
Verantwortung abgeben fällt C++-Entwicklern nicht immer leicht. Dabei trifft der Compiler fast immer die besseren Entscheidungen, wie der vorliegende Artikel zeigt.
C++-Entwickler sind ein stolzes Völkchen, das stets die volle Kontrolle über die selbst geschriebenen Programme anstrebt. Und das trifft selbst auf Situationen zu, in denen dem Compiler bereits alle notwendigen Informationen zur Verfügung stehen. Das in der Folge produzierte Ergebnis ist dann häufig nicht das gewünschte.
Schlauer Compiler
Abbildung 1 zeigt noch einmal das große Bild mit den zehn Empfehlungen für gut geschriebenen C++-Code. Der aktuelle Artikel widmet sich der Handlungsmaxime: Sei nicht schlauer als der Compiler. Denn konkret setzt sich der Artikel mit zwei Features auseinander, die in den Verantwortungsbereich des Compilers fallen: mit der automatischen Typableitung über »auto« sowie der automatischen Speicherverwaltung mit Hilfe von Smart Pointern.

Abbildung 1: “Sei nicht schlauer als der Compiler”, so lautet diesmal das Motto.
Autofokus
Bei Schulungen oder Vorträgen führt der Tipp zur automatischen Typableitung immer wieder zu kontroversen Diskussionen vor allem mit Hardware-nahen Programmierern. Ihr K.-o.-Argument: Wenn ich einen expliziten Typ benötige, hilft mir »auto« nicht weiter. Das stimmt zwar, allerdings lässt sich dieses Problem mit der vereinheitlichten Initialisierung von Datentypen elegant und typsicher lösen. Dazu unten mehr. Zunächst gilt es, die automatische Typableitung mit »auto« vorzustellen.
Wo sind meine Typen?
Die Anwendung des Specifier »auto« ist denkbar einfach. Dank ihm lässt sich der Typ einer Variablen auf Basis ihres Initialisierers ableiten. Dabei liegt der Compiler nie falsch, die Regeln im Detail schildert der Artikel unter [1]. Welche Power in »auto« steckt, zeigt das zweimal refaktorierte Programm in Listing 1.
Listing 1
Refaktorierung mit auto
01 #include <iostream>
02 #include <typeinfo>
03 #include <type_traits>
04
05 int main(){
06
07 std::cout << std::boolalpha << std::endl;
08
09 auto a= 5;
10 auto b= 10;
11 auto sum= a * b * 3;
12 auto res= sum + 10;
13 std::cout << "res: " << res << std::endl;
14 std::cout << "typeid(res).name(): " << typeid(res).name() << std::endl;
15 std::cout << "std::is_same<int, decltype(res)>::value: "
16 << std::is_same<int, decltype(res)>::value << std::endl;
17
18 auto a2= 5;
19 auto b2= 10.5;
20 auto sum2= a2 * b2 * 3;
21 auto res2= sum2 * 10;
22 std::cout << "res2: " << res2 << std::endl;
23 std::cout << "typeid(res2).name(): " << typeid(res2).name() << std::endl;
24 std::cout << "std::is_same<int, decltype(res2)>::value: "
25 << std::is_same<int, decltype(res2)>::value << std::endl;
26
27 auto a3= 5;
28 auto b3= 10;
29 auto sum3= a3 * b3 * 3.1f;
30 auto res3= sum3 * 10;
31 std::cout << "res3: " << res3 << std::endl;
32 std::cout << "typeid(res3).name(): " << typeid(res3).name() << std::endl;
33 std::cout << "std::is_same<int, decltype(res3)>::value: "
34 << std::is_same<int, decltype(res3)>::value << std::endl;
35
36 std::cout << std::endl;
37
38 }
Der Specifier »auto« macht die Refaktorierung zum Kinderspiel. In den Zeilen 9 bis 12 findet die komplette Arithmetik statt, wobei der Code keine Variable explizit typisiert. Während das Ergebnis der Arithmetik weniger interessiert, fällt vor allem auf, dass der Compiler stets den richtigen Datentyp für seine Operationen auswählt. Damit ist es per se nicht möglich, den falschen Datentyp für das Ergebnis »res« zu verwenden.
In Zeile 14 kommt die Runtime Type Information (RTTI, [2]) zum Einsatz. Sie ermöglicht es, den Typ einer Variablen zur Laufzeit zu erkennen. Diese Information lässt sich mit der Type-Traits-Bibliothek jedoch bereits beim Übersetzen ermitteln. Der Ausdruck »std::is_same<int, decltype(res)>::value« findet heraus, ob der deklarierte Typ von »res« (»decltype(res)«) vom Typ »int« ist. Die Details zur Type-Traits-Bibliothek liefert der Artikel unter [3].
Anschließend refaktoriert der Code die Arithmetik ein wenig. Zum einen ist die Variable »b2« in Zeile 19 vom Typ »double«. Zum anderen initialisiert ein »float«-Literal den Ausdruck in Zeile 29. Kein Problem für den Compiler. Er ermittelt immer den richtigen Typ. Das zeigt Abbildung 2 schwarz auf gelb.
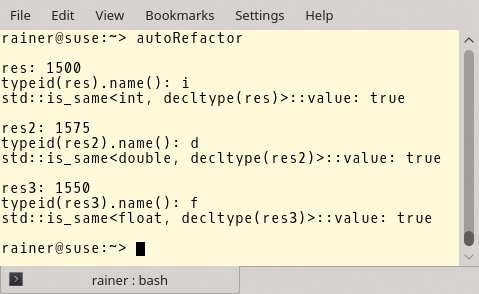
Abbildung 2: Beim Refaktorieren mit »auto« ermittelt der Compiler stets den richtigen Typ.
Manch erfahrener Programmierer wird jetzt mit der Gefahr argumentieren, dass C++ beim Refaktorieren die Typen nicht richtig anpasse. Daher passiere es allzu oft, dass C++ einen zu großen Wert zum Initialisieren einer Variablen verwende. Das führe in der Regel dazu, dass das Programm ein undefiniertes Verhalten zeige. Damit seien Aussagen über das Ergebnis eines Programms nicht mehr möglich. Trotz dieser lauernden Gefahr bestehe aber, so die Kritiker, oft die Notwendigkeit, einen expliziten Typ zu verwenden, da die Hardware ihn brauche.
Die Befürchtung ist aber unbegründet. Dank einer vereinheitlichten Initialisierung mit geschweiften Klammern [4] lässt sich der Komfort der automatischen Typableitung schön mit der Anforderung an explizite Typen verheiraten.
Es darf nur einen geben
Ohne viele Worte gehen in Listing 2»auto« und die Initialisierung in geschweiften Klammern eine Ehe ein. Der Versuch, das Programm zu übersetzen, scheitert kläglich (Abbildung 3). Das Ergebnis »res2« in Zeile 6 hat den Typ »int«. Dank der Initialisierung mit geschweiften Klammern ist keine so genannte Narrowing Conversion möglich.
Listing 2
auto und die {}-Initialisierung
01 int main(){
02
03 auto a2= 5;
04 auto b2= 10.5;
05 auto sum2= a2 * b2 * 3;
06 int res2= {sum2 * 10};
07
08 }
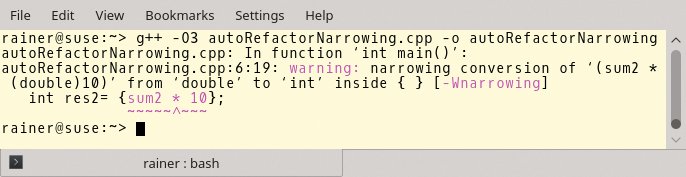
Abbildung 3: Der Specifier »auto« heiratet die Initialisierung mit den geschweiften Klammern. Das Programm lässt sich jedoch nicht übersetzen.
Das heißt, falls C++ den Initialisierer unter Verlust seiner Datengenauigkeit konvertieren muss, moniert der Compiler dies postwendend. Dabei steht »res2« im Beispiel für eine Hardwareschnittstelle, die der Entwickler nur mit einem »int«-Wert ansprechen kann.
Automatische Speicherverwaltung
Weiter geht es mit den Smart Pointern, wobei der Artikel nicht die besonderen Stärken und das Einsatzgebiet der beiden Smart Pointer »std::unique_ptr« und »std::shared_ptr« beleuchtet ([5], [6]), sondern ihren Ressourcenhunger in Sachen Zeit und Speicher. Listing 3 erzeugt bereits ausreichend Daten, um interessante Schlussfolgerungen zu diesem Thema zu ziehen.
Listing 3
Smart Pointer im Vergleich
01 #include <chrono>
02 #include <iostream>
03 #include <memory>
04
05 static const long long numInt= 100000000;
06
07 int main(){
08
09 auto start = std::chrono::system_clock::now();
10
11 for (long long i = 0 ; i < numInt; ++i){
12 int* tmp(new int(i));
13 delete tmp;
14 // std::unique_ptr<int> tmp(new int(i));
15 // std::unique_ptr<int> tmp = std::make_unique<int>(i);
16 // std::shared_ptr<int> tmp(new int(i));
17 // std::shared_ptr<int> tmp = std::make_shared<int>(i);
18 }
19
20 std::chrono::duration<double> dur = std::chrono::system_clock::now() - start;
21 std::cout << dur.count() << std::endl;
22
23 }
Das Programm ist denkbar einfach strukturiert. Die For-Schleife ab Zeile 11 führt 100 Millionen Speicherallokation und -deallokation aus. Das geschieht in verschiedenen, zunächst auskommentierten Varianten. Zuerst kommen Raw-Pointer zum Einsatz. In den Zeilen 14 und 15 ein »std::unique_ptr« und in den Zeilen 16 und 17 ein »std::shared_ptr«. Dabei geben die zwei Smart Pointer »std::unique_ptr« und »std::shared_ptr« ihren Speicher wieder automatisch frei. Genau das ist ihr Mehrwert, allerdings fragt sich, was dieser kostet. Als Compiler kam ein recht aktueller GCC 6.3 zum Einsatz, die Zahlen in Tabelle 1 zeigen den Mittelwert von zehn Programmläufen.
|
Zeigertyp |
Mit maximaler Optimierung |
Ohne Optimierung |
|---|---|---|
|
»new« / »delete« |
3,22 s |
3,25 s |
|
»std::unique_ptr« |
3,18 s |
8,36 s |
|
»std::make_unique()« |
3,17 s |
8,94 s |
|
»std::shared_ptr« |
6,53 s |
12,54 s |
|
»std::make_shared()« |
3,06 s |
30,59 s |
Da es um Performance geht, interessiert in der Tabelle vor allem die Spalte mit der maximalen Optimierung. Die Zahlen sprechen hier eine deutliche Sprache: Bis auf den direkten Aufruf von »std::shared_ptr« verlaufen alle Allokationen und Deallokationen vereinfacht gesprochen gleich schnell.
Allerdings wirft der Test mit maximaler Optimierung noch zwei Fragen auf. Da ein »std::shared_ptr«-Aufruf zwei Speicherallokationen für seine Ressource und seinen Referenzzähler benötigt, ist er der langsamste Smart Pointer im Performancetest. Dies gilt nicht, wenn der Entwickler den »std::shared_ptr« mit der Hilfsfunktion »std::make_shared()« erzeugt. Dann erfolgen die zwei Speicherallokationen in einem Schritt.
Natürlich benötigt der »std::shared_ptr« mehr Speicher als ein Raw-Pointer. Das gilt aber nicht für einen »std::unique_ptr«. Der ist per Design so schnell und Ressourcen-schonend wie ein Raw-Pointer. Die herausragende Eigenschaft des »std::unique_ptr« ist, dass er einen deutlichen Mehrwert gegenüber einem Raw-Pointer besitzt, ohne dafür in Zeit oder Speicher zahlen zu müssen. Das begründet zugleich eine weitere einfache Regel für C++-Entwickler: Fasse keine Speicher direkt an.
Eine Frage, die die Tabelle aufwirft, ist aber noch offen: Warum hat der Autor die Performance auch ohne Optimierung gemessen? Ganz einfach: Weil es interessant zu sehen ist, wie gut Optimierer den Code optimieren, wenn sie dürfen. Diese Beobachtung trifft natürlich auch auf einen modernen Clang-Compiler oder den von Microsoft Visual Studio zu.
Wie geht’s weiter?
Wie bereits eingangs festgestellt, schrauben C++-Programmierer mit Vorliebe an der Performance ihrer Programme. Dieser opfern sie allerdings mitunter auch die Lesbarkeit ihres Codes. Ein Opfer, das oft nicht notwendig ist. Die einfache Regel, die der nächste Artikel in sein Zentrum stellt, lautet daher: Behalte das große Bild im Auge.
Infos
-
Rainer Grimm, “Neue Ausdruckskraft”: Linux-Magazin 02/14, S. 104, https://www.linux-magazin.de/Ausgaben/2014/02/C-11
-
Runtime Type Information (RTTI): http://en.cppreference.com/w/cpp/types
-
Rainer Grimm, “Statisch geprüft”: Linux-Magazin 02/15, S. 106, https://www.linux-magazin.de/Ausgaben/2015/02/C-11
-
Rainer Grimm, “Delinquente Typen”: Linux-Magazin 02/17, S. 82, https://www.linux-magazin.de/Ausgaben/2017/02/C
-
Rainer Grimm, “Räumkommando”: Linux-Magazin 02/13, S. 90, https://www.linux-magazin.de/Ausgaben/2013/02/C-11
-
Rainer Grimm, “Klug aufgeräumt”: Linux-Magazin 04/13, S. 104, https://www.linux-magazin.de/Ausgaben/2013/04/C-11
Der Autor

Rainer Grimm ist Trainer für C++ und Python. Seine Bücher “C++11 für Programmierer”, “C++”, “C++11-Standardbibliothek” sowie “The C++ Standard Library” sind bei O’Reilly und Leanpub erschienen.





