
Abb. 3: Der OpenLDAP-Wurm.
Enterprise-Anwendungen sind verteilte Anwendungen und das Auffinden von Ressourcen stützt sich dabei auf Namens- und Verzeichnisdienste. Dieser Artikel gibt eine Einführung in das Java Naming and Directory API (JNDI) und zeigt seine Anwendung anhand des freien LDAP-Servers OpenLDAP.
Jede Technologie hat ihre eigene Begriffswelt, und leider werden gleiche Begriffe immer wieder für unterschiedliche Dinge verwendet. Deshalb sollen hier zu Beginn die im Umfeld von JNDI benutzten Begriffe eingeführt werden.
Ein Namensdienst ( naming service) ist ein Dienst, der Namen mit Objekten assoziiert und Objekte anhand ihrer Namen findet. Hauptzweck ist die Vereinfachung für die Benutzer. Den Namen www.linux-magazin.de kann man sich leichter merken als die IP-Adresse, die dahinter steckt. Der Namensdienst DNS sorgt für die Zuordnung und Auflösung.
Namen innerhalb eines Namensdienstes folgen gewissen Syntaxregeln ( naming conventions). Bei DNS-Namen sind dies durch Punkte getrennte Zeichenfolgen, Dateinamen verwenden den Slash oder Backslash, LDAP-Namen dagegen durch Komma getrennte Folgen von Key=value-Paaren. Bei Namen unterscheidet man noch atomic names, compound names und composite names.
In dem oben aufgeführten Beispiel ist linux-magazin ein atomic name, während www.linux-magazin.de ein compound name ist. Dagegen ist https://www.linux-magazin.de ein composite name, da hier das DNS-Namenssystem verknüpft wird mit dem Protokoll-Namenssystem. Die Abgrenzung zwischen compound und composite ist aber von der Definition des Namensdienstes abhängig.
Die Zuordnung von Objekten zu Namen heißt binding. Manchmal lassen sich Objekte nicht direkt speichern, sondern nur eine Referenz ( reference). Das ist die Information darüber, wie man an das Objekt rankommt, gewissermaßen eine Adresse im weitesten Sinn.
Zuordnungen durch den Context
Ein zentraler Begriff im JNDI ist der Context. Das ist eine Menge von Zuordnungen zwischen Namen und Objekten. Ein Beispiel, das auch die oben angesprochene Namensverwirrung zeigt, ist ein Verzeichnis (hier nicht im Sinne eines Verzeichnisdienstes) im Dateisystem, zum Beispiel /home. Alle Dateien innerhalb dieses Verzeichnisses bilden einen Context, da hier Dateinamen den entsprechenden Dateien zugeordnet sind. Context-Objekte stellen Methoden für das Auffinden von Objekten ( lookup) zur Verfügung, zusätzlich dazu noch Verfahren für das Erstellen und Löschen von bindings und deren Auflistung.
Ein Name in einem Context kann an ein weiteres Context-Objekt gebunden werden (ein so genannter Subcontext, im obigen Beispiel ein Unterverzeichnis), wodurch ein hierarchisches System entsteht. Sind alle Context-Objekte vom selben Typ, spricht man von einem naming system, das über seine Methoden den naming service bereitstellt.
Jeder Namensdienst hat sein eigenes Interface und die Entwicklerin muss deshalb die verschiedensten APIs beherrschen. Wenn auch DNS-Abfragen in einem Programm nicht zu den Kandidaten gehören, die durch andere Namensdienste ersetzt werden, so ist es durchaus denkbar, dass Objekte in einer ersten Programmversion über die RMI-Registry gefunden werden, in einer späteren Version aber auf CORBA umgestellt wird, mit den entsprechenden Folgen für den Code. Das JNDI sorgt hier für eine einheitliche Schnittstelle für die Anwendungsentwicklerin, so dass der Zugriff auf den Namensdienst transparent geschieht. Die Details werden im Abschnitt ” Ein Blick in das API” erläutert.
Verzeichnisdienste
Verzeichnisdienste ( directory services) sind erweiterte Namensdienste. Neben der Zuordnung von Namen zu Objekten erlaubt ein Verzeichnisdienst auch die Zuordnung von Attributen zu den Objekten. Das Interface wird dadurch mächtiger: Objekte können wie bisher über ihren Namen gefunden werden, zusätzlich aber auch über ihre Attribute. Diese können gesetzt, gelöscht oder gelistet werden.
Ein Verzeichnis ( directory) ist eine zusammengehörige Menge von Verzeichnisobjekten ( directory objects, auch directory entries genannt). Diese können Attribute besitzen. Ein Attribut ist dabei eine Zuordnung zwischen einem Attribut-Namen ( attribute identifier) und einem Satz von Werten ( attribute values). Klassisches Beispiel ist ein Telefonbuch (Verzeichnis) eines Ortes. Dort sind Personen (Verzeichnisobjekte) anhand ihrer Namen aufgeführt. Die Personen haben in der Regel zwei Attribute, die Straße (optional) und die Telefonnummer. Dieses Attribut kann einen oder mehrere Werte haben.
Verzeichnisdienste spielen in vielen vernetzten Umgebungen eine wichtige Rolle. Deshalb haben sich hier die verschiedensten Implementationen entwickelt, zum Beispiel die Novell Directory Services oder das NIS-System ( Network Information System). Informationen zu LDAP sind im Kasten “LDAP und X.500” aufgeführt. Das Verhältnis zwischen Verzeichnissen und Datenbanken wird im Kasten “Verzeichnisse und Datenbanken” näher erläutert.
| LDAP und X.500 |
|---|
| Der Standard ITU X.500 definiert sowohl ein Datenmodell als auch ein Zugriffsprotokoll zu diesen Daten (X.500 Directory Access Protocol, DAP). Dieses Protokoll hatte ähnlich wie SGML den Nachteil, dass es umfassend, aber kompliziert war. Deshalb wurde zuerst von der Universität von Michigan das Lightweight Directory Access Protocol, kurz LDAP entwickelt. Mittlerweile ist es ein IETF-Standard und die entsprechenden Dokumente sind als RFCs verfügbar.
Da LDAP ursprünglich nur als Zugriffsprotokoll ausgelegt war, definierte es kein eigenes Datenmodell. Mit der Evolution des LDAP-Standards hat sich das geändert, allerdings wurde das Basis-Schema praktisch unverändert von X.500 übernommen. Pionier für kommerzielle LDAP-Produkte war Netscape, dessen erste Version 1996 verfügbar wurde (Netscape hatte einfach das LDAP-Team der Universität von Michigan abgeworben). Momentan ist die Version 3 des LDAP-Protokolls aktuell. Weiterentwicklungen sind vor allem in Richtung einer Standardisierung der Authentifizierung, Zugriffskontrolle und Server-Server-Kommunikation (zur Replikation) zu erwarten. Daten sind im LDAP-Verzeichnis in einem hierarchischen Directory Tree (DT) angeordnet. Jeder Eintrag besteht aus einem oder mehreren Attributen. Ein Eintrag wird identifiziert durch seinen so genannten distinguishing name, dem DN. Ein DN wird aus einer geordneten Liste von Attribute-Werte-Paaren gebildet. Jedes Paar in der Liste ist ein Zweig im DT, mit dem Paar ganz rechts als Wurzel. Hier ein einfaches Beispiel: cn=Bernhard Bablok, o=Coffee-Shop Productions, c=DE Die einzelnen Zweige sind countryName und organizationName und commonName Um die Struktur des Verzeichnisses zu definieren, braucht es drei Komponenten: Syntax-Definitionen (Wert-Typen, z.B. Binary oder Case Exact String), Attribut-Definitionen und Klassen für Verzeichniseinträge. Attribut-Definitionen legen fest, welcher Syntax die Wertausprägungen folgen. Darüber hinaus werden so genannte matching rules für Datenvergleiche (wichtig für die Suche) definiert. Ein Beispiel ist die Art und Weise, wie Whitespace behandelt wird. Attribute erlauben Vererbung, das heißt, dass ein neues Attribut ein bestehendes erweitern kann (die Syntax darf dabei aber nicht geändert werden). Jeder Verzeichniseintrag gehört einer oder mehreren Klassen an. Eine Klasse definiert die nötigen und optionalen Attribute dieses Eintrags. Auch Klassen werden über eine Hierarchie definiert. Die oberste Klasse ist die Klasse Top mit dem Attribute objectClass. Der Wert dieses Attributs ist die Liste aller Objekt-Klassen, die für diesen Eintrag gelten. Alle Klassen bilden zusammen das Schema. Wichtigstes Schema ist das User Schema, eine Zusammenfassung davon findet sich im RFC 2256 (X.500(96) User Schema). Will man eigene Objekte speichern, muss man entweder die Schema-Überprüfung im LDAP-Server ausschalten oder die neuen Klassen bekannt machen. Je nach LDAP gibt es dafür unterschiedliche Wege (bei OpenLDAP werden die Klassendefinitionen einfach in die Konfigurationsdatei eingefügt). Die Topologie eines Verzeichnisses kann partitioniert, repliziert oder eine Mischform sein. Im ersten Fall ist ein Eintrag nur einmal in einem einzelnen Server vorhanden. Anfragen, die ein Server nicht beantworten kann, werden an andere Server weitergeleitet ( referrals). Das kann Server-basiert geschehen oder durch den Client (der eine entsprechende Antwort vom Server bekommt und dann selbst entscheiden muss, die Anfrage weiterzugeben oder nicht). Ein Spezialfall von Referrals sind continuations. Diese implementieren die verteilte Suche. Eine replizierte Topologie wird von LDAP ebenfalls unterstützt. Dabei sind zwei Modelle möglich: Master/ Slave und Peer to Peer. Für die Replikation existiert noch kein endgültiger Standard. Der Zugriff auf LDAP-Server erfolgt über LDAP-Urls (definiert in RFC 2255). Hier ein Beispiel ldap://localhost/o=Coffee-Shop%20Productions,c=DE Diese Anfrage liefert alle Attribute des entsprechenden Eintrags zurück. Der Default-Port ist für LDAP-Server 389, kann aber wie gewohnt auch explizit durch einen Doppelpunkt getrennt vom Hostnamen angegeben werden. |
Wie schon bei den Namensdiensten erwähnt hat jeder Verzeichnisdienst sein eigenes Interface. Auch hier führt die Verwendung des JNDI zu einer standardisierten Schnittstelle.
Architektur, Download und Installation
Die Architektur des JNDI besteht aus drei Schichten (siehe Abbildung 1): dem JNDI API ( application programming interface), dem naming manager und dem JNDI SPI ( service provider interface). Die Anwendungsentwicklerin greift mit dem API auf den Naming Manager zu, dieser wiederum nutzt das SPI um die eigentlichen
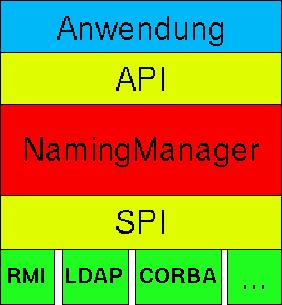
Abb. 1: Schema der JNDI-Architektur
Dienste zu verwenden. Diese Trennung erlaubt die beliebige Erweiterung des Systems und bleibt transparent für die Anwendungsprogramme. Dasselbe Design-Pattern wird auch für die Java-Cryptography-Extensions verwendet.
Service Provider gibt es für eine ganze Reihe von bekannten Namens- und Verzeichnisdiensten (manche erst im Betastatus). Insbesondere Enterprise-JavaBeans-Server stellen auch einen Provider zur Verfügung, damit Anwendungen die Serverobjekte lokalisieren können. Details dazu gibt es in einer späteren Folge der Coffee-Shop-Reihe über Java-Enterprise- Features, die sich spezifischer mit EJBs beschäftigt.
In der Java-Version 1.3 wird das JNDI mit drei Service Providern (LDAP, RMI und CORBA) mitgeliefert. Weitere Service Provider sind von der JNDI-Homepage (siehe [2]) herunterzuladen. Arbeitet man noch mit dem JDK 1.2.x, so ist das JNDI auch getrennt erhältlich. Die Pakete sind relativ klein, die größten Brocken sind die Dokumentation und das Tutorial, die entpackt jeweils etwa 4 MByte belegen. Hat man das JDK 1.3, empfehle ich auch noch den Filesystem-Service-Provider herunterzuladen, da er das Herumspielen mit dem JNDI erlaubt ohne einen LDAP-, RMI- oder CORBA-Dienst zu starten.
| Verzeichnisse und Datenbanken |
|---|
| Verzeichnisse sind Datenspeicher und darin den klassischen (relationalen) Datenbanken verwandt. Oftmals stehen sogar hinter LDAP-Servern ganz normale Datenbanken. Trotzdem gibt es gewichtige Unterschiede zwischen Verzeichnissen und Datenbanken.
Verzeichnisse sind logisch zentralisierte Datenspeicher von physisch verteilten Informationen. Das bedeutet, dass die Daten eventuell partitioniert an verschiedenen Standorten vorliegen oder an mehrere Lokationen repliziert werden, aber jeder Client dieselbe Sicht auf die Daten hat. Die Daten sind meist hierarchisch organisiert und relativ statisch. Ziel ist es, einen einheitlichen Zugriff auf Daten mit anwendungsübergreifendem Charakter (etwa Adressen von Personen oder Ressourcen im Netzwerk) zu ermöglichen und diesen Zugriff anwendungsunabhängig zu steuern. Bei Verzeichnissen handelt es sich stets um eine spezialisierte Nischenlösung. Daten, die für Verzeichnisse geeignet sind, haben folgende Eigenschaften:
Die besonderen Stärken von Verzeichnissen sind der schnelle Zugriff auf die Daten, die Unterstützung von hierarchisch organisierten Daten, zudem Attribute mit mehreren Werten und Suchergebnisse mit potenziell unterschiedlichen Ergebnistypen sowie die Replikationsmöglichkeit. Außerdem sind Verzeichnisse meist einfacher administrierbar als Datenbanken und erlauben eine sehr feine Granularität der Zugriffskontrolle. Den Stärken steht allerdings auch eine Reihe von Schwächen gegenüber. Je nach Implementation kann beispielsweise der Schreibzugriff sehr langsam sein (insbesondere die Zeit, bis die Veränderung an alle Repliken weitergereicht wurde, kann lang sein). Wie schon erwähnt gibt es keine Möglichkeit Veränderungen transaktionsorientiert durchzuführen. Auch ein Locking einzelner Datenelemente existiert nicht, ebenso wenig wie Relationen zwischen diesen Elementen. Damit muss also die schreibende Anwendung die Datenintegrität sicherstellen. Auch die Abfragesprache ist nicht so ausgefeilt wie die für relationale Datenbanken. Vor- und Nachteile von Verzeichnissen müssen also in jedem konkreten Anwendungsfall genau abgewogen werden. Die Entscheidung ist trotzdem meist einfach, da Verzeichnisse eingeführt werden, um existierende Lösungen zu ersetzen oder zu erweitern. Die historischen Wurzeln kann man grob diesen drei Kategorien zuordnen: einmal der Verwaltung von Netzwerk-Ressourcen (etwa NDS, NIS), dann den Adressbuch-basierten Verzeichnissen (insbesondere von E-Mail-Anwendungen) und als dritter Kategorie dem Versuch, mit dem X.500-Standard ein globales Adressbuch zu definieren. Beispiele für solche Verzeichnisse sind das Lotus-Domino-Verzeichnis (mit seiner E-Mail-Vergangenheit) und Microsofts Active Directory, dessen Geschichte auf die LAN-Manager-Domains und auf das Adressbuch von Microsoft Exchange zurückgeht. |
Typischerweise entpackt man alle Pakete unterhalb von /usr/local/jndi und kopiert dann alle JAR-Dateien aus dem lib-Verzeichnis nach /jre/lib/ext oder setzt symbolische Links. Mehr ist nicht zu tun. Wer sich auch das Beispielpaket heruntergeladen hat, kann zur Überprüfung der Konfiguration den JNDI-Browser starten (nach Anpassung der Datei runnit an die eigenen Gegebenheiten).
Ein Blick in das API
Das JNDI-API ist verteilt auf fünf Pakete:
- javax.naming
- javax.naming.directory
- javax.naming.event
- javax.naming.ldap
- javax.naming.spi
Das erste Paket enthält Klassen und Interfaces für den Zugriff auf Namensdienste. Wichtig sind hier die Interfaces Context (insbesondere die Methoden lookup(), listBindings() und list()), das Interface Name mit den Klassen CompoundName und CompositeName sowie die Klasse Reference. Dazu gibt es noch eine ganze Hierarchie von Exceptions, angefangen bei der obersten Klasse NamingException.
Mittels JNDI werden alle Aktionen relativ zu einem Context ausgeführt. Da es hier keinen absoluten Root-Context gibt, muss die Programmiererin am Anfang einen InitialContext erzeugen. Als Argument des Konstruktors dient ein Hashtable, der die dazu notwendigen Konfigurationsparameter enthält. Meist kommt man mit zwei Parametern aus: dem Namen einer Klasse, die das Interface InitialContextFactory implementiert, und einer so genannten Provider-Url.
Ein Beispiel soll das verdeutlichen (siehe Listing 1). Hier wird der File-System-Provider verwendet. In diesem Fall gibt die Provider-Url das Verzeichnis an, relativ zu dem die Aktionen ausgeführt werden. Der File-System-Provider bindet Dateinamen an Objekte vom Typ java.io.File (genau genommen an Referenzen, die über lookup() automatisch aufgelöst werden). Sind eigene Java-Objekte im Dateisystem zu speichern, ist etwas mehr Aufwand nötig, wie weiter unten am Beispiel der Speicherung von Objekten in einem LDAP-Server beschrieben wird.
Das Package javax.naming.directory enthält die notwendigen Erweiterungen des ersten Pakets für Verzeichnisdienste. Analog zum InitialContext gibt es hier einen InitialDirContext. Weitere wichtige Klassen und Interfaces sind BasicAttribute (implementiert Attribute) sowie BasicAttributes (implementiert Attributes). Letzteres ist eine ungeordnete Collection. Änderungen an den Attributes haben keine Auswirkungen auf das Directory, wenn nicht mittels der entsprechenden Methode des DirContext-Objekts ( modifyAttributes()) ein Update durchgeführt wird.
Die letzten drei Packages sollen hier nur kurz erwähnt werden. javax. naming.event erlaubt es, das vom AWT bekannte Event-Listener- Design-Pattern auf Namens- und Verzeichnisdienste anzuwenden. Das javax.naming.ldap-Package enthält die über das directory-Package hinausgehende spezifische LDAP-Funktionalität, das javax.naming.spi-Package die für Service Provider notwendigen Factory-Interfaces sowie die zentrale NamingManager-Klasse.
| OpenLDAP |
|---|
OpenLDAP mit seinem Wappentier, dem OpenLDAP-Wurm (siehe Abbildung 3), basiert auf der Version 3.3 des LDAP-Servers der Universität von Michigan. OpenLDAP ist unter der “OpenLDAP Public License” verfügbar, die von der “Artistic License” (von Perl bekannt) abgeleitet ist. Die Quellen können von [3] heruntergeladen und mittels
> ./configure > make depend > make > su -c "make install" konfiguriert, kompiliert und installiert werden. Wer die Version 7 der SuSE-Distribution sein Eigen nennt, kann OpenLDAP auch wie gewohnt mit Yast installieren. Ein entsprechendes Start-Stop-Skript wird dann ebenfalls automatisch installiert. Der Start während der Bootphase kann über Einträge in /etc/rc.config gesteuert werden. Abb. 3: Der OpenLDAP-Wurm. Die zentralen Komponenten sind slapd und slurpd. Der slapd ist der eigentliche LDAP-Server während der slurpd für die Replikation der Änderungen an andere slapd-Instanzen zuständig ist. Der Backing-Store des LDAP-Servers ist eine LDBM- kompatible Datenbank (unter Linux typischerweise GDBM). Diese Datenbank ist besonders ausgelegt auf das Speichern von Key-Value-Paaren und bietet somit ein einfaches Interface für das Speichern von LDAP-Einträgen. Konfiguriert wird der slapd über die Datei slapd.conf (je nach Konfiguration des OpenLDAP-Pakets unter /usr/local/etc/openldap oder /etc/ openldap). Hier werden die Zugriffsrechte, der Ort der LDBM-Datenbank, die Servertopologie usw. definiert. Es bietet sich an, erst mal die LDAP-Howto zu lesen, außerdem existiert ein Guide für die OpenLDAP-Administration, der Antwort auf die meisten Fragen geben sollte. |
Nach diesem Überblick über die Theorie geht es jetzt an die Praxis. Als Basis dient mir der frei verfügbare LDAP-Server OpenLDAP (Details dazu im Kasten “OpenLDAP”). Wer das Beispiel nachvollziehen möchte, sollte einen entsprechenden Server lokal aufsetzen und mit einigen Daten füllen. Das JNDI-Tutorial liefert auch eine Reihe von Beispielen einschließlich der dazugehörigen Daten mit.
LDAP klassisch …
Ein kleines Beispiel soll die klassische Verwendung eines LDAP-Servers zeigen. Eine Applikation braucht die E-Mail -Adresse zu einem Namen. Die E-Mail-Adresse ist ein Attribut mit dem Namen mail. Dieses Attribut wird abgefragt. Listing 2 zeigt, wie wenig Zeilen dafür notwendig sind. Die äquivalente LDAP-Url sieht wie folgt aus (einfach mal im Netscape eingeben):
ldap://localhost:389/cn=Bablokb,o=CSP,c=DE?sn,mail
Einer der Vorteile von JNDI ist es, sich nicht mit den lästigen Details der Url-Kodierung auseinandersetzen zu müssen.
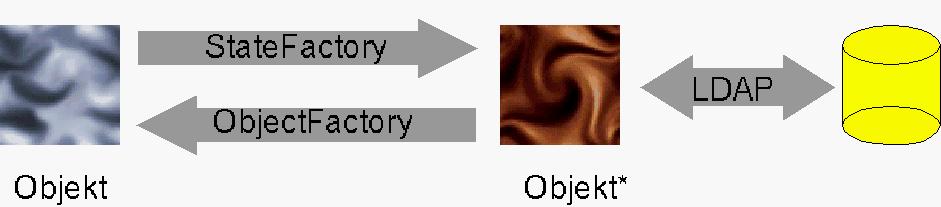
Abb. 2: Umwandlung von Objekten bei der Speicherung im LDAP-Server.
Vergleicht man die Beispiele 1 und 2, sieht man dasselbe Pattern. Zuerst wird die Umgebung konfiguriert, anschließend ein Initial(Dir)Context erzeugt, mit dem verschiedene Operationen (in den Beispielen die verwandten Methoden lookup() und getAttributes()) durchführbar sind.
… und für Java-Objekte
LDAP-Server sind nicht dafür ausgelegt, Java-Objekte zu speichern. Da es aber möglich ist, beliebige Schemata zu definieren, ist das kein prinzipielles Problem. Aufgabe des Service Providers ist es dabei, die Objekte beim Speichern in eine Form umzuwandeln, die der LDAP-Server versteht, und beim Lesen diese Form wieder in sein Original zurückzuübersetzen. Die folgenden Ausführungen beziehen sich auf den LDAP-Service-Provider von SUN. Die zu den Java-Objekten gehörenden Schemata werden auch mit dem Tutorial mitgeliefert.
Die einfachste Art Objekte im LDAP-Verzeichnis zu speichern ist (es), sie zu serialisieren. Dazu muss die Klasse das (Marker-)Interface java.io. Serializable implementieren. Der Nachteil daran ist, dass erstens nicht alle Klassen serialisierbar sind und zweitens die serialisierte Form sehr groß sein kann. Große Einträge sind aber für LDAP-Server nicht sehr effizient zu handhaben, insbesondere in verteilten Topologien.
Es gibt aber mehrere Alternativen zu der Speicherung in der serialisierten Form. Anstatt das Objekt selbst zu speichern, kann man eine Referenz speichern. Dazu muss das Objekt entweder eine Subklasse von javax. naming.Reference sein oder das Interface javax.naming.Referenceable implementieren. Letzteres enthält die Methode getReference(), die beim Speichern mittels DirContext.bind() aufgerufen wird.
Eine Referenz enthält alle notwendigen Informationen um das Objekt wieder erzeugen zu können. Kann das Objekt beispielsweise aus einer Datenbank-Query erstellt werden, so könnte die komplette Query (oder die relevanten Teile daraus) in der Referenz enthalten sein. Außerdem muss die Referenz wissen, welche Factory-Klasse aus diesen Informationen wieder das Originalobjekt herstellen kann.
Neues aus der Zustandsfabrik
Objekte in serialisierter Form oder als Referenzen abzuspeichern sind nur zwei Spezialfälle für ein allgemeines Prinzip. In Abbildung 2 ist dargestellt, was beim Speichern oder Lesen passiert. Das Java-Objekt wird mittels einer StateFactory in eine LDAP-speicherbare Form umgewandelt. State ist hier mit Zustand zu übersetzen: Das Objekt wechselt den Zustand (seine Klasse), behält aber alle Informationen. Beim Lesen dient eine ObjectFactory dazu, aus den gespeicherten Informationen (zu denen natürlich auch die Originalklasse gehört) das Objekt wieder zu erzeugen.
| Listing 1: Beispiel 1 |
|---|
01: import javax.naming.*;
02: import java.io.File;
03: import java.util.Hashtable;
04:
05: public class Beispiel1 {
06: public static void main(String[] args) {
07:
08: try {
09: Hashtable cfg = new Hashtable();
10: cfg.put(Context.INITIAL_CONTEXT_FACTORY,
11: "com.sun.jndi.fscontext.RefFSContextFactory");
12: cfg.put(Context.PROVIDER_URL, "file:/home/bablokb");
13: Context initCtx = new InitialContext(cfg);
14:
15: File f = (File) initCtx.lookup(".emacs");
16: System.out.println(f); // Ausgabe: /home/bablokb/.emacs
17:
18: initCtx.close();
19: } catch (Exception e) {
20: e.printStackTrace();
21: }
22: }
23: }
|
Eine eigene StateFactory für serialisierbare Objekte oder Referenzen zu schreiben, ist nicht notwendig. Braucht man aber volle Kontrolle über die Speicherung, muss man dies tun. Alle StateFactories und ObjectFactories, die das JNDI-Framework verwenden soll, müssen über den Hashtable, der zur Konfiguration dient, bekannt gemacht werden (analog zur InitialContextFactory).
| Listing 2: Beispiel 2 |
|---|
01: import javax.naming.*;
02: import javax.naming.directory.*;
03: import java.io.File;
04: import java.util.Hashtable;
05:
06: public class Beispiel2 {
07: public static final String MYDN = "cn=Bablokb, o=CSP, c=DE";
08: public static void main(String[] args) {
09:
10: try {
11: Hashtable cfg = new Hashtable();
12: cfg.put(Context.INITIAL_CONTEXT_FACTORY,
13: "com.sun.jndi.ldap.LdapCtxFactory");
14: cfg.put(Context.PROVIDER_URL, "ldap://localhost:389");
15: DirContext initCtx = new InitialDirContext(cfg);
16:
17: String[] attribs = new String[2];
18: attribs[0] = "sn";
19: attribs[1] = "mail";
20: Attributes res = initCtx.getAttributes(MYDN,attribs);
21: for (int i = 0; i<attribs.length; ++i) {
22: Attribute a = res.get(attribs[i]); // immer res != null
23: if (a != null) {
24: System.out.println(attribs[i] + ":");
25: NamingEnumeration en = a.getAll();
26: while(en.hasMoreElements())
27: System.out.println("t" + en.nextElement());
28: }
29: }
30: initCtx.close();
31: } catch (Exception e) {
32: e.printStackTrace();
33: }
34: }
35: }
|
Der SUN-Service-Provider hat noch für drei weitere Spezialfälle eingebaute Logik. Das betrifft einmal Objekte, die das DirContext-Interface implementieren und mittels der Methode getAttributes() verlustfrei in Attribute umgewandelt werden können. Die beiden anderen Spezialfälle sind RMI-Objekte und CORBA-Objekte. Die Speicherung der entsprechenden Objektreferenzen in einem LDAP-Server ist in verteilten Enterprise-Lösungen eine wichtige Maßnahme, um die Anzahl der Namensdienste, die eine Entwicklerin kennen und ansprechen muss, zu reduzieren.
Für alle Methoden der Objektspeicherung sind ausführliche Beispiele im JNDI-Tutorial (einschließlich Code-Beispiele) vorhanden.
finally{}
Mit dem JNDI ist es SUN geglückt, ein einfaches API zur Verfügung zu stellen, um einheitlich auf verschiedene Namens- und Verzeichnisdienste zuzugreifen. Über einen einfachen Satz von Konfigurationsparametern, die man bei geschickter Programmierung auch über die D-Option des Java-Interpreters setzen kann, lässt sich die zugrunde liegende Infrastruktur transparent für den Rest des Programms ändern.
Auch wenn ich das SPI nicht behandelt habe, lohnt sich ein Blick in die Dokumentation. Das entsprechende Paketz enthält nur wenige Klassen sowie eine Reihe von Interfaces, die meist nur eine Methode enthalten. Diese Einfachheit ist auch der Grund, warum es schon auf breiter Front Service Provider gibt.
In den nächsten Folgen, in denen es um den Java-Message-Service (JMS) und anschließend (endlich!) um Enterprise-JavaBeans geht, wird uns das JNDI immer wieder begegnen als das Mittel der Wahl, Objekte und andere Ressourcen im Netz zu lokalisieren. (uwo)
| Der Autor |
|---|
| Bernhard Bablok arbeitet bei der AGIS mbH (Allianz Gesellschaft für Informatik Service mbH) als Systemprogrammierer im Systems-Management-Bereich. Wenn er nicht Musik hört, mit dem Radl oder zu Fuß unterwegs ist, beschäftigt er sich mit Themen rund um Objektorientierung. |
| Infos |
|---|
| [1] Coffee-Shop: Von Sandkästen, Schlüsseln und Signaturen, Linux-Magazin 7/2000, S. 106ff.
[2] Die JNDI-Homepage: http://java.sun.com/products/jndi/ [3] Die OpenLDAP-Homepage: http://www.openldap.org |
Copyright © 2002 Linux New Media AG





