
© Maksim Toome, 123RF
Heute sind Webdienste selten, bei denen nicht irgendwo eine MySQL-Datenbank mitwirkt. Manchmal entspricht ihr Durchsatz oder ihre Antwortzeit nicht den Erwartungen. Dieser Artikel zeigt, wie man bei MySQL Performanceprobleme in den Griff bekommt.
Oft sind Performanceprobleme zu lösen, von denen sich anfangs nur diffuse Vorstellungen und vage Beschreibungen finden. Deshalb gilt es als Erstes festzuhalten, worin genau die Schwierigkeiten bestehen. Dieser Schritt hilft bereits Ordnung in die Sache zu bringen. Dazu stellt sich der MySQL-Admin Fragen wie: Wann tritt das Problem auf? Was genau geschieht, bevor der Nutzer merkt, dass die Anwendung langsam wird? Was hat er vorher angeklickt?
Neben Fragen, die die Ursache eingrenzen und darauf abzielen, klarer zu beschreiben, was zu verbessern ist, vervollständigen die MySQL-Logfiles das Bild. Auf jeden Fall ist es immer hilfreich, dem Problem unmittelbar nach seinem Auftreten auf den Grund zu gehen. Es drei Wochen später noch zu verstehen und zu lösen erfordert wesentlich mehr Spürsinn. Zum Schluss heißt es messen, messen, messen. Im Idealfall gibt es eine Monitoring-Infrastruktur, die alle notwendigen Performancedaten bereits erfasst.
Das Ziel identifizieren
Wer das Performanceproblem beschrieben und dokumentiert hat, legt im Anschluss fest, was die Ziele der Tuningmaßnahme sein sollen: Eine kürzere Antwortzeit oder mehr Durchsatz? Ein Ziel könnte etwa lauten: “Die Aktion X, die nach dem Klick 3,5 Sekunden dauert, soll in Zukunft in weniger als einer Sekunde ausgeführt werden.” Wenn es sich um ein Durchsatzproblem handelt, könnte ein Ziel lauten: “Bei 30 Prozent mehr Last im nächsten Jahr soll das System immer noch im Durchschnitt innerhalb von 350 Millisekunden auf eine Bestellung antworten.”
Es ist unabdingbar, realistische Ziele zu wählen. Das heißt solche, die zumindest die natürlichen Grenzen respektieren, die nicht zu beeinflussen sind: Je nach Netzwerk gibt es eine Obergrenze für die Übertragungsgeschwindigkeit. Oder es gibt technische Limits (100 Millionen Zeilen zu durchsuchen dauert halt ein Dutzend Sekunden). Oder der Tuner stößt an finanzielle Grenzen. (Ja, eine SSD könnte 10000 IOPS liefern, aber die zahlt der Kunde nicht.) Performancetuning erfordert immer Kompromisse, seien es finanzielle oder solche bei der Sicherheit oder beim Aufwand für Korrekturmaßnahmen und Codechanges.
Den Engpass finden
Am Anfang gilt es, den Flaschenhals auf der technischen Seite zu finden. Das kann der Webbrowser, das Netzwerk, der Web- oder Applikationsserver, die Datenbank oder auch die Hardware sein. Auf Datenbankmaschinen sind typischerweise die Ressourcen I/O, RAM und CPU – in dieser Reihenfolge – die limitierenden Faktoren.
Welche dieser Ressourcen aktuell die Datenbankleistung begrenzt, lässt sich mit Tools wie »iostat« für das I/O-System, »free« und »vmstat« für den Memoryverbrauch und das Swapping sowie »top« oder »mpstat« für die CPU-Auslastung herausfinden. Den Speicherverbrauch klärt das Kommando »free« , wie in Listing 1 zu sehen ist.
Listing 1
free
# free -m
total used free shared buffers cached
Mem: 117080 113060 4020 2420 1980 62260
-/+ buffers/cache: 48810 68270
Swap: 119730 0 119730
Die wichtigsten Werte in Listing 1 bedeuten:
- Mem total: Insgesamt zur Verfügung stehender Speicher (RAM), hier: 117080 MByte.
- Mem used: Effektiv durch Applikationen genutzter Speicher (RAM), hier: 48810 MByte.
- Mem free: Potenziell freier Speicher (RAM), hier: 68270 MByte.
- Mem cached: Durch das Betriebssystem genutzter Speicher (RAM) für den Filesystemcache, hier: 62260 MByte.
- Swap used: Hier ist zurzeit kein Swapspeicher in Gebrauch.
Ist der Speicher die limitierende Ressource, wird »Mem used« sich in Richtung »Mem total« bewegen und »Mem free« gegen null. Zudem baut das Betriebssystem den Filesystemcache (»Mem cached« ) ab (nähert sich null) und »Swap used« wird sich von null weg hin zu »Swap total« bewegen.
Der Speicherverbrauch des wichtigsten Prozesses (»mysqld« ) lässt sich so ermitteln, wie es Listing 2 demonstriert. Die Speicher-relevanten Werte bedeuten:
Listing 2
Speicherverbrauch von mysqld
01 # ps aux | egrep 'mysqld|VSZ' 02 USER PID %CPU %MEM VSZ RSS START TIME COMMAND 03 mysql 1568 0.0 0.0 4440 744 Sep08 0:00 mysqld_safe 04 mysql 2337 0.1 5.9 29163040 7115280 Sep08 13:00 mysqld
- VSZ: Durch den Prozess vom Betriebssystem angeforderter Speicher (Virtual Size).
- RSS: Durch das Betriebssystem im RAM gehaltener Speicherbereich des Prozesses (Resident Set Size). Dieser Speicher ist Teil des Mem-used-Bereichs aus dem »free« -Befehl. Die Summe der RSS-Werte aller Prozesse sollte in etwa »Mem used« entsprechen. Liegt die Summe der VSZ-Werte aller Prozesse deutlich über dem verfügbaren Speicher (»Mem total« ) ist der Speicher (RAM) overcommitted, was unter Volllast zu Swapping und einem Ausbremsen des Systems führen kann.
Ob und wie stark ein System swapt und wie stark dies das I/O-System belastet, das zeigt Listing 3.
Listing 3
vmstat
01 # vmstat 1 02 procs -------------memory---------- ----swap---- -----io----- -system-- ------cpu----- 03 r b swpd free buff cache si so bi bo in cs us sy id wa st 04 0 0 10848 139772 3612 793656 0 0 0 0 788 2583 7 5 88 0 0 05 0 0 10924 152000 3584 689528 0 76 4 124 802 2759 7 6 88 0 0 <- <i class="replaceable">Beginn des swappens 06 0 1 103260 117124 3528 636156 0 92336 0 92556 834 2607 7 5 83 5 0 07 2 1 126168 138116 3552 553200 0 22908 348 23076 1143 2880 6 3 57 35 0 <- <i class="replaceable">I/O System belastet (wa) 08 0 3 265376 149720 1136 378148 0 105300 252 105348 993 3002 6 4 62 29 0 09 0 14 495028 117264 560 329792 0 137352 1252 137488 880 3506 5 2 22 71 0 <- <i class="replaceable">heftiges Swappen 10 0 10 597776 117244 320 317840 0 29400 588 29400 664 2522 2 2 0 96 0 <- <i class="replaceable">Prozess gekillt 11 0 13 1667548 8263784 784 304768 296 0 920 0 298 675 0 0 25 75 0 <- <i class="replaceable">Ausgelagerter Speicher zurück 12 1 7 1659568 8247460 1200 314888 6900 0 16056 1132 905 1995 6 1 24 70 0 13 1 2 1654428 8148296 2516 373604 13004 0 49036 1100 2444 7135 8 6 68 19 0 14 1 0 1649624 8128492 3088 396844 328 0 2604 28 497 1634 4 1 94 1 0
Die Bestimmung der Auslastung des I/O-Systems ist etwas komplizierter: Es gilt, vier verschiedene I/O-Muster zu erkennen: sequenzielles Lesen und Schreiben sowie Lesen und Schreiben an zufälligen Positionen. Letzteres kommt bei Datenbanken häufig vor. Ersteres können normale, drehende Platten (HDD) besonders gut, Letzteres können SSDs deutlich besser.
Die Auslastung des I/O-Systems lässt sich so abfragen, wie es Listing 4 für sequenzielles Schreiben auf SSD (single threaded, 16-KByte-Blöcke, O_DIRECT) zeigt. Dort stehen »r/s« und »w/s« für die Anzahl der Lese- beziehungsweise Schreiboperationen pro Sekunde (zusammen: IOPS), »await« für die durchschnittliche Servicezeit aller I/O-Requests, »rKB/s« und »wKB/s« für die Menge gelesener beziehungsweise geschriebener Daten (Durchsatz).
Listing 4
Auslastung des I/O-Systems
01 # iostat -xk 1 02 03 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util 04 sda 2.00 8.00 2.00 9500.00 16.00 151948.00 31.99 1.07 0.11 4.00 0.11 0.09 88.40
Ist der Lese- oder Schreibdurchsatz hoch (wie in Listing 4), handelt es sich um sequenzielle Operationen. Zufällige Lese- oder Schreiboperationen ergeben einen deutlich geringeren Durchsatz.
Fehlt noch die CPU-Auslastung. Da muss man etwas genauer hinschauen. Im Beispiel von Listing 5 scheint sich das System zu 71 Prozent im Leerlauf zu befinden, aber Core 1 (ein Thread zum Beispiel einer MySQL-Verbindung) wird über längere Zeit voll ausgelastet.
Listing 5
mpstat
01 # mpstat -P ALL 1 02 03 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 04 all 26.94 0.00 0.59 1.05 0.00 0.02 0.00 0.00 0.00 71.40 <- <i class="replaceable">71% idle 05 0 1.00 0.00 0.37 0.00 0.00 0.06 0.00 0.00 0.00 98.57 06 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 07 2 3.77 0.00 1.32 1.32 0.00 0.00 0.00 0.00 0.00 93.58 08 3 2.82 0.00 0.69 2.89 0.00 0.00 0.00 0.00 0.00 93.60
Ist der limitierende Faktor oder der schuldige Prozess identifiziert, kann der Admin sich überlegen, wie dieses Performanceproblem in den Griff zu kriegen ist. Bei MySQL lassen sich fünf Ebenen identifizieren, auf denen er die Schwierigkeiten angehen und allenfalls auch beseitigen kann.
Ebene 1: Die Hardware
Geschwindigkeitsprobleme kann man oft mit Hardware erschlagen. Das ist gegebenenfalls sogar billiger, als Mannmonate in die Verbesserung des Applikationscodes oder die Architektur zu stecken. Investitionen in bessere, also voraussichtlich teurere Hardware ist aber keine Maßnahme, die sonderlich gut skaliert. Schlechtes Design der Applikation oder eine nicht durchdachte Architektur kann die neue potente Hardware schnell wieder an ihre Grenzen führen. Neue Hardware erkauft vorwiegend Zeit – bis das ursächliche Problem gefixt ist.
Wer schnellere Hardware einsetzen will, der greift für Datenbankserver typischerweise zu mehr RAM und besseren I/O-Systemen (Raid 10, batteriegestützter I/O-Controller, SSD). Solche Maßnahmen beschleunigen die Datenbanken unter Umständen erheblich.
Ebene 2: Das Betriebssystem
An modernen Betriebssystemen kann der Anwender normalerweise nicht mehr allzu viel tunen. Betriebssysteme sind bereits für die meisten Einsatzzwecke optimal vorkonfiguriert. Mehr als 10 bis 20 Prozent Performancegewinn sind hier nicht zu erwarten. Typische Tuningmaßnahmen am Betriebssystem bei Datenbanken sind: Anzahl der Filehandles pro Prozess erhöhen, skalierbares, modernes Filesystem (XFS oder Ext 4) verwenden, I/O-Scheduler auf »noop« stellen und Swappiness auf »1« setzten.
Besondere Beachtung verdient aber eine Tendenz, die in den letzten Jahren Einzug in Rechenzentren gehalten hat: Der ausgeprägte Hang zum Konsolidieren. Begonnen hat er mit dem Siegeszug des SAN, jetzt wird er mit Virtualisierungslösungen aller Arten fortgeführt. Dabei spricht grundsätzlich nichts dagegen, viele, oft leerlaufende Systeme auf einem großen Host zu konsolidieren. Aber für ein hochperformantes und ausgelastetes Datenbanksystem sind Virtualisierungslösungen nicht geeignet.
Das hat mehrere Gründe. Zum einen haben Konsolidierungslösungen wie SAN und Virtualisierung immer einen gewissen Overhead. Zum anderen sind SAN-System geografisch relativ weit weg vom eigentlichen Datenbankserver, was zu höheren Latenzen führen kann. Die eigentlichen großen Probleme beim Konsolidieren sind aber das Overcommitten von Ressourcen (es treffen zu viele Konsumenten auf zu wenige Ressourcen) und der so genannte Noisy-Neighbour-Effekt: Ein anderes virtuelles Gastsystem verursacht so viel Last, dass es auch die Datenbank in den Keller zieht.
Das Perfide am Noisy-Neighbour-Effekt ist, dass aus der Sicht eines Gastsystems nur schwer festzustellen ist, was genau passiert. Man merkt nur, dass sich die eigenen Prozesse irgendwie verlangsamen. Zudem gibt es das Phänomen, dass das Gastsystem mit mehr V-Cores langsamer läuft als mit weniger. Daher sollten Admins aus Performance-Sicht bei kritischen und stark ausgelasteten Datenbanksystemen auf Virtualisierung verzichten.
Ebene 3: Die DB-Konfiguration
Die vordefinierten Konfigurationswerte für MySQL waren lange schlecht. Seit MySQL 5.6 haben sich die Defaultwerte aber stark verbessert. Viele ältere MySQL-Konfigurationsdateien schleppen aber ungünstige Einstellungen mit.
Die aktuellen MySQL-5.6-Versionen lassen sich mit rund 435 Variablen konfigurieren. Da stellt sich für den geplagten DBA schon mal die Frage: Wo fange ich an? (Abbildung 1) Zum Glück reicht es in den meisten Fällen, aus Performance-Sicht sieben MySQL-Variablen richtig zu konfigurieren. Schon damit ist zu erreichen, dass die meisten MySQL-Datenbanken vernünftig schnell arbeiten.
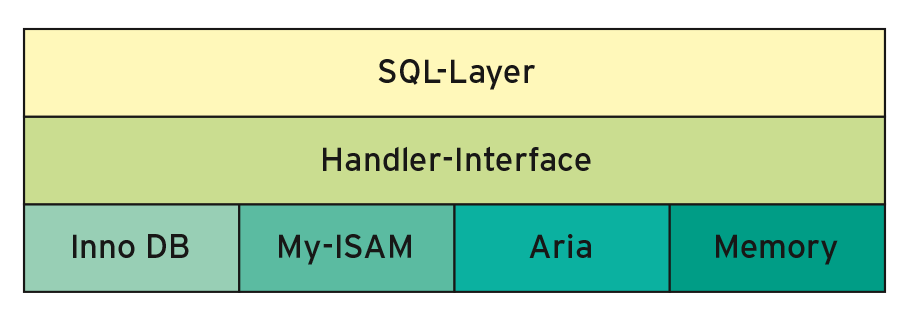
Abbildung 1: Die MySQL-Architektur in einer schematischen Übersicht.
MySQL ist durch seine Storage-Engine-Architektur auf der einen Seite hoch flexibel. Auf der anderen Seite erfordert diese Architektur auch Verständnis dafür, welche Parameter für welchen Bereich und welche Storage-Engine zuständig sind. Für den SQL-Layer sind primär drei Variablen wichtig: »table_open_cache« , »table_definition_cache« und »query_cache_size/query_cache_type« .
Der Table Open Cache
Der Table Open Cache steuert die Anzahl der Filedeskriptoren, die MySQL vom Betriebssystem anfordert. Dieser Wert sollte ungefähr so groß sein wie die Anzahl der Tabellen in den Joins mal der Anzahl der offenen Verbindungen. Ob der Wert groß genug gewählt ist, ermitteln die in Listing 6 angeführten Befehle.
Listing 6
Table Open Cache
01 mysql> SHOW GLOBAL STATUS LIKE 'Open%tables';
02 +---------------+-------+
03 | Variable_name | Value |
04 +---------------+-------+
05 | Open_tables | 400 |
06 | Opened_tables | 70123 |
07 +---------------+-------+
08
09 mysql> SHOW GLOBAL VARIABLES
WHERE variable_name = 'max_connections'
OR variable_name = 'table_open_cache';
10 +------------------+-------+
11 | Variable_name | Value |
12 +------------------+-------+
13 | max_connections | 151 |
14 | table_open_cache | 400 |
15 +------------------+-------+
Dazu ein Rechenbeispiel: Maximale Anzahl gleichzeitig offener Verbindungen x Tabellen pro Join = 151 x 5 (Annahme) = 755. Somit ist der »table_open_cache« (400) bei Maximalauslastung des Systems voraussichtlich unterdimensioniert. Am Rande bemerkt: In MySQL 5.1 ist der »table_cache« umbenannt in »table_open_cache« . Es finden sich aber immer noch alte Konfigurationen, die die neuen Defaultwerte übersteuern.
Der Table Definition Cache
Der Table Definition Cache puffert die geparsten und interpretierten Tabellendefinitionen. Der Anwender kann ihn bei normalen Anwendungen so groß wählen, wie die Anzahl der Tabellen in der MySQL-Instanz. Die Tabellenanzahl ist wie folgt zu ermitteln:
mysql> SELECT COUNT(*) FROM information_schema.tables; +----------+ | count(*) | +----------+ | 153 | +----------+
Die gängigen Defaultwerte von 256 bis 400 für den Table Definition Cache müssten für dieses Beispiel ausreichend dimensioniert sein.
Query Cache
Der nächste relevante MySQL-Parameter aus dem SQL-Bereich ist der Query Cache. Der müsste eigentlich korrekterweise Result Cache heißen, da er Abfrageresultate zwischenspeichert. Bei diesem Cache scheiden sich die Geister. Die einen halten den Cache für nutzlos und würden ihn am liebsten ganz ausschalten. Die anderen profitieren von den Performancegewinnen bei »SELECT« -Abfragen.
Die meisten MySQL-Anwender haben wahrscheinlich eine relativ geringe Anzahl gleichzeitig laufender Verbindungen zur Datenbank und einen hohen Anteil an Leseabfragen abzuarbeiten. Für diese Anwender empfiehlt es sich, den Query Cache einzuschalten.
Achtung: Seit MySQL 5.6 ist der Query Cache per Default ausgeschaltet! Also Vorsicht beim Upgrade. Den Query Cache sollte man nicht allzu groß wählen, da es sonst in gewissen Situationen zu vollständigen Systemblockaden kommen kann. Faustregel: Er sollte nicht größer als 128 MByte sein.
My-ISAM <C>key_buffer_size<C>
Für die My-ISAM-Storage-Engine gibt es vor allem einen wichtigen Parameter zu tunen: die My-ISAM »key_buffer_size« . Sie steuert, wie viel Speicher (RAM) die My-ISAM-Storage-Engine vom Betriebssystem für das Cachen der My-ISAM-Indexblocks anfordern soll. Da heute aber praktisch niemand mehr My-ISAM-Tabellen verwendet, ist dieser Parameter in Zukunft nicht mehr von sonderlicher Relevanz. Als Faustregel gilt hier: 25 bis 33 Prozent des RAM für ein dediziertes, ausschließlich My-ISAM nutzendes Datenbanksystem.
Das Analogon ist »aria_pagecache_buffer_size« bei der Verwendung der Aria-Storage-Engine, die Maria DB mitliefert.
Inno-DB-Parameter
Nun wird es Zeit für die wichtigsten Parameter für die Inno-DB-Storage-Engine, die seit MySQL 5.5 die voreingestellte Storage-Engine bei MySQL ist.
- Den Inno DB Buffer Pool stellt der Admin über den Parameter »innodb_buffer_pool_size« ein. Der steuert, wie viel Speicher (RAM) die Inno-DB-Storage-Engine vom Betriebssystem anfordern soll, um die Inno-DB-Daten- und Indexblocks zu cachen. RAM ist rund 100000-mal schneller als eine Disk, und somit lassen sich die Abfragen signifikant beschleunigen, wenn die Daten im RAM liegen statt auf der Festplatte. Hier gilt tendenziell: Viel hilft viel. Faustregel: Rund 80 Prozent vom freien RAM sollte der Anwender für den Inno DB Buffer Pool verwenden.
- »innodb_log_file_size« : Dieser Parameter steuert die Größe der Inno-DB-Transaktionslogs, von denen es üblicherweise zwei gibt. Die Größe dieser beiden Dateien beeinflusst die Geschwindigkeit von Schreibzugriffen auf Inno DB. Dieser Wert war lange viel zu klein (5 MByte). Die neuen Defaultwerte in MySQL 5.6 tragen dem Rechnung und lauten 48 MByte. Tendenziell: Größer bedeutet eine bessere Schreibperformance, aber auch eine längere Recoveryzeit nach einem Systemcrash. Achtung: Mit MySQL 5.5 und älter sollte der Admin sich in der Dokumentation genau anschauen, wie die Größe dieser Dateien zu ändert ist. Wer es falsch macht, dessen Datenbank startet unter Umständen nicht mehr.
- Der Parameter »innodb_flush_log_at_trx_commit« steuert bei Inno DB, wie die Daten bei einem »COMMIT« auf die Platte gelangen. Der Defaultwert »1« steht für das sauberste Verhalten, das auch ACID-konform ist. Er bedeutet, dass MySQL die Daten beim »COMMIT« aus dem Logbuffer in die Transaktionslogs schreibt und flusht (»fsync« ). Damit ist bei einem Crash des Systems sichergestellt, dass keine Daten verloren gehen. Diese sichere Einstellung hat jedoch auch ihren Nachteil: Ein Flush ist langsam und somit ist der Schreibdurchsatz des Systems gering. Sollte Schreibperformance wichtiger als ein kleiner Datenverlust im Falle eines Crashs sein (etwa 1 Sekunde), dann lässt sich der Wert für »innodb_flush_log_at_trx_commit« auch auf »0 « (Logbuffer einmal pro Sekunde leeren und flushen) oder »2« (Logbuffer bei jedem »COMMIT« leeren und einmal pro Sekunde auf die Platte schreiben) einstellen. Das führt zu einer signifikanten Erhöhung des Schreibdurchsatzes. Eine allgemeine Übersicht über die MySQL-Server- und MySQL-Status-Variablen findet sich bei [1].
Ebene 4: Applikationstuning
Die vierte Tuning-Ebene widmet sich der Applikation, was bei Datenbanken in erster Linie Query-Tuning bedeutet. Hier lassen sich die meisten Performancegewinne erzielen. Leider erfordern diese Maßnahmen meist Änderungen am Design oder zumindest am Code der Anwendung. Das ist nicht immer möglich und stößt auch nicht immer auf Gegenliebe bei den Entwicklern.
Auch ohne Eingriffe in den Code sind jedoch oft bereits durch geschicktes Indexieren Performancegewinne zu erreichen. Indizes sind hauptsächlich dazu da, den Lesezugriff (»SELECT« ) auf Daten zu beschleunigen. Oft taugen Indizes auch dafür, um in »UPDATE« – oder »DELETE« -Operationen Zeilen schneller aufzufinden. Einen Index stellt man sich am besten wie ein Telefonbuch (Ort, Nachname, Vorname) oder ein Register in der Bibliothek (sortiert nach Titel, Autor und so weiter) vor.
Wer eine Person anhand des Ortes, des Nach- und Vornamens sucht, wird im Telefonbuch recht schnell fündig. Fehlt aber die Ortsangabe, wird die Suche ziemlich mühsam, es müssten dann alle Telefonbücher von vorn bis hinten durchmustert werden. Ein analoges Problem hat die MySQL-Datenbank: Fehlt ein Index, führt das zu einem sehr teuren Full Table Scan oder aber, wenn das erste Attribut des Index nicht bekannt ist, zu einem Full Index Scan.
Gibt es dagegen einen Index, so gelangt die Anfrage über den Index-Eintrag oder über eine Reihe von Index-Einträgen (Range) direkt zum Zugriff auf die richtige Tabellenzeile. Mit dem Anlegen der richtigen Indizes kann der Anwender der Datenbank also dazu verhelfen, massiv weniger Arbeit verrichten zu müssen. Was oft zu 10- bis 50-facher Abfragebeschleunigung führt.
Welche Indizes sind richtig?
Jede Tabelle sollte einen eindeutigen Zeilen-Indentifizierer (ID) haben. MySQL verwendet dazu oft ein »AUTO_INCREMENT« -Feld als Primary Key. Sollte eine Tabelle keinen Primary Key haben, ist das bei OLTP-Systemen aus akademischer Sicht einerseits unschön, andererseits ebenfalls Performance-relevant (etwa bei der Replikation).
Bei Inno-DB-Tabellen gilt es, ein besonderes Augenmerk auf die Wahl des Primary Key zu legen. Relevant ist dessen Länge: Der Primary Key wird in allen Secondary Keys (alle Indizes einer Tabelle, die nicht Primary Key sind) als Referenz mit abgelegt. Wer einen langen Primary Key wählt, vergrößert somit alle Secondary Keys. Zudem wird der Primary Key oft sehr intensiv im Zusammenhang mit Joins verwendet. Ein langer Primary Key führt dazu, dass ein Join entsprechend viele CPU-Zyklen braucht.
Ein weiterer Punkt, dem bei der Wahl des Primary Key Beachtung zu schenken ist, ist die Lokalität (physische Lage) der Daten. Inno DB kreiert immer eine so genannte Index Organized Table. Das bedeutet, dass Inno DB die Daten in den Blocks physisch immer so sortiert, wie der Primary Key aufgebaut ist. Das hat ein entsprechendes Sortiermuster der Daten zur Folge, das von Fall zu Fall vor- oder nachteilig sein kann, etwa bei Zeitreihen.
Das Beispiel von Listing 7 erzeugt zwei Tabellen: Eine mit dem Primary Key auf einer »AUTO_INCREMENT« -ID, was einer zeitlich aufsteigenden Reihenfolge der Zeilen entspricht. Die zweite mit einer zufälligen ID als Primary Key, was einer zufälligen Reihenfolge der Zeilen entspricht. Die erste Version kommt dem üblichen Zugriffsmuster in MySQL entgegen. Es werden typischerweise oft relativ junge Zeilen gesucht. In diesem Fall ist eine zeitlich aufsteigende Sortierung meist sinnvoll. Der zweite Primary Key funktioniert dagegen schlecht, da typischerweise nie nach einem völlig wirren Zufallsmuster gesucht wird.
Listing 7
Zwei Primary Keys
01 mysql> CREATE TABLE daten_time (id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, data VARCHAR(64), ts TIMESTAMP); 02 03 mysql> CREATE TABLE daten_random (id CHAR(32) NOT NULL PRIMARY KEY, data VARCHAR(64), ts TIMESTAMP); 04 05 mysql> INSERT INTO daten_time VALUES ( NULL, 'Zeile 1', NULL); SELECT SLEEP(1); 06 mysql> INSERT INTO daten_time VALUES ( NULL, 'Zeile 2', NULL); SELECT SLEEP(1); 07 mysql> INSERT INTO daten_time VALUES ( NULL, 'Zeile 3', NULL); SELECT SLEEP(1); 08 09 mysql> INSERT INTO daten_random VALUES ( MD5(CURRENT_TIMESTAMP()), 'Zeile 1', NULL); SELECT SLEEP(1); 10 mysql> INSERT INTO daten_random VALUES ( MD5(CURRENT_TIMESTAMP()), 'Zeile 2', NULL); SELECT SLEEP(1); 11 mysql> INSERT INTO daten_random VALUES ( MD5(CURRENT_TIMESTAMP()), 'Zeile 3', NULL); SELECT SLEEP(1); 12 13 mysql> CREATE TABLE `daten_time` ( 14 `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, 15 `data` VARCHAR(64) DEFAULT NULL, 16 `ts` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, 17 PRIMARY KEY (`id`) 18 ) ENGINE=InnoDB AUTO_INCREMENT=4 19 20 mysql> CREATE TABLE `daten_random` ( 21 `id` CHAR(32) NOT NULL, 22 `data` VARCHAR(64) DEFAULT NULL, 23 `ts` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, 24 PRIMARY KEY (`id`) 25 ) ENGINE=InnoDB DEFAULT 26 27 mysql> SELECT * FROM daten_time; 28 +----+---------+---------------------+ 29 | id | data | ts | 30 +----+---------+---------------------+ 31 | 1 | Zeile 1 | 2015-09-13 15:24:05 | 32 | 2 | Zeile 2 | 2015-09-13 15:24:06 | 33 | 3 | Zeile 3 | 2015-09-13 15:24:07 | 34 +----+---------+---------------------+ 35 36 mysql> SELECT * FROM daten_random; 37 +----------------------------------+---------+---------------------+ 38 | id | data | ts | 39 +----------------------------------+---------+---------------------+ 40 | 47e0142a3638fdc24fe40d4e4fbce3f1 | Zeile 1 | 2015-09-13 15:24:12 | 41 | b833c1e4c5bfc47d0dbe31c2e3f30837 | Zeile 3 | 2015-09-13 15:24:14 | 42 | c7d46523a316de4e1496c65c3cbdf358 | Zeile 2 | 2015-09-13 15:24:13 | 43 +----------------------------------+---------+---------------------+
Ein weiteres Problem, das Primary Keys betrifft, sind Zeitreihen. Ein Beispiel findet sich in Listing 8. Die Abfrage erfolgt aber typischerweise nicht über die Zeit allein, sondern über Zeit pro Device. Ein Primary Key nur auf »id« wäre hier unglücklich gewählt und entspricht aus Sicht der Abfragelogik einer zufälligen Verteilung. Ein zusammengesetzter Index (»device, ts« ) würde die Daten umsortieren (nach Devices und innerhalb der Devices nach Zeit) und die Abfragen somit deutlich beschleunigen.
Listing 8
Primary Keys und Zeitreihen
01 mysql> CREATE TABLE `daten_timeseries` ( 02 `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, 03 `device` varchar(32) NOT NULL, 04 `data` VARCHAR(64) DEFAULT NULL, 05 `ts` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, 06 PRIMARY KEY (`id`) 07 ) ENGINE=InnoDB AUTO_INCREMENT=4 08 ; 09 10 mysql> INSERT INTO daten_timeseries VALUES (NULL, 'Kühlschrank', '5.8 °C', NULL); 11 mysql> INSERT INTO daten_timeseries VALUES (NULL, 'Waschmaschine', '41.2 °C', NULL); 12 ... 13 14 mysql> SELECT * FROM daten_timeseries WHERE device = 'Kühlschrank' AND ts 15 BETWEEN '2015-09-13 00:00:00' AND '2015-09-13 23:59:59' 16 17 +----+--------------------------+----------+---------------------+ 18 | id | device | data | ts | 19 +----+--------------------------+----------+---------------------+ 20 | 4 | Kühlschrank | 5.8 °C | 2015-09-13 15:34:42 | 21 | 5 | Waschmaschine | 41.2 °C | 2015-09-13 15:34:42 | 22 | 6 | Topfpflanzenfeuchtigkeit | 75% rel. | 2015-09-13 15:34:42 | 23 | 7 | Kühlschrank | 6.0 °C | 2015-09-13 15:35:42 | 24 | 8 | Waschmaschine | 41.1 °C | 2015-09-13 15:35:42 | 25 | 9 | Topfpflanzenfeuchtigkeit | 74% rel. | 2015-09-13 15:35:42 | 26 | 10 | Kühlschrank | 6.2 °C | 2015-09-13 15:36:42 | 27 | 11 | Waschmaschine | 41.2 °C | 2015-09-13 15:36:42 | 28 | 12 | Topfpflanzenfeuchtigkeit | 73% rel. | 2015-09-13 15:36:42 | 29 +----+--------------------------+----------+---------------------+
Weitere Indizes
Neben der Wahl des Primary Key ist es ebenfalls wichtig, die nötigen und richtigen sekundären Indizes anzulegen. Für sie verwenden die meisten Datenbankentwickler typischerweise jene Attribute, die Bestandteil von Joins sind oder nach denen eine Abfrage Informationen filtert (per Where-Klausel). In
mysql> SELECT * FROM employee WHERE last = 'Müller';
ist es sehr wahrscheinlich sinnvoll, einen Index auf das Feld »last« zu legen.
Ob der Optimizer von MySQL einen Index auch tatsächlich nutzt, lässt sich mit dem Befehl »EXPLAIN« ermitteln (Listing 9). Der Nutzer sollte dabei allerdings nicht nur schauen, ob ein Index verwendet wird, sondern auch die Ausführungszeit des Befehls mehrmals messen, um sicherzustellen, dass die Maßnahme auch eine positive Wirkung hat. Es kann nämlich durchaus vorkommen, dass der gewählte Index eine schlechtere Performance zur Folge hat.
Listing 9
EXPLAIN
01 mysql> EXPLAIN SELECT * FROM employee WHERE last = 'Müller'; 02 +----+-------------+----------+------+---------------+------+---------+------+------+-------------+ 03 | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | 04 +----+-------------+----------+------+---------------+------+---------+------+------+-------------+ 05 | 1 | SIMPLE | employee | ALL | NULL | NULL | NULL | NULL | 987 | Using where | 06 +----+-------------+----------+------+---------------+------+---------+------+------+-------------+ 07 08 mysql> ALTER TABLE employee ADD INDEX (last); 09 10 mysql> EXPLAIN SELECT * FROM employee WHERE last = 'Müller'; 11 +----+-------------+----------+------+---------------+------+---------+-------+------+--------------+ 12 | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | 13 +----+-------------+----------+------+---------------+------+---------+-------+------+--------------+ 14 | 1 | SIMPLE | employee | ref | last | last | 67 | const | 1 | Using index condition | 15 +----+-------------+----------+------+---------------+------+---------+-------+------+--------------+
Slow Query Log
Um langsame Abfragen systematisch zu erfassen, dient in MySQL das so genannte Slow Query Log. Es lässt sich seit MySQL 5.1 dynamisch einschalten und konfigurieren:
mysql> SET GLOBAL slow_query_log = 1;mysql> SET GLOBAL long_query_time = 0.200;
Wo das Slow Query Log auf der Platte liegt, kann der Anwender abfragen:
mysql> SHOW GLOBAL VARIABLES LIKE 'slow%file'; +---------------------+----------+ | Variable_name | Value | +---------------------+----------+ | slow_query_log_file | slow.log | +---------------------+----------+
Falls der Pfad nicht genauer spezifiziert ist, liegt die Datei unter »$datadir« in »/var/lib/mysql« .
Ebene 5: Die Architektur
Die fünfte Ebene, auf der man sich nach Möglichkeiten für eine Beschleunigung umsehen kann, ist die Architektur. Sie bietet üblicherweise den größten Hebel für Verbesserungen, den der Anwender aber bereits zu Beginn des Entwicklungsprozesses nutzen muss. Trifft er hier eine falsche Entscheidung, ist sie schwer und meist nur mit sehr großem Aufwand zu korrigieren.
Wichtige Größen sind die Anzahl der Nutzer und die Datenmenge, die im Endausbau anfallen wird. Je größer die erwarteten Werte sind, desto mehr Nachdenken verdient die Architektur. Einige Punkte, die immer wieder zur Sprache kommen, sind:
- Datenbank-Cluster bringen mehr Performance! Diese Aussage ist tendenziell falsch. Datenbank-Cluster sind typischerweise eine Hochverfügbarkeitslösung und keine Lösung, um Performanceprobleme in den Griff zu kriegen. Antwortzeiten bei Lesezugriffen bleiben in etwa gleich. Antwortzeiten für Schreibzugriffe bleiben gleich oder verlängern sich eher. Die Leseleistung kann sich bei den meisten MySQL-Clusterlösungen verbessern – sofern man gewisse Restriktionen in Kauf nimmt. Das Schreiben skaliert kaum bis gar nicht.
- Durch Parallelisieren lässt sich der Durchsatz einer Applikation dramatisch erhöhen. MySQL kann sehr wohl Dutzende von Abfragen gleichzeitig abarbeiten, das erfordert jedoch eine entsprechende Applikation. Selbstständig Abfragen parallelisieren – das kann MySQL nämlich nicht.
- Für Anwendungen, die massiv skalieren sollen und einen hohen Lese-Anteil aufweisen, empfiehlt es sich, in der Applikation eine separate Lese- und eine Schreibverbindung auf die Datenbank zu öffnen. Das ermöglicht später das Umleiten der Lese-Abfragen auf einen MySQL-Lese-Cluster. Bei Automaten, die das automatische Read-Write-Splitting proklamieren, ist Vorsicht angesagt. Eine zuverlässige Intelligenz zu entwickeln, die automatisch richtig entscheidet, ist schwierig. Wie sollen das fremde Entwickler hinkriegen, wenn nicht einmal die eigenen Entwickler dazu in der Lage sind? Zudem funktionieren solche Automaten üblicherweise nur bei Single-Query-Transaktionen.
- Das größte Problem beim Skalieren ist das Schreiben. Die Schwierigkeit beim Lesen lässt sich durch viel RAM und eine entsprechende Anzahl Lese-Slaves lösen. Wenn die Maschine aber beim Schreibdurchsatz in die Knie geht, kann nur ein schnelles I/O-System, zum Beispiel eine SSD, weiterhelfen. Gelangt man auch damit nicht mehr weiter, kommt als allerletzte Lösung Sharding in Betracht, also die Daten über mehrere Datenbank-Backends zu verteilen. Jedes Backend hat sein eigenes I/O-System. So skalieren Schreibzugriffe theoretisch unendlich. Das hat aber signifikanten Einfluss auf die Applikation: Die Applikation muss wissen, wo die Daten liegen, um sie entsprechend auf das richtige Backend schreiben zu können. Diese Forderung hat oft tiefgreifende Änderungen am Applikationscode zur Folge.
Low Hanging Fruits
Oft werden beim Performancetuning von Datenbanken schnelle Resultate erwartet, am liebsten schon morgen. Änderungen am Applikationscode, dort wo es wirklich etwas bringen würde, sind aber zeitaufwändig. Daher stellt sich die Frage: Wo kann man auf die Schnelle noch etwas Performance herauskitzeln? Die schnellsten Lösungen sind:
- Hardware mit mehr RAM und einem schnellen I/O-System (großes Raid 10 mit schnellen Platten und/oder SSD).
- Datenbank korrekt konfigurieren: Den RAM auch richtig nutzen – mit »innodb_buffer_pool_size« für Lesezugriffe und »innodb_log_file_size« für hohen Schreibdurchsatz. Wenn im Falle eines Datenbank-Crash ein geringer Datenverlust zu verschmerzen ist, kann der Admin zusätzlich auch »innodb_flush_log_at_trx_commit« auf »0« oder »2« stellen. Bei einer größeren Anzahl von Tabellen hilft es zudem, den »table_open_cache« sowie auch den »table_definition_cache« zu vergrößern.
- Zu guter Letzt hilft stets das Anlegen der richtigen Indizes dabei, Abfragen signifikant zu beschleunigen.
Einer MySQL-Datenbank Beine machen? Mit den richtigen Praxistipps ist das gar nicht so schwer. (jcb)
Infos





