
© Alberto Loyo, 123RF
Eine leistungsfähige Suchmaschine, ein Tool zum Verarbeiten und Normalisieren von Protokollen und eins zum Visualisieren der Auswertungen – Elasticsearch, Logstash und Kibana bilden den ELK-Stack, der auf Systemen mit großem Log-Aufkommen den Karren aus dem Dreck zieht.
Schon ein einzelner kleiner LAMP-Server produziert etliche Logdateien. Ein großer Serververbund generiert jedoch so viele Protokolle, dass Administratoren mit Bordmitteln schnell an ihre Grenzen geraten, wenn sie die verteilten Logs optimal auswerten möchten. Die völlig unterschiedlichen Formate der diversen Applikationen verursachen zusätzliche Probleme.
Allen diesen Schwierigkeiten stellt sich der ELK-Stack in den Weg, eine Kooperation aus Elasticsearch [1], Logstash [2] und Kibana [3]. Elasticsearch ist ein extrem leistungsfähiger Suchserver. Seine Daten erhält er von Logstash, einer Anwendung, die Daten aus den Serverprotokollen zieht, normalisiert und in einem Elasticsearch-Index ablegt. Kibana schließlich erzeugt aus diesen Daten ansprechende Darstellungen – das Visualisierungstool bietet neben einer Echtzeitanalyse äußerst flexible Ansichten auf die Informationen.
Die Testumgebung bestand aus mehreren Debian-Jessie-Servern. Auf einem davon laufen der ELK-Stack sowie Filebeat [4], ein Dienst, der die lokalen Protokolle einfängt und an Logstash schickt. Filebeat kann ebenfalls Logs aus entfernten Quellen sammeln, was auf einem weiteren Server passiert, der bereits als zentraler Loghost eingerichtet war und erweitert wurde. Er kümmert sich auch um das Syslog-Forwarding.
Drei weitere Server arbeiten als Elasticsearch-Knoten, um den Speicherplatz und die Suchleistung insgesamt zu verbessern. Derzeit kümmert sich der ELK-Stack der Testumgebung um die Protokolle von Postfix, Dovecot, Apache, Nginx und Open Xchange.
Elasticsearch
Elasticsearch [1] von der Firma Elastic ist in Java implementiert und basiert auf Apache Lucene, einer extrem leistungsfähigen Volltext-Suchmaschine, deren Funktionen über ein REST-API bereitstehen. Alle Texte, Dokumente genannt, indexiert Elasticsearch automatisch. Selbst ohne eine Definition von Feldern oder Datentypen findet es auch in großen Datenmengen Suchbegriffe. Elasticsearch unterstützt komplexe Anfragen mit vielen Abhängigkeiten und versteht Metriken, etwa Häufigkeiten des Auftretens bestimmter Kriterien.
Die Hauptkomponente steht unter der Apache-Lizenz und ist kostenlos über das Github-Repository und die Projekthomepage verfügbar. Dort finden Anwender die Quellen, ein Debian- und ein RPM-Paket. Für Elasticsearch gibt es weitere kommerzielle Module, etwa Shield (siehe Abschnitt “Aber sicher!”), Marvel (Monitoring) oder Watcher (Alert).
Einzellizenzen für die Plugins verkauft die Firma Elastic nicht. Anwender müssen stattdessen ein Abo abschließen, das alle Komponenten sowie Support enthält. Preise für die einzelnen Subscription-Modelle listet die Webseite [5] nicht auf. Interessierte Benutzer wenden sich an den Hersteller für ein Angebot.
Die Tester installierten Version 2.1.0 vom 24. November 2015 und verwendeten dazu das Debian-Paket von der Homepage. Sie fügten das Elasticsearch-Repository zu den Paketquellen des eigenen Servers hinzu, um stets auf dem neuesten Stand zu sein. Das Paket integriert sich problemlos ins System – beschwert sich jedoch nicht, wenn eine Java-Laufzeitumgebung fehlt. Anwender sollten diese unbedingt nachrüsten; »openjdk-8-jre« funktionierte im Test einwandfrei. Die Installationsroutine richtet eine Service-Unit für Systemd ein, die sich um Start und Stopp des Daemon kümmert.
Gut verteilt
Mehrere Rechner mit einer Elasticsearch-Installation schließen sich unkompliziert zu einem Cluster zusammen. Die Knoten synchronisieren untereinander ihren Index und verteilen eingehende Suchanfragen von Clients selbstständig. Ab dem zweiten Elasticsearch-Knoten sind die Daten repliziert, ab dem dritten Knoten gewinnen Admins dann Speicherplatz. Elasticsearch teilt seine Indizes automatisch in so genannte Shards (Bruchstücke) auf. So kann der Dienst auch große Datensammlungen verteilt auf vielen Servern speichern.
Damit ist einerseits die Replikation gewährleistet, falls ein Knoten ausfällt. Außerdem findet der Zugriff verteilt statt, was die Sache performanter macht und dafür sorgt, dass auch große Datensammlungen schnell durchsuchbar sind. Admins müssen sich nicht vor dem Installieren und Einrichten entscheiden, ob sie skalieren wollen oder nicht. Es ist jederzeit möglich, das Setup zu erweitern und weitere Elasticsearch-Knoten in den Verbund aufzunehmen. Die Software kennt alle Mechanismen zum Verteilen der Daten von Haus aus, eine weitere Cluster- oder Load-Balancing-Komponente ist also nicht erforderlich.
Administratoren konfigurieren Elasticsearch in der Datei »/etc/elasticsearch/elasticsearch.yml« , die in Abschnitte unterteilt ist. Die Listings zum Artikel [17] liefern ein Beispiel für den ersten sowie eine Einrichtungsdatei für die anderen Knoten. Unter »Cluster« steht der Name des Rechnerverbunds und unter »Node« der Bezeichner für den Knoten, im Beispiel »elch-test1« , »elch-test2« bis »elch-test4« .
Die Tester haben zudem Anpassungen unter »Network« vorgenommen. Als Voreinstellung ist der Elasticsearch-Dienst an »localhost« (IPv4 und IPv6) und Port 9200 gebunden. Da es mehrere Knoten gibt, haben sie hier definiert, dass Elasticsearch auf allen Netzwerkinterfaces lauscht. Es ist derzeit nicht möglich, eine Liste von Interfaces zu definieren und damit den Zugriff einzuschränken – ein Feature-Request an den Hersteller ist bereits abgesetzt.
Gibt es mehrere IP-Adressen, bestimmen Admins im Bereich »Network« über die Variable »publish_host« , mit welcher IP der Rechner mit den anderen Elasticsearch-Knoten kommuniziert. »bind_host« hingegen definiert, auf welchen Adressen der Dienst insgesamt lauscht. Diese Einstellung wird insbesondere dann wichtig, wenn Systemverwalter richtig groß skalieren. Dann wollen sie möglicherweise steuern, dass die Elasticsearch-Knoten in einem Netzwerk untereinander ihre Daten austauschen, aber nach außen für den Zugriff von Clients eine andere IP verwenden.
Auch der Abschnitt »Discovery« in der Konfigurationsdatei ist nur dann interessant, wenn es mehr als einen Elasticsearch-Knoten gibt. Dort listen Admins alle Nodes hintereinander auf. Sobald ein Knoten eingerichtet ist, können die Anwender mit dem Kommandozeilentool »curl« oder mit einem Blick in den Webbrowser überprüfen, ob der Suchdienst läuft (Abbildung 1).
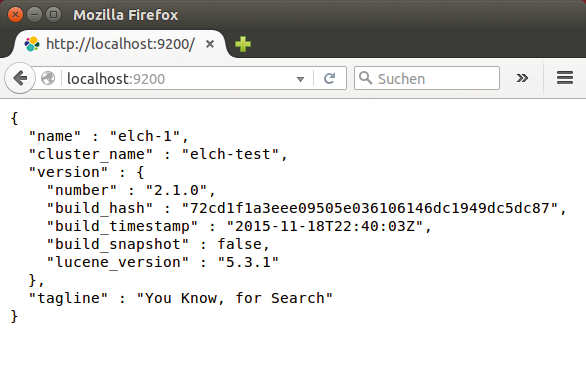
Abbildung 1: Viel ist nicht zu konfigurieren bei Elasticsearch, der Dienst ist nach kurzer Zeit über »localhost:9200« erreichbar.
Aber sicher!
Was schon bei der ersten Kontaktaufnahme auffällt: Es gibt keine Authentifizierungs-Mechanismen bei Elasticsearch und die Daten wandern im Klartext durchs Netz. Eine Rechteverwaltung, die bestimmt, welcher Client auf welchen Teil des Index zugreifen darf, fehlt ebenfalls. Alle diese Sicherheitsfeatures liefert das Plugin Shield [6], das besonders dann interessant wird, wenn Elasticsearch im Verbund mit mehreren Serverinstanzen läuft. Mit dem Skript »/usr/share/elasticsearch/bin/plugin« installieren Admins die Lizenz und Shield auf jedem Knoten, wie auf der Homepage beschrieben. Danach starten sie alle Elasticsearch-Services neu. Systemverwalter dürfen Shield und die anderen kommerziellen Plugins 30 Tage lang testen.
Shield erweitert den Suchdienst um eine Benutzerverwaltung und ein Rechtesystem. Außerdem verschlüsselt es die Datenströme zwischen den Elasticsearch-Knoten mit SSL und verhindert, dass unautorisierte Nodes dem Verbund beitreten. Um die SSL-Zertifikate müssen sich Systemverwalter selbst kümmern. Unterstützung finden sie in der Shield-Dokumentation auf der Webseite.
Alternativ regeln Admins mit IPtables, wer auf den oder die Elasticsearch-Server zugreifen darf. So legen sie beispielsweise fest, dass nur von bestimmten Maschinen aus dem internen Netz heraus Zugriff auf die Knoten erlaubt ist (Listing 1). Das löst aber noch nicht das Problem, dass der Datentransfer unverschlüsselt ist. Bei Logdateien, die unter Umständen schützenswerte Informationen enthalten, ist das alles andere als optimal. Da Elasticsearch einen Webserver bereitstellt, können Admins einen Reverse Proxy vorschalten, der neben einer SSL-Verschlüsselung auch eine Authentisierung mit »htpasswd« aktiviert.
Listing 1
IPtables-Regeln für Elasticsearch
01 iptables -A INPUT -i lo --proto tcp -m multiport --dports 9200,9300 -j ACCEPT 02 iptables -A INPUT -s 192.168.0.0/24 --proto tcp -m multiport --dports 9200,9300 -j ACCEPT 03 iptables -A INPUT --proto tcp -m multiport --dports 9200,9300 -j REJECT --reject-with icmp-port-unreachable 04 iptables -A INPUT --proto tcp -m multiport --dports 9200,9300 -j REJECT --reject-with icmp-port-unreachable
Logstash
Logstash [2] verarbeitet und normalisiert Logdateien. Die Anwendung zieht ihre Informationen aus unterschiedlichen Datenquellen, die Benutzer als Input-Module definieren. Quellen können beispielsweise Datenströme von Syslog oder Protokolldateien sein. In einem zweiten Schritt verarbeiten Filter-Plugins die Daten nach Benutzervorgaben weiter – die Phase kann auch entfallen, das Material wandert dann unbearbeitet weiter. Die Output-Module schließlich geben die Ergebnisse aus; in der Testumgebung geht alles an den Elasticsearch-Service. Abbildung 2 zeigt, wie die Komponenten zusammenspielen.

Abbildung 2: Per Input-Plugin gelangen Daten aus einer oder mehreren Quellen an Logstash. Nach dem Filtern reicht das Output-Modul sie weiter an den Datenspeicher Elasticsearch.
Logstash ist kostenlos und steht genau wie Elasticsearch unter der Apache-Lizenz. Auf der Projektseite sind die Quellen, Debian- und RPM-Pakete sowie Hinweise zum Onlinerepository zu finden. Die Tester installierten Version 2.1.0 vom 25. November 2015. Logstash benötigt ebenfalls eine Java-Laufzeitumgebung. Eine Systemd-Service-Unit fehlt; dafür liefert der Hersteller ein altes Initskript aus, das leider keinen »reload« -Parameter besitzt, denn Logstash ist derzeit nicht in der Lage, seine Konfiguration dynamisch neu zu laden. Ein Bugreport war bei Redaktionsschluss bereits abgesetzt.
Baukasten
Admins konfigurieren Logstash im Verzeichnis »/etc/logstash/conf.d« , das in der Voreinstellung leer ist. Der Hersteller verzichtet darauf, eine einfache Standardkonfiguration zu liefern und Anwendern damit Beispiele zu geben, mit denen sie schnell zu ersten Ergebnissen gelangen und das Zusammenspiel der Logstash-Pipeline nachvollziehen könnten. Eine gute Anlaufstelle ist das Handbuch [7], das ausführliche Erklärungen zu allen Plugins liefert. Auch die Suche im Netz fördert zahlreiche Beispiele anderer Nutzer zutage, die als Vorlage dienen können, und die Heft-DVD enthält die Konfigurationsdateien der Testumgebung mit kurzen Erklärungen.
Da Logstash alle Einrichtungsdateien aus »/etc/logstash/conf.d« in alphanumerischer Reihenfolge einliest und zu einer Gesamtkonfiguration verbindet, ist es eine gute Idee, sich im Vorfeld Gedanken über die Struktur zu machen. Der Testrechner benutzt folgendes Schema: Die Input-Dateien beginnen mit einer »0« , die Filter mit »5« und die Output-Module mit »9« . Vor dem Dateinamen steht eine vierstellige Zahl – so ist genug Platz für Experimente.
Das einfachste Beispiel heißt »0005-file-input.conf« und liest lokale Logdateien ein. Es nutzt das Input-Modul »file« und definiert als Quellen hinter »path« die Nginx-Access-Logfiles der lokalen Maschine; »exclude« schließt Dateien mit der Endung ».gz« aus, und »type« ist ein optionaler Deskriptor, auf den sich die Filter-Plugins beziehen können (siehe Abschnitt “Herausgefischt”).
Wer außer lokalen Protokollen zusätzlich auch Logs entfernter Server einsammeln und verarbeiten möchte, kann Syslog selbst zu Hilfe nehmen (siehe »0001-syslog-input.conf« und »0002-socketsyslog-input.conf« auf der Heft-DVD). Eine andere Möglichkeit bieten Logstash-Forwarder und Filebeat (siehe Kasten “Nach Holzfällerart”).
Nach Holzfällerart
Der Logstash-Server kann von entfernten Rechnern Daten empfangen. Frühere Versionen setzten auf den Logstash-Forwarder [8], ein kleines Tool, das auf jedem Server lief, dort die Protokolle einsammelte und mit dem Lumberjack-Protokoll an einen zentralen Logstash-Server schickte. Die Konfigurationsdatei »0201-lumberjack-input.conf« von der Heft-DVD zeigt ein Beispiel, das den Logstash-Server auch noch für bestehende ältere Logstash-Forwarder-Installationen empfangsbereit hält.
Mit Logstash 2 haben die Entwickler Filebeat [4] eingeführt, einen universellen Dienst, der per Beats-Protokoll Datenströme an einen bestimmen Port auf dem Logstash-Server schickt und Lumberjack langfristig ersetzen soll. Das Beats-Protokoll, das ebenfalls erst seit Logstash 2 existiert, kommt auch bei anderen Datenlieferanten (Data Shippers) zum Einsatz. Die Tester installierten die Filebeat-Version 1.0.0 vom 24. November 2015 von der Projekthomepage. In der Konfigurationsdatei »/etc/filebeat/filebeat.yml« stehen sinnvolle Voreinstellungen, die Admins schnell an eigene Umgebungen anpassen. Die auf der Magazin-DVD enthaltene Datei »filebeat.yml« zeigt die Einrichtung des Testrechners.
Einer der Vorteile von Filebeat ist, dass das Tool die eingesammelten Protokolle auf Wunsch per SSL an den Logstash-Server schickt. Außerdem können Admins die Filebeat-Clients selbst mit Zertifikaten ausstatten und damit regeln, von welchem Rechner sie Logs empfangen. Ein weiterer Pluspunkt ist die Registry, in der Filebeat notiert, welche Dateien er bereits gelesen und verschickt hat. Sollte also der Logstash-Server einmal nicht erreichbar sein, kann Filebeat zu einem späteren Zeitpunkt an jener Stelle anknüpfen, an der die Übertragung unterbrochen wurde.
Filebeat kann theoretisch direkt an Elasticsearch ausliefern, was in der Konfiguration die Voreinstellung ist (Abschnitt »Output« ). Da in diesem Fall aber keine weitere Verarbeitung mit Filtern stattfindet, sondern die Datenströme 1:1 in den Index gelangen, ist die Option auf dem Testrechner auskommentiert. Dafür verschickt Filebeat seine Daten an Logstash.
Die Filter-Module verarbeiten alles, was aus den Quellen nach Logstash gewandert ist. Sie analysieren die Daten(-ströme) und zerlegen sie in einzelne Informationen und Datenfelder. Neben Modulen zum Parsen und Aufteilen gibt es auch solche, die weitere Angaben hinzufügen, die Rohdaten also anreichern. Zu Letzteren gehören beispielsweise »dns« (DNS-Namensauflösung) und »geoip« (IP-Standortbestimmung mittels Maxmind-Datenbank).
Herausgefischt
Alle Logstash-Plugins und damit auch die Filter sind Ruby-Gems, mit dem Skript »/opt/logstash/bin/plugin« verwalten Admins die Erweiterungen auf dem eigenen System [9]. Sie listen vorhandene auf (Abbildung 3), installieren neue aus dem Internet oder von der lokalen Platte und aktualisieren vorhandene. Außer den mitgelieferten Filtern gibt es einige Community-Plugins, die nicht aus Elastics Feder stammen und auch keine Updates von dort erhalten.
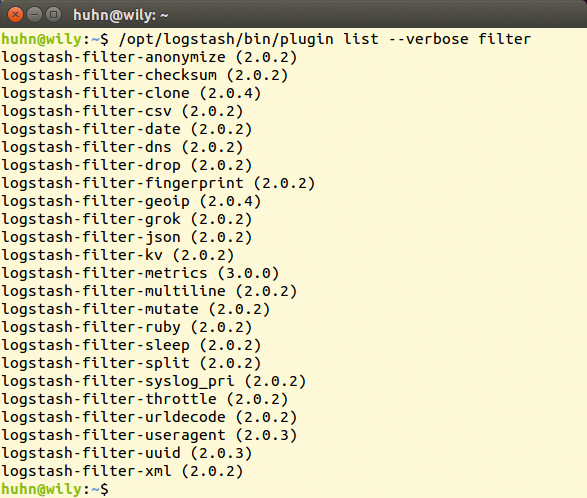
Abbildung 3: Welche Logstash-Filter sind derzeit auf dem System installiert und welche Versionsnummer tragen sie?
Um zu unterscheiden, welche Filter auf welche Daten zugreifen sollen, sind If-else-Statements möglich. Sie nutzen Standardfelder wie beispielsweise den bereits erwähnten Deskriptor »type« , den viele Input-Module setzen. Auch Tags, wie Filebeat sie definieren kann, können als Unterscheidungskriterien für Filter dienen. Im Grunde genommen stehen alle in der bisherigen Verarbeitung ermittelten Felder zur Verfügung – auch solche, die gerade erst aus einer Zeile in einem Log extrahiert wurden.
Die Datei »5003-postfix-filter.conf« von der Heft-DVD zeigt ein Beispiel:
if [postfix_keyvalue_data] {
kv {
source => "postfix_keyvalue_data"
trim => "<>,"
prefix => "postfix_"
remove_field => [ "postfix_keyvalue_data" ]
}[...]
In diesem Fall kommt der »kv« -Filter (Extraktion von Key-Value-Paaren) nur dann zum Einsatz, wenn das Feld »postfix_keyvalue_data« definiert ist.
Ein häufig genutztes Modul, das bestimmte Logformate parsen kann, heißt Grok. Es zerlegt Fließtext in einzelne Datenfelder, orientiert sich an gängigen regulären Ausdrücken und unterstützt Referenzen auf bereits vorher definierte Muster. Logstash selbst enthält einige wenige Grok-Patterns im Plugin »logstash-patterns-core« .
Das Entwickeln eigener Patterns ist nicht trivial. Im Netz gibt es einige halbgare Versuche, aber auch etliche gute Muster unter freien Lizenzen, die Anwender in ihre Konfiguration einbinden können. Eine sehr gute Vorlage für Postfix finden sie unter [10], Beispiele für Dovecot unter [11] und Nginx-Patterns unter [12]. Das Github-Repository unter [13] sammelt Vorlagen für Dienste wie Bacula, Nagios, PostgreSQL und mehr.
Da die Methode “Versuch und Irrtum” mit ständigen Logstash-Neustarts keine gute Idee ist und viel zu lange dauert, füllen zwei Onlinetools eine Lücke im Lieferumfang von Logstash. Auf den beiden Seiten [14] und [15] entwickeln und testen Admins ihre Grok-Patterns ausführlich, bevor sie diese in die Logstash-Konfiguration eintragen und den Dienst neu starten. Auch den Parameter »configtest« des Logstash-Initskripte sollten Admins unbedingt im Auge behalten und mit dem Befehl »/etc/init.d/logstash configtest« ihre Einrichtungsdateien auf Syntaxfehler hin überprüfen.
Ausgegeben
Last, but not least bestimmen die Output-Module, was mit gefilterten Daten passiert. Die Konfigurationsdatei »9001-elasticsearch-output.conf« sorgt dafür, dass Logstash alle Daten an Elasticsearch weiterreicht:
output {
elasticsearch {
hosts => ["localhost:9201"] }
}
Die Portnummer 9201 ist kein Tippfehler – in der Testumgebung ist ein Reverse-Proxyserver vorgeschaltet, der auf dem Elasticsearch-Port 9200 lauscht und alles an 9201 durchreicht.
Während in früheren Logstash- und Elasticsearch-Versionen ein Java-basiertes Protokoll zum Einsatz kam, spricht Logstash seit der Version 2.0 HTTP mit dem Elasticsearch-Server. Wer sich das Shield-Plugin angeschafft hat, definiert im Output-Modul ebenfalls die Authentisierung und schaltet SSL für den Datentransfer ein:
[...]
hosts => ["localhost:9201"]
user => benutzername
password => strenggeheim
ssl => true
cacert => '/pfad/zum/cert.pem'[...]
In der Voreinstellung heißen die von Logstash an Elasticsearch gelieferten Indizes »logstash-%Y.%m.%d« , sind also anhand ihrer Timestamps eindeutig identifizierbar. Damit sie nicht ins Unendliche wachsen, müssen Admins den Datenbestand nicht von Hand pflegen, sondern können zu dem Tool Curator [16] greifen. Das Python-Skript lag bei Redaktionsschluss in Version 3.4 vor und kam in dieser Form auch in der Testumgebung zum Einsatz. Curator optimiert den Datenbestand, indem es beispielsweise Logstash-Daten entfernt, die älter als sieben Tage sind:
/usr/local/bin/curator --host 127.0.0.1 --port 9201 delete indices --timestring '%Y.%m.%d' --prefix logstash --time-unit days --older-than 7
Da in der Testumgebung ein Nginx-Proxyserver vorgeschaltet ist, definiert das letzte Kommando die vom Standard abweichende Portnummer. Wer vorher testen möchte, was im Ernstfall passiert, nutzt die Option »–dry-run« , die im Befehl vor allen anderen Parametern stehen muss, damit Curator nur simuliert. In einem Cronjob ist das Skript gut aufgehoben und kümmert sich fortan automatisch ums Aufräumen.
Kibana
Die dritte und letzte Komponente im ELK-Stack heißt Kibana [3] und stammt ebenfalls aus dem Hause Elastic. Das Programm erzeugt aus den Elasticsearch-Daten ansprechende Darstellungen und Berichte. Neben einer Echtzeitanalyse punktet es vor allem mit äußerst flexiblen Suchalgorithmen und unterschiedlichen Ansichten auf die Informationen. Auch Kibana steht unter der Apache-Lizenz, Version 4.3.0 erschien am 24. November 2015. Anwender erhalten die jeweils neueste Ausgabe als Tar.gz-Archiv von der Projektseite. Es gibt derzeit leider weder fertige Pakete noch ein Repository, sodass der Admin selbst nach Updates Ausschau halten muss.
Im Kibana-Archiv, das auf dem Testrechner im Verzeichnis »/opt« residiert, befindet sich das Unterverzeichnis »config« mit der Einrichtungsdatei »kibana.yml« , in der gewöhnlich nichts zu tun ist – die Voreinstellungen sind sinnvoll und völlig ausreichend, wenn Elasticsearch auf demselben Rechner läuft. Im Verzeichnis »bin« befindet sich das Startskript »kibana« . Es gibt weder ein Initskript noch eine Systemd-Unit, die Admins müssen sich selbst um den Kibana-Start kümmern. Kibana enthält einen eigenen Webserver, Anwender erreichen die Oberfläche über den Browser (»http://localhost:5601« ).
Ohne das bereits erwähnte Elasticsearch-Plugin Shield gibt es keine Benutzer- und Rechteverwaltung, das heißt, dass jeder stets Zugriff auf den kompletten Datenbestand hat. Kibana unterstützt SSL, in der Datei »kibana.yml« können Admins Zertifikat und Schlüssel hinterlegen. Die Tester haben zusätzlich mit Nginx einen Reverse Proxy davorgesetzt, der nicht nur SSL, sondern auch eine einfache Benutzerauthentifizierung mit »htaccess« und »htpasswd« nachrüstet (»etc_nginx_sites-available/kibana« auf der Heft-DVD).
Das Kibana-Webinterface überzeugt auf ganzer Linie. Dank des responsiven Designs macht es auch auf kleineren Displays eine gute Figur. Beim ersten Besuch im Interface tragen Anwender einen Index ein oder übernehmen die Voreinstellung »logstash-*« . Es folgt ein Klick auf »create« – und Kibana ist einsatzbereit. Der nächste Schritt führt in die Abteilung »Discover« , die alle Events versammelt. Per Klick klappen Benutzer die Einträge aus und sehen nun die Tabellen mit ihren Datenfeldern. Die mit »@« gekennzeichneten Felder stammen von Elasticsearch, die mit einem Unterstrich beginnenden kommen aus den Input-Modulen.
Anwender finden im Bereich »Discover« ein Suchfeld, um Anfragen an Elasticsearch zu stellen. Die Suchanfragen können sie über die kleinen Icons rechts neben dem Feld abspeichern und später neu laden, um nicht immer wieder von vorn beginnen zu müssen. Auf der linken Seite listet das Kibana-Interface die einzelnen Felder auf, die Anwender mit einem Klick auf »add« zu den Filterkriterien hinzufügen.
Wie gemalt
Die grafischen Auswertungen schließlich entstehen in der Abteilung »Visualize« . Schritt für Schritt gelangen Benutzer hier zu verschiedenen Diagrammtypen oder Metriken, die sie aus neuen oder vorhanden Suchabfragen zusammensetzen. So beantwortet Kibana beispielsweise Fragen nach der Verteilung von Verschlüsselungs-Algorithmen oder ermittelt die durchschnittliche Größe von E-Mails, sortiert nach Tagen und Stunden. Oft dauert es nur wenige Sekunden, bis die Software Millionen von Einzelwerten im Index durchforscht und verwertbare Metriken herausgeabeitet hat – was »grep« , »awk« & Co. nicht leisten können.
In der Abteilung »Dashboard« fügen Benutzer die zuvor erzeugten Visualisierungen zu einem Gesamtbild zusammen und ordnen verschiedene Ansichten an. So erfassen sie beispielsweise unterschiedliche Aspekte zu ausgehenden Mails (Abbildung 4). Auch für Webserver bietet sich eine Zusammenstellung an, etwa mit Gesamtzugriffen, Betriebssystem-Verteilung und Geo-IP (Abbildung 5). Kibana-Dashboards sind nicht statisch. Sie enthalten ebenfalls ein Suchfeld und weitere Filtermöglichkeiten.
Abbildung 4: Mehrere Visualisierungen ordnen Kibana-Anwender in eigenen Dashboards an und sortieren diese nach unterschiedlichen Themen.
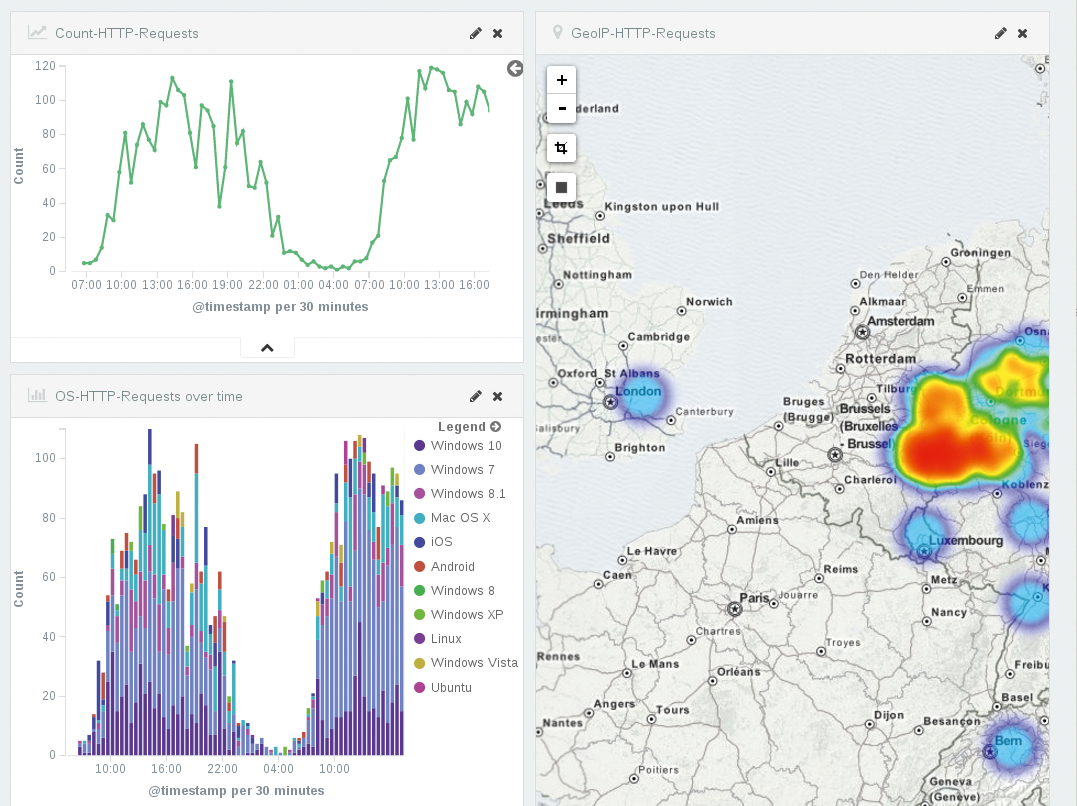
Abbildung 5: Kibana zeigt die Gesamtzugriffe, eine Aufteilung nach Betriebssystemen und die Geo-IP auf einer Karte.
Elch und gut?
Der ELK-Stack eignet sich nicht nur für Web- oder Mailserver, wo sehr viele Zugriffe stattfinden, sondern auch für große Serververbünde mit verteilten Protokollen. Elasticsearch, Logstash und Kibana sind Teamplayer, arbeiten hervorragend zusammen und integrieren auch weitere Komponenten wie Filebeat & Co. gut in die Mannschaft. Die aktuellen Programmversionen überzeugen, Admins bekommen einen leistungsfähigen Werkzeugkasten an die Hand.
Während die Installation problemlos gelingt, fehlen teilweise moderne Systemd-Units und im Fall von Kibana sogar ein Initskript. Aussagekräftige Logstash-Standardkonfigurationen für die Dienste auf einem typischen Linux-Server vermissten die Tester ebenfalls. Die Dokumentation ist zwar ausführlich und im Netz gibt es viele Beispiele von anderen Benutzern, doch ist es schade, dass Systemverwalter diese erst mühsam selbst zusammentragen müssen. Abhilfe schaffen hoffentlich die kommentierten Beispiele auf der Heft-DVD.
Der ELK-Stack ist unglaublich flexibel, erfordert aber eine längere Einarbeitungszeit. Viele Wege führen zu einer Verarbeitungskette. Wenn die Entwickler einen Grundstock von Konfigurationsbeispielen mitgäben, wäre vielen Admins geholfen – so könnten sie schnell erste Ergebnisse sehen, sich besser orientieren und ihren eigenen Stil entwickeln.
Infos
- Elasticsearch: https://www.elastic.co/products/elasticsearch
- Logstash: https://www.elastic.co/products/logstash
- Kibana: https://www.elastic.co/products/kibana
- Filebeat: https://www.elastic.co/products/beats/filebeat
- Elastic-Subscriptions: https://www.elastic.co/subscriptions
- Shield: https://www.elastic.co/products/shield
- Logstash-Handbuch: https://www.elastic.co/guide/en/logstash/current/index.html
- Logstash-Forwarder und Lumberjack-Protokoll: https://github.com/elastic/logstash-forwarder
- Arbeiten mit Logstash-Plugins: https://www.elastic.co/guide/en/logstash/current/working-with-plugins.html
- Postfix-Patterns: https://github.com/whyscream/postfix-grok-patterns
- Dovecot-Patterns: https://github.com/augieschwer/grok-patterns
- Nginx-Patterns: https://www.ulyaoth.net/threads/logstash-forwarder-and-grok-examples.32413
- Github-Repository mit Logstash-Patterns: https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
- Grok Debugger: http://grokdebug.herokuapp.com
- Grok Constructor: http://grokconstructor.appspot.com
- Curator: https://www.elastic.co/guide/en/elasticsearch/client/curator
- Listings zum Artikel: https://www.linux-magazin.de/Ausgaben/Listings





