
Das Kommandozeilentool »find« hangelt sich nur sehr gemächlich durchs Dateisystem. Dagegen lokalisiert das hier vorgestellte Skript »rummage« dank einer Datenbank mit Meta-Informationen blitzschnell selbst entlegene Dateien.
Wo ist das Skript, das ich gestern zusammenklopft habe? Welche Dateien sind neu, brauchen den meisten Platz oder wurden seit drei Jahren nicht mehr angefasst? Dateisysteme lassen sich natürlich schrittweise durchforsten und so die Antworten auf solche Fragen finden. Spottbillige Riesenfestplatten haben allerdings in den letzten Jahren dafür gesorgt, dass Anwender ihr Homeverzeichnis nicht regelmäßig ausmisten und Find & Co. oft zehn- oder gar hunderttausend unnütze Einträge abwandern müssen. Das dauert.
Utilities wie »slocate« durchforsten den Dateibaum bei Nacht, legen dabei einen Index an und erlauben es dem Anwender, die indizierten Dateien anschließend schnell über ihren Namen zu finden. Der Google-Desktop [2] und Spotlight unter Mac OS X setzen sogar noch eins drauf: Sie indizieren zusätzlich verschiedene Metadaten und gestatten es dem Benutzer damit, Dateien anhand von Merkmalen wie Typ, Größe, Name oder Alter wiederzufinden.
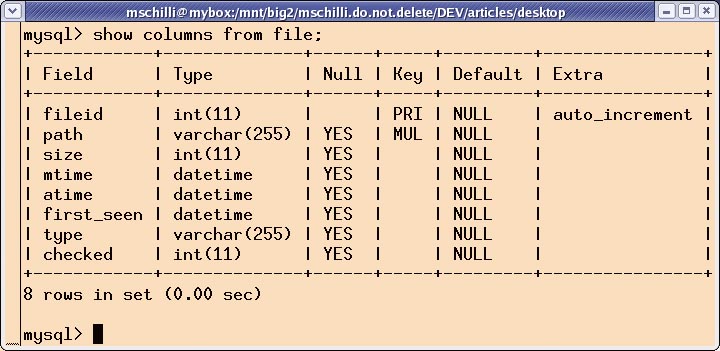
Das hier vorgestellte Skript »rummage« implementiert eine Desk-topsuche in Perl. Es achtet nicht nur auf Dateinamen, es merkt sich au-ßerdem, wann Dateien zum ersten Mal auftauchten und wann sie zum letzten Mal geändert wurden. Es legt eine Reihe von Meta-Informationen über jede gefundene Datei in einer MySQL-Datenbank ab (Abbildung 1). Von Textdateien bildet es einen Volltextindex, damit der Benutzer später per Keyword-Suche ihren Inhalt durchstöbern kann.
Volltext auf Abwegen
Seit der Version 3.23.23 bietet MySQL eine Option, die Tabellenspalten markiert, deren Inhalt später per Volltextsuche zugänglich sein soll. Mit 4.0.1 kamen boolesche Verknüpfungen der Suchausdrücke hinzu. Der Anwender kann sogar Stopplisten anlegen, mit denen er häufige, aber nicht sinntragende Wörter von der Indizierung ausschließt. Außerdem beherrscht die Datenbank Query-Expansion, kann also in Dokumenten suchen, die sie ihrerseits erst im Ergebnis einer Abfrage fand. Allerdings lässt die Query-Geschwindigkeit bei vielen Dateien stark zu wünschen übrig. Und da jedes Volltextdokument in die Datenbank wandert, nimmt diese bald gigantische Ausmaße an.
Auch das Perl-Modul »DBIx::FullTextSearch«, das einen eigenen Index definiert und MySQL als Backend verwendet, hat Macken. Die Indizierung ist recht langsam und sobald mehr als 30000 Dateien im Index sind, nimmt die Geschwindigkeit überproportional ab. Rummage setzt daher auf den bewährten Indizierer Swish-E [3], der rasend schnell arbeitet, nach Schlüsselworten und Phrasen sucht und problemlos skaliert.
Das Modul »SWISH::API::Common« vom CPAN erleichtert die Kommunikation mit Swish-E, indem es sich auf die am häufigsten genutzten Aspekte konzentriert. Allerdings kann Swish-E keine Dateien aus einem einmal erstellten Index löschen, sodass man am besten jeden Tag alles neu indiziert. Während eines nächtlichen Cronjobs schafft der Indizierer problemlos ein paar hunderttausend Dateien, das dürfte für den Hausgebrauch reichen. Zum Beispiel: »05 03 * * * LD_LIBRARY_PATH=/usr/local/lib /home/mschilli/bin/rummage -u -.v /dev/null 2>&1«
Nach dem ersten Indizierungslauf mit »rummage -u« (für Update) darf der Benutzer endlich auf die Metadaten und den Volltextindex zugreifen. Textdateien, die ein Schlüsselwort enthalten, zeigt der Befehl »rummage -k query« an (»-k« steht für Keyword). Der Kasten “Rummage-Kommandos” enthält Beispiele. Wie das Schema in Abbildung 1 zeigt, speichert die MySQL-Datenbank zu jeder Datei den vollständigen Pfad, die Größe in Bytes und die Zeitpunkte ihres ersten Auftauchens, des letzten Lesezugriffs und der letzten Modifikation.
Eine Datei »call.sgml«, die sich irgendwo versteckt in den Tiefen der indizierten Hierarchie befindet, ist per Pfad-Match mit »rummage -p call.sgml« zu finden. Aus »call.sgml« macht »rummage« intern das SQL-Pattern »%call.sgml%« und fragt die Tabelle »file« mit »WHERE path LIKE “%call.sgml%”« ab. Auch ein Teilpfad wie »Beispiele/call.sgml« funktioniert, dann entdeckt »rummage« die Datei nur, falls sie in einem Unterverzeichnis namens »Beispiele« liegt.
Die letzten 20 Dateien, die kürzlich modifiziert wurden, findet der Aufruf »rummage -n 20«. Ohne Angabe eines Integers kommen die Pfade der letzten zehn modifizierten Dateien zurück. Alle innerhalb der letzten Woche geänderten Dateien, zeigt der Aufruf »rummage -m \’7 day\’«. Er generiert eine MySQL-Abfrage der Form:
SELECT * FROM file WHERE DATE_SUB(NOW(), INTERVAL 7 DAY) <= mtime
MySQL rechnet hier für jeden Eintrag aus, ob das Änderungsdatum länger als sieben Tage zurückliegt. Bei Bedarf lässt sich die Anzahl Tage in dem Ausdruck auch gegen »3 month« oder »18 hour« austauschen. Das alles geht natürlich nicht in Echtzeit, sondern bezieht sich auf das letzte Update der Datenbank in der Nacht zuvor. Alles was danach geschah, ist für »rummage« unsichtbar.
Der erste Abschnitt in Listing 1 sollte an die individuellen Bedürfnisse angepasst werden. Die Konstante »$MAX_SIZE« bestimmt die maximale Länge des indizierten Inhalts einer Textdatei. So lässt sich beispielsweise von Logfiles nur der Anfang im Index berücksichtigen. Der Wert »100000« bestimmt in diesem Beispiel, dass das Tool nur die ersten 100 KByte indiziert.
Eine Zeile weiter nennt der Data Source Name »$DSN« dem DBI-Class-Modul den Datenbanktreiber und den Namen der Datenbank (»dts«). Schließlich ist »@DIRS« ein Array von Verzeichnisnamen, die »rummage« rekursiv durchstöbert. Gibt der Benutzer statt Verzeichnissen symbolische Links an, löst Zeile 17 diese auf. Wenn das Indizieren des Homeverzeichnisses zu lange dauert, ist die Beschränkung auf ein oder mehrere Unterverzeichnisse möglich, etwa auf einen lokalen CVS-Workspace.
|
Rummage-Kommandos |
|---|
|
Datenbank auffrischen oder generieren:rummage -u -v Schlüsselwortsuche nach »linux«:rummage -k \’linux\’ Phrasensuche: rummage -k \'”mike schilli”\’ »foo« und »bar« oder »baz« finden:rummage -k \’foo AND (bar OR baz)\’ Wildcard-Suche: rummage -k \’torvald*\’ Datei per Name oder Pfad aufstöbern:rummage -p Teilpfad Die letzten 20 modifizierten Dateien:rummage -n 20 Vergangene Woche modifizierte Dateien:rummage -m \’7 day\’ |
Unverzichtbarer Prototyp
Die Zeile 19 deklariert die Funktion »psearch()«, die später Suchergebnisse der verschiedenen Abfragen ausgibt. Dies geschieht mit Hilfe eines Prototyps, der festlegt, dass »psearch()« den ersten und einzigen Parameter als Skalar erwartet. Das ist wichtig, denn die Ausgabe der DBI::Class-Methoden »search()« oder »search_like()« an »psearch()« sollen in skalarem Kontext stehen, weil sie nur so einen Iterator zurückgeben, den »psearch()« auswertet.
Fiele der Prototyp weg, stünde die Methode »search()« in dem Ausdruck »psearch($db->search(…))« im Array-Kontext und damit gäbe die »search()«-Methode des Moduls DBI::Class nach ihrer Definition eine Liste von Treffern zurück und keinen Iterator.
»getopts()« analysiert die übergebenen Kommandozeilenparameter. Falls sich herausstellt, dass mit »-u« ein Update der Datenbank gefordert ist, schaltet Zeile 23 das Log4perl-Framework ein. Wurden mit »-v« (verbose) ausführliche Meldungen verlangt, wird der Level auf »$DEBUG« gesetzt, sonst kommen mit »$INFO« nur wichtige Meldungen durch. Die Logdatei wird mit jedem Lauf neu überschrieben, damit sie nicht auf Dauer die Platte füllt. Eine Alternative wäre eine Log4perl-Konfiguration mit »Log::Dispatch::FileRotate«.
In Zeile 29 ruft »db_init()« die gleichnamige Funktion in Zeile 144 auf, die die Datenbank mit der Tabelle »file« initialisiert, sofern noch nicht geschehen. Außerdem definiert sie einen Index auf die Spalte »path«, damit »rummage« später blitzschnell nachsehen kann, ob ein Eintrag für eine Datei schon existiert oder nicht und ob sich der Zeitstempel geändert hat. So kann der erste Suchlauf von »rummage« nach der Installation einige Zeit dauern. Darauf folgende Auffrischläufe gehen deutlich schneller.
Objektorientierte Abfragen
Aus dem Datenbankschema wiederum generiert »Class::DBI::Loader« in Zeile 31 die objektorientierte Repräsentation der Datenbank für Class::DBI. Unter dem Deckmantel der Klasse »Rummage::File« wird ab dann objektorientiert auf die Tabelle »file« zugegriffen. Liegt ein Ergebnis als Iterator vor, gibt es »psearch()« aus, das einfach so lange »->next()« aufruft, bis der Iterator keine Ergebnisobjekte mehr liefert.
Die Methode »path()« der Ergebnisobjekte kitzelt dort den Dateipfad jedes Treffers hervor, die Methode »mtime()« den letzten Modifikationszeitpunkt des Eintrags. Nicht alle Abfragen lassen sich bequem mit der Abstraktion von Class::DBI erledigen. Wird\’s zu kompliziert, kann man aber mit Class::DBI wieder auf die SQL-Ebene hinabsteigen.
Frisch in Schwung
Bekommt »rummage« den Parameter »-u« hereingereicht, verlangt der Benutzer danach, das Dateisystem mit File::Find zu durchstöbern und die Datenbank mit den neuesten Meta-Informationen aufzufrischen. Hierzu setzt der in Zeile 79 definierte »UPDATE«-Befehl zunächst die »checked«-Spaltenwerte aller Tabelleneinträge auf »0«. Findet die Stöberfunktion einen Eintrag im Dateisystem, gilt dieser als verifiziert und die »checked«-Spalte wird auf »1« gesetzt. Verbleiben nach dem Durchlauf einige Einträge mit »checked=0«, sind diese offensichtlich in der Zwischenzeit verschwunden und müssen aus der Datenbank und dem Index gelöscht werden.
Zeile 84 startet die Funktion »find()«, die in den angegebenen Verzeichnissen zu suchen beginnt und sich stetig durch die Dateihierarchie arbeitet. Für jeden gefundenen Eintrag ruft »find()« die ab Zeile 104 definierte Funktion »wanted()« auf, Zeile 106 weist alles, was nicht wie eine Datei aussieht, sofort zurück. Das Kommando »stat« in Zeile 112 ermittelt zusätzlich noch Größe und Zeitstempel der Datei.
Ist ein dem Pfad entsprechender Eintrag in der Datenbank vorhanden, prüft Zeile 120, ob der Zeitpunkt der letzten Modifikation mit dem in der Datenbank gespeicherten Wert übereinstimmt. Ist das nicht der Fall, frischen die Zeilen 124 bis 126 die Meta-Informationen (»mtime«, »atime«, »size«) des Eintrags auf. Falls die Datei noch nicht in der Datenbank steht, sorgt die »create«-Methode in Zeile 129 für einen neuen Eintrag.
MySQL erwartet für seine »DATETIME«-Felder das Datum im Format YYYY-MM-DD HH:MM:SS, doch Perls »stat«-Befehl liefert die Unix-Zeit in Sekunden. Das Modul Time::Piece::MySQL vom CPAN stellt die Methode »mysql_datetime« bereit. Die ab Zeile 188 in »rummage« definierte Funktion »mysqltime« kürzt den Aufruf ab.
|
Listing 1: Rummage |
|---|
001 #!/usr/bin/perl -w
002 use strict;
003
004 use Getopt::Std;
005 use File::Find;
006 use DBI;
007 use Class::DBI::Loader;
008 use Log::Log4perl qw(:easy);
009 use SWISH::API::Common;
010 use Time::Piece::MySQL;
011
012 my $MAX_SIZE = 100_000;
013 my $DSN = "dbi:mysql:dts";
014 my @DIRS = ("$ENV{HOME}");
015 my $COUNTER = 0;
016
017 @DIRS = map { -l $_ ? readlink $_ : $_ } @DIRS;
018
019 sub psearch($);
020 getopts("un:m:k:p:v", my %opts);
021
022 if($opts{u}) {
023 Log::Log4perl->easy_init({
024 level => $opts{v} ? $DEBUG : $INFO,
025 file => ">/tmp/rummage.log",
026 });
027 }
028
029 db_init($DSN);
030
031 my $loader = Class::DBI::Loader->new(
032 dsn => $DSN,
033 user => "root",
034 namespace => "Rummage",
035 );
036
037 my $filedb = $loader->find_class("file");
038
039 my $swish = SWISH::API::Common->new(
040 file_len_max => $MAX_SIZE,
041 atime_preserve => 1,
042 );
043 # Keyword search
044 if($opts{k}) {
045 my @docs = $swish->search($opts{k});
046 print $_->path(), "n" for @docs;
047
048 # Search by mtime
049 } elsif($opts{m}) {
050 $filedb->set_sql(modified => qq{
051 SELECT __ESSENTIAL__
052 FROM __TABLE__
053 WHERE DATE_SUB(NOW(),
054 INTERVAL $opts{m}) <= mtime
055 });
056 psearch($filedb->search_modified());
057
058 # Search by path
059 } elsif($opts{p}) {
060 psearch($filedb->search_like(
061 path => "%$opts{p}%"));
062
063 # Search newest
064 } elsif(exists $opts{n}) {
065 $opts{n} = 10 unless $opts{n};
066
067 $filedb->set_sql(newest => qq{
068 SELECT __ESSENTIAL__
069 FROM __TABLE__
070 ORDER BY mtime DESC
071 LIMIT $opts{n}
072 });
073
074 psearch($filedb->search_newest());
075
076 # Index Home Directory
077 } elsif($opts{u}) {
078 # Set all documents unchecked
079 $filedb->set_sql("uncheck_all", qq{
080 UPDATE __TABLE__
081 SET checked=0
082 });
083 $filedb->sql_uncheck_all()->execute();
084 find(&wanted, @DIRS);
085
086 # Update keyword index
087 $swish->index_remove();
088 $swish->index(@DIRS);
089
090 # Delete all dead documents in the DB
091 $filedb->set_sql("delete_dead", qq{
092 DELETE FROM __TABLE__
093 WHERE checked=0
094 });
095 $filedb->sql_delete_dead()->execute();
096
097 } else {
098 LOGDIE "usage: $0 [-u] [-v] [-n [N]] ",
099 "[-p pathlike] [-k keyword] ",
100 "[-m interval]";
101 }
102
103 ###########################################
104 sub wanted {
105 ###########################################
106 return unless -f;
107
108 DEBUG ++$COUNTER,
109 " $File::Find::name";
110
111 my($size,$atime,$mtime) =
112 (stat($_))[7,8,9];
113 $atime = mysqltime($atime);
114 $mtime = mysqltime($mtime);
115
116 my $entry;
117
118 if(($entry) = $filedb->search(
119 path => $File::Find::name)) {
120 if($entry->mtime() eq $mtime) {
121 DEBUG "$File::Find::name unchanged";
122 } else {
123 INFO "$File::Find::name changed";
124 $entry->mtime($mtime);
125 $entry->size($size);
126 $entry->atime($atime);
127 }
128 } else {
129 $entry = $filedb->create({
130 path => $File::Find::name,
131 mtime => $mtime,
132 atime => $atime,
133 size => $size,
134 first_seen => mysqltime(time()),
135 });
136 }
137
138 $entry->checked(1);
139 $entry->update();
140 return;
141 }
142
143 ###########################################
144 sub db_init {
145 ###########################################
146 my($dsn) = @_;
147
148 my $dbh = DBI->connect($dsn, "root",
149 "", { PrintError => 0 });
150
151 LOGDIE "Connecting to DB failed: ",
152 DBI::errstr unless $dbh;
153
154 if(! $dbh->do(q{select * from
155 file limit 1})) {
156 $dbh->do(q{
157 CREATE TABLE file (
158 fileid INTEGER
159 PRIMARY KEY
160 AUTO_INCREMENT,
161 path VARCHAR(255),
162 size INTEGER,
163 mtime DATETIME,
164 atime DATETIME,
165 first_seen DATETIME,
166 type VARCHAR(255),
167 checked INTEGER
168 )}) or LOGDIE "Cannot create table";
169
170 $dbh->do(q{
171 CREATE INDEX file_idx ON file (path)
172 });
173 }
174 }
175
176 ###########################################
177 sub psearch($) {
178 ###########################################
179 my($it) = @_;
180
181 while(my $doc = $it->next()) {
182 print $doc->path(),
183 " (", $doc->mtime(), ")", "n";
184 }
185 }
186
187 ###########################################
188 sub mysqltime {
189 ###########################################
190 my($time) = @_;
191 return Time::Piece
192 ->new($time)->mysql_datetime();
193 }
|
Speicherfresser
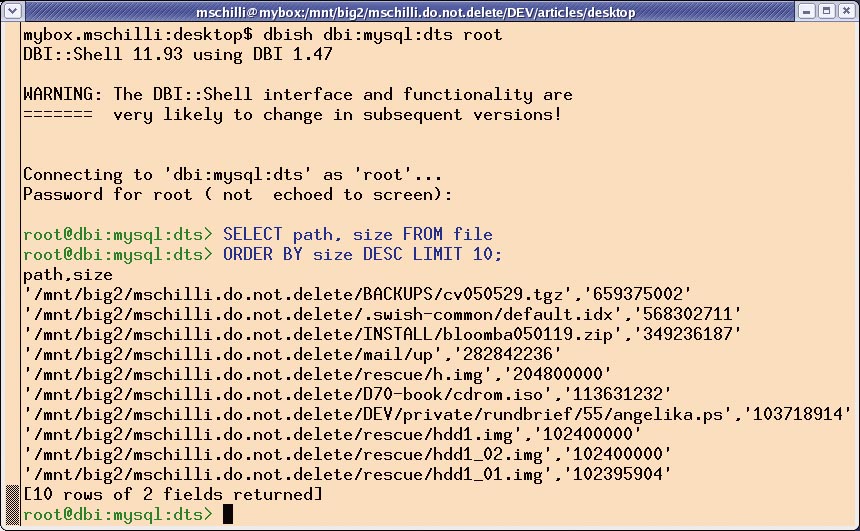
Rummage lässt sich noch erweitern. Mit den bereits eingespeisten Metadaten untersuchter Dateien kann der Benutzer mit dem Clientprogramm »mysql« schon herumspielen, bevor »rummage« mit weiteren DBI::Class-gestützten Abfragen intelligenter gemacht wird. Auch die DBI-Shell »dbish« vom CPAN leistet gute Dienste: Sie dockt an beliebige von DBI unterstützte Datenbanken an und erlaubt SQL-Abfragen. Sie wird mit dem Modul DBI::Shell installiert und für eine MySQL-Datenbank folgendermaßen aufgerufen: »dbish dbi:mysql:dts User Password«. Die SQL-Abfrage
SELECT path, size FROM file ORDER BY size DESC LIMIT 10;
nach den zehn größten Speicherfressern (Abbildung 2) holt diese Verschwender ans Tageslicht.
Die zehn ältesten Dateileichen, die schon seit Ewigkeiten nicht mehr ausgelesen wurden, identifiziert dieser SQL-Ausdruck:
SELECT path, atime FROM file ORDER BY atime ASC LIMIT 10;
Textdateien laufen allerdings täglich durch den Indizierer. Die letzte Access-Zeit einer Textdatei wäre folglich nie älter als einen Tag. Aus diesem Grund setzt der Konstruktor »SWISH::API::Common->new()« den Parameter »atime_preserve«, der das Modul zum Mogeln veranlasst. Nun setzt es den Zugriffsstempel jeder indizierten Datei nach dem Auslesen wieder auf den zunächst vorgefundenen Wert zurück.
Installation
Die Installation der notwendigen Perl-Module sollte ohne Schwierigkeiten zu schaffen sein. Das Anlegen der Datenbank »dts« in MySQL erledigt das Utility »mysqladmin« mit dem Befehl »mysqladmin –user=root create dts«. Die Tabellen erstellt »rummage« ohne Hilfe des Benutzers selbstständig.
Der Indizierer Swish-E und das Modul SWISH::API sind bei Swish-E.org erhältlich. SWISH::API::Common vom CPAN versucht alle beide automatisch zu installieren. Falls das nicht klappt, sollte sich der Benutzer Swish-E 2.4.3 oder neuer runterladen und mit »./configure; make install« installieren. Das Modul SWISH::API liegt der Distribution bei, die Befehlsfolge
cd perl LD_RUN_PATH=/usr/local/lib perl Makefile.PL make install
installiert die Swish-Schnittstelle auf dem Rechner. (jcb)
|
Infos |
|---|
|
[1] Listings zu diesem Artikel: [ftp://www.linux-magazin.de/pub/listings/magazin/2005/09/Perl] [2] Google Desktop Search: [http://desktop.google.com] [3] Michael Schilli, “Perlensuche”: https://www.linux-magazin.de/Artikel/ausgabe/2003/10/perl/perl.html] |
|
Der Autor |
|---|
|
|

Copyright © 2005 Linux New Media AG





