
© xtockimages, 123RF
Bei Big Data ist Apache Hadoop aktuell der Liebling des Marketings. Doch das Setup einer vollständigen Hadoop-Umgebung ist nicht einfach. Open Stack Sahara verspricht dagegen Hadoop auf Knopfdruck.
Hadoop ist eines der Buzzwörter aus dem Kontext des Cloud Computing. Die Big-Data-Anwendung gehört deshalb in dieses Reich, weil skalierbare Cloudumgebungen wie für sie gemacht erscheinen. Hadoop bringt obendrein beste Referenzen mit: Das Werkzeug setzt auf Map Reduce von Google [1] und weiß damit einen ausgesprochen potenten Algorithmus an seiner Seite. Zudem ist der Entwickler der Apache-Suche Lucene, Doug Cutting, auch der Erfinder von Hadoop – an Vorschusslorbeeren mangelt es dem Projekt also nicht.
Komponenten-Wirrwarr
Doch wie bei so vielen Komponenten aus dem Cloud-Dunstkreis kursiert auch in Sachen Hadoop viel Halbwissen. So haben viele Admins den Begriff Hadoop zwar schon einmal gehört, können sich aber – von Big Data einmal abgesehen – gar keine Vorstellung davon machen, worum es eigentlich geht. Fest steht: Hadoop ist ein ausgesprochen komplexes Gebilde, das sich aus mehreren Diensten und diversen Erweiterungen zusammensetzt. Das Herz der Applikation besteht aus zwei Teilen:
- Das Hadoop Distributed File System (HDFS) ist ein spezielles, skalierbares Dateisystem. Es zeichnet sich durch die inhärente Hochverfügbarkeit aus und funktioniert im Wesentlichen wie ein objektbasierter Speicher (zum Beispiel Ceph, das mittlerweile auch als Ersatz für HDFS auftreten kann).
- Der Map-Reduce-Algorithmus stammt aus dem Hause Google. Letztlich geht es bei Big Data meist darum, genau jene Daten aus einem großen Pool zu fischen, die für den jeweiligen Einsatz am sinnvollsten zu sein scheinen. Map und Reduce sind dabei zwei Funktionen innerhalb von Hadoop, die genau diesem Zweck dienen. Die Details zum Algorithmus finden sich unter [1].
Zu den beiden Kernbestandteilen gesellen sich mehrere Komponenten, die zwar nicht zwingend nötig sind, aber in die Kategorie “Nice to have” passen:
- Hbase bietet die Möglichkeit, Daten aus einem Hadoop-Cluster in Form einer Datenbank der Außenwelt anzubieten.
- Hive bietet Data-Warehouse-Funktionalität, sodass sich die in Hadoop abgelegten Daten nicht nur durchforsten, sondern auch katalogisieren lassen, wobei eine SQL-ähnliche Syntax zum Einsatz kommt.
Die Liste ist freilich nicht vollständig; offizielle wie inoffizielle Erweiterungen zu Hadoop gibt es für nahezu jede erdenkliche Aufgabe. Seit der ersten Hadoop-Version 2008 hat die Software eine steile Karriere hingelegt.
Komplexität
Viel Funktionalität bedingt hohe Komplexität. Hadoop bildet da keine Ausnahme: Vom Plan, Hadoop zu installieren, bis hin zur nutzbaren Installation sind viele Arbeitsschritte zu absolvieren. Schneller geht es, wenn der Admin Zugriff auf ein gut vorbereitetes Open Stack hat: Die Open-Stack-Komponente Sahara [2] offeriert Hadoop-as-a-Service. Per Mausklick, so das Versprechen, klickt sich der Admin eine komplette Hadoop-Umgebung zusammen, die kurze Zeit später auch tatsächlich einsatzbereit sein soll.
Da stellen sich gleich mehrere Fragen: Hat der Admin auch dann etwas von Hadoop, wenn er sich mit der Lösung im Vorfeld gar nicht eingehend beschäftigt hat? Funktioniert Sahara überhaupt – und lässt sich mit der Hadoop-Installation, die Sahara produziert, tatsächlich sinnvoll arbeiten? Das Linux-Magazin hat Sahara getestet.
Bewegte Geschichte
Sahara hat diesen Namen noch gar nicht so lange, anfangs firmierte Sahara als Savanna. Doch die Entwickler mussten sich einen neuen Namen für ihr Projekt suchen, weil sie befürchteten, es könnte einen Rechtsstreit um den Namen geben. Das ist insofern kurios, als schon die SDN-Komponente in Open Stack einen ähnlichen Werdegang hinter sich hat: Aus Quantum musste dort bereits vor Jahren Neutron werden.
Stringenter als der Name ist das Ziel von Sahara: Das Programm fragt Anwender zunächst nach einigen grundlegenden Parametern hinsichtlich der Konfiguration des künftigen Hadoop-Clusters. Hat der Admin kundgetan, welche Art von Hadoop-Cluster ihm vorschwebt, soll Sahara sich – so die Theorie – an die Arbeit machen und dem Anwender letztlich einen kompletten Cluster mit Hadoop schlüsselfertig übergeben.
Wer sich schon einmal mit Open Stack näher beschäftigt hat, kriegt an dieser Stelle möglicherweise Schnappatmung: Genau mit diesen Voraussetzungen geht schließlich auch Trove ans Werk, das eine automatische MySQL-Installation in Open Stack ermöglichen soll.
Die Realität ist, dass Trove ein kleines Feature-Set nicht besonders intelligent umsetzt. Kritikpunkte sind dabei neben dem wackeligen Trove-Agent, der in Vanilla-VMs startet und dort MySQL kommissionieren soll, auch Performance- und Sicherheitsaspekte. Von Anfang an bekommt Trove vorgeworfen, dass es wenig Funktionalität bietet, dafür aber sehr komplex daherkommt.
Soviel vorweg: Bei Sahara haben sich die Projektentwickler deutlich mehr Gedanken über eine sinnvolle Architektur gemacht.
Diverse Komponenten
Wie fast alle anderen Open-Stack-Dienste kommt Sahara in Form mehrerer Komponenten daher (Abbildung 1). Das Kernprojekt besteht aus einer Applikation für die Authentifizierung, einer Provisionierungs-Engine, einer eigenen Datenbank für Betriebssystemimages, einem Jobscheduler für Elastic Data Processing (EDP) und den Plugins, über die sich verschiedene Hadoop-Geschmacksrichtungen starten lassen. Dazu gesellen sich ein Sahara-Kommandozeilenclient und eine Erweiterung von Horizon, damit Admins Sahara-Dienste auch über das Open-Stack-Dashboard nutzen können (Abbildung 2). Freilich darf auch – ganz der Philosophie von Open-Stack folgend – ein API auf Restful-Basis nicht fehlen.
Abbildung 1: Sahara ist ein komplexes Gebilde aus mehreren Komponenten, die wichtigsten zeigt diese Grafik.
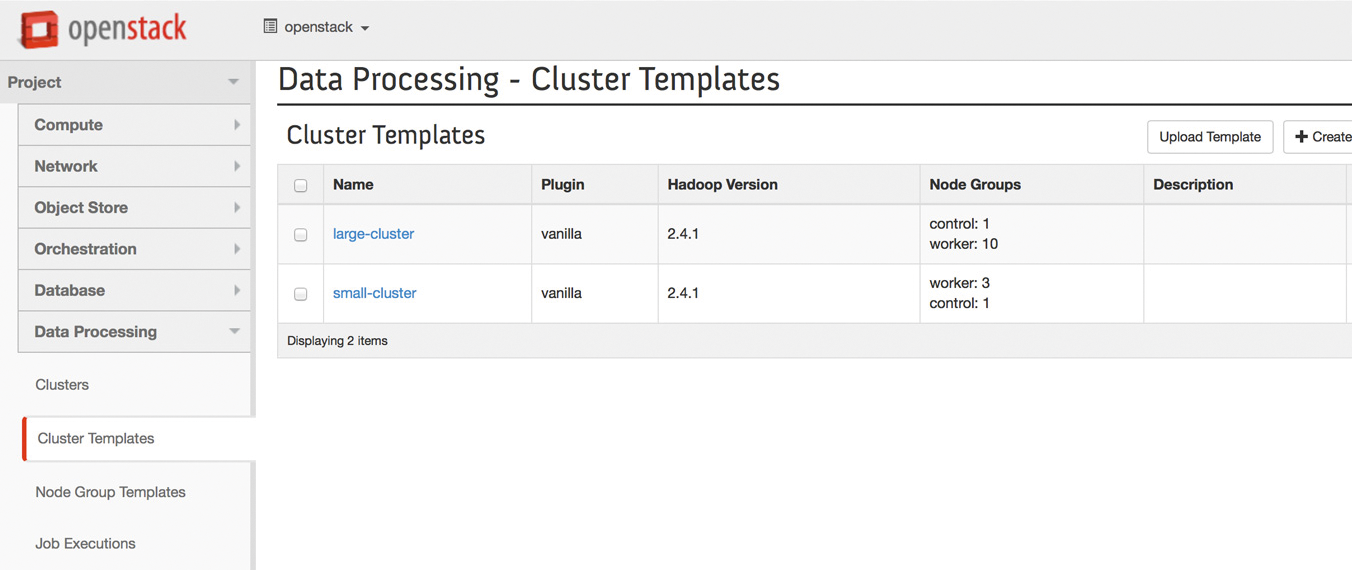
Abbildung 2: Unter dem Menüpunkt »Data Processing« sind in Horizon die Hebel für Sahara versteckt – wenn der Admin die Zusatzseiten installiert.
Begriffswirrwarr
Wie ebenfalls typisch für Open Stack wirft Sahara mit einer Unmenge Begriffe um sich, die es außerhalb des Sahara-Kontexts nicht oder mit anderer Bedeutung gibt. Will der Admin den Überblick behalten, muss er sich an die Nomenklatur von Sahara gewöhnen.
Von zentraler Bedeutung ist beispielsweise der Begriff Cluster: Als solche gelten in Sahara alle virtuellen Maschinen, die zu einer Sahara-Installation gehören. Das umfasst die Sahara-Controller wie die Worker. Wieder zwei neue Begrifflichkeiten: Sahara unterteilt Hadoop-Installationen in Knoten, auf denen spezifische Dienste laufen. Der Master betreibt den Sahara-Name-Node, der als Metadatenserver fungiert. Die Core Worker enthalten tatsächlich Daten und lassen auch einen Tasktracker laufen, der vom Masterknoten Befehle annimmt. Einfache Worker verarbeiten nur Daten und holen sich die von den Core Workers.
Zur Erinnerung: Hadoop nutzt als zentrale Komponente HDFS als Dateisystem, das für den HPC-Einsatz ausgelegt ist: Die Daten sind auf die vorhandenen Knoten der Installation (die Core Worker) verteilt. Weil es aber eine Instanz im Cluster geben muss, die jederzeit weiß, welche Daten wo liegen, ist der Master mit dem Name-Node ausgestattet – gewissermaßen ein Cluster-weiter Server für die Metadaten von HDFS.
Sahara denkt also nicht mehr in der Dimension einzelner VMs – schließlich handelt es sich um einen beliebig skalierbaren Rechencluster. Die genannten Gruppen treten an die Stelle einzelner VMs. Startet der Admin also einen Cluster per Sahara, führt das automatisch zum Start der drei Gruppen Master, Core Worker und Worker. Wie viele VMs zu diesen Gruppen gehören, legt Sahara auf Zuruf des Admin zur Laufzeit dynamisch fest und passt die Anzahl später auf Wunsch automatisch an.
Intelligentes Provisioning
Warum hat es den Anschein, als seien viele Komponenten doppelt vorhanden, und zwar in Sahara wie auch in Open Stack selbst? In Form von Keystone existiert schließlich schon eine Benutzerverwaltung und Heat ist die Open-Stack-eigene Engine für Templates, die augenscheinlich mit der Provisioning Engine nachgebildet wird.
Der zentrale Dreh- und Angelpunkt in Sahara ist definitiv die Provisioning Engine, also der Teil, der Hadoop-Umgebungen tatsächlich startet. Ohne ihn geht bei Sahara gar nichts. Setzt der Admin per Webinterface oder CLI etwa den Befehl ab, einen Hadoop-Cluster zu starten, so schlägt das Kommando zuerst bei der Provisioning Engine auf und wird dann dort weiterverarbeitet.
Der Dienst hat mehrere Aufgaben: Zunächst interpretiert er die Eingabe des Nutzers. Ganz gleich, ob dieser den Befehl grafisch oder auf der Kommandozeile abgesetzt hat – sein Kommando enthält einige Konfigurationsparameter, die Sahara steuern (Abbildung 3). Selbst wenn er die nötigen Parameter nicht selbst angibt, ersetzt das Sahara-Plugin für Horizon oder das CLI sie durch passende Defaults. Die wichtigsten beschreiben die Hadoop-Distribution und die darunterliegende Linux-Distribution. Auch legt der Admin per Befehl an Sahara die Topologie des Clusters fest, bestimmt also, wie viele Knoten die einzelnen Gruppen anfänglich haben sollen.
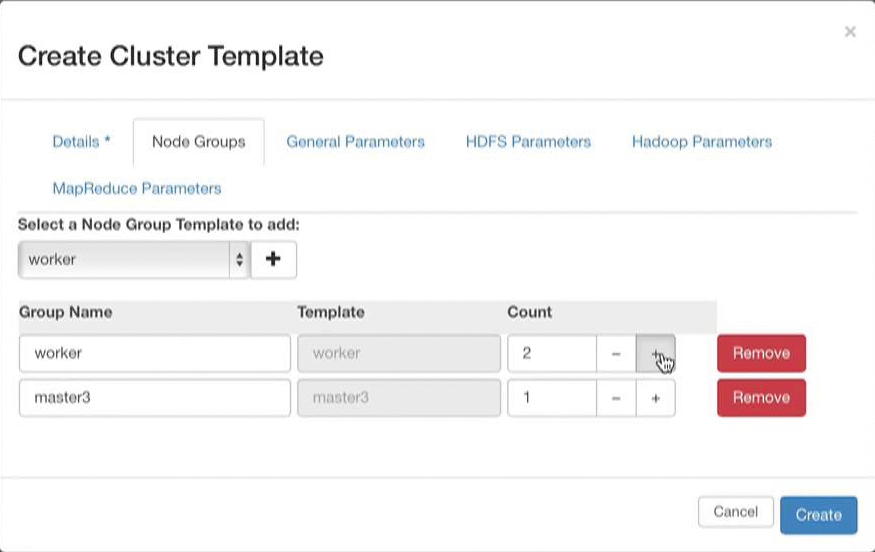
Abbildung 3: Wer selbst ein Template für einen Hadoop-Cluster bauen möchte, findet im Dashboard die passenden Parameter.
Dann geht die Party los: Der Provisioning Scheduler ist dafür verantwortlich, die notwendigen Befehle an die anderen Open-Stack-Dienste zu leiten. Das umfasst die Open-Stack-Authentifizierung Keystone und den Image-Dienst Glance. Sahara implementiert folglich keinen Keystone-Ersatz. Der Dienst, der in Sahara die Authentifizierung abwickelt, greift auf Keystone zurück. Ähnliches gilt für die Sahara-eigene Image-Registry: Sie fußt auf den Funktionen von Glance, rüstet aber beim Image-Management Hadoop-spezifische Funktionen nach, die in Glance fehlen.
Auch die Provisioning Engine selbst produziert nicht unnütz doppelten Code. Weiter oben war bereits die Rede von den verschiedenen Gruppen, die zu einem Hadoop-Cluster gehören (Master, Core Workers, Workers). Heat, das in Open Stack eigentlich für zentrale Orchestrierung verantwortlich zeichnet, kennt diese Einteilung aber nicht. Ein per Heat aufgesetzter Verbund von VMs (Stack) geht stets davon aus, dass der Admin einzelne VMs per Template definiert und dann durch Heat starten lässt.
Damit Heat und die Provisioning Engine von Sahara sinnvoll miteinander reden können, enthält Letztere einen eingebauten “Dolmetscher”: Aus Sahara fallen am Ende tatsächlich die Templates heraus, mit denen Heat arbeiten kann. Aus Sicht des Admin hingegen genügt es, in Sahara selbst Templates anzulegen, die einen Hadoop-Cluster grundsätzlich beschreiben. Den Rest erledigt Sahara intern.
Geschmäcker sind verschieden
Hadoop ist die Bezeichnung einer konkreten Umsetzung von Googles Map-Reduce-Algorithmus – nämlich des originalen Hadoop des Apache-Projekts. In den vergangenen Jahren haben allerdings gleich mehrere Anbieter damit begonnen, den Nutzern eigene Hadoop-Distributionen zu kredenzen. Das ist ähnlich wie bei Linux-Distributionen selbst: Im Kern steckt zwar immer Apaches Hadoop, doch wird es um verschiedene Patches erweitert und dem Nutzer zusammen mit allerlei nützlichen und nutzlosen Erweiterungen geliefert.
Bei der Arbeit an Sahara mussten die Entwickler sich also entscheiden, ob sie nur das originale Hadoop unterstützen oder ob sie auch Support für andere Hadoop-Implementierungen liefern wollen. Herausgekommen ist die zweite Variante: Über Plugins lässt sich Sahara so erweitern, dass es wahlweise die originale Hadoop-Variante ausliefert oder eine andere, etwa die von Hortonworks oder von Cloudera.
Dadurch wird Sahara sehr flexibel: Je nach Setup kann der Admin sogar festlegen, dass mehrere Plugins gleichzeitig aktiv sind. Dem Nutzer selbst bleibt dann die Wahl, welche Geschmacksrichtung er bevorzugt.
Analytics-as-a-Service
Bis hierher bezog sich der Artikel auf Saharas Fähigkeiten, Cluster mit Hadoop zu starten. Allerdings beschränken sich die Fähigkeiten von Sahara nicht auf diesen Arbeitsschritt. Im Hintergrund implementiert das Tool nämlich ein umfassendes Jobmanagement für Hadoop. Im Grunde will Sahara also als Komponente von außen wissen, was in den VMs mit Hadoop passiert. Der Nutzer würde in diesem alternativen Modus selbst auch keine VMs mehr starten.
Um die Sahara-Funktionalität, die dessen Entwickler als Analytics-as-a-Service beschreiben, sinnvoll zu nutzen, würde er stattdessen den Rechenjob selbst bei Sahara direkt anmelden. Dazu legt er einige Parameter fest: Zu welcher der in Hadoop vorgegebenen Kategorien gehört die Aufgabe? Welches Skript soll bei der Aufgabe ausgeführt werden und woher bekommt Hadoop die passenden Daten? Wo soll Sahara die Ergebnisse der Berechnungen ablegen und wo die Logs?
Sobald Sahara die Werte kennt, kümmert es sich um den Rest danach automatisch: Es startet also einen Hadoop-Cluster, führt die entsprechenden Aufgaben darin aus und stellt dem Admin am Ende nur noch das Resultat dieser Berechnungen zur Verfügung. Mittels EDP (Elastic Data Processing) hat der Admin die Option, Sahara die fertigen Ergebnisse in einem Objektspeicher nach Open-Stack-Swift-Standard ablegen zu lassen.
Im Grunde zieht Sahara bei dieser Form der Arbeit neben dem Layer zum Starten von VMs einen zweiten Layer der Abstrahierung zwischen Nutzer und Software ein – die Nutzung von Hadoop ist für den Admin damit selbst dann möglich, wenn der sich mit den Hadoop-Details gar nicht auseinandersetzen möchte.
Saharas langer Arm in die VM
Damit Sahara innerhalb der Hadoop-VMs die Dienste so konfigurieren kann, dass am Ende ein funktionierendes Hadoop entstanden ist, muss es vorrangig in den VMs arbeiten. Die Entwickler sind dem Vorbild von Trove und anderen Diensten dieser Art gefolgt und realisieren die Konfiguration mit einem entsprechenden Agent. Damit die Magie funktioniert, muss der Admin sich ein entsprechendes Basis-Image für die Sahara-Nutzung besorgen oder entlang der Anleitung unter [3] selber bauen.
Der Agent löste 2014 den alten und bis dahin genutzten Mechanismus ab, bei dem das Skript »cloud-init« einen SSH-Server konfigurierte, den Sahara dann von außen ansprach. Die Agent-Lösung ist viel eleganter – und schließt obendrein das Einfallstor, das für eingehende SSH-Verbindungen hin zu Hadoop-VMs vorher offen sein musste.
Und anders als zum Beispiel bei Trove steuert der Sahara-Agent einen echten Mehrwert bei: Während sich beispielsweise ein MySQL noch einigermaßen leicht selbst installieren und konfigurieren lässt, ist das bei Hadoop nicht so. Bei Sahara zahlt sich der Agent also tatsächlich aus.
CLI oder Dashboard?
Wie jeder Open-Stack-Dienst haben Nutzer bei Sahara zwei Möglichkeiten, die Dienste der Software zu beanspruchen. Möglichkeit eins führt über Horizon (Abbildung 4), also das Open-Stack-Dashboard. Hier ist für Admins im Moment aber noch Handarbeit angesagt, denn ordentlich als Paket verfügbar sind die nötigen Dateien noch nicht. Auch sind die Sahara-Komponenten nicht Bestandteil des offiziellen Dashboard.
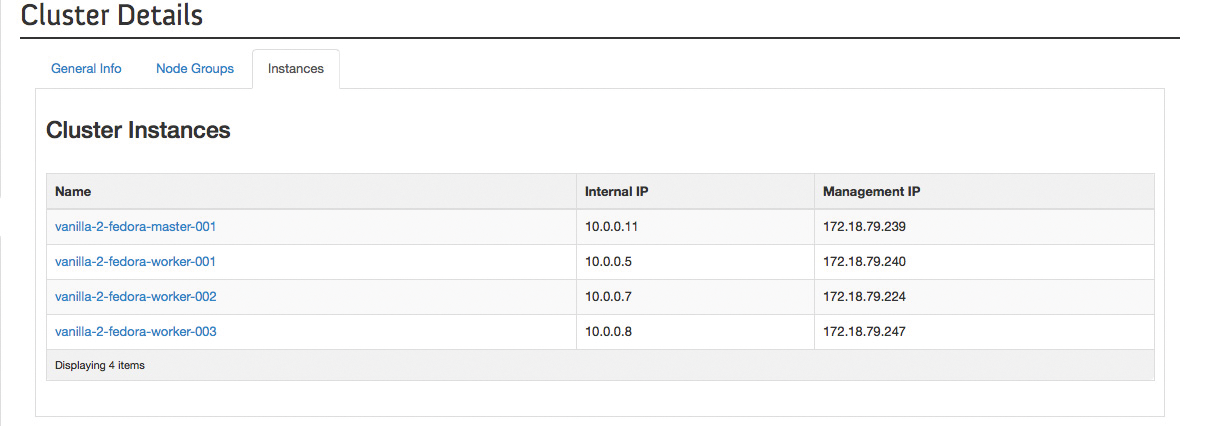
Abbildung 4: Die Sahara-Seiten im Open-Stack-Dashboard liefern schnell die Informationen, welche Knoten zu einem Sahara-Cluster gehören.
Weniger umständlich ist wie üblich der Kommandozeilenclient: Dem Beispiel der anderen Open-Stack-Dienste folgend existiert ein »python-saharaclient« , der alle wichtigen Operationen auf der Kommandozeile erlaubt. Gleichzeitig ist es auch möglich, die entsprechende Python-Bibliothek aus anderen Skripten heraus zu nutzen – wer auf Programmierebene Zugriff auf Sahara haben will, ist hier also an der richtigen Stelle.
Automatisches Skalieren
Die Provisioning Engine von Sahara kann deutlich mehr, als nur VMs für den Betrieb neuer Hadoop-Installationen starten. Die Arbeit mit Hadoop ist allerdings – je nach Umfang des durchzuackernden Materials – rechen- und speicherintensiv. Naturgemäß wollen Unternehmen aber nur so wenig Geld wie irgend möglich ausgeben.
Einerseits könnten Admins also ihre Hadoop-Cluster schon beim Start mit so vielen virtuellen CPUs und virtuellem Speicher versehen, dass es sicher reicht, um die anstehenden Tasks gut abzuarbeiten. Andererseits bekommen Hadoop-Cluster regelmäßig neue Aufgaben zugewiesen. Um den dynamischen Zuwachs abzufangen, müssten Admins ständig mehr virtuelle Ressourcen einbinden, als anfangs notwendig sind – doch verstieße das gegen das Effizienzgebot.
Sahara ist daher ab Werk mit der Fähigkeit ausgestattet, automatisch die Anzahl von VMs in Hadoop-Clustern zu modifizieren. Das geschieht nach Faktoren, die der Admin festlegt. So könnte er Hadoop dazu bringen, mehr Worker zu starten, wenn auf den vorhandenen Workern die Last – ausgelesen aus Faktoren wie der CPU-Nutzung der einzelnen Instanzen – eine bestimmte Grenze überschreitet. Hadoop skaliert den Cluster also nach Bedarf selbst.
Das klappt auch dann, wenn der Admin Analytics-as-a-Service nutzt: Dabei legt er nur eine Grenze fest, die im Hinblick auf die Zahl der Instanzen und deren genutzte Ressourcen nicht zu überschreiten ist (Abbildung 5). Um alles andere kümmern sich Sahara und die integrierte Provisioning Engine selbst.
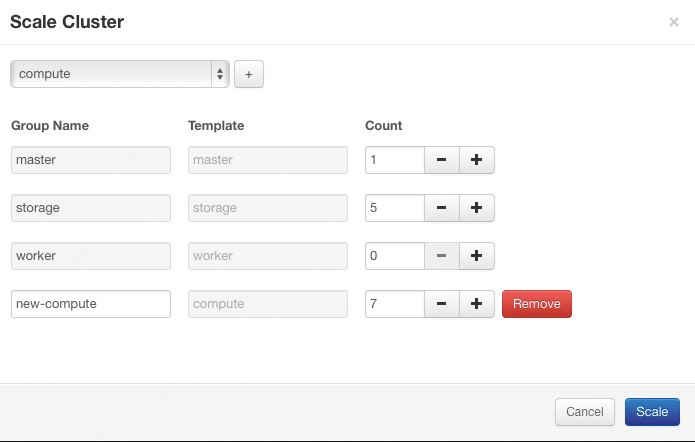
Abbildung 5: Ein Cluster lässt sich in Sahara entweder durch den Admin von Hand skalieren oder automatisch im Analytics-as-a-Service-Modus.
ISPs, die bereits eine Open-Stack-Plattform betreiben und planen in diese Sahara zu integrieren, sollten das Thema Hardware klug angehen. Damit ist klar: Um Hadoop sinnvoll zu betreiben, benötigen Kunden viel einsetzbare Leistungsfähigkeit – und das sowohl im Hinblick auf CPU und RAM wie auch im Hinblick auf das Netzwerk. Denn ein Hadoop-Cluster ist sehr Netzwerk-intensiv, auch Gigabit-Links lassen sich de facto ohne große Schwierigkeiten saturieren.
Hardware für Sahara
Damit steht zweifellos fest: Wer Hadoop als Service anbieten möchte, greift zu den größeren CPUs, zu vielen RAM-Riegeln und idealerweise auch zu schnellen 10-GBit-Netzwerkkarten. Das allein genügt aber noch nicht – wirklich schnell wird Hadoop erst, wenn es lokalen, schnellen Speicher nutzen kann.
Zur Erinnerung: Die Default-Konfiguration von Open Stack packt persistente VMs auf Speicher, der im Hintergrund per I-SCSI angebunden ist. Technisch ist das wenig elegant, aber vor allem ist es sehr langsam. Alternativen mit hohen Durchsatzraten gibt es etwa in Form von Ceph. Die meisten Alternativen haben gemein, dass sie mit einer eher hohen Latenz daherkommen, weil die Pakete stets durchs Netzwerk müssen.
Lokaler Speicher schafft Abhilfe: Läuft die VM auf dem Host und nutzt den lokalen Speicher des Systems, entfällt der Umweg über das Netzwerk. Bis zur aktuellen Open-Stack-Release Kilo konnte Open Stack den Zusammenhang zwischen einer VM und einem mit Cinder erstellten Speicher aber nicht abbilden. Admins konnten sich also aussuchen, ob sie eine VM auf persistentem Netzwerkspeicher betreiben wollten oder lokal auf den einzelnen Hypervisors, dann aber nicht persistent.
In Kilo haben die Entwickler eine lange gewünschte Funktion nachgerüstet, von der auch Sahara profitiert: Nun lässt sich nämlich festlegen, dass Cinder ein Volume auf dem Host anlegen soll, auf dem auch die virtuelle Maschine startet. Um das Thema Hochverfügbarkeit muss sich der Storagetreiber in Cinder dann zwar selbst kümmern, über den Umweg über DRBD 9 beispielsweise sollte das aber machbar sein.
Fazit
Cloud und Big Data, das passt eigentlich wie die Faust aufs Auge. Letztlich sind es gerade die großen HPC-Setups, die den Siegeszug des Cloud Computing erst mit eingeleitet haben. Dass Anbieter große Mengen an Ressourcen zur Verfügung stellen, um Kunden den dynamischen und flexiblen Hadoop-Betrieb zu ermöglichen, ist jedenfalls ein sehr schlüssiger Ansatz. Die Cloud spielt hier besonders den Vorteil aus, dass der Kunde die Leistung sofort bekommt, statt sich erst umständlich einen Hardware-Zoo ins Rack zu hängen.
Erfreulich ist, dass die Sahara-Entwickler viele Probleme früherer Zeiten gelöst haben. Der Umstand, dass sich eine VM genau dort starten lässt, wo auch das per Cinder provisionierte Volume liegt, macht Hadoop überhaupt erst sinnvoll nutzbar. Denn nur mit schnellem Speicher funktioniert Hadoop brauchbar.
Doch bleibt ein großer Wermutstropfen: Aktuell gibt es – gerade im deutschsprachigen Raum – nur wenige Anbieter, die überhaupt öffentlich zugängliche Open-Stack-Clouds betreiben. Und die, die das tun, unterstützen Hadoop nur in den seltensten Fällen, bieten Sahara also gar nicht erst an. Derzeit gibt es – von einer Selbstbau-Cloud abgesehen – also kaum die Möglichkeit, die eigentlich sehr nützliche Funktionalität von Hadoop im Alltag zu nutzen.
Das ist schade: Fände sich ein Anbieter, der Sahara im Portfolio hat, er könnte sich wohl auf den Ansturm von zahlreichen Kunden verlassen.
Infos
Der Autor

Martin Gerhard Loschwitz arbeitet als Cloud Architect bei Sys Eleven. Er beschäftigt sich dort intensiv mit den Themen Open Stack, Distributed Storage und Puppet. Außerdem pflegt er in seiner Freizeit Pacemaker für Debian.





