
gamboo, photocase.com
Mit dem Ende des Rennens um immer höhere CPU-Taktraten ist auch die automatische Beschleunigung von Programmen Geschichte. Jetzt müssen Entwickler ihre Software von Hand anpassen, damit sie von Mehrkernprozessoren profitieren. OpenMP macht den Einstieg einfach.
Bei allen Unterschieden verfolgen die CPU-Hersteller heute eine gemeinsame Strategie: Statt eines einzelnen Rechenkerns integrieren sie zwei oder mehr auf einem Chip. Damit führt eine Verdopplung der Leistung nicht mehr zu einer Vervierfachung der Abwärme. Extreme Beispiele für diese Entwicklung sind der Cell-Chip von IBM, der unter anderem in Sonys Playstation 3 steckt, der Niagara-Prozessor von Sun oder der von Intel gezeigte Experimental-Chip Polaris mit 80 Kernen in einer CPU.
Multicore statt MHz
Mit Einführung dieser so genannten Multicore-CPUs wird plötzlich auch für Programmierer von Desktop-Produkten ein Thema interessant, das zuvor fast ausschließlich bei numerischen Simulationen auf Clustern zur Anwendung kam: das Entwickeln paralleler Programme. Die simple Frage, wie sich in einem Programm mehrere CPUs gleichzeitig nutzen lassen, öffnet eine der Pandora würdige Büchse mit vollkommen neuen und unerwarteten Problemen: Im seriellen Ablauf korrekte Programme verhalten sich auf paralleler Hardware oft unvorhergesehen.
Während es noch relativ einfach ist, auf einem Server mehrere Programme gleichzeitig auszuführen und damit die vorhandenen CPUs auszulasten, ist dies für ein einzelnes Programm schwieriger. Zunächst sollte man sich darüber Gedanken machen, ob und wie es möglich ist, die zu erledigende Arbeit aufzuteilen. Als Analogie kann der Bau eines Hauses dienen: Mehrere Maurer beginnen parallel damit, die Wände zu errichten. Sobald sie fertig sind, können Dachdecker, Installateur und Elektriker gleichzeitig und parallel ihre Aufgaben tun. Am Ende ist es dann wieder möglich, mehrere Maler parallel zu beschäftigen.
Im ersten und dritten Bauabschnitt (Wände errichten beziehungsweise malen) spricht man vom Aufteilen der Daten (Data-based Parallelism), der zweite Abschnitt ist typisch für ein Aufteilen in unterschiedliche Aufgaben (Task-based Parallelism). In der IT entspricht das Aufteilen der Daten meist dem Teilen einer großen Schleife, während einzelne Funktionen, die parallel zur Ausführung kommen, die verschiedenen Aufgaben übernehmen. In beiden Fällen hat der Entwickler dafür zu sorgen, dass das Programm weiterhin korrekte Ergebnisse liefert, dass alle CPUs gleichmäßig belastet werden und dass möglichst alle Programmbereiche parallelisiert sind.
Amdahls Gesetz
Angenommen, von einem Programm mit einer Laufzeit von zehn Minuten sind 80 Prozent parallelisiert und es skaliert mit zunehmender CPU-Zahl. Auf vier Prozessoren nimmt dieser Programmteil also zwei Minuten (8 min/4) in Anspruch, der immer noch serielle Teil weiterhin zwei Minuten. Die gesamte Laufzeit beträgt also vier Minuten, das entspricht einer Beschleunigung um den Faktor 2,5 (10 min/4 min), obwohl sich mancher Anwender bei vier CPUs einen Speedup von vier erhofft.
Dieser Zusammenhang ist unter dem Namen Amdahls Gesetz bekannt. Die Effizienz (Speedup/Anzahl CPUs) beträgt im letzten Fall nur 2,5/4 = 62,5 Prozent. Das Verhältnis wird ungünstiger, wenn noch mehr CPUs zum Einsatz kommen. Die Laufzeit des Programms wird immer mehr von den zwei Minuten des seriellen Anteils geprägt, der höchste erreichbare Beschleunigungsfaktor beträgt damit also 10 min/2 min = 5.
In den vergangenen Jahren erwiesen sich mehrere Ansätze zur Entwicklung paralleler Programme als erfolgreich. Ausgehend von Unix-Systemen mit mehreren CPUs setzte sich der aufgabenzentrierte Ansatz über Posix-Threads durch. Das gleiche Konzept funktioniert, allerdings mit einem veränderten API, auch unter MS Windows. Obwohl beide Herangehensweisen sich ähneln, sind die Unterschiede doch so groß, dass ein C-Programm zweimal entwickelt werden muss, um auf beiden Plattformen zum Einsatz zu gelangen. Skript-basierte Sprachen wie Python kapseln für den Benutzer diese Unterschiede weitgehend und machen so Thread-basierte Anwendungen leichter programmierbar.
Für Cluster: MPI
Ein ganz anderer Ansatz aus dem Bereich der auf einem Cluster verteilten Daten führte zur Entwicklung von MPI, dem Message Passing Interface. In der Regel startet dasselbe Binary gleichzeitig auf mehreren Computern. Anhand einer vom MPI vergebenen ID entscheidet jedes Programm, welche Aufgabe es übernehmen soll. Die Kommunikation zwischen den einzelnen Prozessen läuft über den Austausch von Nachrichten. Ein existierendes serielles Programm muss aber komplett umstrukturiert werden, um mehrere CPUs zu nutzen.
Etwa 1990 begannen mäßig parallele Systeme sich in kommerziell wirksamen Stückzahlen zu verbreiten. Diese Maschinen mit vier bis 16 CPUs wurden vor allem im Bereich der numerischen Simulation als einfacher Weg gesehen, bestehenden seriellen Fortran-Code, der teilweise über Jahre und Jahrzehnte gewachsen war (so genannten Legacy Code), zu beschleunigen und den gewachsenen Ansprüchen anzupassen. Aus diesem Grund fanden sich einige Hardwarehersteller in einem Konsortium zusammen und legten mit Erweiterungen für Fortran und C den Grundstein für OpenMP. Dabei waren die Randbedingungen:
- Einfache Schnittstelle
- Erlaubt eine stufenweise Parallelisierung während der
Entwicklung - Leistungsfähig
- Herstellerübergreifend
- Zielgruppe sind Entwickler numerischer Simulationen
- Serieller Code muss weitgehend unangetastet bleiben
Daher wurden OpenMP-Erweiterungen als Compiler-Pragmas realisiert. Dieses Verfahren bewirkt, dass Compiler, die OpenMP nicht verstehen, die zusätzlichen Anweisungen als Kommentare auffassen und der Code damit rein seriell kompilierbar bleibt. Der Hauptanwendungsbereich der numerischen Simulation führte dazu, dass sich die Spezifikation vor allem auf die Parallelisierung von Schleifen konzentriert.
Der komplette Standard kommt auf gut 100 Seiten Umfang und findet sich unter [1]. Die Spezifikation umfasst heute C/C++ und Fortran. Die Implementierung bleibt jedem Hersteller überlassen, basiert in der Regel jedoch auf den vorhandenen Thread-Bibliotheken. OpenMP verbirgt auf diese Weise die Systemabhängigkeiten der Thread-Programmierung vor dem Anwender.
Compiler-Schalter
Listing 1 zeigt ein erstes kurzes Beispiel für die Anwendung von OpenMP. Die Anweisung »#pragma omp parallel« reicht bereits aus, um das serielle Programm zu parallelisieren. Je nach eingesetztem Compiler ist es eventuell notwendig, beim Kompilieren zusätzliche Schalter anzugeben. Der Intel-Compiler benötigt zum Beispiel zusätzlich »-openmp« (unter Windows: »/Qopenmp«): »icc -openmp -o hello_omp hello_omp.c«. Andernfalls weist der ICC durch eine Fehlermeldung darauf hin, dass die Pragma-Anweisung unbekannt ist und er sie deshalb ignoriert. Beim Gnu-Compiler [2] heißt der entsprechende Schalter »-fopenmp«:
gcc -fopenmp -o hello_omp hello_omp.c
Die Gnu-Compiler unstützen OpenMP ab Version 4.2, zum Beispiel in der aktuellen Fedora-Distribution.
Bei der Ausführung nimmt ein Open-MP-Programm die Anzahl der gleichzeitig und parallel in Hardware ausführbaren Threads als Maß, um zu entscheiden, wie viele Software-Threads es startet. Ein System mit einem Quadcore-Chip entspricht dabei einem System mit vier CPUs. Der Anwender kann dieses Verhalten durch Setzen der Umgebungs-Variablen »OMP_NUM_THREADS« beeinflussen und so auch auf einem System mit nur einer CPU Open-MP-Programme entwickeln, mit mehreren Threads starten und damit das parallele Verhalten testen. Viele bei echten Parallelsystemen mögliche Laufzeitfehler treten dabei natürlich nicht auf.
|
Listing 1: Einfaches |
|---|
01 #include <stdio.h>
02
03 main()
04 {
05 #pragma omp parallel
06 {
07 printf("Hello Worldn");
08 }
09 }
|
Library schafft Abhängigkeiten
Bei einem Start des simplen Beispiels »hello_omp« führt jeder Thread genau dieselben Befehle aus und gibt den Einzeiler »Hello World« aus. Dies demonstriert Listing 2 noch eindringlicher. Hier ermitteln zwei Funktionen der OpenMP-Laufzeitbibliothek sowohl die Anzahl der gestarteten Threads als auch die Thread-ID und geben sie aus.
|
Listing 2: Thread-ID und |
|---|
01 #include <omp.h>
02 main()
03 {
04 #pragma omp parallel
05 {
06 printf("Hello World from process %d out of %dn",
07 omp_get_thread_num(),omp_get_num_threads());
08 }
09 }
|
Das OpenMP-API bietet auch Möglichkeiten, um die Anzahl der Threads zu kontrollieren sowie explizite Locks zu verwenden. Der Einsatz der entsprechenden Library verhindert allerdings – im Gegensatz zu den Pragmas -, dass sich das Programm mit einem Compiler ohne OpenMP-Support kompilieren lässt. Um die Arbeit auf mehrere Threads zu verteilen, bietet OpenMP die Konstrukte »for« und »sections«.
Wie erwähnt liegt der Anlass für die Entwicklung von OpenMP in der numerischen Simulation. Dabei läuft häufig eine Berechnung innerhalb einer Schleife wieder und wieder ab, meistens um Werte innerhalb eines Array zu berechnen. Ein einfaches Beispiel soll das Prinzip demonstrieren. Der serielle Code findet sich in Listing 3. Dieses Beispiel berechnet Werte eines Array und überprüft gleichzeitig, wie viele dieser Werte größer als 0,5 sind. In der Schleife über »i« (Zeile 8) sind die einzelnen Berechnungen unabhängig voneinander – man kann zwei Läufe durchführen, ohne dass das Ergebnis eines Laufs einen Einfluss auf den anderen hat.
|
Listing 3: Numerische |
|---|
01 #define SIZE 30000
02
03 void Calculate()
04 {
05 int generalProgress=0,i,j,percentDone, found=0,procid;
06 static double X[SIZE];
07
08 for( i = 0; i <= SIZE; i ++ )
09 {
10 X[i] = sqrt(exp(cos(i))*exp(sin(i)));
11 for(j=1;j<i;j++)
12 X[i] *= sqrt(exp(cos(j))*exp(sin(i)));
13
14 if( X[i] > 0.5)
15 found ++;
16 generalProgress++;
17 percentDone = (int)((float)generalProgress/(float)SIZE *100.0 + 0.5);
18
19 if( percentDone % 10 == 0 )
20 printf("nbbbb%3d%%", percentDone);
21 }
22 printf("nfound %dn",found);
23 }
|
Abhängige Variable
Das ist bei der »j«-Schleife (Zeile 11) nicht der Fall: Zur Berechnung der Iteration »j + 1« muss stets das Ergebnis des Durchlaufs »j« vorliegen. Abhängigkeiten wie diese (Forward Data Dependency oder Recurrence) verhindern, dass die Parallelisierung einer Schleife ohne komplette Restrukturierung möglich ist. Der Programmierer sollte in einem solchen Fall überprüfen, ob – wie hier – eine äußere oder innere Schleife Abhängigkeiten enthält. In diesem Fall sieht die erste Open-MP-Schleife so aus:
#pragma omp parallel
{
#pragma omp for
for( i = 0; i <= SIZE; i ++ )
}
Oder in Kurzform:
#pragma omp parallel for for( i = 0; i <= SIZE; i ++ )
Das reicht aus, um die Schleife parallel in mehreren Threads rechnen zu lassen. Der Iterationsbereich wird einfach zwischen den Threads aufgeteilt. In diesem Fall – bei einer Iteration von 1 bis 20000 und acht Threads – berechnet der erste Thread die Schleife von 0 bis 2500, der zweite von 2501 bis 5000 und so fort.
Private und geteilte Daten
Der Programmierer sollte auch einen Blick auf die verwendeten Variablen werfen. Wie alle Thread-basierten Ansätze teilt OpenMP die Variablen in die beiden Gruppen Private und Shared. Private bedeutet, dass nur der Thread selbst auf die Variable zugreifen kann und jeder Thread seine eigene Kopie dieser Variablen erhält. Shared hingegen bedeutet, dass alle Threads gleichzeitig Zugriff auf dieselbe Variable, also auf denselben Bereich im Speicher erhalten. In beiden Gruppen gibt es noch Spezialisierungen, auf die die OpenMP-Dokumentation näher eingeht.
OpenMP kennt einige Regeln, um Variablen automatisch einer der beiden Gruppen zuzuordnen. So ist der Iterator der parallelisierten Schleife automatisch privat (dies gilt aber nicht für die Iteratoren von inneren Schleifen). Der Autor empfiehlt jedoch, diese Zuordnung explizit vorzunehmen. Das geschieht in der Anweisung »pragma omp« über die Optionen »private()« und »shared()«. Die zugeordneten Variablen stehen als kommaseparierte Liste in den Klammern. Im Beispiel sind »i«, »j« und »PercentDone« für jeden Thread privat. Die Variablen »generalProgress«, »X« und »found« müssen jedoch von allen Threads aktualisiert werden und sind daher shared:
#pragma omp parallel for private(i,j,percentDone) shared(generalProgress,X,found) for( i = 0; i <= SIZE; i ++ )
Beim Ausführen des Beispiels aus Listing 4 passieren zwei überraschende Dinge: Die Ergebnisse sind nicht mehr korrekt, die Anzahl der im seriellen Lauf gefundenen Werte weicht von der des parallelen Laufs ab. Zudem ist das Programm nicht entsprechend der Anzahl der verwendeten CPUs schneller.
|
Listing 4: Fehlerhaft |
|---|
01 void Calculate()
02 {
03 int generalProgress=0,i,j,percentDone, found=0,procid=0;
04 static double X[SIZE];
05
06 #pragma omp parallel for private(i,j,percentDone)shared(generalProgress,X,found)
07 for( i = 0; i <= SIZE; i ++ )
08 {
09 X[i] = sqrt(exp(cos(i))*exp(sin(i)));
10 for(j=1;j<i;j++)
11 X[i] *= sqrt(exp(cos(j))*exp(sin(i)));
12
13 if( X[i] > 0.5)
14 {
15 found ++;
16 }
17
18 generalProgress++;
19
20 percentDone = (int)((float)generalProgress/(float)SIZE *100.0 + 0.5);
21
22 if( percentDone % 10 == 0 )
23 printf("nbbbb%3d%%", percentDone);
24
25 }
26 printf("nfound %dn",found);
27 }
|
Race Conditions
Ursache für das erste Problem sind in der Regel so genannte Race Conditions. Dabei greifen zwei oder mehr Threads auf denselben Speicherbereich zu, mindestens einer der beteiligten Threads modifiziert diesen Bereich. Damit hängt das Resultat von der Reihenfolge der Zugriffe ab (Abbildung 1).
Ein einfaches Beispiel für eine Race Condition: Zwei Threads führen die Operation X=X+1 aus. Beide laufen zeitlich nicht vollkommen exakt aufeinander abgestimmt, sondern führen analoge Operationen zu unterschiedlichen Zeitschritten aus. Dies kann geschehen, weil beide Threads unterschiedliche Arbeiten verrichten. Aber auch eine OS-bedingte Verzögerung – das Betriebssystem muss einen Thread kurzzeitig anhalten, um eine System-Task auszuführen – ist nicht ungewöhnlich.
Auf Maschinenebene bedeutet dies, dass zunächst ein Thread den Inhalt des Speichers X in ein Register der CPU 1 kopiert. Bevor dieser Thread das Ergebnis zurückschreiben kann, kopiert aber bereits der zweite Thread das Datum in das Register der CPU 2. Beide Threads addieren 1 und kopieren die Daten zurück nach X. Nur ist das Ergebnis, wie in Abbildung 1 dargestellt, nicht wie erwartet »12«, sondern eben nur »11«.
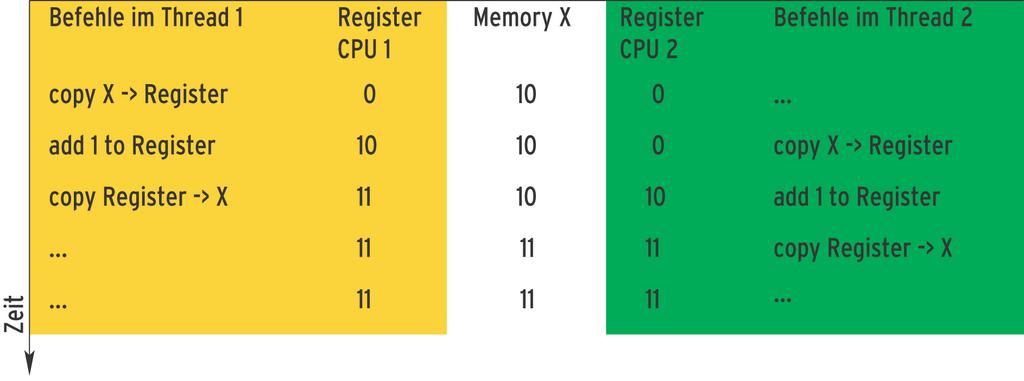
Abbildung 1: Bei ungünstigem zeitlichem Ablauf und zwischen Threads geteilten Daten können Race Conditions auftreten. Bei korrektem Ablauf des Programms aus Listing 4 stünde am Ende im Speicher der Wert »12«.
Es kann übrigens für eine Race Condition schon genügen, wenn nur ein Thread Modifikationen durchführt, ohne mit den lesenden Threads synchronisiert zu sein. Der Ablauf “Thread 1 liest, Thread 1 schreibt, Thread 2 liest” kann ein anderes Ergebnis bewirken als “Thread 1 liest, Thread 2 liest, Thread 1 schreibt”.
Tools helfen
Vorgänge wie diese müssen in parallelen Programmen berücksichtigt werden. In der Regel sind alle Variablen, auf die Threads gemeinsam zugreifen, die also shared sind, auf derartige Lücken zu überprüfen. In einem kleinen Programm ist dies problemlos von Hand zu erledigen, bei größeren Projekten empfiehlt sich dagegen der Einsatz geeigneter Software-Tools wie zum Beispiel des Intel Thread Checker.
Dieses Werkzeug findet eine ganze Reihe von Zugriffskonflikten, die sich aufgrund des Programmverlaufs ergeben, und stellt sie übersichtlich dar (siehe Abbildung 2). Der Programmierer sollte sich aber über den Ausführungspfad (Execution Path) des Code klar sein. Codeteile, die der verwendete Testfall nicht durchläuft, kann das Tool nicht prüfen.
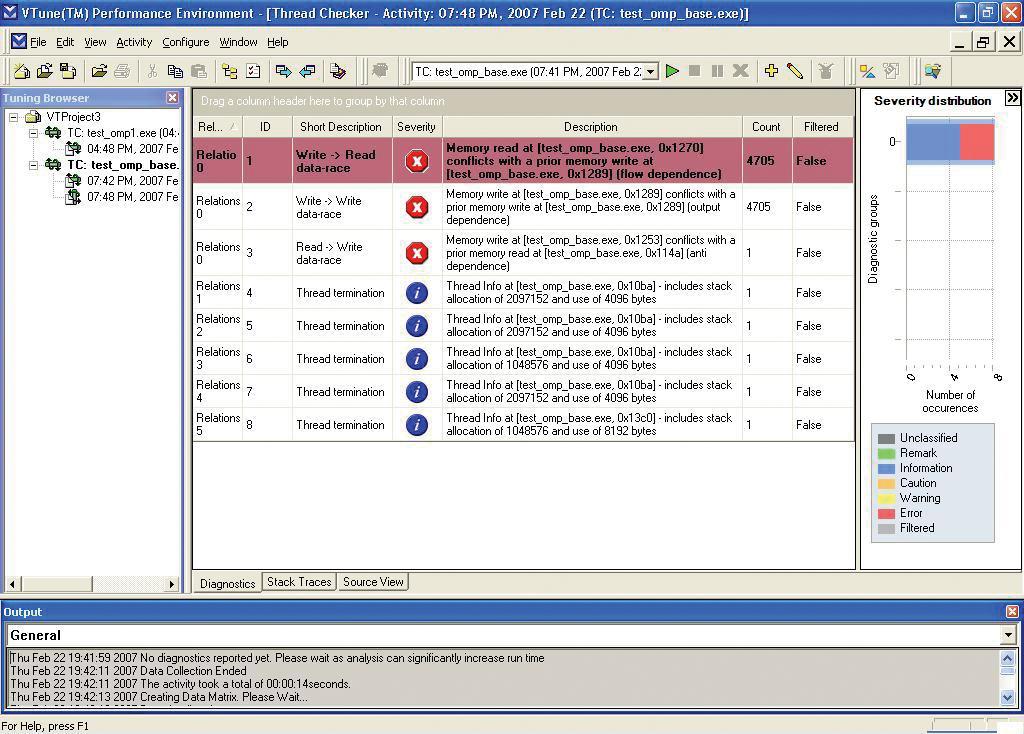
Abbildung 2: Der Intel Thread Checker findet viele potenzielle Probleme Thread-basierter Programme schon bei der Analyse. Das Frontend gibt es derzeit allerdings nur für Windows.
Im Beispiel erkennt das Tool die Zeilen, die die Variablen »found« und »generalProgress« inkrementieren, als problematisch. Beide Variablen sind aber notwendig, um die Informationen über Fortschritt und Fundstellen zwischen den einzelnen Threads zu transportieren. Es gilt also sicherzustellen, dass zu einem Zeitpunkt immer nur ein Thread Änderungen an der Variablen vornimmt. Das dafür erforderliche Locking kostet aber zusätzlich Zeit.
Locking
OpenMP kennt die Direktive »#pragma omp critical«, um einen kritischen Abschnitt zu kennzeichnen. Dies stellt sicher, dass immer nur ein Thread die im folgenden Block eingeschlossenen Codeteile ausführt. Eine Variante ist für einfache Operationen wie »++« oder »*=« verfügbar. Da diese Konstrukte häufig vorkommen, gibt es dafür das Pragma:
#pragma omp atomic generalProgress++;
Der Vorteil liegt in der gegenüber »critical« wesentlich geringeren Anzahl nötiger Lock-Operationen, die vom User unbemerkt automatisch ablaufen.
Für die Variable »found« bietet sich ein alternativer Ansatz an. Eigentlich ist es für das Programm unerheblich, zur Laufzeit den jeweils korrekten Wert der bisher gefundenen Stellen zu kennen – es genügt, dass dieser Wert am Ende der Schleife verfügbar ist. Man könnte also »found« über ein Array aufteilen und jedem Thread eine Stelle im Array als private Variable bereitstellen. Am Ende der Schleife müsste das Array aufsummiert werden, um alle gefundenen Stellen zu erhalten. Dieser Vorgang wird als Reduktion bezeichnet, OpenMP stellt auch dafür ein Sprachelement bereit. Es reicht, die Variable als »reduction(Operator:Variable)« zu kennzeichnen:
#pragma omp parallel for private(i,j,percentDone) shared(generalProgress,X) reduction(+:found)
Bei Beginn der Iteration erhält jeder Thread eine private Variable »found«, deren Wert automatisch auf »0« gesetzt wird (ein neutraler Startwert; für die Operation »*« zum Beispiel ist der Startwert »1«). Die Threads können ohne Locks ihre privaten Kopien modifizieren. Am Ende der Schleife summiert das OpenMP-Runtime alle Werte auf und schreibt sie in »found«.
Mit diesen beiden Änderungen läuft das Programm nun korrekt (Listing 5), aber nicht besonders schnell. Hilfe bei der Analyse leistet zum Beispiel der Intel Thread Profiler. Zurzeit ist die GUI-basierte Auswertung der unter Linux erhobenen Laufzeitdaten leider nur unter Windows möglich.
|
Listing 5: Numerische |
|---|
01 void Calculate()
02 {
03 int generalProgress=0,i,j,percentDone, found=0,procid=0;
04 static double X[SIZE];
05
06 #pragma omp parallel for private(i,j,percentDone)shared(generalProgress,X) reduction(+:found)
07 for( i = 0; i <= SIZE; i ++ )
08 {
09 X[i] = sqrt(exp(cos(i))*exp(sin(i)));
10 for(j=1;j<i;j++)
11 X[i] *= sqrt(exp(cos(j))*exp(sin(i)));
12
13 if( X[i] > 0.5)
14 {
15 found ++;
16 }
17
18 #pragma omp critical
19 generalProgress++;
20
21 percentDone = (int)((float)generalProgress/(float)SIZE *100.0 + 0.5);
22
23 if( percentDone % 10 == 0 )
24 printf("nbbbb%3d%%", percentDone);
25
26 }
27 printf("nfound %dn",found);
28 }
|
Der Profiler zeigt aus zur Laufzeit erhobenen Daten eine genaue Darstellung der einzelnen Threads – vor allem, ob zur gesamten Laufzeit alle Threads nützlichen Code ausführen und nicht einen großen Teil der Zeit mit Wartezyklen vergeuden. Eine Analyse des Beispiels zeigt, dass die einzelnen Threads ganz unterschiedliche Arbeiten verrichten.
Ungerecht
Der Grund dafür ist schnell gefunden, wenn man sich die Schleife etwas genauer ansieht. Je größer der Index »i« der äußeren Schleife wird, desto öfter wird die innere Schleife »j« durchlaufen. OpenMP teilt die Schleife »i« wie erwähnt in gleiche Anteile auf. Bereits bei zwei Threads entsteht damit ein Ungleichgewicht.
Um diese Art von Problemen zu umgehen, kennt OpenMP die Option »schedule(dynamic,CHUNK)«, die eine dynamische Lastverteilung in einer Schleife zur Laufzeit erreicht. Die Schleife wird in Teile der Größe »CHUNK« unterteilt und jedem Thread ein Teil zur Arbeit übergeben. Der Wert sollte kleiner als die Schleifengröße geteilt durch die Anzahl der Threads sein. Hat ein Thread einen Teil abgearbeitet, erhält er einen weiteren »CHUNK« zur Bearbeitung.
Versteckte Locks
Das obige Beispiel enthält noch ein weiteres Problem, das ohne geeignete Tools kaum offenbar wird. Die Ausgabe über »printf« enthält eventuell (systemabhängig) einen impliziten Lock. Schreiben zwei Threads gleichzeitig auf die Konsole (also nach Stdout), muss daher der langsamere der beiden warten, bis der schnellere die Ausgabe abgeschlossen hat. Das führt zwar zu unnötigen Wartezeiten und verlangsamt das Programm. Es ist jedoch nicht notwendig, die Ausgabe von mehr als einem Thread durchführen zu lassen.
Für diesen Zweck scheinen sich zwei Pragmas anzubieten: »#pragma omp single« sorgt dafür, dass der Block nur in einem Thread abläuft; »#pragma omp master« bewirkt, dass nur der Thread 0 diesen Codeteil sieht. Jedoch sind beide Pragmas innerhalb einer parallelisierten Schleife nicht erlaubt. Der Programmierer ist daher gezwungen, eine Unterscheidung über die API-Funktion »omp_get_thread_num()« zu erzwingen. Mit etwas Geschick und dem Einsatz eines »#ifdef _OPENMP« bleibt das Programm dennoch seriell kompilierbar.
Obwohl »pragma omp for« die bei weitem häufigste Variante der OpenMP-basierten Parallelisierung ist, lassen sich auch mittels »section« in Ansätzen aufgabenorientierte Verteilungen durchführen. Ein typisches Beispiel sind Strukturen wie in Listing 6. Die Berechnungen von A, B und C können unabhängig voneinander ablaufen. Das gilt auch für E, F und G – nur muss zuvor D berechnet sein. Hier wirkt wieder Amdahls Gesetz: Entweder »calculate_d()« läuft seriell ab und beschränkt die Skalierbarkeit oder die Funktion muss in sich parallelisiert werden. Für eine begrenzte Skalierbarkeit genügen aber schon wenige OpenMP-Anweisungen (Listing 7).
|
Listing 6: Abhängige |
|---|
01 A= calculate_a(x1,y1,z1); 02 B= calculate_b(x2,y2,z2); 03 C= calculate_c(x3,y3,z3); 04 D= calculate_d(A,B,C); 05 E= calculate_e(x4,y4,d); 06 F= calculate_f(x5,y5,d); 07 G= calculate_g(x6,y6,d); |
|
Listing 7: Teilweise |
|---|
01 #pragma omp parallel sections
02 {
03 #pragma omp section
04 A= calculate_a(x1,y1,z1);
05 #pragma omp section
06 B= calculate_b(x2,y2,z2);
07 #pragma omp section
08 C= calculate_c(x3,y3,z3);
09 #pragma omp barrier
10 }
11 D= calculate_d(A,B,C);
12 #pragma omp parallel sections
13 {
14 #pragma omp section
15 E= calculate_e(x4,y4,d);
16 #pragma omp section
17 F= calculate_f(x5,y5,d);
18 #pragma omp section
19 G= calculate_g(x6,y6,d);
20 }
|
Im ersten Teil sorgen die Section-Direktiven dafür, dass die Berechnung der drei Variablen A, B, C parallel erfolgt. Am Ende des Blocks »sections« wird implizit eine Barriere aufgerufen: Bevor das Programm weiterarbeitet, müssen alle Threads diesen Punkt erreicht haben. Eine solche Schranke lässt sich auch durch die Direktive »#pragma omp barrier« erreichen (Zeile 9). Der Autor befürwortet generell die explizite Verwendung von »barrier« statt der in gewissen Konstrukten implizit vorhandenen Synchronisationspunkte, da das weniger fehleranfällig ist und im Allgemeinen die Lesbarkeit des Code verbessert.
Eine weitere Möglichkeit offenbart sich in der explizieten Verwendung der OpenMP-Bibliothek. Listing 8 zeigt, wie einfach der Programmierer damit eine Schleife auf die vorhandenen Threads aufteilen kann. Der Vorteil gegenüber expliziter Thread-Programmierung liegt darin, dass er sich kaum um die Thread-Erzeugung und andere systemspezifische Eigenheiten kümmern muss. Das Programm bleibt damit portabel – es geht aber etwas Potenzial verloren, optimale Performance zu erreichen.
|
Listing 8: |
|---|
01 nt=omp_get_num_threads()
02 #pragma omp parallel private(i,id) reduction(+:sum) shared(nt)
03 {
04 id = omp_get_thread_num();
05 for(i=id;i<SIZE;i+=nt)
06 {
07 sum += calculate(i);
08 }
09 }
|
Viel einfacher
OpenMP wurde mit dem Ziel geschaffen, seriellen Code mit wenig Aufwand für SMP-Maschinen zu portieren. OpenMP ist im Gegensatz zu den meisten Thread-Bibliotheken auch portabel. Es ist einfach zu lernen wie auch anzuwenden. Genauso leicht ist es aber auch, gravierende Fehler zu begehen. Der Autor empfiehlt daher dringend, jedes parallelisierte Programm gezielt auf Fehler zu überprüfen, die in seriellem Code nicht vorkommen.
OpenMP wird ständig weiterentwickelt. Im Intel-Compiler sind bereits mehrere Verbesserungsvorschläge umgesetzt, die zum Beispiel in den Bereichen Scheduling und Thread-Erzeugung Optimierungen bringen. Gerade die Einfachheit von OpenMP ist aber auch Ursache für manche Einschränkung gegenüber explizitem Threading. So muss jeder Entwickler selbst entscheiden, ob OpenMP für sein Projekt geeignet ist. Da aber Multicore-Systeme nun auch im Consumer-Bereich eher die Regel als die Ausnahme sind, ist OpenMP für viele Anwendungen eine gute Option. (ofr)
|
Infos |
|---|
|
[1] OpenMP: [http://www.openmp.org] [2] GCC-Gomp: [http://gcc.gnu.org/projects/gomp] |





