
© Bruce Rolff 123RF
Kritiker, die Hadoop totsagen wollen und Apache Spark hochleben lassen, handeln voreilig. Hadoop 2 ist dem Status einer einfachen Anwendung entwachsen und zur Big-Data-Plattform gereift. Eine Bestandsaufnahme abseits des Big-Data-Hype.
Über Big Data sprechen – das erfordert immer erst eine Definition dessen, was mit Big Data gemeint ist. Der Begriff ist in erster Linie Marketing-Geschwurbel mit entsprechend vielen Bedeutungen und Interpretationen, vergleichbar Begriffen wie “hoher Berg” oder “schnelles Auto”. Eine weitere Voraussetzung ist die Erläuterung des Konzepts hinter dem Data Lake. Letzterer ist weniger Buzzword und anschaulicher als Big Data. Der Artikel soll erklären, warum Hadoop 2 mehr ist als eine Map-Reduce-Engine, und auch, wie Spark sich nahtlos in das Hadoop-Ökosystem einfügt.
Die Begriffe
Wie der Name vermuten lässt, geht es bei Big Data um die Bearbeitung großer Datenmengen, gerne in Petabytes gemessen. Wikipedia definiert einige Charakteristika von Big Data [1], die im Folgenden als Basis dienen:
Menge: Big Data wird durch die große Menge klar definiert. In manchen Fällen macht es die schiere Menge der Daten unmöglich, sie mit herkömmlichen Methoden zu bearbeiten.
Vielfalt: Die Daten können von verschiedenen Quellen stammen, die nicht zwingend miteinander zu tun haben.
Geschwindigkeit: Im Zusammenhang mit Big Data ist das die Größe dafür, wie schnell die Daten entstehen und bearbeitet werden können.
Variabilität: Die Daten können variabel, unvollständig oder inkonsistent sein.
Komplexität: Die Verbindungen zwischen den Datenquellen müssen nicht vollständig klar und für traditionelle relationale Methoden zugänglich sein.
Big Data kann auch kleiner
Unternehmen und Organisationen können nun zwar einige der oben genannten Ansprüche an die Datenverarbeitung entwickeln und trotzdem keinen Bedarf an der Verarbeitung übergroßer Datenmengen haben. Die Annahme, dass alle Firmen auf Petabytes von Daten sitzen, ist eben nicht notwendigerweise wahr. Im Blogpost “Big Data Surprises” [2] liegt laut den dort betrachteten Erhebungen die Einstiegsgrenze zu Big Data bei 110 GByte. Die Datenmenge, die ein durchschnittliches Unternehmen zu stemmen hat, beträgt laut diesen Analysen zwischen 10 und 30 Terabyte.
Der Artikel “Nobody Ever got Fired for Using Hadoop on a Cluster” [3] weist auf mindestens zwei Analyse-Cluster von Microsoft und Yahoo hin, die auf einen mittleren Input von weniger als 14 GByte pro Job kommen. Die Input-Größe von 90 Prozent der Jobs auf einem Facebook-Cluster liege bei weniger als 100 GByte, heißt es dort weiter.
Eine bessere Beschreibung für Big Data Processing wäre in dem Fall High Performance Data Processing (HPDP), weil die zuvor genannten Charakteristika High Performance Computing benötigen, um ihr Ziel zu erreichen. Diese Bezeichnung ist wiederum dem High Performance Technical Computing (HPTC) ähnlich, das oft als HPC oder Supercomputing bezeichnet wird. Es ließe sich argumentieren, dass HPDP und HPTC das Gleiche sind oder zumindest große Überlappungen aufweisen. Aktuell sei die Diskussion aber auf HPDP eingegrenzt.
Die Tiefen des Data Lake
Ein in den Charakteristika nicht genanntes, aber impliziertes Feature ist das Konzept des zentralen Speicherdepots. Obwohl nicht alle Daten in relationalen Datenbanken zugänglich sind, müssen sie in einer Rohform gespeichert sein. Diese Charakteristik ist es, die HPDP meist von traditionelleren Methoden unterscheidet. Meist als Data Lake bezeichnet steckt dahinter die Idee, ein großes Repository für alle Daten zu schaffen und es nach Bedarf zu nutzen.
Der Ansatz lässt sich dem der traditionellen relationalen Datenbank oder dem Data Warehouse gegenüberstellen: Daten dort hinzuzufügen heißt, sie in ein vorgegebenes Schema zu transformieren, bevor sie in die Datenbank passen. Diesen Schritt bezeichnet in der Regel der Begriff Extract, Transform and Load (ETL), und der kann teuer und zeitfressend sein. Noch bedeutsamer ist der Umstand, dass Entscheidungen, wie die Daten später genutzt werden sollen, bereits bei diesem Schritt fallen müssen. Außerdem gehen bei ETL-Prozess eventuell auch Daten oder Datenbestandteile verloren, die nicht ins Schema passen.
Hadoop dagegen fokussiert darauf, Daten im Rohformat zu nutzen. Im Wesentlichen wird das, was sich als eine Art ETL-Schritt ansehen lässt, erst ausgeführt, wenn Hadoop-Applikationen darauf zugreifen. Dieser Schema-beim-Lesen-Ansatz ermöglicht es Programmierern und Nutzern, je nach Bedarf eine Struktur beim Zugriff zu erzwingen. Der traditionelle Ansatz des Data Warehouse, das Schema-beim-Schreiben, erfordert dagegen Vorausplanung und Annahmen darüber, wie die spätere Datennutzung eventuell aussehen soll.
Bezogen auf Big Data bietet das Data-Lake-Konzept drei Vorteile gegenüber dem traditionellen Ansatz:
- Alle Daten sind verfügbar, ohne Annahmen zur künftigen Verwendung treffen zu müssen.
- Die Daten sind teilbar. Verschiedene Geschäftsfelder oder Forschungszweige können alle verfügbaren Daten nutzen ohne Zugangsbeschränkungen (Kompartimentalisierungseffekte) wegen nicht zueinander passender Systeme.
- Alle Zugangsmethoden sind verfügbar. Jede Datenverarbeitungs-Engine lässt sich nutzen, um die Daten zu erforschen, etwa Map-Reduce, Graph Processing und In-Memory-Tools.
Um keine Missverständnisse aufkommen zu lassen: Hadoop ist nicht auserkoren, um Data Warehouse zu ersetzen. Data Warehouse ist ein geschätztes Businesstool. Dennoch fand die Entwicklung der Data-Warehouse-Technologie vor der Zeit statt, als sich der Data Lake zu füllen begann. Die wachsende Zahl von neuen Datenströmen aus nicht zusammenpassenden Quellen wie sozialen Netzen, Sensoren und Click-Trails fließt in diesen Datensee.
Die Wahl zwischen Hadoop und Data Warehouse lässt sich als Entweder-oder-Entscheidung bezeichnen. Ein Hauptkritikpunkt an Hadoop ist die langsame Batch-Charakteristik der Map-Reduce-Jobs. Bedenken gegenüber der Performance von Hadoop sind bei Version 1 teils gerechtfertigt, doch zeigt sich Hadoop 2 – wie später näher ausgeführt – als flexiblere und besser erweiterbare Plattform.
Die Unterschiede zwischen traditionellem Data Warehouse und Hadoop zeigt Abbildung 1 schematisch. Das Schaubild zeigt, wie verschiedene Daten in den ETL-Prozess oder den Data Lake gelangen. Der ETL-Prozess platziert die Daten in Schemata, um sie in der relationalen Datenbank zu speichern (Write). Nutzt eine Hadoop-Anwendung die Daten, wendet sie das Schema beim Lesen (Read) der Daten aus dem Data Lake an. Gezeigt ist auch das mögliche Verwerfen von Daten während des ETL-Prozesses.
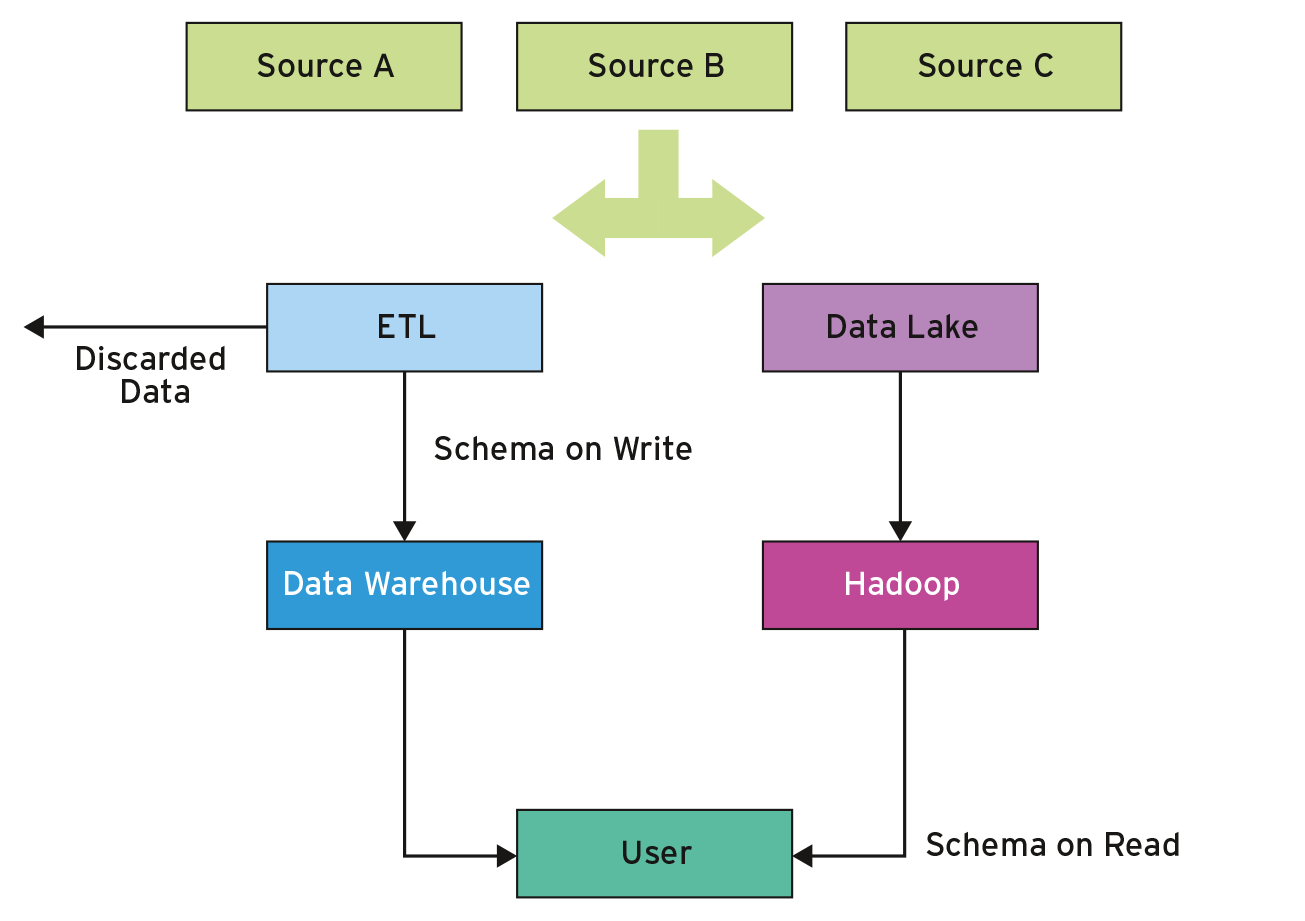
Abbildung 1: Traditionelles Data Warehouse im Vergleich mit dem Hadoop Data Lake.
Hadoop 2 Lake House
Wichtig ist auch der Punkt, an dem Hadoop Daten an den User weitergibt. In Hadoop 1 war dieser Schritt limitiert durch eine parallel arbeitende Map-Reduce-Engine. Populäre Pakete wie Pig [4] oder Hive SQL [5] bauten auf dieser Engine auf. In Version 2 ist Hadoop [6] zum Cluster-Betriebssystem herangewachsen, das eine Plattform zum Bau von Data-Lake-Anwendungen vorhält. Hadoop 2 enthält ein Map-Reduce-Framework, das mit Map Reduce aus Version 1 kompatibel ist, auch die meisten Anwendungen sind ohne Änderungen lauffähig, Pig und Hive eingeschlossen.
Hadoop 1 hatte zwei Kernkomponenten: das Hadoop Distributed File System (HDFS) – der Data Lake für den Cluster. Und eine monolithische Map-Reduce-Engine, die Map-Reduce-Jobs und -Workflows managt. Hadoop 2 hat dieses Design erweitert und bietet mehr Flexibilität. Die Hauptkomponenten sind auf drei angewachsen: Das gleiche HDFS wie in Version 1. Die zweite Komponente heißt Hadoop YARN (Yet Another Ressource Negotiator) – ein nicht auf bestimmte Anwendungen festgelegter Workload-Scheduler für User-Jobs.
Als dritte Komponente sind Anwendungen zu nennen. Darunter sind alle unter YARN lauffähigen Applikationen zu verstehen, die mit YARN-Services auf Cluster-Ressourcen zugreifen und den Data Lake nutzen. Diese Applikationen können beliebige Datenverarbeitungstypen anwenden etwa Map Reduce, Graph Processing und Message Passing Interface (MPI). Sogar In-Memory-Anwendungen wie Apache Spark sind opportun.
Ein Designfeature von beiden Versionen ist die Nutzung eines einfachen Redundanzmodells. Viele Hadoop-Cluster bestehen aus gewöhnlichen Hardwarekomponenten wie x86-Servern, Ethernet und Festplatten. Da Hardware fehleranfällig ist, sind redundant ausgelegte Prozesse und Speicher Teil des Hadoop-Designs auf Toplevel.
Weil der Map-Reduce-Prozess von Haus aus funktional ist, fließen Daten nur in eine Richtung. So lassen sich Input-Dateien als Teil des Prozesses nicht ändern. Diese Einschränkung ermöglicht ein einfaches Redundanzmodell. Tote Prozesse in ausgefallenen Nodes lassen sich auf anderen Servern starten, ohne Resultate zu verlieren. Die Bearbeitungszeit verlängert sich dabei aber eventuell.
YARN-Scheduler
Hadoop 2 erledigt dieses Level der Non-Stop-Redundanz im YARN-Scheduler. Eine Anwendung darf dort bei Laufzeit Ressourcen anfordern und freigeben. Sie kann auch zusätzliche Ressourcen anfordern, um eine Task zu beenden, sollte ein Prozess abstürzen. Da die Ressourcen-Verwendung dynamisch erfolgt, können Anwendungen ungenutzte Ressourcen freigeben, was die Ausnutzung des Clusters erhöht. Diese Situation ist typisch für große Map-Reduce-Jobs, bei denen die Mapping-Phase oft mehr Prozesse benötigt als die Reducer-Phase.
Die Redundanz erstreckt sich auch auf das HDFS. Anders als bei vielen HPTC-Clustern, bei denen parallele I/O-Prozesse als Subsysteme separat von den Nodes ausgelegt sind, nutzt ein Hadoop-Cluster gewöhnliche Hardware für Prozess- und Storage-Nodes. Diese Nodes dienen öfter als Processing- und Speicher-Elemente gleichermaßen. Damit lässt sich die Abarbeitung bei den Daten erledigen. So umspannt der Data Lake meist den ganzen Hadoop-Cluster. Die Ausführung der Jobs kann man sich sinnbildlich wie bei Flotten von Fischerbooten vorstellen, die den Data Lake auf der Suche nach Resultaten durchkreuzen.
Um im Bild zu bleiben, darf man sich YARN als Bootshaus vorstellen, bei dem sich Boote zum Fischen auf dem See ordern lassen. Das HDFS ist zudem ebenso leicht mit genügend Redundanz konfigurierbar, damit der Verlust eines Node oder Rack nicht zum Datenverlust oder einem Fehler des laufenden Jobs führt. Dieses Non-Stop-Design ist ein Markenzeichen von Hadoop-Clustern und es unterscheidet sich von den meisten HPTC-Systemen, in denen vereinzelte Hardwarefehler und daraus resultierende abstürzende Jobs akzeptabel sind.
Vor Apache Spark sei ein weiteres Projekt genannt: Apache Tez [7]. Tez operiert im Hintergrund und widmet sich der Optimierung von Hadoop-Map-Reduce-Jobs. Die meisten hochkarätigen Tools wie Hive SQL und Pig erzeugen Kombinationen von Map-Reduce-Jobs, die dann auf dem Cluster ausgeführt werden. Jeder Map-Reduce-Job arbeitet separat und schreibt und liest so auch vom HDFS, nutzt also die Festplatte.
Tez kombiniert diese individuellen Jobs und vermeidet möglichst die Festplattennutzung, indem das Tool Daten direkt in den Hauptspeicher (In-Memory) transferiert und so zur nächsten Phase im Map-Reduce-Workflow. Als Teil des Stinger-Projekts hat Tez die Geschwindigkeit von Hive-SQL-Jobs auf Hadoop um den Faktor 50 gesteigert, in manchen Fällen auch um den Faktor 160 [8].
Apache Spark
Mit erweiterten Map-Reduce-Fähigkeiten punktet das Projekt Apache Spark [9]. In erster Linie ist Spark ein Tool für parallele In-Memory-Berechnungen. Als schnelles und allgemein taugliches Cluster-Computing-System hält es APIs für Java, Scala und Python und eine optimierte Engine für die generelle Ausführung von Graphen vor. Spark unterstützt diverse Tools, etwa Spark SQL, die Bibliothek MLlib, GraphX und Spark Streaming. Zudem bietet Spark über 80 High-Level-Operatoren, um parallele Applikationen zu bauen, und lässt sich interaktiv über die Shells von Scala und Python ansprechen.
Spark ist stand-alone im Cluster-Modus auf EC2, unter Hadoop YARN und Apache Mesos lauffähig. Es kann vom HDFS, Hbase [10], Cassandra [11] und jeglicher Hadoop-Datenquelle lesen. Nicht zuletzt beschleunigt Spark dank In-Memory-Processing einige Programme um das 100-Fache gegenüber Hadoop-Batch-Map-Reduce-Jobs und um das 10-Fache beim Schreiben auf Festplatte – ähnlich den Resultaten mit Tez. Spark ist Teil des kommenden Stinger-Projekts [8], um Hadoop Hive SQL zu verbessern.
Fazit
Apache Spark erlebt einen Hype und bietet die erwähnten Vorzüge, unter anderem bei der Geschwindigkeit. Hadoop 2 ist dagegen nicht länger das One-Trick-Pony der ersten Ausgabe und die bevorzugte Plattform für neue Tools, die den stetig wachsenden Data Lake abfischen. Bleibt nur, es auszuprobieren.
Spark scheint es dem Anwender dabei etwas leichter zu machen als die Aufgabe, eine Java-Anwendung für die Nutzung des Hadoop-Map-Reduce-API zu schreiben. Der Vorteil liegt darin, dass Entwickler entscheiden können, welcher Ansatz besser für den Data Lake passt. Hadoop 2 hat bei der Anwendungsentwicklung einen erstaunlichen Umfang erreicht. Das schließt Programme ein, die unter Hadoop 1 nicht ausführbar waren, und auch solche für Hadoop Yarn.
Einige Verwirrung um Hadoop resultiert daraus, dass es sich von einer Anwendung zur Plattform gemausert hat, auf der Applikationen wie Spark implementierbar sind. Der Wert einer offenen Big-Data-Plattform ist hoch einzuschätzen. Hadoop 2 ist das Betriebssystem für Data-Lake-Cluster und ein Meilenstein in der Evolution der Datenanalyse. (uba)
Infos
- Big-Data-Characteristika: http://en.wikipedia.org/wiki/Big_data
- Big Data Surprises: http://www.sisense.com/blog/big-data-surprises
- “Nobody ever got fired for using Hadoop on a cluster”, 1st International Workshop on Hot Topics in Cloud Data Processing: http://research.microsoft.com/pubs/163083/hotcbp12%20final.pdf
- Apache Pig:https://pig.apache.org
- Apache Hive:https://hive.apache.org
- Apache Hadoop:https://hadoop.apache.org
- Apache Tez:http://tez.apache.org/install.html
- Stinger Project:http://hortonworks.com/labs/stinger/
- Apache Spark: https://spark.apache.org
- Apache Hbase: http://hbase.apache.org
- Apache Cassandra:http://cassandra.apache.org





