
© mopic, 123RF
Die statistische Programmiersprache R seziert eine Datenbasis nach allen Regeln der Kunst. Eingebettet in Python und unterstützt von diversen Webtechnologien bereitet sie aber auch Daten passend für den Webbrowser auf – im Beispiel solche zur Laufbahn von Kometen.
Der Mehrwert umfangreicher Daten zeigt sich erst bei einer eingehenden Datenanalyse. Die Open-Source-Sprache R [1] erweist sich hierbei als leistungsstarkes Tool, um eine vorliegende Datenbasis qualitativ und quantitativ nach allen Regeln der Statistik zu beurteilen. Doch R kann noch mehr: Eingebettet in die Skriptsprache Python [2] lässt es sich auch mit Mehrwert in Webanwendungen einsetzen.
Der vorliegende Artikel demonstriert den Einsatz anhand einer Beispielanwendung, in der es darum geht, Kometendaten auszuwerten. Ein Apache-Webserver visualisiert zu diesem Zweck mit Hilfe von Webtechnologien wie HTML, Javascript, Jquery [3] und CSS3 die Ergebnisse statistischer Reports, die Python in Kombination mit R und der Datenbank Mongo DB [4] erstellt. Konkret erzeugen die Python-Skripte verschiedene Reports, die sie aus Daten über Kometenlaufbahnen generieren.
Kometenhaft
Abbildung 1 demonstriert, wie der Reportgenerator der Beispielanwendung die Kometendaten in Firefox unter Ubuntu 12.04 anzeigt. Über die obere Auswahlliste wählt der Nutzer eine Reportvariante aus. Klickt er auf »Senden« , setzt Javascript eine HTTP-Anfrage an den Apache-Webserver ab, der daraufhin den Report erstellen lässt. Das erledigen Python-Skripte, die wiederum auf R zurückgreifen.

Abbildung 1: Die Kometendaten-Anwendung im Praxiseinsatz unter Firefox.
Die Python-Skripte laden zunächst die Kometendaten in eine Mongo-DB-Datenbank. Dann lesen sie diese aus und erzeugen mit Hilfe von R den angefragten Report in Form einer Grafik, die als PNG-Datei in einem öffentlichen Verzeichnis des Webservers landet. Der sendet die URL als Antwort auf die HTTP-Anfrage an den Browser zurück. Letzterer wertet die Antwort mit Javascript-Unterstützung aus und lädt die zugehörige Grafik im Ausgabebereich über »img« -Tags nach.
Webserver
Über die Direktiven in Listing 1 bereitet ein Entwickler zunächst den Webserver Apache unter Ubuntu 12.04 auf den Einsatz der Beispielanwendung vor. Das Skript aus dem Listing kopiert er dazu mit Rootrechten in den Pfad »/etc/apache2/site-available/rconf« . Der Befehl »sudo a2ensite« bindet es in die Konfiguration des Webservers ein, über »sudo service apache restart« aktiviert der Entwickler die erweiterte Konfiguration, indem er den Webserver neu startet.
Listing 1
apache.conf
01 Listen 8080 02 <VirtualHost *:8080> 03 DocumentRoot /home/pa/www 04 <Directory /home/pa/www> 05 Options +ExecCGI 06 AddHandler cgi-script .py 07 </Directory> 08 </VirtualHost>
Die Beispielanwendung erreichen Nutzer dann über die URL »http://localhost:8080« . Zeile 1 lässt Apache auf dem Port »8080« lauschen, die Zeilen 2 bis 8 behandeln die eingehenden HTTP-Anfragen. Die Zeilen 5 und 6 erlauben es, Python-Skripte über die CGI-Schnittstelle des Webservers auszuführen, wenn sie sich im Wurzelverzeichnis »/home/pa/www« befinden.
Datenspeicher
Die Beispielanwendung nutzt das freie No-SQL-Datenbanksystem Mongo DB [4] als Datenspeicher. Die Befehle aus Listing 2 installieren die aktuelle Version 2.6.2 unter Ubuntu 12.04. Zeile 1 holt den Schlüssel für das externe Repository, Zeile 2 bindet es ein. Zeile 3 aktualisiert die Paketliste. Die letzten beiden Zeilen installieren »mongodb-org« und die aktuelle Version der Python-Schnittstelle Pymongo, wobei »easy_install« hilft.
Listing 2
Installation von Mongo DB und Py-Mongo
01 sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10 02 echo 'deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen' | sudo tee /etc/apt/sources.list.d/mongodb.list 03 sudo apt-get update 04 sudo apt-get install -y mongodb-org 05 sudo easy_install pymongo
Um den Import der Beispieldaten in Mongo DB kümmert sich das Python-Skript »import_comets.py« aus Listing 3. Der Befehl »python import_comets.py data/comets.csv« startet den Import von der Kommandozeile. Das Skript liest die Beispieldaten aus der CSV-Datei »data/comets.csv« .
Listing 3
bin/import_comets.py
01 from pymongo import MongoClient
02 import csv
03 import sys
04
05 def pfl(val):
06 try:
07 return float(val)
08 except:
09 return None
10
11 with open(sys.argv[1]) as csvfile:
12 collec = MongoClient()["galaxy"]["comets"]
13 for row in csv.reader(csvfile, delimiter="\t"):
14 try:
15 collec.insert({"name":row[0],"observer":row[1],"type":row[2],"period":pfl(row[3]), "ecc":pfl(row[4]), "semaj_axs":pfl(row[5]), "perih_dist":pfl(row[6]), "incl":pfl(row[7]), "abs_mag":pfl(row[8])})
16 except:
17 print "Error: could not import: ", row
Zeile 1 bindet die Klasse »MongoClient« aus dem Python-Paket »pymongo« ein, die nächsten beiden Zeilen importieren die Module »csv« und »sys« . Zeile 11 liest den Pfad der CSV-Datei aus dem Feld der Kommandozeilenparameter »sys.argv« , öffnet die Datei dann mit »open« und speichert den resultierenden Deskriptor in der Variablen »csvfile« .
Wenn sie noch nicht vorhanden sind, dann legt das Python-Skript in Zeile 12 die Mongo-DB-Datenbank »galaxy« und die Datensammlung »comets« an. Die Methode »reader()« liest dann die CSV-Datei ein und trennt sie anhand des Tabulatorzeichens in Spalten auf. Die »for« -Schleife holt die jeweils nächste Zeile aus dem »reader« -Objekt und speichert sie im Feld »row« . Zeile 15 legt schließlich den Datensatz aus »row« in Form eines Python-Dictionary als Schlüssel-Wert-Paare in der Mongo-DB-Datenbank ab. Zahlenwerte überführt die Funktion »pfl()« in Fließkommazahlen. Schlägt die Umwandlung fehl, gibt das Skript den Wert »None« zurück.
Die Schlüssel entsprechen den Attributen aus Tabelle 1. Die Beispieldaten geben charakteristische Parameter bekannter Kometen wieder. Sie unterscheiden sich primär durch ihre Bahnformen. Wie die Planeten bewegen sich wiederkehrende Kometen, beispielsweise der Halleysche Komet, auf Ellipsenbahnen (&0x03B5; < 1) um die Sonne, siehe Abbildung 2. Nicht wiederkehrende Kometen bewegen sich auf Parabelbahnen (&0x03B5; = 1) oder Hyperbelbahnen (&0x03B5; > 1).
Tabelle 1
Übersicht der Kometendaten
|
Attribut |
Bedeutung |
|---|---|
|
name |
Kometenname |
|
observer |
erstmals beobachtet von |
|
type |
Kometentyp: »RP« wiederkehrend regulär, »NP« nicht wiederkehrend |
|
period |
Umlaufzeit in Jahren |
|
ecc |
numerische Exzentrizität &0x03B5; der Bahn |
|
semaj_axs |
große Halbachse in Astronomischen Einheiten, 1 AE = 1,4960 x 1011 m |
|
perih_dist |
nächster Sonnenabstand in AE |
|
incl |
Einfallswinkel der Bahn in Gradmaß |
|
abs_mag |
relative Helligkeit |
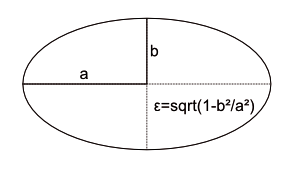
Abbildung 2: Typische Kenngrößen einer Ellipse: a – große Halbachse, b – kleine Halbachse, &0x03B5; – Exzentrizität (Kreis!=0).
Ergebnisorientiert
Bei R handelt es sich um eine freie Implementierung der statistischen Programmiersprachen S und Splus. Wie diese erleichtert R es erheblich, statistische Rechnungen auszuführen und passende Grafiken zu erzeugen (siehe Kasten “R interaktiv”). R erscheint unter der GPL und liegt in Version 3.1.2 vor. Listing 4 zeigt die Installation der aktuellen Version unter Ubuntu 12.04.
Listing 4
Installation von R unter Ubuntu 12.04
01 sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E084DAB9 02 sudo add-apt-repository ppa:marutter/rrutter 03 sudo apt-get update 04 sudo apt-get install r-base r-base-dev
R interaktiv
Wie Python lässt sich auch R in einer interaktiven Shell starten, was der Befehl »R« bewirkt. Darin lässt sich dann experimentieren. Der Ausdruck
hist(round(runif(100000, 0.5, 6.5)) + round(runif(100000, 0.5, 6.5)))
beschreibt zum Beispiel ein Würfelexperiment mit zwei Würfeln. Die Funktion »runif()« bestimmt zunächst zwei Vektoren mit jeweils 100000 gleichverteilten Zufallszahlen aus dem Intervall 0,5 bis 6,5, die »round()« anschließend komponentenweise auf 1 und 6 rundet.
Jede Komponente der Vektoren simuliert einen Würfelwurf. Der Aufruf von »hist()« erstellt für die Summe der Vektoren ein Histogramm wie in Abbildung 3. Dort sind entlang der x-Achse die Augensumme und entlang der y-Achse deren Häufigkeit aufgetragen. Wie zu erwarten ist, stellt sich eine symmetrische Verteilung um den Erwartungswert »7« heraus.
Auch die Beispieldaten zu den Kometen lassen sich interaktiv einlesen und auswerten, wenn das Ergebnis auch grafisch nicht sehr beeindruckt (Abbildung 4). Das Kommando
df = read.csv("data/comets.csv", sep="\t", dec=".")
liest die Daten der Beispielanwendung über die Methode »csv()« aus der CSV-Datei »data/comtes.csv« in die R-Sitzung ein, überführt sie in ein Objekt vom Typ Dataframe und speichert es in einer Variablen mit dem Namen »df« . Das benannte Attribut »sep=”\t”« aus dem Methodenaufruf separiert die Spalten anhand des Tabulatorzeichens, »dec=”.”« legt den Punkt als dezimales Trennzeichen fest. Die Namen der Attribute entnimmt R der ersten Zeile der CSV-Datei. Der Ausdruck »head(df)« listet schließlich den Kopf von »df« tabellenförmig auf (Abbildung 4).
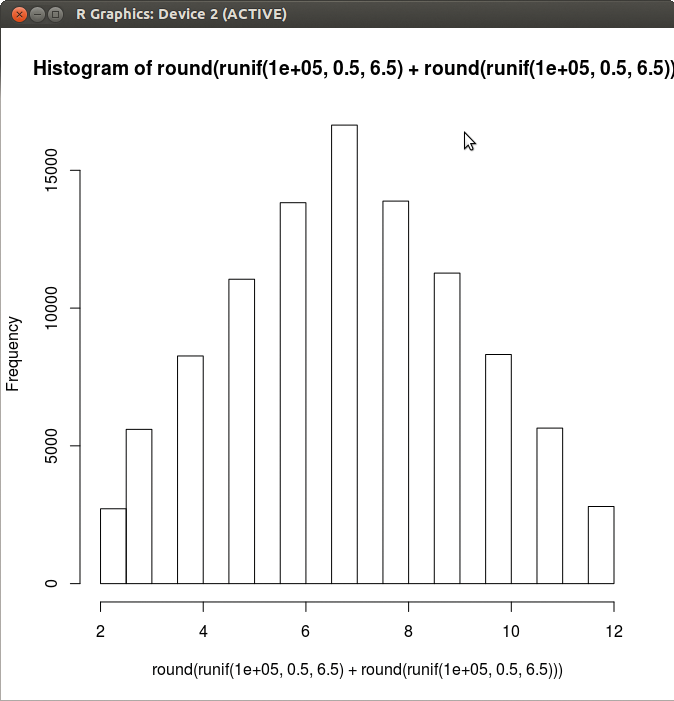
Abbildung 3: Simulation eines Würfelexperiments unter R.
Wie Javascript speichert R Werte ausschließlich in Objekten, die es lexikalisch an eine Umgebung oder ein Closure-Objekt bindet. Die am häufigsten verwendeten Datentypen sind Vektoren, Matrizen, Listen und Dataframes. R verarbeitet die Werte mit Hilfe zahlreicher Built-in-Funktionen und Operatoren, der gängigsten Kontrollstrukturen sowie benutzerdefinierter Funktionen und Operatoren. Im Comprehensive R Archive Network (Cran, [5]) finden sich zudem zahlreiche Module für R.
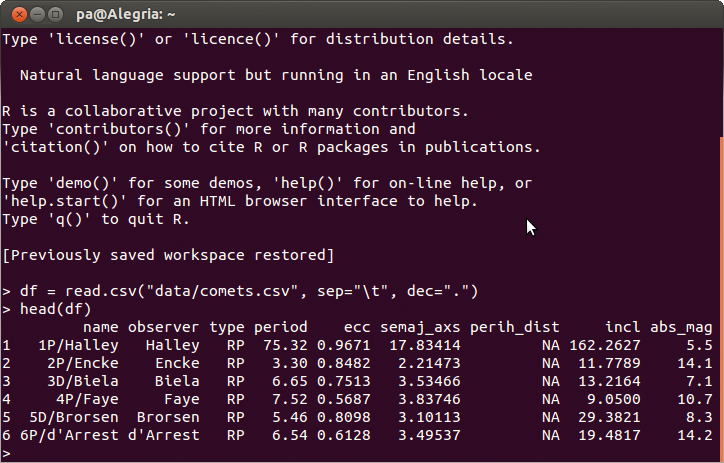
Abbildung 4: Eine interaktive R-Session listet die Beispieldaten tabellenförmig auf. Das Feature kennen Programmierer auch von Python, es hilft unter anderem beim Testen von Funktionen.
R-Schnittstelle
Die Beispielanwendung nutzt das Python-Paket Rpy2 [6] als Schnittstelle zu R. Rpy2 übergibt Daten und Funktionsaufrufe über Rs C-Schnittstelle an einen eingebetteten R-Prozess und nimmt die Ergebnisse wieder entgegen. Mit dem Modul »robjects« stellt Rpy2 darüber hinaus eine objektbasierte Schnittstelle zu R zur Verfügung, die für jeden Objekttyp aus R eine eigene Python-Klasse anbietet.
Die Funktionen aus R arbeiten auf den Objekten der Python-Klassen wie mit nativen R-Objekten: Sie überführen zum Beispiel den Python-Ausdruck »robjects.r. length(robjects.FloatVector([1.0, 2.0])« für den eingebetteten R-Prozess in den Ausdruck »length(c(1.0, 2.0))« und werten ihn dort aus. Rpy2 steht unter der GPLv2 und liegt derzeit in Version 2.5.4 vor. Listing 5 installiert die aktuelle Version von Rpy2 unter Ubuntu 12.04.
Listing 5
Installation von Rpy2
01 sudo apt-get install python-dev 02 sudo easy_install rpy2
Zum Report
Die Python-Reports der Beispielanwendung nutzen allesamt die Klasse »reporter« aus Listing 6 (Zeilen 5 bis 21), um Daten aus der Mongo-DB-Datenbank zu lesen und sie mit Hilfe von R in ein Python-Dataframe-Objekt zu überführen. Ihre Konstruktor-Funktion übernimmt in ihrer Parameterliste (Zeile 6) den Namen einer Mongo DB und einer Datensammlung, eine Liste mit Attributen sowie einen optionalen Selektor.
Listing 6
www/rreporter.py
01 from pymongo import MongoClient
02 import rpy2.robjects as ro
03 import json
04
05 class reporter:
06 def __init__(self, name, collec, keys, fexpr=None):
07 count = 0
08 doc = None
09 for doc in MongoClient()[name][collec].find(fexpr):
10 try:
11 if count == 0:
12 ro.r('df = %s' %ro.Dataframe({key: float(doc[key]) for key in keys}).r_repr())
13 count += 1
14 else:
15 ro.r('df[nrow(df)+1,] = %s' %ro.FloatVector([float(doc[key]) for key in keys]).r_repr())
16 except:
17 pass
18 self.df = ro.r('df')
19
20 def respond(self, obj):
21 print "Content-Type: application/json;charset=utf-8\n\r\n\r%s" %json.dumps(obj)
Die Zeilen 9 bis 18 iterieren über alle Einträge eines Datenbank-Cursors, den der Aufruf der Methode »find()« in Zeile 9 aus der abgefragten Datensammlung generiert. Beim ersten Schleifendurchlauf erzeugt der Konstruktor »Dataframe« (Zeile 12) aus dem übergebenen Dictionary ein Objekt. Der Generatorausdruck erzeugt das Dictionary in den geschweiften Klammern aus der Liste der übergebenen Attribute, dem Aufrufparameter »keys« und den gleichnamigen Attributwerten des aktuellen Cursoreintrags aus der Variablen »doc« . Nach der Instanzierung wandelt die Methode »r_repr()« das Objekt in eine Zeichenkette um und setzt es für »%s« in »df=%s« ein.
Der eingebettete R-Prozess wertet das Objekt mit Hilfe der Methode »r()« als Dataframe-Objekt aus. Zuletzt speichert er es in der Variablen »df« . Auf ähnliche Weise fügt der zweite R-seitige Schleifendurchlauf in Zeile 15 »df« die ausgelesenen Cursoreinträge hinzu. Diesmal verpackt die Methode »r()« die Werte in ein Objekt vom Typ »FloatVector« und fügt sie in den R-Ausdruck »df[nrow(df)+1,] = %s« ein.
Zeile 18 speichert den so erzeugten Dataframe wieder als Python-Objekt in der Komponente »self.df« . Die Python-Skripte nutzen »respond()« ab Zeile 20, um die Ergebnis-URL im Stil einer CGI-Antwort an den Webserver zu übertragen. Zeile 21 hängt das übergebene Python-Objekt dazu im Json-Format an den Header.
Listing 7 erzeugt den ersten Report. Dieser stellt die relative Häufigkeit der Bahntypen Ellipse, Parabel und Hyperbel als Tortendiagramm dar (Abbildung 1). Per Shebang »#!« wählt das Skript zuerst Python als ausführende Instanz. Über die Methode »importr()« holt es R-Module nach, dann importiert es die Klasse »reporter« aus Listing 6 sowie das Modul »robjects« .
Listing 7
www/bahntypen.py
01 #!/usr/bin/env python
02 from rpy2.robjects.packages import importr
03 from rreport import reporter
04 import rpy2.robjects as ro
05
06 devs = importr('grDevices')
07
08 main = "Verteilung der Bahntypen"
09 path = "tmp/bahntypen.png"
10
11 rep = reporter("galaxy", "comets", ["ecc"])
12 num = ro.r.nrow(rep.df)[0]
13 vals = ro.r.table(ro.r.cut(rep.df.rx2(1), [0, 0.9999, 1.0001, 2]))
14
15 label = lambda label, i: "%s %s %%" %(label, round((vals[i]*100)/num))
16 labels = [label("Ellipse", 0), label("Parabel", 1), label("Hyperbel", 2)]
17 col = ro.r.rainbow(len(labels))
18
19 devs.png(file=path, width=512, height=512)
20 ro.r.pie(vals, labels=labels, col=col, main=main)
21 devs.dev_off()
22
23 rep.respond({"fileref":path})
Zeile 6 nutzt »importr()« , um den Exportmechanismus von Grafiken in den laufenden R-Prozess einzubinden. Die Variable »main« speichert in Zeile 8 den Titel des Reports, in »path« (Zeile 9) legt das Python-Skript den Pfad der zu erstellenden Grafik relativ zum eigenen Speicherort ab. Zeile 11 erzeugt als Instanz ein Objekt der Klasse »reporter« und speichert es in der Variablen »rep« . Der Konstruktor-Aufruf übernimmt den Namen der Mongo DB (»galaxy« ) sowie der Datensammlung (»comets« ). Die Liste im dritten Aufrufparameter fordert die Werte der Exzentrizitäten an.
Zeile 12 zählt mittels »nrow« die Datensätze im Dataframe-Objekt »rep.df« und speichert das Ergebnis in der Variablen »num« . Die Methode »rx2()« kopiert zunächst die Werte aus der ersten Spalte von »rep.df« in ein Objekt vom Typ »FloatVector« . Dann bildet »cut()« die Komponenten des Vektors auf einen der drei R-Faktoren »[0-0.9999)« , »[0.999-1.0001)« oder »[1.0001-2)« ab (es sind halboffene Intervalle) und erstellt mit »table()« aus dem Ergebnisvektor eine Kontingenztafel. Die Variable »vals« speichert Letztere ab.
Die Lambda-Funktion aus Zeile 15 formatiert die Beschriftung der Tortenstücke und übernimmt dafür eine Bezeichnung in der Variablen »label« und einen Index in »i« . Aus »i« , »vals« und »num« berechnet die Funktion die relative Häufigkeit des Bahntyps in Prozent.
Indem sie die Lambda-Funktion wiederholt aufruft, erzeugt und speichert die Zeile 16 Beschriftungen im Feld »labels« , Zeile 17 erzeugt einen Farbindex für die Tortenstücke aus drei Farbstufen. Zeile 19 öffnet mittels »png()« die Datei aus der Variablen »path« , um darin die Abbildungen zu speichern. Zeile 20 erstellt mit »pie()« das Tortendiagramm. Die Funktion übernimmt die Kontingenztafel »vals« mit den Grafikoptionen der Zeilen 16, 17 und 8. Zeile 21 beendet die Ausgabe in die Datei, bevor »rep.respond()« die relative URL der Grafik als HTTP-Antwort an den Browser schickt.
Der Report »keppler3.py« aus Listing 8 verifiziert hingegen die Gültigkeit des Dritten Keplerschen Gesetzes [7]. Demnach ist das Quadrat der Umlaufzeit T eines Himmelskörpers, der sich auf einer Ellipsenbahn um die Sonne bewegt, proportional zum Kubik seiner großen Halbachse: T2~a3. Wird also a3 gegen T2 aufgetragen, so sollte sich nach Kepler eine Gerade einstellen.
Listing 8
www/keppler3.py
01 #!/usr/bin/env python
02 from rpy2.robjects.packages import importr
03 from rreport import reporter
04 import rpy2.robjects as ro
05
06 devs = importr('grDevices')
07
08 main = "3. Keplersches Gesetz"
09 path = "tmp/keppler3.png"
10
11 rep = reporter("galaxy", "comets", ["semaj_axs", "period"], {"semaj_axs":{"$lt":100}})
12 x_lab = "Grosse Halbachse / [AE]"
13 x_vals = ro.FloatVector([x**3 for x in rep.df.rx2(1)])
14
15 y_lab = "Umlaufdauer / [Jahre]"
16 y_vals = ro.FloatVector([x**2 for x in rep.df.rx2(2)])
17
18 devs.png(file=path, width=512, height=512)
19 ro.r.plot(x_vals, y_vals, xlab=x_lab, ylab=y_lab, main=main)
20 devs.dev_off()
21
22 rep.respond({"fileref":path})
Listing 8 unterscheidet sich erst ab Zeile 11 von Listing 7, indem es die Werte der großen Halbachse und der Umlaufdauer in das Dataframe-Objekt lädt. Der letzte Parameter im Konstruktor-Aufruf von Zeile 11 enthält den Mongo-DB-Selektor »{“semaj_axs”:{“$lt”:100}}« , den die aus Listing 6 übernommene Klasse »reporter« an die Methode »find()« übergibt. Der Selektor wählt nur die Daten von Kometen mit einer großen Halbachse kleiner als 100 AE aus.
In Zeile 12 speichert die Variable »x_lab« die Beschriftung der x-Achse. Zeile 13 nimmt mit dem Generatorausdruck die Werte der großen Halbachse ins Kubik und übergibt das Ergebnis an den Konstruktor der Klasse »FloatVector« , der sie in der Variablen »x_vals« ablegt.
Die Zeilen 15 und 16 wiederholen das Prozedere für die Umlaufdauer und die y-Achse, erstere quadriert das Skript jedoch nur. Die Funktion »plot()« erstellt ein Punktdiagramm, das »x_vals« gegen »y_vals« aufträgt (Abbildung 5). Die Punkte fallen wie erwartet auf eine Gerade.
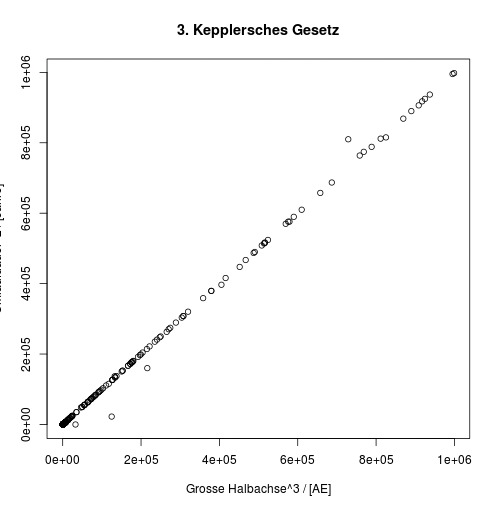
Abbildung 5: Die Kometen bestätigen das Dritte Keplersche Gesetz.
Listing 9 vergleicht die Verteilung der Exzentrizitäten für reguläre und wiederkehrende Kometen (»{“type”:”RP}« ) mit der Normalverteilung mit Hilfe des Quantil-Quantil-Plots »qqnorm()« (Zeile 14). Der Aufruf von »qqline()« zeichnet nachträglich eine Modellgerade in die Grafik. Je besser die Quantile der gemessenen Verteilung mit jener der Normalverteilung übereinstimmt, desto näher liegen die Punkte auf der Winkel-halbierenden Modellgeraden (Abbildung 6). Die Verteilung der Exzentrizitäten ähnelt der Normalverteilung weitestgehend, weicht jedoch für größere Werte von &0x03B5; zu stark davon ab. Womöglich unterliegen diese Kometen stärkeren Streuprozessen.
Listing 9
www/eccdistr.py
01 #!/usr/bin/env python
02
03 from rreport import reporter
04 from rpy2.robjects.packages import importr
05 import rpy2.robjects as ro
06
07 devs = importr('grDevices')
08
09 path = "tmp/qqnorm.png"
10
11 rep = reporter("galaxy", "comets", ["ecc"], {"type":"RP"})
12
13 devs.png(file=path, width=512, height=512)
14 ro.r.qqnorm(rep.df.rx2(1))
15 ro.r.qqline(rep.df.rx2(1))
16 devs.dev_off()
17
18 rep.respond({"fileref":path})
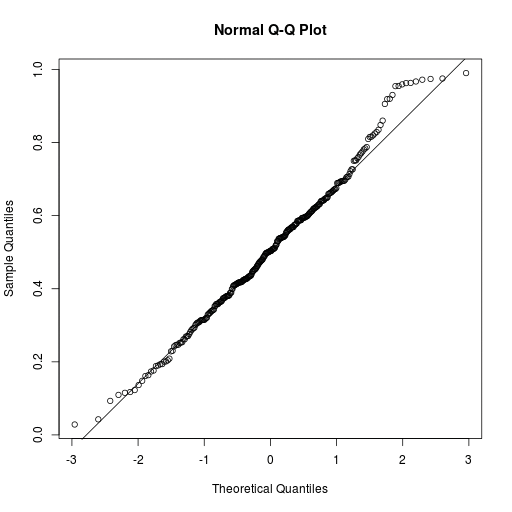
Abbildung 6: Keine normalverteilte Exzentrizität.
Webinterface
Listing 10 zeigt das HTML-Dokument der Beispielanwendung. Sein Kopf bindet in das verwendete CSS3-Stylesheet die Javascript-Bibliothek Jquery und Javascript-Code zur Reportgenerierung. Die Auswahlliste erzeugen die Zeilen 12 bis 16. Die »value« -Attribute der »option« -Elemente speichern die jeweiligen URLs der Python-Reports. Zeile 12 erzeugt den Submit-Button. Das »div« -Element, das die »id=”output”« enthält, gibt die Ergebnisse aus.
Listing 10
www/index.html
01 <!DOCTYPE html> 02 <html> 03 <head> 04 <meta charset="UTF-8"/> 05 <link href="css/styles.css" rel="stylesheet"></link> 06 <script src="//ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script> 07 <script src="js/app.js"></script> 08 </head> 09 <body class="centered"> 10 <div class="container"> 11 <form> 12 <select id="report"> 13 <option value="bahntypen.py">Verteilung der Bahntypen</option> 14 <option value="keppler3.py">3. Keplersches Gesetz</option> 15 <option value="eccdistr.py">Verteilung der Bahnexzentrität</option> 16 </select> 17 <input type="submit" value="Senden"/> 18 </form> 19 </div> 20 <div id="output" class="container"><p>Bitte wählen</p></div> 21 </body> 22 </html>
Listing 11 zeigt schließlich den Javascript-Code, den der Jquery-Ausdruck in Zeile 6 von Listing 10 einbindet. Er initialisiert den Javascript-Code der Zeilen 2 bis 17, nachdem der Browser die Webseite aus Listing 10 vollständig geladen hat. Die Rückruffunktion in den Zeilen 2 bis 8 wird beim Versenden des Formulars in Listing 10 aktiviert. In ihrem Rumpf unterbricht die Methode »preventDefault()« zunächst den Versendeprozess, bevor die folgende Zeile über die Funktion »image()« ein Loader-Bild in den Ausgabebereich schreibt.
Listing 11
www/js/app.js
01 $(document).ready(function() {
02 $('form').submit(function(e) {
03 e.preventDefault();
04 image("/img/ajax-loader.gif");
05 $.getJSON($('#report').val(), function(data) {
06 image(data.fileref);
07 }).fail(function(e) {out($('<p>').text("Error: " + e.status + " - " + e.statusText))});
08 });
09
10 function image(url) {
11 out($("<img>").attr("src", url+"?"+(Date.now())));
12 }
13
14 function out(obj) {
15 $('#output').empty().append(obj);
16 }
17 });
Ab Zeile 5 startet Jquery mittels »getJSON()« einen Report auf dem Webserver. Dabei sendet »getJSON()« eine asynchrone HTTP-Anfrage an den Webserver und erwartet ein Dokument im Json-Format als Antwort. Die URL der HTTP-Anfrage liest Jquery mittels »$(‘#report’).val()« aus dem »value« -Attribut des aktuell ausgewählten Punktes der Auswahlliste, die in Listing 10 steckt. Im Erfolgsfall verwandelt das Skript das Json-Objekt aus der HTTP-Antwort in ein Javascript-Objekt und übergibt es in der Variablen »data« an die Rückruffunktion (Zeilen 5 bis 7).
Zeile 6 lädt die Ergebnisgrafik mit Hilfe der Funktion »image()« vom Webserver im Browser nach. Die URL liest Jquery aus der Komponente »data.fileref« . Im Fehlerfall gibt Zeile 7 anstelle der Grafik eine Fehlermeldung im Browser aus. Dazu nutzt sie, wie auch der übrige Code, die Funktion »out()« (Zeilen 14 bis 16).
R-Folge
Mit der R-Schnittstelle Rpy2 lassen sich anspruchsvolle statistische Rechnungen unter R mittels Python ins Web bringen. Dabei versucht Rpy2 die Statistiksoftware R möglichst sprachgetreu unter Python zu emulieren. Das kann jedoch nur bedingt gelingen, zudem verlängert der eingebettete R-Prozess die Antwortzeit der Python-Skripte.
Der Entwickler sollte daher erwägen Alternativen einzusetzen: Zwar bettet das Apache-Modul »rApache« [8] den R-Prozess performant in den Webserver ein, jedoch wälzt es die Anwendungslogik vollständig auf R ab. Das Python-Modul Pandas [9] erfreut sich zwar wachsender Beliebtheit, emuliert bisher aber nur eine Teilmenge von R.
Infos
- Statistik-Programmiersprache R: http://r-project.org
- Python: https://www.python.org
- Jquery: http://jquery.com
- Mongo DB: http://www.mongodb.org
- Cran: http://cran.r-project.org
- Rpy2: http://rpy.sourceforge.net
- Drittes Keplersches Gesetz: http://de.wikipedia.org/wiki/Keplersche_Gesetze
- R-Apache: http://rapache.net
- Pandas: http://pandas.pydata.org





