
© photocase.com
Der effiziente, Ressourcen-schonende Umgang mit sehr großen Datenmengen fordert vom Datenbankserver spezielle Fähigkeiten. Informix bietet dem DBA für diesen Zweck das Konzept der fragmentierten Tabelle.
Branchenriese IBM hat mit Informix und DB2 gleich zwei dicke kommerzielle Datenbanken in seinem Portfolio, beide laufen auch unter Linux. Dabei kursierten nach der Übernahme von Informix durch IBM im Jahr 2001 zunächst Spekulationen über die Zukunft der Produkte. Inzwischen aber hat sich der Informix Dynamic Server (IDS) neben DB2 als bevorzugte Plattform für OLTP-Anwendungen (Online Transaction Processing) etabliert. In dieser Rolle kommen seine Vorzüge, etwa die Ressourcen-schonende Multithreading-Technologie oder seine Fragementierungs-Mechanismen, besonders gut zum Tragen. Letztere sind Thema dieses Artikels.
Als Beispiel dient ein Mobilfunk-Unternehmen, das die Gesprächsdaten seiner Kunden (CDRs, Call Detail Records) für die Dauer von 80 Tagen in einer Informix-Tabelle ablegt. Die Eckdaten lauten: zehn Millionen Kunden, durchschnittlich fünf CDRs pro Kunde und Tag, 80 Tage Aufbewahrungsdauer.
Die resultierende Tabelle muss also rund vier Milliarden Datensätze aufnehmen. Täglich sind rund 50 Millionen neue CDRs zu laden, etwa die gleiche Datenmenge – nämlich die CDRs des 81. Tages – ist aus der Tabelle zu entfernen.
Fragmentierungs-Konzepte
Eine fragmentierte Tabelle besteht aus mehreren physischen Komponenten, die jeweils nur eine Teilmenge der gesamten Daten enthalten. Gegenüber dem Benutzer beziehungsweise der Applikation präsentiert Informix diese Tabelle jedoch als logische Einheit. Der Administrator kann, ohne eine Änderung an der Applikation vorzunehmen, jede normale Tabelle in eine fragmentierte Tabelle überführen. Dabei unterscheidet Informix zwei Verfahrensweisen: die ausdruckbasierte Fragmentierung (Expression Based) und die Umlauf-Fragmentierung (Round-Robin).
Die Wahl zwischen diesen Methoden fällt bereits beim Anlegen der Tabelle oder später über ein »Alter Table«-Statement. Dabei legt der Administrator auch die DB-Spaces, also die logischen Speicherorte, fest, die ihrerseits aus so genannten Chunks bestehen, denen wiederum physische Volumes oder Raw Devices entsprechen.
Bei der Round-Robin-Fragmentierung erfolgt jeder Insert abwechselnd in die für diese Tabelle definierten DB-Spaces. Diese Methode ist in der Praxis selten anzutreffen, da auch Disk-Striping auf der darunter liegenden Ebene physischer Platten ähnliche Effekte erzielt. Ein weiterer Nachteil ist, dass der Informix-interne Optimierer bei diesem Verfahren nicht feststellen kann, ob die in einem Fragment gespeicherten Daten für das Ergebnis womöglich irrelevant sind und gar nicht berücksicht werden müssten (Fragment-Eliminierung).
Effizienter ist die ausdruckbasierte Methode, die eine gezielte Aufteilung der einzelnen Tabellenfragmente anhand einer in SQL formulierten Bedingung erlaubt. Sie ermöglicht es dem Optimierer auf Grundlage der dabei verwendeten Where-Klausel, bestimmte Fragmente von der Suche nach den Ergebnissen von vornherein auszuschließen. Je nach Granularität der Fragmentierung und Art der Abfrage verbessert sich dadurch die Performance ganz erheblich.
Tages-Tabelle
Listing 1 zeigt das Anlegen einer fragmentierten Tabelle zur Speicherung der Call Detail Records. Insgesamt entstehen 80 Fragmente, die die Daten eines einzelnen Tages – also jeweils rund 50 Millionen Datensätze – beinhalten. Wichtig ist, dass die Fragmentierungs-Klausel auf relativ statischen Spalten beruht. Wenn sich nämlich die zugrunde liegende(n) Spalte(n) häufig ändern, führt dies zur Verschiebung von Datensätzen innerhalb der Fragmente. Das gilt es aus Performancegründen zu vermeiden.
|
Listing 1: Anlegen einer |
|---|
01 CREATE TABLE cdr_all_data 02 ( 03 cdr_id CHAR(20) NOT NULL, 04 cdr_date DATETIME YEAR TO SECOND NOT NULL, 05 ... 06 ... 07 ) 08 FRAGMENT BY EXPRESSION 09 cdr_date BETWEEN '2006-01-01 00:00:00' AND '2006-01-01 23:59:59' IN cdr_dbs1, 10 cdr_date BETWEEN '2006-01-02 00:00:00' AND '2006-01-02 23:59:59' IN cdr_dbs2, 11 cdr_date BETWEEN '2006-01-03 00:00:00' AND '2006-01-03 23:59:59' IN cdr_dbs3, 12 ... 13 ... 14 cdr_date BETWEEN '2006-03-22 00:00:00' AND '2006-03-22 23:59:59' IN cdr_dbs80'; 15 16 CREATE INDEX ix_cdr_id on cdr_all_data(cdr_id); |
Ohne Ladehemmung
Eine tägliche Aufgabe besteht darin, die am Vortag angefallenen CDR-Daten in die Datenbank einzuspeisen. Das Laden dieser Daten in eine Tabelle mit bereits vier Milliarden vorhandenen Datensätzen würde – nicht zuletzt wegen der Pflege des riesigen Indexbaums – sehr viel Zeit und Ressourcen kosten. Auch das vorherige Löschen der bestehenden Indizes, das anschließende Laden der Daten und der Neuaufbau der Indizes scheint in Anbetracht der Datenmenge wenig praktikabel.
Zudem ließen sich während dieser Zeit aufgrund der temporär fehlenden Indizes bestimmte Abfragen auf die CDR-Daten gar nicht mehr ausführen, denn ein sequenzieller Tablescan, den die Datenbank ohne Index wählen müsste, hätte wegen der vielen Datensätze einen inakzeptablen Zeitbedarf.
Die Informix-Lösung besteht darin, die täglichen Datensätze zunächst in eine eigenständige Tabelle zu laden, die sich später in eine übergeordnete Tabelle einklinkt. Das Laden geschieht in der Regel mit Hilfe des High Performance Loader (HPL). Dabei handelt es sich um ein mächtiges, im Datenbankserver integriertes Utility, das den Vorgang parallelisiert. Im Express-Modus werden die Daten, unter Umgehung des Bufferpools, direkt in den Speicher der Datenbank geschrieben. Das Laden ist so – abhängig von vorhandener CPU- und I/O-Bandbreite – in wenigen Minuten beendet.
Anhänglich
Der folgende Code zeigt die Definition einer Tagestabelle. Wichtig für das spätere Einhängen der Tages- in die Haupttabelle ist der Check-Constraint auf die Spalte »cdr_date«. Er stellt sicher, dass die neu zu ladenden Datensätze bereits dem in der Fragmentierungs-Klausel angegebenen Wertebereich entsprechen:
CREATE TABLE cdr_day_data ( cdr_id CHAR(20) NOT NULL, cdr_date DATETIME YEAR TO SECOND NOT NULL CHECK (cdr_date BETWEEN '2006-03-23 00:00:00' AND '2006-03-23 23:59:59') ) in cdr_dbs1;
Es empfiehlt sich, im Anschluss an den Ladevorgang ein »update statistics« auf die neu geladene Tabelle durchzuführen. Ein »attach« übernimmt die dabei ermittelten Informationen beim anschließenden Einhängen der Tagestabelle als Fragment einer übergeordneten Tabelle. So kann sich der Admin einen zeitintensiven Statistik-Lauf für die Milliarden-Datensätze-Tabelle sparen.
Das schon erwähnte Anhängen des Fragments an die Haupttabelle demonstriert das folgende Listing:
ALTER FRAGMENT ON TABLE cdr_all_data ATTACH cdr_day_data AS (cdr_date BETWEEN '2006-03-23 00:00:00' AND '2006-03-23 23:59:59');
Die Tabelle »cdr_day_data« enthält die CDR-Daten des aktuellen Tages. »attach« verwandelt sie in ein Fragment der Tabelle »cdr_all_data«. Intern findet lediglich eine Änderung im Data-Dictionary statt, die nur Millisekunden kostet. »cdr_day_data« existiert danach nicht mehr als eigenständige Tabelle, sondern bildet ein neues Fragment der Tabelle »cdr_all_data«.
Informix muss keinen zusätzlichen Scan der Daten vornehmen, da der Check-Constraint auf Tabelle »cdr_day_data« die Konsistenz der Daten gewährleistet. Auch ein zeitaufwändiger Neuaufbau der Indizes entfällt in diesem Fall, denn der Indexbaum der Tabelle »cdr_day_data« wird – wie die Daten selbst – in ein Fragment des Indexbaums der Tabelle »cdr_all_data« überführt.
Löschen durch Aushängen
Neben dem Laden der neu angefallenen CDRs müssen die Daten des 81. Tages, konform zu den gesetzlichen Vorgaben, aus der Tabelle verschwinden. Das konventionelle Löschen von 50 Millionen Datensätzen würde neben einer hohen Belastung der CPU auch zu unübersehbar vielen Einträgen in den Transaktions-Logs führen. Diese erhebliche CPU- und I/O-Belastung ist zu vermeiden.
Die Informix-Lösung: »detach« separiert wieder das für den zu löschenden Tag reservierte Fragment in eine unabhängige Tabelle. So gelangen die Daten des 81. Tages, die im DB-Space »cdr_dbs0« lagern, in eine eigene Tabelle »cdr_old_data«. Die Detach-Operation führt abermals nur eine Änderung im Data-Dictionary der Datenbank durch und ist in Sekundenbruchteilen abgearbeitet.
ALTER FRAGMENT ON TABLE cdr_all_data DETACH cdr_dbs0 cdr_old_data;
Das zeitaufwändige, Ressourcen-intensive Löschen von 50 Millionen Datensätzen entfällt.
Parallel lesen
Die bisherigen Beispiele erläuterten den Nutzen der Fragmentierungs-Technologie bei Lade- und Löschoperationen. Aber auch beim Lesen ergeben sich deutliche Geschwindigkeitsvorteile. Abbildung 1 zeigt die Abarbeitung von drei Select-Anfragen an die fragmentierte Tabelle »cdr_all_data«. Neben dem gleichzeitigen Durchsuchen mehrerer Fragmente (Query 1 und 3) lassen sich – je nach Art der Anfrage – auch komplette Fragmente ausklammern (Query 2 und 3). Parallelisierung und Fragment-Eliminierung zusammen erlauben effizientes Durchsuchen großer Datenmengen.
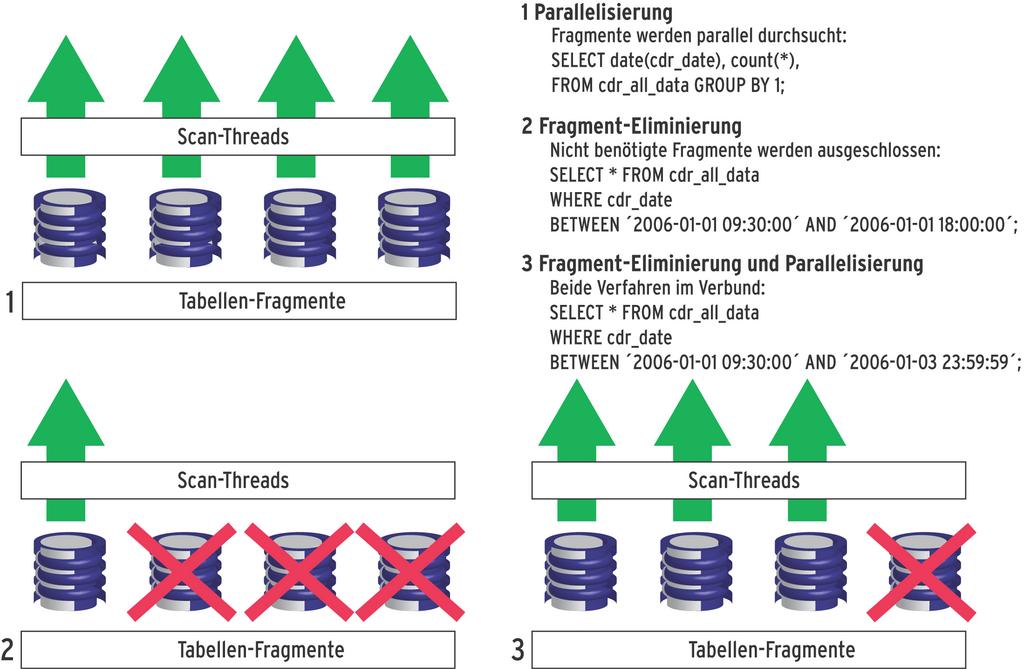
Abbildung 1: Bei der Bearbeitung von Selects kann eine fragmentierte Tabelle verschiedene Optimierungspotenziale gleichzeitig ausschöpfen.
Tabelle 1 zeigt einen Vergleich der Ausführungszeiten der drei Abfragen aus Abbildung 1 für eine normale, unfragmentierte und für eine fragmentierte Tabelle mit CDR-Daten. Die gemessenen Ausührungszeiten sind stark von der zugrunde liegenden Hardware abhängig, die hier aufgeführten Ergebnisse liefern darum lediglich einen Anhaltspunkt. Eine geschickte Verteilung der Daten auf möglichst viele Platten und der Einsatz mehrerer CPUs bringen besonders bei der parallelen Verarbeitung mehrerer Fragmente ganz entscheidende Performancevorteile.
|
Tabelle 1: Vergleich |
||
|---|---|---|
|
Abfrage |
CDR-Tabelle unfragmentiert |
CDR-Tabelle fragmentiert |
|
Query 1 |
1480 s |
185 s |
|
Query 2 |
1468 s |
21 s |
|
Query 3 |
1472 s |
26 s |
Fragmentierte Indizes
Informix erlaubt das Anlegen von Indizes auf fragmentierte Tabellen, wobei es die folgenden Arten unterscheidet:
- Index analog zur Tabelle fragmentiert (Default),
- Index mit expliziter Fragmentierungs-Klausel,
- Index unfragmentiert in einem separaten DB-Space.
Per Default liegen die Indexfragmente in denselben DB-Spaces wie die Daten. Ein wesentlicher Vorteil dabei ist, dass bei einem »attach« oder »detach« eines Fragments kein Neuaufbau des Index notwendig ist. Ein »attach« wandelt den auf der einzuhängenden Tabelle bereits vorhandene Index analog zu den Daten in ein Indexfragment der aufnehmenden Tabelle um.
Fehlen Indizes in der einzuhängenden Tabelle, ist Informix clever genug, diese vorher selbstständig anzulegen und in ein Indexfragment der aufnehmenden Tabelle zu konvertieren. Dank dieser Technik kann ein Neuaufbau der Indizes für die Monstertabelle mit ihren Milliarden Datensätzen entfallen.
Bei einem eindeutigen (»unique«) Index muss die zur Fragmentierung der Daten gewählte Spalte auch Bestandteil dieses Index sein. Hintergrund dafür ist, dass Informix sonst bei jedem Insert eines neuen Datensatzes oder bei einem Update für diese Spalte alle Indexfragmente durchsuchen müsste, um die Eindeutigkeit sicherzustellen.
Indizes mit einer expliziten Fragmentierungs-Klausel eignen sich sowohl für fragmentierte als auch für unfragmentierte Tabellen. Je nach Art der Zugriffe hat es durchaus Sinn, eine von der der Daten abweichende Fragmentierungs-Strategie zu wählen.
Erweiterungen in IDS 10
Bisherige IDS-Versionen erwarteten für jedes Fragment einen separaten DB-Space. Bei einer breit angelegten Fragmentierung, beispielsweise mit 365 Fragmenten für jeden einzelnen Tag des Jahres, führen das Anlegen und die Überwachung dieser 365 DB-Spaces zu einem nicht unerheblichen administrativen Mehraufwand. Die aktuelle Informix-Version schafft hier Abhilfe. IDS 10 erlaubt nämlich das Anlegen gleich mehrerer Partitionen eines Fragments im gleichen DB-Space.
Der »CREATE TABLE«-Befehl aus Listing 2 zeigt, wie der Anwender eine fragmentierte Tabelle anlegt, die sich aus mehreren Partitionen pro Fragment zusammensetzt. Die einzelnen Automarken liegen in diesem Beispiel in separaten Fragmenten, pro Fragment gibt es für jedes Automodell eine eigene Partition innerhalb des gleichen DB-Space. Partitionen erlauben die Anwendung einer beliebig granularen, ausdruckbasierten Fragmentierung, ohne dass nennenswerter Overhead anfällt.
|
Listing 2: Mehrere Partitionen |
|---|
01 CREATE TABLE car_data 02 ( 03 car_vendor char(20) not null, 04 car_type char(5) not null, 05 ... 06 ) 07 FRAGMENT BY EXPRESSION 08 PARTITION p_audi_a2 (car_vendor = "Audi" and car_type ="A2") in audi_dbs, 09 PARTITION p_audi_a3 (car_vendor = "Audi" and car_type ="A3") in audi_dbs, 10 PARTITION p_audi_a4 (car_vendor = "Audi" and car_type ="A4") in audi_dbs, 11 PARTITION p_audi_a6 (car_vendor = "Audi" and car_type ="A6") in audi_dbs, 12 ... 13 ; |
Konfigurationsoptionen
Wer sich für das Schema einer fragmentierten Tabelle interessiert, dem hilft der Schalter »-ss« beim Aufruf des »dbschema«-Utility (Listing 3a). Analog dazu kann man auch das Data-Dictionary der jeweiligen Informix-Datenbank abfragen (Listing 3b). Der Admin darf Insert-, Update- und Delete-Rechte individuell pro Fragment vergeben. Voraussetzung dafür ist eine ausdruckbasierten Fragmentierung. Die Systemtabelle »sysfragauth« gibt Auskunft über diese Berechtigungen.
|
Listing 3a: Schema |
|---|
01 dbschema -d DB-Name -t Tab-Name -ss |
|
Listing 3b: Schema |
|---|
01 select st.tabname, sf.strategy,sf.exprtext, sf.nrows,sf.dbspace, sf.partitionfrom systables st, sysfragments sfwhere st.tabid = sf.tabidand st.tabname = Tab-Name; |
Gibt der Admin beim Anlegen einer fragmentierten Tabelle Extent-Größen vor, muss er darauf achten, dass sich die jeweilige Angabe dann auf ein einzelnes Fragment und nicht etwa auf die Gesamttabelle bezieht. Als Extents bezeichnet Informix in diesem Zusammenhang die Zusammenfassung mehrerer hintereinander liegender Datenbankpages zu einer logischen Einheit.
Die IDS-Version 10 erlaubt unterschiedlicher Pagegrößen beim Anlegen von DB-Spaces. Dabei gilt jedoch die Einschränkung, dass alle DB-Spaces, die Fragmente derselben Tabelle enthalten, eine einheitliche Pagegröße aufweisen müssen. Hingegen darf sich die Pagegröße für Daten- und Indexfragmente unterscheiden.
Implizite und explizite temporäre Tabellen
Implizite temporäre Tabellen (»select into temp«) verteilt Informix selbstständig nach dem Round-Robin-Verfahren in die zur Verfügung stehenden temporären DB-Spaces. Sinnvoll ist es, mehrere temporäre DB-Spaces anzulegen und sie mit Hilfe des Konfigurationsparameters »DBSPACETEMP« bekannt zu geben. Für explizite temporäre Tabellen (»create temp table«) ist – analog zu regulären Tabellen – eine dedizierte Fragmentierungs-Strategie möglich.
Informix versucht eine Fragment-Eliminierung nicht nur bei einem expliziten Zugriff auf eine fragmentierte Tabelle vorzunehmen. Auch bei Nested-Loop-Joins kann zum Beispiel durchaus eine Fragment-Eliminierung in der inneren Tabelle stattfinden.
Beim Fragmentierungs-Schema ist die Angabe einer Remainder-Klausel möglich. In dieses Remainder-Fragment sortiert die Datenbank alle Datensätze ein, die sie keinem Fragment zuordnen kann. Ohne bestehendes Remainder-Fragment erhält die Applikation einen entsprechenden SQL-Fehlercode vom Datenbankserver, falls keine der verwendeten Fragmentierungs-Klauseln die Zuordnung zu einem Fragment gestatten würde.
Fazit
Das effiziente Verwalten sehr großer Datenmengen erfordert spezielle Fähigkeiten des Datenbankservers. Informix gibt dem Administrator hierfür mit der fest im Datenbankkern integrierten Fragmentierungs-Technologie ein mächtiges Werkzeug in die Hand.
Wegen seiner Ressourcen-schonenden Multithreading-Architektur und der damit verbundenen Parallelisierungs- und Skalierungs-Möglichkeiten eignet sich der Informix Dynamic Server vor allem für jenen unternehmenskritischen Einsatz, der hohe Verfügbarkeit und Skalierbarkeit erfordert. Linux dringt gerade auch in diese Bereiche immer stärker vor und bildet dabei zusammen mit Informix ein starkes Team. (jcb)
|
Infos |
|---|
|
[1] IDS 10 Information Center: [http://publib.boulder.ibm.com/infocenter/idshelp/v10/index.jsp] [2] Informix Developer Zone: [http://www.ibm.com/developerworks/db2/zones/informix] [3] Informix Support Center: [http://www.ibm.com/software/data/informix/ids/support] [4] Informix Trial Downloads: [http://www.ibm.com/developerworks/downloads/im/ids/?S_TACT=105AGX28&S_CMP=TRIALS] [5] Informix Online Book: [http://docs.rinet.ru/InforSmes/index.htm] [6] Informix Usergroup: [http://www.iiug.org] [7] Informix Newsgroup: »comp.databases.informix« |
|
Der Autor |
|---|
|
Eric Herber arbeitet als freiberuflicher Berater für Informix und DB2. |





