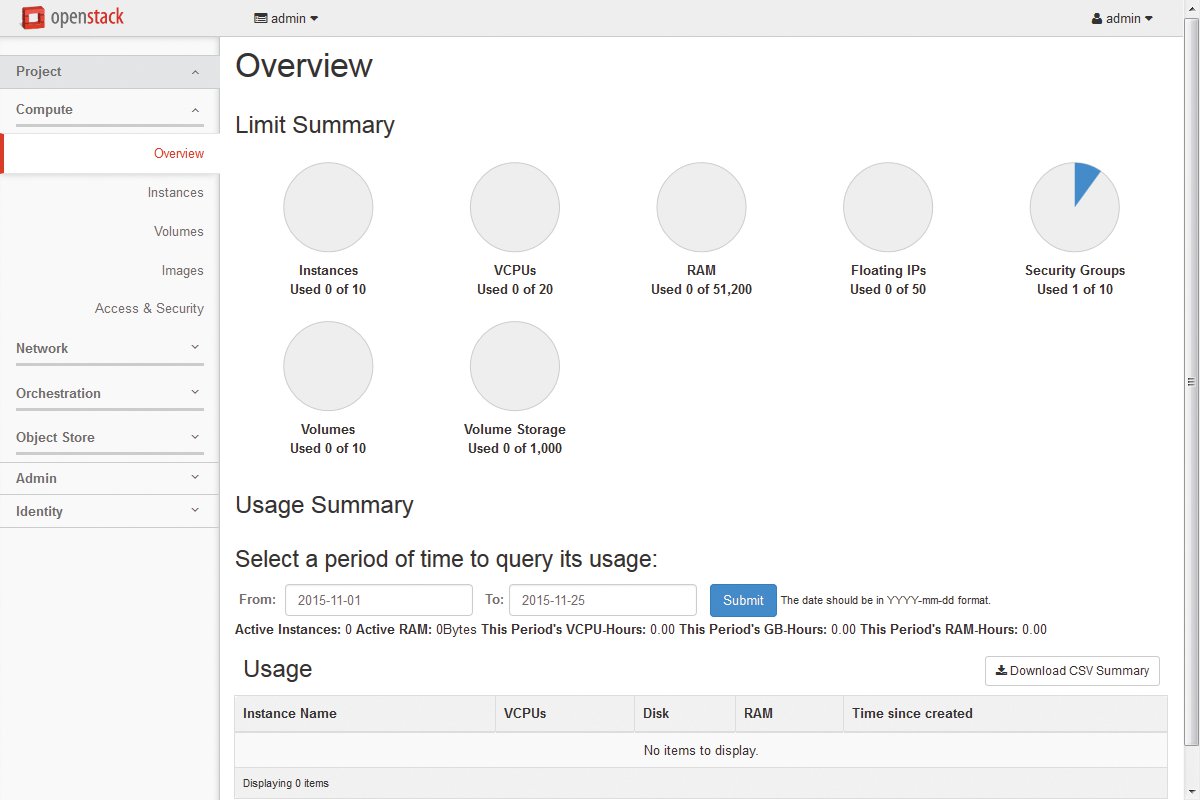
Abbildung 3: Auch bei Open Stack haben Nutzer die Wahl zwischen einem API für die verschiedenen Dienste oder einem GUI, dem Dashboard.
Apropos API: Innerhalb des Open-Stack-Projekts ist auch die Meinung salonfähig, Open Stack müsse API-Kompatibilität zu EC2 bieten. Bis vor einigen Releases gehörte das EC2-API fix zu Nova. Mittlerweile haben die Entwickler es in ein eigenes Projekt ausgelagert [1], das sich als externe Zusatzkomponente installieren lässt.
Das EC2-API von Nova übersetzt dann eingehende Befehle von Amazon-Syntax in native Nova-Syntax. Der Vorteil liegt auf der Hand: Wer die Verwaltung von VMs in EC2 gewohnt ist, kann dank des EC2-Kompatibilitäts-API die gewohnten Kommandos und Werkzeuge weiterhin nutzen. Er muss sich nicht umgewöhnen und die Nutzung der APIs von Open Stack verstehen. Das erleichtert die Migration signifikant.
Auch erwähnt sei allerdings, dass die EC2-Kompatibilität von Open Stack in den vergangenen Jahren sukzessive an Relevanz verloren hat. Und zwar vor allem deshalb, weil die nativen Open-Stack-APIs kontinuierlich besser geworden sind.
Persistenter Speicher
Amazon bietet in AWS die Möglichkeit, virtuelle Maschinen mit persistentem Speicher auszustatten, der den Neustart von Instanzen überlebt (kurz “EBS” für “Elastic Block Storage”, Abbildung 4). Mit der Zeit haben sich diese Volumes zum unverzichtbaren Werkzeug gemausert, auch in Sachen Devops: Ein Datenbank-Upgrade etwa verläuft wesentlich einfacher, wenn eine neue VM mit frischer Datenbank in der neuen Version schon bereit und in diese “nur” noch das Volume mit den Datenbankdateien einzuhängen ist.
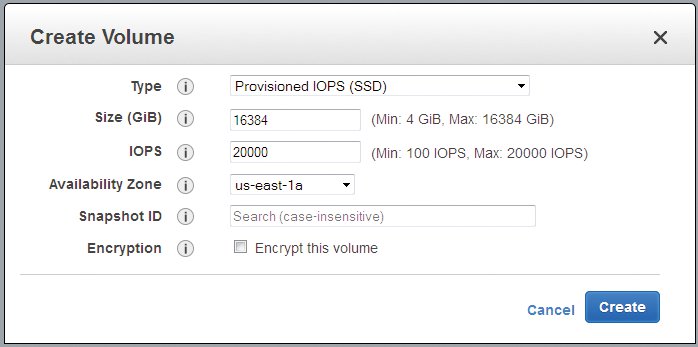
Abbildung 4: Die elastischen Volumes sind bei AWS sehr wichtig – sie ermöglichen bessere Wartung und die Haltung persistenter Daten.
Open Stack hat für diese Funktionalität wieder eine eigene Komponente: Cinder ist für persistente Volumes zuständig. Der Dienst fungiert als Vermittler: Im Hintergrund greift er auf echte Speichergeräte zu, etwa einen Ceph-Cluster oder klassische SAN-Storages, und teilt den dort angebotenen Speicher in Stücke auf. Diese verbindet Cinder anschließend direkt mit den einzelnen VMs.
Genauso lässt sich die Verbindung freilich auch wieder trennen, wenn sie nicht länger nötig ist. Von Blockgeräten lassen sich zudem problemlos Snapshots anlegen, sodass alle wichtigen Features in Sachen Volume implementiert sind. Auch hier bleibt Open Stack nicht hinter den Erwartungen zurück, die AWS schürt.
Gefragte Ablage
Ein zentraler Dienst in AWS ist neben EC2, also der Virtualisierung, S3, der Objektspeicher von Amazon. S3 folgt einem simplen Prinzip: Per Restful-API lädt der Client Dateien in den Speicher und ruft sie auf dieselbe Weise auch wieder ab. Was zunächst klingt wie Dropbox oder Google Drive kann aber noch mehr: Über die Jahre hat Amazon S3 immer wieder um Zusatzfunktionen erweitert, etwa um die Möglichkeit, temporäre Links für den Zugriff auf Dateien anzubieten.
Wichtig ist in diesem Kontext aber genauso die Feststellung, dass S3 mit dem Speichern von Daten in EC2-VMs nichts zu tun hat. Ein S3-Bucket lässt sich also nicht als Blockgerät an eine virtuelle Maschine anschließen – genau dafür gibt es ja das zuvor schon beschriebene EBS. Das tut der Popularität von S3 allerdings keinen Abbruch, und bis heute ist der Dienst einer der wichtigsten in AWS. So wichtig, dass am Markt mittlerweile mehrere S3-Nachbauten existieren.
Das allein ist schon reichlich delikat: Obwohl S3 mittlerweile beliebt und weit verbreitet ist, handelt es sich nicht um ein offenes Protokoll. Zwar gibt es von Amazon eine API-Referenz, doch die Quellen des Protokolls hat der Hersteller bisher nicht offengelegt. Alle S3-Server orientieren sich insofern an der erwähnten API-Referenz, weiteren Dokumenten und an den Clients, die zu S3 kompatibel sind. Im Grunde sind sie Reverse-Engineering-Ansätze.
Bisher hat Amazon dazu geschwiegen – es scheint aber nicht völlig undenkbar, dass der Anbieter dem Treiben eines Tages ein Ende setzen könnte und auf das eigene geistige Eigentum an S3 pocht.
Ein S3-Ersatz
Bei allen Bedenken gilt: Wer eine Open-Stack-Cloud als AWS-Ersatz anstrebt, kommt um einen S3-Dienst nicht herum. Hierzu bieten sich dem Admin gleich mehrere Möglichkeiten. Open Stack selbst hat einen Objektspeicher im Programm: Open Stack Swift. Swift ist jene Komponente, für die Rackspace bis heute verantwortlich zeichnet – der Teil, den Rackspace seinerzeit in die Kooperation mit der Nasa eingebracht hat.
Für den Swift-Dienst haben die Entwickler zwei Protokolle implementiert: Einerseits hat Swift ein eigenes Protokoll gleichen Namens, das als primär gilt. Andererseits haben die Swift-Entwickler ein S3-Interface gebaut, mit dem sich auf Swift wie auf S3 zugreifen lässt. Mittlerweile ist das S3-API in ein eigenes Projekt ausgelagert [2], das sich auf ein bestehendes Swift bauen lässt.
Wie bei Nova geht also auch bei Swift der Trend in die Richtung, die nativen Open-Stack-APIs zu stärken und externe Nachbauten erst nachrangig zu berücksichtigen. Anders als bei Nova könnte das bei Swift allerdings noch zu einem echten Problem werden, falls sich in der Swift-Community irgendwann mal niemand mehr findet, der das S3-API weiterhin pflegen möchte. Denn wer Nova in Open Stack benutzen möchte, kann das über die Open-Stack-eigenen CLI-Werkzeuge oder über das Dashboard tun. Für das Swift-Protokoll hingegen gibt es kaum einen nennenswert verbreiteten GUI-Client. Einzig Cyberduck [3] beherrscht Swift. Im Gegensatz dazu finden sich S3-Clients wie Sand am Meer, etwa auch für diverse Skript- und Programmiersprachen wie Go, Ruby oder PHP.
Swift hat noch einen signifikanten Nachteil: Es funktioniert zwar als Objektspeicher, beherrscht aber – wie das Vorbild S3 – keine Funktionen, um in Open Stack auch als Backend für Cinder zu funktionieren, also Volumes für VMs anzubieten. Wer Swift für S3 nutzt, braucht zwangsläufig noch eine Lösung für blockbasierten Speicher der VMs.
Ceph zur Hilfe
Aus eben diesem Grund hat es sich bei vielen großen Open-Stack-Setups heute eingebürgert, Swift von Anfang an durch eine externe Komponente – nämlich Ceph – zu ersetzen. Ceph war im Linux-Magazin bereits bei vielen Gelegenheiten Thema [4]; im Wesentlichen ist Ceph ein Objektspeicher, der sich über verschiedene Frontends und Protokolle ansprechen lässt. Für blockbasierten Speicher steht die RBD-Schnittstelle zur Verfügung, die für sowohl Nova wie auch Cinder eine native Anbindung hat. Hinzu gesellt sich das Ceph Object Gateway [5], das nach außen das Open-Stack-Swift- oder das Amazon-S3-Protokoll exponiert und die Daten im Hintergrund im Ceph-Objektspeicher ablegt. So schlägt der Admin zwei Fliegen mit einer Klatsche: Dieselbe Storage-Technologie versorgt dann sowohl VMs als auch den S3-Dienst mit Speicher.
Der Vollständigkeit halber sei angemerkt, dass auch die S3-Implementation des Ceph Object Gateway in Sachen Qualität und Funktionsumfang nicht an das Original herankommt. In ihrer Dokumentation gehen die Entwickler ausgiebig [6] auf die unterstützten Funktionen ein und erwähnen auch Einschränkungen. Admins dürfen aber grundsätzlich davon ausgehen, dass S3-Clients wie Cyberduck mit einem Ceph hinter dem S3-Gateway zurechtkommen (Abbildung 5).
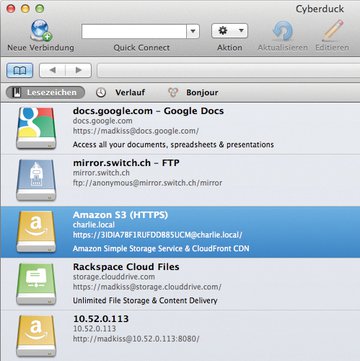
Abbildung 5: Cyberduck ermöglicht den Zugriff auf S3- oder Swift-Laufwerke ab Werk und spielt mit Swift und dem Ceph Object Gateway gut zusammen.
Orchestrierung hüben wie drüben
Schamlos abgekupfert hat Open Stack nachweislich in Sachen Orchestrierung. Amazon war hier früh auf der Höhe der Zeit: Man hatte erkannt, dass es nicht genügt, Kunden nur Virtualisierung anzubieten. Zwar erspart Virtualisierung der Kundschaft bereits viel Arbeit und Warterei. Doch wer oft virtuelle Umgebungen in EC2 baut, arbeitet die gleichen Schritte immer und immer wieder ab: Das Anlegen eines persönlichen Netzwerks, das Verbinden des Netzes mit der Außenwelt, das Starten und Aufsetzen der benötigten VMs und das Konfigurieren etwaiger Zusatzdienste sind ständig wiederkehrende Aufgaben.
Konsequent machte sich Amazon daran, diese Arbeiten für den Kunden wegzuautomatisieren. Das Ergebnis: Amazon Cloudformation. Der Kunde beschreibt hier abstrakt – etwa in Yaml-Syntax – sein Setup in einer Text-Datei und reicht dieses Template an die Cloud weiter. Die erstellt das Setup aus dem Template.
Den Open-Stack-Entwicklern war schnell klar, dass sie einen ähnlichen Dienst brauchen. Das Ergebnis der Bemühungen heißt in Open Stack heute Heat: Der Dienst bietet wie Cloudformation in AWS umfangreiche Orchestrierung. Prinzipiell funktioniert er auch so ähnlich wie sein Vorbild: Admins schreiben Templates und laden diese bei Heat ab, das sich um die Umsetzung kümmert.
Anfangs gab es eine direkte Kompatibilitätsschnittstelle zu Cloudformation, sodass sich die AWS-Templates auch in Open-Stack-Clouds nutzen ließen. Das geht heute zwar noch immer, doch deutlich ausgereifter ist in Heat mittlerweile das HOT-Format: Die Abkürzung steht für Heat Orchestration Template, das native Template-Format von Heat. Diverse Beispiele im Netz zeigen, wie ein HOT-Template in Open Stack zu nutzen ist [7]. Alle wichtigen Funktionen, die in Cloudformation vorhanden sind, beherrscht Heat auch für Open Stack.
Klaffende Lücken: XaaS-Dienste
Bis hierhin hat sich Open Stack passabel geschlagen. Allerdings gibt es in AWS auch Funktionen, die mit Open Stack aktuell nicht sinnvoll nachzubilden sind. Davon im Wesentlichen betroffen sind die diversen XaaS-Dienste, also “as a Service” etwa am Beispiel von Database as a Service. Hier schneidet Open Stack noch am besten ab: In Form von Trove liegt für DBaaS eine eigene Komponente vor, die mittlerweile einigermaßen ausgereift ist. Bis Trove diesen Punkt aber erreichen konnte, vergingen mehrere Jahre. Das ist nicht verwunderlich, denn bei Open Stack arbeiten kleine Teams an den umfassenden Komponenten, wo Amazon riesige Entwicklermannschaften auf einzelne Features loslässt.
Entsprechend fällt auf, dass es für viele AWS-Features in Open Stack gar keine Entsprechung gibt – oder zumindest keine nutzbare. Wer etwa einen Queue-Dienst as a Service betreiben möchte, erhält den in AWS innerhalb weniger Mausklicks. Für Open Stack müsste der Cloudanbieter zunächst Zaqar [8] installieren, das mit dem Amazon-Featureset einerseits nicht mithalten kann und andererseits für einen sehr spezifischen Usecase verfasst wurde.
Ähnlich verhält es sich mit NFS as a Service: Zwar existiert Monasca für Open Stack, doch ist dieses konzeptionell so eingeschränkt, dass es sich nur in einer spezifischen Art und Weise des Open-Stack-Deployments überhaupt einsetzen lässt. Amazon hingegen bietet in Form von EFS eine perfekt funktionierende Lösung, die ad hoc nutzbar ist.
Auch beim automatischen Skalieren von Clouddiensten war Amazon deutlich früher als Open Stack am Start. So ist es etwa kein Problem, in Amazon auf Basis verschiedener Parameter wie der Last oder der genutzten RAM-Menge dynamisch Instanzen nachzustarten oder zu löschen. In Open Stack geht das mittlerweile zwar auch, doch hier muss erst der Betreiber wieder ran: Er muss die Komponenten Ceilometer und Senlin bereitstellen und sie miteinander verbinden. Erst danach können Anwender Regeln festlegen, auf deren Basis Open Stack automatisch virtuelle Umgebungen in die Breite skaliert.
Fazit
Open Stack stellt unter Beweis, dass es sich vor der fast schon übermächtigen Amazon-Konkurrenz nicht zu verstecken braucht. Was die Open-Stack-Entwickler in Sachen Features liefern, ist durchweg grundsolide: Beim Thema Virtualisierung bewegen sich beide Ansätze auf Augenhöhe. Wer also seinen Kunden eine EC2-Alternative bieten möchte und den recht komplexen Aufbau einer Open-Stack-Umgebung dabei nicht scheut, der erhält am Ende eine gut funktionierende Lösung, mit der sich auch durchaus gutes Geld verdienen lässt.
Auch beim Beiwerk kommt Open Stack nicht schnell ins Trudeln: Swift oder Ceph als Ersatz für Amazons S3 bieten zwar nicht ganz dessen Funktionsumfang, dürften im Alltag aber für die meisten Anwendungsfälle auch völlig ausreichend sein. Garniert mit der Tatsache, dass in Open Stack wie in AWS umfassende Orchestrierung zur Verfügung steht, macht das Open Stack zu einer sehr attraktiven AWS-Alternative.
Weniger rosig sieht es naturgemäß bei den Zusatzdiensten aus, die Amazon als Teil von AWS anbietet. Das hat mehrere Gründe: Einerseits ist die AWS-Entwicklerabteilung deutlich größer als die kleineren Gruppen, die sich um die Entwicklung einzelner Open-Stack-Dienste kümmern. Andererseits entwickelt Amazon bei AWS bekanntlich nur für genau einen Usecase und für genau die Entwicklungsumgebung, die man für richtig hält. Open Stack muss hingegen eine große Menge möglicher Szenarien und potenzieller Funktionen abdecken, um für viele Nutzer attraktiv zu sein.
Daher wirkt manche AWS-Funktion fertig, während der vergleichbare Open-Stack-Dienst noch eine reine Baustelle ist. Weil sich die Open-Stack-Entwickler allerdings auf ihren Lorbeeren nicht ausruhen, dürfen Admins auch bei diesen Komponenten mit steten Verbesserungen rechnen.
Infos
- Nova-EC2-API: https://github.com/openstack/ec2-api
- Swift-S3-API: https://github.com/openstack/swift3
- Cyberduck: https://cyberduck.io/?l=de
- Martin Loschwitz, “Sichtbar renoviert”: Linux-Magazin 05/16, S. 62
- Ceph Object Gateway: http://docs.ceph.com/docs/master/radosgw/
- S3-Kompatibilität: http://docs.ceph.com/docs/master/radosgw/s3/
- HOT-Templates: https://docs.openstack.org/developer/heat/template_guide/hot_guide.html
- Zaqar: https://wiki.openstack.org/wiki/Zaqar





