
© Michal Bednarek, 123RF
Mit dem Open-Source-Framework Scrapy lassen sich eigene Crawler unter Python mit minimalem Aufwand und auf professionellem Niveau bauen. Der vorliegende Artikel zeigt eine Beispielanwendung.
Ein Crawler demonstriert die Einsatztauglichkeit des Scrapy-Framework [1] in Version 1.0 unter Python 2.7 [2]. Er wühlt sich rekursiv durch die HTML-Dokumente einer Webseite und folgt allen vorgefundenen Verlinkungen.
Tabelle 1
Definition der gespeicherten Messgrößen
|
Messgröße |
Bedeutung |
|---|---|
|
»keywords« |
Anzahl der Wörter im »<title>« -Tag |
|
»words« |
Anzahl aller Wörter außer »keywords« |
|
»relevancy« |
Häufigkeit aller Schlüsselwörter in der Menge der Wörter |
|
»tags« |
Anzahl aller Tags |
|
»semantics« |
Anzahl aller semantischen Tags |
|
»links« |
Anzahl aller »<a>« -Tags mit »<href>« -Attribut |
|
»injections« |
Anzahl fremder Ressourcen |
Sinn der Übung: Im Geiste von HTML 5 das nicht-semantische Markup in Webseiten aufspüren. Dabei misst der Crawler die pro Seite verwendeten Wörter sowie den Umfang charakteristischer Tag-Gruppen (Tabelle 1). Die Ergebnisse speichert er zusammen mit der URL in einer Datenbank ab. Die Auswertung der Messergebnisse zeigt Abbildung 1.
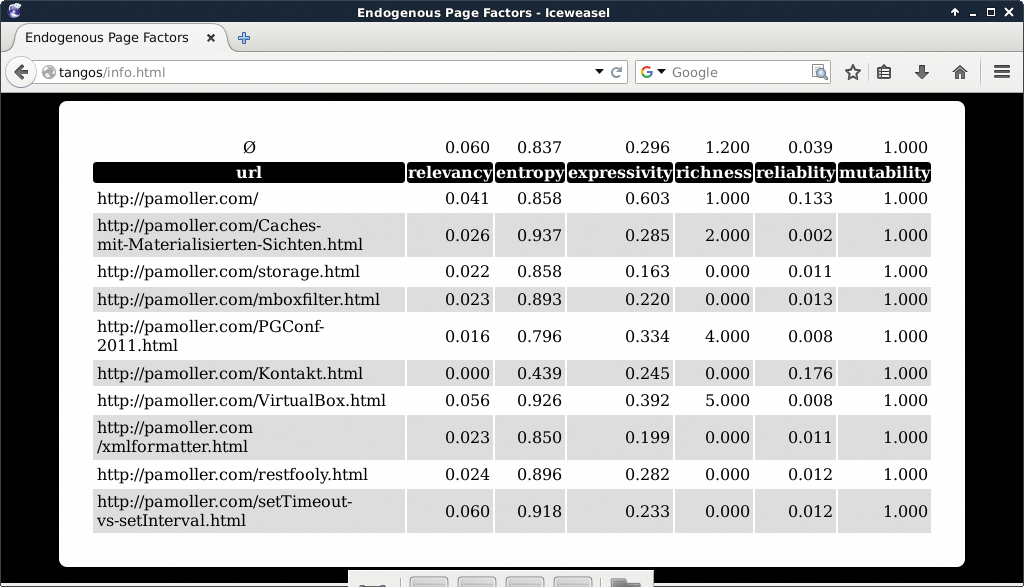
Abbildung 1: Die Seitenfaktoren auf Basis der relativen Häufigkeiten der gemessenen endogenen Größen.
Zur Installation bindet unter Debian 8 der bordeigene Paketmanager Apt die benötigten Pakete ein:
apt-get install python-pip libxslt1-dev python-dev python-lxml
Im Klartext zählen dazu Pythons Paketmanager Pip, die Bibliothek »libxslt« nebst Headerdateien, die Headerdateien von Python sowie die Python-Bindings der »libxml« und »libxslt« . Da Debian 8 Python 2.7 und die »libxml« bereits vorinstalliert, lässt sich Scrapy über
sudo pip install scrapy
einspielen. Anders als Apt installiert Pip die neueste Scrapy-Version für Python 2.7 aus dem Python Package Index [3].
Probelauf
Im ersten Schritt startet der Anwender eine interaktive Scrapy-Session in der Scrapy-Shell (Abbildung 2). Im zweiten animiert die Scrapy-Engine über das Kommando
fetch('https://www.linux-magazin.de')
den bordeigenen Downloader dazu, die Startseite des Linux-Magazins per HTTP-Anfrage zu lesen und in das Antwort-Objekt »response« zu überführen (Abbildung 3).
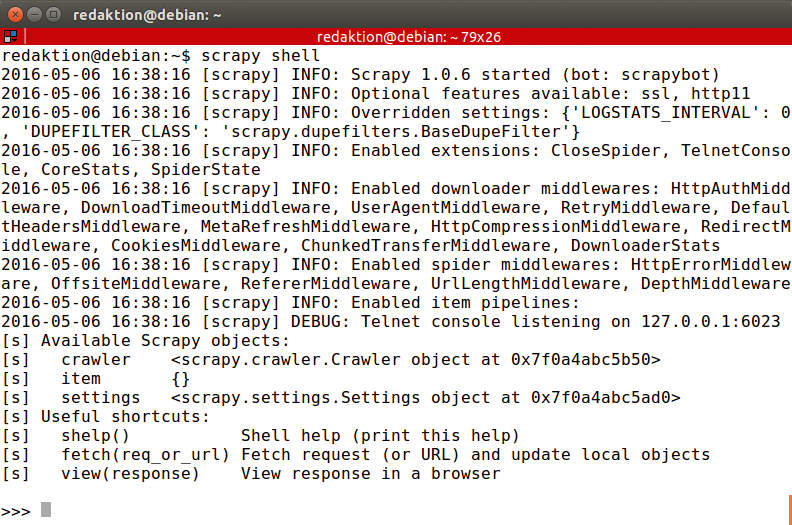
Abbildung 2: Mit der Scrapy-Shell lassen sich Befehle interaktiv testen.
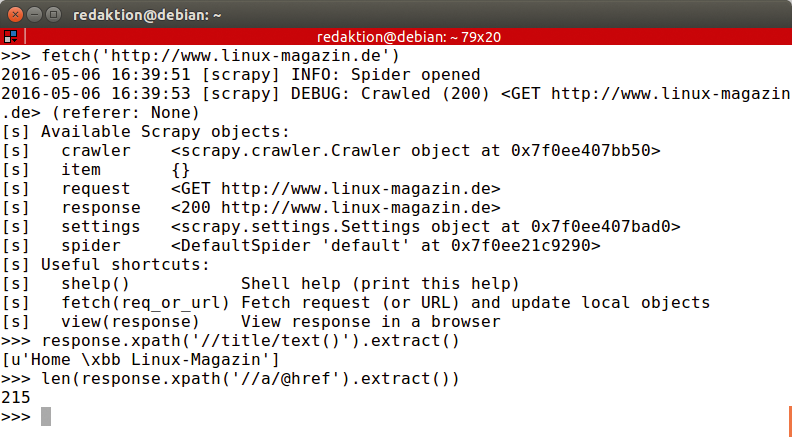
Abbildung 3: Der bordeigene Downloader überführt die Startseite des Linux-Magazins in ein Antwortobjekt.
Wie die Komponenten im Detail zusammenarbeiten, demonstriert Abbildung 4. Sie verdeutlicht, dass die Engine den Downloader nicht direkt anspricht, sondern die HTTP-Anfrage zunächst an den Scheduler übergibt (Abbildung 4, oben). Eine Downloader-Middleware (Abbildung 4, Mitte rechts) modifiziert die HTTP-Anfrage vor ihrem Einsatz. Die standardmäßig aktivierte »CookiesMiddleware« speichert Cookies der abgefragten Domain, die »RobotsTxtMiddleware« unterdrückt die Abfrage von Dokumenten, welche die Datei »robots.txt« [4] auf dem Webserver für Crawler sperrt.
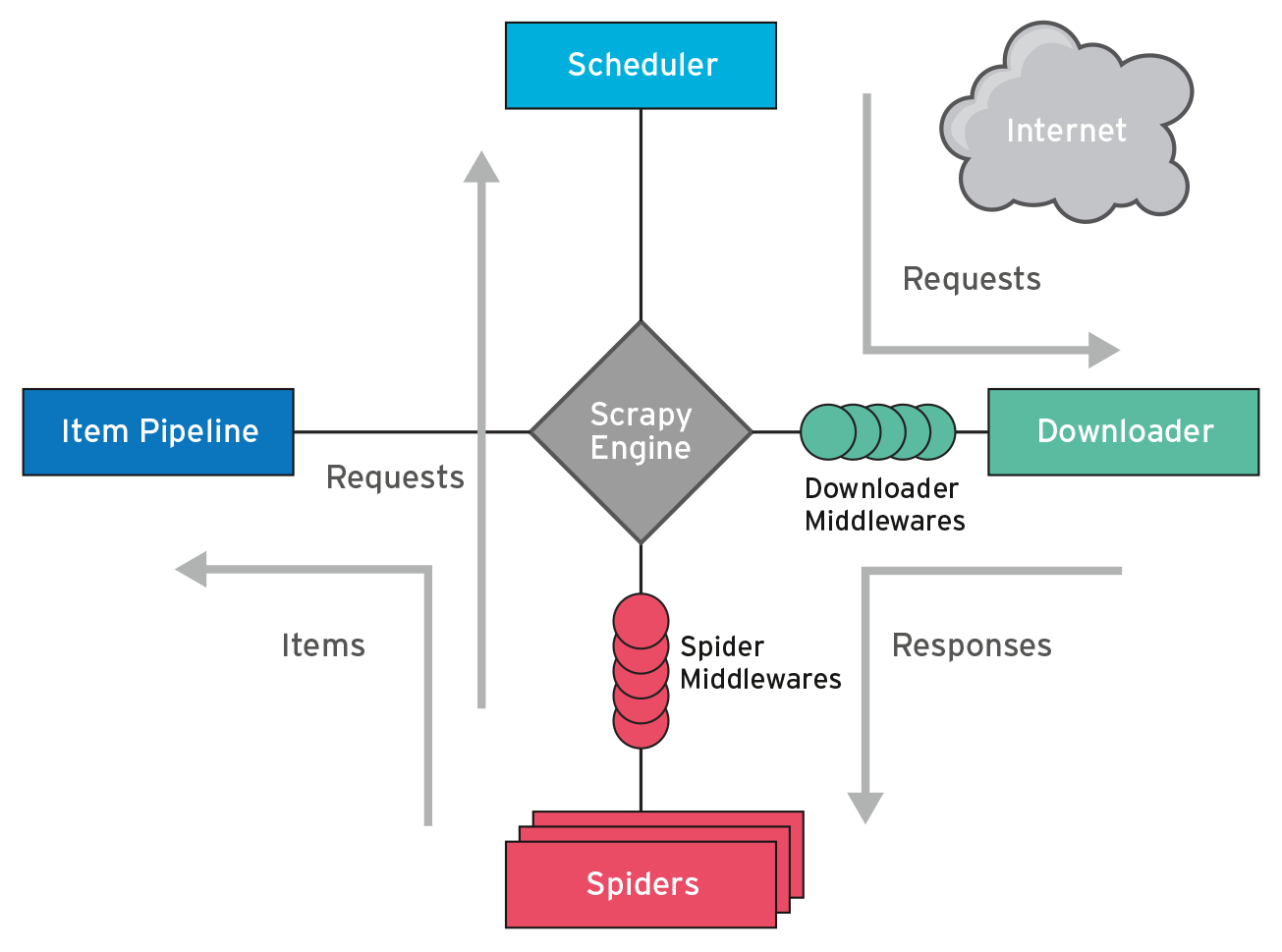
Abbildung 4: Die Scrapy-Engine delegiert Aufgaben an verschiedene Komponenten, etwa Spider, die Item-Pipelines und Middleware. Im Hintergrund werkelt Twisted, ein Event-getriebenes Netzwerk-Framework.
Fährtenleser
Die Dokument-Bestandteile wertet Scrapy aus, indem es sie über das Response-Objekt wie in Abbildung 3 interaktiv abfragt und betrachtet. Die Auswahl erfolgt wahlweise mit Hilfe von CSS-Selektoren [5] wie unter Jquery oder mit X-Path-Ausdrücken [6] wie unter XSLT. Exemplarisch zeigt sich das im Befehl
response.xpath('//title/text()').extract()
den der User als Nächstes eingibt (Abbildung 3). Er ruft die Methode »xpath()« auf. Der Teilausdruck »//title« wählt zunächst alle »title« -Tags aus dem HTML-Dokument aus, »/text()« den jeweils folgenden Textknoten. Die Methode »extract()« überführt die Ergebnismenge in die Python-Liste:
[u'Home \xbb Linux-Magazin']
Über den Ausdruck
len(response.xpath('//a/@href').extract())
extrahiert der Nutzer die Werte des »href« -Attributs aus allen »<a>« -Tags in eine Liste. Deren Länge findet die Python-Funktion »len()« heraus, es sind »215« (Abbildung 3).
Geburtshelfer
Mit dem erworbenen Wissen über Scrapy lässt sich eine Beispielanwendung bauen. Den Grundstein legt der Befehl
scrapy startproject mirror
der eine passende Verzeichnisstruktur erzeugt (Listing 1). Die Anwendung erreicht der User nach dem Wechsel in das Projektverzeichnis »mirror« . Die inhaltsleeren Dateien mit den Namen »__init__.py« sind rein technischer Natur [7]. Die Spider- und Pipeline-Klassen finden sich in den gleichnamigen Unterverzeichnissen. Die Ergebnisse speichert Scrapy im Verzeichnis »results« , die darauf basierenden Reports in »reports« .
Listing 1
Beispielprojekt mirror
01 |- scrapy.cfg 02 |- mirror: 03 |- __init__.py 04 |- items.py 05 |- pipelines 06 |- __init__.py 07 |- filter.py 08 |- normalize.py 09 |- store.py 10 |- reports 11 |- attr.py 12 |- results 13 |- 2016032210001458637243.sqlite3 14 |- settings.py 15 |- spiders 16 |- __init__.py 17 |- attr.py 18 |- utils.py
Zum reinen Skelett des Projekts kommen später ein paar Listings hinzu. Die Datei »mirror/utils.py« aus der letzten Zeile von Listing 1 speichert Hilfsfunktionen. Listing 2 zeigt den Inhalt dieser Datei. Die globalen Einstellungen des Projekts liegen ebenfalls im Python-Format vor und landen in »mirror/settings.py« (Listing 3). Die Variablen in den ersten drei Zeilen legt dabei Scrapy an, ihre Großschreibung erinnert an Konstanten unter C, die es in Python aber nicht gibt.
Listing 2
mirror/utils.py
01 from urlparse import urlparse 02 03 def optvalue(alist, key, default=[]): 04 if key in alist: 05 return alist[key] 06 return default 07 08 def domain(url): 09 return urlparse(url).netloc 10 11 def join(tags): 12 return "|".join(['//'+tag for tag in tags]) 13 14 def relevance(kds, wds): 15 if len(kds) == 0 or len(wds) == 0: 16 return 0 17 return reduce(lambda acc, kw: float(wds.count(kw)) + acc, kds, 0)/len(kds + wds) 18 19 def is_absurl(url): 20 return reduce(lambda acc, p: url.startswith(p) or acc, [u'http://', u'https://', u'//'], False)
Listing 3
mirror/settings.py
01 BOT_NAME = 'mirror'
02 SPIDER_MODULES = ['mirror.spiders']
03 NEWSPIDER_MODULE = 'mirror.spiders'
04 ITEM_PIPELINES = {
05 'mirror.pipelines.normalize.Words': 300,
06 'mirror.pipelines.filter.Injections': 400,
07 'mirror.pipelines.store.Attributes': 500
08 }
09 RESULTS = 'mirror/results/'
10 MEDIA_TAGS = ['video', 'audio', 'img', 'canvas']
11 INJECT_TAGS = ['script/@src', 'img/@src', 'video/@src', 'audio/@src', 'iframe/@src', 'embed/@src', 'link/@href']
12 SEMANTIC_TAGS = ['html', 'head', 'title', 'meta', 'link', 'body', 'header', 'footer', 'nav', 'article', 'aside', 'section', 'h1', 'h2', 'h3', 'h4', 'p', 'a', 'ul', 'ol', 'li', 'dl', 'dt', 'figure', 'table', 'th', 'tr', 'td', 'video', 'audio', 'form', 'input', 'label', 'button']
Zeile 1 speichert den Namen, den Scrapy anstelle der Browserkennung im Kopf der HTTP-Anfragen an den abgefragten Webserver überträgt. Die Zeilen 2 und 3 sind aus Sicht von Scrapy systemimmanent und bedürfen keiner Änderung. Die dann folgenden Variablen speichern anwendungsspezifische Konstanten.
Transportarbeiter
Bevor Scrapy die abgefragten Daten in die Item-Pipeline schickt (Abbildung 4, links), überführt es sie in ein Item-Objekt. Das hilft beim Formatieren und Validieren der Anwendungsdaten. Die Item-Klasse der Beispielanwendung steckt in »mirror/items.py« (Listing 4).
Listing 4
mirror/items.py
01 from scrapy import Item, Field 02 03 class Attributes(Item): 04 url = Field() 05 keywords = Field(input_processor=Split()) 06 words = Field(input_processor=Split()) 07 medias = Field() 08 links = Field() 09 tags = Field() 10 semantics = Field() 11 injections = Field() 12 13 class Split(): 14 def __call__(self, values): 15 return [word for value in values for word in value.split()]
Zeile 1 importiert explizit die benötigten Basisklassen »Item« und »Field« aus dem Scrapy-Paket. Zeile 3 deklariert die »Item« -Klasse »Attributes« , die in den runden Klammern auf die Elternklasse »Item« verweist. Der abschließende Doppelpunkt leitet einen Block ein, dem alle folgenden, gleich eingerückten Zeilen angehören.
Die Anwendungsdaten legt Scrapy nicht direkt in den Attributen ab, sondern speichert sie in Objekten vom Typ »Field« (Zeilen 4 bis 11). Der Konstruktor von »Field« setzt sich wie üblich aus dem Klassennamen und einem Paar runder Klammern zusammen.
Dank des Aufrufparameters »input_processor« jagt das »Field« -Objekt die zu speichernden Daten zuvor durch die Methode »__call__()« , die zum übergebenen Objekt vom Typ »Split« gehört. Die Klasse instanziert der Code in den Zeilen 13 bis 15. Die Signatur von »__call__()« ist, wie bei allen Methoden, die Scrapy selbsttätig aufruft, vorgegeben. Die Methode nimmt im Aufrufparameter »values« eine Liste von Zeichenketten entgegen, die der etwas komplexere Listenausdruck in Zeile 15 in einzelne Wörter aufspaltet.
In ihm iteriert die »for« -Schleife in Gestalt der Variablen »value« über alle Elemente der Liste »values« . Die zweite Schleife knöpft sich die mit »split()« aufgespaltete Zeichenkette aus »value« vor. Bei jedem Durchlauf setzt das Skript über die Variable »word« (rechts neben der öffnenden, eckigen Klammer) ein Wort in die Ergebnisliste.
Fleißige Spinne
Innerhalb von Scrapy-Anwendungen führen die erwähnten Spider (Abbildung 4, Mitte) Regie. Sie speichern den Teil des Anwendungscodes, der, ähnlich wie in der interaktiven Session aus Abbildung 3, die Funktion »fetch()« aufruft und das Antwortobjekte »response« auswertet. Listing 5 zeigt den Spider, der in der Anwendung unter »mirror/spiders/attr.py« wartet. Neben dem »CrawlSpider« bietet Scrapy die generischen Spider »XMLFeedSpider« und »CSVFeedSpider« .
Listing 5
mirror/spiders/attr.py
01 from scrapy.spiders import CrawlSpider, Rule
02 from scrapy.linkextractors import LinkExtractor
03 from scrapy.loader import ItemLoader
04 from mirror.items import Attributes
05 from mirror.utils import join
06
07 class Attr(CrawlSpider):
08 name = "attr"
09 rules = [Rule(LinkExtractor(), callback='parse_page')]
10 start_urls = ["http://localhost"]
11 allowed_domains = ["localhost"]
12
13 def parse_page(self, resp):
14 ldr = ItemLoader(item=Attributes(), response=resp)
15 ldr.add_value('url', resp.url)
16 ldr.add_xpath('keywords', 'string(//title)')
17 ldr.add_xpath('words', "string(//*[name()!='title'])")
18 ldr.add_xpath('links', '//a/@href')
19 ldr.add_xpath('tags', '//*')
20 ldr.add_xpath('medias', join(self.settings.get('MEDIA_TAGS')))
21 ldr.add_xpath('semantics', join(self.settings.get('SEMANTIC_TAGS')))
22 ldr.add_xpath('injections', join(self.settings.get('INJECT_TAGS')))
23 return ldr.load_item()
Die Zeilen 1 bis 5 importieren alle nötigen Klassen und Funktionen. Der Rest des Listings definiert die Spider-Klasse, die sich von »CrawlSpider« ableitet. Der Start des Crawlers mit »scrapy crawl attr« wählt, instanziert und ruft die Spider-Klasse anhand des Namens auf, der als Wert im Attribut »name« in Zeile 8 steckt. Mit der Angabe aus Zeile 9 marschiert das Objekt rekursiv weiter durch das Dokumenten-Gestrüpp. Das Attribut »rules« nimmt gewöhnlich Regeln analog zu einem Router auf. Diese URLs weist es dann verschiedenen Callback-Funktionen zu. Nach der Zuweisung folgt die Angabe:
Rule(LinkExtractor(), callback='parse_page')
Sie setzt im ersten Element der Liste die Defaultroute, indem sie dem Regelobjekt »Rule« ein »LinkExtractor()« -Objekt ohne Pfadangabe übergibt. Dann benennt »callback« die Funktion »parse_page()« (Zeile 13) als Callback-Funktion.
Bevor diese startet, fragen Objekte vom Typ »CrawlSpider« im Attribut »start_urls« nacheinander alle Seitenadressen aus der Liste ab. Sie übergeben die Antwortobjekte jeweils an Callback-Funktionen. Die Angabe »allowed_domains« aus Zeile 11 ist optional. Sie beschränkt die Abfragen auf die gelisteten Domains.
Gleich in Zeile 13 übernimmt »parse_page()« im zweiten Argument das »Response« -Objekt und packt es in die Variable »resp« . Die folgende Zeile instanziert mit der Variablen »ldr« ein Containerobjekt vom Typ »ItemLoader« . Dies ist in der Lage, andere Objekte aufzunehmen. Es kümmert sich zunächst darum, das übergebene »Item« -Objekt vom Typ »Attributes« aus Listing 4 zu initialisieren.
Copyshop
In den Zeilen 15 bis 22 kopiert Listing 5 die Werte aus dem »Response« – in die Attribute des »Item« -Objekts. Die URL des »Response« -Objekts weist Zeile 15 mit der Methode »add_value()« dem gleichnamigen Attribut innerhalb des »Item« -Objekts zu. Die Zeilen 16 bis 22 kopieren mittels »add_xpath()« Dokument-Bestandteile anhand übergebener X-Path-Ausdrücke in die aufgezählten Attribute.
Zeile 16 extrahiert mittels »//title« alle »<title>« -Tags, während die X-Path-Funktion »string()« deren jeweiligen Textwert holt. Auch die »add_« -Funktionen verwalten ihre Ergebnisse in Listenform. Zeile 17 holt auf ähnliche Art und Weise alle Wörter aus dem HTML-Dokument. Der Ausdruck »[name()!=’title’]« pickt aus der Auswahl aller Tags (»//*« ) nur jene, die nicht »<title>« heißen.
Die Zeilen 18 und 19 kopieren, wie es Abbildung 3 zeigt, sämtliche Verlinkungen und Tags in das »Item« -Objekt. Die drei folgenden Zeilen werten die Listen »MEDIA_TAGS« , »SEMANTIC_TAGS« und »INJECT_TAGS« aus Listing 3 aus. Dabei verwandelt die Hilfsfunktion »join()« aus der Datei »mirror/utils.py« sie in X-Path-Ausdrücke. Konkret formt »join()« die übergebene Liste von Tags »[‘a’, ‘b’]« nach »//a | //b« um. Das Pipe-Symbol repräsentiert in X-Path den Oder-Operator. Die drei Listen findet der Spider über die Methode »get()« des Settings-Objekts im gleichnamigen Attribut.
Zeile 23 beendet die Initialisierung des »Item« -Objekts, indem es die Methode »load_item()« aufruft. Leere Attribute würden einen Fehler verursachen. Die »return« -Anweisung übergibt das »Item« -Objekt zuletzt in die Item-Pipeline.
Rohrpost
Die Item-Pipeline verarbeitet die »Item« -Objekte dann weiter, die Variable »ITEM_PIPELINES« konfiguriert die Pipeline in den Zeilen 4 bis 8 der Beispielanwendung von Listing 3. Die übergibt die »Item« -Objekte der Reihe nach jeweils an ein Objekt der Pipeline-Klassen »Words« (300), »Injections« (400) und »Attributes« (500), modifiziert sie oder speichert sie und schiebt sie weiter.
Listing 6 zeigt den Code zur Klasse »Words« , die Wörter für die folgende Auswertung prüft und vereinheitlicht. Scrapy erzeugt und bindet hier die Pipeline-Objekte ein, indem es für jedes »Item« -Objekt die Methode »process_item()« aufruft (Zeile 2). Sie übernimmt im zweiten Argument das »Item« -Objekt, im dritten (»spider« ) eine Referenz auf das aufrufende Spider-Objekt. Die zwei Folgezeilen überschreiben die Werte zu den Attributen »keywords« und »words« . In Zeile 3 fischt die Funktion »filter()« alle Elemente aus der Liste »item[key]« , für die die Lambda-Funktion (»lambda wd: wd.isalnum()« ) einen wahren Wert zurückgibt. Das betrifft Zeichenketten aus rein alphanumerischen Zeichen.
Listing 6
mirror/pipelines/normalize.py
01 class Words(object): 02 def process_item(self, item, spider): 03 for key in ['words', 'keywords']: 04 item[key] = map(lambda wd: wd.lower(), filter(lambda wd: wd.isalnum(), item[key])) 05 return item
Die zweite Lambda-Funktion – »map()« – formatiert die Wörter der Ergebnismenge anschließend in Kleinbuchstaben. Die »return« -Anweisung der letzten Zeile überreicht das »Item« -Objekt dann an das nächste Pipeline-Objekt (Listing 7). Dies betrachtet den möglichen Einfluss fremden Contents auf die aktuelle Browser-Session.
Listing 7
mirror/pipelines/filter.py
01 from mirror.utils import is_absurl, domain 02 03 class Injections(object): 04 def process_item(self, item, spider): 05 item['injections'] = [other 06 for own in item['url'] 07 for other in item['injections'] 08 if domain(other) != domain(own) and is_absurl(other) 09 ] 10 return item
Die Pipeline-Klasse »Injections« aus Listing 7 reduziert mit den Hilfsfunktionen »is_absurl()« und »domain()« , die wiederum aus »mirror/utils.py« stammen, die Liste der eingebunden Ressourcen auf fremden Content.
Dazu überschreibt die Methode »process_item()« das Attribut mit Hilfe der gefilterten Liste, die der Listenausdruck ab Zeile 5 erzeugt. Die erste »for« -Schleife liest lediglich die URL der Seite aus, die zweite iteriert über die zu injizierenden Tags. Stellt das Attribut gemäß der »if« -Fallunterscheidung eine absolute URL dar, die von der aktuellen Domain abweicht, übernimmt die Schleife die Ressource aus der Variablen »other« . Die »return« -Anweisung reicht das so veränderte Item erneut an das letzte Glied der Pipeline weiter (Listing 8). Das reduziert die Resultate zwecks späterer Auswertung und legt sie in einer Datenbank ab.
Listing 8
mirror/pipelines/store.py
01 import sqlite3
02 from os.path import join
03 from time import gmtime, strftime
04 from mirror.utils import relevance, optvalue
05
06 class Attributes(object):
07 def __init__(self, path):
08 self.db = path
09
10 @classmethod
11 def from_crawler(cls, crawler):
12 return cls(join(crawler.settings.get('RESULTS'), "%s.sqlite3" %(strftime('%Y%m%d%H%M%s', gmtime()))))
13
14 def open_spider(self, spider):
15 self.conn = sqlite3.connect(self.db, isolation_level = None)
16 self.cur = self.conn.cursor()
17 self.cur.execute("CREATE TABLE Attributes (url text PRIMARY KEY, keywords int, words int, relevancy int, tags int, semantics int, medias int, links int, injections int)")
18
19 def close_spider(self, spider):
20 self.conn.close()
21
22 def process_item(self, item, spider):
23 self.cur.execute('INSERT INTO Attributes VALUES (?,?,?,?,?,?,?,?,? )', (item['url'][0], len(item['keywords']), len(optvalue(item, 'words')), relevance(optvalue(item, 'keywords'), optvalue(item, 'words')), len(optvalue(item, 'tags')), len(optvalue(item, 'semantics')), len(optvalue(item, 'medias')), len(optvalue(item, 'links')), len(optvalue(item, 'injections'))))
24 return item
Die Pipeline-Klasse »Attributes« (Zeile 6 von Listing 8) wertet das Item-Objekt aus und speichert das Ergebnis in einer SQlite-Datenbankdatei [8] ab. Das SQL-kompatible freie Datenbank-Framework kommt ohne Serverprozesse aus und alle gängigen Programmiersprachen unterstützen es.
Listing 8 schreibt alle Daten direkt und synchron über den Treiber in die Datenbankdatei. Zeile 1 bindet den passenden Treiber aus Python ein, die nächsten drei Zeilen importieren benötigte Funktionen aus den Standardpaketen »os.path« , »time« sowie »mirror/utils.py« .
Die Konstruktorfunktion »__init__()« übernimmt im zweiten Aufrufparameter »path« den Pfad, über den Python die SQlite-Datenbank öffnet. Scrapy verwendet die Klassenmethode »from_crawler()« (Zeilen 10 bis 12), um ein Objekt zu instanzieren. Ein Blick in die Methode zeigt, dass »from_crawler()« in seiner Parameterliste mit dem Crawler-Objekt eine Referenz auf die Einstellungen aus Listing 3 übernimmt. Erst liest sie den Wert der Variablen »RESULTS« aus Zeile 9 in Listing 3 aus. Dann bezieht sie ihn im Konstruktor-Aufruf in den Zeilen 7 und 8 von Listing 8 mit ein. Am Ende erzeugen »gmtime()« und »strftime()« im Zusammenspiel mit einer Variante der Zeichenketten-Formatierung noch einen Zeitstempel für den Dateinamen.
Die Methode »open_spider()« (Zeilen 14 bis 17) ruft die Scrapy-Engine beim Erstellen des Spiders im Stile einer Callback-Funktion einmalig auf. Sie erzeugt und speichert in Zeile 15 eine Datenbankverbindung im Attribut »conn« . Die Angabe »isolation_level=None« veranlasst den Treiber dazu, jede SQL-Anweisung sofort persistent in der Datenbankdatei anzulegen. Zeile 16 erzeugt und speichert das Datenbank-Cursor-Objekt, das Datenbankoperationen ausführt. Zu diesen gehört auch der SQL-Befehl, der die Ergebnistabelle anlegt:
CREATE TABLE Attributes (url text PRIMARY KEY, keywords int, words int, relevancy int, tags int, semantics int, medias int, links int, injections int)
Die Methode »process_item()« ab Zeile 22 fügt die Werte aus dem Item-Objekt gemäß Tabelle 1 mit Hilfe des SQL-Befehls »INSERT« in die Tabelle »Attributes« ein. An der Stelle der Fragezeichen landen die Werte des nachfolgenden, von den runden Klammern umfassten Tupels. Die Funktion »len()« zählt dabei mehrfach die Länge der ausgelesenen Listen. Die Hilfsfunktion »optvalue()« ersetzt None-Werte gegen leere Listen, »relevance()« ermittelt die Häufigkeit aller Keywords im restlichen Text der Webseite.
Auswertung
Der User startet den Crawler wie erwähnt über die Kommandozeile und aus dem Projektverzeichnis »mirror« heraus:
scrapy crawl attr
Listing 9 zeigt die SQL-Abfrage, die den Report aus Abbildung 1 gemäß den Tabellen 1 und 2 erzeugt. Die Stärke von SQL offenbart sich in der kompakten und satzähnlichen Ausdrucksweise. Nur das Umwandeln der Typen und das Formatieren erfordern lästige Tipparbeit.
Tabelle 2
Interpretation der erhobenen Daten
|
Größe |
Berechnung |
Interpretation |
|---|---|---|
|
Relevancy |
– |
Maß für die Glaubwürdigkeit des Titels |
|
Entropy |
(Words+Semantics)/(Words+Tags) |
Nicht-semantische-Tags wie »div« oder »span« reduzieren den Informationsgehalt |
|
Expressivity |
Semantics/Tags |
Semantische Tags verbessern die funktionale Einordnung der Dokument-Bestandteile |
|
Richness |
Medias |
Medien bereichern den Inhalt |
|
Reliability |
Links/Words |
Verlinkungen bürgen für die Glaubwürdigkeit |
|
Mutability |
Injections |
Externe Ressourcen entfremden die Seite |
Die endogenen Seitenfaktoren beurteilen eine Webseite aus verschiedenen Perspektiven. Die abgeleitete Größe der Entropie ist ein Maß für den mittleren Informationsgehalt der Seite. Die Größen sind wortgleich, aber nicht identisch mit den korrespondierenden Terminologien aus der Informationstheorie [9]. In der Beispielanwendung beschreiben sie nur, wie nicht semantische Tags wie »div« und »span« den Inhalt verwässern. Wäre der Wert der Entropie 1, würden generische Spider bessere Ergebnisse erzielen. Der Durchschnitt 0,837 aus Abbildung 1 lässt noch Luft nach oben.
Listing 9
SQL-Abfrage für den Report
01 SELECT url, printf('%.3f', relevancy), printf('%.3f', cast((words + semantics) as float)/(words + tags)) as entropy, printf('%.3f', cast(semantics as float)/tags) as expressivity, printf('%.3f', cast(medias as float)) as richness, printf('%.3f', cast(links as float)/words) as reliablity, printf('%.3f', cast(injections as float)) as mutability FROM Attributes
Fazit
Die Programmierung unter Scrapy bringt Spaß und überraschende Einsichten. Dank der klug gewählten Modularisierung und guten Dokumentation konzentriert sich der Benutzer auf das Extrahieren und Akkumulieren von Daten. Wer tiefer in Scrapy einsteigt, erkennt an der Vielzahl von Facetten, die es abdeckt, auch den professionellen Ansatz, den das Framework verfolgt.
Infos
- Scrapy-Framework: http://scrapy.org
- Python: https://python.org
- Python Package Index: http://pypi.python.org
- Robots Exclusion Standard: https://de.wikipedia.org/wiki/Robots_Exclusion_Standard
- CSS-Selektoren: https://api.jquery.com/category/selectors/
- X-Path-Ausdrücke: https://www.w3.org/TR/xpath/
- Sinn von »__init__.py« : http://stackoverflow.com/questions/448271/what-is-init-py-for
- SQlite: http://sqlite.org
- Informationstheorie: http://www.informatik.uni-leipzig.de/~brewka/papers/TheorieI8.pdf





