© Puwadol Jaturawutthichai, 123RF
Der Arbeitgeber von Autor Chris Hinze litt wie vermutlich alle Homepage-Baukasten-Anbieter unter Spammern und illegalen Inhalten. Ein Praxisbericht, der auf der Theorie des Deep Learning beruht.
Wer wie wir einen Homepage-Baukasten [2] betreibt, dürfte sie zur Genüge kennen: Nutzer, die ihre Webseiten für Spam oder andere illegale Inhalte missbrauchen. Diese Seiten manuell überprüfen ist bei Millionen von Nutzern nicht nur mühsam, sondern auch ineffizient. Neuronale Netze [3] sparen Arbeit, indem sie Seiten automatisiert prüfen. Die Trainingsdaten kommen aus unserem Bestand bereits klassifizierter Seiten.
Der Artikel beschreibt, wie ein Entwickler ein passendes neuronales Netz konzipiert, wobei ihm Tensorflow ([4], [5]) und TF-Learn [6] helfen. Erstere ist eine Machine-Learning-Bibliothek von Google, Letztere eine Bibliothek mit High-Level-API für Tensorflow. Sie vereinfachen den Umgang mit neuronalen Netzen.
Training Day
Um zu lernen, braucht das neuronale Netz sowohl positive als auch negative Beispiele. Unsere manuell zusammengetragene Liste von Nutzern ließ sich recht eindeutig in Spammer und legitime Nutzer aufteilen. Wir achten darauf, beide Arten mengenmäßig gleich zu verteilen. Neben dieser Klassifizierung enthält der eingesetzte Datensatz den Namen des Nutzers beziehungsweise die zugehörige Website, die IP-Adresse, mit der er diese registriert hat, sowie die Sprachversion, für die er sich entscheidet.
Das nun angelernte Netz erkennt automatisiert Spammer, die sich neu registrieren. Wir kombinieren es mit einer manuellen Prüfung. Seiten, die das Netzwerk mit sehr hoher Wahrscheinlichkeit als Spam klassifiziert, sperrt das zugehörige Python-Skript vollautomatisch, den Rest mit einer hohen Wahrscheinlichkeit prüft ein Mitarbeiter.
Gutes Netz
Neuronale Netze sind mathematische Modelle, die beliebige Funktionen annähern. Sie orientieren sich dabei an vernetzten Neuronen, wie sie das menschliche Gehirn besitzt, zum Beispiel im visuellen Kortex ([7], [8]). Das Besondere: Die Anwender müssen das Verhalten dieser Netze nicht explizit modellieren. Vielmehr trainieren sie es den Netzen mit Hilfe von Beispieldaten an.
Neuronale Netze helfen dort, wo sich Funktionen nur schwer von Hand modellieren lassen, häufig kommen sie in der Bild- und Spracherkennung zum Einsatz. Als Input benötigen sie bereits klassifizierte Trainingsdaten. Daraus stellen sie Zusammenhänge her und versuchen dann, neue Daten ähnlich zu klassifizieren. Sie lernen also keine neuen Kunststücke, sondern passen ihr Verhalten an ein vorgegebenes Schema an.
Gehirnzelle
Ein einzelnes künstliches Neuron besteht aus mehreren gewichteten Eingängen und einer meist nicht-linearen so genannten Aktivierungsfunktion, die den Ausgabewert des Neurons mitbestimmt. Hinzu kommt noch ein Schwellenwert oder Bias, der die gewichteten Eingänge ergänzt und somit die Aktivierungsfunktion beeinflusst. Die mathematische Formel dahinter sieht dann so aus:
Sie gewichtet mit dem Vektor »w« den Eingabevektor »x« und summiert beide. Dann addiert sie den Bias »b« und wendet darauf die Aktivierungsfunktion ? an. Indem Entwickler mehrere der Neuronen geschickt miteinander kombinieren, berechnen diese komplexere Funktionen (siehe Kasten “Probleme lösen mit neuronalen Netzen”.
Probleme lösen mit neuronalen Netzen
Ein einzelnes Neuron kann bereits linear separierbare Probleme lösen. Ein Beispiel für ein solches Problem ist die binäre Oder-Funktion. Trägt man etwa die möglichen Eingaben und Ausgaben in ein Koordinatensystem ein, lassen sich die beiden Ausgabewerte durch eine Gerade voneinander trennen (das rechte obere Neuron in Abbildung 1). Das Problem ist damit linear separierbar.
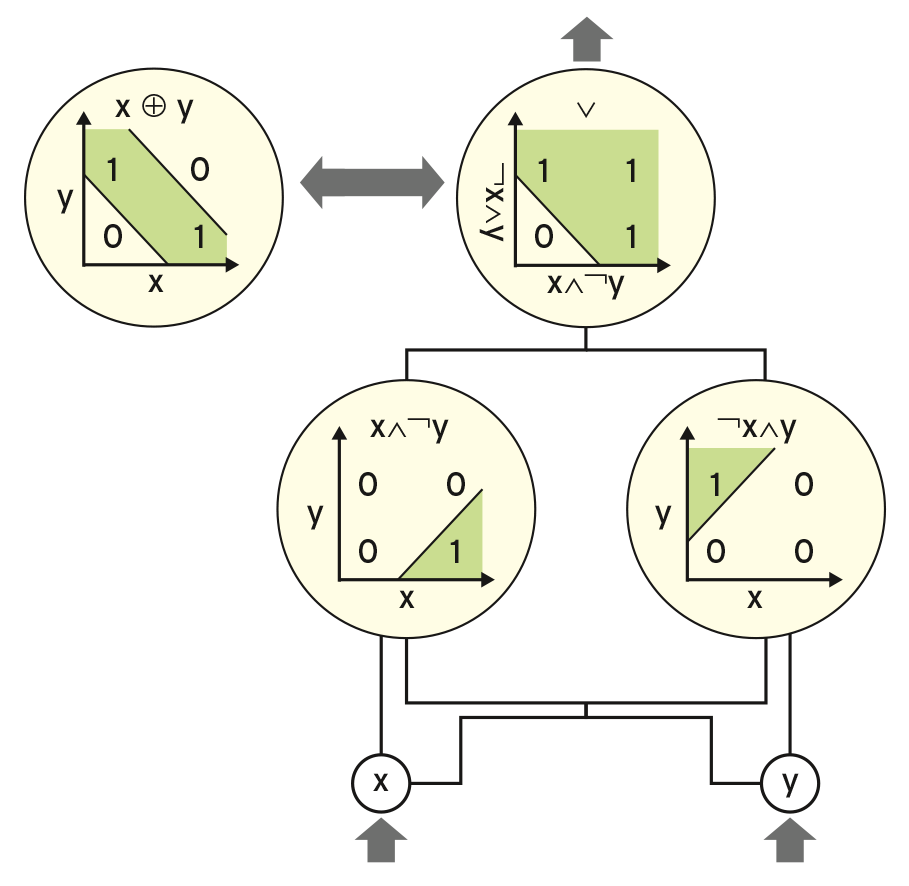
Abbildung 1: Ein binäres XOR ist als solches nicht linear separierbar, lässt sich aber in linear separierbare Teilprobleme zerlegen.
Doch nur wenige Probleme sind so einfach zu lösen. Ein einzelnes Neuron reicht zur Klassifizierung in der Regel nicht aus. Da sich komplexere Herausforderungen jedoch meist in linear separierbare Teilprobleme zerlegen lassen, die einzelne Neuronen dann wiederum lösen können, kommen in der Praxis ganze Netze aus Neuronen zum Einsatz.
Abbildung 1 zeigt das binäre exklusive Oder, das sich als nicht linear separierbar erweist. Eine einzige Gerade genügt nicht, um die beiden Einsen von den Nullen zu trennen. Wie die Aussagenlogik weiß, setzt sich die XOR-Funktion aus einer Kombination zweier Konjunktionen zusammen:
Sowohl die beiden Konjunktionen als auch die Disjunktion sind wiederum linear separierbar. Es ist also möglich, das binäre exklusive Oder durch drei Neuronen zu modellieren, wobei eines die Ausgaben der beiden anderen als Eingabe empfängt. Diese Kombination aus Neuronen bildet ein kleines, zweischichtiges neuronales Netz.
Wie das kleine Beispiel zeigt, berechnen Deep-Learning-Experten komplexere Funktionen einfach, indem sie mehrere Neuronen miteinander kombinieren. Die Potenz neuronaler Netze erhöht sich mit der Anzahl der eingesetzten Schichten und zum Teil mit deren Aufbau. Die Schichten erlauben es den Experten, mehr Funktionen zu berechnen.
Vernetztes Lernen
Mehrere Schichten miteinander verbundener Neuronen bilden ein so genanntes neuronales Netz (Abbildung 2). Ein solches besteht mindestens aus einer Eingabeschicht, welche die Eingabewerte empfängt, sowie einer Ausgabeschicht, in der die Daten nach dem Passieren mehrerer verdeckter Schichten ankommen. Sämtliche Neuronen auf einer Schicht verwenden dabei in der Regel dieselbe Aktivierungsfunktion.
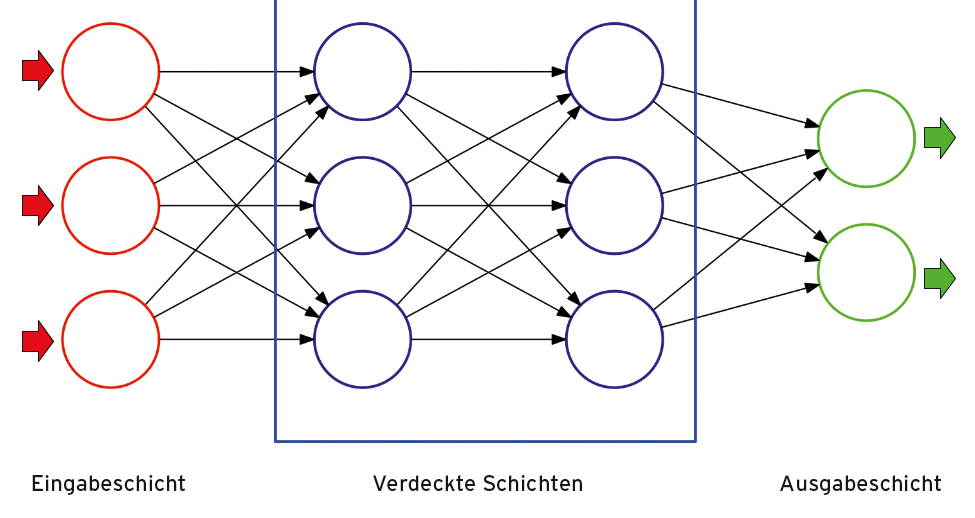
Abbildung 2: Ein neuronales Netz mit zwei verdeckten Schichten.
Neuronale Netze lernen, indem ein Optimierungsverfahren die Parameter des Netzes, die Gewichtungen der Verbindungen und die Bias sämtlicher Neuronen bestimmt und dann Schritt für Schritt verfeinert. Der Vorgang, in dessen Ablauf das Verfahren die Parameter bestimmt, gehört zu den Optimierungsproblemen. In diesem Prozess kommen viele klassische Methoden aus der Numerik zum Einsatz, zum Beispiel das Gradientenverfahren [9].
Zunächst initialisiert das Skript das zu trainierende Netz mit zufällig gewählten Parametern. Dann wendet es den Trainingsdatensatz auf das neuronale Netz an und ermittelt den Abstand zwischen den Ergebnissen des Netzes und den richtigen Resultaten aus den Trainingsdaten. Der Abstand heißt Loss (Verlust), ihn soll das Skript im weiteren Laufe des Optimierungsverfahrens minimieren.
Zirkeltraining
Das Training verläuft iterativ. Im Rahmen eines Durchlaufs (einer so genannten Epoche) lässt der Entwickler den kompletten Datenbestand einmal über das neuronale Netz laufen und bestimmt den Verlust. Aus Performancegründen verwendet er dabei nicht alle Daten auf einmal, sondern teilt sie in kleinere Portionen (Batches) auf.
Im Verlauf einer weiteren Epoche legt das Trainingsskript dann über das Optimierungsverfahren neue Parameter mit einem geringeren Verlust fest. Mit diesen wiederum berechnet es anschließend die Genauigkeit des Netzes neu. Im Idealfall konvergiert nach einer gewissen Anzahl von Epochen die Genauigkeit gegen einen bestimmten Wert. Das Netz darf als angelernt gelten und das Trainingsskript speichert die errechneten Gewichtungen und Schwellenwerte.
Abbildung 3 zeigt vereinfacht, wie das Gradientenabstiegsverfahren das Minimum einer einzelnen Gewichtung »w« bestimmt. Die x-Achse zeigt die Gewichtung, die y-Achse den Wert der Loss-Funktion mit dieser Gewichtung. Das Trainingsskript bestimmt mit jeder Iteration des Gradientenverfahrens die Ableitung – und damit die Steigung – des Loss-Graphen an der Stelle des aktuellen Gewichts und bewegt sich dann eine Schrittweite – die Lernrate ? – in diese Richtung.
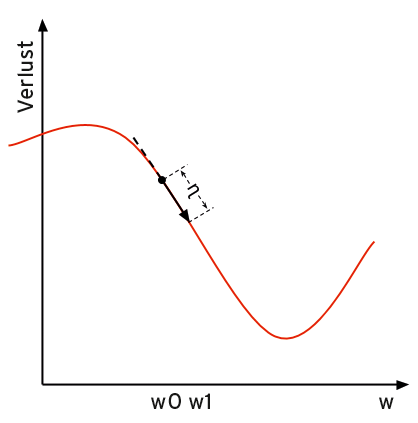
Abbildung 3: Das Gradientenabstiegsverfahren bestimmt in dieser vereinfachten Darstellung das Minimum einer Funktion.
Merkwürdig
Die Felder der Datensätze, die als Eingaben für das Netz dienen, heißen Merkmale. Das neuronale Netz arbeitet mit reellen Zahlen, daher lassen sich Namen und IP-Adressen nicht direkt in Form von Strings als Merkmale einfügen.
Unsere Erfahrungen zeigen, dass Spammer oft sehr kryptische Nutzernamen verwenden. Daraus konnten wir folgende Merkmale ableiten: die Länge, die Anzahl der Bindestriche, die Anzahl der Ziffern, die Differenziertheit der Zeichen, die Anzahl der Vokale, die Anzahl der Nicht-Buchstaben und das Vorkommen bestimmter Keywords (zum Beispiel »credits« , »100mg« , »taler« ).
Eine Geolocation-Datenbank löst das zu einer bestimmten IP-Adresse passende Land sowie den ISP auf. Unsere Bestandsdaten legen auch hier verschiedene Merkmale nahe. Sie verraten, wie oft ein ISP als Spammer fungiert, wie häufig eine Kombination aus einem bestimmten Ursprungsland und der gewählten Sprache für den Baukasten auftritt und aus welchem Land uns besonders viel Spam erreicht. Als letztes Merkmal gleicht die Software dann die IP-Adresse mit einer Liste bekannter Proxys ab.
Im nächsten Schritt sortieren wir Merkmale aus, die wenig mit der Klasse korrelieren und damit wenig zum Ergebnis beitragen. Der Hintergrund dafür: Ein kleineres Netz lässt sich schneller trainieren und braucht auch weniger Ressourcen. Über eine Korrelationsmatrix erkennen wir, wie gut sich Merkmale für die Spamerkennung eignen. Sie gibt also über die Abhängigkeit zwischen Merkmalen untereinander und mit der Klassifizierung Auskunft.
Listing 1 zeigt ein Python-Skript, das die Korrelationsmatrix aufstellt. Es liest eine CSV-Datei mit den Daten ein, berechnet über die Funktion »np.corrcoef()« die Korrelationsmatrix und erzeugt abschließend eine PNG-Datei mit dem Dichteplot der Matrix. Die erste Spalte (in den Beispieldaten der Nutzername) ignoriert sie dabei. Finden sich in der CSV-Datei weitere Werte, die nicht den reellen Zahlen angehören, muss der Entwickler die Funktion »read_file()« entsprechend anpassen. In der letzten Spalte sollte die Klasse stehen, die Spammer von legitimen Seitenbauern unterscheidet.
Listing 1
correlation.py
01 import csv
02 import numpy as np
03 import os
04 import sys
05 import dnn
06 import tflearn
07 from PIL import Image, ImageDraw
08
09 def read_file(filename):
10 data = []
11 with open(filename, "r") as file:
12 reader = csv.reader(file, delimiter=",")
13 next(reader) # Header ueberspringen
14 for row in reader:
15 row.pop(0) # Benutzernamen entfernen
16 row = map(float, row)
17 data.append(row)
18 return data
19
20 def calculate_correlation_matrix(data):
21 with np.errstate(invalid="ignore"):
22 return np.corrcoef(data, rowvar=0)
23
24 def draw_matrix(matrix, filename, size=20):
25 n = len(matrix)
26
27 img = Image.new("RGB", (n*size, n*size))
28 draw = ImageDraw.Draw(img)
29
30 for i in range(0, n):
31 for j in range(0, n):
32 color = "hsl(0, 0%%, %d%%)" % (matrix[i][j]*100)
33 draw.rectangle((i*size, j*size, (i+1)*size, (j+1)*size), fill=color)
34
35 img.save(filename)
36
37 if __name__ == "__main__":
38 if len(sys.argv) < 2:
39 sys.exit("Usage: python correlation.py <input-csv-file>")
40
41 input_file = sys.argv[1]
42
43 data = read_file(input_file)
44 matrix = calculate_correlation_matrix(data)
45 draw_matrix(np.absolute(matrix), "correlation.png")
46
47 print(matrix)
Der Dichteplot (Abbildung 4) zeigt übersichtlich, welche Merkmale sich besonders gut eignen. Jede Zeile und Spalte steht jeweils für ein Merkmal. Je heller das Feld, desto höher korrelieren Zeilenmerkmal und Spaltenmerkmal. Die letzte Zeile und Spalte verrät die Korrelation mit der Klasse. Merkmale eignen sich also umso besser zur Klassifizierung, je heller das Feld in der letzten Zeile und Spalte leuchtet.
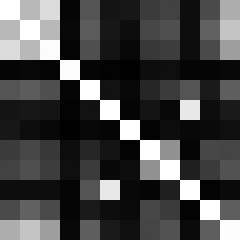
Abbildung 4: Über den Dichteplot der Korrelationsmatrix lassen sich die Abhängigkeiten zwischen Merkmalen bestimmen.
Die Korrelationsmatrix verrät zudem, ob sich zwei Merkmale zu sehr ähneln und ob zur Klassifizierung womöglich auch eines genügt. Ein Beispiel dafür wären die Merkmale »6« (die Anzahl der Zahlen im Benutzernamen) und »10« (die Anzahl der Nicht-Buchstaben). Das weiße Feld deutet auf eine starke Abhängigkeit zwischen beiden Variablen hin. Es reicht also, Merkmal »6« zu betrachten, Merkmal »10« bietet keine Zusatzinformation.
Hyperparameter
Der Löwenanteil der Arbeit mit neuronalen Netzen steckt darin, mit Hilfe der so genannten Hyperparameter die Struktur oder Konfiguration des Netzes zu bestimmen. Diese optimiert der Entwickler üblicherweise von Hand, indem er jede Netzkonfiguration einzeln anlernt und die Ergebnisse vergleicht, bis er auf eine gute Konfiguration stößt. Zu den Hyperparametern gehören die Anzahl und Breite der Schichten, die Aktivierungsfunktionen der Schichten, die Anzahl der Epochen, die Größe der verabreichten Datenportionen (Batches) sowie das verwendete Optimierungsverfahren und die Lernrate.
Eine Vielzahl von Aktivierungsfunktionen bietet TF-Learn im Paket »tflearn.optimizations« an. Die wichtigsten stellt Abbildung 5 dar, die einfachste ist die Identität oder auch lineare Aktivierungsfunktion. Sie gibt den Eingabewert unverändert zurück. Die Sigmoidfunktion ist nicht-linear und damit als Aktivierungsfunktion deutlich interessanter als die lineare. Die Funktion ist beschränkt und liefert nur positive Werte zwischen 0 und 1 zurück.
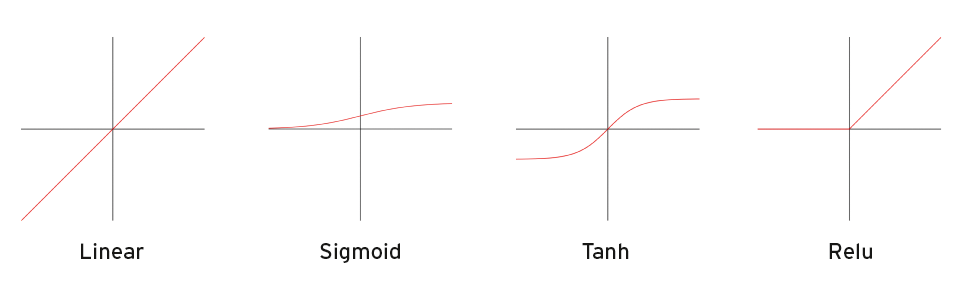
Abbildung 5: Die wichtigsten Aktivierungsfunktionen im Überblick.
Tanh lässt sich mit Sigmoid vergleichen, liefert aber Werte zwischen -1 und 1 zurück. Eine weitere Aktivierungsfunktion heißt Rectified Linear oder auch Relu. Sie lässt sich als lineare Funktion mit einem Schwellenwert vorstellen. Relu konvergiert sehr schnell und ist momentan die empfohlene Funktion. Wir verwenden sie auch für unser Netz.
Eine weitere wichtige Aktivierungsfunktion hört auf den Namen Softmax. Sie setzt den Wert des Neurons ins Verhältnis mit den Werten anderer Neuronen der Schicht. Ihre besondere Eigenschaft besteht darin, dass sich alle Ausgabewerte dieser Schicht zu 1 addieren. In Netzen, die der Klassifizierung dienen, setzen Anwender sie häufig für die Ausgabeschicht ein. Die Ausgabe des Netzes lässt sich dann als Wahrscheinlichkeiten für die einzelnen Klassen interpretieren.
Neben den Schichten und deren Aktivierungsfunktionen sucht der Entwickler auch ein Optimierungsverfahren aus. Statt des klassischen Gradientenverfahrens verwendet er zum Trainieren neuronaler Netze oft Adam, einen Algorithmus, mit dem Anwender in der Regel gute Ergebnisse erzielen. Adam braucht noch eine Lernrate. Der voreingestellte Wert von 0,001 eignet sich für den Anfang, lässt sich aber verkleinern, um womöglich ein noch besseres Ergebnis zu erzielen. Alle mit TF-Learn ausgelieferten Optimierungsverfahren stecken übrigens im Paket »tflearn.optimizers« .
Mit Hilfe der gefundenen Hyperparameter trainiert der Entwickler nun sein Netz und misst dessen Genauigkeit. Anschließend variiert er diese. Das wiederholt er so lange, bis er die Genauigkeit nicht mehr signifikant steigern kann.
Abbildung 6 zeigt den Verlust während des Trainings als Graph. Dieser gibt Aufschluss, ob die Lernrate zu hoch oder niedrig ist. Der Loss-Graph soll möglichst einer fallenden Exponentialkurve gleichen (der blaue Graph). Ist die Lernrate zu hoch, sinkt der Verlust zwar anfangs schnell, konvergiert aber möglicherweise zu früh (rot). Das deutet an, dass der Anwender noch nicht das Optimum gefunden hat. Bei einer zu niedrigen Lernrate fällt der Loss nur sehr langsam, dafür ist es wahrscheinlicher, dass der Nutzer tatsächlich das globale Optimum findet (gelb). Ist der Loss-Graph zu verrauscht, lässt sich die Batchgröße erhöhen.
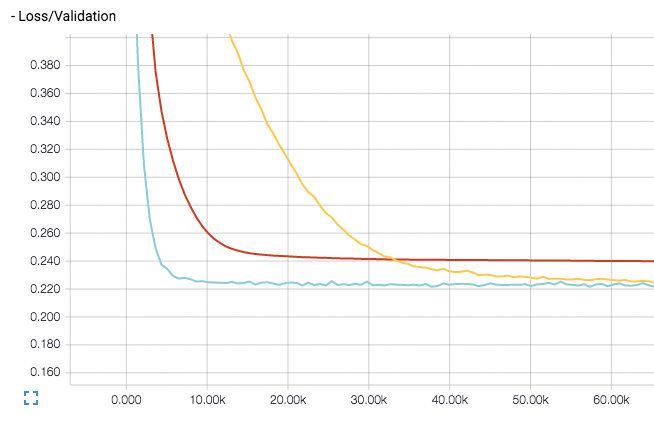
Abbildung 6: Verlust (Loss) während des Trainings bei verschiedenen Lernraten, der blaue Graph stellt das Ideal dar.
Waschechte Konfiguration
Obschon das Optimierungsverfahren mit Hilfe der Trainingsdaten auf ein gutes Ergebnis hinarbeitet, könnte es passieren, dass das Netz die Trainingsdaten quasi auswendig lernt, anstatt sie zu generalisieren und ein allgemeingültiges Verfahren zu erarbeiten. Dieser Effekt heißt Overfitting [10]. Um zu testen, ob das Netz wirklich generalisiert, sollten die Entwickler den Datensatz bereits im Vorfeld in Trainingsdaten und Validierungsdaten aufsplitten. Die Trainingsdaten dienen dazu, Parameter zu optimieren. Der Entwickler bestimmt dann mit den dem Netz noch unbekannten Validierungsdaten die Genauigkeit und vergleicht verschiedene Netzkonfigurationen miteinander.
Bei der Suche nach guten Hyperparametern arbeitet er also auch auf ein gutes Ergebnis mit den Validierungsdaten hin. Diese lassen sich jedoch nicht mehr verwenden, wenn der Entwickler letztendlich bestimmen will, wie gut das Netz mit ganz frischen Daten zurechtkommt. Am Ende trennt er also von seinem Datenbestand noch ein Set an Testdaten ab. Trainings-, Validierungs- und Testdaten sollten sich idealerweise in einem Verhältnis von 80:10:10 Prozent befinden.
Unser Netz besteht übrigens aus einer Schicht aus 30 Neuronen mit der linearen Aktivierungsfunktion und vier Relu-Schichten mit je 30 Neuronen. Adam optimiert mit einer Lernrate von 0,00001. Nach 500 Epochen erreicht die Aktivierungsfunktion mit den Validierungsdaten eine Genauigkeit von 92,6 Prozent, mit den Testdaten immerhin noch eine Genauigkeit von 91,9 Prozent. Das Training dauerte auf einem Macbook Pro etwa 30 Minuten.
Für ein besseres Ergebnis normalisiert der Entwickler die Daten im Vorfeld. Dazu gewichtet er die Werte zunächst um den Mittelwert, indem er das arithmetische Mittel abzieht. Dann bringt er sie auf das Intervall [-1, 1], indem er sie durch die Standardabweichung teilt. Wichtig ist, arithmetisches Mittel und Standardabweichung nur über die Trainingsdaten zu bestimmen und diese Werte für die Validierungs-, Test- und Produktivdaten erneut zu verwenden.
Tensorflow
Um das Ganze zu implementieren, verwenden wir Tensorflow [4]. Die Bibliothek hat Tensorboard im Gepäck, eine Webapp, die Statistiken aus Tensorflow anzeigt und grafisch aufbereitet (Abbildung 7). Das Tool hilft beim Optimieren der Netzstruktur. Es eignet sich wirklich gut, um den Lernprozess zu überwachen und verschiedene Konfigurationen miteinander zu vergleichen. TF-Learn [6] nutzt Tensorflow ebenfalls und stellt einfacher zu benutzende Funktionen für neuronale Netze bereit.
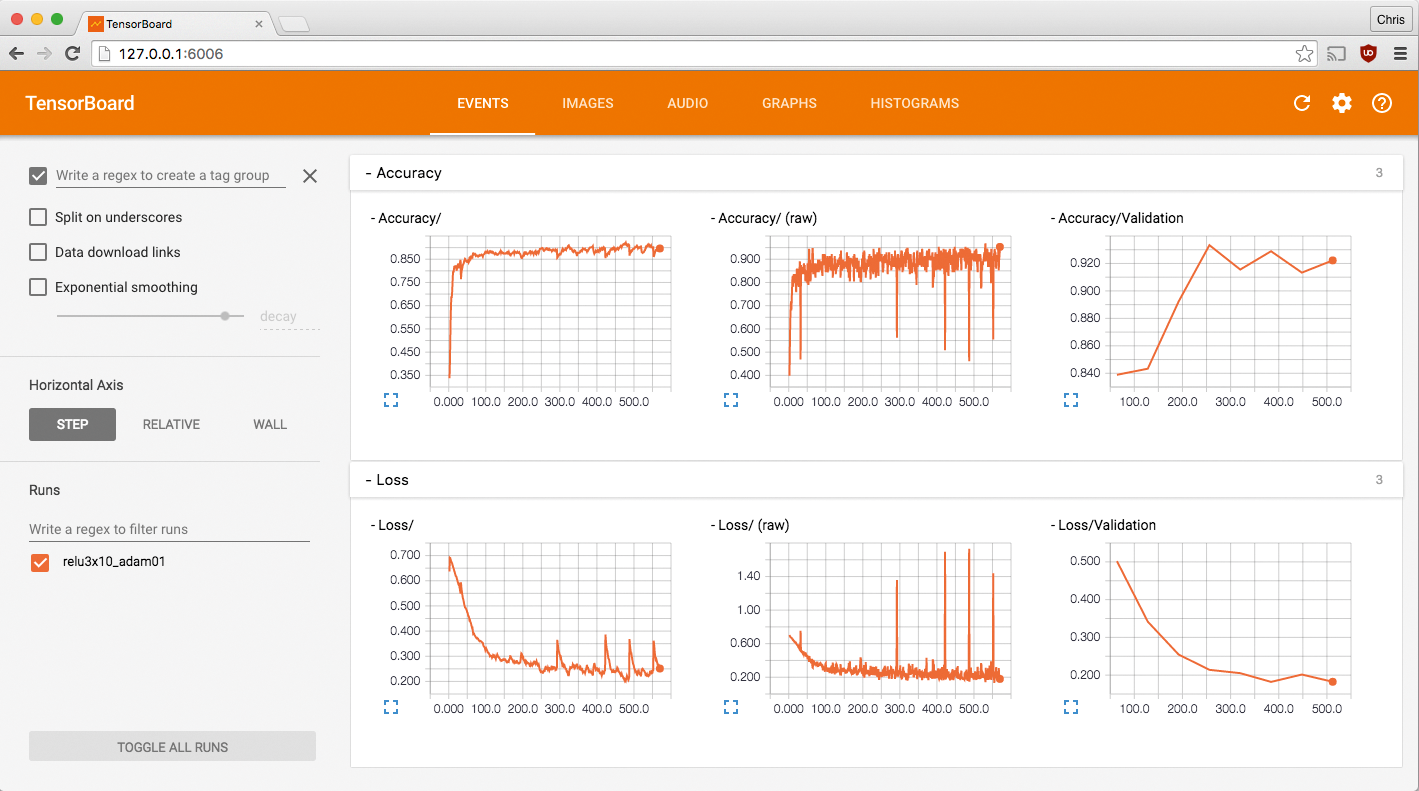
Abbildung 7: Tensorboard bereitet die statistischen Daten aus Tensorflow grafisch auf.
Wie ein Nutzer Tensorflow installiert, beschreibt [11]. Pythons Paketmanager »pip« holt dann TF-Learn auf die Festplatte. Allerdings braucht der User mindestens Version 0.2.2. Zu Redaktionsschluss mussten wir diese – wie unter [12] – beschrieben über Git einspielen. Zudem benötigt er die Pakete »numpy« , »sklearn« , »scipy« und »pillow« .
Listing 2 zeigt Ausschnitte aus dem Skript »dnn.py« , das neuronale Netze trainiert, evaluiert und zur Klassifizierung (Listing 3) nutzt (Listing 4).
Listing 2
train-Funktion (Auszug aus dnn.py)
01 [...] 02 def train(name, dir, input, net, optimizer, batch_size, epochs): 03 # Daten einlesen und aufteilen 04 data, labels = parse_csv(*input) 05 X_train, X_val, X_test, y_train, y_val, y_test = split_data(data, labels) 06 07 # Preprocessing: zero-centern und normalisieren 08 X_train, mean = tflearn.data_utils.featurewise_zero_center(X_train) 09 X_train, std = tflearn.data_utils.featurewise_std_normalization(X_train) 10 X_val = tflearn.data_utils.featurewise_zero_center(X_val, mean) 11 X_val = tflearn.data_utils.featurewise_std_normalization(X_val, std) 12 np.save(dir+"mean", mean) 13 np.save(dir+"std", std) 14 15 # Training 16 net = tflearn.regression(net, optimizer=optimizer) 17 model = tflearn.DNN(net, best_checkpoint_path=dir) 18 model.fit(X_train, y_train, validation_set=(X_val, y_val), show_metric=True, 19 n_epoch=epochs, batch_size=batch_size, run_id=name) 20 [...]
Listing 2 demonstriert, wie der Entwickler ein Netz mit TF-Learn trainiert. Zuerst lädt das Skript die Eingabedaten aus der CSV-Datei, teilt sie auf und normalisiert sie. Es speichert den Mittelwert und die Standardabweichung der Trainingsdaten, um sie später auch auf die Produktivdaten anzuwenden. Der Parameter »best_checkpoint_path« (Zeile 17) weist TF-Learn an, den Stand des Netzes jedes Mal zu sichern, sobald das Skript beim Training mit den Validierungsdaten eine höhere Genauigkeit erreicht. Über die Methode »model.fit()« aus der TF-Learn-Bibliothek trainiert das Skript das Netz »n_epoch« Epochen lang.
Listing 3
evaluate-Funktion (Auszug aus dnn.py)
01 [...] 02 def evaluate(name, dir, input, net, optimizer, batch_size, epochs): 03 [...] 04 # Daten einlesen und aufteilen 05 data, labels = parse_csv(*input) 06 X_train, X_val, X_test, y_train, y_val, y_test = split_data(data, labels) 07 08 # Preprocessing: zero-centern und normalisieren 09 mean, std = np.load(dir+"mean.npy"), np.load(dir+"std.npy") 10 X_test = tflearn.data_utils.featurewise_zero_center(X_test, mean) 11 X_test = tflearn.data_utils.featurewise_std_normalization(X_test, std) 12 13 net = tflearn.regression(net, optimizer=optimizer) 14 model = tflearn.DNN(net, best_checkpoint_path=dir) 15 model.load(get_checkpoint(dir)) 16 17 print(model.evaluate(X_test, y_test)) 18 [...]
Listing 3 kümmern sich um die Evaluation des Netzes. Zuerst liest der Code wieder die CSV-Datei mit den Eingabedaten ein und separiert sie. Dank des festen Seed des Zufallszahlengenerators teilt das Skript die Daten bei jeder Ausführung gleich auf. Dann holt es den Mittelwert und die Standardabweichung und normalisiert die Testdaten damit. Schließlich evaluiert es den Zustand des Netzes mit der besten Genauigkeit und bestimmt mit »model.evaluate()« die Trefferquote des Testdatensatzes.
Listing 4
predict-Funktion (Auszug aus dnn.py)
01 [...] 02 def predict(name, dir, input, net, optimizer, batch_size, epochs): 03 [...] 04 # Daten einlesen 05 X, _ = parse_csv(sys.argv[3], input[1]) 06 07 # Preprocessing: zero-centern und normalisieren 08 mean, std = np.load(dir+"mean.npy"), np.load(dir+"std.npy") 09 X = tflearn.data_utils.featurewise_zero_center(X, mean) 10 X = tflearn.data_utils.featurewise_std_normalization(X, std) 11 12 net = tflearn.regression(net, optimizer=optimizer) 13 model = tflearn.DNN(net, best_checkpoint_path=dir) 14 model.load(get_checkpoint(dir)) 15 16 for line in model.predict(X): 17 print(line) 18 [...]
Um die Klassifizierung der Daten mit Hilfe des Netzes kümmert sich der Code aus Listing 4. Er liest ebenfalls die zu klassifizierenden Daten als CSV-Datei ein, normalisiert sie, lädt dann den Stand des Netzes und klassifiziert Datensätze mit »model.predict()« . Dabei gibt die Funktion pro Datensatz die Wahrscheinlichkeiten für jede Klasse aus.
Experimente
Struktur und Konfiguration der einzelnen Netze bestimmt die Datei »experiments.py« (Listing 5). Ein Experiment ist eine Funktion. Sie liefert ein Tupel aus Eingabedaten, Netz, Optimierungsverfahren, Batchgröße und Anzahl der Epochen zurück. Dabei ist »input« ein Tupel aus dem Dateinamen der CSV-Datei, der Liste der Spalten mit Merkmalen sowie jener Spalte, die die Klasse angibt.
Listing 5
experiments.py
01 import tflearn
02
03 def relu3x10_adam01():
04 input = ("trainingdata.csv", ("name_length", "char_diff", "hyphens", "numbers", "vocals"), "spammer")
05
06 net = tflearn.input_data(shape=[None, 5])
07 for i in range(3):
08 net = tflearn.batch_normalization(net)
09 net = tflearn.fully_connected(net, 10, activation="relu")
10 net = tflearn.batch_normalization(net)
11 net = tflearn.fully_connected(net, 2, activation="softmax")
12
13 optimizer = tflearn.optimizers.Adam(learning_rate=0.001)
14 batch_size = 128
15 epochs = 300
16
17 return input, net, optimizer, batch_size, epochs
Die Methoden »tflearn.input_data()« , »tflearn.batch_normalization()« und »tflearn.fully_connected()« definieren die Schichten des Netzes. Der Entwickler weist jeder Schicht einzeln eine Breite und eine Aktivierungsfunktion zu. Die Eingabeschicht empfängt die Merkmale, ihre Größe hängt von deren Anzahl ab. Vor jeder vollständig verbundenen Schicht sollte sich eine Batch-Normalisierungs-Schicht befinden. Für die letzte Schicht empfiehlt sich der Typ Softmax mit der Zahl der Klassen als Breite.
Die Batchgröße verrät, wie viele Datensätze das Optimierungsverfahren im Laufe einer Iteration auf einmal verarbeitet. Je größer der Wert, desto glatter verlaufen die Loss- und Accuracy-Graphen in Tensorboard und desto schneller trainiert Tensorflow das Netz – aber desto mehr Ressourcen braucht es auch. »128« bis »1024« sind ein guter Richtwert.
Die »epochs« -Variable im Skript steht für die Anzahl der Epochen, gibt also vor, wie oft das neuronale Netz das gesamte Trainingsset lernt. Unser Netz konvergierte meist nach 500 Iterationen. Hier bietet es sich an, einen höheren Wert einzusetzen. Sobald sich der Verlust nicht mehr ändert, kann der Entwickler das Training auch vorzeitig manuell abbrechen. Um ein Netz zu trainieren, ruft er
python dnn.py train experiment
auf, wobei »experiment« der Name einer Funktion ist, die der Entwickler zuvor in der Datei »experiments.py« angelegt hat. Während des Trainings erscheinen direkt im Terminal der aktuelle Loss und die Genauigkeit sowohl zu den Trainings- als auch den Validierungsdaten. Tensorboard stellt die Werte als Graph dar. Es lässt sich über
tensorboard --logdir=/tmp/tflearn_logs/
starten. Das Webinterface ruft der Benutzer im Browser gewöhnlich über die URL »http://127.0.0.1:6006« auf. Hinter dem Eintrag »Events« verbergen sich die geplotteten Graphen zu Genauigkeit und Verlust. Unter »Runs« wählt der Nutzer die Experimente aus. Die Daten aktualisieren sich gewöhnlich alle 120 Sekunden automatisch, über den Button rechts oben aktualisiert er sie auf Wunsch auch manuell.
Hat er eine gute Konfiguration gefunden und ist mit der Genauigkeit des Netzes zufrieden, prüft der Entwickler über
python dnn.py evaluate experiment
wie gut das Netz die noch unbekannten Testdaten erkennt, um seine Generalisierungsfähigkeit zu testen. Um neue Datensätze zu klassifizieren, muss er sie auch in einer CSV-Datei ablegen und über
python dnn.py predict experiment Input
aufrufen. Das Netz klassifiziert die Daten und gibt zeilenweise die Wahrscheinlichkeiten für die entsprechenden Klassen aus. In unserem Fall beschreibt der erste Wert pro Zeile die Wahrscheinlichkeit, dass der Nutzer gute Absichten verfolgt, und der zweite die, dass es sich um einen Spammer handelt.
Ausblick
Doch es gibt auch Grenzen des Verfahrens. Obwohl neuronale Netze beliebig komplexe Funktionen annähern, kann es passieren, dass Optimierungsverfahren nicht die optimale Lösung finden. In diesem Fall erreicht das trainierte Netz nur eine geringe Genauigkeit. Ein weiteres potenzielles Problem verursachen unausgewogene oder widersprüchliche Trainingsdaten, in denen beispielsweise ganz zufällig nur die Spammer Bindestriche in ihren Namen tragen. Bei großen Netzen besteht zudem die erwähnte Gefahr des Overfitting, bei dem das Netz die Trainingsdaten auswendig lernt und nur schlecht auf neue, noch unbekannte Daten anschlägt.
Trotz der Grenzen prüfen wir mit der oben beschriebenen Methode deutlich mehr Seiten als zuvor, weil das Netz potenzielle Spammer bereits vorsortiert. Manuelle Klassifizierungen sammeln wir, um sie dem Netz später wieder in Form von Trainingsdaten zuzuführen und es so zu verbessern.
Wer selbst mit neuronalen Netzen experimentieren möchte, findet auf der Heft-DVD des Linux-Magazins neben den Listings eine CSV-Datei mit generierten Beispieldaten, ähnlich denen, die der Artikel nutzt. Mit der in Listing 5 angegebenen Beispielkonfiguration erreicht ein Deep-Learning-Anwender nach etwa 300 Epochen 98 Prozent Genauigkeit mit den Validierungsdaten und 96,5 Prozent mit den Testdaten. Vielleicht gelingt es einem Leser ja, mit dem Wissen aus dem Artikel die Konfiguration zu verbessern und den Wert zu überbieten.
Infos
- Alle Listings zum Artikel online: https://www.linux-magazin.de/static/listings/magazin/2016/12/machine_learning/
- Homepage-Baukasten: http://www.homepage-baukasten.de
- Wolfgang Ertel, “Grundkurs Künstliche Intelligenz”, 2008
- Tensorflow: https://www.tensorflow.org
- “Tensorflow: Large-scale machine learning on heterogeneous systems” (2015): http://download.tensorflow.org/paper/whitepaper2015.pdf
- TF-Learn: http://tflearn.org
- Sebastian Mogilowski, Markus Feilner, Kristian Kißling, “Passender Anstrich”: Linux-Magazin 11/2016, S. 86ff.
- Stanford CS Class CS231n: Convolutional Neural Networks for Visual Recognition: https://cs231n.github.io
- Bengio, Yoshua, “Practical recommendations for gradient-based training of deep architectures”: Neural Networks, Tricks of the Trade, 2012, S. 437-478
- Overfitting: https://www.ibm.com/developerworks/community/blogs/jfp/entry/Overfitting_In_Machine_Learning
- Tensorflow installieren: https://www.tensorflow.org/versions/r0.10/get_started/os_setup.html#pip-installation
- TF-Learn installieren: http://tflearn.org/installation/
Der Autor

Chris Hinze studiert an der Universität Erlangen-Nürnberg Informatik und arbeitet bei der Benjamin Lochmann New Media GmbH als Webentwickler. Dort beschäftigt er sich mit Backends für Smartphone-Apps und hat an der automatisierten Spamerkennung von http://homepage-baukasten.de mitgewirkt.





