
© wathanyu sowong, 123RF
Das Versprechen von Software Defined Storage ist es, heterogenen Speicher zentral und mit eingebauter Redundanz zu verwalten. Der folgende Test geht der Frage nach, wie kompliziert das Aufsetzen der dazu nötigen verteilten Dateisysteme ist. Ein Benchmark zeigt, welche Operationen jedes am besten beherrscht.
Nicht selten landen Technologien, die anfangs hauptsächlich in großen Rechenzentren zum Einsatz kommen, irgendwann auch in den Netzwerken kleinerer Unternehmen oder gar – wie im Falle der Virtualisierung – auf den Desktops gewöhnlicher User. Dieser Prozess lässt sich auch für Software Defined Storage (SDS) beobachten.
Im Grunde geht es bei SDS darum, die Festplatten mehrerer Server in eine große, redundante Speicherlandschaft zu verwandeln. Der Nutzer des Speichers soll sich nicht mehr darum kümmern, auf welcher konkreten Festplatte seine Daten im Augenblick liegen. Zugleich soll er sich beim Crash einzelner Komponenten darauf verlassen, dass die Landschaft die Daten dennoch konsistent speichert und zugänglich macht.
In einer Umgebung mit nur einem Fileserver ergibt die Technologie wenig Sinn, in großen IT-Landschaften deutlich mehr. Hier setzt der Admin das Szenario professionell mit dedizierten Servern und Kombinationen aus SSDs und traditionellen Festplatten um. Gewöhnlich verbindet er die Komponenten dabei über ein 10-Gigabit-Netzwerk miteinander und mit den Clients.
SDS bringt aber inzwischen auch schon Mehrwert, wenn in kleinen oder mittelständischen Unternehmen mehrere Server warten, auf denen Festplattenplatz brachliegt. In diesem Fall kann es interessant sein, diesen Platz mit Hilfe der verteilten Dateisysteme in einem redundanten Array zu bündeln.
Kandidatenkür
Linux-Admins dürfen gleich auf mehrere Varianten solcher hochverfügbaren, verteilten Dateisysteme zugreifen. Bekannt sind Gluster-FS [1] und Ceph [2], unbekannter ist Lizard-FS (siehe folgenden Artikel, [3]). Dieser Beitrag analysiert die drei Systeme und vergleicht in einem Benchmark die Lese- und Schreibgeschwindigkeiten im Testnetz.
Zwar ist die Geschwindigkeit ein zentrales Feature von Dateisystemen, doch gibt es nicht nur ein Tempo: Je nachdem, wofür der Admin das Dateisystem einsetzen möchte, kann mal das sequenzielle Schreiben, mal das schnelle Anlegen neuer Dateien, mal auch das zufällige Lesen unterschiedlicher Daten ausschlaggebend sein. Die Benchmark-Ergebnisse geben Hinweise auf die Schwächen und Stärken der Systeme.
Die drei Kandidaten im Test verfolgen dabei unterschiedliche Ansätze. Ceph ist ein verteilter Object Store, der in Form von Ceph-FS [4] auch als Dateisystem einsetzbar wird. Gluster-FS und Lizard-FS sind hingegen als Dateisysteme konzipiert. Während jedoch zum Betrieb eines Gluster-Setups bereits zwei Knoten genügen, braucht Lizard-FS noch einen zusätzlichen Kontrollknoten. Dafür bringt es eine Weboberfläche mit (Abbildung 1), die den Admin über den Zustand des Clusters informiert.
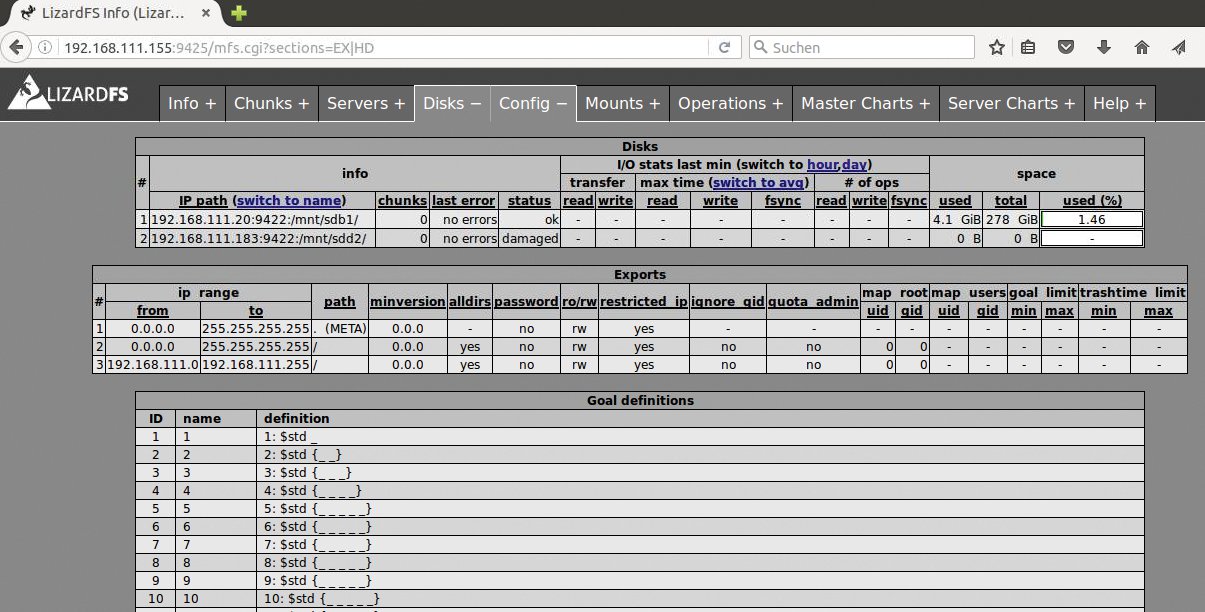
Abbildung 1: Lizard-FS gehört eher zu den Newcomern unter den verteilten Dateisystemen, bringt aber eine Weboberfläche für Admins mit.
Der Artikel schaut zunächst, wie viel Aufwand Installation und Konfiguration der Dateisysteme bereiten, und betrachtet im Benchmark den Datendurchsatz.
Der Testaufbau
Das Setup im Linux-Magazin-Labor bestand aus einem Client mit Ubuntu Linux 16.04 LTS, der mit zwei Storage-Servern mit reichlich Festplatten verbunden war (Tabelle 1). Als Betriebssystem auf den Storage-Servern lief Centos 7, auf einem vierten Admin-Rechner Ubuntu 16.04 LTS. Er diente Ceph-FS und Lizard-FS als Monitor respektive Master-Server.
Testhardware
|
Server |
CPU |
RAM |
Storage |
|---|---|---|---|
|
Fileserver 1 |
Intel Xeon X5667 mit 3 GHz und 16 Kernen |
16 GByte |
Disk-Array T6100S mit 10 Hitachi-Platten (7200 RPM), als Raid 1 konfiguriert |
|
Fileserver 2 |
Intel Core i3 530 mit 2,9 GHz und 4 Kernen |
16 GByte |
I-SCSI-Array Thecos mit 2 320-GByte-Festplatten, als Raid 1 konfiguriert |
|
Admin-Server |
Intel Core 2 E6700 mit 2,66 GHz und 2 Kernen |
2 GByte |
keine Angabe |
|
Client |
Intel Core 2 6320 mit 1,86 GHz und 2 Kernen |
2 GByte |
keine Angabe |
Fileserver 1 besaß ein über SCSI angeschlossenes Storage-Array, Fileserver 2 war über I-SCSI an ein weiteres Array angebunden. Die Kommunikation zwischen den Servern erfolgte mit Gigabit-Ethernet, während der Client und der Admin-Server jeweils nur eine 100-MBit/s-Schnittstelle mitbrachten. Kein Aufbau für Hochleistungsanforderungen, aber in kleineren Unternehmen nicht unüblich. Das Setup erlaubte es zudem, die Kandidaten unter gleichen Bedingungen zu testen. Als Testwerkzeuge kamen dabei Bonnie++ [5] in Version 1.97 und Iozone 3.429 [6] zum Einsatz. Die startete der Tester jeweils auf dem Client und ließ sie dann jeweils auf das gemountete Dateisystem des Testkandidaten los.
Gluster-FS
Gluster-FS ließ sich unter den Teilnehmern am einfachsten aufsetzen. Der Tester musste die Software lediglich auf dem Ubuntu-Client und den beiden Storage-Servern installieren. Zur Installation auf Centos fügte er das Epel-Repository [7] hinzu und rief »yum update« auf.
Dann kann er die Software in Version 3.8.5 über die Pakete »centos-release-gluster« und »glusterfs-server« einspielen. Um den Dienst zu starten, aktiviert der Admin den »glusterd« über »systemctl«. Nach dem Start des Dienstes auf beiden Storage-Servern prüft er deren Lebenszeichen über:
gluster peer probe IP/Hostname_des_Peer peer probe: success.
Erscheint die Antwort aus der zweiten Zeile, verläuft alles nach Plan. Taucht eine Fehlermeldung auf, liegt die Ursache vermutlich an der fehlenden Namensauflösung oder der Admin hat schlicht vergessen den Dienst zu starten.
Das Dateisystem erzeugt der Tester auf den existierenden Dateisystemen der Storage-Server, um es im zweiten Schritt zu aktivieren:
gluster volume create lmtest replica 2 transport tcp Fileserver_1:/MountpointFileserver_2:/Mountpointgluster volume start lmtest
Um das neu angelegte Volume zu nutzen, benötigt der Tester noch das Paket »glusterfs-client«. Es bringt die Kerneltreiber und notwendigen Werkzeuge mit, um ein Volume einzubinden. Das erledigt dann der Befehl:
mount.glusterfs Fileserver_1:/lmtest /mnt/glusterfs
Anschließend steht das Dateisystem auf dem Client für die Leistungstests bereit.
Spaß mit “ceph-deploy”
Beim schnellen Einstieg in Ceph hilft die Dokumentation unter [8]. Installation und Konfiguration übernimmt das Werkzeug »ceph-deploy«[9]. Da es SSH-Verbindungen zu den verwalteten Systemen verwendet, sollte der Admin zunächst die Preflight-Sektion der Dokumentation [9] durcharbeiten. Dies sind die wesentlichen Arbeitsschritte:
- Einen »ceph-deploy«-User auf allen Systemen anlegen.
- Diesen User in die Sudoers-Liste eintragen, damit er alle Kommandos ohne Passworteingabe ausführen kann.
- Einen SSH-Schlüssel in der »~/.ssh/authorized_keys«-Datei dieses Benutzers eintragen, damit sich das Admin-System damit anmelden kann.
- Die »~/.ssh/config« so konfigurieren, dass SSH beim Kommando »ssh host« den angelegten Benutzer und die richtige Schlüsseldatei verwendet.
Diese Schritte führt der Admin auf allen vier Rechnern aus, also auf den Storage-Servern, dem Client und dem Admin-Server. Unter Centos auf den Storage-Servern ergänzt er wieder das Epel-Repository [7] und installiert Ceph 10.2.3. Für Debian- und Ubuntu-Systeme (Client und Admin-Server) wartet in der Preflight-Sektion der Dokumentation [9] eine Anleitung, wo auf der Ceph-Homepage sich das Repository für Ceph 10.2.2 befindet, das im Test zum Einsatz kam.
Das Tool »ceph-deploy« sammelt Daten wie Schlüssel im aktuellen Verzeichnis. Die Dokumentation empfiehlt daher, für jeden Ceph-Cluster ein eigenes Verzeichnis anzulegen. Das Kommando
ceph-deploy new mon-node
schiebt die Installation an. Es erzeugt im aktuellen Verzeichnis unter anderem die Datei »ceph.conf«. Damit der Testaufbau mit zwei Storage-Nodes funktioniert (Ceph verwendet standardmäßig drei, damit es eine Mehrheit gibt), benötigt die Konfigurationsdatei im Abschnitt »[global]« die Zeile:
osd pool default size = 2
Es folgt die Installation der eigentlichen Software, die »ceph-deploy« ebenfalls übernimmt. Dazu dient das Kommando:
ceph-deploy install Admin-Rechner Fileserver_1 Fileserver_2 Client
Als Argumente erwartet es eine Liste der Hosts, auf die »ceph-deploy« die Software spielen soll. Das Tool verteilt die Pakete also an den Client, an die Storage-Nodes, die in der Ceph-Welt OSDs heißen (Object Storage Devices), sowie an den Admin-Rechner, auf dem zugleich der Admin- sowie der Monitor-Node laufen, wobei letzterer die Kontrolle besitzt.
Da »ceph-deploy« praktischerweise auch die verschiedenen Linux-Distributionen kennt, kümmert es sich selbst um die Installationsdetails. Anschließend aktiviert der Tester den ersten Monitor-Node über den Befehl:
ceph-deploy mon create-initial
Das Kommando sammelt auch die Schlüssel der beteiligten Systeme ein, damit die Ceph-interne Kommunikation funktioniert.
Danach erzeugt der Tester das Volume, was in zwei Schritten passiert. Über die Kommandos
ceph-deploy osd prepare Fileserver_1:/VerzeichnisFileserver_2:/Verzeichnisceph-deploy osd activate Fileserver_1:/VerzeichnisFileserver_2:/Verzeichnis
legt er das Volume auf den Storage-Servern Fileserver_1 und Fileserver_2 an. Wie bei Gluster existieren auch die Verzeichnisse bereits und enthalten das Dateisystem, auf dem Ceph die Daten speichert. Als Admin aktiviert er das Volume anschließend. Der Befehl
ceph-deploy admin Admin-Rechner Fileserver_1 Fileserver_2 Client
verteilt die Schlüssel an alle Systeme. Als Argument dient wieder die Liste der Rechner, die einen Key brauchen.
Fehlt noch der Metadaten-Server. Ihn legt er mit dem Befehl »ceph-deploy mds create mdsnode« an. Das Kommando »ceph health« überprüft am Ende, ob der Cluster funktioniert.
Der Client
Für den Ceph-Client stehen drei Optionen zu Wahl. Neben Kernelspace-Implementierungen von Ceph-FS und Ceph Rados gibt es Ceph-FS noch in einer Userspace-Version. Der Test schickt Ceph Rados und Ceph-FS mit Kernelspace-Implementierung ins Rennen.
Als Block Device legt der Tester über »rbd create lmtest –size 8192« ein neues Rados Block Device an (RBD), das er mit
rbd map lmtest --name client.admin
aktiviert. Das Gerät steht dann im Pfad »/dev/rbd/rbd/lmtest« bereit und lässt sich mit einem Dateisystem versehen, das der Client wie eine lokale Festplatte mountet.
Auf dem Ubuntu-Rechner wirft das »map«-Kommando allerdings eine Fehlermeldung aus. Um das Rados-Device dennoch anzulegen, muss der Tester einige Argumente übergeben, um Features abzuschalten. Der Befehl
rbd feature disable lmtest exclusive-lock object-map fast-diff deep-flatten
bringt nach einigen Tests den gewünschten Erfolg.
Danach gilt es, ein Ceph-Dateisystem (Ceph-FS) bereitzustellen. Dazu erzeugt der Admin im ersten Schritt einen Pool für Daten und einen für Metadaten:
ceph osd pool create datapool 1 ceph osd pool create metapool 2
Die beiden Zahlen am Ende verweisen auf den Index der Placement Group. Dieses Kommando führt der Cluster-Betreiber auf dem Admin-Node aus, der auf dem Admin-Rechner läuft, und erzeugt dann das Dateisystem, das diese beiden Pools verwendet. Die Anweisung lautet:
ceph fs new lmtest metapool datapool
Der Client mountet jetzt das Dateisystem. Hierzu muss er sich jedoch authentisieren. Das Passwort generiert »ceph-deploy« und verteilt es auf den Client. Dort landet es in der »/etc/ceph/ceph.client.admin.keyring«-Datei.
Der Benutzername lautet im Test einfach »admin«, ihn übergibt der Client mit dem folgenden Kommando an das Dateisystem:
mount -t ceph mdsnode:6789:/ /mnt/cephfs/ -o name=admin,secret=Keyring-Passwort
Anschließend steht das Dateisystem für den Test bereit.
Lizard-FS
Lizard-FS, das der zweite Artikel des Schwerpunkts beleuchtet, ähnelt Ceph im Aufbau. Die Daten landen auf so genannten Chunk-Servern (die auch die Festplatten enthalten sollten), ein Master-Server koordiniert alles. Den Unterschied macht die anfangs erwähnte Weboberfläche (Abbildung 1).
Zur Installation der Version 3.10.4 unter Centos fügt der Admin das Repository unter »http://packages.lizardfs.com/yum/el7/lizardfs.repo« zum Verzeichnis »/etc/zum.repos.d« hinzu. Auf dem Master-Server (dem Admin-Rechner) installiert er dann das Paket »lizardfs-master«, auf dem Client »lizardfs-client« und auf den Chunk-Servern mit den Festplatten »lizardfs-chunkserver«.
Die Konfiguration findet sich auf allen Systemen unter »/etc/mfs«. Auf dem Master-Rechner verwandelt er die Dateien »mfsgoals.cfg.dist«, »mfstopology.cfg.dist«, »mfsexports.cfg.dist« und »mfsmaster.cfg.dist« in Versionen ohne die Endung ».dist«. Für einen Testaufbau passen dann die Inhalte aller Dateien, lediglich die Datei »mfsmaster.cfg« benötigt die Einträge aus Listing 1.
Listing 1
mfsmaster.cfg
01 PERSONALITY = master 02 ADMIN_PASSWORD = admin123 03 WORKING_USER = mfs 04 WORKING_GROUP = mfs 05 SYSLOG_IDENT = mfsmaster 06 EXPORTS_FILENAME = /etc/mfs/mfsexports.cfg 07 TOPOLOGY_FILENAME = /etc/mfs/mfstopology.cfg 08 CUSTOM_GOALS_FILENAME = /etc/mfs/mfsgoals.cfg 09 DATA_PATH = /var/lib/mfs
Auf den Chunk-Servern warten die Konfigurationsdateien im Verzeichnis »/etc/mfs«. In die Datei »mfschunkserver.cfg« gehört lediglich der Eintrag »MASTER_HOST«, der auf den Master verweisen soll. In die Datei »mfshdd.cfg« trägt der Admin die Verzeichnisse ein, in denen Lizard auf dem Chunk-Server Daten ablegt. Da der Dienst unter der Benutzerkennung »mfs« läuft, muss der Betreiber sicherstellen, dass dieser Benutzer Schreibrechte für die verwendeten Verzeichnisse besitzt.
Schließlich startet der Admin die Master- und Chunk-Server-Dienste auf den jeweiligen Rechnern:
systemctl start lizardfs-master systemctl start lizardfs-chunkserver
Damit ist alles vorbereitet, der Client kann das Dateisystem einhängen und darauf zugreifen:
mfsmount -o mfsmaster=lizard-master Mountpoint
Um die anfangs angesprochene Webschnittstelle zu nutzen, installiert der Admin das Paket »lizardfs-cgiserv«, das dann als Server auf Port 9425 Verbindungen akzeptiert.
Bonnie Voyage
Für die Tests setzt der Tester auf Bonnie++ und Iozone (siehe Kasten “So haben wir getestet”). Bonnie++ testet im ersten Lauf byteweises und dann blockweises Schreiben, wozu es das »putc()«-Makro respektive den Systemaufruf »write(2)« verwendet. Der Test überschreibt die Blöcke per Rewrite und misst den Datendurchsatz dabei.
So haben wir getestet
Zum Einsatz kamen Bonnie++ 1.97 und Iozone 3.429. Ersteres testet sequenzielles block- und byteweises Schreiben, Lesen und Überschreiben. Zudem erzeugt die Software sequenziell, aber auch zufällig, Dateien und löscht sie wieder. Iozone beschränkt sich darauf, das Schreiben, Lesen und Überschreiben zu testen, aber dafür mit verschiedenen Blockgrößen.
Um die Performance des Dateisystems und nicht des Cache-Speichers vom Client zu testen, leerte der Tester die Caches mit »echo 3 > /proc/sys/vm/drop_caches«. Jeden Test wiederholte er für jedes Dateisystem zweimal und betrachtete dann die Mittelwerte der jeweiligen Versuche.
In den Testergebnissen hält Bonnie++ auch die CPU-Last während des Tests fest. Gerade das byteweise Schreiben ist bei schneller Netzwerkanbindung oder bei lokalen Platten aber eher ein Test für die CPU des Clients als für den getesteten Speicher.
Ceph-FS und Ceph Rados schreiben mit 391 und 386 KByte pro Sekunde deutlich schneller als Gluster mit 12 KByte und Lizard mit 19 KByte. Dafür liegt bei den beiden Ceph-Kandidaten die CPU-Last des Clients bei gut über 90 Prozent, während Bonnie für die beiden anderen nur 30 Prozent (Lizard) und 20 Prozent (Gluster) misst. Ein NFS-Mount zwischen dem Client und Fileserver_2 schafft 530 KByte/s (Abbildung 2).
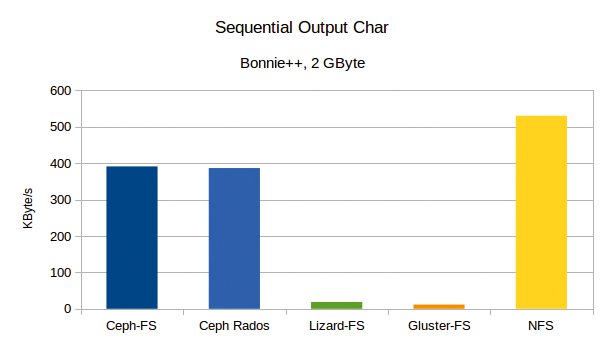
Abbildung 2: Die beiden Ceph-Kandidaten schreiben die Daten schneller, belasten dabei aber auch die CPU deutlich stärker.
Beim blockweisen Schreiben fallen die Unterschiede weniger frappierend aus. Beide Ceph-Varianten und Lizard liegen dicht beieinander, Gluster erzielt etwa die Hälfte der Performance (Abbildung 3). In Zahlen: Ceph Rados erreichte 11,1 MByte/s, Ceph-FS 11,5 MByte/s, Lizard 11,4 MByte/s und Gluster 5,7 MByte/s. Die lokale NFS-Verbindung schafft im Vergleich nur 10,6 MByte/s. Vermutlich erzielen Ceph und Lizard hier dank der Verteilung auf mehrere Server einen höheren Durchsatz.
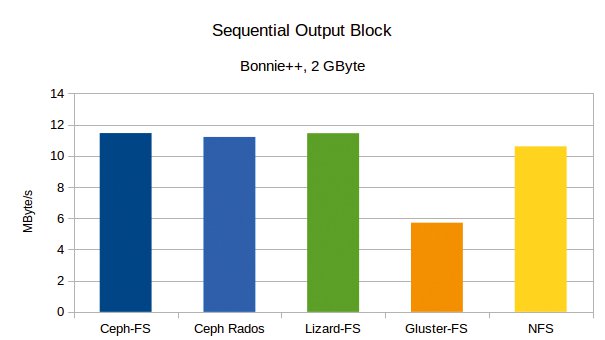
Abbildung 3: Beim blockweisen Schreiben sieht das Ergebnis etwas ausgeglichener aus. Die NFS-Werte liegen unter denen von Ceph und Lizard.
Beim Überschreiben der Dateien liegen die Ergebnisse wieder weiter auseinander. Ceph-FS tut sich mit 6,3 MByte/s spürbar leichter als Ceph Rados (5,6 MByte/s). Lizard-FS fällt dagegen mit 1,7 MByte/s deutlich ab und Gluster landet abgeschlagen auf dem vierten Platz mit 311 KByte/s.
Beim Lesen nähert sich das Feld dann wieder an (Abbildung 4). Beim byteweisen Lesen liegt das sonst im hinteren Teil des Feldes laufende Gluster mit knapp 2 MByte/s vor Ceph Rados (1,5 MByte/s), Lizard (1,5 MByte/s) und dem hier abgeschlagenen Ceph-FS (913 KByte/s). NFS hält sich mit 1,4 MByte/s im Mittelfeld. Auffällig bei Ceph-FS ist, dass die CPU-Auslastung trotz der niedrigen Leistung bei 99 Prozent liegt.
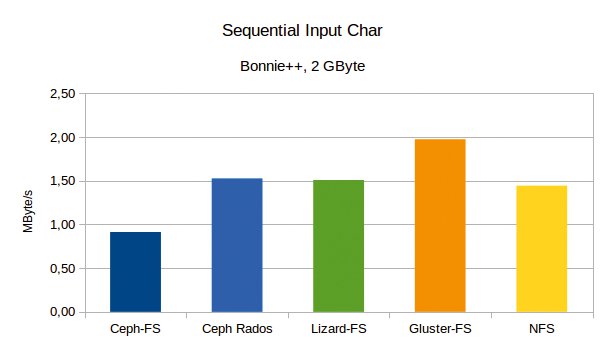
Abbildung 4: Beim byteweisen Lesen schiebt sich Gluster-FS an die Spitze, während Ceph-FS deutlich abfällt.
Bonnie++ testet auch Seek-Operationen, um die Geschwindigkeit der Leseköpfe sowie das Anlegen und Löschen von Dateien zu erkunden.
Bei den Seeks ist im Test die Spanne wieder extrem groß, Ceph Rados stellt sich mit durchschnittlich 1737 Input/Output-Operations per Second (IOPS) als klarer Sieger heraus. Ihm folgt Ceph-FS (1035 IOPS), dann kommt lange nichts, schließlich trödeln noch Lizard (169 IOPS) und Gluster (85 IOPS) hinterher. NFS liegt im Vergleich mit 739 IOPS in der Mitte.
Die letzte Testrunde befasst sich mit dem Anlegen und Lesen (hier ist der Stat-Systemcall gemeint, der die Metadaten einer Datei, etwa den Besitzer oder die Erzeugungszeit ausliest) und dem Löschen von Dateien. In bestimmten Anwendungsfällen, etwa als Webcache, sind diese Leistungsdaten wichtiger als das rohe Lesen oder Schreiben in einer Datei.
Beim linearen Anlegen von Dateien gewinnt Ceph Rados mit einer ganzen Größenordnung Vorsprung (Abbildung 5). Das ist ungewöhnlich und liegt mutmaßlich daran, dass Ceph Rados die Datei-Operationen auf dem Ext-4-Dateisystem des Block Device ausführte. Dies meldete womöglich wesentlich schneller an Bonnie++ zurück, dass die Datei angelegt sei. Das Rados Device schafft im Durchschnitt rund 7500 IOPS. Ceph-FS landet trotzdem mit rund 540 IOPS auf dem zweiten Platz, gefolgt von Lizard mit 340 und dicht dahinter Gluster mit 320. NFS verliert diesen Wettkampf mit 41 Operationen. Das zufällige Anlegen bringt kaum messbare Unterschiede – mit Ausnahme für Ceph Rados, das noch schneller arbeitet.
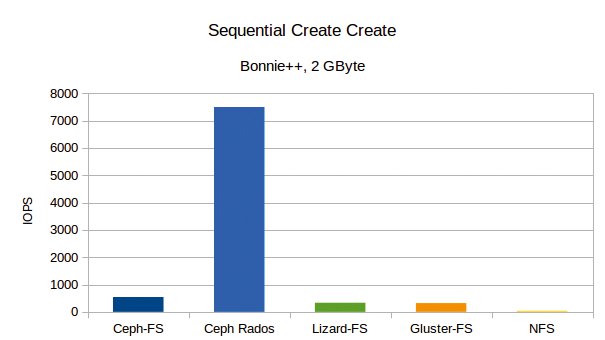
Abbildung 5: Für den starken Ausschlag beim Test mit Ceph Rados könnten Dateioperationen auf dem Ext-4-System des Block Device verantwortlich sein.
Das Auslesen der Datenstrukturen liefert kein einheitliches Messergebnis. Bei Ceph Rados verweigert Bonnie++ beim linearen und zufälligen Lesen das Ergebnis. Das passiert auch beim zufälligen Lesen mit Ceph-FS. Bei diesen Dateisystemen ist die Posix-Konformität wohl nicht 100-prozentig gegeben.
Lizard gewinnt das lineare Lesen mit rund 25500 IOPS, gefolgt von Ceph-FS mit etwa 16400 IOPS und Gluster mit 15400 IOPS. Beim zufälligen Lesen kommen Lizard und Gluster nur noch auf eine Größenordnung niedrigere Messwerte (1378 IOPS für Lizard und 1285 IOPS für Gluster). NFS hätte die Tests mit rund 25900 IOPS (linear) und 5200 IOPS (zufällig) mit Abstand gewonnen.
Bleibt noch das Löschen von Dateien. Klarer Sieger (und wie beim Erzeugen vermutlich außer Konkurrenz) ist Ceph Rados mit etwa 12900 linearen und 11500 zufälligen IOPS. Die drei anderen Kandidaten beherrschen das zufällige Löschen jeweils besser als das lineare. Ein Sieger ist zwischen ihnen nicht auszumachen, Ceph-FS ist aber Letzter. Die Werte im Einzelnen: Lizard (669 IOPS linear, 1378 IOPS zufällig) Gluster (886 IOPS linear, 1285 IOPS zufällig), Ceph-FS (567 IOPS linear, 621 IOPS zufällig).
In der Zone
Ergänzend zog der Tester noch Iozone heran, das ihn mit einer großen Menge an Daten versorgte. Abbildung 6 zeigt einen Ausschnitt. Im Gegensatz zu Bonnie++ beschränkt sich das Testwerkzeug auf Lesen und Schreiben, tut dies jedoch mit weitaus mehr Detailtiefe als Bonnie++. Es liest und schreibt Dateien in unterschiedlichen Block- und Dateigrößen, wobei das Schreiben mit »write()« und »fwrite()« erfolgt und vorwärts, zufällig und überschrieben wird. Iozone liest zudem vorwärts, rückwärts und zufällig und greift auch hier zu den Betriebssystem- und Bibliotheksaufrufen.
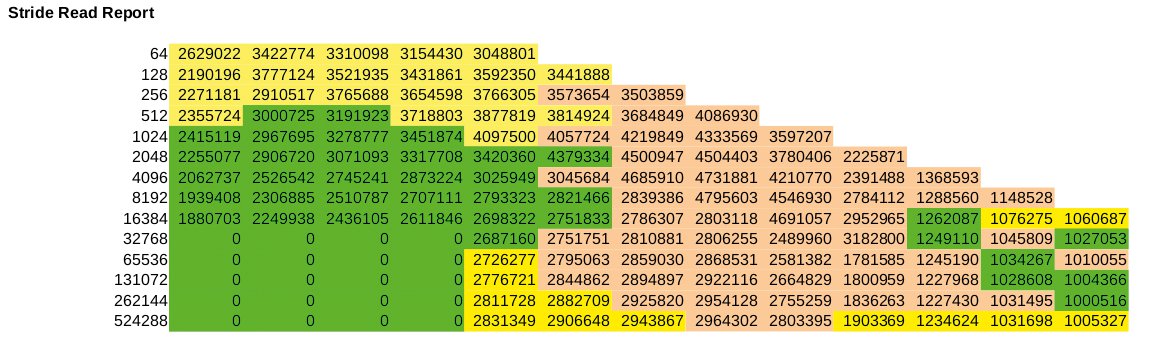
Abbildung 6: Beim Stride-Read-Test von Iozone übernimmt Lizard-FS (gelb) bei kleineren Dateigrößen die Führung. Rot gefärbt ist Ceph-FS, grün Ceph Rados.
Im Schreibtest bestätigt Iozone im Wesentlichen die Ergebnisse von Bonnie++. Aber es gibt auch Messwerte, bei denen Ceph Rados vorne liegt. In den meisten Fällen ist dies bei Operationen mit kleinen Blockgrößen der Fall. Beim Lesen liegt das Block Device bei den kleinen Blockgrößen fast durchgängig vorn, im mittleren Bereich führt Ceph-FS. Lizard-FS punktet in einigen Tests bei großen Dateien und Blockgrößen.
Eine Ausnahme bildet der Stride-Read-Test, in dem Iozone linear jeden soundsovielten Block liest (etwa 64 Byte ab Block 1024 und so weiter). Hier gewinnt Lizard auch bei kleinen Dateien und Dateigrößen und erscheint in Abbildung 6 gelb eingefärbt.
Fazit
Die Konfiguration gelang mit Gluster am einfachsten, gefolgt von Lizard-FS. Ceph aufzusetzen forderte dem Tester etwas größeren Aufwand ab.
Bei der Performance machen Ceph-FS (Posix-Mounten) und Ceph Rados (Block Device mit einem eigenen Dateisystem versehen) im Linux-Magazin-Testlabor in den meisten Disziplinen die beste Figur. Ceph Rados zeigt einige Ausreißer nach oben, profitiert hier aber in Wirklichkeit nur vom Caching auf dem Client.
Scheut der Admin die Komplexität von Ceph, bringt Lizard zwar kleine Performance-Einbußen, den Admin aufgrund des Setups aber schneller ans Ziel. Gluster-FS bleibt bei den meisten Tests im Schatten, schiebt sich aber beim sequenziellen Lesen von Zeichen vor.
Im Iozone-Test hat Lizard-FS beim Lesen häufig die Nase vorn, aber nicht beim Schreiben. Je mehr Blockgröße und Dateigröße anwachsen, desto häufiger entscheidet Lizard das Rennen für sich oder landet zumindest auf einem Platz hinter Ceph-FS, aber noch vor Ceph Rados.
Als traditionelle SDS-Alternative ließ der Autor NFS laufen, das sich gut schlug, aber den verteilten Dateisystemen nicht unbedingt davonrannte.
Infos
-
Gluster-FS: https://www.gluster.org
-
Ceph: http://ceph.com
-
Lizard-FS: https://lizardfs.com
-
Bonnie++: http://www.coker.com.au/bonnie++/
-
Iozone: http://www.iozone.org
-
Epel-Repository: https://fedoraproject.org/wiki/EPEL
-
Ceph-Dokumentation: http://docs.ceph.com/docs/master/start/
- »ceph-deploy«: http://docs.ceph.com/docs/jewel/rados/deployment/





