
© Fotograf, 123RF.com
Das Wiener Unternehmen Linbit löst das wirklich in die Jahre gekommene DRBD 8 durch die neue Version 9 ab – und lässt dabei kaum einen Stein auf dem anderen. Ein erster Test zeigt: DRBD 9 kann sich gegen Objektspeicher gerade beim Thema Latenz behaupten.
Admins mögen jene Werkzeuge am liebsten, die im Alltag klaglos ihre Aufgabe erfüllen. Die Replikationslösung DRBD (Distributed Replicated Block Device, [1]) hat sich in über 15 Jahren den Ruf erarbeitet, eine solche Lösung zu sein. Regelmäßig berichten Admins, sie seien etwa bei ihrem neuen Arbeitgeber auf Rechner mit DRBD gestoßen, die ihren Job erledigen und die seit Jahren keiner mehr angefasst hat.
Der Erfinder von DRBD, Philipp Reisner, startete sein Projekt 1999 als Bestandteil seiner Diplomarbeit an der TU Wien. Das Projekt war aus dem Plan entstanden, an der TU Server mit redundantem Storage zu versorgen, ohne viel Geld für die tonangebenden SAN-Systeme der namhaften Hersteller auszugeben.
Reisner gründete nach dem Ende seines Studiums Linbit, eine Firma, die fortan DRBD betreute und auch die Vermarktung der Lösung übernahm. Ihren vorläufigen Höhepunkt erreichte die DRBD-Entwicklung, als Linux-Erfinder Linus Torvalds 2009 die Lösung offiziell in den Linux-Kern aufnahm.
DRBD und Infiniband über RDMA
Der neue Transport-Layer ermöglicht es DRBD 9, nahezu jedes Transportmedium für sich zu nutzen, solange ein entsprechendes Transportmodul dafür vorhanden ist. Besonders stolz ist man in Wien auf den Layer, der RDMA über Infiniband möglich macht. Infiniband bietet ab Werk sowieso schon eine deutlich geringere Latenz als beispielsweise TCP/IP. Davon profitieren besonders Applikationen, die auf ihren Speicher sequenziell zugreifen. Das klassische Beispiel ist etwa MySQL, das jede einzelne Transaktion auf die Platte bringt, bevor es sich um den nächsten anstehenden Write kümmert.
RDMA ermöglicht beim Einsatz entsprechender Infiniband-Karten samt Treiber noch weitere Optimierungen in Sachen Durchsatz. Ein Benchmark-Vergleich von DRBD 8.4 und DRBD 9 zeigte beim Test, dass der Transfer von 1 GByte Daten vom Rechner eins auf den Rechner zwei bei DRBD 9 ungefähr doppelt so schnell war wie bei DRBD 8.4 ( die alte Version benötigte etwa 1.2 Sekunden, die neue Version lediglich 0,54).
Das Konzept hinter DRBD ist denkbar einfach: Linbit selbst nennt als Vergleich immer wieder die Festplattenspiegelung (Raid 1), die hier allerdings übers Netz erfolgt. Innerhalb eines Linux-Systems zeigt sich eine DRBD-Ressource dabei als normales Blockdevice: Wenn ein Programm auf das Blockdevice schreibt, kümmert sich DRBD im Hintergrund darum, dass die Daten auf unterschiedlichen Platten in mehreren Servern landen. Dabei ist es recht vielseitig, beherrscht es doch den synchronen Modus wie auch den asynchronen.
The times they are a-changin’
Doch die Zeiten ändern sich, auch für DRBD gibt es in dieser Hinsicht keine Ausnahme. Mittlerweile hatte die Software viele ihrer Alleinstellungsmerkmale verloren. Lange punkteten DRBD-Lösungen mit einer Kombination aus vernünftigem Preis, guter Performance und inhärenter Hochverfügbarkeit. Die große Schwäche von DRBD war stets die Beschränkung auf zwei Knoten (Abbildung 1). Moderne IT-Umgebungen setzen auf das Skalieren in die Breite. An einen Cluster mit DRBD 8 lässt sich zwar ein dritter Knoten anhängen, das ist aber kein Skalieren in die Breite.
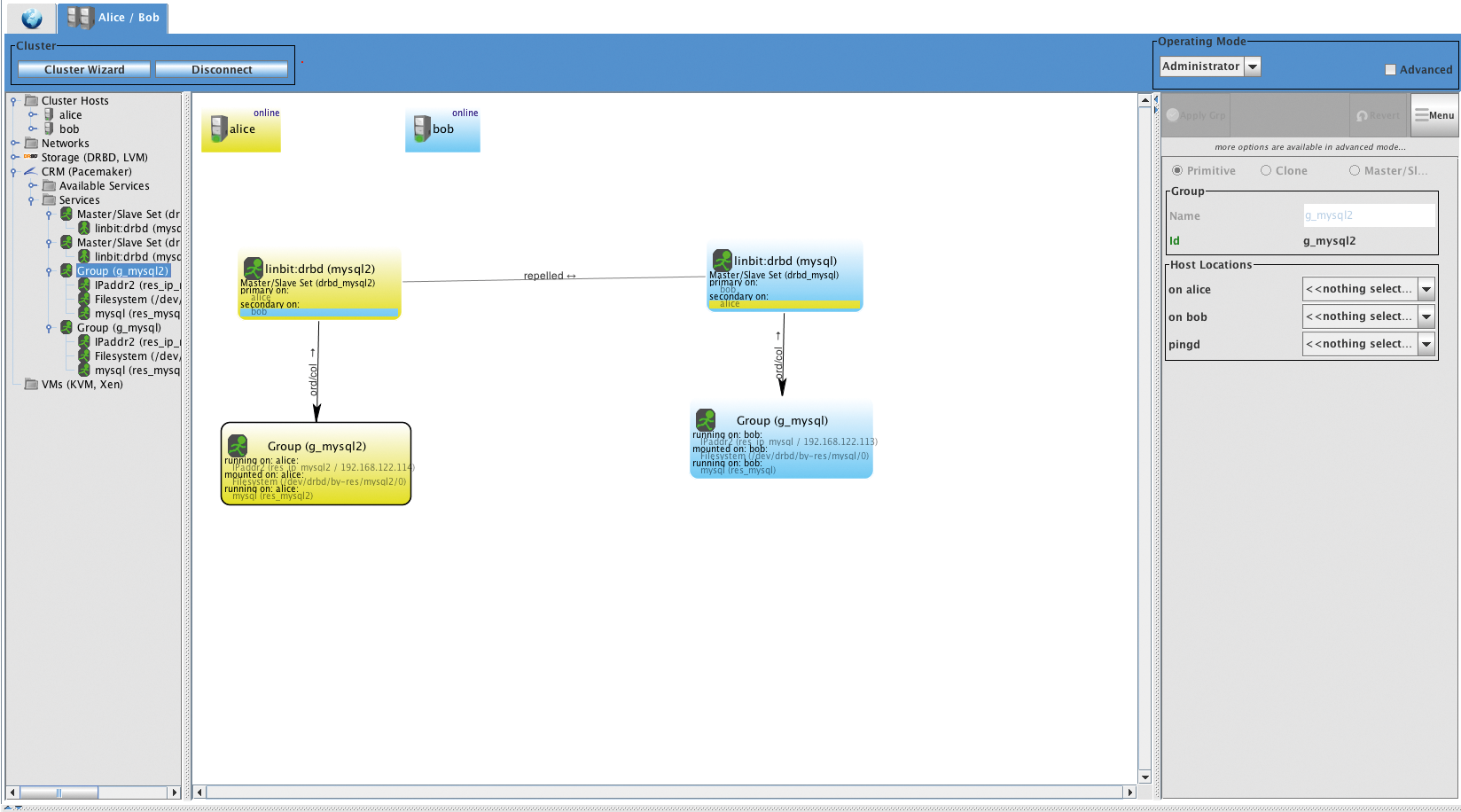
Abbildung 1: Zu Zeiten von DRBD 8 war die Zahl von Knoten, zwischen denen sich eine DRBD-Ressource replizieren ließ, auf zwei beschränkt.
Die Aufmerksamkeit ziehen deshalb aktuell andere Speicherlösungen auf sich. Da gibt es etwa Ceph [2], das Red Hat vor zwei Jahren für viel Geld gekauft hat und das sich seither als Admins Liebling zu positionieren versucht. Zuvor hatte Red Hat bereits Gluster-FS geschluckt, inzwischen scheint man in Raleigh aber das Interesse an dieser Lösung verloren zu haben. Wer keine Anbindung in Form eines Blockdevice benötigt, landet bei Open Stack Swift, das ebenfalls nahtlos skalierbaren und replizierten Speicher verspricht und verschiedene Restful-APIs anbietet.
Die Objektspeicher wildern damit in dem Marktsegment, das DRBD bis vor ein paar Jahren fast für sich alleine gepachtet hatte. Swift, Ceph und die diversen anderen Lösungen haben Redundanz ab Werk eingebaut, funktionieren ebenfalls mit Standardhardware und liegen in Sachen Performance fast immer gleichauf. So schauen sich Unternehmen auf der Suche nach SAN-Ersatz heute eher bei der Konkurrenz um als bei Linbit. Zusätzlich zur Redundanz bieten die neuen Objektspeicher obendrein auch die leichte Skalierbarkeit, die DRBD fehlt.
Um so erstaunlicher, dass sich bei DRBD in den letzten Jahren nicht sehr viel getan hat. Das schon vor einiger Zeit angekündigte Feature, mehr als zwei Knoten direkt aus DRBD heraus ansteuern zu können, war bis jetzt nicht mehr als ein Plan und noch nicht implementiert. Tatsächlich hatten viele Admins DRBD längst ad acta gelegt, weil die Objektspeicher seine Aufgaben vermeintlich viel besser erledigen.
DRBD 9 lebt
Linbit selbst hat sein Produkt aber noch lange nicht abgeschrieben: 2015 soll das Jahr des Durchbruchs von DRBD 9 werden. Dieser Tage läuten die Wiener eine PR-Kampagne ein, die die Vorzüge der neuen Version erklären soll – und ganz nebenbei auch die Antwort auf die Frage gibt, wozu DRBD in Zeiten von Ceph & Co. eigentlich noch nötig ist.
Hält das Produkt, was die Werbung verspricht? Und gelingt es DRBD, seine Nische gegen die diversen Hipster-Technologien der Gegenwart zu behaupten? Ein erster Blick auf DRBD 9 verrät mehr. Und wer die Arbeit mit DRBD 8 gewohnt ist, merkt schnell: DRBD 9 macht nicht alles neu – aber das meiste.
DRBD 8 als Wegbereiter
Eine Analyse des Release Candidate von DRBD 9 verdeutlicht, dass die Entwickler erste Funktionen für DRBD bereits in die Vorgängerversion DRBD 8.4 integriert hatten. Dieses Vorgehen ist in der Open-Source-Community nicht ungewöhnlich – und in diesem Fall war sie sogar zwingend notwendig. Bereits zwischen DRBD 8.3 und 8.4 hatte es massive Veränderungen gegeben, die im Wesentlichen zwei Teilbereiche der Software betrafen: das Handling von TCP/IP-Verbindungen sowie das Handling von Synchronisationsprozessen zwischen den Platten einer DRBD-Ressource.
Doch der Reihe nach: Zunächst haben sich die Entwickler beim Übergang zu DRBD 8.4 eingehend Gedanken über das Thema Verbindungsabbruch gemacht. In DRBD 8.3 war es zwingend notwendig, dass eine DRBD-Ressource zwischen zwei Hosts eine eigene TCP/IP-Verbindung nutzen konnte. Wer zwischen zwei Servern gleich mehrere DRBD-Ressourcen betrieb, hatte also für jede Ressource eine dezidierte TCP/IP-Verbindung. DRBD kommt bekanntlich gern in HA-Clustern zum Einsatz, und es ist ausdrücklich darauf ausgelegt, dass es den plötzlichen Abbruch einer Replikationsverbindung samt anschließendem Failover verkraftet, ohne dass Daten verloren gehen. Intern besitzt es gleich mehrere Funktionen, die dem Datenfraß vorbeugen.
Dennoch war in DRBD 8.3 eine für den Admin sehr unangenehme Situation denkbar, die entsteht, wenn zwei Rechner ihre DRBD-Replikationsverbindung zueinander verlieren, wobei allerdings die TCP/IP-Verbindungen aller Ressourcen nicht im exakt gleichen Moment abbrechen. Theoretisch wie praktisch ist es möglich, dass die eine DRBD-Ressource ihrem Gegenpart auf der anderen Seite zumindest ein paar Bits mehr senden kann als eine andere DRBD-Ressource des identischen Clusters.
Gerade bei Diensten, die auf mehrere DRBD-Ressourcen im Hintergrund zurückgreifen, führt das zu Problemen. Denn theoretisch sind in solchen Szenarien nur die Datensätze der einzelnen Ressourcen auf beiden Seiten des Clusters konsistent. Zwischen verschiedenen Spiegelpaaren (Ressourcen) kann es aber eine Divergenz geben – wahlweise ist die eine Ressource ein kleines Stückchen in der Zukunft oder die andere ein kleines Stück in der Vergangenheit.
DRBD 8.4 löst das Problem mit dem Feature “Multi Volume per Connection”. Bricht bei DRBD 8.4 die Replikationsverbindung einer Ressourcengruppe ab, tut sie das für alle zur Gruppe gehörenden Ressourcen an exakt der gleichen Stelle. Der Admin muss sich über Daten-Zeitreisen keine Gedanken machen.
Für DRBD 9 waren die Änderungen am Connection-Handling in DRBD 8.4 wegweisend. Denn schon in jener Version trafen die Entwickler verschiedene Entscheidungen im Hinblick auf Netzwerkverbindungen, die insbesondere die starre Kopplung von Ressourcen an einzelne TCP/IP-Verbindungen aufhoben. Das Multi-Node-Feature in DRBD 9 nutzt exakt jene Vorarbeit und wäre ohne den vorherigen Trippelschritt in 8.4 so nicht möglich gewesen.
Das Activity Log
Die zweite signifikante Änderung auf dem Weg zu DRBD 9 betrifft das Activity Log, das in DRBD 8.4 bereits deutlich größer als zuvor sein konnte und seine maximale Größe für DRBD 9 nochmals anhebt. Das Activity Log ist die von Linbit erfundene Methode, partielle Resynchronisierung zu erlauben. Grundsätzlich gilt im Storage-Umfeld bekanntlich die Alles-oder-nichts-Regel: Weiß also der Admin nicht zuverlässig, dass ein Datensatz insgesamt intakt ist, muss er zwangsläufig den gesamten Datensatz für korrupt halten und mit dem Backup anrücken.
Im Kontext von Datenreplikation kann so ein ungewisser Zustand schneller eintreten, als es dem Admin recht ist: Bricht die Replikationsverbindung weg, kann es durchaus sein, dass auf dann aktiven Knoten bereits Daten auf der Platte gelandet sind, die es noch nicht zum sekundären Partner im Clusterverbund geschafft haben. Fällt nun der primäre Knoten weg, wird der vormals sekundäre Knoten der neue primäre.
Im synchronen Modus hätte DRBD der vormals auf den primären Knoten zugreifenden Applikation für den gesamten Schreibvorgang übrigens noch kein Acknowledgement gesendet – die Applikation wüsste also, dass ihr Write es noch nicht abschließend auf die Platte aller Clusterknoten geschafft hat. Auf dem vormals primären Knoten, der gerade kaputt ist, liegen die Daten aber schon auf der Festplatte. Und weil der Knoten gerade offline ist, sind sie zum Löschen unerreichbar.
Wie soll eine Lösung wie DRBD damit umgehen? Spätestens dann, wenn der andere Clusterknoten dem Cluster wieder beitritt, müssen die überschüssigen Daten dort von der Platte. SAN-basierte Lösungen haben das Problem lange Zeit dadurch erschlagen, dass sie nach dem Ausfall eines Replikationspartners eine komplette Synchronisation (Full Resync) des gesamten Datenbestands angestoßen haben. Auch DRBD setzte früher noch auf diese Strategie. Doch bei Platten mit mehreren Terabyte Kapazität und noch größeren Werten, für die Raid-Verbünde im Hintergrund sorgen, ist das nicht mehr praktikabel.
DRBD löst das Problem seit einigen Jahren über das so genannte Activity Log. Die Idee dahinter: Wenn die Replikationslösung nach dem Wiedererscheinen eines Knotens im Cluster weiß, auf welche Teile des Datenträgers dort zuletzt zugegriffen worden ist, kann sie einfach nur diese letzten Blöcke überspielen. Hieraus bezieht das Activity Log seinen Namen: In ihm steht, welche Bereiche des Datenträgers (Extents) zuletzt aktiv waren. Nur über die im Activity Log als “aktiv” markierten Blöcke führt DRBD dann einen Resync aus.
In DRBD 8.4 haben die Entwickler viel Arbeit in die Performance und auch in das Fassungsvermögen des Activity Log investiert und diese Funktionalität so erheblich aufgewertet. DRBD 9 profitiert davon in besonderer Weise.
Endlich: n Knoten in DRBD
Die wichtigste Funktion in der neuen DRBD-Version 9 ist zweifellos der Support für mehr als zwei Knoten innerhalb einer DRBD-Spiegelung (einer Ressource im DRBD-Sprech). In der einfachsten Art des Setups erlaubt dieses Feature die Replikation des gleichen Datensatzes auf eine fast beliebige Anzahl von Knoten (Abbildung 2) – nicht ganz beliebig, weil theoretische Limits zwar existieren, für den alltäglichen Betrieb aber kaum relevant sind.
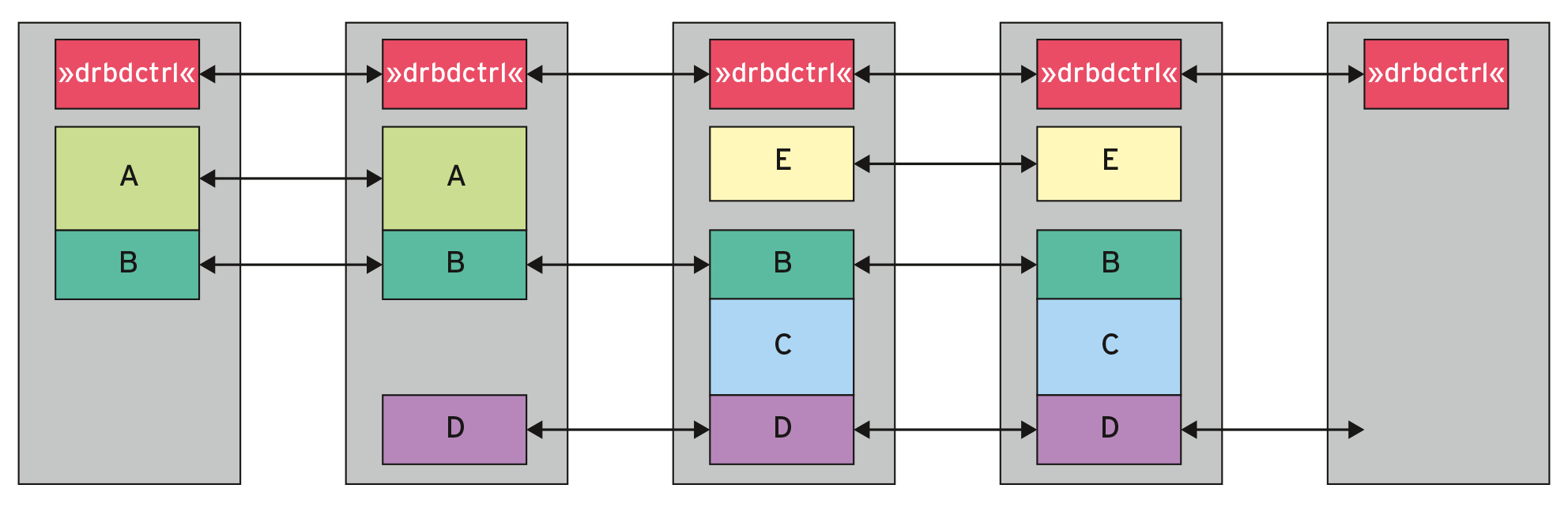
Abbildung 2: Indem es die Ressourcen zwischen vielen Clusterknoten dynamisch zuweist, ermöglicht DRBD 9 das Skalieren in die Breite.
Nebenbei rüstet DRBD 9 auf diese Weise auch die Skalierbarkeit in die Breite nach. Das klingt einfacher, als es ist: Immerhin basiert DRBD nach wie vor auf dem Umgang mit Blockdevices. Im Linux-Kernel gehört DRBD folglich zum Blocklayer und zur Nutzerseite hin werden tatsächlich auch Blockdevices für die Nutzung exponiert. Anders formuliert: DRBD fehlt die Zwischenschicht, die Objektspeicherlösungen wie Ceph einziehen, um über eine große Anzahl von Blockspeichern hinweg Daten zu verteilen. Bei DRBD kann ein Dateisystem nicht größer sein als das größte Blockdevice, das zu einer DRBD-Ressource unterhalb des Dateisystems gehört.
DRBD 9 begegnet dem Problem, indem es alle Blockdevices innerhalb eines Clusters zentral verwaltet und bei Bedarf DRBD-Ressourcen auf den Platten innerhalb des Speicherclusters anlegt, die die notwendige Größe haben. Eine wichtige Rolle spielt hier das neue Userland-Tool »drbdmanage« .
Das Verwalten beliebig vieler DRBD-Ressourcen mit Replikationen über ebenfalls beliebig viele Geräte zwang die DRBD-Entwickler zu vielen Radikalumbauten. Auf Basis der Veränderungen am Code für Netzwerkverbindungen der Vorversion nutzt DRBD 9 ein neues Modell, um Verbindungen zu anderen Hosts intern abzubilden. Jede DRBD-Ressource auf jedem Host kann nun von beliebig vielen anderen DRBD-Knoten Kommandos empfangen oder an sie Befehle versenden.
Ein Transport-Layer
Mit dem neuen Verbindungscode geht ein Transport-Interface (Abbildung 3)einher, das in DRBD 9 Einzug hält. Vorangegangene Versionen integrierten den Transport-Teil von DRBD fest in das eigentliche DRBD-Modul. Der Code für TCP/IP-Verbindungen oder Infiniband war also direkt mit dem Replikationscode verwoben. In DRBD 9 benutzt die Software eine generische Schnittstelle für diverse Transportmechanismen. Ein zweites Kernelmodul kümmert sich darum, dass die Kommunikation im Hintergrund über den jeweils gewünschten Weg läuft. Der Teil, der sich also um die Replikation kümmert, gibt seine Daten an das generische Interface weiter, das im Hintergrund die Daten dann auf das richtige Kabel legt.
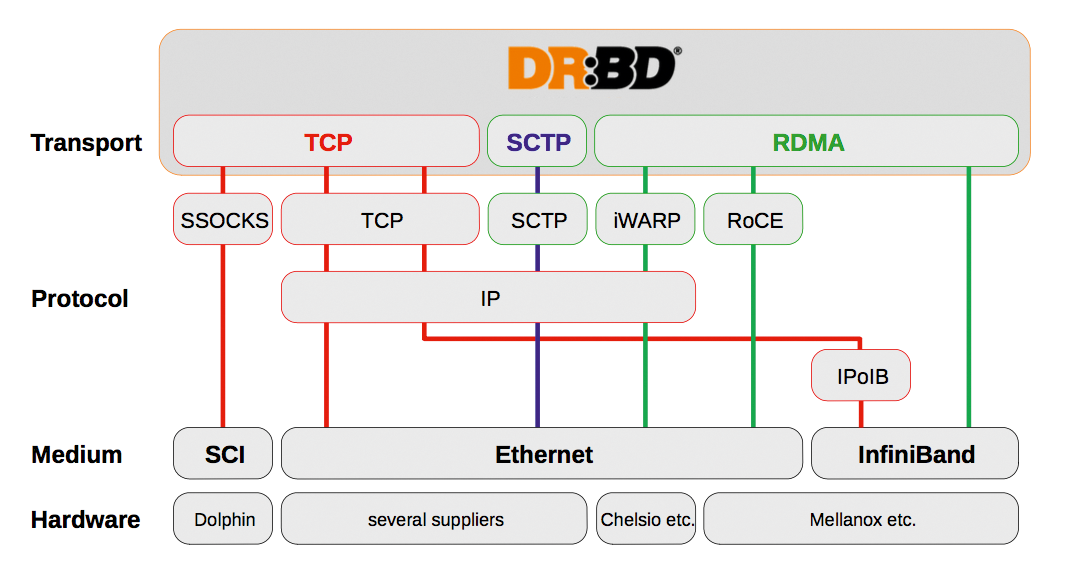
Abbildung 3: Linbit stattet DRBD 9 mit einem neuen Transport-Layer aus, der sich in der Theorie für jedes Protokoll verwenden lässt.
Dadurch wird DRBD 9 sehr viel flexibler als seine Vorgänger. Zum Beispiel kommt Version 9 mit einem Transportmodul für RDMA über Infiniband und einem für TCP/IP. Denkbar wäre aber theoretisch auch, DRBD über Fibre Channel reden zu lassen – auch wenn das aktuell noch Zukunftsmusik ist. Auf RDMA ist Linbit besonders stolz – kein Wunder, lassen sich mit Infiniband über RDMA doch je nach Einsatzzweck deutlich höhere Durchsätze erreichen (Abbildungen 4 und 5), als es beim typischen TCP/IP-Networking der Fall ist (mehr dazu im Kasten “DRBD und Infiniband über RDMA”).
Abbildung 4: Deutliche Performance-Vorteile mit DRBD über Infiniband mit RDMA: 2 GByte pro Sekunde gegenüber …
Abbildung 5: … knapp 1 GByte pro Sekunde vermitteln einen Eindruck von den Vorteilen, die RDMA liefert.
Management mit “drbdmanage”
Admins, die mit DRBD 8 bereits gearbeitet haben, kennen den Workflow: Wollen sie Cluster um eine zusätzliche DRBD-Ressource erweitern, genügt es, auf beiden Clusterseiten das passende Backing-Device anzulegen, DRBD um eine entsprechende Konfiguration zu erweitern und die DRBD-Ressource händisch anzulegen. Bei DRBD 9 würde das zur Sisyphusarbeit. Allein eine Vielzahl von Knoten in Scale-out-Setups würde das Setup fast unwartbar machen, weil der Admin von Hand aufzeichnen müsste, welche DRBD-Ressourcen über welche Server wie gespiegelt sind. Kämen neue Rechner hinzu, müsste der Admin von sich aus darauf achten, diese entsprechend einzubinden.
Das ist nicht praktikabel. Eine der wichtigsten Neuerungen in DRBD 9 ist deshalb gar nicht Bestandteil des Kernelmoduls, sondern ein eigenständiges Werkzeug: »drbdmanage« gehört ab der Version 9 fest zum Lieferumfang. Das Tool ist ein Framework für die Konfiguration von DRBD nach Client-Server-Prinzip: Auf jedem Host, der Bestandteil des Clusters ist, läuft ein eigener Daemon für »drbdmanage« . Der kommuniziert mit dem System per Dbus und erwartet Befehle von außen (Abbildung 6).
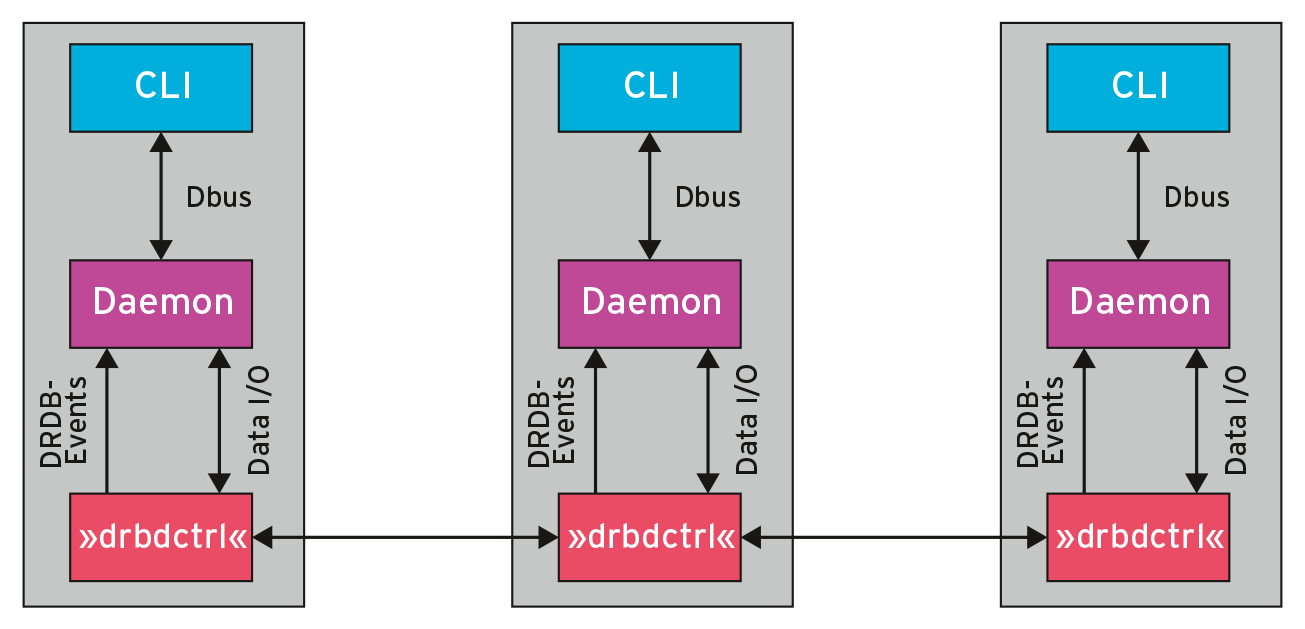
Abbildung 6: Das Werkzeug »drbdmanage« nimmt dem Admin bei DRBD 9 die meiste Arbeit ab, was das Konfigurieren von DRBD-Ressourcen betrifft.
Will der Admin eine neue DRBD-Ressource anlegen, setzt er die passenden Befehle per »drbdmanage« ab und erhält am Ende die Information, auf welchen Knoten im Cluster die DRBD-Ressource zur Verfügung steht. Seine eigene Konfiguration legt »drbdmanage« stilecht auf einer DRBD-Ressource ab, die auf jeden Host des Clusters repliziert ist. Jede Instanz des »drbdmanage« -Daemon hat damit zu jedem Zeitpunkt die gewünschte Clusterkonfiguration zur Hand. Obendrein kümmert sich »drbdmanage« auch um das Hinzufügen neuer Hosts zum Cluster. Die Zeiten des händischen Kopierens von Konfigurationsdateien sind also vorbei.
Auf in die Cloud
War DRBD bisher die Lösung der Wahl für kleinere HA-Setups, wollen die Macher von Linbit mit DRBD 9 auch in die Cloud. Als Plattform haben sich die Entwickler Open Stack ausgeguckt. Zwei Komponenten in Open Stack sind dafür verantwortlich, mit dem Speicher einer Plattform zu kommunizieren: Nova, das VMs verwaltet, auf der einen Seite und Cinder, das persistenten Speicher verwaltet, auf der anderen.
Beide Komponenten verfügen über eine generische Treiber-Schnittstelle, an die sich leicht andocken lässt. Entsprechend kommen von Linbit zwei passende Treiber: Der Cinder-Treiber stellt eine direkte Verbindung von Cinder und »drbdmanage« her, sodass Cinder selbst Ressourcen in DRBD anlegen und verwalten kann. Der Nova-Treiber versetzt Nova in die Lage, virtuelle Maschinen direkt auf DRBD-Ressourcen zu starten.
Das Revier verteidigen
Gleichzeitig bringt DRBD 9 auch Neuerungen für das angestammte Einsatzgebiet. Wer DRBD mit dem Clustermanager Pacemaker betreibt, freut sich beispielsweise über das Feature, das DRBD auf einer Clusterseite automatisch dazu bringt, in den Primary-Modus zu wechseln. Bis DRBD 8.4 musste der Admin den Wechsel vom primären in den sekundären Modus veranlassen oder er lagerte diese Aufgabe an Pacemaker aus. Nun kann DRBD das allein: Merkt eine Ressource auf einem Host, dass sie schreibend benutzt werden soll, wechselt sie automatisch in den Primary-Modus, falls das möglich ist.
Wozu das Ganze?
Gerade weil es um DRBD in den letzten Jahren eher ruhig geworden war, hatten viele Admins Zweifel daran, dass DRBD 9 überhaupt noch notwendig ist. Ceph und Konsorten haben den Bedarf an nahtlos skalierbarem, redundantem Speicher in den letzten Jahren schließlich hinreichend gut gedeckt. Wer so denkt, vergisst allerdings einen wichtigen Teilaspekt des Themas Performance, denn die hat bekanntlich zwei Dimensionen: Durchsatz und Latenz.
Der Durchsatz gibt an, wie viele Daten sich in einem Zeitraum insgesamt von A nach B bringen lassen. Die Latenz bestimmt, wie lange ein einzelnes Paket benötigt, um von A nach B zu kommen. In Sachen Durchsatz legen Objektspeicher ordentlich vor: In aller Regel schreiben Objektspeicher nämlich auf viele verschiedene Spindeln innerhalb des Clusters gleichzeitig – und kombinieren so deren Schreibrate.
Mit DRBD lässt sich dieser Effekt dadurch nachahmen, dass auf allen beteiligten Clusterknoten die Festplatten für DRBD in einem Raid-Verbund an einem Controller mit entsprechendem Puffer hängen. Aktuell gelingt es sowohl DRBD als auch allen typischen Objektspeichern, auf diese Weise das Netzwerk schneller zu saturieren als die Speichermedien auf beiden Seiten.
Wirklich wichtig ist allerdings das Thema Latenz. Die Zwischenschicht, die Ceph & Co. in den Storage-Layer einziehen, um Daten über die Grenzen diverser Platten hinweg verwaltbar zu machen, wirkt sich insbesondere auf die Latenz negativ aus. Im Klartext heißt das, dass einzelne Schreibvorgänge deutlich länger brauchen, als es ohne den Objektspeicher der Fall wäre. Kritisch wird es, wenn die Applikation sequenziell arbeitet, wie es bei MySQL als Beispiel der Fall ist.
Beispielzahlen machen das deutlich: TCP/IP ist nicht auf Latenz optimiert, ermöglicht aber immer noch mehrere Tausend I/O-Operationen pro Sekunde (IOPS). In einem typischen Ceph-Cluster kann die Applikation aber kaum mehr als 300 IOPS realisieren. Wer also eine virtuelle Maschine so betreiben möchte, dass ihr Storage-Backend Ceph ist, wird innerhalb dieser VM kaum befriedigend MySQL laufen lassen können.
DRBD schlägt Ceph ein Schnippchen
Gerade weil bei DRBD diese Schicht fehlt, punktet es in Sachen Latenz gegen die großen Mitbewerber. Obendrein beherrscht DRBD andere Transport-Layer als Ethernet mit TCP/IP – eben auch das auf Latenz optimierte Infiniband. Gerade für Setups, bei denen Latenz eine große Rolle spielt, eignet sich DRBD daher häufig besser Objektspeicher.
Obendrein bringt DRBD eine weitere Eigenschaft mit, die bei Objectstores in der Regel fehlt: Über das Protokoll A beherrscht DRBD nämlich die asynchrone Replikation. Ist diese aktiviert, erhält eine Applikation das Acknowledgement für einen Schreibvorgang in dem Augenblick, in dem die Daten auf dem ersten DRBD-Knoten ihren Weg auf die Platte gefunden haben. Freilich bedeutet das im Falle eines Falles auch, dass die Gefahr größer ist, Daten zu verlieren.
Fazit
DRBD 9 schneidet alte Zöpfe ab und sorgt dafür, dass die Software aus Wien in der Gegenwart des Cloud Computings ankommt. Ansätze wie der neue Transport-Layer oder »drbdmanage« rüsten Funktionalität nach, die sich Admins seit vielen Jahren wünschen. Es bewahrheitet sich einmal mehr, dass Totgesagte länger leben. Die Entwickler von Linbit haben die Dokumentation der Software unter [3] bereits online gestellt.
Infos
- DRBD: http://www.drbd.org
- Ceph: http://www.ceph.com
- DRBD 9, Users Guide: http://drbd.linbit.com/users-guide-9.0





