
Beim deklarativen Programmieren drückt der C++-Programmierer unter anderem mit Hilfe von Schlüsselwörtern aus, was er erreichen möchte. Der Compiler kümmert sich dann um den weiteren Weg.
In zeitgemäßem C++ gibt es zahlreiche Beispiele für deklarative High-Level-Programmierung, und das hat Gründe. Derart programmierter Code ist nicht nur weniger fehleranfällig, sondern auch leichter zu lesen. Vielen gilt deklaratives Programmieren deshalb als die Zukunft der C++-Programmierung.
Wen das nicht überzeugt, dem liefere ich gern noch ein Killerargument: Deklaratives Programmieren gibt dem Compiler viel mehr Freiheit, optimierten Objektcode zu erzeugen. Eine Freiheit, die er heute womöglich noch nicht nutzt, die sich aber nach einem Compiler-Upgrade oder beim Einsatz eines neueren C++-Standards zeigt.
Das große Bild
Zehn Thesen, die guter C++-Code beherzigt, hatte ich zu Beginn dieser Reihe aufgestellt [1]. Im vorliegenden Artikel geht es um die zweite: “Programmiere deklarativ” (Abbildung 1).

Abbildung 1: Deklaratives Programmieren gehört neuerdings zum guten Ton in der C++-Programmierung.
Wer diesem Ratschlag folgt, darf einerseits direkt mit den Schlüsselwörtern »default« und »delete« bestimmen, ob eine Methode zur Verfügung steht oder sich nicht aufrufen lässt. Andererseits legt er mit »override« und »final« fest, ob der Code eine virtuelle Methode überschreiben darf oder nicht.
Startet der Entwickler etwa mit der Klasse »std::thread« explizit einen Thread, drückt er mit Hilfe einer Task aus, welche Arbeit in optimaler Form zu erledigen ist. Die Range-basierte For-Schleife reduziert dann die Tipparbeit in Kombination mit der automatischen Typableitung auf das Notwendigste.
Dabei muss es ihn ganz im Sinne der deklarativen Programmierung nicht mehr kümmern, dass unter der Oberfläche mehrere Iteratoren an der Arbeit sind. Lambda-Funktionen erzeugen schließlich Prädikate. Über diesen Weg kommt er am Ende deutlich leichter ans Ziel als auf dem steinigen Pfad über das Funktions-Template »std::bind()«.
Deklarativer wird es nicht
Auch wenn ich den vier neuen Schlüsselwörtern »default«, »delete«, »override« und »final« bereits einen (online kostenlos verfügbaren) Artikel [2] gewidmet habe, dürfen diese hier nicht fehlen, denn deklarativer wird es in C++ nicht.
Der Compiler erzeugt bei Bedarf sehr viele spezielle Methoden: den Default-Konstruktor, den Copy- und den Move-Konstruktor, den Copy- und den Move-Zuweisungsoperator, die Operatoren »new« und »delete« in der einfachen und für C-Arrays in verschiedenen Formen sowie den Destruktor. Die Schlüsselwörter »default« und »delete« steuern dieses Compiler-Verhalten explizit. Während eine als »default« deklarierte Methode diese vom Compiler anfordert, unterdrückt »delete« eine Methodengenerierung, die standardmäßig zur Laufzeit zur Verfügung stünde.
In Listing 1 erzeugt der Entwickler eine Klasse »OnlyMoveable«, deren Instanzen er lediglich verschieben darf. Der Compiler generiert in der Klasse »OnlyMoveable« sowohl den Default-Konstruktor (Zeile 2) als auch den Move-Zuweisungsoperator (Zeile 5) sowie den Move-Konstruktor (Zeile 6). Den Copy-Zuweisungsoperator (Zeile 3) und den Copy-Konstruktor (Zeile 4) setzt er hingegen auf »delete«. Formal gesprochen unterstützt nun die Klasse »OnlyMoveable« die Move-, aber nicht die Copy-Semantik.
Listing 1
Die Klasse OnlyMoveable
01 struct OnlyMoveable{
02 OnlyMoveable()= default;
03 OnlyMoveable& operator= (const OnlyMoveable&)= delete;
04 OnlyMoveable (const OnlyMoveable&)= delete;
05 OnlyMoveable& operator= (OnlyMoveable&&)= default;
06 OnlyMoveable (OnlyMoveable&&)= default;
07 };
In Listing 2 überprüft der Compiler zudem, ob eine als »override« deklarierte Methode in einer abgeleiteten Klasse die virtuelle Methode einer Basisklasse überschreibt. Dazu muss der Code sowohl die Parameter als auch den Rückgabetyp und die »const«-Zusicherungen der Methode einhalten. Ist die zu überschreibende Methode nicht virtuell, moniert der Compiler dies ebenfalls.
Listing 2
override und final im Einsatz
01 class Base {
02 void func1();
03 virtual void func2(float);
04 virtual void func3() const;
05 virtual long func4(int);
06
07 virtual void h(int) final;
08 };
09
10 class Derived: public Base {
11 virtual void func1() override; // ERROR
12 virtual void func2(double) override; // ERROR
13 virtual void func3() override; // ERROR
14 virtual int func4(int) override; // ERROR
15 virtual long func4(int) override; // OK
16
17 virtual void h(int); // ERROR
18 virtual void h(double); // OK
19 };
Mit dem Schlüsselwort »final« definiert der Programmierer nicht nur eine nicht ableitbare Basisklasse, sondern auch eine nicht überschreibbare virtuelle Methode. Dabei berücksichtigt der Compiler die Parameter, den Rückgabetyp und die »const«-Zusicherung der als final deklarierten Methode.
Es kommt zu Fehlermeldungen, weil die Methode »func1()« (Zeile 11) der Klasse »Base« nicht virtuell ist und die Methode »func2()« (Zeile 12) fälschlich einen »double«-Parameter erwartet. Die Methode »func3()« (Zeile 13) adressiert eine eigentlich als »const« deklarierte Methode in der Klasse »Base«, während »func4()« (Zeile 14) zunächst den falschen Rückgabetyp besitzt.
Da der Entwickler die Methode »h()« oben als »final« festlegt, kann die Klasse »Derived« sie in Zeile 17 nicht überschreiben. Den Parametertyp »double« (Zeile 18) überladen ist hingegen möglich.
Vom Thread zur Task
Deklarativ bleibt es auch bei den Tasks in C++, denn bei ihnen denkt der Entwickler nur noch in Workloads. Der kleine Codeschnipsel in Listing 3 soll den Vergleich von Threads mit Tasks auf den Punkt bringen. Sowohl der Thread (Zeilen 4 bis 7) als auch die Task (Zeilen 9 bis 10) berechnen die Summe von 2000 und 11. Dabei könnten sie unterschiedlicher nicht vorgehen.
Listing 3
Threads versus Tasks
01 #include <future>
02 #include <thread>
03
04 int res;
05 std::thread t([&]{ res= 2000+11; });
06 t.join();
07 std::cout << ret << std::endl; // 2011
08
09 auto fut= std::async([]{ return 2000+11; });
10 std::cout << fut.get() << std::endl; // 2011
Während der Thread sein Arbeitspaket sofort und explizit in einem separaten Thread berechnet, zieht die Task einen Promise »std::async([]{ return 2000+11; })« heran und stellt das Ergebnis in seinem assoziierten Future »fut« bereit. Dieser holt das Ergebnis irgendwann in der Zukunft mit Hilfe des Aufrufs »fut.get()« ab. Den Datenkanal zwischen Promise und Future stellt die Abbildung 2 schematisch dar.
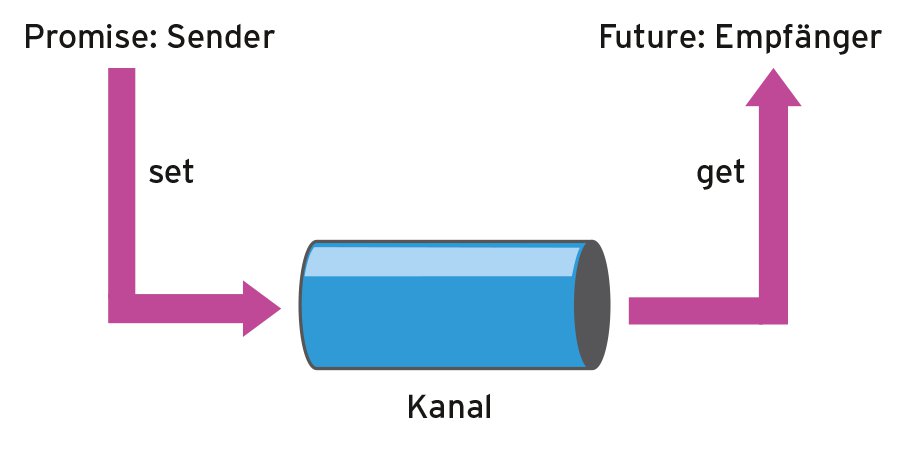
Abbildung 2: Der Datenkanal zwischen Promise und Future.
Während der Promise das Ergebnis seiner Berechnungen in den Datenkanal schiebt, holt der Future es später wieder ab. An dieser Stelle ist zu fragen, warum ein Datenkanal eine deutlich höhere Abstraktion als ein Thread darstellen soll und Tasks die Zukunft von C++ sind.
Zunächst zur ersten Frage. Tasks bieten zwei sehr schöne Abstraktionen an. Zum einen entscheidet die C++-Laufzeit, ob sie einen neuen Thread startet. Das tut sie abhängig davon, wie komplex das Arbeitspensum des Promise ist, wie viele Prozessoren zur Verfügung stehen oder wie ausgelastet das System ist. Zum anderen besteht zwischen dem Promise und dem Future ein Kanal, genau genommen ein gesicherter Kanal. Das heißt, C++ gewährleistet die sichere Kommunikation zwischen den zwei Kommunikationsendpunkten ohne Schutzmechanismen wie Locks oder Mutexe.
Das gilt nicht für den Thread. Eigentlich hätte ein Entwickler schon in dem kleinen Codebeispiel den Zugriff auf die geteilte Variable »res« schützen müssen, denn hier lauert bereits ein kritischer Wettlauf. In Zukunft wertet C++20 die Tasks, und hier insbesondere Futures, deutlich auf, indem es sie um die Komposition erweitert. Damit startet ein Future automatisch, wenn
- sein Vorgänger,
- einer seiner Vorgänger oder
- alle seine Vorgänger
mit ihrer Arbeit fertig sind. Hinter Tasks verbergen sich Threadpools, auf die der Entwickler einfach seine Aufgaben schiebt. Die Pools lasten das System optimal aus. Künftig sollen Threads nur noch ein Implementierungsdetail für höhere Abstraktionen wie Tasks sein.
Nie mehr verzählen
Ein ähnliches Schicksal blüht For-Schleifen, in denen der Programmierer den Zähler explizit hochzählen muss. Zum einen machen die Algorithmen der Standard Template Library nahezu alle For-Schleifen überflüssig, zum anderen existiert mit der Range-basierten For-Schleife eine deutlich einfachere Variante.
Range-basierte For-Schleifen verhindern die gefürchteten Off-by-one-Fehler [3], denn wer nicht zählt, kann sich nicht verzählen. Nimmt die Range-basierte For-Schleife ihre Argumente per Referenz an, lassen sie sich wie in Listing 4 direkt manipulieren.
Listing 4
Range-basierte For-Schleife
01 int myArray[5] = {1, 2, 3, 4, 5};
02 for (auto& c : myArray) c *= 2;
03 for (auto c: myArray) std::cout << c << " "; // 2 4 6 8 10
04
05 std::vector<int> vecInt({1, 2, 3, 4, 5});
06 for (auto& c: vecInt) c *= 2;
07 for (auto c: vecInt) std::cout << c << " "; // 2 4 6 8 10
08
09 std::string str= {"Only for Testing Purpose."};
10 for (auto& c: str) c=std::toupper(c);
11 for (char c: str) std::cout << c; // ONLY FOR TESTING PURPOSE.
12
13 str= {"Only for Testing Purpose."};
14 for (autor& c: str) c=std::isupper(c)? std::tolower(c): std::toupper(c);
15 for (auto c: str) std::cout << c; // oNLY FOR tESTING pURPOSE
Einfacher geht es kaum noch. Weder benötigt die Range-basierte For-Schleife einen Zähler, noch muss der Entwickler dank automatischer Typableitung mit »auto« den Typ der Container-Elemente »c« direkt angeben. In Kombination mit Lambda-Funktionen erlaubt »auto« deutlich ausdrucksvolleren Code, wie das Beispiel in Listing 5 zeigt.
Listing 5
Lambda-Funktionen als Prädikat
01 #include <algorithm>
02 #include <functional>
03 #include <iostream>
04
05 int main(){
06
07 std::cout << std::endl;
08
09 std::vector<int> myVec(20);
10 std::iota(myVec.begin(),myVec.end(),0);
11
12 std::cout << "myVec: ";
13 for ( auto i: myVec) std::cout << i << " ";
14 std::cout << std::endl;
15
16 std::function< bool(int)> myBindPred=
17 std::bind( std::logical_and<bool>(),
18 std::bind( std::greater <int>(),std::placeholders::_1,9 ),
19 std::bind( std::less <int>(),std::placeholders::_1,16 ));
20
21 myVec.erase(std::remove_if(myVec.begin(),myVec.end(),myBindPred),myVec.end());
22
23 std::cout << "myVec: ";
24 for ( auto i: myVec) std::cout << i << " ";
25
26 std::cout << "\n\n";
27
28 std::vector<int> myVec2(20);
29 std::iota(myVec2.begin(),myVec2.end(),0);
30
31 std::cout << "myVec2: ";
32 for ( auto i: myVec2) std::cout << i << " ";
33 std::cout << std::endl;
34
35 auto myLambdaPred= [](int a){return (a>9) && (a<16);};
36
37 myVec2.erase(std::remove_if(myVec2.begin(),myVec2.end(),myLambdaPred),myVec2.end());
38
39 std::cout << "myVec2: ";
40 for ( auto i: myVec2) std::cout << i << " ";
41
42 std::cout << "\n\n";
43
44 }
Es geht auch einfacher
Ein Prädikat ist eine aufrufbare Einheit, die einen Wahrheitswert zurückliefert. Die Standard Template Library verwendet Prädikate häufig, wenn es zum Beispiel darum geht, Elemente aus einem Container zu entfernen, die einer Bedingung genügen. Leider ist die Theorie einfacher als die Praxis. So will das Prädikat in Listing 5 (Zeile 16) sein Geheimnis nicht so schnell preisgeben.
In Zeile 21 kommt das Prädikat zum Einsatz und entfernt alle in Zeile 10 enthaltenen Elemente aus »myVec«, die dem Prädikat nicht genügen. Dabei stellt sich die Frage, um welches Prädikat es sich handelt. Die Antwort liefert eine Lambda-Funktion in Zeile 35, die das Prädikat dank »auto« direkt an die Variable »myLambdaPred« bindet und es unmittelbar einsatzbereit macht. Die Zeile 37 entfernt analog zur Zeile 21 alle Elemente des Containers, die größer als 9 und kleiner als 16 sind: »(a>9) && (a<16)«.
Die Funktion »std::iota()« in Zeile 10 füllt den Vektor »myVec« mit um 1 aufsteigenden Werten, beginnend mit der 0. Die Funktion »std::remove_if()« in den Zeilen 21 und 37 entfernt dabei keine Elemente aus dem Container, sondern gibt nur das logische Ende des veränderten Containers zurück. Daher sind auch die abschließenden Aufrufe »myVec.erase()« beziehungsweise »myVec2.erase()« notwendig, um den veränderten Container jeweils auf seine korrekte Größe zu reduzieren. Dieses eigentümliche Konstrukt ist in der C++-Community unter dem Namen Erase-Remove-Idiom [4] bekannt. Wer einen Blick auf die Ausgabe des Programms werfen möchte, schaut abschließend auf die Abbildung 3.
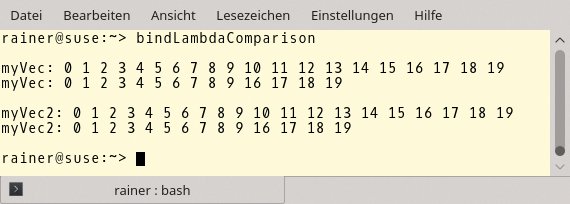
Abbildung 3: Prädikat mit »std::bind()« und einer Lambda-Funktion.
Wie geht’s weiter?
Der Artikel in der übernächsten Ausgabe stellt den dritten Tipp ins Zentrum: “Unterstütze automatische Optimierungen”. Die zentrale Idee dabei ist, Code so zu schreiben, dass ein Compiler-Upgrade oder der Einsatz eines neueren C++-Standards automatisch zu einem Performanceboost der Anwendung führen. Bekanntes Beispiel sind Move-Operationen, die anstelle der teuren Copy-Semantik zum Tragen kommen, Funktionen, die der Compiler bereits zur Compile-Zeit ausführt oder Algorithmen der Standard Template Library, die C++ parallelisiert oder gar parallelisiert und vektorisiert ausführt.
Infos
-
Rainer Grimm, “Von der Theorie zur Praxis”: Linux-Magazin 12/16, S. 100, https://www.linux-magazin.de/Ausgaben/2016/12/C
-
Rainer Grimm, “Automatik mit Methode”: Linux-Magazin 08/14, S. 100, https://www.linux-magazin.de/Ausgaben/2014/08/C-11
-
Off-by-one-Fehler: https://de.wikipedia.org/wiki/Off-by-one-Error
-
Erase-Remove-Idiom: https://en.wikipedia.org/wiki/Erase%E2%80%93remove_idiom
Der Autor

Rainer Grimm ist Trainer für C++ und Python. Seine Bücher “C++11 für Programmierer”, “C++”, “C++11-Standardbibliothek” sowie “The C++ Standard Library” sind bei O’Reilly und Leanpub erschienen.





