
© Gleb TV, 123RF
Reguläre Ausdrücke helfen Admins und Entwicklern zwar in vielen Lebenslagen, entpuppen sich aber häufig auch als schwer verdaulich. Abhilfe will die Simple Regex Language schaffen. Mit ihr schreiben Entwickler den benötigten Ausdruck in natürlicher Sprache auf und vermeiden so nicht nur Tippfehler.
Reguläre Ausdrücke erweisen sich oft als unentbehrlich. Linux-Nutzer fahnden mit ihnen nach Dateinamen oder Suchbegriffen in Texten, Entwickler prüfen die Korrektheit von E-Mail-Adressen.
Vereinfacht gesagt sind reguläre Ausdrücke Suchbegriffe, in denen spezielle Platzhalter gleich mehrere mögliche Zeichen repräsentieren. Um in der Datei »system.log« alle Zeilen zu finden, in denen die beiden Begriffe »Error« und »error« auftauchen, schreibt der Entwickler:
grep -e '[eE]rror' system.log
Das Kürzel »[eE]« bedeutet: Hier steht entweder ein kleines oder ein großes E.
Zu hart
Solche Platzhalter sind zwar kurz und knackig, machen reguläre Ausdrücke aber schnell unleserlich. Wer kann schon auf Anhieb sagen, welche Texte der folgende Ausdruck beschreibt:
/^(?:\w|[\.\-\+])+(?:@) (?:[a-z]|[0-9]|[\.\-])+(?:\.)[a-z]{2,}$/i
Wer die Zeile verstehen möchte, muss den kompletten Ausdruck mühsam und zeitaufwändig in Einzelteile zerlegen. Anders herum schmuggeln sich auch beim Zusammenstellen regulärer Ausdrücke immer wieder (Tipp-)Fehler ein. Beschreibt der daraus resultierende reguläre Ausdruck nicht mehr exakt eine E-Mail-Adresse, rutschen in einer Webanwendung womöglich beliebige Eingaben oder sogar Schadcode durch.
Wortspiel
Das Problem der Unverständlichkeit will die noch junge Simple Regex Language (SRL, [1]) des Entwicklers Karim Geiger angehen. Er startete SRL im Herbst 2016 laut eigener Aussage als Spielerei, andere Entwickler halfen dabei, das Open-Source-Projekt in anderen Sprachen zu implementieren.
Die Simple Regex Language erlaubt es, reguläre Ausdrücke in natürlicher englischer Sprache aufzuschreiben. Im Beispiel mit der Logdatei beginnen die beiden Wörter »Error« und »error« entweder mit »E« oder »e«. Auf Englisch formuliert klingt das so:
one of "eE"
Dann folgt in beiden Fällen immer wortwörtlich (»literally« auf Englisch) die Zeichenkette »rror«:
one of "eE" literally "rror"
Das ist bereits der komplette Ausdruck in der Simple Regex Language. Sie berücksichtigt bei Schlüsselwörtern keine Groß- und Kleinschreibung, »LITERALLY« ist somit dasselbe wie »literally«. Innerhalb der Argumente spielen Groß- und Kleinschreibung dagegen sehr wohl eine Rolle: »literally “Error”« bedeutet also etwas anderes als »literally “error”«.
| Schlüsselwort | Bedeutung |
|---|---|
| literally “string” | Steht stellvertretend für die Zeichenkette »string«. |
| one of “abc” | Eines der Zeichen a, b oder c. |
| letter from a to d | Eines der Zeichen a, b, c oder d. »letter« ohne das Anhängsel »from …« steht für einen beliebigen Kleinbuchstaben. |
| uppercase letter | Beliebiger Großbuchstabe. |
| any character | Groß- oder Kleinbuchstabe von a bis Z, eine Zahl von 0 bis 9 oder ein Unterstrich (»_«). |
| no character | Alle anderen (Sonder-)Zeichen und Umlaute. |
| digit from 1 to 4 | Eine der Ziffern 1, 2, 3 oder 4, wobei »digit« ohne das Anhängsel »from …« für eine beliebige Ziffer zwischen 0 und 9 steht. |
| anything | Beliebiges Zeichen mit Ausnahme eines Zeilenumbruchs. |
| new line | Zeilenumbruch. |
| whitespace | Ein Whitespace-Zeichen (dazu gehören das Leerzeichen, der Tabulator und der Zeilenumbruch). |
| no whitespace | Zeichen, das kein Whitespace-Zeichen ist. |
| tab | Tabulator. |
| backslash | Backslash-Zeichen (»\«). |
| raw “[a-z]” | Steht für das Ergebnis des regulären Ausdrucks »[a-z]«. |
In SRL rahmt der Entwickler Strings – im Beispiel »rror« – wahlweise mit einfachen oder doppelten Anführungsstrichen ein. Die einzelnen Bestandteile des kompletten Ausdrucks trennt er optional mit einem Komma oder einem Zeilenumbruch voneinander. Dies ist nicht der Logik geschuldet, sondern verbessert lediglich die Lesbarkeit:
one of "eE", literally "rror"
Der Beispielausdruck passt auf alle Textstellen, in denen die Zeichenketten »error« oder »Error« auftauchen. Eine gültige Fundstelle wäre somit auch das Wort T»error«ismus.
Leere Worte
Leerzeichen (Whitespaces) trennen die Wörter korrekt voneinander:
whitespace one of "eE" literally "rror" whitespace
In Logdateien steht das Wort »Error« meist am Anfang einer Zeile. Wen nur solche Zeilen interessieren, der schreibt:
begin with one of "eE" literally "rror"
Nun muss der Prüftext mit »Error« oder »error« anfangen. Der Ausdruck funktioniert allerdings nur dann, wenn das Prüfprogramm – ähnlich wie »grep« – jede Zeile der Datei als neu zu testenden Text betrachtet.
| Schlüsselwort | Bedeutung |
|---|---|
| exactly 4 times | Etwas wiederholt sich ganz genau vier Mal. Der Ausdruck »exactly 1 time« lässt sich mit »once« abkürzen, »exactly 2 times« mit »twice«. |
| between 2 and 4 times | Etwas wiederholt sich zwei bis vier Mal; das nachstehende Schlüsselwort »times« ist optional. |
| optional | Etwas darf vorkommen, muss aber nicht. |
| once or more | Etwas muss mindestens ein Mal vorkommen. |
| never or more | Etwas muss mehrfach oder gar nicht vorkommen. |
| at least 2 times | Etwas muss mindestens zwei Mal vorkommen. |
Einige Logdateien markieren Fehler mit dem Kürzel »EE«. Dies berücksichtigt:
begin with any of (literally "EE", (one of "eE" literally "rror"))
Wie bei den herkömmlichen regulären Ausdrücken gruppieren auch hier Klammern zusammengehörige Teilausdrücke, wobei »any of« als logisches Oder auftritt. Im Beispiel beginnt der Text (»begin with«) entweder mit der Zeichenkette »EE« oder mit »Error« beziehungsweise »error«. Das Komma ist Kosmetik: In den Klammern hinter »any of« dürfen beliebige Teilausdrücke stehen, von denen einer (»one of«) zutreffen sollte.
Wenn die Post klingelt
Mitunter sollen sich Zeichen mehrmals wiederholen. So stehen beim Kürzel »EE« exakt zwei »E« hintereinander. Auch das lässt sich mit SRL ausdrücken: »literally “E” exactly 2 times«. Anstelle von »exactly 2 times« lässt sich auch »twice« schreiben. Sinnvoll eingesetzt, erkennt der Ausdruck etwa eine E-Mail-Adresse. Diese beginnt mit einer Mischung aus Buchstaben und Zahlen sowie den Sonderzeichen »_«, ».«, »-« und »+«:
begin with any of (any character, one of".-+") once or more
Der Ausdruck »any character« steht für einen beliebigen Buchstaben zwischen A und Z oder für eine Ziffer zwischen 0 und 9 oder einen Unterstrich »_«. Groß- und Kleinschreibung spielen dabei keine Rolle. In der E-Mail-Adresse dürfen sich die erlaubten Zeichen beliebig oft wiederholen, es muss allerdings mindestens ein Zeichen vorhanden sein. Diese Bedingung stellt der Eintrag »once or more« sicher.
| Schlüsselwort | Bedeutung |
|---|---|
| capture (Bedingung) | »capture« fängt die Bedingung auf und lässt sie sich von der Engine zurückliefern. Wer »capture« mehrfach einsetzt, kann den einzelnen aufgefangenen Teilen auch Namen geben: »capture (anything once or more) as “first”«. |
| any of (Bedingung) | Jede Bedingung innerhalb der Klammern könnte zutreffen. |
| capture (Bedingung1) until (Bedingung2) | Fängt den Ausdruck Bedingung1 auf, sofern nicht schon die Bedingung2 zutrifft. |
Dann folgt das »@«-Zeichen: »literally “@”«. Der Domainname dahinter darf sich wiederum aus mehreren Buchstaben oder Zahlen sowie den Sonderzeichen ».« und »-« zusammensetzen. Mit dem Punkt als einem erlaubten Zeichen erschlägt der Entwickler zugleich auch mögliche Subdomains:
any of (letter, digit, one of ".-") once or more
Doch funktioniert »any character« hier nicht, da Domainnamen den Unterstrich »_« verbieten. In die Bresche springen »letter« und »digit«: Das erste steht stellvertretend für einen Buchstaben, das zweite für eine beliebige Ziffer. Den Abschluss bildet immer die Toplevel-Domain, die mit einem Punkt startet: »literally “.”«. Es folgen mindestens zwei weitere Buchstaben, mit denen der komplette Text und somit die E-Mail-Adresse endet:
letter at least 2 times must end
Dass Groß- und Kleinschreibung keine Rolle spielen, erklärt der Entwickler, indem er noch explizit ein »case insensitive« nachschiebt.
Den kompletten Ausdruck zeigt Listing 1. Es hält den Test auf die E-Mail-Adresse bewusst einfach, zum Beispiel erlaubt der Standard noch weitere Sonderzeichen vor dem »@«. Der Domainname muss zudem immer mit einem Buchstaben oder einer Zahl enden.
Listing 1
Prüfung einer E-Mail-Adresse
01 begin with any of (any character, one of ".-+") once or more 02 literally "@" 03 any of (letter, digit, one of ".-") once or more 04 literally "." 05 letter at least 2 times must end 06 case insensitive
Test, Test, 1, 2, 3
Ob der zusammengeklöppelte Ausdruck wie gewünscht funktioniert, lässt sich direkt auf der SRL-Homepage unter dem Menüpunkt »Build« testen [2]. Dort geben Interessierte unter »Your SRL Query« nur den SRL-Ausdruck ein, tippen einen Test-Text unter »Test Input« ein und lassen ihn via »Run Query« prüfen (Abbildung 1). Im unteren Bereich der Seite erfahren Entwickler umgehend, ob der Test-Text zum SRL-Ausdruck passt. Zusätzlich liefert die Seite als Vergleich den zugehörigen regulären Ausdruck.
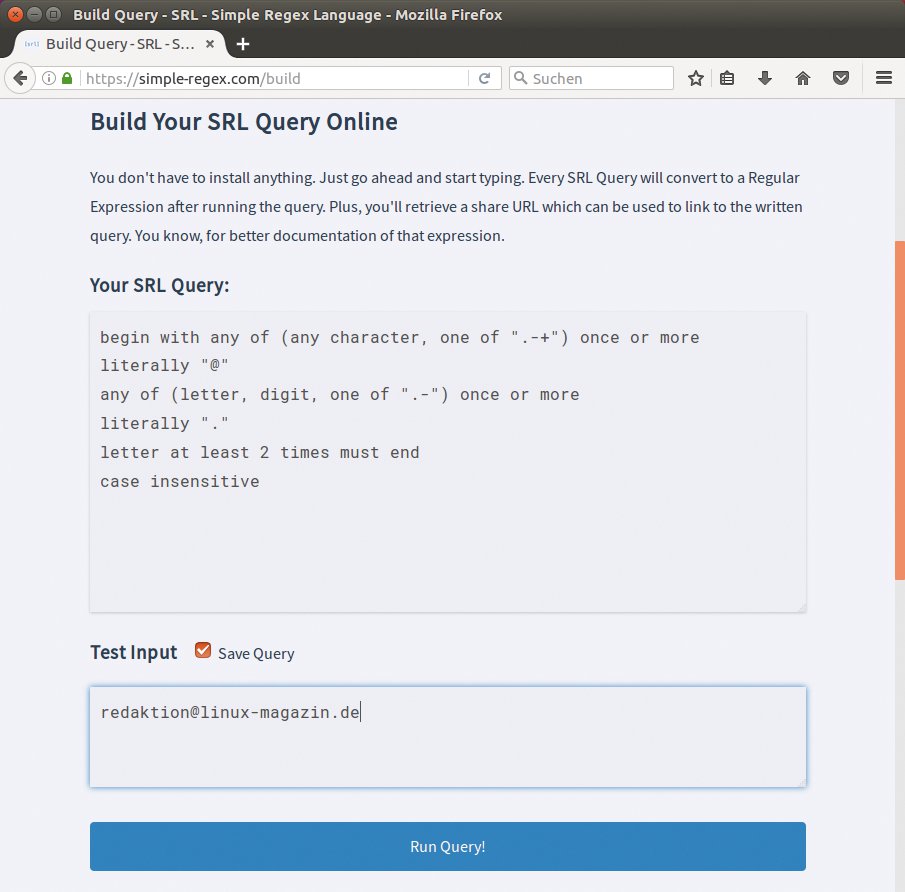
Abbildung 1: Hier prüft die SRL-Homepage mit dem angegebenen SRL-Ausdruck, ob »redaktion@linux-magazin.de« eine gültige E-Mail-Adresse ist. Das Ergebnis …
Abbildung 2 zeigt als Beispiel den regulären Ausdruck zu Listing 1 – der ist übrigens mit dem kryptischen Ausdruck vom Anfang identisch. Setzt der Tester noch ein Häkchen vor »Save Query« (rechts neben »Test Input«), merkt sich der Server alle Eingaben. Über die URL am unteren Seitenrand ruft er die Seite mit dem SRL-Ausdruck später jederzeit wieder ab. Da unklar bleibt, wo die gespeicherten Daten landen, sollten Tester als »Test Input« keine sensiblen Daten verwenden.
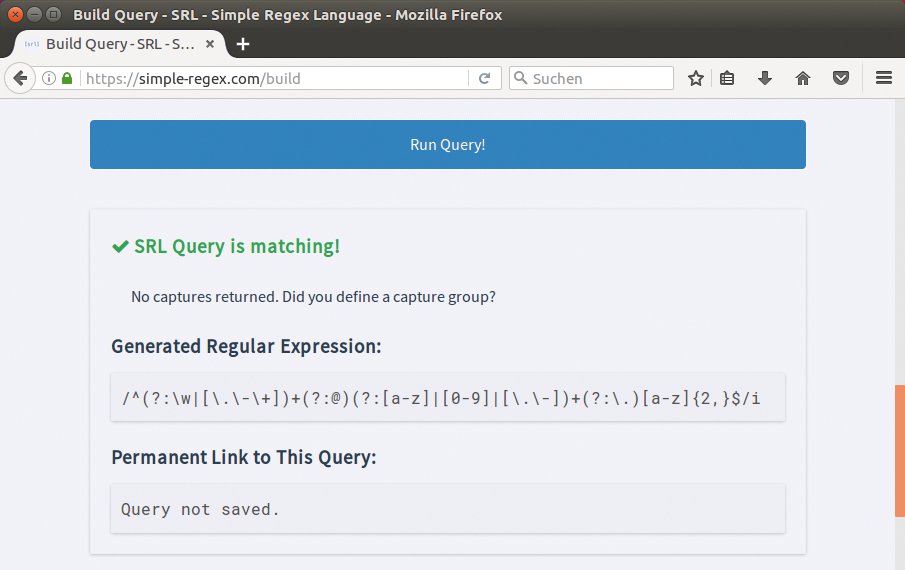
Abbildung 2: … findet sich im unteren Teil der Seite zusammen mit dem zugehörigen regulären Ausdruck.
Mit einem fertigen SRL-Ausdruck lässt sich erst einmal noch nicht viel anfangen, denn »grep« und die meisten anderen Tools verdauen ausschließlich konventionelle reguläre Ausdrücke. Abhilfe gibt es gleich doppelt: Einerseits kann ein Entwickler auf der SRL-Homepage unter »Build« den erzeugten normalen regulären Ausdruck kopieren und dann an Grep & Co. übergeben. Andererseits warten auf Github bereits spezielle SRL-Bibliotheken für Javascript, PHP, Python und C++, die allesamt unter der MIT-Lizenz stehen [3]. Vertreter für Java und C# sind noch in Arbeit.
| Schlüsselwort | Bedeutung |
|---|---|
| if followed by | Prüft, ob etwas bestimmtes folgt (Lookahead). |
| if not followed by | Prüft, ob etwas nicht folgt. |
| if already had | Prüft, ob etwas vorausging (Lookbehind). |
| if not already had | Prüft, ob etwas nicht vorausging. |
Die Funktionen und Klassen dieser Bibliotheken nehmen einen SRL-Ausdruck entgegen, werten ihn aus und wandeln ihn in einen regulären Ausdruck um. Im Falle von PHP erstellt der Nutzer etwa nur ein »SRL«-Objekt und prüft den Text über seine Methode »isMatching()«:
$srl = new SRL('one of "eE" literally "rror"');$srl->isMatching('Error'); // ist True
Neben den vorgestellten Schlüsselwörtern wie »literally« bietet SRL noch die Kollegen aus den Tabellen 1 bis 6. Sie entsprechen durchweg ihren jeweiligen Pendants bei den regulären Ausdrücken. Eine ausführliche Referenz sowie viele weitere Beispiele finden sich auf der offiziellen SRL-Homepage [1].
| Schlüsselwort | Bedeutung |
|---|---|
| case insensitive | Groß- und Kleinschreibung spielen keine Rolle mehr. |
| multi line | Der zu prüfende Text verläuft über mehrere Zeilen. |
| all lazy | Die Auswertung erfolgt nach dem Lazy-Prinzip. |
| Schlüsselwort | Bedeutung |
|---|---|
| start with | Etwas bezieht sich explizit auf den Anfang eines Strings. |
| must end | Etwas bezieht sich auf das Ende eines Strings. |
Fazit
Die Simple Regex Language notiert reguläre Ausdrücke verständlicher, wodurch zugleich Fehler schneller auffallen. Die langen Schlüsselwörter blähen aber gerade komplexe Ausdrücke etwas auf. SRL kennt derzeit keine Kommentare, die als Gedächtnisstütze dienen könnten. Auch Rekursionen fehlen. Zudem unterstützt (noch) keines der bekannten Tools die SRL-Notation. Das zwingt Entwickler den SRL-Ausdruck umzuwandeln oder zu einer der Bibliotheken zu greifen.
Dennoch lohnt ein Blick auf die SRL: Wer selten oder zum ersten Mal einen regulären Ausdruck erstellt, dürfte mit der SRL wesentlich schneller ans Ziel kommen. Alte Regex-Hasen gestalten dank der SRL ihre Ausdrücke lesbarer.
Entwickler Karim Geiger möchte künftig mit der SRL nicht nur weitere Programmiersprachen unterstützen, sondern die Sprache möglichst standardisieren und die Syntax sowie die Befehle klarer definieren. Langfristig könnte er sich auch eine Art Decompiler vorstellen, der reguläre Ausdrücke in die SRL übersetzt. Eine Bash-Version sei nicht geplant, aber vorstellbar. Von Übersetzungen der englischen Ausdrücke in andere Sprachen hält er persönlich eher nichts. Er befürchtet, damit eine Komplexität einzuführen, die inkompatible Versionen zur Folge haben könnte.
Infos
- Simple Regex Language: https://simple-regex.com
- Build-Tool für die SRL: https://simple-regex.com/build
- SRL-Bibliotheken: https://github.com/SimpleRegex






