
© Joerg Hackemann, 123RF
Standardhardware plus geeignete SDS-Software gleich ausfallsicherer, flexibel konfigurierbarer, Posix-konformer Storagepool. Setzt man für die Variable “geeignete SDS-Software” den Gluster-FS-Konkurrenten Lizard-FS ein, dann geht die Gleichung nach den Erkenntnissen aus dem folgenden Artikel restlos auf.
Storage assoziieren die meisten erfahrenen IT-ler mit großen Appliances, die Software und Hardware eines Herstellers fest miteinander kombinieren. Auf Dauer erweisen sich solche Kästen jedoch als unflexibel, sie skalieren nur in einem vorgegebenen Maß und sind nur mit Mühe zu Lösungen anderer Hersteller migrierbar. Da kommt Software Defined Storage (SDS) wie gerufen: Hier abstrahiert Software die Storagefunktionalität der Hardware.
Verteilte SDS-Dateisysteme schalten durchaus verschiedene herkömmliche Server mit Festplatten oder SSDs zu einem Pool zusammen, wobei jedes System freien Speicher bereitstellt und – je nach Lösung – unterschiedliche Aufgaben übernimmt. Das Skalieren gelingt auf Anhieb, indem der Admin weitere Geräte hinzufügt, Flexibilität ist durch die Unabhängigkeit vom Hardwarehersteller und eine schnelle Reaktion auf wachsende Anforderungen gegeben. Moderne Softwarestorages sorgen dafür, dass Daten ausfallsicher über Servergrenzen hinweg verfügbar bleiben.
Große Auswahl und große Unterschiede
Im Open-Source-Bereich gibt es bereits Lösungen [1] wie Lustre, Gluster-FS, Ceph und Moose-FS (siehe Einführungs- und Benchmark-Artikel). Die sind funktionell nicht identisch, Ceph etwa hat sich spezialisiert auf Object Storage. Besonders gefragt ist das Feature, bei dem ein SDS ein Posix-kompatibles Dateisystem bereitstellt; aus Sicht des Clients verhält sich das verteilte Dateisystem wie ein gewöhnliches lokales.
Einige der Storage-Softwarelösungen sind von Firmen gesteuert, etwa Lustre (Xyratex), Gluster-FS (Red Hat) und Ceph (Inktank Storage). Andere hängen von wenigen Entwicklern ab und bekommen zeitweise kaum oder endgültig überhaupt keine Pflege mehr. Beim Projekt Moose-FS (von der polnisch-amerikanischen Firma Core Technology, [2]) beispielsweise war im Sommer 2013 kaum noch Aktivität zu erkennen, und das Mitte 2008 gestartete System wirkt wie ein Ein-Mann-Projekt ohne Langzeitstrategie und aktive Community. Genau Moose-FS und dessen Vernachlässigung nahm eine Handvoll Entwickler aus Polen zum Anlass, um einen Fork zu initiieren und ihn unter GLPLv3-Lizenz aktiv weiterzuentwickeln – Lizard-FS [3] war geboren.
Seine Entwickler sehen Lizard-FS als verteiltes, skalierbares Dateisystem mit Enterprise-Features wie Fehlertoleranz und Hochverfügbarkeit. Hauptsächlich etwa zehn Entwickler arbeiten an der Software eigenständig unter dem Dach der Warschauer Firma Skytechnology. Wer es installieren möchte, kann Lizard-FS aus den Quellen bauen oder von der Download-Seite [4] Pakete für Debian, Ubuntu, Centos und Red Hat beziehen. Seit einigen Monaten halten zudem diverse Distributionen die Software offiziell vor.
Komponenten und Architektur
Das Design von Lizard-FS sieht eine Trennung von Metadaten wie Dateinamen, Speicherorten und Prüfsummen von den eigentlichen Daten vor. Damit keine Inkonsistenzen entstehen und atomare Aktionen auf Dateisystemebene möglich sind, schleusen die Systeme alle Vorgänge durch einen so genannten Master. Der hält alle Metadaten vor und ist der zentrale Ansprechpartner für Serverkomponenten und Clients.
Damit Master ausfallen dürfen, kann ein zweiter in eine Shadow-Rolle schlüpfen. Hierzu installiert der Admin einen Master auf einem zusätzlichen Server, der aber passiv bleibt. Der Shadow-Master holt permanent alle Änderungen der Metadaten ab und spiegelt damit den Zustand des Dateisystems im eigenen Arbeitsspeicher. Fällt der Master aus, schaltet sich das zweite System mit dem Shadow-Master in die aktive Rolle und versorgt alle Teilnehmer mit Informationen weiter (Abbildung 1).
Der Open-Source-Variante von Lizard-FS fehlt allerdings der automatische Failover zwischen dem primären und theoretisch beliebig vielen sekundären Mastern. Der Administrator ist daher entweder gezwungen manuell umzuschalten oder eine eigene Failover-Mechanik zu bauen, etwa auf Grundlage eines Pacemaker-Clusters. Da das Umschalten der Master-Rollen lediglich aus dem Abändern einer Konfigurationsvariablen sowie einem Reload des Master-Daemon besteht, sollten Administratoren mit Erfahrung im Betrieb von Clustern schnell eine eigene Lösung zustande bringen.
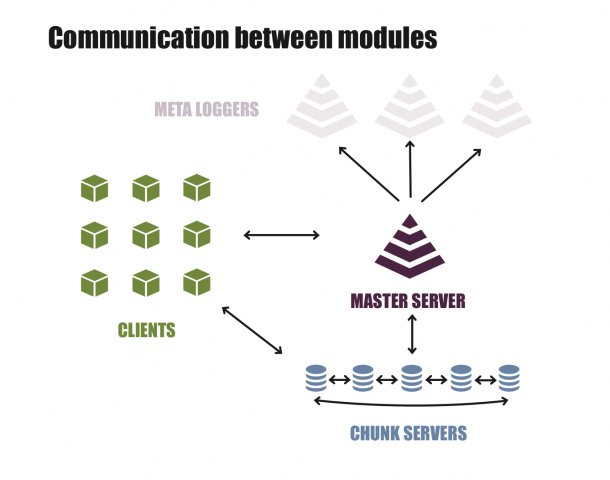
Abbildung 1: Der Lizard-FS-Master bildet das Zentrum aller Operationen.
Die Chunk-Server speichern
Für das Verwalten, das Speichern und die Replikation der eigentlichen Daten sind die so genannten Chunk-Server verantwortlich. Alle Chunk-Server sind miteinander verbunden, sie schließen ihre jeweils lokalen Dateisysteme zu einem Pool zusammen. Daten teilt Lizard-FS ab einer bestimmten Größe in Stripes auf, sie bleiben aus Sicht der Clients aber eine Datei.
Wie alle anderen Komponenten auch installiert der Admin jeden Chunk-Dienst auf einem beliebigen Linux-System. Chunk-Server sollten im Idealfall über schnelle Speichermedien (wie SAS-HDs oder SSDs) verfügen und exportieren einen Teil ihres Filesystems in den Storagepool. Im Minimalfall läuft ein Chunk-Server in einer virtuellen Maschine und gibt beispielsweise ein 20 GByte großes Ext-4-Dateisystem frei.
Der Metadata-Backup-Logger sammelt – ähnlich wie ein Shadow-Master – stets die Änderungen der Metadaten ein und sollte naturgemäß auf einem eigenen System laufen. Anders als ein typischer Master hält dieser die Metadaten jedoch nicht im Arbeitsspeicher, sondern lokal im Dateisystem vor. Im unwahrscheinlichen Fall eines Totalausfalls aller Lizard-FS-Master steht somit eine Sicherung für das Disaster-Recovery bereit.
Alle Komponenten stellen kaum Anforderungen an das darunter liegende System. Einzig der Master-Server sollte, je nach Anzahl der zu verwaltenden Dateien, etwas mehr Arbeitsspeicher besitzen.
Was die Clients alles tun
Aus der Perspektive seiner Clients stellt Lizard-FS ein Posix-Dateisystem bereit, das sie – ähnlich wie bei NFS – über einen Mount-Befehl einhängen, etwa unter »/mnt«. Vom Accounting sollten Admins jedoch nicht zu viel erwarten: Benutzer und Gruppen, die womöglich aus einem LDAP oder Active Directory kommen, kennt Lizard-FS nicht. Jeder Client im LAN darf jede Freigabe einhängen. Wer den Zugriff limitieren möchte, kann bloß einzelne Exporte read-only auslegen oder ACLs auf der Grundlage von Netzbereichen und/oder IPs vergeben. Auch die Vergabe eines (!) Kennworts für alle Berechtigten ist möglich.
Während die Serverkomponenten zwingend Linux als Basis voraussetzen, greifen neben Linux-Clients, die das Paket »lizardfs-client« installiert haben, auch Windows-Rechner über ein proprietäres Tool von Skytechnology auf das Netzwerkdateisystem zu. Die Konfigurationsdatei für die Lizard-FS-Exporte lehnt sich sichtbar an die von NFS bekannte Datei »/etc/exports« an und akzeptiert auch einen guten Teil der von NFS bekannten Parameter.
Greift der Benutzer oder eine Anwendung auf eine Datei im Storagepool zu, kontaktiert der installierte Lizard-FS-Client den aktuellen Master. Dieser verfügt über eine Liste aktueller Chunk-Server und der dort beherbergten Daten. Nach dem Zufallsprinzip präsentiert der Master dem Client einen passenden Chunk-Server, woraufhin der direkten Kontakt aufnimmt und die Daten anfordert (Abbildung 2).
Auch beim Schreiben hält der Client wieder Rücksprache mit dem Master. Es könnte ja sein, dass Balancing-Mechanismen von Lizard-FS zwischenzeitlich die betreffende Datei verschoben haben oder der eben noch zuständige Chunk-Server offline gegangen ist. In der Standardkonfiguration wählt der Master auch fürs Speichern einen Chunk-Server per Zufall aus, wobei er als Nebenbedingung darauf achtet, dass alle Server im Pool gleichmäßig belastet sind.
Hat der Master einen Chunk-Server für den Schreibvorgang ausgewählt und an den Client übermittelt, sendet dieser im nächsten Schritt seine Daten an den Ziel-Chunk-Server (Abbildung 3). Der bestätigt den Schreibvorgang und leitet – falls notwendig – eine Replikation der frisch geschriebenen Daten ein. Damit sorgt der Chunk-Server dafür, ein gegebenenfalls gesetztes Replikationsziel möglichst zügig zu erreichen. Eine Antwort an den Lizard-FS-Client signalisiert den Erfolg des Schreibvorgangs. Der Client beendet daraufhin die geöffnete Write-Session, indem er den Master über den vollendeten Vorgang unterrichtet.
Sowohl beim Lese- als auch beim Schreibvorgang beachtet der Lizard-FS-Client eine möglicherweise konfigurierte Topologie. Wenn es dem Client sinnvoll erscheint, bevorzugt dieser ortsnahe Chunk-Server gegenüber jenen, die tendenziell nur mit einer höheren Latenz erreichbar sind. Die Ortsnähe oder -ferne ergibt sich anhand von Labels (wie »frankfurt«, »rack1« oder »ssd«) oder durch die IP-Adressen der Teilnehmer.
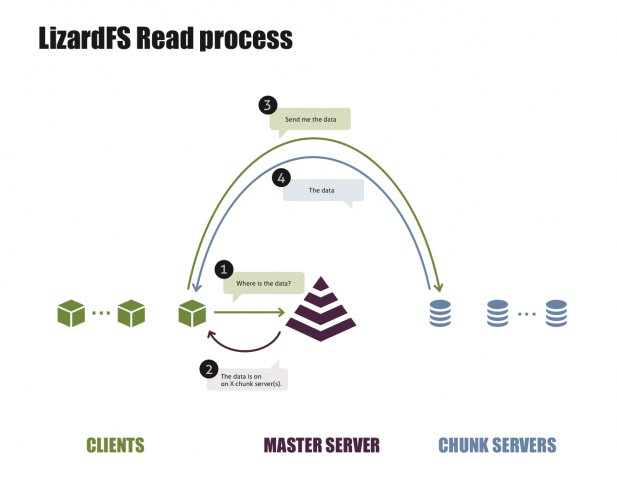
Abbildung 2: Veranschaulichung eines Lesevorgangs unter Lizard-FS.
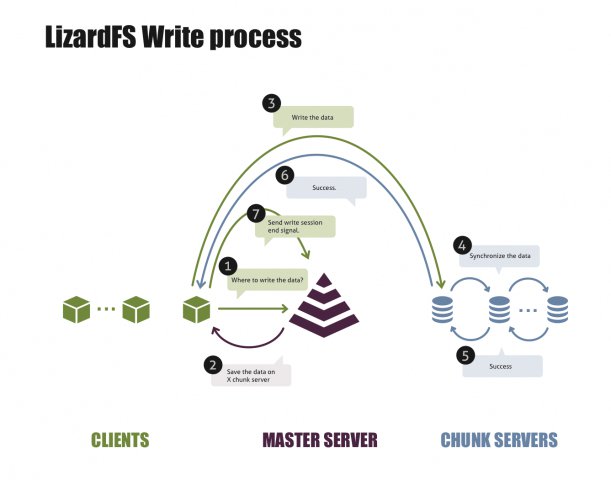
Abbildung 3: So läuft ein Schreibvorgang unter Lizard-FS ab.
Topologien und Goals
Seiner Natur folgend läuft Lizard-FS auf mehreren Servern, wobei es für die Funktionalität keine Rolle spielt, ob es virtuelle oder dedizierte Maschinen sind. Jeder Server darf jede Rolle einnehmen – auch wechselnde –, wobei eine Spezialisierung oft sinnvoll scheint. So sollten Chunk-Server auf Hosts mit großen und möglichst schnellen Festplatten laufen, während die Master-Server vor allem Ansprüche an CPU und Arbeitsspeicher stellen. Der Metadata-Backup-Logger hingegen fühlt sich wegen geringer Anforderungen ohne Nachteile auch auf einer kleinen virtuellen Maschine oder einem Backupserver wohl.
Die Daten repliziert Lizard-FS mit Hilfe vorgefertigter Replikationsziele (Goals) beliebig oft zwischen den Systemen, sie liegen also redundant und zugleich fehlertolerant vor: Fällt ein Chunk-Server aus, bleiben die Daten stets über andere Server verfügbar. Ist das defekte System repariert und wieder im Verbund eingegliedert, verteilt Lizard-FS die Dateien automatisch neu und erfüllt damit die Replikationsziele wieder.
Der Admin stellt die Goals Server-seitig ein; alternativ dürfen auch Clients Replikationsziele setzen. Damit gelingt es einem Client beispielsweise, ein eingehängtes Dateisystem normal – also redundant – vorzuhalten, temporäre Dateien aber nur an einer Stelle im Pool abzulegen.
Die Chunk-Server lassen sich mit den Topologien aus dem eigenen Rechenzentrum füttern, womit Lizard-FS weiß, ob die Chunk-Server im selben Rack oder Cage liegen. Wer die Topologien geschickt konfiguriert, bei dem bleibt der durch die Replikation verursachte Traffic hinter dem nächstgelegenen Switch oder innerhalb einer Co-Location. Der Lokalität zuträglich ist, dass Lizard-FS die Topologien auch an die Clients meldet.
Wer Lizard-FS-Setups über Rechenzentrumsgrenzen hinweg einsetzen möchte, wird die Topologien auch als Grundlage für die Georeplikation verwenden und Lizard-FS zeigen, welche Chunk-Server sich in welchem Rechenzentrum befinden. Die Clients, die auf den Storagepool zugreifen, lassen sich so motivieren, RZ-lokale Chunk-Server gegenüber weit entfernten zu bevorzugen.
Darüber hinaus müssen sich Anwender und Applikationen nicht um eine eigene Replikation bemühen. Die richtige Georeplikation ist eine natürliche Folge korrekt konfigurierter Topologien, und das Setup synchronisiert die Daten automatisch zwischen zwei oder mehr Standorten.
Skalieren und schützen
Geht der freie Speicherplatz im Storagepool zur Neige, fügt der Admin weitere Chunk-Server hinzu. Umgekehrt darf er Server herauszunehmen, wenn die darauf lagernden Daten auch anderweitig vorhanden sind. Fällt ein Chunk-Server aus, sorgt Lizard-FS selbstständig für eine Re-Balance und bietet gerade zugreifenden Clients alternative Chunk-Server als Datenquellen an. Analog zu den Chunk- skalieren auch die Master-Server. Genügen zwei Master nicht mehr, etwa weil ein Unternehmensstandort hinzukommt, setzt der Admin vor Ort einfach zwei weitere Master dazu.
Wer Daten nicht nur ausfallsicher und fehlertolerant speichern, sondern auch vor neugierigen Augen schützen will, muss zusätzliche Maßnahmen ergreifen. Lizard-FS verteilt Dateien zwar manchmal als Stripes auf mehreren Servern, was in Sachen Sicherheit und Datenschutz aber kaum Vorteile bringt. Lizard-FS selbst hat keine Verschlüsselungsmechanik eingebaut – ein echter Minuspunkt.
Der Admin muss also selbst dafür Sorge tragen, zumindest die lokalen Dateisysteme auf den Chunk-Servern zu schützen, zum Beispiel durch selbst verschlüsselnde Festplatten oder via Luks gecryptete Dateisystem-Container. Der Ansatz hilft freilich bei Hardwarediebstahl (im Vorbeigehen herausgezogene Wechselplatten), laufende Chunk-Server kann jeder angreifen, der einen Lizard-FS-Client im LAN hat.
In einem Gespräch über anstehende in Lizard-FS-Neuerungen berichtete Chief Satisfaction Officer Szymon Haly von Skytechnology Anfang November 2016, dass seine Firma den Bedarf an Verschlüsselungsfeatures durchaus sehe. Für das erste Quartal 2017 sei eine neue Lizard-FS-Version geplant, die das Verschlüsseln von Dateien und Ordnern ermöglichen werde. Die Art der Verschlüsselung und ob die neue Version auch die verwendeten Kommunikationsprotokolle absichern werde, verriet Szymon Haly nicht.
Freies Interface, proprietäres Failover
Damit Benutzer und Administratoren den Überblick behalten, stellt Lizard-FS mit dem CGI-Server ein simples, aber ausreichendes Web-GUI bereit (Abbildung 4). Der Admin kann die Komponente prinzipiell auf jedem System installieren und erhält damit eine Übersicht über alle Server im Verbund, die Anzahl der Dateien, deren Replikationszustände und andere wichtige Informationen.
Wer einen Supportvertrag mit Skytechnology abschließt, darf den proprietären U-Raft-Daemon einsetzen. Das Tool ist unabhängig von Lizard-FS und gestaltet auf Grundlage des Raft-Consensus-Algorithmus [5] eine Failover-Automatik, bei der mit Heartbeats alle Master, auf denen der U-Raft-Daemon installiert ist, aus ihrer Mitte einen Hauptverantwortlichen wählen. Damit das Quorum zuverlässig funktioniert, sollte die Zahl der Master ungerade sein. Zudem müssen sich alle im selben Netz befinden, denn mit dem jeweils primären Master verschiebt sich dessen IP (Floating-IP).
Bei U-Raft sorgen einfache Shellskripte dafür, die Master passend zu befördern oder zu degradieren. Wer Lizard-FS zusammen mit dem U-Raft-Daemon betreibt, gibt die typischen Master- und Shadow-Rollen auf und überlässt U-Raft ganz die Verwaltung der einzelnen Rollen. U-Raft sorgt sogar für den Start und Stopp des Master-Daemon, was das Initskript für den Lizard-FS-Master unbrauchbar macht. In Abbildung 5 informiert U-Raft über den Clusterzustand.
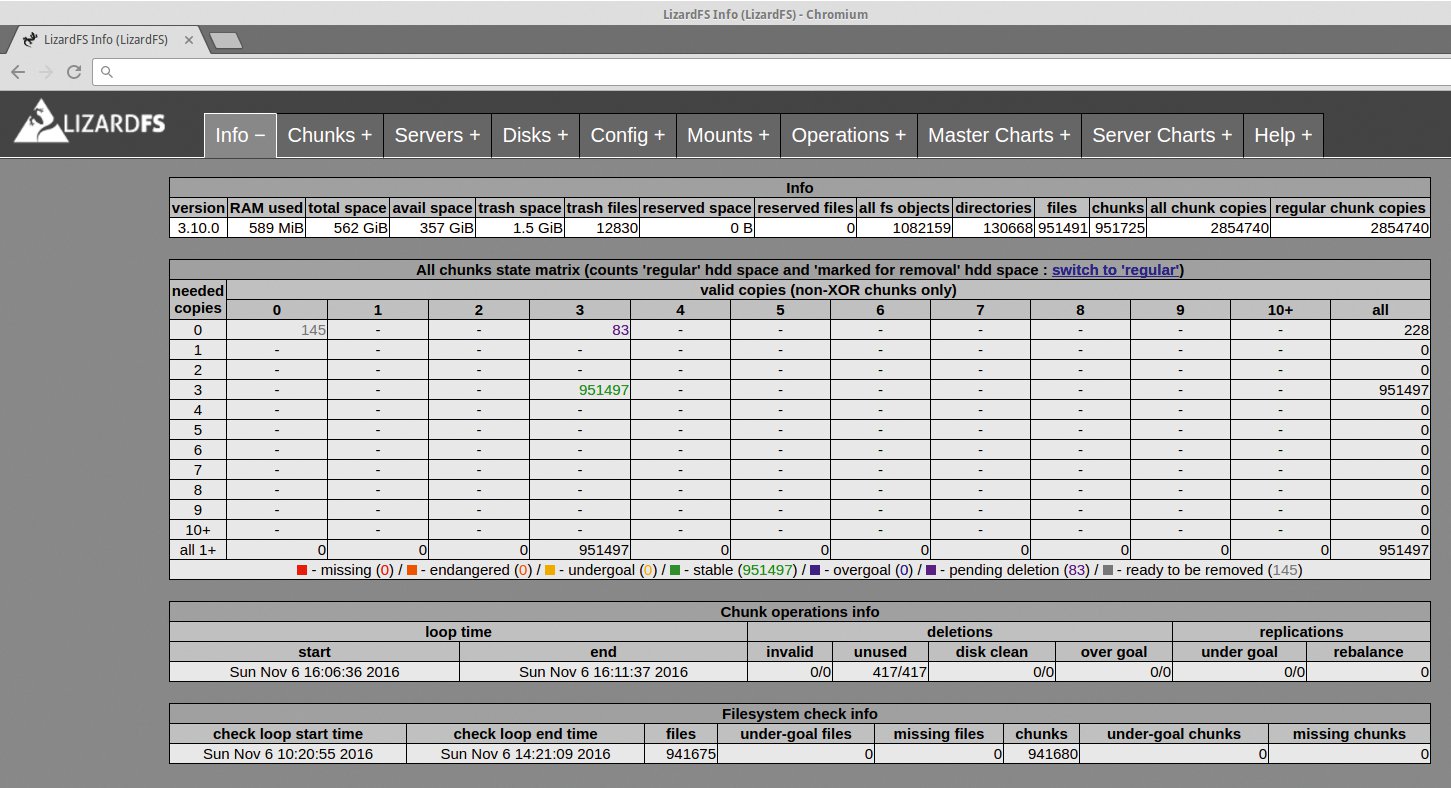
Abbildung 4: Die Lizard-FS-Weboberfläche zeigt die Server im Verbund, die Anzahl der Dateien und deren Replikationszustände.
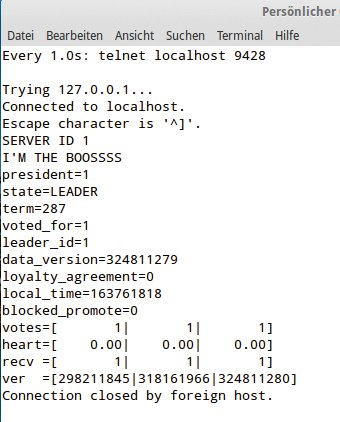
Abbildung 5: Ausgabe des U-Raft-Daemon zum aktuellen Clusterzustand.
Monitoring
Für die Basisüberwachung einer Lizard-FS-Umgebung steht das eben erwähnte Web-GUI bereit, das aber ein klassisches Monitoring unmöglich ersetzen kann. Lizard-FS benutzt jedoch bei fast allen administrativen Tools, die auch die Abfrage von Zuständen erlauben, ein spezielles Ausgabeformat, das Checks leicht auslesen können. Einer Anbindung an Nagios oder andere Monitoringtools steht damit nichts im Wege.
Dank der Kompatibilität zu einer älteren Moose-FS-Version funktionieren zudem viele Überwachungsmodule beziehungsweise -Plugins für das Mutterprojekt, die das Internet zahlreich bereithält (Abbildung 6). Findige Systembetreuer schreiben ihre eigenen Checks. Eine noch simplere Lösung: Der Autor des Artikels arbeitet für eine Firma, die einen Supportvertrag mit Skytechnology abgeschlossen hat. Im Rahmen unterstützender Dienstleistungen bekam sie Nagios-Checks geliefert, die – abgesehen von Details – ein zuverlässiges Monitoring der beteiligten Dienste erlauben.
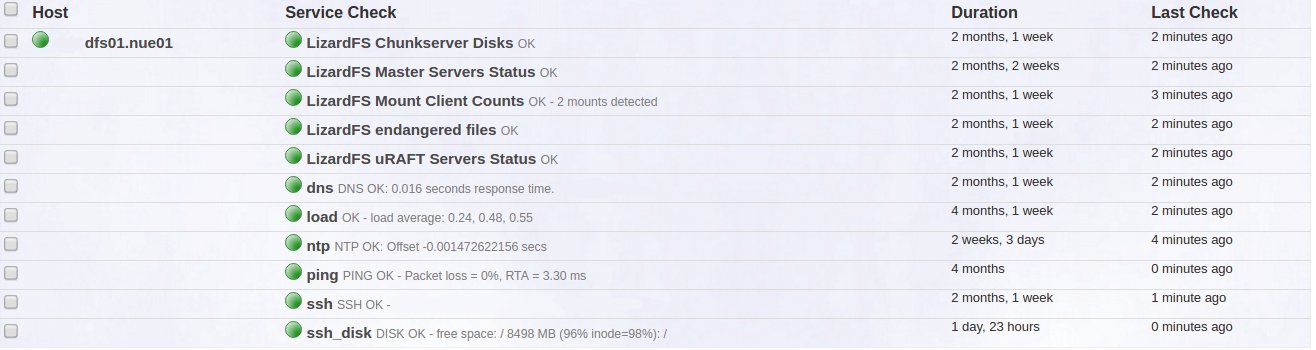
Abbildung 6: Die Nagios-Oberfläche Adagios zeigt das Ergebnis von fünf Lizard-FS-Checks auf einem Host.
Wo soll man es einsetzen?
Das Posix-konforme Lizard-FS ist prinzipiell überall einsetzbar, wo ein Client Speicherplatz benötigt. Der sinnvollste Einsatzzweck ergibt sich, wenn Nutzdaten zur besseren Verfügbarkeit redundant zu speichern sind und dies nicht auf klassischen und damit ebenso teuren wie unflexiblen Storage-Appliances erfolgen soll. Lizard-FS hingegen verteilt die Daten nach einem eigenen System in einem mehr oder minder großen und Netz-topologisch weitläufigen Pool aus günstiger Standardhardware.
Doch genau dies kann auch zum Nachteil werden: Der Administrator kann nicht bestimmen, dass zusammenhängende Daten auch zusammen auf einem Chunk-Server abzulegen sind. Zwar vermag er durch Topologien Einfluss auf Speicherorte zu nehmen (zum Beispiel: eine Kopie im Rack 14, eine andere im Rack 15), eine Garantie für feste Speicherorte ist das allerdings nicht. Zusammengehörige Daten, die sich über mehrere Chunk-Server (und damit über Rack- oder gar RZ-Grenzen hinweg) erstrecken, erzeugen beim Lesen und Schreiben naturgemäß wechselnde Netzlatenzen, was bei Anwendungen zu für deren Benutzer spürbar stark unterschiedlichen Antwortzeiten führen kann.
In der Praxis als nachteilig erweist sich verteiltes Speichern bei großen, stark frequentierte Datenbanken – hier darf der Systemarchitekt gegenüber Lizard-FS Skepsis entwickeln. Für alles andere hingegen eignet es sich bestens, für Renderfarmen etwa oder Mediendateien, bei denen alle Clients gleichzeitig auf Netz-topologisch jeweils nahe gelegene Chunk-Server zugreifen und damit die Performance der Server ausreizen.
Zu Unrecht wenig bekannt ist die Möglichkeit, Lizard-FS als Storage für virtuelle Maschinen einzusetzen. Skytechnology arbeitet eigenen Angaben zufolge an einer besseren Integration in VMware.
Quotas, Müll, Snapshots
Wo viele Systeme oder User auf Lizard-FS-Volumes zugreifen, kann der Admin Quotas aktivieren und so die Nutzung des Speicherplatzes einschränken.
Da Benutzer von Samba und Windows-Freigaben den Mülleimer gewohnt sind, lässt sich ein solcher auch für Lizard-FS-Freigaben aktivieren. In den Mülleimer verschobene Dateien bleiben dann auf den Chunk-Servern, solange sie nicht die konfigurierte Vorhaltezeit überschritten haben. Administratoren haben das Recht, Freigaben mit einem bestimmten Parameter einzuhängen, womit ihnen ein Zugriff auf die virtuellen Papierkörbe gelingt. Leider fehlt jedoch die Option, den Usern selbst Zugriff auf bereits gelöschte Daten zu geben.
Eine andere Möglichkeit, Dateien vorzuhalten, bieten die Snapshots. Es gibt ein Kommando, um eine Datei in einen Snapshot zu duplizieren. Diese Aktion ist besonders effizient, denn der Master-Server kopiert primär nur die Metadaten. Erst wenn sich der Inhalt des Originals vom Snapshot zu unterscheiden beginnt, modifizieren die Chunk-Server die entsprechenden Blöcke.
Um Dateien zu archivieren, eignet sich Lizard-FS ebenfalls. Dank der Replikation-Goals und Topologien lassen sich Dateien so anlegen, dass eine Kopie von ihnen stets auf einem gewünschten oder einer Gruppe von Chunk-Servern landet. So ist es machbar, dass eine Gruppe Chunk-Server mit Tapes (LTO) als Speichermedien ausgerüstet ist, da Lizard-FS Bandlaufwerke nativ ansprechen kann. Der Admin sorgt so dafür, dass sein Storagesystem bestimmte Daten stets auf Tape vorhält und Clients bei Bedarf auch davon lesen können.
Im Vergleich
Lizard-FS muss sich natürlich mit seinen SDS-Konkurrenten messen lassen, etwa mit Ceph oder Gluster-FS. Ceph ist primär ein zum Amazon-S3-API kompatibler Object Store, kann aber auch Blockdevices oder das Posix-kompatible Dateisystem Ceph-FS bereitstellen, das mehr ein Overlay über dem Object Store ist als ein robustes Dateisystem. Außerdem stuft der Hersteller Ceph-FS erst seit Ende April 2016 als Ready for Production ein, sodass Langzeitergebnisse für einen direkten Vergleich fehlen. Alles in allem ginge ein direkter Vergleich Ceph-FS mit Lizard-FS an der Realität vorbei.
Gluster-FS bietet auf dem Papier nahezu die gleiche Funktionalität wie Lizard-FS, ist aber schon seit 2005 auf dem Markt und genießt entsprechend viel Ansehen in der SDS-Community. Red Hats verteilter Storage offeriert eine Menge Betriebsmodi, die je nach Konfiguration andere Level an Ausfallsicherheit und Performance produzieren.
Es bietet diese Konfigurationsmöglichkeiten auf Volume-Ebene, während Lizard-FS die Replikationsziele pro Ordner oder Datei festlegt. Beide Varianten haben ihre Vor- und Nachteile: Bei Gluster-FS muss sich der Administrator beim Anlegen des Volume für eine Variante entscheiden, während er die Replikationsart bei Lizard-FS jederzeit ändern darf.
Sicherheitsbewusste Systembetreuer erfreut Gluster-FS mit der Möglichkeit, ein Volume mit einem Key zu verschlüsseln. Nur Server, die den richtigen Key vorweisen, sind dann berechtigt das Volume einzuhängen und zu entschlüsseln. Sowohl Gluster- als auch Lizard-FS sind auf Linux-Clients als Fuse-Module im Userspace implementiert.
Lizard-FS schreibt ihm angediente Daten nur auf einen Chunk-Server; von dort aus replizieren die Chunk-Server sie untereinander weiter. Bei Gluster-FS übernimmt dagegen der Client die Replikation: Der Schreibvorgang geschieht auf allen beteiligten Gluster-FS-Servern parallel, sodass der Client sicherstellen muss, dass der Replikation überall Erfolg beschert war. Das sorgt bei Schreibzugriffen zwar für weniger Performance, fällt aber ansonsten nicht ins Gewicht.
Während Lizard-FS dem Client stets einen Master präsentiert, dürfen Gluster-FS-Clients beim Einhängen des Volumen mehrere Server angeben. Fällt der erste Server der Liste aus, greift der Client selbstständig auf andere Nodes zu. Das bedeutet gegenüber Lizard-FS einen klaren Vorteil, denn der Admin kann Ausfallsicherheit ohne eine proprietäre Komponente oder ein selbst gebasteltes Pacemaker-Setup sicherstellen.
Fazit
Lizard-FS positioniert sich nicht als Konkurrent des Object-Store Ceph, wohl aber als Alternative zu Gluster-FS und läuft bereits in Setups mit mehreren hundert Terabyte als produktive SDS-Lösung. Sie besitzt viele Features, die zu den Ansprüchen vieler potenzieller SDS-Nutzer passen dürften (siehe Kasten “Evaluation und Erfahrungswerte”). Zudem kann es Daten auch zwischen mehreren Rechenzentren synchron halten. Spannend wird es, falls die Entwickler ihre Ankündigung wahr machen und ein S3-kompatibles API implementieren.
Evaluation und Erfahrungswerte
Der Autor dieses Artikels befasst sich schon länger mit SDS-Technologien und stieß dabei im Herbst 2015 auf Lizard-FS. Seither betreibt er eine Lizard-FS-2.6-Pilotumgebung unter Debian 7. Ein weiteres System mit Lizard-FS 3.10 auf Debian 8 hält er im Produktivbetrieb. Beide Cluster hat er zahlreichen Tests unterzogen, die das Verhalten der SDS-Lösung in alltäglichen und Ausfallszenarien zeigen sollen.
Die hier im Artikel beschriebenen Tests decken zwar nur einen Teil der möglichen Ereignisse ab, zeigen aber, dass die Setups grundsätzlich funktionieren und mit Fehlerfällen erwartbar umgehen können – auch wenn der Failover-Fall manchmal etwas träge verläuft. Eines der Testszenarien war der Neustart eines Masters, um einen Wechsel der Master-Rolle auf einen anderen Knoten in einem anderen Rechenzentrum zu provozieren. Der gleichzeitig stattfindende Lesezugriff eines Clients wurde während des Master-Wechsels für knapp zwei Sekunden unterbrochen, lief danach jedoch weiter. In solchen Fällen scheint es also wichtig, dass die zugreifende Applikation mit solchen Wartezeiten umgehen kann und der Master-Wechsel möglichst schnell erfolgt.
Ein anderes Szenario sieht vor, dass Clients die RZ-lokalen Chunk-Server kennen und sie beim Lesezugriff gegenüber den Chunk-Servern von einem anderen Standort bevorzugen. Während des Lesevorgangs eines RZ-lokalen Clients trennten Tester die Chunk-Server im selben Standort vom Netz, womit der Client die Daten ohne erkennbare Verzögerung von den Chunk-Servern des anderen Standorts bezog. Sobald die vom Netz getrennten Chunk-Server im RZ wieder verfügbar waren, schwenkte der Client automatisch zurück und las die Daten von den ursprünglichen Nodes.
Die Tests förderten aber auch ein Limit ans Tageslicht: Der Admin legt in Lizard-FS Goals fest, die besagen, wie oft das verteilte Dateisystem eine Datei vorhalten soll. In der Regel konfiguriert er mindestens genau so viele bis deutlich mehr Chunk-Server, um das Ziel zu erfüllen. Wenn durch Tests, Reboots, Abstürze oder andere Ausfälle jedoch zu wenige Chunk-Server online sind, um das Ziel für eine neue Datei sofort zu erfüllen, verweigert der Master den Schreibvorgang. Im getesteten Szenario waren nur noch zwei Chunk-Server bei einem Replication-Goal von drei verfügbar. Ein Lizard-FS-Entwickler bestätigte dieses Verhalten und versprach eine interne Diskussion anzustoßen.
Ausblick
Während des über einjährigen Evaluierungszeitraums wurde der Autor des Artikels Zeuge einiger Neuerungen: So entstand eine Online-Dokumentation [6], die sogar die Installation beschreibt. Zudem hat Skytechnology vermutlich auf Grund des schnellen Wachstums neue Entwickler eingestellt. “Wir arbeiten nun zusammen daran, den verbliebenen Moose-FS-Code vollständig zu ersetzen, damit wir Features implementieren können, die bisher so nicht möglich waren”, berichtet Michal Bielicki, DACH-Region-Chef von Lizard-FS.
Dazu sollen spürbare Änderungen bei der Performance und Unterstützung von IPv6 und Infiniband zählen. Chief Satisfaction Officer Szymon Haly kündigte im Gespräch mit dem Linux-Magazin ebenfalls fürs erste Quartal 2017 eine dateiweise Verschlüsselung an.
Weitere Verbesserungen sollen erweiterte ACLs, besseres Logging-Verhalten bei Windows-Clients und Minimal-Goal-Settings bringen. Letzteres wünscht sich die Community schon länger, denn solche Settings könnten für mehr Zuverlässigkeit und Datensicherheit sorgen.
Gerüchte, wonach Skytechnology die proprietäre Failover-Komponente U-Raft als Open-Source-Projekt freigeben will, wollten die Firmenvertreter gegenüber dem Linux-Magazin weder bestätigten noch dementieren. Allerdings hatte Adam Ochma?ski, Gründer und CEO von Skytechnology, Ende August auf Github geschrieben, Lizard-FS 3.12.0 werde U-Raft enthalten [7]. Ob er damit die Offenlegung des Quellcodes oder die Veröffentlichung in Binärform meint, ist unklar.
Schade ist, dass Skytechnology, die Firma hinter Lizard-FS, bislang den Daemon für automatische Failovers zahlenden Kunden vorbehält. HA-erfahrene Admins werden zwar mit Pacemaker einen funktionierenden Cluster hinbekommen, eine Kochbuch-Anleitung, Skripte und Tipps dafür aber fehlen. Verbesserungspotenzial gibt es bei der Kommunikation nach außen (Roadmap, mehr Dokumentation, Community-Arbeit), bei der Softwareversionierung (kleine Änderungen provozieren schon mal eine Major-Release) und im technischen Detail: Ein SDS sollte schon heute eine native Verschlüsselung für die Kommunikation zwischen den Nodes und Daten mitbringen und dafür sorgen, dass Schreibvorgänge auch dann möglich bleiben, wenn viele Chunk-Server offline sind. Den etwas mehr als zehn aktiven Entwicklern wird die Arbeit nicht so schnell ausgehen.
Infos
-
Verteilte Dateisysteme: https://en.wikipedia.org/wiki/List_of_file_systems#Distributed_file_systems
-
Moose-FS: https://moosefs.com,http://moosefs.org
-
Lizard-FS: https://lizardfs.com
-
Download: https://lizardfs.com/download/
-
Projektseite des Raft-Algorithmus: https://raft.github.io
-
Online-Dokumentation: https://lizardfs.com/documentation/
-
Skytechnology informiert zur U-Raft-Veröffentlichung: https://github.com/lizardfs/lizardfs/issues/389





