
© _Higuera, Fotolia
Rsync gleicht den Inhalt von fernen Files an den Stand auf der lokalen Maschine an. Der Clou dabei: Weicht das Derivat nur geringfügig vom Original ab, dann schont Rsync dank eines cleveren Verfahrens die Ressourcen und recycelt das vorhandene Datenmaterial.
Bandbreite sparen klingt altmodisch, ist es aber nicht – selbst bei einer flotten 16-GBit-Anbindung dauert es Stunden, mehrere DVD-Images einer Linux-Distribution zu laden. Besonders ärgerlich ist, wenn man die Betaversion schon hat und sich zur Final nur kleine Teile geändert haben. Wo es für Quelltexte vielleicht ein Patch gibt, wird\’s bei Binärdaten schon schwieriger. Binärpatch-Utilitys wie BS-Diff [4] und X-Delta [5] haben sich nicht durchgesetzt.
Patches leiden sowieso unter einer Einschränkung: Sie geben den Unterschied zweier vorgegebener Versionen wider [6]. Wer mehrere Zwischenstände überspringen will oder eine Kopie verändert, wird damit nicht glücklich, er braucht viele Patches oder scheitert anderweitig. Rsync [1] nimmt ihm die Sucherei ab und gleicht gar Files einander an, die nicht voneinander abstammen.
Rsync verteilt die Aufgabe sehr geschickt zwischen Client und Server. Der Empfänger einer Datei teilt dem Sender mit, was er schon hat, der Sender vergleicht das mit seinem Original-Datenbestand und schickt alles rüber, was dem Empfänger fehlt.
Nicht lange quatschen
Die Kunst bei dieser Aktion ist, den Kommunikationsaufwand klein zu halten. Beide Beteiligten wissen vorab nicht, wo sich Unterschiede und Gemeinsamkeiten befinden. Mag sein, dass die Files identisch sind oder dass einer Version Daten anhängen, die die andere Seite nicht hat. Häufig auch stimmen in Binärdaten zwar große Teile überein, aber die liegen an unterschiedlichen Positionen in der Datei. Einen Algorithmus, ein Protokoll und ein Tool, das die Gemeinsamkeiten nutzt, hat der Samba-Pionier Andrew Tridgell entwickelt und in seiner Doktorarbeit beschrieben (siehe Kasten “Entwicklungsziele”).
|
Entwicklungsziele |
|---|
|
Rsync-Erfinder und Samba-Entwickler Andrew Tridgell beschreibt in seiner Doktorarbeit [2] anschaulich, warum er Rsync entwickelt hat: Er war es leid, Quellcode-Änderungen mit dem Hauptarchiv abzugleichen, indem er Patches erstellte oder die kompletten Files durch seine Einwählverbindung quetschte. Er wollte ein Tool, das selbst herausfindet, was es senden muss und was nicht. Dafür formulierte er die Ziele:
Der drittletzte Punkt schont die CPU, der vorletzte spart Bandbreite und der letzte vermeidet bei hohen Netzwerk-Latenzen Wartezeit. |
Den genauen Ablauf bei der Kommunikation fasst [3] zusammen – und weist auch darauf hin, dass das Rsync-Protokoll keineswegs zu den Glanzstücken gehört. Der Algorithmus dafür umso mehr: Der Rsync-Empfänger teilt die vorhandene Zieldatei in Blöcke fester Größe auf (je nach Dateigröße), berechnet für jeden Block eine Prüfsumme und teilt nur diese Summen dem Sender mit. Der durchforstet seine eigene Datei und ermittelt, welchen der Blöcke er ebenfalls hat. Am Ende sendet er alle fehlenden Stellen zusammen mit Hinweisen, welche Blöcke der Empfänger an welcher Stelle wiederverwenden muss.
Die Aufgabe “Finde einen Abschnitt in der Datei, der eine bestimmte Prüfsumme besitzt, egal an welcher Stelle dieser Abschnitt liegt” bedeutet auf den ersten Blick sehr viel Rechnerei. Ein wenig geschickter Ansatz wäre es, sich für jede mögliche Position alle Bytes zu holen, um die komplette Summe zu berechnen (Abbildung 1).

Abbildung 1: Vorgegeben ist die Prüfsumme über einen Block fester Größe, unbekannt aber die Stelle des Blocks innerhalb einer Datei. Die langsamste Lösung berechnet die komplette Prüfsumme an jeder möglichen Stelle erneut.
Schiebung
Andrew Tridgell fand eine Möglichkeit, nicht jedes Mal die komplette Prüfsumme zu ermitteln. Bei jeder neuen Position ändern sich schließlich nur zwei Stellen im Block: einer fällt hinten raus und vorne kommt ein neuer dazu. Tridgells Algorithmus braucht für die Berechnung der nächsten Stelle nur den herausfallenden und den neu hinzukommenden Wert (Abbildung 2).
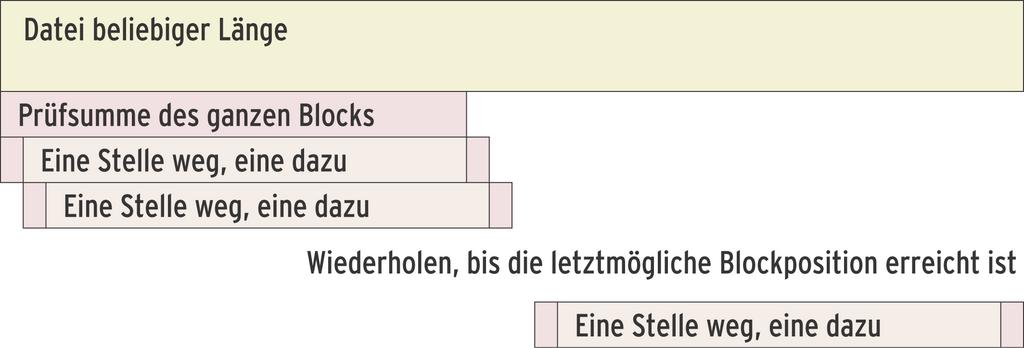
Abbildung 2: Die optimierte Version bestimmt ab der zweiten Position nicht mehr die komplette Summe, sondern zieht nur den Wert vor dem Block ab und rechnet den neu hinzugekommenen Wert ein.
Der 32-Bit-Wert seiner Prüfsumme teilt sich in zwei Hälften: 16 Bit berechnen sich als simple Modulo-216-Summe. Beim Verschieben addiert Rsync den neuen und subtrahiert den herausfallenden Wert. Dummerweise ergibt das gleiche Prüfsummen, wenn zwei Werte ihre Reihenfolge tauschen. Um auch die Byteposition mit einzubeziehen, multipliziert der zweite Teil des Prüfsummenwerts jede Stelle des Blocks mit ihrer Nummer innerhalb des Blocks, wobei die Nummern von hinten beginnen.
Beim zweiten Teil ist die Verschiebung auch verblüffend einfach berechenbar: Den wegfallenden Wert subtrahieren und danach das Ergebnis der ersten Hälfte addieren. In ihr stecken die addierten Werte aller Bytepositionen, womit sich der Faktor jeder Stelle um eins erhöht. Mit gerade mal zwei Additionen, zwei Subtraktionen und einer Multiplikation (für den wegfallenden Wert der zweiten Hälfte) sind beide Teile berechnet (Abbildung 3). Beim Vereinen fallen noch ein Shift- und ein Additionsschritt an.
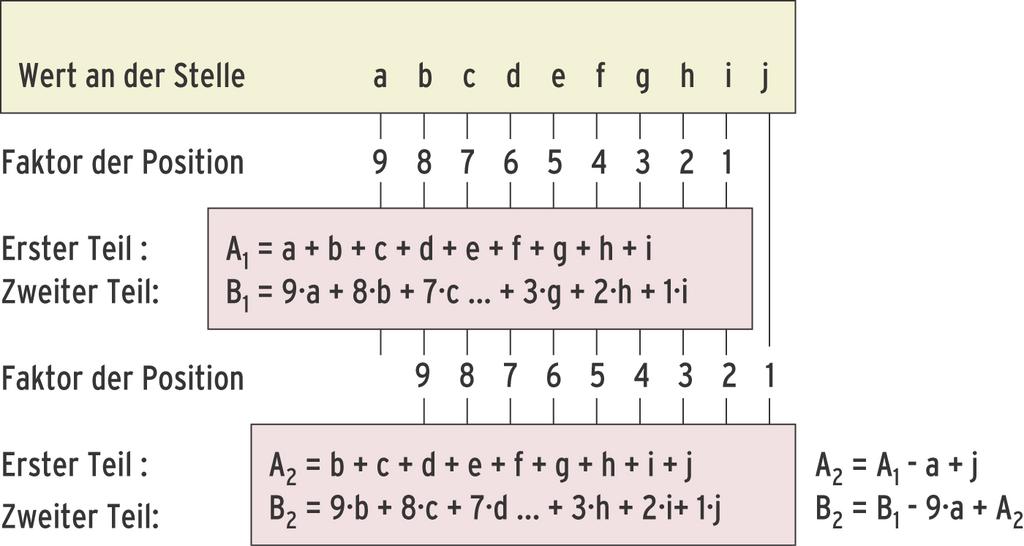
Abbildung 3: Dieser Algorithmus berechnet die rollierende Rsync-Prüfsumme. Er besteht aus zwei Teilen: Einer einfachen und einer gewichteten Summe, bei der jede Stelle mit einem Faktor multipliziert ist. Von einer Prüfsumme ausgehend berechnet sich die verschobene Summe wie rechts unten dargestellt.
Bist du zu schwach
So elegant die Schiebeberechnung sein mag, einen wirklich starken Hashwert ergeben sie nicht. Sprich: Es passiert zu leicht, dass zwei unterschiedliche Blöcke identische Prüfsummen erzeugen. Ein aus der Kryptographie stammender MD4-Algorithmus (Message Digest Nummer 4) mit 128 Bit ist in dieser Disziplin wesentlich besser. Rsync kombiniert kurzerhand beide Verfahren. Die Zielseite schickt dazu für jeden Block neben dem Rsync-eigenen Prüfwert zusätzlich eine starke MD4-Summe.
Die Quelle sucht anhand des Schiebeverfahrens nach möglichen Übereinstimmungen. Dabei rattert der Suchausschnitt byteweise durch die Zieldatei, das Programm berechnet die Prüfsumme für den aktuellen Bereich und vergleicht ihn mit der Tabelle der in der Zieldatei vorhandenen Blöcke. Gibt es eine Übereinstimmung, dann kommt die rechenintensive MD4-Prüfung an die Reihe: Der Sender bestimmt auch diesen Wert und nur wenn er ebenfalls übereinstimmt, hat Rsync einen Block der Zieldatei wiedergefunden.
Der Rest
Wann immer der Sender einen Block entdeckt, informiert er den Empfänger darüber. Er sendet alle Daten, die vor dem gefundenen Block liegen, in komprimierter Form und sagt, welchen Block der Empfänger daran anhängen soll. Am Ende hat der Empfänger eine exakte Kopie der Datei.
In machen Fällen kürzt Rsync sogar heftig ab: In der Defaultkonfiguration reicht es, wenn Dateigröße und Änderungsdatum übereinstimmen, dann verzichtet das Tool auf jeden weiteren Vergleich dieser Datei. Die Option »–checksum« führt einen weiteren Schnelltest durch, der mehr Sicherheit gibt, dass die Dateien wirklich identisch sind.
Derzeit arbeiten die Entwickler an Rsync 3.0.0. Neben vielen neuen Features gehören auch weitere Optimierungen dazu, sodass Rsync künftig noch schneller und mit weniger Speicherbedarf es schafft, Dateien über das Netz abzugleichen.
|
Infos |
|---|
|
[1] Rsync: [http://samba.org/rsync/] [2] Andrew Tridgell, “Efficient Algorithms for Sorting and Synchronization”: [http://samba.org/~tridge/phd_thesis.pdf] [3] How Rsync Works: [http://samba.org/rsync/how-rsync-works.html] [4] Binär-Diff und -Patch: [http://www.daemonology.net/bsdiff/] [5] X-Delta: [http://xdelta.org] [6] Andreas Romeyke, “Der feine Unterschied – Algorithmen hinter Diff”: Linux-Magazin 01/07, S. 106 |





