
© jakobradlgruber, 123RF
Für Docker-Setups, die gut skalieren müssen, erweist sich die effiziente Verwaltung von Docker-Containern als mindestens so wichtig wie die Container selbst. Flocker will zumindest für den Storage und die Verfügbarkeit in einer solchen Landschaft eine Lösung bieten.
Docker — der Hype um die Container scheint ungebrochen. Keine Woche vergeht, in der nicht irgendein großes Unternehmen im besten Marketing-Sprech ein neues Produkt auf Docker-Basis ankündigt. Und auch die Docker-Entwickler selbst lassen die IT-Gemeinde regelmäßig wissen, welche neuen Funktionen sie in die Container eingebaut haben. So bildet sich eine Produktumgebung heraus, die Branchengrößen wie Red Hat oder Suse zusätzlich mit erheblichen Investitionen düngen.
Das wiederum ruft tatsächlich ein steigendes Interesse unter Anwendern hervor. Typische ISPs nutzen Containervirtualisierung zum Beispiel, um ihren Kunden virtuelle Systeme zu bieten, ohne den Overhead eines vollständigen virtuellen PC in Kauf nehmen zu müssen. Je nach genutzter Virtualisierungstechnik spart das locker 20 bis 30 Prozent an Leistung, Für andere Firmen ist Docker ein ideales Entwicklungswerkzeug: In solchen Konstellationen gibt es Golden-Master-Vorlagen für Container, die sich beliebig oft starten lassen und jedes Mal wieder zu einer sauberen Entwicklungsumgebung führen.
Alle Docker-Szenarien haben eine Gemeinsamkeit, wenn sie sich auf Enterprise-Ebene abspielen: Stets stehen die Betreiber von Docker-Containern irgendwann vor dem Problem, dass sie ihre Hardware auf der einen Seite und ihre Docker-Container auf der anderen Seite verwalten müssen.
Ab Werk – nichts
Ein Problem liegt dabei in der Art und Weise, wie einfache Docker-Container arbeiten. Docker ist nach seiner eigenen Definition nicht für den Betrieb über mehrere Rechner hinweg ausgelegt. In der einfachsten Spielart ist ein Container im Docker-Format eine rein lokale Angelegenheit – der Anwender startet per Kommandozeile den entsprechenden Container lokal auf seinem System und greift danach via Netz darauf zu. Freilich kann derselbe Anwender auch auf einem zweiten Host einen Docker-Container händisch starten und die beiden Container im Anschluss miteinander kommunizieren lassen.
Der Ansatz funktioniert aber schon dann nicht mehr, wenn wie bei großen Systemen mehr als nur ein Hardwarepaar im Spiel ist. Auch andere Probleme tun sich in produktiven Docker-Umgebungen auf, zum Beispiel: Wie lassen sich etwa die Daten, die zu einer VM gehören, zwischen Hosts synchron halten, sodass die gleiche VM jederzeit entweder auf Host 1 oder auf Host 2 starten kann?
Klassische Hochverfügbarkeit der Daten kommt bei Setups mit Docker als Thema selten vor. Im Alltag wäre sie aber wichtig: Wer beispielsweise eine Datenbank in einem Docker-Container betreibt, möchte natürlich nicht, dass diese nur auf einem einzelnen Host laufen kann. Denn dann wäre ja Feuer unterm Dach, wenn eben dieser Host ausfiele.
Flocker als Retter in der Not
Genau hier setzt Flocker [1] an. Flocker will ein umfassendes Flottenmanagement im Hinblick auf persistenten Speicher für Docker realisieren. Einerseits soll es mit Flocker möglich sein, Docker-Container möglichst effizient auf eine Armada physischer Rechner zu verteilen. Vorrangig aber bietet Flocker eine Lösung für ein drängendes Storageproblem: Die Entwickler von Flocker versprechen, dass sich Storagegeräte für Docker-Container völlig unabhängig von einem bestimmten Container verwalten lassen, sodass der zu den Daten gehörende Dienst theoretisch auf jedem beliebigen Rechner laufen könnte (Abbildung 1).

Abbildung 1: Flocker erweitert Docker um persistente Volumes, die sich auch von einem Host auf einen anderen übertragen lassen. (Quelle: Cluster HQ)
Damit stopft Flocker eine Lücke, die typische Docker-Setups aufweisen. Und der Dienst geht noch weiter: Flocker will Admins zum Beispiel auch die Option bieten, Multi-Container-Applikationen so zu starten, dass die dazugehörigen Container automatisch auf mehrere Hosts verteilt sind. Das Ganze natürlich mit persistentem Speicher im Hintergrund, sodass Container schnell zwischen den Hosts umziehen können.
Damit wildert Flocker eigentlich im Jagdrevier von Flottenmanagern wie Googles Kubernetes. Will die Software also tatsächlich ein vollständiger Flottenmanager sein, der in direkter Konkurrenz zu anderen Ansätzen steht? Oder lassen sich etwa Kubernetes und Flocker sogar sinnvoll miteinander kombinieren?
Cluster HQ als treibende Kraft
Hinter Flocker steckt das amerikanische Unternehmen Cluster HQ. Die Firma gibt es laut Crunchbase bereits seit 2008. Spannend liest sich die kurze Selbstbeschreibung: Man sei dafür zuständig, Docker einen funktionierenden Data-Layer zu spendieren. Auf diese Idee kann man aber erst einige Zeit nach Gründung der Firma gekommen sein, denn von Docker war vor sieben Jahren noch keine Rede. Anfang 2015 konnte Cluster HQ rund 12 Millionen Dollar in seiner ersten Investorenrunde einsammeln.
Geld ist also genug da, auch für eine längerfristige Entwicklung von Flocker. Darauf liegt bei Cluster HQ im Augenblick der Fokus: Wer die Website des Unternehmens [1] öffnet, erhält dort vorrangig Informationen zu Flocker.
Dreh- und Angelpunkt: Volumes
Wer sich mit Flocker erstmals beschäftigt, stolpert über einen Haufen von Fachbegriffen. Im Flocker-Universum ist der wichtigste definitiv das Volume: Als Volume firmiert in Docker-Setups jede Art von Storagegerät, das Daten von einem spezifischen Docker-Container enthält. Volumes für Docker sind keine Erfindung von Cluster HQ, auch im reinen Docker-Umfeld ist der Begriff geläufig.
So geht auch die offizielle Docker-Dokumentation [2] auf das Thema Volumes direkt ein. Sie beschreibt Volumes als Datensilos, die am Union-FS-Layer von Docker vorbeigehen und somit nicht direkt zu einem Container gehören. Trotzdem lassen sie sich an einen Container anschließen und tauchen danach im Container als eigenes Verzeichnis auf. Docker selbst enthält aber keinerlei Intelligenz, um sich um die Verwaltung von Containern auf Host-Ebene zu kümmern oder gar die darunterliegende Hardware zu beachten. Der Befehl
docker run -d -P --name web -v /webapp training/webapp python app.py
würde etwa einen neuen Container namens »web« mit einem frischen Volume starten, das anschließend im Container selbst unter »/webapp« zur Verfügung stünde.
Ein Blick auf den gestarteten Container per »docker inspect web« würde anschließend verraten, dass Docker den Container in seinem eigenen Lib-Verzeichnis lokal angelegt hat, meist also in »/var/ lib/docker/volumes« . Auf ähnliche Weise ließe sich auch ein auf dem Host befindliches Verzeichnis direkt in den Container integrieren, vorausgesetzt natürlich, dass der Docker-Nutzer auf den Ordner die dafür nötigen Zugriffsrechte hat.
So oder so: Bei typischen Docker-Installationen sind Volumes immer lokal. Admins behelfen sich dadurch, dass sie einen zentralen Speicher etwa mittels eines gesharten Dateisystems wie NFS anbinden und die Volumes für Docker-Container händisch auf diesem verwalten. Über Performance oder Effizienz braucht man dann aber schon gar nicht mehr nachzudenken. Wirklich elegant ist die Lösung auch nicht. Denn das Umziehen von Containern müsste der Admin manuell bewerkstelligen.
Genau hier setzt Flocker an: Von außen stülpt die Software einen neuen Layer über Docker, der sich fortan um die Verwaltung von Docker-Volumes und der dazugehörigen Geräte kümmert. Er erledigt automatisch alle anfallenden Aufgaben, um Container mit persistenten Volumes zu versorgen – Flocker übernimmt im Grunde also die Automatisierung der Arbeitsschritte, die ansonsten der Admin von Hand machen müsste.
Das klassische Flocker-Setup besteht aus mehreren externen Komponenten, die die Flocker-Entwickler selbst geschrieben haben. Aus einer beliebigen Anzahl von Knoten, wobei auf jedem Knoten der Flocker-Agent läuft, formt Flocker einen Cluster. Der Agent kommuniziert mit dem Docker Control Service, der idealerweise auf einem eigenen Host oder zumindest in einer separaten VM läuft – unabhängig von den restlichen Docker- und Flocker-Komponenten. Im Hintergrund hat Flocker zudem eine Schnittstelle hin zu verschiedenen Storagelösungen: Von hier kommt der Speicher, den Flocker kommissioniert und den Docker-Containern zur Verfügung stellt.
Der Controller und das API
Die Architektur von Docker erinnert in vieler Hinsicht an andere Projekte des Docker-Dunstkreises, etwa an Googles Kubernetes. Die wichtigste Komponente der gesamten Installation ist der Flocker Control Service, er ist die zentrale Instanz innerhalb eines Flocker-Clusters.
Die Control-Komponente kommuniziert bei Flocker in beide Richtungen: Einerseits holen sich die Flocker-Agenten auf den Hosts die spezifischen Informationen für einzelne Container und die damit in Verbindung stehenden Volumes. Zugleich ist Flocker Control die Schnittstelle hin zur Nutzerseite: Will der Admin einen neuen Container mit persistentem Speicher starten, tut er das in Flocker nicht mehr direkt über Docker auf den einzelnen Hosts – stattdessen weist er den Control-Service von Flocker dazu an, einen passenden Container zu starten (Abbildung 2).
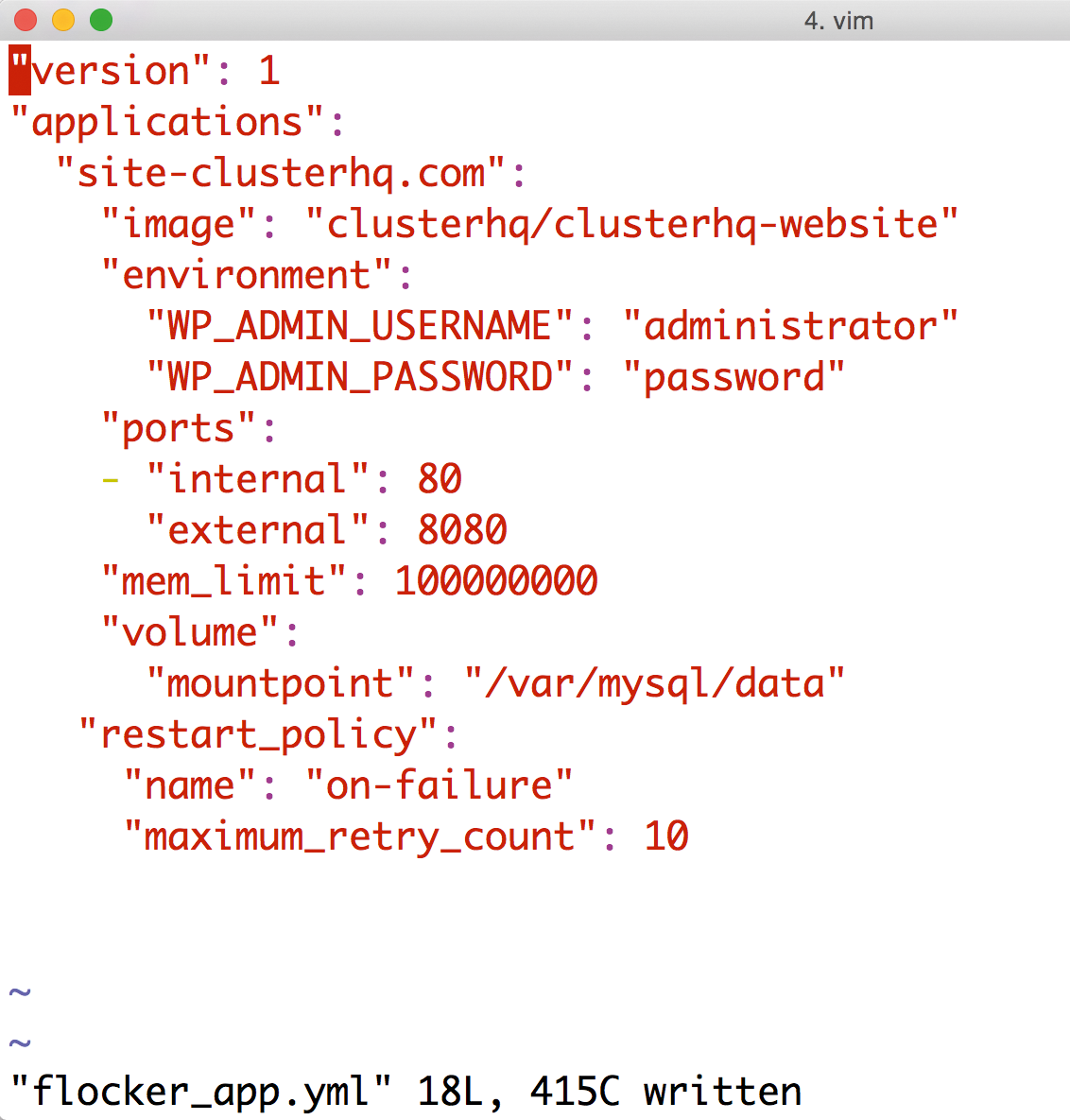
Abbildung 2: In Version 1.0 muss Flocker die Container per Docker starten. Dazu nutzt »flocker-cli« eigene Yaml-Konfigurationsdateien.
Hier agiert Flocker nicht mehr nur als Speichermanager – wer Flocker mit dem Control-Dienst so einsetzt, nutzt es im Grunde als halben Flottenmanager. Mittlerweile ist Cluster HQ von dieser Sichtweise wieder abgerückt, aber dazu später mehr. Für die stabile Flocker-Version 1.0 gilt aber, dass Admins sich umgewöhnen müssen, was den Umgang mit Containern angeht.
Vorbildlich: Wer Flocker installiert, kommt nicht um das Aufsetzen eigener Zertifikate für Flocker-Control und die Agents herum. Die Kommunikation zwischen diesen Komponenten läuft stets verschlüsselt ab, ähnlich wie zum Beispiel bei Puppet.
Flocker Control nutzt ein Restful-API für die Kommunikation zur Außenwelt – im Cloud Computing gehört das mittlerweile zum guten Ton. Statt spezieller Protokolle kommt also HTTP zum Einsatz, notfalls lässt sich der Control-Daemon von Flocker auch mit Curl ansprechen. Sinnvoller ist aber der Kommandozeilenclient »flocker-cli« : Das ist auch der offizielle Weg, um mit dem Flocker-API zu sprechen.
Eigene Templates
Gerade weil Flocker Control hier als De-facto-Flottenmanager auftritt und sich zwischen Docker und den Admin drängt, muss es alle Docker-Funktionen so gut wie möglich unterstützen. Die Entwickler haben das über eigene Templates im Yaml-Format gelöst. Jede Flotte von Docker-Containern benötigt mindestens zwei Konfigurationsdateien: Die erste beschreibt detailliert die Container-Konfiguration selbst, im zweiten Template beschreibt der Admin, auf welchen Hosts innerhalb des Setups Flocker die Container dann auch starten darf. Unter [3] findet sich eine allerdings eher oberflächliche Erklärung der wichtigsten Konfigurationsoptionen beider Dateien.
Liegen beide Dateien – im Beispiel sind das »clusterhq_deployment.yml« für das Blech und »clusterhq_app.yml« für die Container – vor, dann startet der folgende Befehl die gewünschten Container:
flocker-deploy controlservice.example.com clusterhq_deployment.yml clusterhq_app.yml
Der Parameter »controlservice.example.com« ist dabei die Adresse, unter der der Flocker-Control-Dienst erreichbar ist.
Der Agent organisiert den Speicher
Der Befehl sorgt dafür, dass die Flocker-Agents auf den einzelnen Hosts die Docker-Container in Gang setzen. Aber vorher fehlt noch ein wichtiger Schritt, der klärt, wie genau Flocker die gestarteten Container mit persistenten Volumes versorgt. Diese Aufgabe fällt ebenfalls in die Verantwortung der Agents.
Lösungen wie Open Stack kommissionieren den Storage meist über eine zentrale Cluster-weite Komponente (etwa »cinder-volume« bei Open Stack). Nicht so bei Flocker: Hier zeichnet jeder Agent dafür verantwortlich, dass die gestarteten Container die Volumes bekommen, die sie haben sollen. Die Agents sind auf der Hypervisor-Seite also das exekutive Pendant zum Control-Dienst – sie sind die Mädchen für alles. Den technischen Unterbau für diese Aufgabe haben die Flocker-Leute sehr elegant gelöst: Der Flocker-Agent arbeitet auf jedem Host mit echten Docker-Volumes. Also mit jenen Volumes, die in Docker ab Werk ohnehin vorgesehen sind.
Ein Container, den Flocker mit persistentem Speicher gestartet hat, unterscheidet sich nach außen de facto nicht von einem normalen Docker-Container, an den der Admin händisch ein Volume angeschlossen hat. Das Zauberwort lautet Named Volumes. Der Name rührt daher, dass sich ein Docker-Volume durch einen Namen eindeutig identifizieren lässt, selbst wenn man es von dem einen Docker-Container löst und an einen anderen übergibt.
Damit das funktioniert, wickelt der Agent viele Aufgaben ab, ohne dass es der Admin merkt: Auf dem konfigurierten Backend-Storage legt er ein passendes Docker-Volume mit eindeutigem Namen an und startet den Container anschließend so, dass er eben jenes Volume benutzt. Gleichzeitig hinterlässt der Agent im Control-Server einen Eintrag darüber. Der Control-Server erfährt nach dem Start des Containers also, dass das eindeutig identifizierbare Volume X aktuell zum Container Y gehört.
Soll das Volume später zu einem anderen Container wandern, weist der Flocker-Controller die Agents auf den Hosts entsprechend an – und sorgt damit für persistente Volumes in Docker. Dienste wie Datenbanken lassen sich über dieses Prinzip also erstmals in Docker-Containern betreiben, ohne dass der Container auf einen einzelnen Host festgenagelt ist. In der Praxis bedeutet diese Arbeitsaufteilung, dass jeder Agent im Cluster wissen muss, welche Storagegeräte zur Verfügung stehen. Die passenden Einträge gehören direkt in die Konfigurationsdatei der Agents.
Große Auswahl in Sachen Storage
Unter [4] pflegt Cluster HQ eine Liste der Storagevarianten, die Flocker 1.0 im Augenblick verwenden kann. Dabei fällt besonders die Unterstützung für ZFS auf: Flocker nutzt ZFS als Ansatz, um lokalen Blockspeicher für Docker nutzbar zu machen. ZFS beherrscht ein eigenes Replikationsfeature, sodass das Speichern von Daten auf mehreren Hosts gleichzeitig kein Problem darstellt.
Allerdings weist Cluster HQ darauf hin, dass der ZFS-Treiber für Flocker noch nicht stabil sei und seine Nutzung im produktiven Umfeld nicht empfohlen ist. Schade, denn um zum Beispiel niedrige Latenzen für Datenbanken zu garantieren, ist die Arbeit mit schnellem, lokalen Speicher fast unumgänglich.
Besser eignen sich die anderen Storage-Backends: Amazons EBS-Storage in der AWS-Cloud oder Cloud Block Storage von Rackspace lassen sich schon jetzt produktiv einsetzen. Der Flocker-Agent legt bei entsprechender Konfiguration dann einfach Volumes in den jeweiligen Cloudumgebungen an.
Großen Wert legt Cluster HQ auch auf Open-Stack-Unterstützung: Cinder, das sich in Open-Stack-Clouds typischerweise um die Zuweisung von persistentem Speicher kümmert, bietet ja ohnehin ein entsprechendes API. Ein Client bittet bei Cinder also lediglich um die Zuweisung eines Volume und erhält im standardisierten Format dann die Information, wo er das Volume findet und wie er es nutzen kann (Abbildung 3). »nova-compute« , das in Open Stack VMs verwaltet, arbeitet genauso, wenn es eine VM von persistentem Speicher startet. Die gleiche Funktionalität haben die Flocker-Entwickler im Flocker-Agent nachgebaut: Ist der Agent so eingestellt, dass er mit einer Instanz des Cinder-API reden kann, darf er auch die dort zur Verfügung gestellten Volumes für Docker-Container nutzen.
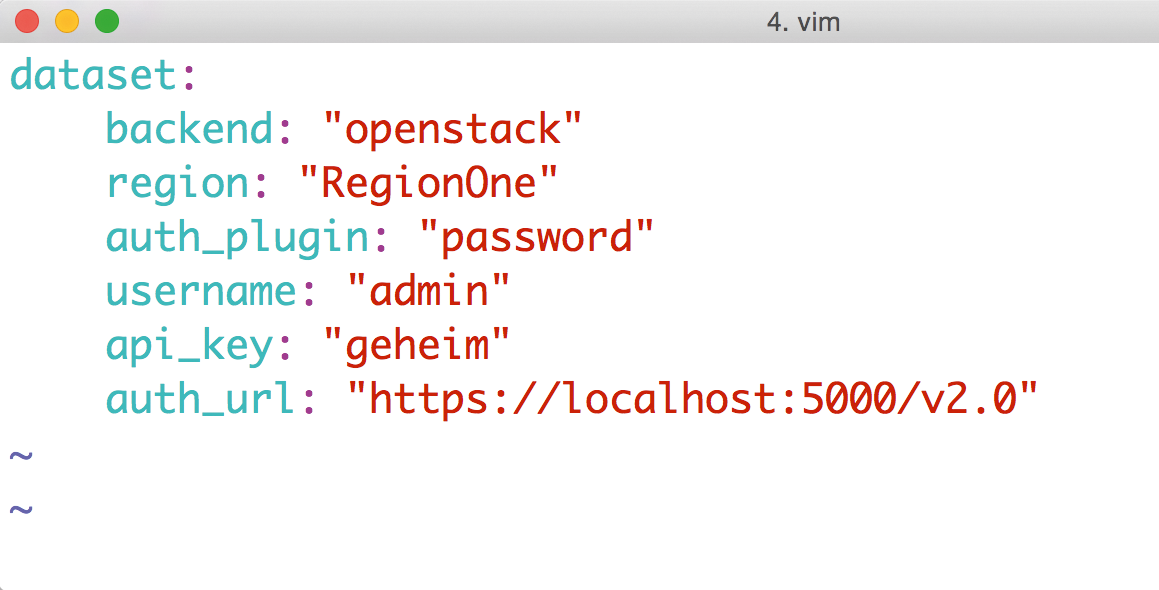
Abbildung 3: Cloud-kompatibel ist Flocker definitiv: Auf Wunsch bezieht das Tool seine Volumes aus Open Stack Cinder.
Wer EMC-Storages besitzt, freut sich schließlich über die Unterstützung für die Scale-IO- und Extreme-IO-Produkte des Herstellers. Weitere Treiber für Speicher anderer Hersteller bietet Flocker aktuell noch nicht, es scheint aber sehr wahrscheinlich, dass sich das in absehbarer Zeit ändern wird.
Flocker 1.0: Eher nicht
Was für die Major-Releases fast jeder Software gilt, gilt umso mehr für Programme aus dem sprunghaften Cloud Computing: Eine Null hinter dem Punkt bei der Versionsnummer lässt nur bedingt auf ein fertiges Produkt schließen. Flocker macht diese Erfahrung gerade am eigenen Leib. Denn die Version 1.0, die erst im Mai das Licht der Welt erblickte, erschien beim Verfassen dieses Artikels bereits in vielerlei Hinsicht veraltet. Tatsächlich hat das Flocker-Design in der vorgestellten Version nämlich eine bedeutende Schwachstelle – den halbfertigen Flottenmanager.
Das wird an zwei Stellen besonders deutlich: Einerseits verhindert der Umweg über das Flocker-CLI die nahtlose Integration mit anderen Werkzeugen wie eben Googles Kubernetes. Kubernetes kommt mit eigenen Agents daher, die sich um alle Belange von Containern kümmern wollen – inklusive des direkten Startens von Containern auf den Zielsystemen. Von Flocker hat Kubernetes aber keine Ahnung, sodass der Admin sich entscheiden muss: Entweder setzt er auf Kubernetes und verzichtet auf Flocker oder umgekehrt.
Zwar hat Cluster HQ für dieses Problem eine rudimentäre Lösung in Form eines Extensions-API für Docker gebastelt, die das Unternehmen Powerstrip nennt. Solche Eigenbrötler-Ansätze werden gerade in großen Umgebungen aber schnell zum Problem – und das Basteln wollen Admins in Setups mit möglicherweise Dutzenden Hypervisor-Hosts wohl eher vermeiden. Hinzu kommt, dass es Powerstrip [5] nie über den Status eines Proof of Concept hinaus geschafft hat. Bei Redaktionsschluss Anfang Juli war der letzte Commit vom Mai, was wenig Grund zur Euphorie bietet.
Mindestens genauso schwer wiegt außerdem, dass der Admin mit Flocker allein definitiv nicht glücklich wird. Gerade weil Flocker kein echter Flottenmanager ist, fehlen viele Funktionen schmerzlich. Die Docker-Images sind ein Beispiel: Will der Admin per Flocker auf verschiedenen Hosts Docker-Container starten, muss er zuvor händisch sicherstellen, dass alle Hosts auch tatsächlich das gewünschte Docker-Image besitzen. Selbst wenn der Admin also für Flocker und gegen andere Flottenmanager entscheiden würde, wäre das Setup so kaum nutzbar.
Die Zukunft sind Docker-Plugins
Die großen Probleme der eigenen Lösung sind wohl auch Cluster HQ nicht verborgen geblieben. Als die Docker-Entwickler auf der Dockercon die Version 1.7 von Docker vorstellten und deren wichtigste Features anpriesen, war Cluster HQ mit Flocker ganz vorne dabei: Erstmals wird Docker 1.7 (Abbildung 4) nämlich eine Architektur für Plugins besitzen, über die externe Funktionalität nachladbar ist. Und bei der Konzeption der Plugin-Architektur waren die Cluster-HQ-Entwickler direkt beteiligt. Der Lohn für die Arbeit: Für Docker 1.7 stehen mehrere Plugins vorab zur Verfügung, und eines davon ist Flocker (Abbildung 5).

Abbildung 4: Der Plugin-Architektur gehört die Zukunft: In Docker 1.7 steuert Docker den Flocker-Daemon – vorher war es umgekehrt. (Quelle: Cluster HQ)
Abbildung 5: Rege Entwicklertätigkeit beim Flocker-Docker-Plugin, das bei der Dockercon als erstes Storage-Plugin überhaupt seinen großen Auftritt hatte.
Wer Flocker per Docker-Plugin nachrüstet, dreht die Kommandohierarchie in seiner Cloud um: Fortan steuert Docker dann Flocker. Der Admin startet also beispielsweise einen Container mit angehängtem Volume und Docker ruft dazu im Hintergrund das Flocker-Plugin auf. Aus Admin-Sicht bleibt das Flocker-API selbst außen vor, ein Docker mit Flocker lässt sich genauso bedienen wie ein normales Docker – und verhält sich auch identisch.
Der unschlagbare Vorteil dabei ist, dass sämtliche externen Flottenmanager wie Kubernetes oder Docker Swarm von Flocker gar nichts zu wissen brauchen. Auch für die Entwickler zahlt sich diese Lösung aus, denn sie halten ihren Code vollständig rein von Hacks für spezifische Anbauteile. Die neue Plugin-Architektur in Docker 1.7 ist also ein echter Gewinn für alle.
Damit gilt: Wer Flocker schon jetzt aktiv nutzen will, nimmt Flocker 1.0 und kombiniert es mit Docker 1.6. Dann ist die Nutzung des Flocker-CLI jedoch obligatorisch. Wer aber noch etwas warten kann, der freut sich lieber auf Docker 1.7 – dann mit dem Flocker-Plugin – und erhält eine in jeder Hinsicht deutlich rundere Lösung.
Wer Flocker ausprobieren möchte, kann das übrigens relativ leicht tun: Es spricht nichts dagegen, erste Gehversuche in Cloud-VMs oder lokalen VMs zu unternehmen. Außerdem stehen auch schon fertige Vagrant-VMs zur Verfügung.
Fazit
Flocker ist im Container-Hype eine ausgesprochen erfrischende Neuerung [6]. Die Entwickler von Cluster HQ wischen mit ihrem Produkt mal eben eine der größten Fehlannahmen vom Tisch, die sich im Dunstkreis von Cloud und Containern eingenistet hat: Nicht jede VM lässt sich nämlich mitsamt ihren Daten zu jedem beliebigen Zeitpunkt aus frischen Quellen neu erstellen. Doch auch Dienste mit persistenten Daten, dazu gehören beispielsweise die Datenbanken, haben in Clouds und in Container-Setups eine eigene Existenzberechtigung. Ja mehr noch, sie sind dort praktisch unvermeidlich.
Dank Flocker gibt es nun die Möglichkeit, Dienste mit persistenten Daten künftig auch unter Docker in Containern zu betreiben. Wenn Flocker den Umbau beendet hat, in dem es sich zurzeit durch die Wandlung zum Docker-Plugin noch befindet, wird die Lösung sicherlich sehr schnell an Popularität gewinnen. Cluster HQ: Alles richtig gemacht.
Infos
- Cluster HQ: http://www.clusterhq.com/
- Docker-Volumes: https://docs.docker.com/userguide/dockervolumes/
- Konfigurationsdateien: https://docs.clusterhq.com/en/1.0.1/using/config/configuration.html
- Backend-Storages: https://docs.clusterhq.com/en/1.0.1/introduction/index.html#supported-storage-backends
- Powerstrip: https://github.com/ClusterHQ/powerstrip
- Installation: https://docs.clusterhq.com/en/1.0.1/using/installing/index.html





