
© Ruslan Nassyrov, 123RF
Deep Learning gilt als Hype-Technologie, lässt sich aber auch im Alltag einsetzen und löst nicht nur Automatisierungsaufgaben der Industrie. Gimp-Nutzer Sebastian Mogilowski zeigt in diesem Artikel, wie er mit Hilfe neuronaler Netze seine alten Schwarz-Weiß-Bilder nachträglich koloriert.
Über Go sind sie in den Fokus der Öffentlichkeit gerückt, aber neuronale Netze (NN) spielen nicht nur das traditionelle japanische Brettspiel besser als der beste menschliche Spieler. Sie lösen auch weit praktischere Aufgaben. So ermöglicht es mir ein Projekt aus Japan, mit Hilfe eines neuronalen Netzes alte Schwarz-Weiß-Fotos mit Farbe zu versehen – und das ganz ohne große Erfahrungen mit Bildbearbeitung.
Forscher der Universität Waseda in Tokio haben mir dabei die eigentliche Arbeit abgenommen. Sie trainierten mit einer Datenbank, die verschiedene Objekte enthält, ein Neuronenmodell darauf, die Objekte auf einem Bild korrekt zu erkennen und mit passenden Farbinformationen zu versehen. Mit Hilfe dieses Modells identifiziert das Netzwerk dann die einzelnen Bestandteile eines Bildes, etwa Bäume und Personen, und ordnet ihnen passende Farben zu.
Den Code für die auf der Siggraph 2016 [1] vorgestellte und unter Deep Learning einzuordnende Technik finden Interessierte auf Github [2]. Die Webseite der Universität [3] bietet eine wissenschaftliche Arbeit [4] zum Thema sowie einige Beispielbilder.
Neuronale Netze bestehen aus vielen Schichten, die Schritt für Schritt Informationen ausfiltern. Bei einem Bild wären das etwa die Helligkeit und die Kanten bis hin zu Schatten. Am Ende erkennt das Netz konkrete und komplexe Objekte. Siri, Google Now oder Cortana nutzen dasselbe Prinzip zur Spracherkennung.
Das Problem ist, dass jede einzelne Schicht Fehler machen kann. Beim Auswerten ihrer Daten reicht sie diese Fehler an die nächste Schicht weiter. Die im hier beschriebenen Projekt eingesetzten Convolutional Neural Networks (CNN, “gefaltete neuronale Netzwerke”, [5]) steuern allerdings dagegen.
CNN versus NN
Das Konzept dafür stammt aus der Biologie, als Vorlage dient aber nicht das menschliche Gehirn, sondern der visuelle Kortex von Katzen. Der Convolutional Layer zieht dabei die räumliche Struktur der Objekte mit in Betracht.
CNNs unterscheiden sich von herkömmlichen neuronalen Netzen durch eine andere Art des Signalflusses zwischen den Neuronen. Bei NNs wandern die Signale üblicherweise entlang des Input-Output-Kanals in eine Richtung, ohne die Möglichkeit, eine Schleife zu durchlaufen. Das ist bei CNN anders. Indem die Forscher die Bereiche, auf denen die Neuronen operieren, nicht nur überlappend, sondern auch versetzt anordnen, trägt jede Schicht zu einem zuverlässigeren Gesamtergebnis bei, was die Erkennungsrate optimiert. Das Netz identifiziert Objekte auch dann, wenn diese sich an einer anderen Position als auf den Trainingsvorlagen befinden.
Deep Learning ermöglicht es einem Computer also zu erkennen, was auf einem Bild zu sehen ist. Das klappt auch, wenn sich das Objekt auf einem Bild gegenüber dem Trainingsmodell deutlich verändert, weil es etwa vor einem anderen Hintergrund steht oder weil sich der Blickwinkel auf das Objekt oder die Lichtverhältnisse wandeln [6].
CNN bewältigen also sehr gut Aufgaben, die ein visuelles Erkennen erfordern. Das Ergebnis hängt aber stark von Qualität und Umfang der Trainingsdaten ab, wie die Beispielbilder später zeigen.
Das in Abbildung 1 dargestellte Modell besteht grob aus vier parallelisierten und kombinierten Netzwerken: Das Low-Level-Features-Netzwerk erkennt zum Beispiel Ecken und Kanten eines Bildes auch bei feiner Auflösung. Die Daten landen zum einen im Global-Features-Netzwerk, das sie erst durch vier gefaltete, dann durch drei vollständig verbundene Schichten schickt, die jeweils die Neuronen der einen mit allen der anderen Schicht verknüpfen. Das Resultat ist eine globale, 256-dimensionale Vektorrepräsentation des Bildes. Zum anderen extrahiert das Mid-Level-Features-Netzwerk Texturen aus den Daten des Low-Level-Feature-Netzwerks.
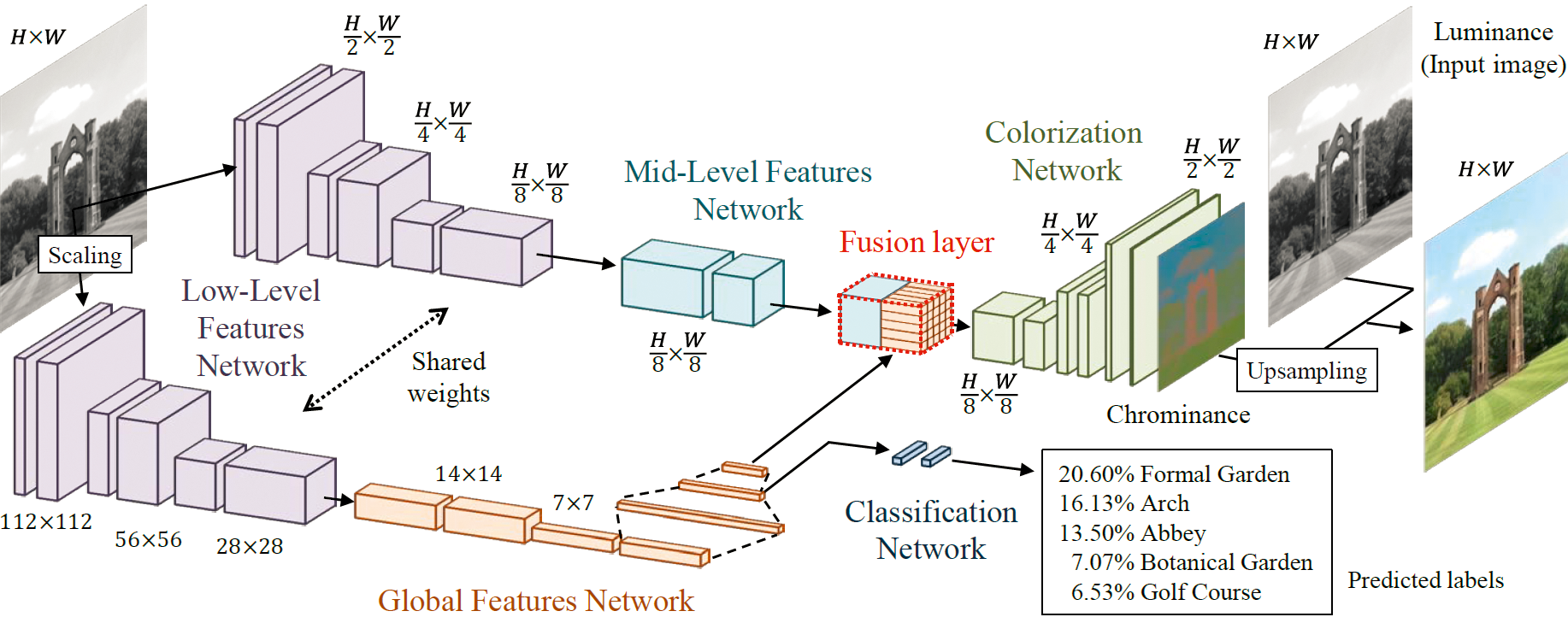
Abbildung 1: Grob gesehen besteht das verwendete Modell aus einem Netzwerk, das sich in vier funktionale Netzwerke unterteilen lässt.
Der Fusion Layer kombiniert dann die Ergebnisse des Global- und des Mid-Level-Features-Netzwerks, die Resultate sind dank der Vektorisierung auflösungsunabhängig. Zuletzt ergänzt das Colorization-Netzwerk noch Farbinformationen (Chrominanz) und Leuchtdichte (Luminanz) und stellt die Auflösung des Ursprungsbildes wieder her.
Das Ende-zu-Ende-Netzwerk führt also globale und lokale Eigenschaften von Bildern zusammen und prozessiert sie in beliebiger Auflösung. Legt das Global Features Network dabei nahe, dass es sich um eine Außenaufnahme handelt, orientiert sich das Local-Features-Netzwerk eher an Farben aus der Natur.
Nicht nur graue Theorie
Aus der Theorie kann ich als Anwender aber auch praktischen Nutzen ziehen. Mit Hilfe der japanischen Forscher und der Bildverarbeitung Gimp lasse ich meine Schwarz-Weiß-Bilder kolorieren. Das setzt jedoch einen leistungsstarken Computer mit einer halbwegs aktuellen Grafikkarte voraus.
In meinem Test für das Linux-Magazin kam Ubuntu 16.04 mit Gnome-Desktop zum Einsatz, in erster Linie, weil auch die Forscher aus Japan mit diesem System (allerdings in Version 14.04) arbeiten. So ließen sich die wenigsten Probleme erwarten. Nachahmer installieren zunächst Git, Gimp und den Lua-Paketmanager Luarocks:
sudo apt-get install git gimp luarocks
Mit nur unwesentlich mehr Aufwand spielen sie dann Torch [7] ein, Facebooks Deep-Learning-Bibliothek. Die ist in Lua [8] geschrieben und steht unter der BSD-Lizenz. Sie stellt Algorithmen für Deep Learning bereit und lässt sich dank Lua einfach installieren.
Weil es C-Backends und eine Matlab-ähnliche Umgebung verwendet, stößt Torch insbesondere bei wissenschaftlichen Projekten auf große Gegenliebe. Außerdem beinhaltet es bereits Pakete, um grafische Modelle und Bildverarbeitung zu optimieren. Das zugehörige »nn« -Paket erzeugt nicht nur neuronale Netze, sondern stattet diese auch mit diversen Fähigkeiten aus.
Torch lässt sich aus Github klonen, auf der Heft-DVD befindet sich ebenfalls ein aktueller Schnappschuss. Am Ende gilt es, das mitgelieferte Install-Skript auszuführen:
git clone https://github.com/torch/distro.git ~/torch --recursivecd ~/torch bash install-deps ./install.sh
Der Schritt ergänzt Torch auch als »PATH« -Variable in der ».bashrc« , wobei der User die Bash neu starten sollte. Nun holt er noch Lua-Pakete auf den Rechner:
luarocks install nn luarocks install image luarocks install nngraph
Damit sind die Vorarbeiten bereits in trockenen Tüchern.
Im folgenden Schritt widme ich mich der eigentlichen Kolorierungssoftware. Die lässt sich über »git clone« von Github [2] herunterladen, ich spiele sie mit dem mitgelieferten Skript namens »download_model.sh« auf meinen Rechner:
cd ~ git clone https://github.com/satoshiiizuka/ siggraph2016_colorization.gitcd siggraph2016_colorization ./download_model.sh
Für den ersten Versuch habe ich das Bild »test1.jpg« in den Ordner »siggraph2016_colorization« kopiert. Dabei handelt es sich um den Scan eines Fotos mit 638 mal 638 Pixeln. Ich schnitt das Bild quadratisch zu, weil das neuronale Netz auf quadratische Bilder trainiert ist. Dann übergab ich es dem Kolorierungsskript:
th colorize.lua test1.jpg test1_color1.jpg
Das noch nicht so überzeugende erste Ergebnis zeigt Abbildung 2. Die Ursache liegt womöglich darin, dass das CNN Bilder in der Größe 224 mal 224 verarbeitet. Außerdem besteht meine Bildvorlage nicht wirklich aus Graustufen.

Abbildung 2: Ein erster Kolorierungslauf bringt eher wenig, denn das Bild ist noch nicht für die Kolorierungssoftware optimiert.
Für den nächsten Versuch habe ich das Bild mit Hilfe von Gimp in Graustufen umgewandelt (»Image | Mode | Grayscale« ), was zu keiner sichtbaren Änderung führte. Also verkleinerte ich das Bild auf 224 mal 224 Pixel, ohne es aber grau zu skalieren. Das verschlechterte die Auflösung, aber verbesserte zumindest die Farbgebung. Am Ende stellte ich zugleich Graustufen ein und verkleinerte das Bild auf 224 mal 224 Pixel (Abbildung 3). Doch wie übertrage ich die deutlich besseren Farbinformationen auch auf Bilder in höherer Auflösung?

Abbildung 3: Mit Graustufen und skaliert auf 224 mal 224 Pixel: Besser Farbgebung – miese Auflösung. Hier hilft Gimp.
Neue Ebene
Mit Gimp lässt sich das Bild in ein Lab-Farbmodell [9] zerlegen. Dabei unterteilt Gimp es in drei Ebenen: Eine »L« -Ebene für die Leuchtkraft (Luminanz), eine »a« -Ebene für die Farbtöne zwischen Grün und Rot sowie eine »b« -Ebene für die Farben zwischen Blau und Gelb [10].
Die Idee ist, das große und das kleine Bild jeweils in diesen Farbraum zu zerlegen. Anschließend will ich die Ebenen »a« und »b« des kleinen Bildes auf die Auflösung des großen Bildes skalieren und auf dieses übertragen. Füge ich die Ebenen wieder zusammen, erhalte ich das große Bild mit den Farbinformationen des kleinen Bildes.
Dazu öffne ich im ersten Schritt jeweils das eingefärbte kleine und das große Bild in Gimp. Über »Colors | Components | Decompose« rufe ich ein Menü auf, um das Bild zu zerlegen, und suche »LAB« als Farbmodus aus (Abbildung 4). Die Option, um das Bild in Ebenen zu zerlegen, sollte vorausgewählt sein.
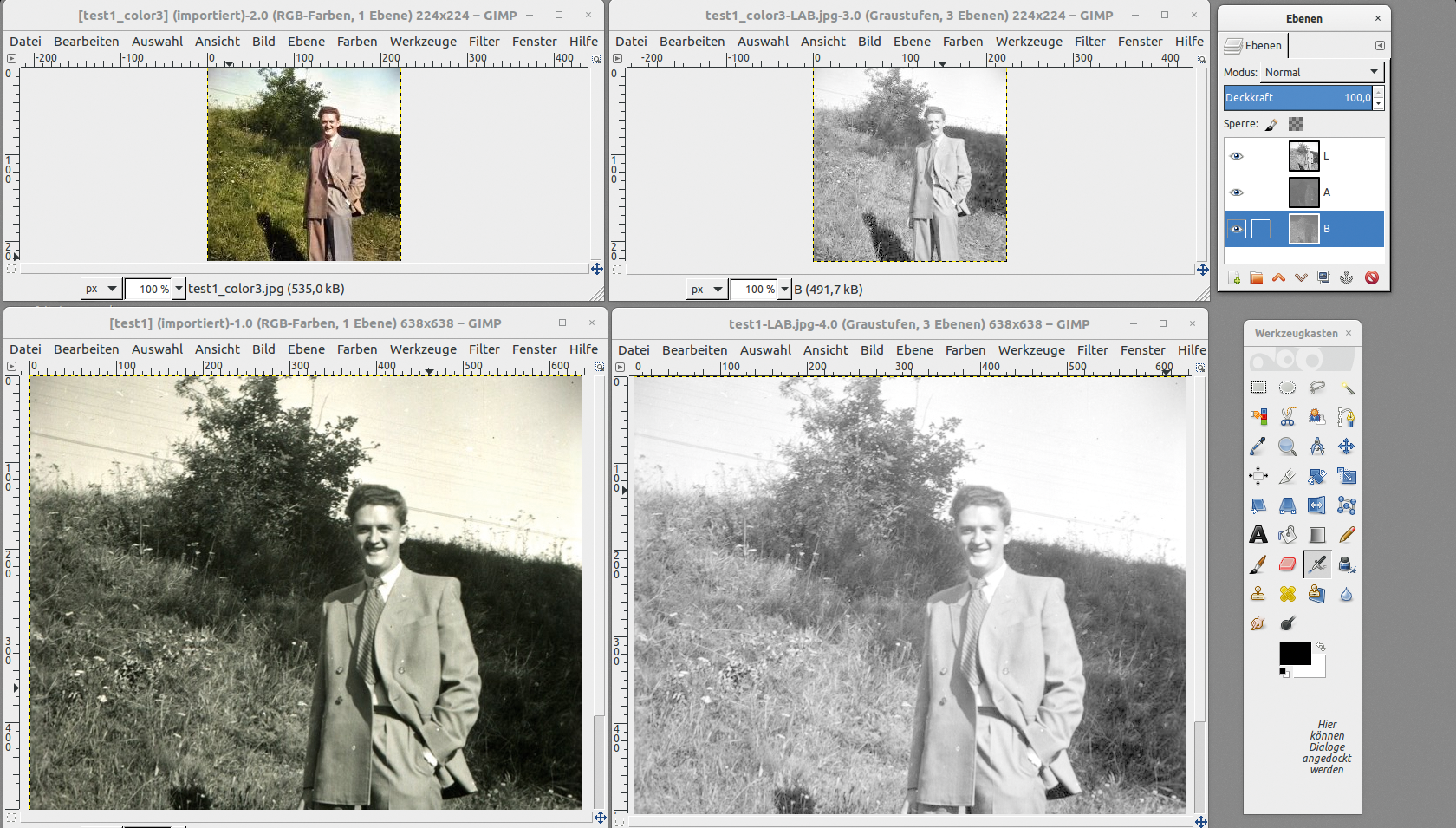
Abbildung 4: Oben links erscheint das kleine Bild im Original, daneben die per Gimp extrahierten Lab-Farbebenen.
Im nächsten Schritt aktiviere ich vom kleinen Bild die »a« -Ebene und skaliere diese mit Hilfe eines Rechtsklicks und »Ebene skalieren« auf eine größere Auflösung. Ich klicke die Ebene mit der Maus an und kopiere sie über [Strg]+[C]. Anschließend wähle ich das große Bild aus und füge die Ebene in den »Ebenen« -Dialog ein.
Indem ich auf das Anker-Symbol am unteren Rand des »Ebenen« -Dialogs klicke, bette ich die »Schwebende Auswahl« fest ein und wiederhole das Prozedere mit der »b« -Ebene. Am Ende führe ich über »Farben | Komponenten | Wieder zusammenfügen« die Farbebenen wieder zusammen. Das Ergebnis: Ein Bild in höherer Auflösung mit den Farbinformationen des kleineren Bildes. Zum Vergleich zeigt Abbildung 5 noch einmal das Graustufen-Bild als Ausgangsbasis.

Abbildung 5: Aus einem Graustufen-Bild macht die auf Torch basierte Kolorierungssoftware ein farbiges Foto, wenn auch nicht in Perfektion.
Verfärbungen
Das Ergebnis lässt Raum für manuelle Nachbesserungen. So ist die linke Hand farblich Teil der Wiese und einem Hosenbein fehlt die Farbe. Die Mängel leiten dabei auch direkt zum Thema Grenzen des Verfahrens über. Bei Bildern mit sehr vielen unterschiedlichen Farben funktioniert die Farbgebung nicht oder nur eingeschränkt. Die Software versucht dann, einen Durchschnittswert zu berechnen und vermutet, dass die Farben sich ähneln. Heraus kommt mitunter ein farbiger Brei.
Auch kann das CNN Farben nicht erraten. Das bedeutet: Stößt es auf einem Schwarz-Weiß-Foto auf einen noch nicht klassifizierten Gegenstand, etwa ein Zelt [11], rät sie dessen Farbe auf Basis der dominierenden Farben – und liegt unter Umständen komplett daneben. Immerhin erzielt das Modell laut Studie “natürlich aussehende” Ergebnisse [4].
Als weiteres nützliches Deep-Learning-Projekt im Bildbereich sei noch das neuronale Netzwerk der Chinese University of Hong Kong erwähnt, das Personen auf Fotos freistellt [12]. Das dort demonstrierte Verfahren ist nicht perfekt, liefert aber bessere Ergebnisse als die in aktuelle Bildbearbeitungsprogramme integrierten Funktionen. Auch hier kommt ein CNN zum Einsatz.
Infos
- Siggraph 2016: http://s2016.siggraph.org
- Github-Repository des Projekts: https://github.com/satoshiiizuka/siggraph2016_colorization
- Projekt-Webseite: http://hi.cs.waseda.ac.jp/~iizuka/projects/colorization/en/
- Wissenschaftliche Arbeit zum Projekt: http://hi.cs.waseda.ac.jp/~iizuka/projects/colorization/data/colorization_sig2016.pdf
- Convolutional Neural Networks: https://annalyzin.wordpress.com/2016/01/26/introduction-to-convolutional-neural-network/
- CNN-Klassifizierungen: http://cs231n.github.io/classification/
- Torch: http://torch.ch
- Lua: https://www.lua.org
- Lab-Farbmodell: https://docs.gimp.org/de/glossary.html#glossary-lab
- Gimps Decompose-Plugin: https://docs.gimp.org/de/plug-in-decompose-registered.html
- Projektpräsentation: http://hi.cs.waseda.ac.jp/~iizuka/projects/colorization/data/IizukaSIGGRAPH2016_slide.pdf
- Bilder mit Deep Learning freistellen: http://www.cse.cuhk.edu.hk/leojia/papers/portrait_eg16.pdf





