
© Peter Mueller, sxc.hu
So richtig kam das semantische Web bisher nicht in die Gänge. Das Simile-Projekt versucht es anzuschieben und bietet dafür eine ganze Reihe Software-Tools, die bestehende Websites mit semantischen Informationen anreichern. Vollautomatisch geht es aber nicht.
Wie dumm das gewohnte Web ist, zeigt sich oft schon bei der einfachen Google-Suche. Wer mit Hilfe der Suchmaschine zum Beispiel ein Linux-Problem lösen will, stößt zwar meist auf Leidensgenossen, findet aber nicht unbedingt eine Antwort. Das liegt daran, dass Google nur das Auftreten der Schlüsselwörter vergleicht, mit denen der Anwender bei der Suche sein Problem umreißt.
Die Google-Logik analysiert weder die Struktur einer Forumskonversation (ein Frage-Antwort-Schema) noch die Dokumentenstruktur. Letzteres führt zum Beispiel auch dazu, dass eine Suche nach »Linux Schlüsselwort« zu Artikeln verzweigt, die mit Linux gar nichts zu tun haben, nur weil auf dem entsprechenden Portal in der Seitenleiste immer der Menüpunkt »Linux« steht.
Nur in Ansätzen macht Google etwas, was man als Sprachanalyse bezeichnen kann. Mit Hilfe statistischer Methoden, so genannter N-Gramme, kann Google falsch geschriebene Wörter oder Phrasen korrigieren. Es ist jedoch nicht in der Lage, die Bedeutung gesuchter Wörter zu erkennen. Für Google gibt es keinen Unterschied zwischen der Bank als Zahlungsinstitut und der Bank als Sitzgelegenheit. Angesichts der Komplexität der menschlichen Sprachen ist es im Übrigen fraglich, ob Computer dazu jemals in der Lage sein werden.
Bessere Informationen
Mit solchen Problemen wollte und will sich eine Entwicklergemeinde des Web nicht zufrieden geben, die sich unter dem Schlagwort “Semantic Web” versammelt. Eine ganzer Reihe großer Namen, darunter nicht zuletzt der Web-Vater Tim Berners-Lee, will Daten im Web mit Meta-Informationen anreichern, um ihre maschinelle Verarbeitung intelligenter und damit für Menschen nützlicher zu machen [1].
Einerseits sollen die Metadaten die Beschaffenheit der dargestellten Daten näher spezifizieren, andererseits sollen so genannte Taxonomien oder Ontologien ein gemeinsames Weltbild festlegen, mit dessen Hilfe der Computer weitere Schlüsse zieht. So kann eine Seite, die einen Autotyp näher beschreibt, die semantische Information “Auto” enthalten. Ist in der entsprechenden Ontologie ein Auto ein bestimmter Typ eines Fahrzeugs, kann auch eine semantische Suche nach “Fahrzeug” die beschriebene Automobil-Seite finden.
Richtig durchsetzen konnten sich die Techniken des semantischen Web bisher nicht. Das liegt unter anderem an dem langsamen Standardisierungsprozess des W3-Konsortiums, aber auch an der Vielzahl unterschiedlicher Normen und in der Praxis verwendeten Technologien. Am weitesten verbreitet ist wohl das Resource Description Format RDF, das in geringem Umfang bei den beliebten RSS-Newsfeeds zum Einsatz kommt [2]. Allerdings basieren nicht alle RSS-Formatversionen auf RDF.
Mikroformate
Mit dem Einsatz der Seitenbeschreibungssprache HTML beschränkt sich das Web gegenwärtig auf die Repräsentation der Textoberfläche, also die Darstellungsebene. Egal ob es sich um eine Liste von Personen oder eine Liste von Autos handelt, die entsprechenden Tags im HTML-Markup sind die gleichen, zum Beispiel »li«, »div« oder »td«. Die im Umfeld von Web 2.0 in letzter Zeit viel diskutierten Mikroformate versuchen in das HTML-Web etwas Semantik einzuführen, indem sie Meta-Informationen in das Klassenattribut von HTML-Elementen eintragen, zum Beispiel:
<div class="Strasse">Süskindstraße</div>
Wie leicht vorstellbar ist, geht das eher mit sehr minimalistischem Markup als mit Seiten, die ihre Informationen übermäßig auszeichnen. Entsprechend sind die Hauptanwendungen für Mikroformate derzeit Kalendereinträge und elektronische Visitenkarten.
Was die zugrunde liegende Ontologie oder Taxonomie betrifft, sorgen die so genannten Folksonomies zumindest bei einzelnen Sites für Einheitlichkeit. Benutzer heften dabei ihren Onlinedaten, zum Beispiel den Fotos bei Flickr.com, mehrere Schlüsselwörter an, die im Fachjargon ebenfalls Tags heißen. Durch Server-seitige Speicherung und Ajax-Techniken können Benutzer nicht nur immer neue Tags vergeben, sondern auch auf den Bestand bereits vergebener Schlüsselwörter zurückgreifen.
Mikroformate und Folksonomies werden von einigen schon als semantisches Web von unten bezeichnet, weil sie einige Probleme des semantischen Web gewissermaßen ad hoc zu lösen versuchen. Auch die Vertreter der reinen Lehre setzen nicht unbedingt auf Ontologien, die von Standardisierungsgremien konstruiert werden, sondern sehen in den Folksonomies durchaus Potenzial. Das Web 2.0 lässt sich deshalb als Übergangsphase verstehen, das sukzessive mehr semantische Techniken integriert.
Web-Recycling
Soll sich das semantische Web im großen Stil durchsetzen, müssen Webmaster nicht nur neue Sites mit passenden Meta-Informationen versehen. Es stellt sich natürlich auch die Frage, was mit den Milliarden von bestehenden Seiten passieren soll, die keine solchen Informationen enthalten. Ein Projekt am Massachusetts Institute of Technology (MIT) hat es sich deshalb zum Ziel gesetzt, Softwarewerkzeuge zu entwickeln, die den Übergang erleichtern.
Unter dem Namen Simile (Semantic Interoperability of Metadata In unlike Environments) ist eine ganze Reihe von Tools entstanden, die konventionelle Webseiten verarbeiten, sie mit semantischen Informationen im RDF-Format anreichern und lokal oder auf einem Server speichern [3]. Einen Überblick über bestehende Projekte gibt Tabelle 1. Kernstück der Tool-Sammlung ist die Firefox-Extension Piggybank (Sparschwein), welche die Kluft zwischen alt und neu überbrücken soll.
|
Tabelle 1: |
|
|---|---|
|
Tool |
Aufgabe |
|
Piggybank |
Firefox-Extension, die Ergebnisse von Xpath-Abfragen lokal |
|
Solvent |
Hilfs-Extension für Piggybank zum Screenscrapen |
|
Semantic Bank |
Server, der Piggybank-Informationen für mehrere Benutzer |
|
Welkin |
RDF-Graf-Visualisierung |
|
Longwell |
Faceted Browser für RDF-Daten |
|
Gadget |
Inspektor für große XML-Datensätze |
|
Referee |
Metadaten-Extraktor und Referrer-Crawler für Logfiles |
|
Exhibit |
Erzeugt automatisch HTML-Seiten aus einer Datenbasis |
|
Babel |
Format-Übersetzer, zum Beispiel von JSON ins |
|
Fresnel |
Vokabular zur RDF-Anzeige |
|
Httptracer |
Sniffer für HTTP-Traffic |
|
Timeline |
DHTML-Widget, das Daten chronologisch anordnet |
|
Rdfizer |
Sammlung von Tools zur RDF-Konvertierung |
Statt einen allein stehenden Browser für das semantische Web hat das Simile-Team einen Mittelweg gewählt, der durch die Integration in den Firefox-Browser auch die Nutzung existierender Websites erlaubt. Die Extension lässt sich einfach durch Anklicken des entsprechenden Links auf der Piggybank-Website installieren, setzt aber das Vorhandensein des Java-Plugin voraus.
Im Test funktionierte Piggybank weder mit den Plugins aus dem JDK 1.4.2, noch mit dem ganz neuen JDK 1.6.0, sondern nur mit JDK 1.5.0. Zum Aktivieren des mit dem JDK installierten Java-Plugin ist ein symbolischer Link im systemweiten Plugin-Verzeichnis oder dem des Benutzers nötig:
cd $HOME/.mozilla/plugins ln -s /usr/java/jdk1.5.0_11/jre/plugin/i386/ns7/libjavaplugin_oji.so
Funktioniert etwas nicht, bekommt der Benutzer von Firefox leider wenig Hilfe. Der Browser startet das Simile-Plugin dann einfach nicht. Eventuell hilft es, den Browser mit »firefox -P development« im Entwickler-Modus zu starten.
Klappt alles, taucht an der unteren Fensterleiste rechts ein neuer Button auf, oben neben der Location-Bar erscheint ein kleines Schweinchen, das den Piggybank-Browser startet. Bei der ersten Benutzung ist die lokale Datenbank noch leer. Über den neuen Menüpunkt »Extras | Piggybank | Collect and Browse« lässt sie sich füllen. Die Extension sucht damit auf der aktuellen Seite nach RDF-Ressourcen und speichert sie gegebenenfalls lokal ab.
Handelt es sich um eine Website ohne solche semantischen Informationen, greift Piggybank auf einen so genannten Screenscraper zurück, der die Daten bildlich gesprochen von der Bildschirmoberfläche kratzt. Solche Screenscraper müssen für jede Website neu geschrieben werden, da sie stark von der jeweiligen Dokumentstruktur abhängen.
Infos abkratzen
Piggybank bringt drei fertige Scraper mit, einige weitere finden sich auf der Website. In den meisten Fällen bleibt es aber dem Benutzer überlassen, für seine spezifische Anwendung einen eigenen zu schreiben. Sonst zeigt Piggybank nur die wenigen Informationen an, die es auf Standard-Webseiten automatisch erkennt, zum Beispiel URL und Titel (Abbildung 1).
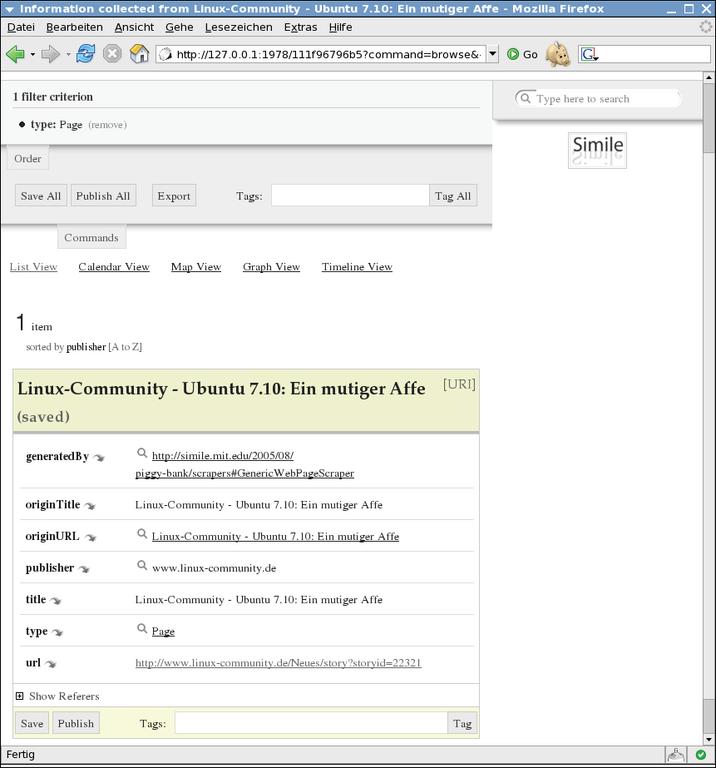
Abbildung 1: Ohne Screenscraper findet Piggybank auf HTML-Seiten nur einige wenige Informationen wie URL und Titel.
Als Hilfe zum Selberschreiben von Screenscrapern bietet Simile eine weitere Firefox-Extension namens Solvent an, die diesen Prozess etwas vereinfacht. Nach erfolgreicher Installation ist sie über ein weiteres Icon am unteren rechten Fensterrand, das aussieht wie eine Spraydose, erreichbar. Beim Anklicken zeigt Firefox im Bereich der aktuell geöffneten Seite zwei zusätzliche Fenster (Abbildung 2).
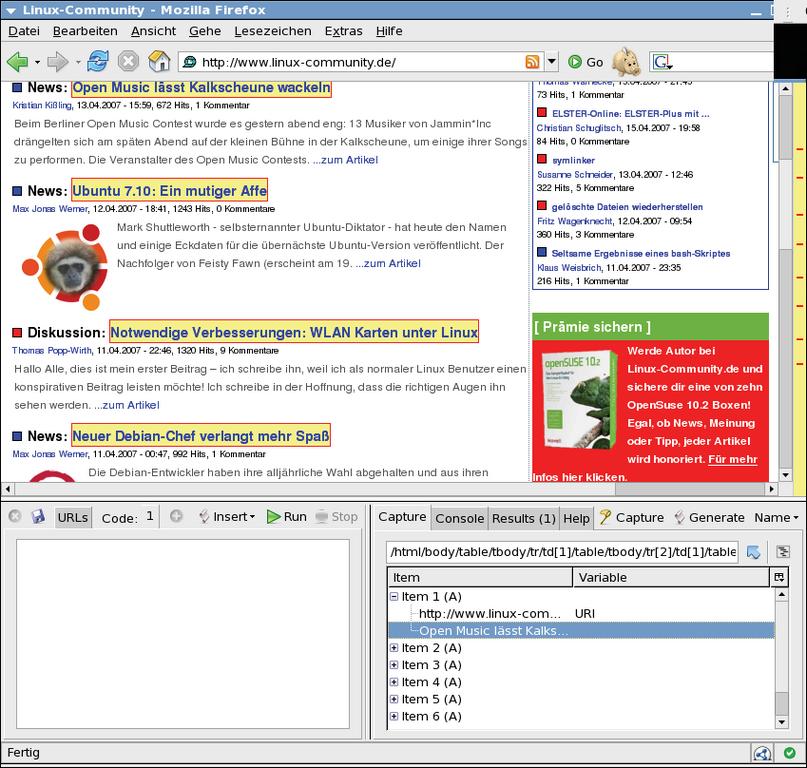
Abbildung 2: Die Firefox-Extension Solvent hilft dem Benutzer beim Schreiben eigener Screenscraper für Piggybank. Die gelb unterlegten Seitenelemente erfüllen den gleichen Xpath-Ausdruck.
Um Informationen von einer Website zu schaben, klickt der Anwender zunächst auf den Button »Capture«, woraufhin der Cursor sich in eine Hand verwandelt. Mit ihr klickt er anschließend die ihn interessierenden HTML-Elemente an, die Solvent gelb unterlegt, sobald sich der Cursor darüber bewegt.
Beim Anklicken sucht die Extension selbstständig weitere Elemente der Seite, die dem gewählten Xpath-Ausdruck entsprechen, der in der oberen Zeile des rechten Fensters zu sehen ist (Abbildung 2: »/html/body/table/…«). Gleichzeitig zeigt Solvent die ausgewählten Elemente in der unteren Fensterhälfte an. Der blaue Pfeil rechts neben dem Xpath-Ausdruck aktiviert Elemente der nächsten darüber liegenden Ebene.
Hat der Anwender die gewünschten Seitenelemente identifiziert, muss er semantische Informationen hinzufügen, die im HTML-Code naturgemäß fehlen. Dazu klappt er zuerst eins der gefundenen Items aus und benutzt dann den Button »Name«. Hinter ihm verbergen sich ein paar voreingestellte semantische Markups, er darf aber auch eigene Auszeichnungen definieren. Im vorliegenden Fall wählt er zum Beispiel für die URL das Element »URI«, für den Titel entsprechend »Title«.
Eigene Tags lassen sich über das Menü vergeben, ihre Namen sollten standardkonform eine URL enthalten. Die meisten voreingestellten Tags bezieht Simile aus dem Dublin Core, der eine Taxonomie implementiert, die zum Beispiel auch das Open-Office-Format ODF für seine Metadaten verwendet. Der Dublin Core trägt das URL-Präfix »http://purl.org/dc/elements/1.1/«.
Scraper-Code
Nur selten lässt sich der automatisch erzeugte Scraper ohne weiteres Zutun verwenden. Es sind meist zumindest noch Anpassungen von Elementnamen im Code nötig. Bei kompliziert aufgebauten Seiten genügen manchmal die Xpath-Ausdrücke auch nicht, um die gewünschten Informationen zu extrahieren. Hier muss der Anwender gelegentlich sogar selbst noch HTML mit eigenem Javascript weiterverarbeiten.
Wer so die Seitenelemente und ihre Metadaten eingestellt hat, kann mit dem Button »Generate« den Scraper-Code erzeugen, den Solvent im linken Fenster darstellt. Ein weiterer Klick auf »Run« startet den Scraper für die aktuell geöffnete Seite und zeigt wiederum rechts das Ergebnis im RDF-Format. Der Button »Show Results in Piggybank« stellt das Ergebnis im Piggybank-Browser (Abbildung 3) dar. Dort kann der Benutzer zum Beispiel auch noch Tags zur Information hinzufügen und seine Daten lokal speichern.
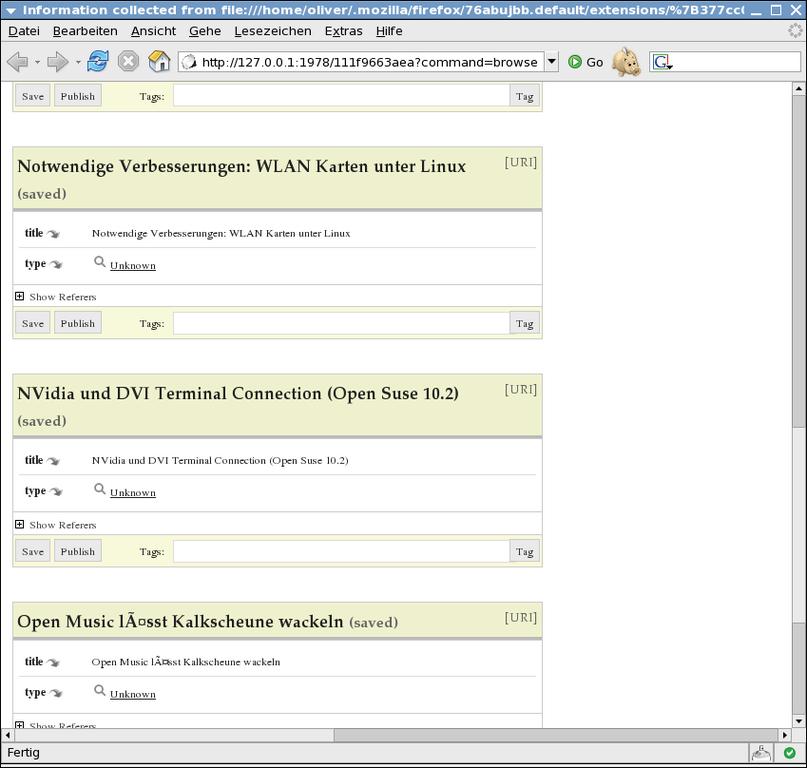
Abbildung 3: Piggybank zeigt als Firefox-Extension die Informationen, die Solvent von einer Webseite extrahiert und die der Benutzer mit semantischem Markup angereichert hat.
Code selbst schreiben
Um einer Gruppe von Benutzern die gemeinsame Arbeit an einem Datenbestand zu ermöglichen, gibt es vom Simile-Projekt einen Server namens Bank, auf dem Piggybank seine Informationen speichert. Weitere Simile-Tools erlauben zum Beispiel das Screenscrapen auf der Kommandozeile, wandeln die gewonnenen RDF-Daten in andere Formate um und zeigen sie geordnet an.
Auch die Tools, die das Simile-Projekt anbietet, können aus dem dummen alten Web nicht selbstständig und automatisch ein semantisches Web zaubern. Dafür sind die Websites zu unterschiedlich strukturiert. Schon bei den Screenscrapern geht es ohne Kenntnisse von Xpath und Javascript kaum, reines Klicken führt bei komplex aufgebauten Seiten kaum weiter. Die Vielzahl der Tools erlaubt jedoch ein Experimentieren mit semantischen Technologien, ohne von Hand RDF schreiben zu müssen. Zumindest für sehr populäre Sites werden aber wohl im Lauf der Zeit fertige Screenscraper entstehen, die dann jeder einfach wiederverwenden kann.
|
Infos |
|---|
|
[1] Tim Berners-Lee u.a., “The Semantic Web”: [http://www.sciam.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21&catID=2] [2] Resource Description Format: [http://www.w3.org/RDF] [3] Simile: [http://simile.mit.edu] |





