
© mezzotint123rf, 123RF
Ausfallsicherheit ist auch für Fileserver-Admins ein großes Thema. Dank der CTDB und Ceph lässt sich Samba auch als Cluster problemlos betreiben.
Die weite Verbreitung von Samba bringt es mit sich, dass sich Fileserver-Admins regelmäßig fragen müssen, wie sie den Dienst gegen Ausfälle absichern können. Zwar ist Samba inzwischen ausgereift und läuft in den meisten Fällen problemlos. Stürzt aber der Server ab, auf dem Samba läuft, wäre der Dienst nicht mehr verfügbar, Gleiches gilt, wenn das Netzwerk Schluckauf hat. Jede Komponente wird automatisch zum Problem, wenn sie ausfällt und keine andere Komponente ihren Dienst übernimmt.
Die Samba-Entwickler wissen das und haben auf das Problem reagiert: In Samba findet sich nämlich ein waschechter Clustermodus, mit dem sich der Dienst hochverfügbar machen lässt. Das bedeutet: Mehrere Samba-Server stehen für Clientanfragen zur Verfügung und machen es untereinander aus, wie sie die abarbeiten.
In einem solchen Setup fällt der Crash eines einzelnen Samba-Servers nicht mehr ins Gewicht, weil andere Server dessen Agenda übernehmen können. Die Einrichtung gestaltet sich allerdings nicht ganz intuitiv, auch weil die Clusterimplementierung von Samba sich in den vergangenen Jahren mehrfach grundlegend geändert hat. Der folgende Artikel gibt einen Überblick über die wichtigsten HA-Fragen in Sachen Samba.
Die Herausforderung
Warum ist ein Samba-Cluster überhaupt eine besondere Herausforderung? Um das zu verstehen, ist ein kleiner Ausflug in die Theorie des Speicherns notwendig. Von besonderer Bedeutung ist dabei das Thema Locking. Die Ausgangsfrage ist stets, wie eine Anwendung mit konkurrierenden Zugriffen auf die gleiche Datei umgeht. Anwendung kann in diesem Falle ein einfaches Dateisystem auf einem Datenträger ebenso wie eine komplexe Applikation sein. Auf jeden Fall muss sie sich um das Locking kümmern. Man stelle sich das Chaos vor, das andernfalls entstünde: Zwei Clients greifen zeitgleich auf dieselbe Datei zu und verändern Teile davon. Am Ende steht eine korrupte Datei, mit deren Inhalt weder Client A noch Client B etwas anfangen kann.
Auf der Datenträger-Ebene haben die verschiedenen Dateisysteme in den vergangenen Jahren praktisch alle Lösungen durchprobiert: Ältere Dateisysteme verweigern den Zugriff auf eine Datei rigoros, wenn diese schon geöffnet ist. Moderne Dateisysteme verfolgen das Prinzip, dass der letzte Schreibvorgang gewinnt und den Inhalt der Datei bestimmt. Vim-Benutzer kennen das, denn Vim legt Swap-Dateien für geöffnete Dateien an und prüft, bevor es eine Datei öffnet, ob für diese bereits eine Swap-Datei existiert. Ist das er Fall, zeigt Vim eine deutliche Warnmeldung an, bevor es die Datei öffnet.
Weil auch Samba ein Netzwerk-Dateisystem anbietet, verfügt es ebenfalls über interne Lockingfunktionen. Sein Zauberwort heißt TDB (Trivial Database) und bezeichnet ein Datenbankformat, in dem Samba seine internen Metadaten abspeichert. Eine der wichtigsten Datenbanken ist »locking.tdb« , in der sich Samba merkt, welche Clients gerade auf welche Datei zugreifen.
Samba setzt maßgeblich auf Opportunistic Locking, weil Windows-Clients dies auf Samba-Laufwerken erwarten. Das bedeutet, dass ein Client dem Server mitteilt, dass er die exklusiven Zugriffsrechte auf eine Datei des Samba-Share für sich beansprucht. Wenn der Samba-Server der Anfrage entsprochen hat, schreibt er einen entsprechenden Vermerk in »locking.tdb« und verbietet anderen Clients den Zugriff auf dieselbe Datei.
Solange der Vorgang auf eine einzelne Samba-Instanz beschränkt ist, klappt das alles wunderbar: Schließlich kann der einzige Samba-Server dann zuverlässig davon ausgehen, dass seine Version von »locking.tdb« die aktuelle ist. Andere Samba-Instanzen, die diese verändern könnten, gibt es ja nicht.
Wenn sich diese Grundannahme jedoch ändert – wie bei geclustertem Samba –, ist die Herausforderung da: Dann müssen mehrere Samba-Instanzen der Installation untereinander die Inhalte ihrer »locking.tdb« -Dateien synchron halten. Das bedeutet nichts anderes, als den Zugriff von Clients auf Dateien des Samba-Volume clusterweit zu managen.
Die Lösung der Samba-Entwickler für dieses Problem heißt CTDB: Das “C” steht hier für Cluster und beschreibt eine Erweiterung von TDB, dank der viele Samba-Instanzen ihre TDB-Inhalte dynamisch austauschen können. Erst mit CTDB lässt sich ein Samba-Cluster also sinnvoll betreiben.
Voraussetzungen für geclustertes Samba
Um einen Samba-Cluster zu bauen, müssen mehrere Voraussetzungen erfüllt sein. Storage und RZ-Infrastruktur spielen eine große Rolle. Dass mehrere Samba-Instanzen Zugriff auf dasselbe Dateisystem brauchen, wenn sie es im Clustermodus bereitstellen wollen, klingt wie eine Binsenweisheit, ist aber entscheidend, um an den Clusterbetrieb mit CTDB überhaupt denken zu können.
Noch vor wenigen Jahren hätten sich Admins hier mit geteilten Dateisystemen befassen müssen: GFS oder OCFS2 (Oracle Cluster File System 2) verwalten den clusterweiten Zugriff auf dasselbe Dateisystem, etwa einen per I-SCSI verbundenen NAS-Share. Doch das setzt auch zwingend den Betrieb eines Clustermanagers voraus, bevorzugt Pacemaker. Und der sorgt bei vielen Admins für Verdruss, weil er ausgesprochen komplex ist und gerade im Gespann mit GFS oder OCFS2 kaum zu durchdringen.
Zum Glück haben die verteilten Speicherlösungen ihren Kollegen inzwischen den Rang abgelaufen. Verteilte Speicher funktionieren anders: Sie bilden aus vielen kleinen Segmenten der teilnehmenden Server ein großes Dateisystem und kümmern sich intern um dessen Konsistenz. Der Zugriff erfolgt durch festgelegte, eigenständige Mechanismen über einfache Schnittstellen. Im Grunde ist ein verteilter Speicher zwar nicht weniger komplex als Pacemaker mit OCFS2, aber er versteckt seine Komplexität besser. Die Einstiegshürde ist bei verteilten Speichern also deutlich niedriger.
Zwei Konkurrenten dominieren den Markt, beide kommen von Red Hat: Auf der einen Seite bietet Gluster-FS ein klassisches verteiltes Dateisystem, auf der anderen Seite ist Ceph ein Objektspeicher, der seine Inhalte auch in Form eines Posix-kompatiblen Dateisystems – Ceph-FS – anbieten kann. Ceph-FS steckte mehrere Jahre im Betastadium, doch die letzte Ceph-Version “Jewel” hat das geändert: Laut Aussage der Entwickler eignet sich Ceph-FS nun auch für den produktiven Betrieb. Für diesen Artikel fiel die Wahl des Samba-Speichers deshalb auf Ceph mit Ceph-FS.
Drei Server stehen im folgenden Beispiel für Ceph bereit: Alice, Bob und Charlie – jeder davon hat eine Festplatte zur Verfügung, die er für den Ceph-Objektspeicher beisteuert. Der Inhalt dieser Anleitung lässt sich so mit virtuellen Maschinen nachstellen. Wer also erst ausprobieren möchte, muss dafür keine extra Hardware anschaffen.
Doch der schönste Samba-Cluster hilft nicht, wenn zuvor grundlegende Regeln der Hochverfügbarkeit keine Beachtung fanden. Im Grunde steht ein HA-Cluster mit Samba den gleichen Herausforderungen gegenüber, mit denen sich auch alle anderen Dienste auf einem Server herumschlagen müssen: Durch das Clustern auf Software-Ebene ist nur ein Punkt abgedeckt. Der Ausfall von Infrastruktur, die Samba nicht kontrolliert, kann Samba noch immer aus dem Tritt bringen.
Die beiden klassischen Fälle sind Netzwerk und Strom: Mehrere Samba-Server im Clusterverbund sind gut, doch wenn beide am selben Stromkreis hängen und dieser ausfällt, dann sind auch beide Server tot. Beim Ethernet ist die Problematik gleich: Wenn alle Knoten des Clusters an demselben Switch hängen und dieser ausfällt, ist der Samba-Dienst zwar noch verfügbar, doch seine Clients können ihn nicht mehr erreichen.
Hier empfiehlt es sich, den Bonding-Treiber für Linux zu nutzen und mehrere Switches einzubinden, deren Uplink ebenfalls redundant sein sollte.
Die nötige Infrastruktur schaffen
Die Frage nach dem Maß an Redundanz hängt auch vom Budget für das Projekt ab. Redundanz auf Strom- und Netzwerkebene verursacht erhebliche Mehrkosten, weil viele Komponenten doppelt vorhanden sein müssen. Am Ende sieht sich der Admin also einer Abwägung gegenüber: Je mehr Setup-Teile er redundant auslegt, desto geringer ist die Gefahr eines Ausfalls des Dienstes, desto teurer wird die Angelegenheit aber auch.
Schritt 1: Ceph startklar machen
Zunächst steht der Datenspeicher im Mittelpunkt, den Samba nutzt, im Beispiel also Ceph-FS auf einem Ceph-Cluster (Alternative siehe Kasten “Plan B für Ceph und Samba”). Es empfiehlt sich für das Beispiel unbedingt, die aktuelle Ceph-Version (bei Redaktionsschluss Jewel 10.2.0) zu nutzen, denn die Entwickler bewerten Ceph-FS erst in dieser als stabil. Im Beispiel kommt Ubuntu 16.04 zum Einsatz, für das Red Hat bereits fertige Pakete der genannten Ceph-Version bereithält [1].
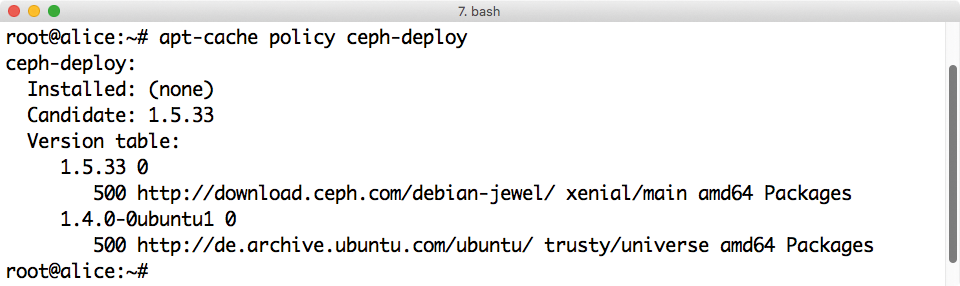
Abbildung 1: Die aktuelle Version von »ceph-deploy« von Inktank ist deutlich neuer als jene, die Ubuntu 14.04 oder Ubuntu 16.04 mitliefern.
Durch die Installation führt das Ceph-Werkzeug »ceph-deploy« . Es bereitet die drei Rechner des Setups für Ceph vor, installiert Ceph und erlaubt es dem Admin auch, die Festplatten in Ceph zu aktivieren. Der erste Schritt ist also, »ceph-deploy« zu installieren. Zwar liegt auch Ubuntu ein Paket mit dem Werkzeug bei, doch die Empfehlung ist ganz klar, auf das »ceph-deploy« aus dem Red-Hat-Repository zu setzen (Abbildung 1). Das aktiviert der Admin vorher mit
wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
für den GPG-Schlüssel und mit
sudo apt-add-repository 'deb http://download.ceph.com/debian-jewel/ xenial main'
für die Pakete selbst. »apt-get update && apt-get install ceph-deploy« holen das Tool schließlich auf das System. Diese Schritte sind nur auf einem der drei Systeme auszuführen.
Server für Ceph vorbereiten
Damit Ceph und »ceph-deploy« arbeiten können, muss SSH funktionieren. Auf allen Hosts sollte zudem ein User namens »ceph« vorhanden sein, den »ceph-deploy« später nutzt. Jener User sollte auch »sudo« ohne Passwort nutzen können, um auf den Systemen Befehle als »root« auszuführen. Das bewirken die Befehle:
echo "ceph ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ceph sudo chmod 0440 /etc/sudoers.d/ceph
Ceph-deploy nutzt SSH, um innerhalb des Clusters Befehle auszuführen. Um viele Passworteingaben zu vermeiden, sollte sich der Nutzer »ceph« per SSH zwischen den Servern ohne Passwort frei hin und her verbinden können.
Der Befehl »ssh-copy-id« kopiert den öffentlichen Teil eines SSH-Schlüssels auf einen entfernten Host. In der Datei »~/.ssh/config« sollte für die anderen Server des Ceph-Clusters der Standard-Nutzername zudem auf »ceph« gesetzt sein, damit »ceph-deploy« sich nicht als »root« einzuloggen versucht.
Ebenso müssen die drei Rechner samt ihrer IP-Adresse auf allen drei Hosts in »/etc/hosts« stehen. Es ist sinnvoll, einen der drei Knoten zum Master zu erklären und diesen für die folgenden »ceph-deploy« -Aufrufe auszuwählen – auf die Funktionalität von Ceph wirkt sich das aber nicht aus.
Den Ceph-Cluster ausrollen
Sobald »ceph-deploy« startklar ist, erledigen sich weitere Schritte der Ceph-Installation fast wie von selbst. Mit dem Kommando »install« sorgt »ceph-deploy« dafür, dass auf allen angegebenen Hosts die nötigen Pakete für Ceph vorhanden sind. Im Beispiel installiert der Befehl
ceph-deploy install --release jewel alice bob charlie
auf dem imaginären Master-Host Ceph automatisch auf allen drei Rechnern.
Dann folgt das Setup des Clusters. Zur Erinnerung: Ceph besteht aus drei Komponenten: Object Storage Devices (OSD), Monitoring-Servern (MON) und Metadaten-Servern (MDS). Erstere sind die Festplatten, die der Cluster benötigt. Letztere erweitern den Ceph-Objektspeicher um Posix-Fähigkeiten für den Betrieb als Dateisystem. Die Monitoring-Server sind die wichtigsten Ceph-Komponenten: Sie überwachen das Quorum und stellen die Funktion des Clusters sicher.
Beim Ausrollen von Ceph sind die Monitoring-Server aus genau diesem Grund die ersten Komponenten, die der Admin sich vorknöpft. Für ihre Installation in einem neuen Cluster hat »ceph-deploy« das Kommando »new« : »ceph-deploy new alice bob charlie« auf dem Master-Server rollt automatisch einen neuen Ceph-Cluster auf den drei genannten Hosts aus, auf denen am Ende des Vorgangs jeweils der Prozess »ceph-mon« läuft. Wenn »ceph-deploy« die Arbeiten abgeschlossen hat, lässt sich mit dem Befehl »ceph -w« bereits auf dem ersten der drei Hosts ein funktionierender Cluster erkennen, obgleich dieser noch gar keine Platten hat.
Die folgen erst im nächsten Schritt: Auf Alice, Bob und Charlie ist jeweils »/dev/sdb« für Ceph vorgesehen. Der Befehl »ceph-deploy create alice:sdb« (analog auch für Bob und Charlie) erledigt das in einem Aufwasch. Wer das interne Journal des OSD auf eine schnelle SSD auslagern möchte, gibt die Zielpartition in der Form »:Partition« am Ende des Befehls an, also etwa »ceph-deploy create alice:sdb:/dev/sdf1« , wenn »/dev/sdf1« eine Partition auf einer SSD ist.
Weil im Cluster Ceph-FS zum Einsatz kommen soll, fehlen noch die erwähnten Metadaten-Server: Die installiert der Admin mit: »ceph-deploy mds create alice bob charlie« . Ein erneuter Blick in »ceph -w« zeigt ein neues Bild: Nun existiert ein Ceph-Cluster mit drei MON, drei OSD und drei MDS und ist bereit für den Betrieb (Abbildung 2).
Abbildung 2: Nach dem Setup des Ceph-Clusters steht dieser bereit: Drei MON, drei OSD und drei Metadaten-Server warten auf Anfragen.
Übrigens: Wer das Setup später tatsächlich betreiben will, wird das wohl auf echtem Blech tun. Hier gelten die üblichen Ceph-Tipps in Sachen Redundanz und Performance. Drei einzelne Server sind Pflicht und wer OSD-Journale auf schnelle SSDs auslagern möchte, sollte nicht mehr als vier OSD-Journale auf eine einzelne SSD packen. Bei Ceph-Clustern dürfte in den meisten Fällen der erreichbare Durchsatz maßgeblich sein, sodass auch eine dicke Anbindung der einzelnen Ceph-Knoten an das lokale Netz bestimmt nicht schadet.
Schritt 2: Samba vorbereiten
Weiter geht’s mit der Konfiguration für Samba, damit es CTDB nutzt und auf Ceph-FS zugreift. Hier gilt es, eine Klippe zu umschiffen: Der Betrieb von Samba auf den Ceph-Clusterknoten wirkt im ersten Augenblick verlockend. Aber die Ceph-Entwickler raten dringend davon ab, einen Ceph-FS-Dateisystemmount auf einem Host zu aktivieren, der selbst Teil des Ceph-Clusters ist. Das so genannte Loopback-Problem ist nicht Ceph-spezifisch und gilt für alle vergleichbaren Lösungen.
Fest steht damit, dass Samba in einem Setup mit Ceph-FS auf eigenen Hosts laufen und auf Ceph-FS aus der Ferne zugreifen sollte. Die weiteren Server heißen im Beispiel Daisy und Eric.
Plan B für Ceph und Samba
Alternativ zum Setup, das dieser Artikel beschreibt, lassen sich Ceph und Samba auch in anderer Weise miteinander kombinieren. Der Umweg über Ceph-FS fällt dann weg: Die Red-Hat-Entwickler haben für Samba nämlich ein VFS-Modul entwickelt, das direkt an die Rados-Bibliothek gekoppelt ist und so direkt mit dem Objektspeicher reden kann.
Die Vorteile dieser Lösung sind klar: Einerseits fällt die Notwendigkeit für einen lokalen Ceph-FS-Mount auf dem Samba-Server weg. Dadurch löst sich das beschriebene Deadlock-Problem in Sachen Speicherfreigabe elegant in Luft auf. Andererseits ist auch der Betrieb der Metadaten-Server nicht mehr nötig, weil Ceph-FS nicht zum Einsatz kommt.
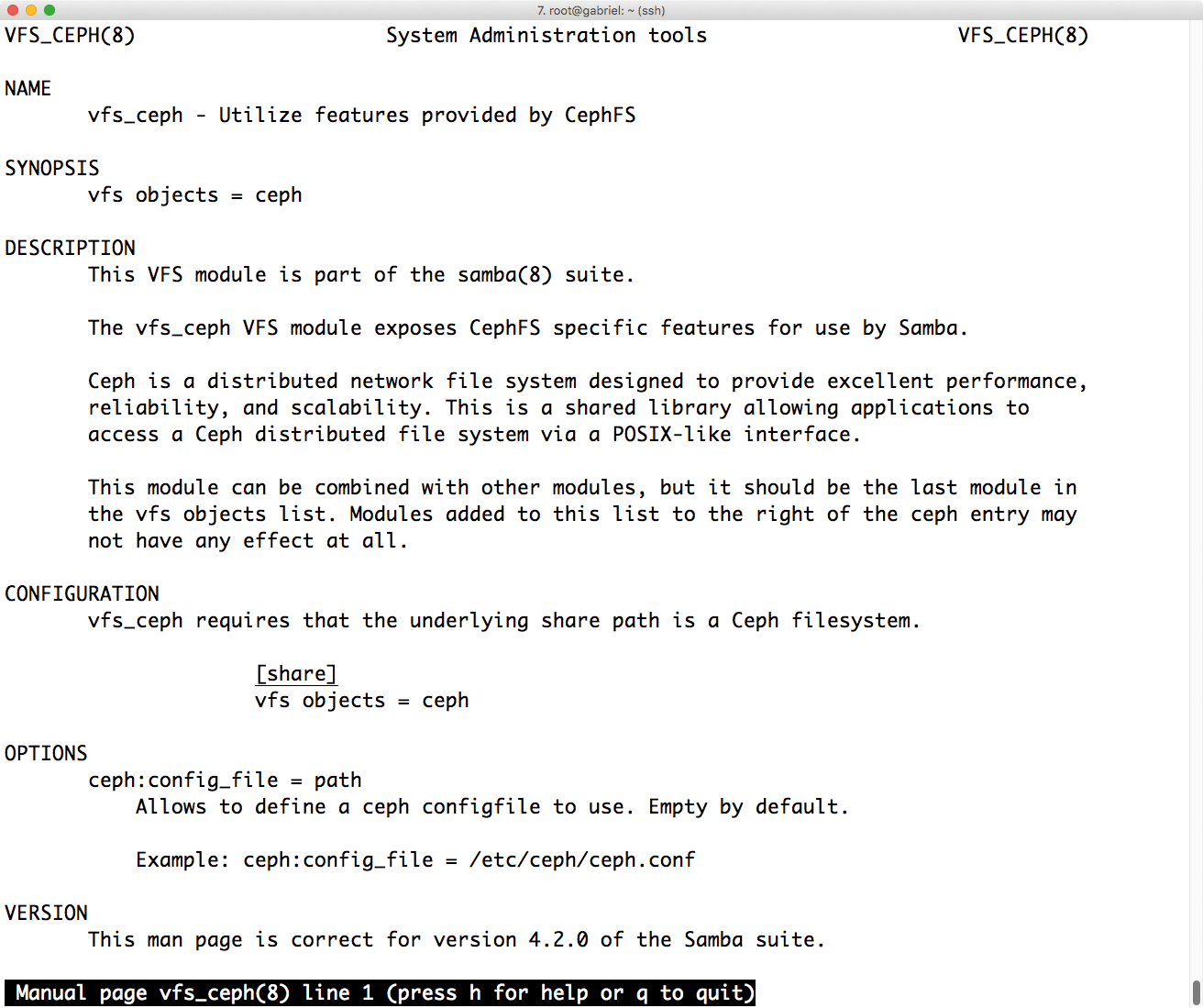
Abbildung 3: Als Alternative zu dem Umweg über Ceph-FS bietet sich das VFS-Modul für Ceph an, das aktuellen Samba-Versionen (ab 4.2) beiliegt.
Das VFS-Modul für Samba (VFS steht für Virtual File System und beschreibt Samba-Treiber, die zu teilende Dateien von anderen Quellen als von lokalen Dateisystemen beziehen) liegt allen Samba-Versionen ab 4.2 bei (Abbildung 3). Wer also ein einigermaßen aktuelles Paket in seiner Distribution vorfindet, kann auch den Weg über das »vfs_ceph« -Modul für Samba gehen. Details zum Treiber und der nötigen Konfiguration finden sich unter [2].
Auf denen ist zunächst der Ceph-FS-Mount erforderlich. Ceph setzt auf den bereits eingebauten Authentifizierungs-Mechanismus Ceph X, den »ceph-deploy« ebenfalls aktiviert. Damit das Mounten klappt, ist also das Passwort eines aktiven Ceph-X-Nutzers nötig. Der Artikel geht davon aus, dass der Zugriff mit den Rechten des Admin-Users »admin« geschieht. Die Ceph-Dokumentation erläutert alles Wesentliche über die Nutzerverwaltung [3].
Das Passwort des »admin« -Nutzers liegt auf dem Master-Server in »/etc/ceph/ceph.client.admin.keyring« ; es handelt sich um den Eintrag hinter »key =« , im Beispiel etwa »AQCj2YpRiAe6CxAA7/ETt7Hcl9IyxyYciVs47w==« . Dieser Schlüssel gehört in eine gesonderte Datei mit einem frei wählbaren Namen, zum Beispiel »/etc/ceph/admin.secret« . Nun lässt sich Ceph-FS nach »/mnt/samba« mounten:
sudo mount -t ceph IP:6789:/ /mnt/samba -o name=admin,secretfile=/etc/ceph/admin.secret
Bei »IP« sollte die IP-Adresse eines MON-Servers stehen, also etwa die lokale IP-Adresse von Alice. Analog lässt sich der Mount auch per Eintrag in »/etc/fstab« realisieren:
IP:6789:/ /mnt/samba ceph name=admin,secretfile=/etc/ceph/admin.secret,noatime 0 2
Nach dem Neustart des Systems ist Ceph-FS dann unter »/mnt/samba« sofort aktiv. Der Eintrag samt Schlüsseldatei sollte auf allen Hosts vorhanden sein, die ein Ceph-FS-Dateisystem mounten wollen.
Schritt 3: CTDB verwenden
Damit CTDB nutzbar ist, muss der Clustermodus beim Kompilieren von Samba explizit aktiviert worden sein. Alle aktuellen Distributionen kommen mit clusterfähigem Samba in einer hinreichend aktuellen Version daher – ähnlich wie »vfs_ceph« benötigt auch CTDB Samba in der Version 4.2 oder neuer. Darüber hinaus sollte Samba bereits grundlegend eingerichtet sein.
Mindestens vier Parameter müssen in der »smb.conf« stehen, damit CTDB funktionieren kann:
- netbios name = Eintrag
- clustering = yes
- idmap config * : backend = autorid
- idmap config * : range = 1000000-1999999
Das separate Paket »ctdb« muss ebenfalls installiert sein, es enthält alle für CTDB relevanten Programme.
Hinzu kommen mehrere CTDB-spezifische Konfigurationsdateien, die an lokale Voraussetzungen anzupassen sind. Auch hier gibt es einige nötige Werte:
- »CTDB_NODES« verweist auf eine Datei, in der alle beteiligten Knoten des Samba-Clusters aufgelistet sind. Der Default ist »/etc/ctdb/nodes« , das Programm erwartet in der Datei pro Zeile die IP-Adresse eines der Clusterknoten.
- »CTDB_RECOVERY_LOCK« verweist auf eine Datei, die CTDB auf dem geteilten Speicher erwartet, im Beispiel etwa »/mnt/samba/lock« .
- »CTDB_PUBLIC_ADRESSES« ist etwas kompliziert: Hier erwartet CTDB die Datei mit einer Liste aller Netzwerkinterfaces der einzelnen Knoten samt zugehöriger IP. Die Syntax der Datei ist »IP/Netzmaske Netzwerkinterface« . Für das Beispiel von Daisy und Eric könnte die Datei etwa so aussehen: »10.42.0.1/24 eth0 10.42.0.2/24 eth0«
An »CTDB_PUBLIC_ADRESSES« wird deutlich, dass CTDB ein kleiner Clustermanager ist: Die Angabe der IP-Adressen benötigt CTDB, damit es nach dem Ausfall eines Knotens dessen IP-Adresse auf einem anderen Samba-Knoten aktivieren kann. Genau darin liegt auch der Unterschied zwischen dieser Datei und »CTDB_NODES« : In ersterer erwartet Samba ein Netz, das die CTDB-Instanzen für die Kommunikation per CIFS zu den Clients nutzen. In »CTDB_NODES« hingegen stehen die privaten IPs, über die die CTDB-Instanzen untereinander kommunizieren.
Fällt der Host, dem eine IP aus »CTDB_PUBLIC_ADRESSES« zugewiesen ist, zu irgendeinem Zeitpunkt aus, dann sorgt CTDB automatisch dafür, dass die IP woanders aktiv wird und somit auch die CIFS-Clients weiterhin Antworten auf ihre Anfragen erhalten. Die IP-Adressen aus »CTDB_PUBLIC_ADRESSES« sind außerdem in das DNS entsprechend einzutragen, sodass die Namensauflösung funktioniert.
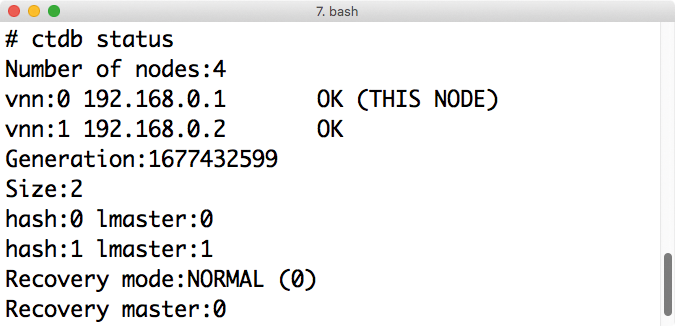
Abbildung 4: Mit dem Befehl »ctdb status« lässt sich der Admin Informationen über den Zustand des CTDB-Clusters anzeigen.
Danach ist Samba startklar: Zusätzlich zu den bekannten Diensten Smbd, Nmbd und Winbind muss nun auch der Dienst »ctdb« laufen. Ob die CTDB-Einrichtung funktioniert hat, zeigt im nächsten Schritt der Befehl »ctdb status« : Hier sollten nun mehrere Nodes auftauchen und der Cluster sollte sich im Status »NORMAL« befinden (Abbildung 4). Danach lässt sich jeder der CTDB-Knoten als einzelner Samba-Server nutzen.
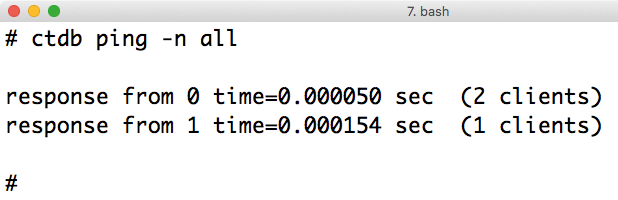
Abbildung 5: »ctdb ping« führt einen Ping-Befehl zu allen Knoten des CTDB-Clusters aus und zeigt die Resultate an.
Trotzdem arbeitet er jedoch im Hintergrund auch als Teil des Clusters. Sogar einen eingebauten Healthcheck gibt es: Der Befehl »ctdb ping« pingt vom aktuellen Knoten aus alle anderen CTDB-Knoten und zeigt die Antwortzeiten an (Abbildung 5).
Infos
- Ceph Jewel für Ubuntu 16.04: http://download.ceph.com/debian-jewel/dists/xenial/main/binary-amd64/
- »vfs_ceph« für Samba: http://manpages.ubuntu.com/manpages/xenial/man8/vfs_ceph.8.html
- Ceph-X-Verwaltung: http://docs.ceph.com/docs/hammer/rados/operations/user-management/
Der Autor

Martin Gerhard Loschwitz arbeitet als Cloud Architect bei Sys Eleven. Er beschäftigt sich dort intensiv mit den Themen Open Stack, Distributed Storage und Puppet. Außerdem pflegt er in seiner Freizeit Pacemaker für Debian.





