
© mikekiev, 123Rf
Was sagen Metadaten über vernetzte Geräte? Aus diesen leicht zu sammelnden Informationen und dem Umfang lassen sich mehr Schlüsse ziehen, als man denkt. Und das nicht nur in guter Absicht.
Welche Betriebssysteme sind im eigenen Netz installiert? Welche Software läuft unter ihnen? Diese und ähnliche Fragen stellen sich häufig in IT-Abteilungen, besonders wenn entweder die Benutzer eine Schatten-IT betreiben oder wenn die Dokumentation und die Automatisierung der Softwareverteilung noch ausbaufähig sind. Hinter solchen und ähnlichen Fragen stehen überdies nicht immer lautere Absichten, auch Angreifer interessieren sich für das Inventar.
Zum Ermitteln des Ist-Standes sind in den letzten Jahren viele Verfahren entwickelt worden, die entweder auf aktivem Messen [1] (etwa mit Nmap) oder auf passivem Mitschneiden von Netzverkehr [2] beruhen. Das passive Verfahren analysiert den kompletten Netzverkehr oder Teile davon, um daraus Rückschlüsse zu ziehen. So überprüft es beispielsweise anhand der IP-Adresse beziehungsweise des DNS-Namens, ob ein Gerät regelmäßig die Domain »update.microsoft.com« besucht, was den Schluss nahelegen würde, dass es ein Microsoft-Betriebssystem benutzt.
Dieser Artikel stellt nun einen neuartigen Ansatz vor. Er beruht ebenfalls auf der Analyse des Netzverkehrs, betrachtet aber für die Analyse ausschließlich die weit verbreiteten und oftmals leicht verfügbaren Metadaten der Netzkommunikation in Form von Flowrecords. Die Analyse der Metadaten von Netzwerkverbindungen kann einige Vorteile bieten: Sie braucht viel weniger Speicher und Rechenleistung als die Analyse kompletter Pakete, sie wahrt den Datenschutz, sie braucht keinen Mirrorport am Router, sie ist vergleichsweise schnell.
Das hier diskutierte Beispiel benutzt dafür Flowrecords, das sind kurze Informationen, die unter anderem die Quelle und das Ziel eines IP-Pakets angeben, aber auch das verwendete Protokoll (etwa TCP, UDP oder ICMP) oder die übertragene Bytemenge. Typische Vertreter von Flowrecords sind Netflows, Cflows oder IPFIX, die jeweils aus verschiedenen Produkten stammen und auch unterschiedlichen Details beinhalten.
Die grundsätzliche Idee besteht darin, aus den vorhandenen Informationen – soweit es geht – Rückschlüsse auf die übermittelten Daten zu ziehen. Dabei ist schnell klar, dass sich Aufrufe von einfachen Webseiten oder verschickte E-Mails in ihrer Repräsentation in den Metadaten nur marginal unterscheiden. Deshalb lässt sich über den Inhalt der übertragenen Nachricht oder die betrachtete Unterseite einer Webseite nichts sagen.
Das trifft jedoch nicht bei Downloads zu, da sie allein auf Grund ihrer Größe deutliche Unterscheidungsmerkmale erkennen lassen. Ist erst einmal ermittelt, was die betrachteten Hosts herunterladen, lässt sich leicht auf das verwendete Betriebssystem oder die verwendete Software schließen, insbesondere wenn es sich um Updates bereits installierter Programme handelt.
Aufzeichnen von Flowrecords
Flowrecords lassen sich, wie in der Abbildung 1 skizziert, prinzipiell überall dort aufzeichnen, wo Zugriff auf den Netzverkehr besteht. Das kann entweder bei der direkten Kommunikation im eigenen Subnetz (1) passieren oder auch bei der unternehmensinternen Kommunikation an einem der zwischengeschalteten Switche (2). Laufen hingegen die Netzpakete zu einem externen Kommunikationspartner, dann ist die Erhebung von Flowrecords ebenfalls in den unternehmenseigenen Switchen (3), beim Edge-Router (4) oder auf dem Transportweg im Internet (5) möglich.
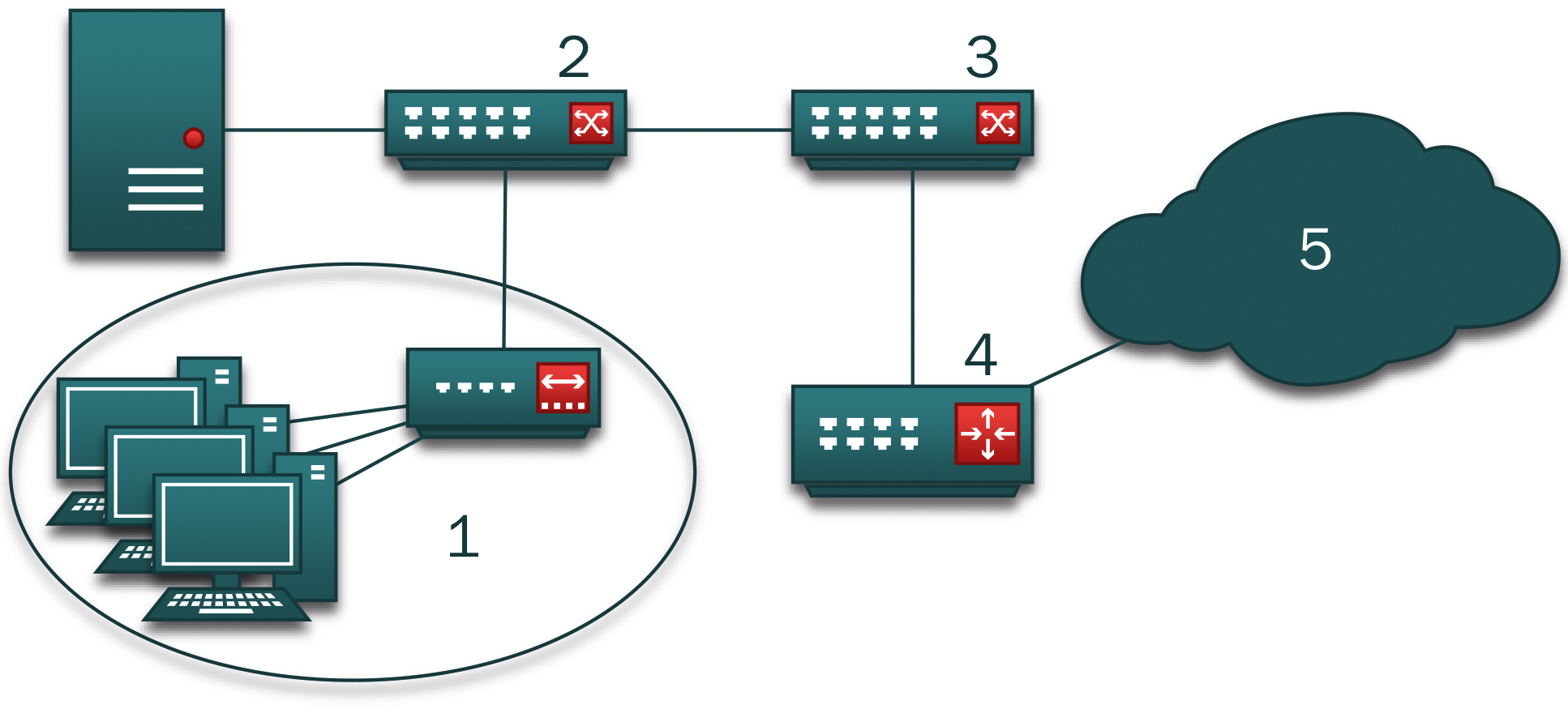
Abbildung 1: Aufzeichnungsorte für Flowrecords.
Um selber aktiv Metadaten in Form von Flowrecords aufzuzeichnen, gibt es unter Linux eine Reihe von geeigneten Programmen. Der im nächsten Abschnitt beschriebenen Testaufbau verwendet die Kombination aus Softflowd [3] und Flowtools [4], um Netflows aus dem Netzverkehr abzuleiten und als Flowrecords in Dateien zu speichern.
Aufzeichnen von Flow
Softflowd kann aus dem Netzverkehr, den es auf einem ausgewählten Netzinterface mitschneidet oder aus einer vorher aufgezeichneten Packet-Capture-Datei liest, Cisco-Netflow-Daten generieren und diese an einen Flowcollector schicken. Dabei versendet es immer vollständige Flows. Der Flowcollector erhält anschließend nur Metadaten der Verbindung übermittelt, also etwa die Quell- und Zieladressen und die Ports sowie Min-, Max-, Avg-, Total-Bytes und die Anzahl der beobachteten Pakete.
Weil viele Geräte im Netzwerk wie beispielsweise Switche und Router ebenfalls Cisco-Netflows auf die gleiche Weise generieren und verschicken, eignet sich Softflowd besonders, um zu Testzwecken solche Geräte ohne irgendwelchen Hardware-Aufwand in einer virtuellen Umgebung nachzuahmen.
Als Flowcollector, der die von Softflowd verschickten Flows empfängt und weiterverarbeitet, kam »flow-capture« aus der Flowtools-Programmsammlung zum Einsatz. Flow-capture speichert die empfangenen Flows in Dateien, die dann weiter analysierbar sind. Die Dateien rotieren automatisch, sodass eine Datei immer die Flows aus einem bestimmten Zeitfenster speichert. Alte Dateien lassen sich entweder nach Datum oder alternativ nach der Menge des belegten Plattenplatzes löschen.
Sowohl »softflowd« als auch »flow-tools« sind in den Paketquellen von Debian und anderen Linux-Distributionen enthalten und lassen sich daraus installieren. Zum Aufzeichnen von Netflows muss »softflowd« nur mit der Option »-i« das zu verwendende Interface und mit der Option »-n« die IP-Adresse sowie den Port des Zielsystems angeben. Standardmäßig läuft Softflowd sofort als Daemon im Hintergrund. Wenn Softflowd im Vordergrund laufen soll, muss der Benutzer zusätzlich die Option »-d« setzen.
Das folgende Beispiel generiert aus dem am Interface »eth0« beobachtbaren Netzverkehr Netflows und schickt diese an Localhost:
softflowd -i eth0 -n 127.0.0.1:4432
Zum Überprüfen, ob Softflowd tatsächlich Flows aufzeichnet, bietet sich das mitgelieferte Programm »softflowctl« an. Der Befehl »softflowctl statistics« (Listing 1) gibt aktuelle Statistiken zu den analysierten Paketen aus. Er zeigt an, wie viele Pakete Softflowd insgesamt schon verarbeitet hat und wie viele Flows er als vollständig (»expired« ) erkannt und verschickt (»exported« ) hat. Softflowctl sollte der Admin mit der Option »shutdown« auch verwenden, um Softflowd sauber zu beenden. Dabei überträgt es alle noch nicht übermittelten Flows an den Collector und beendet sich.
Listing 1
Softflow-Statistiken
01 # softflowctl statistics 02 03 softflowd[24361]: Accumulated statistics since 2015-12-09T13:43:24 UTC: 04 Number of active flows: 930 05 Packets processed: 94705 06 Fragments: 0 07 Ignored packets: 62238 (62238 non-IP, 0 too short) 08 Flows expired: 1208 (0 forced) 09 Flows exported: 1522 in 71 packets (0 failures) 10 Packets received by libpcap: 156943 11 Packets dropped by libpcap: 0 12 Packets dropped by interface: 0 13 14 Expired flow statistics: minimum average maximum 15 Flow bytes: 32 636 67838 16 Flow packets: 1 4 320 17 Duration: 0.00s 21.33s 1600.30s 18 19 Expired flow reasons: 20 tcp = 0 tcp.rst = 55 tcp.fin = 32 21 udp = 1116 icmp = 5 general = 0 22 maxlife = 0 23 over 2 GiB = 0 24 maxflows = 0 25 flushed = 0 26 27 Per-protocol statistics: Octets Packets Avg Life Max Life 28 icmp (1): 2896 10 146.27s 383.79s 29 tcp (6): 414827 1179 42.91s 792.03s 30 udp (17): 351002 3264 19.09s 1600.30s
Um die von Softflowd gesammelten Netflows zu verarbeitet, muss der Admin »flow-capture« starten. Flow-capture hat viele Einstellungsmöglichkeiten, die bestimmen, wie es die Flowrecord-Dateien anlegt und nach welchen Kriterien es die Dateien rotiert oder löscht. Eine simple Konfiguration zeigt dieses Beispiel:
flow-capture -w /tmp/flows -n 287 0/127.0.0.1/4432
Die Option »-w« gibt an, in welchem Verzeichnis Flow-capture die Flowrecords speichern soll. Mit der Option »-n« bestimmt der Benutzer, wie oft pro Tag eine neue Flowrecord-Datei zu erstellen ist. 287 Rotationen pro Tag ergeben rund alle fünf Minuten eine neue Datei. Das Fünf-Minuten-Intervall ist gut zum Testen geeignet, da in dieser Zeit einige Flows anfallen, man aber nicht zu lange warten muss, bis eine Datei verfügbar ist.
Die letzte Option gibt an, auf welcher IP, von welchen Host und auf welchem Port Netflows zu empfangen sind. Die Null anstelle einer IP-Adresse gilt als Wildcard für beliebige Adressen, es empfiehlt sich allerdings, den Host, der die Netflows schickt, explizit anzugeben, da sonst auch andere Hosts Flows an das System senden könnten.
Was die Flowrecords enthalten, überprüft das Tool »flow-print« aus der Flowtools-Programmsammlung. Aus den Metadaten der Verbindungen in Listing 2 ist ersichtlich, dass der erste Flow zu einem Mailclient gehört und die anderen eine HTTPS-Verbindung zeigen.
Listing 2
Beispiel für flow-print
01 # flow-print < ft-v05.2015-12-09.144601+0100 02 srcIP dstIP prot srcPort dstPort octets packets 03 212.227.xxx.xxx 129.187.xxx.xxx 6 993 38812 52 1 04 129.187.xxx.xxx 178.249.xxx.xxx 6 44678 443 1544 8 05 178.249.xxx.xxx 129.187.xxx.xxx 6 443 44678 696 6 06 129.187.xxx.xxx 178.249.xxx.xxx 6 43068 443 1080 7 07 178.249.xxx.xxx 129.187.xxx.xxx 6 443 43068 5393 4
Analyse der Metadaten aus Flowrecords
Die so zu den beobachteten Verbindungen gesammelten Metadaten sind vielfältig verwendbar. Zum Beispiel lassen sie sich nutzen, um pro IP oder Subnetz die belegte Bandbreite zu berechnen und in Rechnung zu stellen oder um mittels maschinellen Lernens Abweichungen, etwa eine sprunghafte Zunahme ausgehender Verbindungen, vom Normalzustand in der Kommunikation zu unterscheiden. Sie eignen sich auch als Rohmaterial für eine Inventarisierung der Geräte im heimischen Netz. Gelangen sie in falsche Hände, können sie Angreifern wertvolle Hinweise geben. Und nicht zuletzt sind es solche Metadaten, die im Zuge der Vorratsdatenspeicherung gesammelt werden. Wie sich zeigt, sind sie durchaus geeignet, auch inhaltliche Schlussfolgerungen zu ziehen.
Aus diesen Gründen ist es interessant zu überprüfen, wie viel diese Metadaten über den eigentlich übertragenen Inhalt aussagen und mit welcher Genauigkeit sich Rückschlüsse auf die übertragenen Daten ziehen lassen. Um dies zu erforschen, wurde in einer Testumgebung ein Webserver eingerichtet, auf dem 50 Dateien von zufälliger Größe zwischen 1 MByte und 50 MByte gehostet waren. Auf dem Webserver sammelten die Tester mit »softflowd« und »flow-capture« , wie oben beschrieben, Flowrecords, während andere Hosts die Dateien herunterluden. Auf diesen Systemen waren zum einen die Linux-Distributionen Debian und SLES und zum anderen Windows Server 2008 installiert, damit eventuelle Unterschiede durch das Betriebssystem in den Test eingingen.
Die Flowrecords landeten zur Analyse mit »flow-print« in einer Tab-separierten Datei und diese im Python-Data-Exploration-Framework Pandas [5]. Das filterte die Daten anhand der Quell-IP-Adresse und des Quell-Ports, sodass nur die Testdatei-Downloads übrig blieben. Da die Dateien immer in derselben Reihenfolge heruntergeladen wurden, ließen sich die Downloads mit der tatsächlich heruntergeladenen Datei annotieren. Um die Records zu klassifizieren, kam das Python-Framework Sklearn [6] zum Einsatz, das verschiedene Klassifizierungsmethoden implementiert.
Zum Training der Klassifikationsverfahren erzeugten die Tester einen aus 25 Wiederholungen des Downloads der 50 Dateien – also 1250 Flowrecords – bestehenden Datensatz eines ein Hop vom Webserver entfernten Linux-Hosts. Als effizienteste Klassifizierungsmethode erwies sich ein Entscheidungsbaum-Klassifizierer, der nur die Anzahl der insgesamt übertragenen Bytes betrachtet. Eine Hinzunahme der Anzahl der übertragenen Pakete brachte keine Verbesserung, sondern eine Verschlechterungen von 1 bis 10 Prozent.
Mit dieser Klassifizierung ließ sich für ebenfalls 25 Wiederholungen der 50 Downloads von einem ein Hop entfernten Linux-System eine Genauigkeit von über 98 Prozent bei der Zuordnung von Flowrecord zu heruntergeladener Datei erreichen. Von einem sechs Hops entfernten Linux-System waren 88 Prozent der Downloads korrekt der entsprechenden Datei zuzuordnen.
Nahmen die Pakete von demselben, sechs Hops entfernten System einen Umweg über einen VPN-Server, reduzierte dies die Erkennungsrate auf 61 Prozent. Das zeigt, dass bei zunehmender Entfernung vermutlich durch Paketverluste und Neu-Übertragungen die insgesamt übertragenen Bytes zu stark abweichen, um bei ähnlich großen Dateien eine hohe Genauigkeit zu erhalten.
Die Tests unter Linux verliefen unter Verwendung des Download-Programms »wget« , unter Windows wurden die Dateien mit dem Windows Internet Explorer heruntergeladen. Dabei hat sich gezeigt, dass Windows nicht für jeden Download einen neuen Port öffnet, sondern nach erfolgtem Download den Port sofort wiederverwendet. Dadurch lassen sich hier die Downloads in den Flowrecords nicht klar voneinander trennen und die Analyse schlägt fehl. Hier wäre in weiteren Test zu ermitteln, ob dieses Verhalten Browser-abhängig ist oder eventuell auch auf anderen Systemen auftritt.
Insgesamt konnte der Test zeigen, dass mit ausreichender Nähe im Netzwerk eine sehr gute Zuordnung von beobachteten Flowrecords zu den zuvor mit einem Testsystem analysierten und gelernten Dateien möglich ist. Dadurch könnte ein Netzbetreiber auf einfache Weise – ohne eine aufwändige und meist auch teure Deep-Packet-Inspektion – erkennen, welche Updates installiert wurden.
Datensicherheit
Die hier vorgestellte Methode, die erfolgten Downloads direkt aus den Metadaten zu erkennen, hat natürlich große Auswirkungen auf die allgemeine Sicherheit von Geräten im eigenen Netz. Viele Updates wie beispielsweise [7] sind nicht für alle Versionen eines Betriebssystems vorgesehen, sodass relativ schnell erkennbar ist, welche Version genau in Verwendung ist. Gegen komplette Scans des Internets oder des eigenen Subnetzes bieten verschiedene Hersteller von Sicherheitssoftware Gegenmaßnahmen an. Metadaten sind jedoch, bedingt durch ihre passive Natur, durch Schutzsysteme nicht filterbar und es ist auch nicht möglich, sie zu verhindern.
Diese Methode eignet sich also weniger für den Einsatz im großen Internet. Das liegt zum einen daran, dass die Erkennungsrate stark abnimmt, je weiter man sich vom eigentlichen Downloadserver entfernt, zum anderen stört die Tatsache, dass etliche Anbieter Updates mittlerweile über alternative Wege ausliefern. Besonders sei hier an die Peer-to-Peer-Updatefunktion von Windows 10 oder auch an Content Delivery Networks (CDN) erinnert, die ein weltweit verteiltes Netz und entsprechend viele verschiedene IP-Adressen verwalten.
Gerade diese großen Provider bieten zudem allgemein so viele Dateien unterschiedlichen Typs an, dass eine Identifikation alleine anhand der Größe der Datei recht aussichtslos erscheint. Auch ist es ohne Kenntnis der DNS-Anfragen gerade bei CDNs nicht möglich zu erkennen, welche Domain ursprünglich angefragt wurde.
Immerhin ist es aber immer wichtig zu wissen, dass die allgemeine Sorglosigkeit, die besonders in Bezug auf Metadaten herrscht, im schlimmsten Fall zum Verhängnis werden kann, nämlich dann, wenn ein Angreifer nach der Identifikation der auf einem System verwendeten Software eine nicht behobene Schwachstelle dieses Systems ausnutzen kann.
Referenz-Downloads
Für die Zuordnung der Flows zu den Downloads ist es notwendig zu wissen, welche möglichen Downloads es überhaupt gibt. Da diese Aufgabe wegen der schieren Menge an Möglichkeiten unmöglich manuell zu bewältigen ist, muss man sich eine Automatisierungsstrategie überlegen. Dabei erwiesen sich zwei Methoden als sehr zweckmäßig.
Die erste Methode basiert auf Grappern, die ähnlich funktionieren wie die klassischen Grapper der Suchmaschinen, die das Internet für eine schnelle Suche indizieren. Dabei wird ebenfalls das Internet oder eine geeignete Auswahl an Webseiten nach Download-Links durchsucht. Da im unteren Kilobyte-Bereich die Erkennungsrate sehr schlecht ist, sollten Admins bei der Indizierung nur Downloads betrachten, deren Größe einen gewissen Schwellenwert übersteigt.
Diese Methode hat jedoch den massiven Nachteil, dass beispielsweise inkrementelle Updates so nicht zu erkennen sind, da Download-Links zumeist den vollen Download anbieten. Außerdem wird die Sammlung oftmals schon nach kurzer Zeit unübersichtlich groß.
Die zweite Methode basiert auf Honeypots, die mit einer gleichen Softwarekonfiguration bestückt sind, wie sie auch im Unternehmensnetz vorkommt. Durch die Beobachtung des Netzverkehrs dieser Honeypots kann der Admin nun direkt die Update-Verläufe beobachten. Zudem ist es möglich, von diesen Systemen direkt Downloads zu starten, was durch die fehlende anderweitige Nutzung einfach in den Flows zu erkennen ist.
Diese Methode hat den großen Vorteil, dass insbesondere dann, wenn die Honeypots im selben Subnetz wie die zu schützenden Systeme platziert sind, die aufgezeichneten Paketgrößen zu guten Erkennungsraten führen. Auch lassen sich spezielle Update-Mechanismen besser nachbauen und analysieren. Diese Vorteile erkauft man sich jedoch mit dem Umstand, dass auf diese Weise nur bekannte Software-Versionen und -Kombinationen in die Überwachung einbezogen sind und dass als Honeypots Systeme erforderlich sind, die mit lizenzierten Vollversionen der eingesetzten Software arbeiten müssen.
Fazit
Für IT-Verantwortliche, die sich ein Bild über die eigene IT-Infrastruktur machen wollen und die nicht auf alle betriebenen Systeme Zugriff haben oder haben sollen, ist die hier vorgestellte Methode eine weitere Möglichkeit neben den klassischen Penetration-Tests, die Assets besser schützen zu können. Sie lenkt das Augenmerk auf den Wert der Metadaten. Wer im eigenen Netz direkt an den Switches und Backbone-Routern Flowrecords mitspeichert, sorgt außerdem dafür, dass die Entfernungen zu den beobachteten Systemen nicht zu groß werden, sodass die Varianz der beobachteten Downloadgrößen auf einem beherrschbaren Niveau bleiben sollte.
Mehr zu diesem und zu vielen weiteren Themen der IT-Sicherheit gibt es auf der 23. DFN-Konferenz “Sicherheit in vernetzten Systemen” des DFN-CERT am 09. und 10. Februar 2016 im Grand Elysee Hotel Hamburg. Das Programm findet sich unter https://www.dfn-cert.de/veranstaltungen/sicherheitskonferenz2016.html. Anmeldung unterhttps://cgi.dfn-cert.de/cgi-bin/registration.pl.
Infos
- Wolfgang Hommel, Stefan Metzger, Michael Grabatin, Felix von Eye, “Automatisierte Portscan-Auswertung in großen Netzen”: Admin-Magazin, 01/2013, S. 94
- Andreas Bernhard, “Netzbasierte Erkennung von Systemen und Diensten zur Verbesserung der IT-Sicherheit”: Bachelor-Arbeit, Ludwig-Maximilians-Universität München, März 2014
- Softflowd: http://www.mindrot.org/projects/softflowd
- Flowtools: https://code.google.com/p/flow-tools
- Pandas: http://pandas.pydata.org
- Sklearn: http://scikit-learn.org
- Sicherheitsupdate für Microsoft: https://technet.microsoft.com/library/security/MS15-130





