
© Prasit Rodphan, 123RF
Container lösen in vielen Bereichen klassische Paravirtualisierung ab. Auch die Cloudlösung Open Stack ist davon betroffen. Mehrere Ansätze ermöglichen den Betrieb von Containern in der Cloud.
Über Jahre hinweg wurden die Begriffe Virtualisierung und Paravirtualisierung fast synonym gebraucht: Wer sich mit Virtualisierung beschäftigte, landete entweder bei KVM oder Xen auf der Open-Source-Seite oder mit VMware & Co. bei proprietären Produkten. Daneben gab es zwar schon lange Container, sie führten aber eher ein Schattendasein.
Das änderte sich mit dem kometenhaften Aufstieg Dockers. Seitdem sind Linux-Container eine ernste Alternative zur Paravirtualisierung. Die Vorteile liegen auf der Hand: Kunden brauchen für die gleiche Dienstleistung weniger Ressourcen – und Dienstleister können mit derselben Menge Hardware mehr Kunden bedienen. Kein Wunder also, dass die Nachfrage steigt.
Leicht zeitversetzt wirkt sich diese Entwicklung auch aufs Cloud Computing und die damit verbundenen Programme aus. Open Stack etwa hat den Trend hin zu Containern eine ganze Weile tapfer ignoriert – um sich des Themas letztlich doch noch anzunehmen. Verschiedene Entwicklungen belegen das: Einerseits haben die Entwickler ihre Arbeit am Docker-Treiber [1] für Open Stack wieder aufgenommen, sodass sich Docker-Container direkt aus Open Stack heraus verwalten lassen.
Auch auf anderen Ebenen spielen Container eine Rolle: Magnum [2] soll sich als eine eigenständige Komponente um die effiziente Verwaltung von Docker-Containern oder Kubernetes-Installationen direkt aus Open Stack heraus kümmern. Da fragt sich der verwirrte Admin: Welche Container-Optionen bietet Open Stack denn nun tatsächlich und wie gut funktionieren sie? Dieser Artikel gibt Antworten auf die drängendsten Fragen und verschafft einen Überblick über die aktuelle Situation.
Warum Container wichtig sind
Container bieten gegenüber Paravirtualisierung etliche Vorteile. Weil kein kompletter Computer mehr nachzubilden ist, entfallen diverse Komponenten, die bei Paravirtualisierung zusätzliche Ressourcen schlucken: Allein die Tatsache, dass in Containern kein eigener Kernel läuft, wirkt sich merklich auf den Ressourcenbedarf aus. Der ist in der Folge deutlich geringer als bei den paravirtualisierten Systemen.
Fast noch wichtiger ist Dockers Ökosystem, denn bei Docker steht die Virtualisierung nicht so sehr im Fokus. Der Grund für die große Popularität der Lösung ist eher ihre Vielseitigkeit: Entwickler können ihre Applikation zum Beispiel in Form fertiger Container verteilen, die auf jedem Docker-fähigen System laufen.
Ein anderes Paradebeispiel ist Googles Kubernetes: Die Lösung, um sinnvoll Container in einem Netz zu verteilen und zu orchestrieren, erfreut sich größter Beliebtheit in der Community und bei Unternehmen. Anwender fragen regelmäßig nach Möglichkeiten, um sowohl Docker als auch Kubernetes (oder das Docker-Gegenstück Docker Swarm) in Open Stack zu betreiben – weil sie von eben jenem Ökosystem profitieren wollen.
Blick auf die Technik
Dem Hype rund um Docker und Kubernetes steht die Technik entgegen, mit der es der Admin im Rechenzentrum üblicherweise zu tun bekommt. Open Stack hat sich zum Branchenprimus in Sachen Cloud entwickelt, bis dato setzte die Lösung aber vornehmlich auf Paravirtualisierung. Zwar gehört auch Support für Xen und KVM seit der ersten Open- Stack-Version fest zum Lieferumfang, in Sachen Docker oder Kubernetes ging es aber deutlich langsamer voran.
In der aktuellen Version (Mitaka) der Virtualisierungskomponente Nova fehlt bis heute jede Unterstützung für Docker. Die Image-Komponente Glance kann zwar im Docker-Format gespeicherte Container verwalten. Eine Open-Stack-Cloud, die auf der Standard-Distribution von Open Stack beruht, hat von Containern aber erst mal keine Ahnung und kann diese auch nicht starten.
Im Laufe der Projektgeschichte gab es in Open Stack gleich mehrere Versuche, das Problem zu lösen. Die prominentesten Beispiele sind einerseits der Docker-Treiber für Nova und andererseits LXD, das Canonical eigens für Container in Open Stack erfunden hat. Beide Lösungen haben aber spezifische Nachteile.
Nova-Docker: Eine bewegte Geschichte
Open Stack bietet als Cloudlösung zwei Dienste hauptsächlich an: einerseits Virtualisierung von Rechenleistung, andererseits On-Demand-Speicher nach dem Vorbild von Dropbox oder Google Drive. Beim Thema Virtualisierung versteht sich die Lösung als Framework. Entsprechend konfiguriert verwaltet sie einen Pool von Ressourcen (CPU, RAM, Plattenplatz) und bietet über APIs den Nutzern die Möglichkeit, Teile dieser Ressourcen ad hoc und nach Bedarf zu verwenden. Dazu gehört die umfassende Verwaltung virtueller Systeme: Nova weist im Beispiel der KVM-basierten Cloud etwa einzelne Rechner dazu an, per Libvirt VMs zu starten.
Der erste, logische Ansatz für Container in Open Stack ist folglich die native Integration von Containern in die VM-Verwaltung von Nova. So wie Nova also per Libvirt KVM-VMs startet, soll es im Container-Beispiel Docker-Container auf den einzelnen Hosts direkt aufrufen. Nova ist intern modular aufgebaut, verschiedene Virtualisierungslösungen lassen sich über Nova-Treiber anbinden. Damit Nova und Docker miteinander sprechen, ist also ein Docker-Treiber für Nova nötig.
Ein entsprechendes Projekt gibt es tatsächlich: Der Nova-Docker-Treiber [1] existiert seit Jahren und hat eine bewegte Geschichte hinter sich. Anfangs war er direkt in Nova integriert und damit offizieller Teil von Open Stack. Weil er den Qualitätsansprüchen der Open-Stack-Entwickler aber nicht gerecht wurde, flog er bald wieder raus und wird seither als separates Projekt weiterentwickelt. Die mangelnde Qualität machten die Entwickler an technischen Problemen fest.
Mit der Brechstange
Einerseits steht der Nova-Docker-Treiber vor der schwierigen Aufgabe, dass er verschiedene Grundsätze aus der Open-Stack-Welt mit Grundsätzen aus der Welt von Docker-Containern unter einen Hut bringen muss. Dazu gehören Images: Erst seit relativ kurzer Zeit ist der Treiber in der Lage, Abbilder aus Glance zu lesen, also aus der Open-Stack-eigenen Image-Verwaltung (Abbildung 1).
Abbildung 1: Der Open-Stack-Imagedienst Glance beherrscht mittlerweile auch Docker-Container.
Vorher mussten Admins auf allen Docker-Hosts Container selbst ausrollen, wenn sie auf Basis dieser Container-Abbilder gestartet werden sollten. Der Admin baute im Schatten von Glance also quasi eine zweite Image-Verwaltung auf. Das ist jetzt nicht mehr nötig, denn der Nova-Docker-Treiber redet heute direkt mit Glance und lädt in Glance hinterlegte Container auf Ziel-Hosts, auf denen ein neuer Container zu starten ist.
Auch auf der Programmier-Ebene gibt es Probleme: Wer etwa nicht das Standard-SDN in Open Stack nutzt, ist auf einen speziellen Treiber der SDN-Lösung für den Nova-Docker-Treiber angewiesen. Doch weil der bis heute nicht wieder offizieller Teil von Nova geworden ist, bieten die meisten Hersteller von SDN-Lösungen einen entsprechenden Nova-Docker-Treiber nicht an. Im schlimmsten Falle muss ein Unternehmen, das Docker-Container direkt in Open Stack betreiben möchte, sich einen passenden Treiber also selber bauen.
Hinzu kommen schließlich Probleme bei der Containerverwaltung im Docker-Open-Stack-Gespann: Ein Mischbetrieb von KVM und Docker in derselben Open-Stack-Cloud erfordert einige Konfigurationsarbeit und funktioniert am Ende trotzdem nicht zuverlässig.
Der native Betrieb von Docker-Containern in Open Stack gibt also ein eher trauriges Bild ab: Schon die Installation des Treibers wird mangels entsprechender Pakete zur Bastelarbeit, die sich beim Thema SDN fortsetzt. Im Grunde will Docker selbst einen großen Teil der Aufgaben erledigen, für die sich auch Open Stack zuständig fühlt. Diese Kollision der Interessen beider Projekte lässt darauf schließen, dass native Integration von Docker-Containern in Open Stack eigentlich als gescheitert gelten muss.
LXD als Rettung
Auch Canonical kennt das Problem und stieg vor zwei Jahren mit LXD selbst in den Containermarkt ein. LXD beruht auf einem simplen Prinzip: Die Technik nutzt im Hintergrund die gleichen Funktionen wie Docker, bietet aber auch eine echte Schnittstelle für Lösungen wie Open Stack auf der anderen Seite.
Bei laufendem LXD, so das Versprechen von Canonical, lassen sich LXD-Container genauso ohne Probleme aus Open Stack heraus starten wie die paravirtualisierten KVM-Varianten. Und Canonical hat Wort gehalten: Der LXD-Hypervisor-Treiber für Nova ist seit einigen Versionen in das Open-Stack-Modul integriert, sodass viele Probleme der Docker-Variante gar nicht erst aufgetreten sind.
Den Markt umkrempeln konnte LXD aber nicht: Die Lösung fristet heute eher ein Nischendasein, auch weil die anderen Distributoren auf den Zug nicht aufgesprungen sind. Am Ende sieht der Admin sich also mit einer Containerlösung für Open Stack konfrontiert, für die es praktisch kein eigenes Ökosystem gibt. Hier funktioniert die Technik, aber es scheitert an der Unterstützung durch mehrere Firmen und eine Community.
Oft nachgefragt:Container in VMs
Unternehmen fragen oft nach Containern in der Cloud. Ganz konkret geht es dann um Docker, das ein Unternehmen unbedingt nutzen will. Für Admins ist das aus den oben genannten Gründen ein Problem, denn mit dem Nova-Docker-Treiber ist kein Blumentopf zu gewinnen. Die Docker-Unterstützung ganz auszulassen stellt aber auch nicht zufrieden.
In den vergangenen Jahren hat sich deshalb ein Mittelweg etabliert: Er verlagert den Betrieb der Container vom Host in eigens für diesen Zweck gestartete VMs. Jene VMs setzen dann auf eine der klassischen Techniken für die Paravirtualisierung, deren Handhabung Open Stack problemlos beherrscht. Auf den physischen Hosts der Cloud läuft dann wie gehabt eine paravirtualisierte virtuelle Maschine, die letzten Endes die Container beherbergt.
Zwar büßt der Admin bei diesem Ansatz einen Teil des Ressourcengewinns wieder ein, mit dem Containervirtualisierung eigentlich einhergeht. Im Gegenzug erhält er aber kompletten Zugriff auf sämtliche Features, die Lösungen wie Docker und Kubernetes bieten.
Fast allen Cloudanbietern ist dieser Vorteil den Overhead wert. Und weil es technisch kein Problem darstellt, aus der Open-Stack-Infrastruktur heraus das Geschehen in VMs der Cloud direkt zu beeinflussen, lässt sich die Verwaltung von Containern in VMs sogar direkt in die Verwaltung der Cloud einbauen. Genau darum kümmert sich ein eigenes Projekt: Open Stack Magnum [2].
Um zu verstehen, wofür Magnum überhaupt gut ist, stellt man sich am besten den Workflow der Arbeit mit Containern in einer klassischen Open-Stack-Cloud vor. Die Idee, Container in paravirtualisierten Open-Stack-VMs zu starten, ist an sich ja nicht spektakulär: Der Admin startet in einem solchen Fall einfach eine gewöhnliche VM, richtet darin die für Docker benötigten Komponenten her und betreibt anschließend in dieser VM seine Container. Genau das war freilich schon bisher problemlos möglich.
Die Idee
All diese Schritte bedingen allerdings einige Handarbeit: Damit aus einem nackten Ubuntu-Cloud-Abbild ein Docker-Host für den Containerbetrieb wird, sind einige Kommandozeilenbefehle nötig. Der Lohn der Arbeit ist eine zweite Verwaltungsebene: Fortan muss der Admin sich nicht nur um die VM kümmern, die in Open Stack läuft, sondern auch um die Container darin. Außerdem vermag er die Container von außerhalb der VM nicht zu steuern, das kann nur direkt auf dem Docker-Host der VM geschehen.
Ein Teil der Arbeit lässt ich aber wegautomatisieren: Heat ermöglicht das automatisierte Starten von VMs mit einer entsprechenden Konfiguration auch für viele VMs gleichzeitig. Eine Hürde bleibt bei diesem Ansatz allerdings unüberwindbar: Weil Open Stack nicht weiß, was innerhalb der VMs läuft, kann es die darin laufenden Container auch nicht als Ressourcen selbst verwalten.
Magnum macht Container zu Ressourcen
Genau an dieser Stelle setzt Open Stack Magnum an. Seine Entwickler sprechen etwas vollmundig davon, dass Magnum Container in Open-Stack-VMs zu “First Class Ressources” mache. Der Begriff ist zwar nicht formal definiert, die allgemeine Erwartung an solche Ressourcen in Open Stack ist aber, dass sie sich auch direkt aus der Cloudverwaltung heraus steuern und administrieren lassen. Magnum baut also die Brücke zwischen der Verwaltung von Open Stack auf der einen und Containern in Open-Stack-VMs auf der anderen Seite.
Im Kontext einzelner Container werden die Vorteile dieses Prinzips gar nicht so schnell offensichtlich, wohl aber wenn die Rede nicht mehr von einzelnen Containern, sondern von Containerverbünden ist. Konkret richtet sich Magnum also auch an Admins, die Docker Swarm oder Googles Kubernetes nutzen wollen. Die sollen letztlich davon profitieren, dass sie ganze Containergespanne per Mausklick aus der Open-Stack-Umgebung heraus genauso starten und verwalten können, als handele es sich um echte, native Open-Stack-VMs (Abbildung 2).
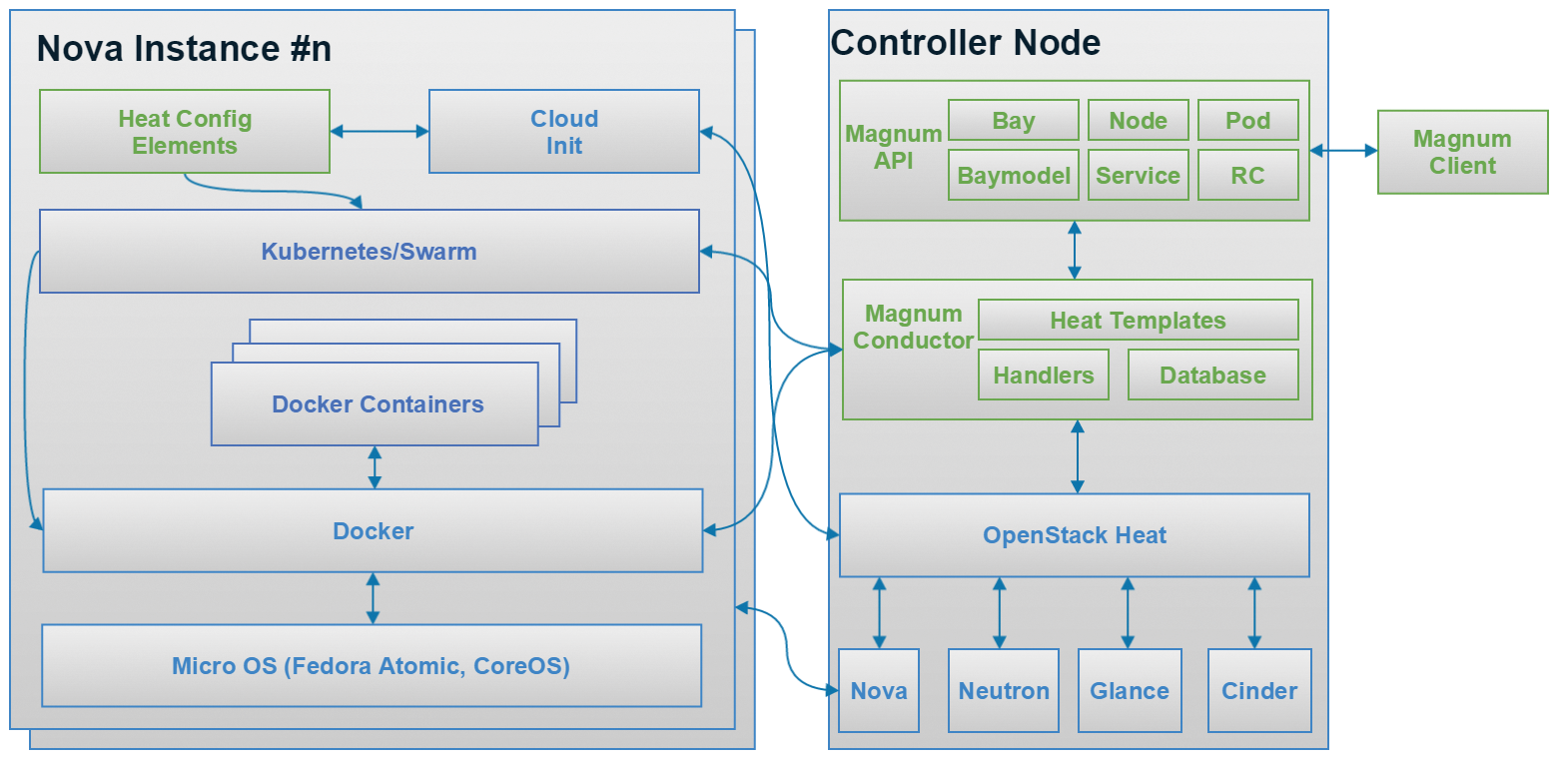
Abbildung 2: Open Stack Magnum integriert sich vollständig in Open Stack und bietet Container, die in paravirtualisierten VMs laufen, als Ressource in Open Stack.
Der technische Unterbau
Was im Prospekt leicht aussieht, bedingt, dass unter der Haube eine Vielzahl von Komponenten zusammenarbeiten. Wie üblich besteht Magnum aus mehreren Komponenten. Die sichtbare Komponente ist das Magnum-API: Magnum folgt hier dem Beispiel praktisch aller anderen Open-Stack-Komponenten und ermöglicht es Nutzern, per Restful-API Befehle an die Lösung zu senden. Das ist wahlweise über den Magnum-Client auf der Kommandozeile oder das Open-Stack-Dashboard zu erledigen (Abbildung 3), für das es ebenfalls ein eigenes Magnum-Modul gibt.
Abbildung 3: Weil Magnum auf vorhandene Open-Stack-Komponenten zurückgreift, ist Heat maßgeblich an der Ausführung von Container-Stacks beteiligt.
Das API enthält einen großen Teil der Magnum-Intelligenz: Sie definiert alle im Containerkontext relevanten Ressourcentypen, etwa Nodes, Pods oder Dienste. Der Admin schickt dem Magnum-API im konkreten Beispiel den Befehl, einen Kubernetes-Pod mit diesen und jenen Parametern in der Open-Stack-Umgebung zu starten. Anders als Open Stack Nova kennt das Magnum-API jene Ressourcentypen und weiß, was zu tun ist.
Zur Tat schreitet das API aber nicht selbst: Das modulare Magnum-Design weist diese Aufgabe einer anderen Komponente namens Magnum Conductor zu. Auf der einen Seite erhält dieser vom API die Information, welche Ressourcen seitens des Nutzers gewünscht sind. Er führt über die vorhandenen Ressourcen Buch durch entsprechende Einträge in seiner Datenbank. Auf der anderen Seite kümmert der Conductor sich darum, dass entsprechende VMs gestartet und darin die gewünschten Container ausgerollt und konfiguriert werden.
Der Conductor erfindet für diesen Zweck das Rad aber nicht neu: Er setzt bei der Verwaltung der VMs auf Open Stack Nova. Und weil in Open Stack grundsätzlich das Prinzip “Mehr Layer!” gilt, redet er auch nicht direkt mit Nova, sondern baut aus eingehenden Requests ein Template für Open Stack. Dabei handelt es sich um die Orchestrierungskomponente von Open Stack. Zur Erinnerung: Die Idee hinter Orchestrierung in Cloudsetups ist, viele Ressourcen schnellstmöglich in automatisierter Weise anzulegen, wobei Verbindungen zwischen den Ressourcen durchaus Beachtung finden.
Ein typischer Orchestrierungs-Workflow wäre etwa das Anlegen eines privaten Netzes, das anschließend per Gateway-Ressource mit einem öffentlichen Cloudnetz verbunden wird, um schließlich eine VM mit einem Port im privaten Netz zu starten, die auch eine öffentliche IP (Floating-IP im Open-Stack-Sprech) zugewiesen bekommt. Einzeln durchgeführt würden all diese Schritte einige Zeit in Anspruch nehmen, mit einem passenden Heat-Template ist das Anlegen einer solchen VM eine Sache von Sekunden.
Mikro-Betriebssysteme
Genau diesen Vorteil nutzt auch der Magnum Conductor. Er versorgt Heat mit automatisch generierten Templates, sodass Heat schließlich die benötigten Ressourcen mit Hilfe der eigentlich zuständigen Open-Stack-Komponenten (also Glance, Neutron, Nova …) anlegen kann. Am Ende des Vorgangs entstehen in der Open-Stack-Cloud virtuelle Maschinen, die über ihr Heat-Template entsprechend vorkonfiguriert sind und Container-Ressourcen betreiben.
Open Stack Nova sieht weiterhin nur diese; anders Magnum, das auch weiß, welche Containerdienste in den VMs laufen. Komplexe Containersetups mit Kubernetes oder Docker Swarm führen nur zu komplizierteren Heat-Templates in Magnum, aus Nutzersicht lassen sich mit Magnum Container aber genauso verwalten wie einzelne Nova-VMs.
Magnum setzt auch auf Open-Stack-Bordmittel, wenn es um die Konfiguration der Nova-VMs für den Containerbetrieb geht. Es erwartet als Betriebssystem für die Container-VMs ein Mikro-OS, also etwa Atomic oder Core OS. Damit sich Magnum nutzen lässt, muss der Admin mindestens ein solches Image im Glance der Open-Stack-Cloud hinterlegen. Anders als etwa die Open-Stack-eigene DBaaS-Lösung Trove besteht Magnum aber nicht auf einem eigenen Agenten innerhalb der Ziel-VM. Stattdessen geschieht die Konfiguration über Kommandozeilenbefehle.
Auch aus Anbietersicht praktisch
In Form von Magnum erhält Open Stack eine vollständige Containerverwaltung, die sowohl Docker als auch Kubernetes sinnvoll bespielen kann. Nicht nur aus Sicht des Cloudkunden, sondern auch aus der des Cloudanbieters bietet Magnum Mehrwert. Der wichtigste Faktor ist die Tatsache, dass man sich Support für Docker und Kubernetes auf die Fahnen schreiben kann: Beide Produkte lassen eine Public Cloud auf einen Schlag sehr viel attraktiver wirken.
Anders als bei der klassischen Bastelei mit Nova-Docker lässt sich Magnum obendrein sehr leicht in eine vorhandene Open-Stack-Cloud integrieren: Es stehen nur die Installation des Magnum-API sowie des Magnum Conductor auf dem Programm. Die Dienste nutzen dieselbe Konfigurationsdatei und orientieren sich dabei an den klassischen Open-Stack-Komponenten. Der Geübte begegnet hier keinen größeren Unklarheiten.
Magnum ist aber auch aus einem ganz anderen Grund für den Anbieter sehr attraktiv. Es ermöglicht, Container-Dienstleistungen in die vorhandene Cloudinfrastruktur zu integrieren. Dadurch gehen alle Funktionen, die in einer Open-Stack-Cloud bereits vorhandenen sind, auch auf die Containerverwaltung automatisch über. Am deutlichsten gelingt das bei der Nutzerverwaltung: Open Stack bringt in Form von Keystone eine komplette Userverwaltung mit, die auch unterschiedliche Hierarchiestufen erlaubt und sich sogar an LDAP anbinden lässt.
Auch Magnum ist natürlich an Keystone angepasst, sodass sich ad hoc aus derselben Benutzerverwaltung heraus sowohl die klassische Paravirtualisierung als auch die Containervirtualisierung verkaufen lässt. Die Pflege einer separaten Nutzerdatenbank entfällt.
Murano als App-Katalog
Magnum ist übrigens nicht die einzige Möglichkeit, Container in Form virtueller Maschinen in Open Stack auszurollen. Open Stack Murano [3] bietet dies über Umwege ebenfalls: Hinter dem Codenamen verbirgt sich wiederum eine eigene Open-Stack-Komponente, deren erster Fokus aber nicht Container sind. Murano versteht sich stattdessen als Glance auf Steroiden: Die Idee hinter dem Dienst ist, dass Cloudbenutzer VMs innerhalb einer Cloud bauen und die so entstandenen VMs dann als Image einfach publizieren können (Abbildung 4).
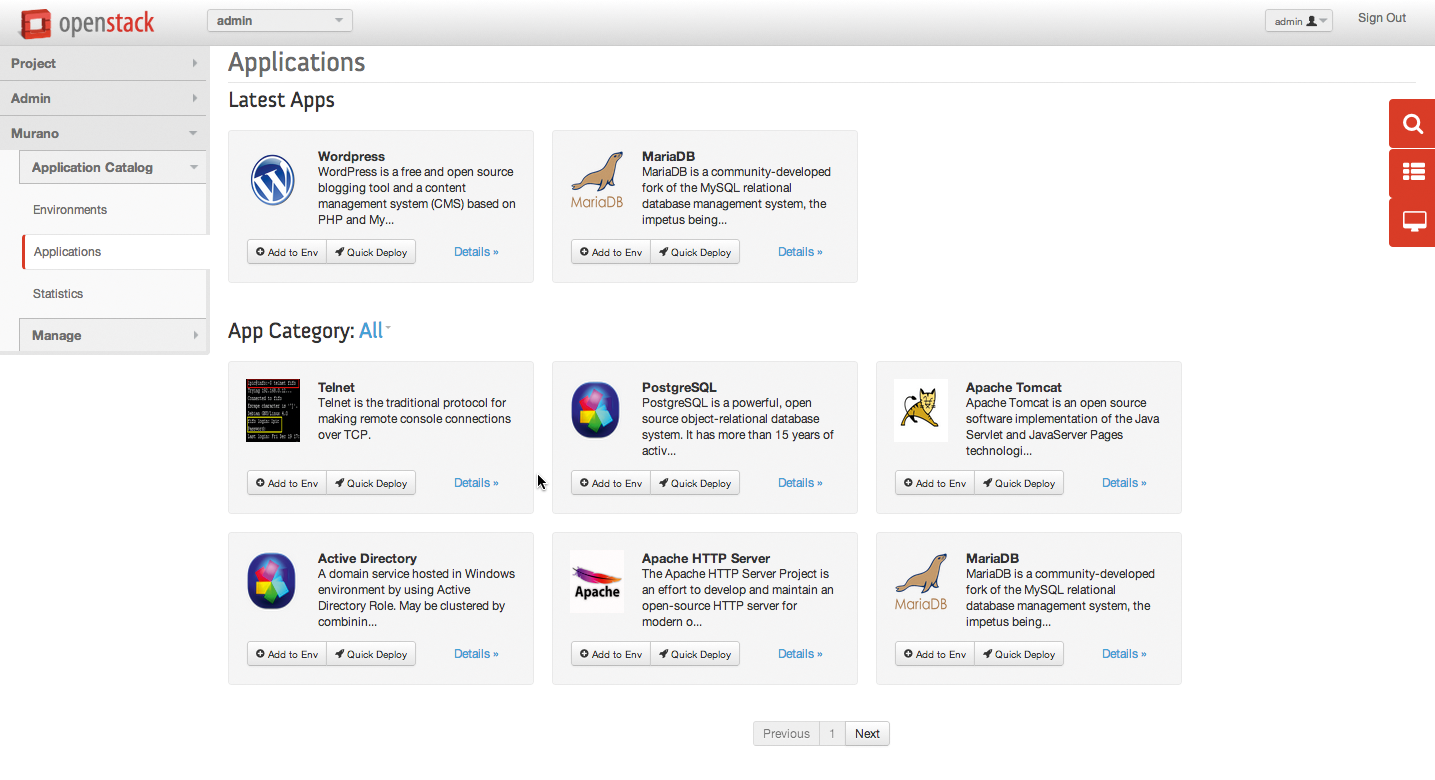
Abbildung 4: Murano ist ein Applikationskatalog für Open Stack, in dem sich auch Kubernetes findet. Vergleichbar mit dem Magnum-Featureset ist das aber nicht.
Für Kubernetes existiert bereits eine fertige Murano-Applikation, die sich über den Dienst in vorhandene Open-Stack-Clouds einbinden lässt. Allerdings bleibt bei diesem Ansatz ein großer Teil der Magnum-Funktionalität auf der Strecke. Letztlich rollt Murano nur eine Applikation in Form mehrerer VMs aus, in denen entsprechend vorkonfigurierte Container laufen. Der Management-Teil oder die Möglichkeit, einzelne Container direkt in Open Stack als Ressource zu verwalten, fallen unter den Tisch. Eine vergleichbare Lösung ließe sich sogar mit Ansible ohne zusätzliche Open-Stack-Komponente realisieren – oder auch mit Heat, wenn man sich die Zeit nimmt, ein entsprechendes Template für den Orchestrierungsdienst zu verfassen.
Fazit: Kein Widerspruch
Open Stack Magnum ist für Open-Stack-Admins eine gute Nachricht. Denn die Komponente löst ein echtes Problem: Native Docker-Container lassen sich mit Nova praktisch nicht produktiv betreiben – auf das Thema deshalb verzichten wollen allerdings die wenigsten Anbieter. Magnum zwingt die Anbieter von Public Clouds zu einem Kompromiss. Zwar laufen die Container letztlich innerhalb der VMs, weil die Entwickler nur diesen Weg für gangbar hielten, um sich Probleme mit nativen Containern vom Hals zu halten. Im Gegenzug steht in Form von Magnum aber eine gut funktionierende Komponente zur Verfügung, um Container in Open Stack zu betreiben – und die Ressourcen aus solchen Container-VMs gleich mit.
Der administrative Aufwand für die Installation der Lösung hält sich in Grenzen. Für Magnum darf das Open-Stack-Projekt sich also auf die Schulter klopfen, während Anwender sich über gut funktionierende Container-Orchestrierung in Open Stack freuen. Dass nicht absehbar ist, ob und wann Nova-Docker sinnvoll zu benutzen sein wird, schmerzt unter diesen Umständen kaum – eigentlich ist die Lösung dank Magnum überflüssig.
Infos
- Nova-Docker-Treiber: https://github.com/openstack/nova-docker
- Open Stack Magnum: https://wiki.openstack.org/wiki/Magnum
- Open Stack Murano: https://wiki.openstack.org/wiki/Murano





