
Abb. 1: Die Architektur von Prowler.
Der Begriff Content Management wird heute übermäßig beansprucht. Es gibt ein unübersichtliches Spektrum von Anbietern und Produkten, die sich vor allem mit Speziallösungen zu profilieren suchen. Im Folgenden wird der Ansatz des Open-Source-Projekts Infozone näher erläutert.
Das Content Management ist sehr stark mit der Entwicklung von großen Websites und den dabei auftretenden Problemen verbunden. Die schiere Menge an Daten, die Komplexität der Strukturen und des damit verbundenen Workflows macht den Einsatz von Software-Werkzeugen erforderlich.
Da die Website eines Unternehmens zunehmend strategische Bedeutung für das eigentliche Geschäft erlangt, ergeben sich für die Anbieter von entsprechenden Werkzeugen langfristige Perspektiven, die diesen neu entstandenen Markt sehr attraktiv machen. Viele große und noch mehr kleine Unternehmen wollen etwas vom Kuchen abhaben und führen deshalb ihre Produkte und Technologien unter Content Management.
Das macht den Markt zurzeit zwar etwas unübersichtlich, aber auch sehr dynamisch und interessant – vor allem da über die künftige Entwicklung keinesfalls Einigkeit herrscht und jeder Akzente setzen möchte.
Einer dieser Unterscheidungspunkte ist die Fähigkeit der einzelnen Produkte, sich in bestehende IT-Strukturen integrieren zu lassen. Hier wird auch der Anspruch des jeweiligen Anbieters deutlich. Während sich kleine Anbieter auf die Verwaltung von Websites konzentrieren, können und müssen größere Unternehmen auch die Integration mit bestehenden Softwaresystemen wie ERP, Dokumenten-Management oder Messaging-Lösungen leisten.
Websites werden dabei nicht mehr nur als Präsentationsmedium begriffen und eingesetzt, sondern zunehmend zur zentralen Informationsplattform im Unternehmen ausgebaut. Dadurch entstehen auch ganz neue Anforderungen an das Content Management: Neben redaktionellen Inhalten müssen nun auch Daten aus anderen Quellen mit einbezogen und verwaltet werden.
Infozone und Prowler
Ein sehr genereller Ansatz zum Thema Content Management kommt aus der Open-Source-Szene. Das Infozone-Projekt [1] (siehe Kasten “Das Infozone-Framework”) hat sich die Entwicklung und Integration von Komponenten für den Aufbau von Unternehmensportalen (Enterprise-Information-Portal – EIP) zur Aufgabe gemacht. Das Content-Management-Framework Prowler spielt dabei eine zentrale Rolle.
Das Infozone-Framework: Rationalisierung durch Integration |
|
Infozone wurde im Juni 2000 ins Leben gerufen. Das unter Apache-Lizenz veröffentlichte Projekt ist ein Java/XML-Komponenten-Framework für die professionelle Erstellung von komplexen Enterprise-Information-Portals (EIP). Es erlaubt die Erschließung der unterschiedlichsten elektronischen Datenquellen durch Integration. EIPs sollen in größeren Unternehmen und Organisationen durch die Kanalisierung der Informationsflüsse Rationalisierungseffekte auslösen. In diesem Kontext stellt Infozone den Mitarbeitern eines Unternehmens einen personalisierten, Browser-basierten Zugang zu allen geschäftsrelevanten Informationen bereit. Aber auch andere Bezugsgruppen wie Kunden, Lieferanten und Partner können auf alle für sie freigegebenen Datenquellen des Unternehmens zugreifen. Im Framework selbst werden einige sehr zentrale Komponenten direkt im Rahmen der Infozone-Group entwickelt. Andere stammen aus dem Apache-Projekt und werden für den Einsatz in Infozone ausgewählt und angepasst. In Abbildung 2 ist die Architektur von Infozone dargestellt. Bislang werden folgende Komponenten verwendet:
Für die Zukunft plant die Infozone-Group die Integration und Entwicklung einer Reihe weiterer Module. Ganz oben auf der Liste steht dabei Jetspeed [7] von Apache XML, das die Erstellung von personalisierten Web-Applikationen erleichtern soll. |
Prowler ist im Gegensatz zu anderen Systemen keine fertige Anwendung, sondern ein Java-Framework, dessen API sich am Java-Servlet-Modell orientiert. Dieses Framework stellt wichtige Content-Management-Funktionen wie Nutzer-, Rechte-, Versions- und Transaktionsverwaltung bereit, lässt dem Programmierer darüber hinaus aber die Möglichkeit, eigene Funktionen und Erweiterungen zu integrieren.
Transaktionales XML-File-System
Der Kern von Prowler ist ein transaktionales XML-File-System, das es ermöglicht, in eine hierarchische Struktur an beliebiger Stelle die Inhalte der zugrunde liegenden Datenquellen einzufügen. Grundsätzlich sind alle möglichen Systeme als Datenquellen integrierbar, etwa Applikations-Server, ERP-Systeme, Mail- oder Groupware-Server, RDBMS, OODBMS und was sonst noch eine Rolle in der Unternehmens-IT spielt.
Abb. 1: Die Architektur von Prowler.
Im Unterschied zu normalen File-Systemen verwendet Prowler zur Darstellung der Daten aber XML und ist transaktionssicher. Daten aus Quellen, die von sich aus kein XML liefern können, werden über spezielle Content-Adapter automatisch in XML gewandelt. Somit entsteht eine einheitliche XML-Sicht auf alle Daten, was den Aufwand für die Präsentation via Cocoon [6] und SchemoX [1] (siehe Kasten “Das Infozone-Framework”) sowie das Suchen und Weiterverarbeiten der Daten erheblich vermindert.
Neben der durchgehenden Verwendung von XML ist die Integration eines JTA/XA-konformen Transaktions-Managers [2] eine weitere Besonderheit von Prowler. Dieser macht den Zugriff auf verschiedene transaktionale Datenquellen möglich, zum Beispiel Datenbanken oder Applikations-Server, innerhalb einer globalen Transaktion oder einer HTML-Seite. Die Konsistenz der Daten wird vom Transaktions-Manager über Zwei-Phase-Commit sichergestellt.
Darüber hinaus ist er für die flexible Zuordnung von Transaktionen zu Server-Threads verantwortlich und deshalb gerade für Web-Applikationen mit Tausenden gleichzeitigen Nutzern ein wichtiger Faktor für deren Skalierbarkeit [3].
Prowler ist also kein erweitertes Redaktionssystem, sondern eine Datenintegrations-Technologie, die den transaktionalen Zugriff auf den Inhalt verschiedenster Datenquellen über eine XML-Schnittstelle ermöglicht.
Ein Beispiel
Um die Sache nicht zu abstrakt werden zu lassen, werden wir die Funktionsweise von Prowler an einem einfachen Beispiel verdeutlichen. Unsere kleine Applikation soll zwei Dinge erledigen: den Inhalt einer SQL-Datenbank abfragen und darstellen sowie ein XML-Dokument in einer Datenbank ablegen.
Folgende Datenquellen bekommt Prowler als Ressourcen zur Verfügung gestellt: eine SQL-Datenbank in Form von PostgreSQL [4] und eine Datenbank, die direkt XML speichern kann in Form von Ozone/XML [5].
Welche Datenquellen mit welchen Parametern in einer Prowler-Applikation verwendet werden, ist unabhängig von der eigentlichen Logik in einer XML-Datei beschrieben. Listing 1 zeigt die Konfiguration für das Beispiel. Wir gehen davon aus, dass Prowler schon installiert wurde und dass alle Dateien im aktuellen Verzeichnis liegen.
Listing 1: Prowler-Konfigurationsdatei |
<?xml version="1.0" encoding="UTF-8"?>
<properties>
<prowler adapter="document"
loglevel="info warn error debug debug2 debug3 " name="intranet">
<usermanager factory="org.infozone.prowler.um.lightweigt.LeightweightUserManager"/>
<tr>
</prowler>
<adapter alias="document"
factory="org.infozone.prowler.adapter.ProwlerDocumentAdapter"
xmlcache="ozonexml">
<prop name="versioning" value="false"/>
</adapter>
<adapter alias="db2xml"
factory="org.infozone.prowler.adapter.sql.DB2XMLAdapter"
xmlcache="ozonexml">
<prop name="propsFile" value="db2xml.properties"/>
<res name="postgres_jdbc"/>
</adapter>
<resource alias="postgres_jdbc" factory="org.infozone.prowler.resource.jdbc.JDBCResourceImpl">
<prop name="xadatasource" value="org.infozone.prowler.resource.jdbc.PostgresXADataSourceFactory"/>
<prop name="pass" value=""/>
<prop name="hostname" value="localhost"/>
<prop name="port" value="5432"/>
<prop name="database" value="test"/>
<prop name="user" value="test"/>
<prop name="protocol" value="postgresql"/>
<prop name="driver" value="org.postgresql.Driver"/>
</resource>
<resource alias="ozonexml" factory="org.infozone.prowler.resource.ozone.OzoneXMLResource">
<prop name="user" value="intranet"/>
<prop name="url" value="ozonedb:remote://localhost:3333"/>
<prop name="passwd" value=""/>
</resource>
</properties>
|
Wir definieren zwei Ressourcen: postgres_jdbc stellt die Verbindung zu PostgresSQL über JDBC her und ozonexml ist für die Anbindung von Ozone zuständig. Um den Inhalt beider Ressourcen als XML zur Verfügung zu stellen, definieren wir zwei Adapter: db2xml konvertiert die relationalen Daten aus PostgreSQL mit Hilfe des RDBMS/XML-Mapping- Tools DB2XML nach XML. Dagegen konvertiert document keine Daten, sondern speichert die XML-Dokumente in seinem Cache, hier in ozonexml, ab und kann sie von dort auch wieder lesen.
Nun zur eigentlichen Applikation. Grundsätzlich gibt es zwei Wege, um mit Prowler zu arbeiten. Einmal direkt über ein Java-API und zum anderen über eine Cocoon-XSP-Library für die Realisierung von Webseiten. Wir werden beide Wege kurz demonstrieren.
Die Java-API
Im ersten Teil der Applikation werden wir mit der Java-API ein Repository aufbauen und ein XML-Dokument in Prowler ablegen. Als XML-Dokument verwenden wir eines der allseits bekannten und geliebten Shakespeare-Dramen, nämlich hamlet.xml. Demgegenüber enthält die SQL-Datenbank eine einfache Tabelle adressen mit den Spalten name, vorname und wohnort, die schon ein paar Einträge enthält. Der um das Exception-Handling gekürzte Code ist in Listing 2 zu sehen.
Listing 2: Java-Code der Beispielklasse |
import org.infozone.prowler.*;
import org.w3c.dom.*;
import javax.xml.parsers.DocumentBuilder;
public class ProwlerTest {
public static void main( String[] args ) throws Exception {
// 1. Prowler initialisieren
Prowler prowler = new Prowler( "prowler.xproperties" );
// 2. Session oeffnen
session = prowler.newSession( "root", "" );
session.open( null );
// 3. Root-Dokument parsen und setzen
DocumentBuilder db = ProwlerServices.newDocumentBuilder();
Document doc = db.parse( "rootdoc.xml" );
session.setRootDocument( doc );
// 4. `hamlet.xml' parsen und einbinden
doc = db.parse( "hamlet.xml" );
session.addDocument( doc, Prowler.newAdapterID( "document" ),
new ProwlerRepositoryPath( "/root/hamlet", session.rootDocument() ) );
// 5. Session schließen und Prowler herunterfahren
session.close();
prowler.shutdown();
}
}
|
In Schritt 1 und 2 wird Prowler initialisiert und dann eine Session geöffnet. In Schritt 3 wird die Applikations-spezifische Prowler-Struktur (also das Root-Dokument) erzeugt. Diese Struktur ist wieder XML und sieht für das Beispiel wie folgt aus:
<?xml version="1.0" encoding="UTF-8"?> <root> <hamlet/> <adressen prowler:href="" prowler:type= "adapter"/> </root>
Interessant ist hier der schon eingefügte Link auf die Adressen-Tabelle. Eine solche Verlinkung kann natürlich auch über das API hergestellt werden. prowler:href verweist dabei auf den Adapter db2xml mit der Tabelle adressen. Das heißt also, dass an dieser Stelle wird bei Bedarf die Tabelle als XML Dokument eingeblendet wird.
Als Nächstes speichern wir mit addDocument() Shakespeares hamlet.xml und setzen einen Link darauf in das hamlet-Tag. Damit wäre auch schon die erste Applikation fertig und nach deren Ausführung ein kleines Repository erzeugt.
Cocoon als Front-End
Die Java-API wird aber nur zur Programmierung der jeweils spezifischen Präsentationslogik einer Applikation verwendet. Alles andere geht wesentlich einfacher, zum Beispiel über die Prowler-XSP-Library. Mit deren Hilfe lässt sich Prowler-Content via Cocoon dynamisch in XML-Dokumente einbauen und danach in HTML, WML, PDF oder ein anderes Ausgabeformat umwandeln. Um die Prowler-XSP-Library in Cocoon nutzen zu können, muss zunächst das Cocoon-Konfigurations-File wie folgt erweitert werden:
processor.xsp.logicsheet.prowler.java = resource://org/infozone/ui/xsp/prowler.xsl
Ziel unserer Beispielseite ist es, die Adressen der Leute anzuzeigen, die Meyer heißen. Wie das aussieht, zeigt Listing 3.
Listing 3: Eine XML-Seite für Cocoon |
<?xml version="1.0"?>
<! File: meyers.xml >
<?cocoon-process type="xsp"?>
<?cocoon-process type="xslt"?>
<?xml-stylesheet href="mystyle.xsl" type="text/xsl"?>
<! Hier wird der prowler-Namespace definiert und damit die entsprechende
XSP-Library eingebunden >
<xsp:page
xmlns:xsp="http://www.apache.org/1999/XSP/Core"
xmlns:response="http://www.apache.org/1999/XSP/Response"
xmlns:prowler="http://www.infozone-group.org/prowler">
<page>
<! Einloggen >
<prowler:login id="login" user="root" passwd="" properties="prowler.xproperties"/>
<prowler:onSuccess idref="login">
<! Adressen suchen >
<prowler:xpathQuery path-order="path1 path2" id="adressen">
<prowler:path id="path1">/root/adressen</prowler:path>
<prowler:path id="path2">/database/table0/record0[name/text()='Meyer']</prowler:path>
</prowler:xpathQuery>
<prowler:onError idref="adressen">
Fehler beim Auslesen der Adressen.
</prowler:onError>
</prowler:onSuccess>
<prowler:onError idref="login">
Login fehlgeschlagen.
</prowler:onError>
</page>
</xsp:page>
|
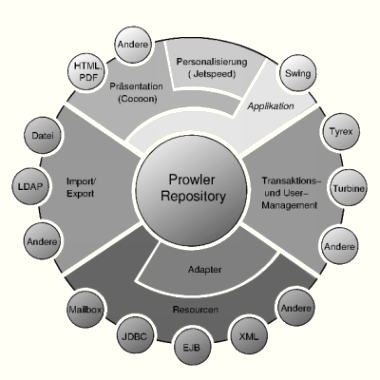
Abb. 2: Die Infozone-Architektur
Zuerst kommt wieder das übliche Einloggen. Dann geht’s gleich mit der Abfrage per XPath weiter. Dazu müssen wir praktisch einen (X)Pfad durch das Repository angeben. Das pathorder-Attribut gibt an, in welcher Reihenfolge die angegebenen Pfade abgearbeitet werden sollen.
Wir fangen bei dem Root-Dokument mit /root/adressen an und hangeln uns von Link zu Link weiter. Da hier nur ein Link zu überspringen ist, enthält der nächste XPath-Teil auch schon die eigentliche Anfrage: /database/table0/ record0 [name/text() =’Meyer’]. Das Ergebnis wird als DOM-Baum geliefert und per XSP in das XML-Dokument eingebaut. Ein hier nicht gezeigtes Style Sheet verwandelt die Ausgabe in HTML und schickt sie zum Browser. Die kleine Web-Applikation kommt ohne eine einzige Zeile Java-Code aus, leistet aber ziemlich viel.
Genauso einfach wie der eigentliche Zugriff auf die Daten sind auch die weiteren Funktionen von Prowler über eine Java-API oder eine XSP-Library zu benutzen. Zum Beispiel sind das die Nutzer-, Rechte- und Versionsverwaltung, Workflow-Unterstützung, Transaktionsverwaltung und der Export/Import des gesamten Inhalts in ein File-System oder andere Formate.
Das alles kann im Rahmen dieses Artikels nicht beschrieben werden. Trotzdem konnten wir hoffentlich einen Einblick in das Content Management im Allgemeinen und Prowler im Besonderen geben. Fragen zum Artikel oder zu Prowler sind bei den Autoren oder gleich in der Prowler-Mailing-Liste jederzeit willkommen. ( uwo)n
Infos |
|
[1] http://www.infozone-group.org [2] http://java.sun.com/products/jta |
Die Autoren |
|
Die Autoren Gerd Müller, Falko Bräutigam und Robert Strunz arbeiten bei der SMB GmbH in Leipzig. Als Diplom-Informatiker befassen sich Falko und Gerd neben ihren Aufgaben im Management vorrangig um technologische Fragen in Bezug auf Infozone. Robert ist verantwortlich für die Unternehmenskommunikation von SMB. |





