
© Andrew Salamchev, 123RF
Jede produktive Open-Stack-Installation, die Dienste und VMs mehrerer Kunden beherbergt, bietet für externe und interne Angreifer eine Menge Angriffspunkte. Das Härten des Gesamtsystems kann aus einem morschen Gemäuer fast ein Bollwerk machen – mehr als ein bisschen Mörtel bedarf es dafür aber schon.
Die Virtualisierung von Computing-Dienstleistungen ist eine tolle Idee. Sie ermöglicht es, potente Hardware effektiv zu nutzen, indem sie den Betrieb vieler virtueller Systeme auf einem physischen System erlaubt. Doch gibt es auch Zweifel an diesem Konzept: Eine der größten Sorgen der Virtualisierungsgegner besteht darin, dass es einem Angreifer gelingen könnte, aus seiner VM auszubrechen und so Zugriff auf Ressourcen des physischen Hosts zu bekommen. Die Trennung der Ressourcen unterschiedlicher VMs auf demselben Server wird zum Dreh- und Angelpunkt, der entscheidet, ob der Anwender dem Prinzip Virtualisierung vertrauen kann.
Wie wichtig es ist, dass die Grenzen von VM und Host nicht verschwimmen, zeigt ein simples Gedankenexperiment. Gegeben sei ein Server, der mehrere virtuelle Maschinen betreibt, die alle demselben Kunden gehören. Schon in diesem Szenario ist es kritisch, wenn der Ausbruch aus einer VM und damit der direkte Zugriff auf den Server gelingt: Im schlimmsten Fall hat der Angreifer nun nämlich vollen Zugriff auf die VMs des Hosts und kann diese – je nach Bedarf – ausräumen, um an sensible Daten zu kommen, oder sie verminen, um noch mehr Informationen unbemerkt abzufischen.
Um diesen Zustand zu erreichen, muss ein Angreifer mehrere Hürden überspringen: Zunächst muss es ihm gelingen, auf die virtuelle Maschine selbst irgendwie Zugriff zu erhalten. Wenn alle VMs zum selben Kunden gehören und dieselben Admins sie regelmäßig warten, lässt sich dieses Risiko zwar minimieren, doch ausschließen lässt es sich nicht. Im zweiten Schritt muss der Angreifer die Hürde zwischen VM und Host überspringen. Verschiedene Technologien wie etwa SE Linux helfen dabei, einige der Risiken zu minimieren.
Alles noch viel schlimmer in der Cloud
Das Gefahrenpotenzial ist deutlich größer, stellt man sich den Einbruch wie zuvor beschrieben nicht in einer Virtualisierungsumgebung vor, in der einzelne Hosts Kunden fest zugeordnet sind, sondern in einer Cloud, im schlimmsten Fall in einer öffentlichen Cloud.
Hier ist es eine seitens des Anbieters explizit formulierte Bedingung, dass jede virtuelle Maschine jedes Kunden zusammen mit beliebigen anderen VMs auf beliebigen Hosts laufen muss. Denn aus Anbietersicht würde alles andere nicht skalieren. Erst indem sich die verfügbaren Hypervisoren in eine Menge beliebig verteilbarer Computing-Kapazität verwandeln, entfaltet das Prinzip der Public Cloud seine Wirkung.
Dabei sinkt aber die Kontrolle, die einzelne Kunden über ihren Teil des Setups haben, fast auf null: Sie können sich nicht aussuchen, auf welchem Host ihre VM läuft und wer auf demselben Host ebenfalls Maschinen hat. Sie haben keine Kontrolle über die Software, die in anderen VMs auf demselben Hypervisor läuft, oder darüber, wie gut diese gepflegt und gewartet ist. Stattdessen müssen sie dem Anbieter der Plattform vertrauen und hoffen, dass dieser seine Hausaufgaben in Sachen Security ordentlich macht.
Anhand einer Open-Stack-Umgebung erklärt der folgende Artikel, welche potenziellen Einfallstore es gibt und wie Admins die aus ihnen resultierenden Gefahren bestmöglich minimieren.
Einfallstore erkennen
Der offensichtlichste Einfallspunkt für externe Angreifer ist auch bei den Servern in der Cloud die einzelne VM. Wer Zugriff auf eine beliebige VM in der Cloud erhält, verschafft sich bei lückenhafter Trennung zwischen Host und VMs über diesen Umweg Zugriff auf den Server. Das Angriffsszenario unterscheidet sich von dem bei klassischer Virtualisierung ohne Cloud im Grunde nicht.
Hinzu kommt eine Reihe weiterer Faktoren, die bei Clouds ein mögliches Einfallstor bieten: Praktisch jede Cloud setzt etwa auf Netzwerkvirtualisierung. Meist kommt dabei Open Vswitch zum Einsatz, das über ein Konstrukt aus VxLAN- oder GRE-Tunneln, Netzwerkbrücken und virtuellen Ports auf dem Hypervisor virtuelle Netzwerke realisiert. Wer irgendwie Zugriff auf die Hypervisor-Rechner bekommt, kann zumindest den von virtuellen Maschinen produzierten Netzwerktraffic abfangen und so auch an sensible Daten gelangen.
So komplex muss der Angriffsplan aber meist gar nicht sein: Nicht selten hat ein Angreifer es bei Cloud-Computing-Umgebungen mit einem Softwaremuseum zu tun, das selbst elementare Grundsätze der IT-Sicherheit ignoriert. Dazu gehört die Aufteilung von Diensten, sodass jene Dienste, die von außen nicht erreichbar sein müssen, das auch nicht sind, genauso wie das regelmäßige Einspielen von Updates.
Gerade bei Open Stack kommt erschwerend hinzu, dass sich kritische Daten problemlos herausfinden lassen, sobald einem potenziellen Angreifer die Login-Credentials für einen Account in einem Open-Stack-Projekt in die Hände fallen: In der Regel ist ein solcher Satz Credentials ausreichend, um bestehende VMs und Volumes nach Belieben zu verändern oder auszulesen.
Was ist aus Anbieter-Sicht zu tun, um sich gegen eine Fülle verschiedener Angriffsszenarien zu wehren? Ein großer Teil der Arbeit besteht zunächst darin, ein wartbares Setup zu schaffen, in dem sich sicherheitsrelevante Selbstverständlichkeiten tatsächlich umsetzen lassen.
Welche Dienste müssen von außen erreichbar sein?
Das Härten einer Open-Stack-Umgebung beginnt schon bei der Planung des Setups und orientiert sich an einer simplen Frage: Welche Dienste müssen von außen erreichbar sein? Weil Open Stack wie die meisten anderen Clouds durchgehend auf APIs setzt, lässt sich diese Frage schnell beantworten. Die API-Komponenten müssen von der Außenwelt aus zugänglich sein – sonst nichts. Auch auf MySQL oder Rabbit MQ, die für den Betrieb von Open Stack nötig sind, brauchen Anwender von außen nicht zuzugreifen.
Und selbst die APIs exponiert eine Cloud in der Regel nicht direkt, weil damit Hochverfügbarkeit unmöglich wäre. Dafür kommen Load Balancer hinzu (Abbildung 1), also separate Rechner, die eingehende Verbindungen nur auf spezifischen Ports erlauben und die erste Linie im Kampf gegen Angriffe bilden.
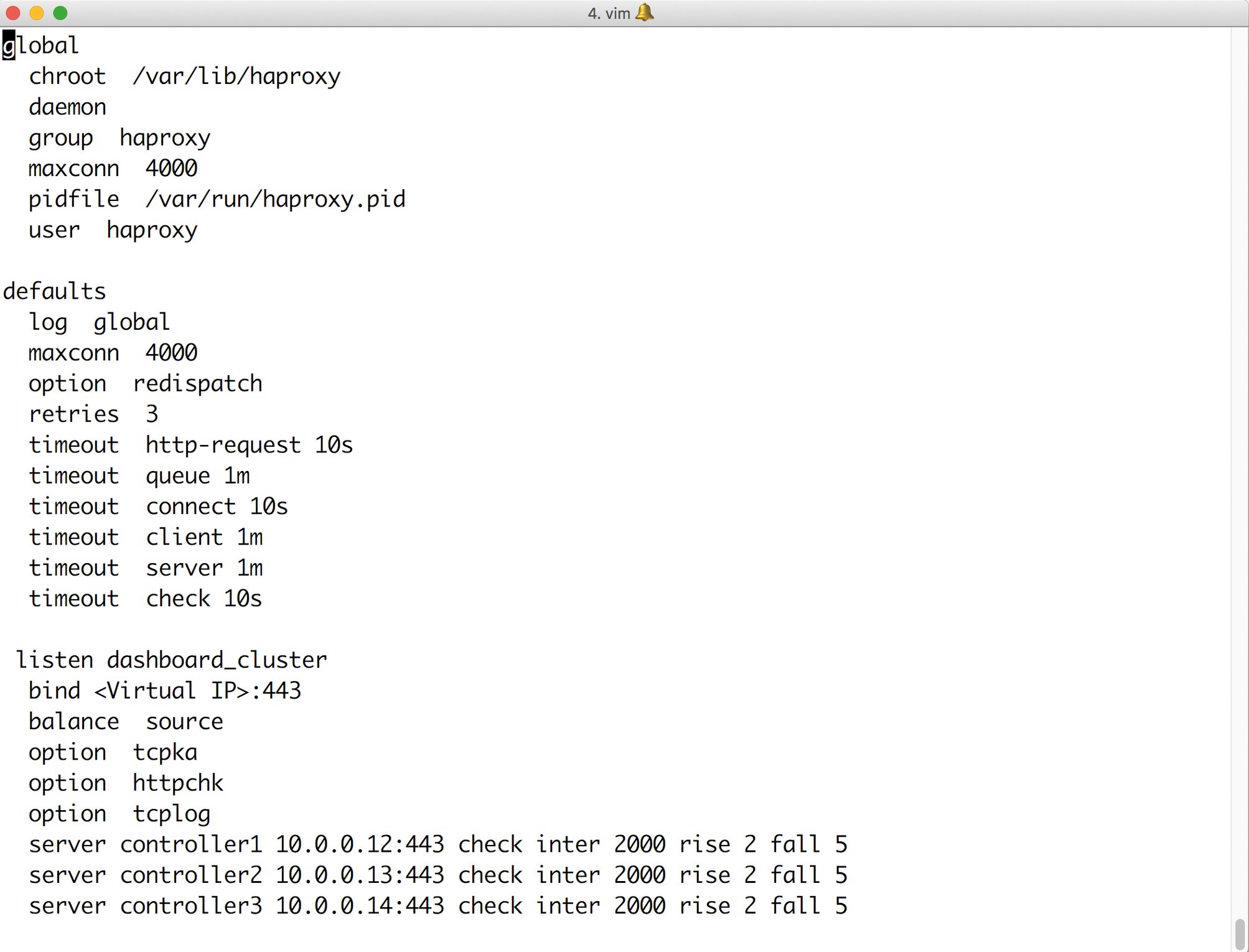
Abbildung 1: Load Balancer wie hier HA Proxy kommen regelmäßig zusammen mit Open Stack zum Einsatz. Sie bilden eine Linie im Kampf gegen Einbrecher.
Ein erster wichtiger Schritt beim Absichern von Open Stack besteht also im Design des Netzwerklayouts, das den externen Zugriff auf Ressourcen dort unmöglich macht, wo er unnötig ist. Admins tun gut daran, hier so radikal wie möglich vorzugehen: Wenn weder die Open-Stack-Controller noch die Hypervisoren von außen erreichbar sein müssen, brauchen sie auch keine öffentliche IP-Adresse. Mehr noch: Es ist auch nicht zwingend notwendig, von einem dieser Hosts aus Verbindungen zur Außenwelt herzustellen. Komplett vom Internet isolierte Systeme verhindern effektiv, dass Angreifer Schadsoftware nachladen, wenn sie sich auf irgendeinem Wege tatsächlich Zugriff verschafft haben.
Dieses Setup schafft freilich zusätzliche Arbeit. Distributions-Updates oder zusätzliche Softwarepakete müssen irgendwie ihren Weg auf die betroffenen Server finden. Doch diese Herausforderung lässt sich durch den Betrieb lokaler Spiegelserver (Abbildung 2) und eines lokalen Paket-Repository umgehen.
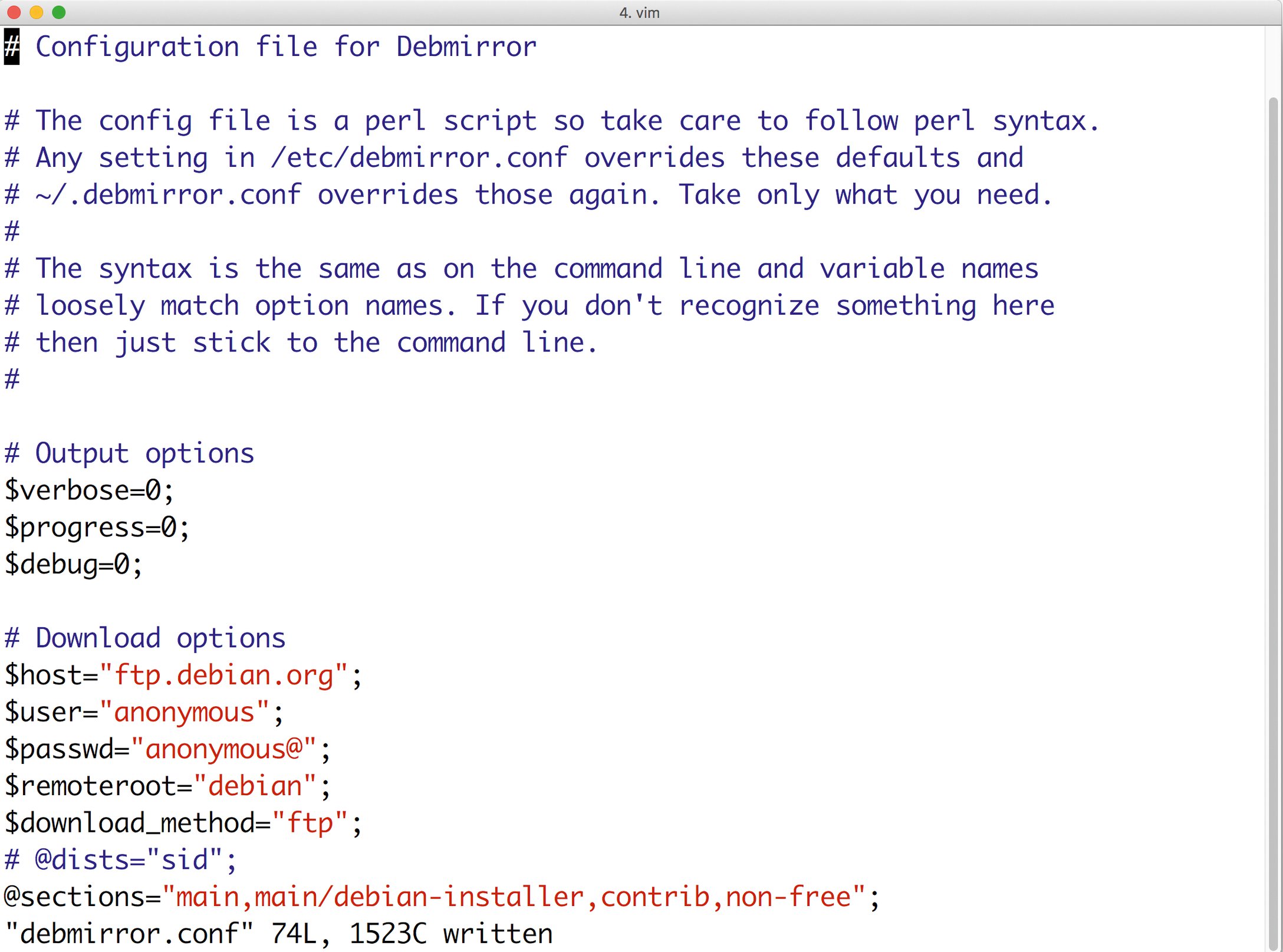
Abbildung 2: Debmirror legt einen lokalen Paketspiegel von einem offiziellen Debian- oder Ubuntu-Mirror an. So lassen sich Maschinen lokal aktuell halten, auch wenn sie keinen Zugang zum Internet haben.
Das Prinzip versteht besser, wer in Netzwerksegmenten denkt: Ein Netzwerksegment solcher Setups umfasst also Systeme, die ausschließlich mit anderen Servern lokal kommunizieren. Das zweite Segment ist eine Art DMZ: Hier befinden sich Server, die mit einem Bein im privaten Netz und mit dem anderen im Internet stehen. Die bereits erwähnten Load Balancer, die Spiegelserver und die Open-Stack-Netzwerkknoten sind typische Beispiele.
Jenes Netzwerksegment sollte zudem mit Servern versehen sein, die als Jumphost fungieren, also den Zugriff auf einzelne Systeme im privaten Netz ermöglichen. Hier sollten Maßnahmen wie VPN-Zugriff und Login über SSH-Schlüssel oder – noch besser – Zertifikate zum Einsatz kommen. Paketfilter sind grundsätzlich eine gute Idee, bieten aber nur so lange Schutz, bis sich jemand mit Admin-Rechten Zugang zu einem Server verschafft hat. Danach sind sie praktisch wirkungslos, weil sie jederzeit vom Angreifer selbst außer Kraft zu setzen sind.
Updates sind das A und O
Wer sein Netzwerk wie beschrieben plant, schafft eine physische Hürde für den Zugriff auf die kritischen Komponenten der Cloud. Ein zweiter wichtiger Baustein beim Abhärten von Open Stack besteht im konsequenten Einspielen von Updates für alle Komponenten. Das trifft auch die Server, die im genannten Design von außen gar nicht direkt erreichbar sind: Eine Lücke in KVM, die den Ausbruch aus der virtuellen Maschine ermöglicht, würde jede Netzwerk-basierte Trennung aushebeln.
Der Punkt Updates einspielen ist wieder so eine Binsenweisheit – nach der Erfahrung des Autors ist es im Cloudkontext jedoch unerlässlich, auf sie hinzuweisen. Denn vielen Admins von Open-Stack-Clouds steht beim Gedanken an Updates die Panik in den Augen. Das hat gerade bei Open Stack konkrete Gründe: Weil die Lösung komplex und schwierig aufzusetzen ist, atmen viele Admins erleichtert auf, wenn ihnen ein erstes Open-Stack-Setup gelungen ist.
Meist handelt es sich dabei aber um typische Handaufzuchten, an Faktoren wie Automatisierung und Wartbarkeit denken die Akteure zu diesem Zeitpunkt noch nicht. Was sich schnell als fataler Fehler herausstellt: Wenn eine Open-Stack-Plattform erst mal aus Dutzenden oder Hunderten Knoten besteht, lässt sie sich nicht einfach so auf Basis frischer Software neu installieren. Die auf ihr laufenden Dienste verhindern oft sogar den Neustart einzelner Knoten, um etwa ein Kernel-Update einzuspielen.
Händisch installierte Open-Stack-Umgebungen ähneln eher moderner Kunst als leicht wartbaren Plattformen. Doch lassen sich die größten Schmerzen im Hinblick auf Updates vermeiden, wenn Admins ein paar wichtige Grundregeln für die einzelnen Knoten beachten.
- Nur automatische Deployments. Die erste Grundregel besteht darin, dass es in einer produktiven Umgebung keine Server geben sollte, die händisch installiert sind. Anders formuliert: Es muss zu jedem Zeitpunkt möglich sein, jeden beliebigen Knoten aus dem Setup zu entfernen und ihn durch eine automatische Neuinstallation zu ersetzen, die gleichzeitig die neueste Software auf die Platte packt. Ein Szenario für das automatische Deployment ist in Clouds Pflichtprogramm. Änderungen per Hand auf den Knoten der Cloud sind dadurch automatisch verboten, weil sie nicht problemlos reproduzierbar sind (Abbildung 3).
Abbildung 3: RHOP, Suse Cloud oder Ubuntu bieten automatische Deployment-Tools und machen deutlich: Automatisierung in der Cloud ist Pflicht.
- Rechner ersetzbar machen. Damit sich ein Rechner für Updates problemlos aus dem Verbund entfernen und neu installieren lässt, muss eine zweite Grundregel erfüllt sein: Die VMs jedes Knotens der Cloud müssen sich jederzeit während des laufenden Betriebes auf andere Cloudknoten migrieren lassen – es sollte also möglich sein, jeden Server ohne Downtime für die Kunden leerzuräumen.
In klassischen Clouds ist hier meistens der Storage das Problem: Wer seine VMs in Open Stack nicht auf einem verteilten Speicher, sondern deren virtuelle Platten direkt auf ihrem jeweiligen Hypervisor ablegt, schafft sich einen Wartungsalptraum. Denn dann existieren die Daten der VM nur genau einmal auf jenem Hypervisor.
Sinnvoller sind verteilte Speicherlösungen wie Ceph: Liegt eine VM auf Ceph, lässt sich das zu ihr gehörende RBD-Laufwerk jederzeit auch auf einem anderen Host an die VM ankoppeln. Das Gespann aus VMware und Libvirt samt RBD-Treiber beherrscht diese Form der Live-Migration problemlos. Andere Komponenten wie die am Markt verfügbaren SDN-Lösungen unterstützen diese Funktionalität ebenfalls, sodass einer erfolgreichen Live-Migration nichts mehr im Wege steht.
- Schneller Ersatz. Wer dafür sorgt, dass eine beliebige VM von einem Hypervisor jederzeit auf einen anderen Hypervisor wechseln kann, erleichtert sich das Einspielen von Updates also erheblich. Wenn das im Linux-Magazin 3/2017 beschriebene Bare-Metal-Deployment klappt, ist das Einspielen von Updates eigentlich unnötig: Ist ein Rechner mit veralteter Software ausgerüstet, installiert der Admin ihn einfach neu und mit den aktuell verfügbaren Paketen.
Im Sicherheitskontext ergibt sich noch ein weiterer Vorteil, wenn Rechner sich beliebig aus dem Setup entfernen lassen: Entsteht auch nur der kleinste Verdacht, dass ein Rechner möglicherweise kompromittiert sei, lässt er sich schnell aus der Cloud entfernen, etwa für forensische Untersuchungen. Sobald die abgeschlossen sind, sorgt die automatische Neuinstallation dafür, dass der Server schnell wieder zur Verfügung steht.
Neuralgischer Punkt: Keystone
Open Stack Keystone, das offiziell Identity heißt, ist in Open Stack fast die Wurzel aller Funktionalität. Egal ob Nutzer von außen oder Dienst in der Cloud: Alle Clients, die irgendwas in Open Stack tun wollen, holen sich zuvor von Keystone über die Kombination aus Benutzername und Passwort ein Token und senden dieses danach bei ihren Requests mit, um sich zu authentifizieren. Ein Token ist ein temporär gültiges Passwort, anhand dessen Keystone einen Request auf seine Legitimation hin überprüft.
Entsprechend heikel ist Keystone im Hinblick auf Open-Stack-Clouds: Wenn es einem Angreifer gelingt, an einen gültigen Satz von Credentials zu kommen, kann er zumindest innerhalb der Projekte, in denen der betroffene Zugang eine Rolle spielt, tun und lassen, was er will. Mehr noch: Service-Zugänge, also jene, die andere Open-Stack-Dienste für die Kommunikation mit Keystone nutzen, sind in der Regel uneingeschränkt. Entsprechend kritisch ist der Umgang mit diesen sensiblen Informationen.
Das unsägliche Admin-Token
Noch aus der Anfangszeit von Keystone übrig geblieben ist das Admin-Token, das im Klartext in »keystone.conf« stehen kann. Das ist praktisch ein Generalschlüssel für die gesamte Cloud: Mit ihm lassen sich beliebige andere Accounts anlegen und modifizieren. Früher diente das Admin-Token dazu, um Keystone ganz am Anfang einer Open-Stack-Installation mit dem ersten Satz Nutzerdaten zu versehen. Mittlerweile gibt es in »keystone-manage« für diesen Zweck ein »bootstrap«-Kommando, das die Ersteinrichtung ohne gesetztes Admin-Token ermöglicht. Open-Stack-Admins sollten sicherstellen, dass der Eintrag »admin_token« in »keystone.conf« auskommentiert ist und keinen Wert enthält.
Jeder Open-Stack-Dienst, der mit Keystone reden möchte, muss die Credentials für seinen Service-Zugang kennen. Praktisch alle Komponenten erwarten diese Information in Form eines separaten Eintrags in der eigenen Konfiguration. Dort stehen dann alle relevanten Daten im Klartext.
Aus Admin-Sicht ist es wünschenswert, den Lesezugriff auf jene Konfigurationsdateien in geeigneter Weise zu beschränken. Zwar sollten Angreifer es bis auf die betroffenen Hosts erst gar nicht schaffen, wenn sie aber doch eingeloggt sind, sollten sie zumindest mit einem normalen Nutzerzugang die Konfigurationsdateien der Dienste nicht auslesen können.
Separation of Concern: Rollen in Keystone
Auch auf Service-Ebene lässt sich die Situation in Keystone durch ein passendes Nutzer-Rollen-Schema entschärfen. Keystone unterscheidet ab Werk nicht besonders fein – es kennt nur zwei aus Nutzersicht relevante Rollen: die Admin- und die Userrolle. Die Adminrolle weisen viele Admins Nutzern in Projekten eher versehentlich zu, weil sie annehmen, dass sie damit dem jeweiligen Nutzer spezielle Rechte innerhalb des Projekts zuteilen.
Sie vergessen dabei: Wer auch nur in einem Projekt die Adminrolle hat, kann sich auf Umwegen Zugriff auf andere Projekte verschaffen. Es verbietet sich deshalb von selbst, Nutzern die Adminrolle zuzuweisen.
Auch die Userrolle lässt sich noch entschärfen. Der Dienst identifiziert Benutzer anhand ihrer Login-Daten, die aus dem Benutzernamen, dem Passwort und dem Projekt bestehen, für das ein Nutzer ein Token anfordert. In Keystone ist zudem hinterlegt, welche Rollen ein Nutzer für ein bestimmtes Projekt hat.
Keystone selbst trifft allerdings nicht die Entscheidung darüber, was ein Nutzer mit einer spezifischen Rolle in einem Projekt tun darf, das entscheiden die einzelnen Komponenten: Jeder der Open-Stack-Dienste hat eine Datei namens »policy.json« (Abbildung 4), in der für alle dem Dienst bekannten API-Operationen vermerkt ist, welche Rolle der Dienst dafür benötigt.
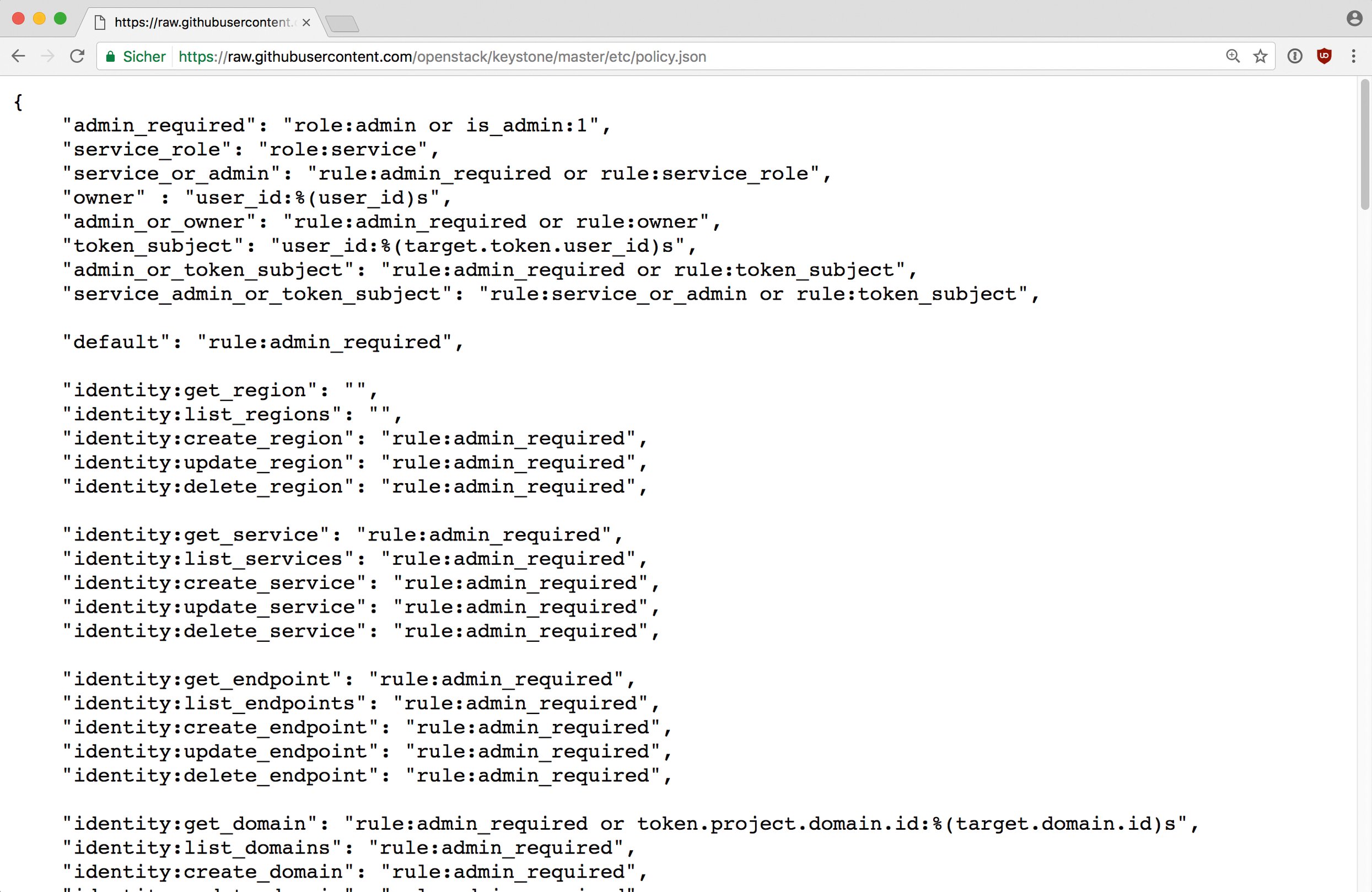
Abbildung 4: Mittels »policy.json«-Dateien – hier am Beispiel von Keystone – steuern die Open-Stack-Dienste den Zugriff auf einzelne API-Funktionen.
Indem der Admin also die »policy.json«-Dateien aller Dienste anpasst, kann er ein nur auf die Userrolle ausgelegtes System aufbohren. Denkbar ist etwa, für schreibende API-Operationen (etwa das Anlegen einer neuen virtuellen Maschine oder eines virtuellen Netzwerks) eine Operatorrolle zu schaffen, für lesende Operationen eine Viewerrolle. Anschließend gilt das Prinzip der Separation of Concerns: Wer nur lesende Operationen ausführt, bekommt ausschließlich die Viewerrolle. Wer Schreibrechte braucht, bekommt zusätzlich die Operatorrolle.
Das Vorgehen folgt dem Prinzip der Risikominimierung: Je weniger Zugänge mit Schreibrechten existieren, desto geringer ist die Gefahr, dass ein Account in die falschen Hände gerät. Der Vollständigkeit halber sei erwähnt, dass Open Stack es dem Admin nicht gerade leicht macht, für sein Setup passende »policy.json«-Dateien zu erstellen. Denn einerseits sind viele API-Operationen gar nicht oder schlecht dokumentiert, andererseits ist die Gesamtzahl der API-Operationen mit deutlich über 1000 riesig. Wer seine »policy.json«-Dateien auf Vordermann bringen möchte, tut also gut daran, viel Vorlaufzeit einzuplanen.
VMs absichern
Die bisher vorgestellten Maßnahmen setzen nicht auf der VM-Ebene an. Sie dienen stattdessen dazu, die Angriffsfläche einer Open-Stack-Cloud so klein wie möglich zu halten und den möglichen Schaden zu minimieren, den Angreifer im Erfolgsfall hervorrufen. Auch die Virtualisierung in Open Stack selbst bietet Ansatzpunkte, um die Sicherheit des Setups zu erhöhen.
Welche Tools zur Verfügung stehen, hängt auch vom genutzten Hypervisor ab. Das Handbuch für Sicherheit von Open Stack [1] etwa weist KVM als jenen Hypervisor aus, der sich der meisten externen Sicherheitsmechanismen bedienen kann. Das umfasst Svirt, also die Virtualisierungskomponente von SE Linux, genauso wie App Armor, Intels TXT sowie C-Groups und Mandatory Access Controls (MAC) auf Linux-Ebene.
Intels TXT-Feature kommt hier sogar besondere Bedeutung zu: Die Trusted Execution Technology ermöglicht es, auf Servern nur das Ausführen bestimmten Codes zu erlauben. Open Stack greift das Feature in Form der Trusted Compute Pools auf.
Darin lassen sich Server gruppieren, die TXT unterstützen. Wählen Kunden für ihre VMs dann diesen Trusted Computing Pool (Abbildung 5) aus, können sie sicher sein, dass ihre VMs nur auf Servern mit TXT-Funktionalität laufen. Dieses Setup ist im Admin-Guide von Open Stack unter [2] dokumentiert. Auch wer nicht auf TXT setzt, erreicht durch Svirt oder das auf Ubuntu ohnehin ab Werk aktive App Armor einen guten Grundstock an Sicherheit.
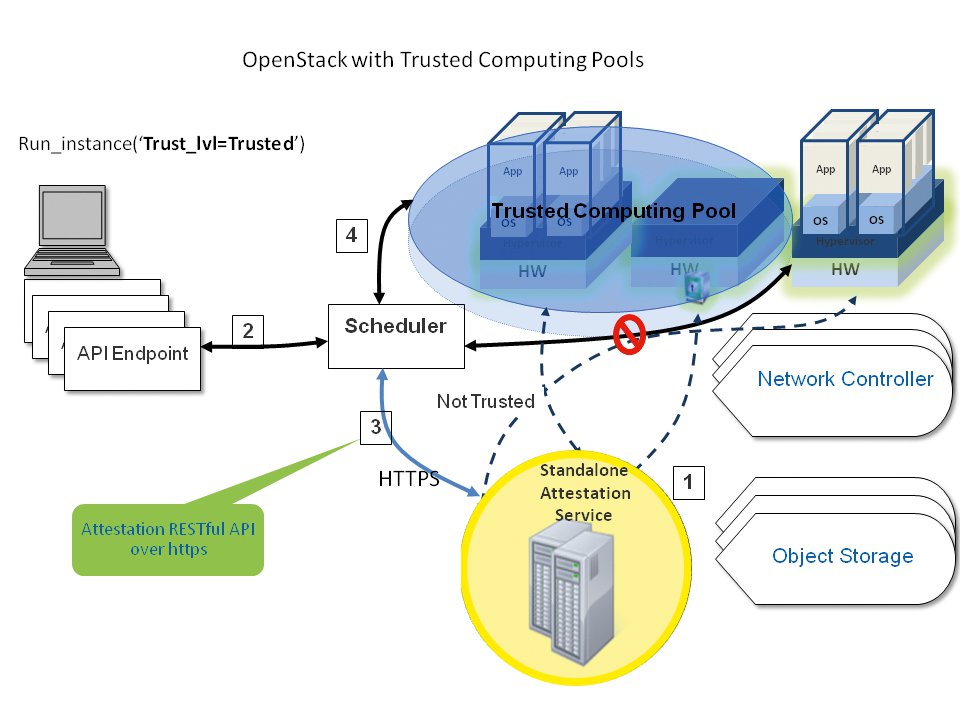
Abbildung 5: Trusted Computing Pools (auf Basis von Intels TXT-Technik) erlauben es, Einschränkungen für Programme zu definieren, die auf Cloudservern laufen.
Traurig, aber wahr: Viele Clouds laufen auf Ubuntu-Systemen, auf denen App Armor explizit deaktiviert ist, etwa weil es in der Standardkonfiguration mit der eingesetzten Storage-Lösung nicht gut harmoniert und der Aufwand für das Finden der passenden Konfiguration zu groß erschien. Sinnvoll ist dieses Vorgehen natürlich nicht.
Merken, dass etwas nicht stimmt
Letzter Punkt im Sicherheitskontext bei Open Stack ist das Thema Monitoring. Schon bei konventionellen Setups ist es für Admins eine Herausforderung, zu merken, dass etwas nicht stimmt. Bei Open Stack ist das Problem noch deutlich größer: Kunden können sich im Normalfall Zugänge zur Cloud selbst anlegen und danach in ihren VMs tun und lassen, was sie wollen. In der Regel ist dem Anbieter das egal.
Doch was geschieht, wenn ein Projekt in der Cloud die Gesamtperformance der Installation negativ beeinflusst oder andere Kunden stört? Hier muss der Anbieter proaktiv tätig sein: Er muss seine Cloud so überwachen, dass er Auffälligkeiten rechtzeitig wahrnimmt und Gegenmaßnahmen ergreifen kann.
Klassisches Incident-Monitoring im Stinne von Nagios & Co. greift hier zu kurz. Denn der Anbieter möchte im Hinblick auf das Thema Sicherheit nicht wissen, wie viel Traffic seine Cloud gerade produziert. Er will aber sehr wohl merken, wenn sich ein- oder ausgehender Traffic ohne trifftigen Grund plötzlich stark verändern.
Graphing-Systeme und Time-Series-Datenbanken wie Open TSDB oder Prometheus springen hier in die Bresche. Sie zeichnen verschiedene Performancedaten auf eine Zeitachse und erlauben auch Thresholds zu definieren. Sobald sich etwa die Werte für ein- und ausgehenden Traffic außerhalb dieser Grenzen bewegen, schlägt das System Alarm. Der Admin kann dann zumindest nachsehen und feststellen, ob ein Problem vorliegt.
Fazit
Es fällt auf, dass es gar nicht die tollen Spezialtechnologien sind, die den Admin besser schlafen lassen. Viel eher wirkt sich die konsequente Umsetzung guter Standards beim Deployment und bei der Administration von Systemen positiv aus. Auch auf der Open-Stack-Ebene lassen sich durch verschiedene Maßnahmen die möglichen Einfallstore für Angreifer zumindest deutlich verkleinern. Sicherheit in Open Stack entpuppt sich entsprechend als Gesamtkonzept, bei dem viele Faktoren zusammenwirken. (jcb)
Infos
- Open Stack Security Guide: https://docs.openstack.org/security-guide/
- Trusted Computing Pools: https://docs.openstack.org/admin-guide/compute-security.html
Der Autor

Martin Gerhard Loschwitz ist Head of Cloud bei der Firma iNNOVO Cloud. Er beschäftigt sich dort bevorzugt mit den Themen Distributed Storage, Software Defined Networking und Open Stack.





