
© khunaspix, 123RF
Container sind für verschiedene Devops-Konzepte eine unerlässliche Zutat. Doch falsch eingesetzt richten sie mehr Schaden als Nutzen an. Wer Docker & Co. im produktiven Umfeld verwendet, sollte die folgenden Ratschläge beherzigen.
Ähnlich wie den Begriff “Cloud” führen heute so viele “Devops” im Munde, dass sie sich nicht mehr auf eine einheitliche Definition einigen können. Die gängigste Annahme sieht vor, dass Devops als Philosophie anzusehen ist, nach der die Optimierung von Abläufen am Ende automatisch dazu führt, dass Entwicklung und Betrieb von IT besser aufeinander abgestimmt sind. Konkrete Vorgaben im Hinblick auf zu nutzende Werkzeuge oder Programme machen die meisten Definitionen nicht mehr.
Dennoch haben sich Container flächendeckend durchgesetzt. Der kometenhafte Aufstieg von Docker hat die Technik in den Köpfen von Entwicklern, Admins und Planern gleichermaßen verankert. Logisch: Container bieten Entwicklern einerseits in Windeseile eine saubere Umgebung, in der sie beliebig experimentieren können. Andererseits minimieren sie den Aufwand beim Deployment beträchtlich. Man könnte fast meinen, ein Container sei die technische Umsetzung des Devops-Prinzips.
Doch wer in klassischer Manier mit Containern umgeht und sie in der beschriebenen Weise nutzt, geht gerade im betrieblichen Alltag ein erhöhtes Risiko ein, denn eine Blackbox (Abbildung 1) in Form eines Containers ist für Admins ein Horrorszenario. Der folgende Artikel erläutert die potenziellen Probleme von Containern und stellt Alternativen vor. Denn wer Container in der richtigen Weise nutzt, profitiert von ihren Vorteilen und umgeht die Fallen.
Abbildung 1: Der Community-Teil des Docker-Hub enthält viele Images, deren Herstellung meist kaum nachvollziehbar ist. Zum Problem wird das beispielsweise beim Updaten.
Bestandsaufnahme
Um die Probleme im Zusammenhang mit Containern zu verstehen, hilft ein Blick auf die Ausgangssituation, wenn Docker zum Einsatz kommt: Entwickler arbeiten vor sich hin und haben am Ende einen fertigen Container, in dem die gewünschte Applikation problemlos läuft. Meist beginnen sie ihre Arbeit bereits mit einem fertigen Abbild: Wer etwa eine Webanwendung auf Basis von Ubuntu 16.04 entwickeln möchte, nimmt einen Container, in dem Ubuntu und Apache bereits vorinstalliert sind, und fügt die eigene Anwendung hinzu. Läuft sie nach ein paar Anpassungen in diesem Container, erstellt der Entwickler daraus erneut ein Abbild und stellt es dem Admin zur Verfügung.
Der ist für den Betrieb der IT-Infrastruktur zuständig: Er lädt den Container also auf einen Docker-Host und nimmt ihn dort in Betrieb. Unmittelbar danach steht der Dienst des Containers im Netz zur Verfügung – Entwickler und Admin, klopfen sich auf die Schulter (sofern nicht einer beide Rollen in Personalunion verkörpert) und entfernen den Eintrag von ihrer To-do-Liste. Dass der Container zum Problem werden könnte, wird erst viel später offenbar.
Notwendige Updates werden zum Problem
Auffallen wird das Problem, wenn Updates eingespielt werden müssen. Meist handelt es sich um Sicherheitsupdates, und man muss nach etwaigen Beispielen in der Vergangenheit nicht lange suchen. Erinnert sei an verschiedene Fehler in der SSL-Standardbibliothek, die deren Austausch nötig machten. Auch das Problem im Resolver der C-Bibliothek (»libc« ) vor ein paar Monaten ist so ein Fall.
Wenn es hart auf hart kommt, sieht sich der Admin mit der Anforderung konfrontiert, viele Systeme gleichzeitig zu aktualisieren. Für physische Rechner ist die Lösung einfach: Sobald der Distributor ein passendes Update bereitstellt, installiert die Update-Funktion des Systems oder eine Automatisierungslösung die entsprechenden Pakete.
Bei Containern nach Docker-Art ist die Sache komplizierter. Weil sie oft auf dem Basis-Image eines Drittanbieters beruhen, kann der Admin kaum etwas über ihre Update-Fähigkeit sagen. Im besten Fall hat auch der Container automatische Updates aktiviert und ist entlang gängiger Standards gebaut, sodass das Update funktioniert. Nutzt die Applikation innerhalb des Containers aber zum Beispiel eigene Bibliotheken, ist das Chaos perfekt. Eine lokal gebaute C-Bibliothek innerhalb des Containers lässt sich auch nur direkt im Container updaten.
Alternativ dazu könnte der Entwickler den Container auch neu bauen, sodass er danach die notwendige Sicherheitskorrektur von vornherein enthält. Dazu müsste aber sichergestellt sein, dass der Entwickler den Container samt Applikation jederzeit wieder neu erstellen kann. Je nach Anzahl der ausgerollten Container müsste das außerdem für viele verschiedene Container zur gleichen Zeit passieren. Wer also Hunderte oder Tausende Container nutzt, sieht sich einem Mammutprojekt gegenüber.
Entwickeln und betreiben
Container wie im Beispiel eignen sich, um den wichtigsten Unterschied zwischen Entwicklung und Betrieb zu verdeutlichen. Entwicklung hat in der Regel die Aufgabe, vorhandene Applikationen zu verbessern. Dazu gehören neue Funktionen genauso wie die Anpassung an andere Voraussetzungen.
Liefert beispielsweise eine Komponente, deren Funktionen die eigene Applikation nutzt, neue Features, wird der Entwickler diese auch in der Anwendung nutzen wollen. Die Aufgabe des Entwicklers ist es aber nicht, sich über den Betrieb der Anwendung Gedanken zu machen. Deshalb genügt ihm meist die Erkenntnis, dass eine neue Funktion innerhalb seiner Entwicklungsumgebung wie gewollt ihren Dienst verrichtet.
Admins haben im Hinblick auf den Betrieb einer Plattform dagegen völlig andere Interessen. Für sie stehen die Faktoren Stabilität, Sicherheit sowie Wartbarkeit im Vordergrund. Neue Features sind zwar schön, doch die neue Softwareversion muss sich im Rahmen des vorhandenen Konzeptes betreiben lassen. Freilich ist es häufig mühsam, eine Anwendung so auszurollen, dass sie in die vorhandene Infrastruktur passt. Das Deployment der ursprünglichen Entwicklungsumgebung als Container ist hier eine Versuchung, die zunächst einfach realisierbar erscheint. Admins sollten ihr aus den genannten Gründen allerdings widerstehen.
Das alles bedeutet aber nicht, dass Firmen gänzlich auf Container verzichten müssen. Schließlich bieten diese zweifellos Vorteile. Das beschriebene Dilemma entsteht nicht dadurch, dass überhaupt Container zum Einsatz kommen, sondern durch die problematische Art und Weise ihrer Verwendung. Es gibt durchaus Lösungen, um Container ohne Dauerfrust für den Admin zu betreiben.
Alternative 1: Overlay-FS
Einer der großen Nachteile des klassischen Container-Deployments ist die Tatsache, dass an jedem Container ein komplettes Linux-System hängt. Zwar ist ein Container per se kein eigenständiges System, aber durch die vollständige Linux-Distribution im Hintergrund wird er zu einem eigenen Punkt, den es bei der Wartung zu beachten gilt.
Den Overhead in Sachen Plattenplatz kann man dabei noch vernachlässigen, denn schließlich gehört Storage zu den billigsten Posten. Doch der zusätzliche Wartungsaufwand schmerzt – vor allem vor dem Hintergrund, dass das System, das meist viele Container gleichzeitig beheimatet, ja selbst eine vollständige Linux-Installation ist.
Das Problem lässt sich elegant mit Overlay-FS umgehen. Overlay-FS ist ein Konkurrenzprodukt zu Au-FS, das dem einen oder anderen vielleicht noch von Knoppix bekannt ist. Die Idee: Programme greifen durch das Overlay-FS hindurch auf die ursprünglichen Dateien des Hostsystems zu. Legt der Admin auf einem Overlay-FS-Mount neue Dateien an oder verändert vorhandene Dateien, so schlägt sich das nicht auf das Dateisystem des Hosts nieder. Die Differenz zwischen Host- und Overlay-FS verwaltet stattdessen Overlay-FS selbst. Die Rede ist vom Union-Mount: Der Admin sieht sowohl die Inhalte des Hosts als auch die Änderungen, die er auf dem Overlay-FS angelegt hat (Abbildung 2).
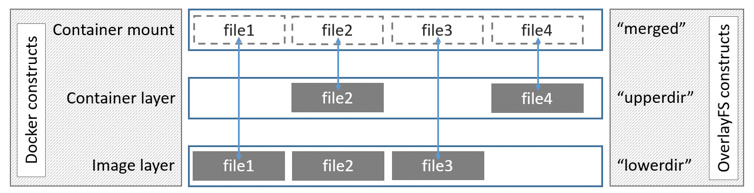
Abbildung 2: Overlay-FS ermöglicht es Containern, das Dateisystem ihres Hosts zu nutzen – Veränderungen speichert der Overlay-FS-Treiber in einem separaten Image.
Wer sich für Container auf Overlay-FS entscheidet, investiert also erst einmal einiges an Arbeit in das auf dem Host installierte Betriebssystem. Hier gilt es im ersten Schritt, eine solide Basis zu schaffen: Neben den grundsätzlichen Dingen muss das Hostsystem für Overlay-FS die Komponenten haben, die später die genutzten Container benötigen. Laufen etwa vorrangig PHP-Anwendungen als Container, sollten die benötigten PHP-Module auf dem Host vorhanden sein. Es gilt: Je mehr Dinge im Hostsystem vorhanden sind, desto kleiner werden die jeweiligen Container.
Host-Betriebssystem als Basis
Der Wartungsaufwand reduziert sich erheblich, weil sich der Overlay-FS-Treiber Änderungen des Hosts merkt und an seine Clients weitergibt: Installiert der Admin also auf dem Host eine neue SSL- oder C-Bibliothek, so kümmert sich – dank des Union-Mount-Prinzips – Overlay-FS darum, dass die Änderungen auch bei allen Overlay-FS-Instanzen ankommen. Am Ende genügt der Restart der jeweiligen Container, um die Änderung in Kraft zu setzen.
Für Overlay-FS ist der Einsatz eines aktuellen Kernels übrigens empfohlen. Wer auf Ubuntu in einer LTS-Version setzt, hat gute Karten: Schließlich stellt Canonical für die jeweils aktuelle LTS-Version auch Backports der Kernel späterer Ubuntu-Versionen bereit. Für Ubuntu 14.04 war bei Redaktionsschluss etwa Linux 4.2 verfügbar, nach der Veröffentlichung von Ubuntu 16.04 wird auch der zu dieser Version gehörende Kernel bald seinen Weg in Ubuntu 14.04 finden. Andere Distributionen mit Langzeit-Support verfolgen allerdings andere Strategien im Hinblick auf Kernelupdates; ein Blick in die jeweilige Dokumentation hilft.
Eine Frage des Containers
Overlay-FS auf Host-Seite ist nur die halbe Miete, wenn es um die effiziente Verwaltung von Containern geht – die andere Hälfte muss die Containerlösung selbst beisteuern. Docker versteht bereits seit einigen Versionen den Umgang mit Overlay-FS, doch stellt sich naturgemäß eine Frage: Wer den gesamten Wust an Image-Funktionalität auf Docker-Seite umgeht, hat kaum noch Vorteile durch den Einsatz von Docker.
Ein Blick auf Alternativen schadet also nicht: Auch LXC hat einen Overlay-FS-Treiber (Abbildung 3) und ist in Sachen Funktionalität kaum weniger potent als Docker. Logisch: Docker und LXC nutzen im Linux-Kernel dieselben Funktionen, etwa Cgroups und Namespaces. Tatsächlich ist LXC die ältere der beiden Lösungen und diente Docker in vieler Hinsicht als Vorbild. Wer sich den Docker-Weg ersparen möchte, schaut bei der LXC-Konkurrenz vorbei.
Abbildung 3: Overlay-FS lässt sich auch zusammen mit LXC nutzen. Außerdem verwenden Docker und LXC auch dieselben Kernelfunktionen wie Cgroups oder Namespaces.
Eine Aufgabe bleibt dem Admin aber auch mit LXC nicht erspart: Er muss die benötigten Container starten, sie also so vorbereiten, dass sie für Entwickler brauchbar sind. Bei Docker ist diese Funktion in den Docker-Werkzeugen schon enthalten. Wer LXC nutzt, legt die benötigten Container entweder händisch an oder integriert das Provisionieren der Container in seine Automatisierung. Die ist in Container-Setups größeren Maßstabs ohnehin nötig: Schließlich muss es immer möglich sein, das Setup um weitere Hypervisor-Hosts für neue Container zu erweitern, wenn dem bisherigen Setup die Ressourcen ausgehen.
Ansible ist nicht nur die Automatisierungslösung der Stunde, es verfügt auch über wirklich gut ausgebaute LXC-Funktionalität: Das komplette Provisionieren von Containern auf LXC-Basis ist per Ansible schnell erledigt (Abbildung 4). Auf Wunsch lassen sich sogar Dutzende Container gleichzeitig starten, und zwar aus einem einzelnen Playbook für Ansible.
Abbildung 4: Ansible hat ein eigenes LXC-Modul und lässt sich deshalb als Automatisierungswerkzeug perfekt mit dem Container-Tool kombinieren.
Klare Verhältnisse
Ein Container-Setup auf LXC-Basis erfüllt sowohl die Bedürfnisse von Admins als auch die der Entwickler. Denn wie beim typischen Deployment-Ansatz steht es auch in diesem Zusammenhang den Entwicklern offen, innerhalb des Containers Veränderungen nach Belieben durchzuführen. Weil jeder einzelne Container vom Hauptsystem strikt getrennt ist, schlagen sich Änderungen in den Containern auf dem Host nicht nieder. Anders als im typischen Fall kennt der Admin aber die Basis des Containers und kann bei Bedarf sogar Änderungen in dessen Dateisystem über den Overlay-FS-Umweg anstoßen. Der Container ist also nicht mehr eine Blackbox, sondern beruht auf definierten Standards.
Freilich lässt sich auch so nicht mit letzter Gewissheit verhindern, dass Entwickler in Containern eine Sicherheitslücke aufreißen, die der allgemeine Update-Lauf eben nicht durch Änderungen des Hostsystems repariert. Doch die große Mehrheit der Entwickler wird sich mit dem zufriedengeben, was sie per Overlay-FS schon in ihrem Container vorfinden. Wenn also doch einmal händische Updates nötig sind, ist die Zahl der betroffenen Installationen viel kleiner.
Alternative 2: Reproduzierbare Container
So elegant die vorgestellte Lösung auf Basis von Overlay-FS auch ist – sie passt vielleicht nicht zu den eigenen Anforderungen. Wer sich nicht auf ein einziges Standardsetup beziehen kann, weil er verschiedene Ubuntu-Versionen unterstützen muss oder zu Ubuntu noch Centos dazukommt, hat zwei Optionen: Entweder stellt der Admin sich entsprechend viel Hardware ins Rack, um die nötigen Overlay-Systeme für die unterschiedlichen Distributionen anzubieten. Wenn das nicht geht, bleiben nur vollwertige Container.
Die gute Nachricht ist: Hier kann Docker verschiedene Stärken ausspielen, und wer Docker sinnvoll nutzt, umgeht auch das zuvor beschriebene Blackbox-Problem. Das Zauberwort heißt Reproduzierbarkeit: Container, die sich jederzeit problemlos wiederherstellen lassen, verursachen im administrativen Alltag wenig Probleme.
Die Diskussion erinnert an den Vergleich zwischen Kätzchen und Herdentier, der im Cloudkontext gern bemüht wird: Kätzchen sind klassische Systeme alter Schule, die – wenn überhaupt – in geringem Maße automatisiert sind und viel Handarbeit erfordern. Das Herdentier steht als Sinnbild für virtuelle Maschinen, die alle auf gleiche Weise automatisiert ausgerollt werden und zu jedem Zeitpunkt durch eine veränderte Version ihrer selbst austauschbar sind.
Der Faktor Reproduzierbarkeit löst das Problem der schieren Container-Anzahl, mit denen ein Admin es im Problemfall zu tun hat: Wenn sich per Knopfdruck viele Container automatisch neu anlegen lassen, entfällt die sehr zeitaufwändige Reparatur der einzelnen Instanzen.
Docker liefert das Rüstzeug
Dass viele Admins Docker nutzen, um riesige Mengen an Kätzchen zu bauen, ist nicht vorrangig Schuld der Containerlösung. Tatsächlich lassen sich auch mit Docker saubere Container erstellen. Ein einfaches Beispiel zeigt dies eindrücklich:
FROM ubuntu RUN apt-get update && apt-get install -y x11vnc xvfb firefox RUN mkdir /.vnc RUN x11vnc -storepasswd 1234 ~/.vnc/passwd RUN bash -c 'echo "firefox" >> /.bashrc' EXPOSE 5900 CMD ["x11vnc", "-forever", "-usepw", "-create"]
Der gesamte Codeblock erzeugt einen Docker-Container, in dem sowohl X11 als auch Firefox laufen und der den Zugriff von außen per VNC erlaubt. Auf Grundlage eben dieses Docker-File lassen sich auf jedem Host gleiche Docker-Container reproduzierbar anlegen. Basis für den Vorgang ist das Ubuntu-Abbild vom Docker-Hub, das quasi offiziell ist und das der Anbieter auch pflegt.
Zugegeben: Das Beispiel ist übersichtlich. Aufwändige Webapplikationen werden sich mit so wenigen Befehlen kaum zufriedengeben, und Docker-Files werden nicht dadurch lesbarer, dass sie sich über mehrere Bildschirmseiten ziehen. Der zweite elementare Bestandteil reproduzierbarer Container ist deshalb der Einsatz einer Automatisierungslösung.
Puppet, Chef, Ansible …
Ob dazu Puppet, Chef, Ansible oder eine andere Lösung zum Einsatz kommt, ist aus Admin-Sicht zweitrangig. Wichtig ist lediglich, dass ein frischer, auf einem offiziellen Abbild basierender Container nach Aufruf des Tools die gewünschte Funktion liefert. Das Gros der Arbeit bleibt dabei zur Abwechslung nicht am Admin hängen, sondern am Entwickler: “Funktioniert auf meinem Rechner im Container” reicht in dieser Konstellation nicht; obendrein muss das Setup auch jederzeit reproduzierbar sein.
Admins sind in vielen Fällen nicht in der Lage, das zu leisten: Sie kennen einfach nicht alle potenziell auszurollenden Anwendungen bis ins letzte Detail – schon gar nicht, wenn es um neu entwickelte Versionen einer Anwendung geht. Natürlich spricht aber nichts dagegen, dass Admins ihren Entwicklern bei der Umsetzung der Automatisierung unter die Arme greifen. Denn durch diese Kooperation ersparen sich beide Seiten aufwändige Nacharbeiten, die andernfalls später vielleicht anstehen.
Ganz sicher Aufgabe des Admins ist es nämlich, auf die Einhaltung seiner selbst definierten Regeln zu achten. Bittet ein Entwickler um das Deployment eines Containers für den Live-Betrieb, schadet ein kurzer Blick vor dem Start nicht. Kommt anstelle des nackten Image der gewählten Distribution ein modifiziertes Image zum Einsatz, ist das ein hartes K.o.-Kriterium.
Solch ein Betriebskonzept erfordert anfangs zwar Geduld und den Willen zur Kooperation auf allen Seiten. Doch etabliert es letztlich Betriebsabläufe, von denen Admins wie Entwickler profitieren: Erstere haben wartbare Container, Letztere bringen Entwicklungsumgebungen auf Containerbasis deutlich schneller auf den Weg als beim händischen Setup.
Alternative 3: Base-Images selber bauen
Der dritte Betriebsmodus für den Umgang mit Containern ist eigentlich kein eigenes Konzept, sondern eine Abwandlung von Alternative 2. Doch ist sie noch radikaler: Sie geht davon aus, dass Basisabbilder für Container nicht aus dem Internet kommen. Stattdessen ist ihre Erstellung der erste Arbeitsschritt des eigenen Entwicklungsprozesses. Wenn Entwickler zusammen mit Admins also Container für den produktiven Einsatz bauen, fangen sie quasi bei null an und rufen eine Kette von Befehlen auf, an deren Ende ein spezieller Container für den jeweiligen Zweck steht.
Das Konzept wirkt im ersten Augenblick unnötig komplex: Schließlich ist es deutlich komfortabler, das Ubuntu-Basis-Image vom Docker-Hub als Grundlage zu verwenden. Das Herrichten der nötigen Umgebung, in der Container entstehen können, nimmt hingegen einige Zeit in Anspruch, und auch der Vorgang des Zusammenstellens der Container dauert in den meisten Fällen länger als der Download eines Basis-Image. Für Setups mit wenigen Containern eignet sich dieser Ansatz deshalb weniger.
Zum Tragen kommen die Vorteile dieses Lösungswegs stattdessen in großen Umgebungen mit sehr vielen Containern: Weil das Entwickler- und das Betriebs-Team von Anfang an die volle Kontrolle über den Inhalt der Container haben, generieren sie diese gleich so, dass sie alle benötigten Komponenten enthalten. Wenn zum Beispiel für den Betrieb einer Applikation spezifische Pakete erforderlich sind, landen diese gleich installiert im Container. Eine Automatisierungslösung, die Pakete nach dem Container-Start nachinstalliert, ist überflüssig.
Wer seine Toolchain für den Containerbau im Griff hat, entledigt sich auch elegant des Update-Problems: Satt in laufenden Containern Updates zu installieren, generiert das Entwicklungs- oder das Betriebs-Team einfach neue Container, die alle benötigten Updates bereits enthalten. Das passiert im besten Fall einfach per Knopfdruck: Der Admin stößt den Neubau aller laufenden Container an und ersetzt schließlich die laufenden Container durch das neue Pendant. Zudem hat er in diesem Szenario die Gewissheit, dass seine Container-Images keine unerwünschten Komponenten enthalten.
Multistrap als Hilfe
Wer sich für diese Herangehensweise entscheidet, findet viele Werkzeuge im Netz, die beim Anlegen von Docker-Containern helfen. Multistrap ist ein gutes Beispiel (Abbildung 5): Es richtet sich an Fans von Debian oder Debian-basierten Distributionen. Unter [1] findet sich eine fertige Multistrap-Konfiguration für Ubuntu 16.04. Es genügt, Multistrap zusammen mit der Konfigurationsdatei aus dem besagten Repository aufzurufen, damit ein Docker-Container für die aktuelle LTS-Version von Ubuntu entsteht.
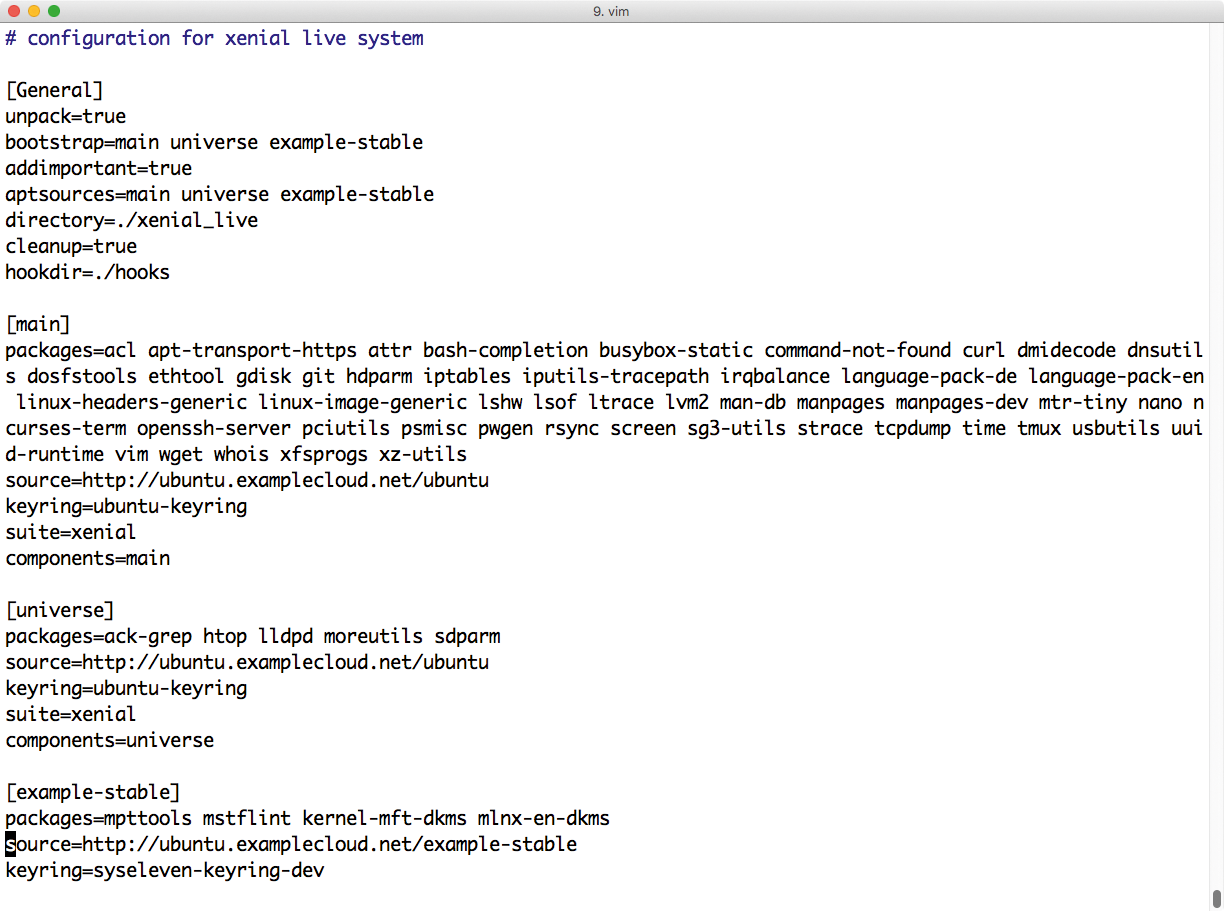
Abbildung 5: Das Tool Multistrap erstellt neue Container von Grund auf – Admins erhalten auf diese Weise eine genaue Liste der enthaltenen Dienste und Pakete.
Multistrap startet »customize.sh« am Ende des Bauvorgangs. Das Shellskript erlaubt das Ausführen beliebiger Befehle im Dateisystem des künftigen Containers, bevor Multistrap daraus das Abbild für den Container baut. Wer sich hier nicht zu sehr in Bash-Magie versteifen möchte, nimmt zusätzlich eines der Automatisierungswerkzeuge.
Fazit
Container sind nützlich und stellen in Devops-Konzepten eine Bereicherung dar – solange man einige Regeln beachtet. Wenn Container reproduzierbar sind, lassen sie sich auch effizient verwalten. Blackboxes führen dagegen zu Problemen. Wer Container einsetzt, sollte das beherzigen.
Infos
- Multistrap-Templates für Ubuntu 16.04: https://github.com/Blitznote/docker-ubuntu-debootstrap





