
© laurentiu iordache, 123RF
Open Stack will im ganz großen Geschäft mitspielen und muss deshalb liefern. Die neue Version 2014.2 alias Juno räumt auf und leistet Modellpflege – von einer großen Neuerung abgesehen: Ironic, das Baremetal-Deployment-Tool, das wohl auf dem Sprung zur offiziellen Komponente ist.
Das Open-Stack-Projekt ([1], [2], [3]) produziert in einem strengen Takt. Im April und im Oktober stehen Releases an, koste es, was es wolle. Bis dato hat der Releasemanager Thierry Carrez dafür gesorgt, dass das Projekt diesen Plan einhielt, und auch die nächste Version von Open Stack – die 2014.2 – lag bei Redaktionsschluss voll im Plan. Mit dem Erscheinen dieses Linux-Magazins wird “Juno” bereits verfügbar sein.
Vorsichtige Erneuerung
Juno setzt die Tradition der letzten Versionen fort und kommt als sorgsam erweiterte Open-Stack-Distribution daher. Die gute Nachricht für Admins ist, dass etwa die bestehenden APIs kompatibel mit denen bleiben, die bereits da sind. Wer also Applikationen verwendet, die direkt mit den APIs reden, wird diese auch in Juno nutzen können. Insgesamt dürfte sich die Arbeit beim Upgrade von Icehouse zu Juno in Grenzen halten. Denn nach dem wilden Chaos in den ersten Open-Stack-Versionen haben die Entwickler mittlerweile verstanden, dass es dem Prestige des Projekts nicht zuträglich ist, wenn zwischen zwei Releases kein Stein auf dem anderen bleibt. Wenn sich Dinge ändern, kündigen die Entwickler das deutlich und mindestens eine Version im Voraus an – so bleibt genug Zeit, ein Upgrade sorgfältig und professionell vorzubereiten.
Ein gutes Beispiel dafür ist der Treiber für Open V-Switch in Neutron, der in Icehouse bereits als »deprecated« geflaggt war. Juno enthält den Treiber gar nicht mehr, weil er zwischenzeitlich durch das “Modular Layer 2”-Framework ersetzt worden ist, das intern meist nur ML2 heißt (Abbildung 1). Wer eine Cloud hat, die den alten »openvswitch« -Treiber nutzt, muss also auf ML2 umstellen. Doch der Arbeitsaufwand, den das verursacht, bleibt überschaubar.

Abbildung 1: Das alte Open-V-Switch-Plugin ist in Juno endgültig Geschichte. An seine Stelle tritt das ML2-Plugin für Open V-Switch, auf das Admins nun umstellen müssen – falls noch nicht geschehen.
Auch sonst hat sich in Neutron einiges getan: Der Layer-3-Agent unterstützt nun endlich inhärente Hochverfügbarkeit, ein Feature, auf das Admins sehr lange gewartet haben. Bis einschließlich Icehouse war es Neutron völlig egal, wenn der Netzwerkknoten ausfiel und damit die laufenden VMs von der Außenwelt trennte. Wollte der Admin auf Layer 3 HA nutzen, dann musste er die mit Werkzeugen wie Pacemaker selber stricken. Auch das führte allerdings nur selten zu befriedigenden Ergebnissen, brachte es doch zusätzliche Komplexität in Open-Stack-Szenarien ein.
Der Neutron-Scheduler
In Juno ist damit Schluss: Der Neutron-Scheduler kümmert sich ab sofort darum, dass L3-Netzwerke automatisch auf andere Systeme ausweichen, sollte der erste Host ausfallen. Garniert haben die Entwickler die Funktionalität mit Plugins auf Basis von VRRP, Conntrackd und Keepalived, wobei zu Redaktionsschluss noch nicht feststand, ob tatsächlich alle Plugins Bestandteil von Juno sind – für das Conntrackd-Plugin war beispielsweise die projektinterne Review noch nicht abgeschlossen. Grundsätzlich wird Neutron aber HA-Features für L3-Netzwerke in Juno beherrschen, was als Meilenstein gelten darf (Abbildung 2).
Abbildung 2: Der Layer-3-Agent in Neutron unterstützt ab Juno für externe Netze HA-Fähigkeiten, die er über Dienste wie Keepalived und Protokolle wie VRRP zur Verfügung stellt.
Und auch sonst hat sich bei Neutron in Juno einiges verändert: Neue Treiber für eine ganze Reihe von Netzwerkhardware, darunter Arista, Brocade und Nuage sind genauso an Board wie neue Load-Balancing-Treiber für Geräte von A10-Networks. In Juno wächst Neutron damit deutlich näher an Geräte heran, die regelmäßig als Infrastruktur in Rechenzentren zu finden sind.
Federation für Keystone
Keystone werkelt als ID-Komponente bei Open Stack oft nur im Hintergrund, doch wer deshalb denkt, die Anwendung sei unwichtig, irrt gewaltig. Keystone ist im Open-Stack-Kontext eine Art Root-Applikation, ohne die alle Räder still stehen. Für Juno haben sich die Keystone-Entwickler mehrere Gimmicks einfallen lassen, das wichtigste ist der Basissupport für ein Federation-Modell.
Vereinfacht ausgedrückt funktioniert das so: Ein Keystone identifiziert einen Nutzer an dessen Login-Credentials und händigt ihm – wie üblich – ein entsprechendes Token aus. Mit diesem wendet der Nutzer sich an eine andere, entfernte Keystone-Instanz, die das Token validiert und so dem Nutzer auch für die dortige Cloud den Zugriff ermöglicht. Leider ist dieses Feature für Juno noch als experimentell markiert, spätestens in der K-Release soll die Funktion aber offiziell zur Verfügung stehen.
Weitere Verbesserungen bei Keystone umfassen verbesserten LDAP-Support, komprimierte Tokens sowie viele Neuerungen bei dem API in Version 3. Es existiert parallel zum schon bekannten API in Version 2, wird dasselbe aber wohl irgendwann ersetzen.
Außerdem haben insbesondere die Hypervisor-Treiber für KVM auf Libvirt, VMware und Hyper-V in Nova neue Features erhalten. Hyper-V-VMs sind nun per Soft-Reboot zu restarten; vorher war nur ein harter Reboot möglich. Obendrein steht für Hyper-V-VMs in Zukunft ein echtes Log im Webinterface zur Verfügung, bis dato war der Log-Abschnitt für VMs, die auf Microsofts Hyper-V liefen, einfach leer.
Ein weiteres großes Projekt wirft seine Schatten voraus: Die K-Version von Open Stack wird ein Feature namens “Scheduler as a Service” bieten, und die Grundlage dieses Dienstes wird die Komponente sein, die in Juno noch als »nova-scheduler« firmiert. Um voranzukommen, hat der Nova-Scheduler schon jetzt in Juno eine große Überarbeitung erfahren.
Glance beherrscht in Zukunft das asynchrone Verarbeiten von Requests, was verschiedene Hintergrundtasks wie das Konvertieren von Images in Glance erst ermöglichen wird. Juno legt dafür allerdings nur den Grundstein, konkrete Funktionalität wird das Feature wohl erst in der K-Version entfalten.
Cinder
Cinder (Abbildung 3) zeichnet sich vor allem durch diverse neue Treiber aus, darunter welche für Datera, EMC, Prophetstore und das SMB-FS, das Dateisystem von Samba. Außerdem beherrscht Cinder nun die Replikation von Volumes, wenn die zugrunde liegende Speichertechnik das kann: Läuft Cinder beispielsweise auf zwei Storewiz-Geräten, kann es in Zukunft deren Replikation einsetzen, um lückenlose Hochverfügbarkeit zu garantieren. Praktisch dürfte die Funktion in diesem Sinne auch für Softwarelösungen zur Replikation wie beispielsweise DRBD werden.
Abbildung 3: Eine heiße Diskussion ist um ein Patch entbrannt, das Cinder um eine Option für lokalen Storage erweitert. In Juno steht es aber sicherlich noch nicht bereit.
Ceilometer
Mehr hat sich bei Open Stacks Metering-Komponente Ceilometer getan, die ab jetzt deutlich umfangreicher messen kann. Traffic, der über VPNaaS, LBaaS oder die Firewall-Lösung FWaaS läuft, entgeht dem Dienst in Zukunft nicht mehr. Zudem kann Ceilometer nun direkt per IPMI auf Maschinen zugreifen und unterstützt das Xen-API, um mit Xen-basierten Servern zu sprechen. Mit dem Deployment-Tool Ironic ist Ceilometer in Juno ebenfalls nahtlos integriert.
Auch die Performance des Dienstes hat sich gebessert: Künftig schreibt Ceilometer mit mehreren Worker-Prozessen in seine Datenbank, statt per Single-Thread wie bisher. Dadurch soll es dem Dienst möglich werden, deutlich größere Datenmengen zu verarbeiten.
Wenig Neues gibt es hingegen bei Heat, der Orchestrierungskomponente: Die war während des Release-Zyklus eher mit sich selbst beschäftigt. So sind nur einige Templatefunktionen hinzugekommen, die in der Hauptsache mehr für Nischen-Setups als die große Masse der Deployments relevant scheinen.
Dickes Ding: Ironic
Spätestens die nächste Release Kilo erhebt aber ein Stück Software zur Kernkomponente von Open Stack, auf das viele Cloud-Admins bereits händeringend warten. Erstmals wird Ironic nämlich zentraler Bestandteil der Cloudlösung sein. Open Stack erhält damit einen so genannten Baremetal-Deployment-Treiber, mit dem sich nackte Hardware direkt integrieren lässt (Abbildung 4).
Abbildung 4: Die Dienste-Liste aus Icehouse ist für Juno nicht mehr aktuell: Hinzu kommt Ironic, Novas eigener Treiber für Baremetal-Deployments.
Bisher war der Deal bei Open-Stack-Clouds stets dieser: Den tatsächlichen Funktionsumfang von Open Stack konnten Admins erst in dem Augenblick nutzen, in dem die Open-Stack-Komponenten auf ihren Systemen installiert und konfiguriert waren. Was vorher passierte, lag allein im Verantwortungsbereich des Admin selbst: Wie beispielsweise ein Betriebssystem auf die Platte kommt, war Open Stack egal.
Wer die benötigten Open-Stack-Dienste pro Host installiert und konfiguriert, das war ein Punkt, der Open Stack ebenfalls völlig kalt ließ. Auch ein Werkzeug, das die zentrale Administration der bereits vorhandenen Maschinen ermöglicht hätte, fehlte. Wer Automatisierung auf Host-Ebene wollte, musste sich mit Werkzeugen wie Razor [4], Foreman [5] oder Crowbar [6] beschäftigen.
Genau das ist aber aus mehreren Gründen unsinnig. Zunächst haben in einer Open-Stack-Installation die Hypervisor-Systeme eine sehr ähnliche Aufgabe wie die virtuellen Maschinen, die in ihnen laufen. Auch von der Struktur her ist das Blech den VMs ähnlich: Hypervisors kann es im Grunde beliebig viele geben, genauso ist die Zahl der VMs fast unbegrenzt. Mit Nova existiert allerdings bereits ein Werkzeug, das VMs innerhalb von Open Stack vorzüglich verwaltet – was spricht also dagegen, eben jenes Tool auch für die Verwaltung von Hosts zu nutzen? Hier setzt Ironic an.
Wer etwa Ubuntus MaaS schon mal genutzt hat, wird viele Ideen bei Ironic wiederfinden, denn der Treiber ermöglicht es, echtes Blech innerhalb einer Open-Stack-Wolke so zu behandeln, als bestünde es aus virtuellen Systemen. Schraubt der Admin eine Maschine ins Rack, sorgt Ironic danach per PXE und vielen anderen Werkzeugen dafür, dass der Rechner ein fertiges Betriebssystem aus Glance übergestülpt bekommt.
Offiziell läuft der Prozess unter dem Stichwort des “Baremetal Provisionings”. Am Ende steht die Installation der eigentlichen Open-Stack-Dienste, die als Cloud in der Cloud fungieren. Schmankerl sind jene Funktionen, die das automatische Bios-Update einiger Fabrikate ermöglichen oder die korrekte Konfiguration von Raid-Festplatten.
Triple O
Auch HPs Triple O (das dreifache “O” steht für Open Stack On Open Stack, [7], [8]) setzt im Kern auf Ironic. Ist ein System mit Ironic erst installiert, lässt es sich damit im Anschluss auch sehr tiefgreifend verwalten. Aber wirklich komfortabel wird die Nutzung von Ironic tatsächlich erst mit Triple O, zu dem auch ein GUI namens Tuskar gehört (Abbildung 5). Triple O ist im Open-Stack-Projekt ein sehr aktives Unterprojekt, in den letzten Monaten haben seine Entwickler viele große Brocken erledigt, um Open Stack on Open Stack zu einer funktionierenden Lösung zu machen.
Abbildung 5: Tuskar ist Bestandteil von Triple O und integriert die verschiedenen Baremetal-Dienste nahtlos in Horizon, das Open-Stack-Dashboard.
Ironic ist definitiv auf dem Weg zur offiziellen Core-Komponente, gehört also bald direkt zum innersten Kern der Umgebung. Die Entwickler verpflichten sich damit, Ironic in Zukunft zu pflegen und mit Updates zu versorgen. Der Weg, den Ironic bis zu diesem Ritterschlag nehmen musste, war alles andere als kurz: HP hat sich in großem Umfang an der Ironic-Entwicklung beteiligt, Monty Taylor stellte das Konzept bereits im Sommer 2012 beim Linuxtag in Berlin vor [9]. Künftig bringt Ironic eine echte Alternative zu anbieterspezifischen Lösungen und ermöglicht es Triple O, einer der ganz großen Open-Stack-Player zu werden.
Fazit
Einmal mehr präsentiert sich mit Juno eine Open-Stack-Version als behutsame Pflege der Vorgängerin, die außerdem ein paar pfiffige Zusatzfeatures im Gepäck hat. Die gute Nachricht für Admins ist: Wer mit Icehouse zurechtkommt, wird auch mit Juno keine Schwierigkeiten haben, denn in Sachen Bedienung gibt es kaum Differenzen.
Lediglich der Wegfall des alten Open-V-Switch-Treibers stellt das eine oder andere Setup möglicherweise vor Herausforderungen, denn wer nicht auf die Entwickler-Warnungen in Icehouse gehört hat, muss jetzt Gas geben. Der ganze Rest an Änderungen passt hingegen nahtlos ins Bild, selbst die Updates von Icehouse auf Juno sollten höchstens mittelmäßig kompliziert sein. Was sich in Sachen Automatisierung getan hat, beschreibt der Kasten “Open Stack und Automatisierung”.
Open Stack und Automatisierung
Wenn das Thema Open Stack öffentlich zur Debatte steht, geht es meist um die Kernkomponenten der Lösung, also Keystone, Glance, Nova und deren Kollegen. Eine typische Open-Stack-Installation besteht allerdings aus mehr Komponenten als diesen, und im Lichte neuer Open-Stack-Versionen schadet es nicht, auch auf die neuen Helferkomponenten einen Blick zu werfen.
Von Rabbit MQ bis zu Ansible und Saltstack
Rabbit MQ [10] und MySQL erweisen sich als verlässliche Partner, der Grad der Veränderung von einer Open-Stack-Release zur nächsten geht faktisch gegen null. Anders liegt die Sache bei den Automatisierungslösungen, die Admins bei der Wartung einer Cloud auf Open-Stack-Basis unterstützen. Wirkt bei herkömmlichen IT-Setups Automatisierung mit Puppet, Chef oder anderen Werkzeugen dieser Art wie ein nettes Gimmick, ist in Clouds das Thema Automatisierung nicht zu umgehen.
Admin-Experte und Linux-Urgestein Kristian Köhntopp betet in diesem Kontext immer wieder sein Mantra vor [11]: “Wer sich auf einer VM oder auf einem System einer Cloud einloggt, macht ein internes Ticket auf.” Denn in solchen Fällen, so die Logik, sei entweder die Automatisierung defekt oder das Logging nicht gut genug – alternativ treffen vielleicht auch beide Faktoren im gleichen Umfang zu.
Was erst mal reißerisch klingt, hat Hand und Fuß: Ist eine Cloud mit Dutzenden, vielleicht gar Hunderten Virtualisierungshosts erst mal gebaut, ist es für Admins unmöglich, jede einzelne Maschine händisch zu betreuen.
Die meisten großen Open-Stack-Deployments setzen deshalb selbstverständlich auf Automatisierung. Der Grad der Unterstützung durch die Tools ist dabei unterschiedlich: Chef funktioniert mittlerweile gut, nachdem Suse und Dell viel Zeit und Arbeit in die entsprechenden Cookbooks gesteckt haben. Für Ansible [12], Saltstack [13] und die vielen anderen Alternativen existieren Lösungen mit teils großen Unterschieden in der Qualität.
Der Quasi-Standard für die Automatisierung von Open Stack ist aber immer noch Puppet. Das liegt nicht zuletzt daran, dass die »puppet-openstack« -Module auf Stackforge gepflegt werden [14] und im Rahmen ihrer Entwicklung die gleichen Tools nutzen, auf die auch Open Stack und seine Komponenten setzen.
Wer beispielsweise ein Patch an die Entwickler für eines der Puppet-Module senden will, muss damit den gleichen Review-Prozess per Git und Gerrit durchlaufen, durch den jede Open-Stack-Änderung muss. Die Altvorderen der Entwickler der Puppet-Module heben oder senken am Ende den Daumen und bestimmen so über Wohl und Wehe der Veränderungen.
Großer Umbau
Für die Juno-Version der Module haben die Aufpasser ihren Daumen deutlich öfter gehoben als gesenkt. Die Puppet-Module, die Juno unterstützen werden, haben einen großen Umbau durchlaufen – das Stichwort in diesem Zusammenhang lautet Konsolidierung. Freilich sind für die Module auch ein paar neue Funktionen und neue Parameter hinzugekommen. Wirklich auffällig ist aber die Einführung eines Meta-Moduls, das sich »puppet-openstack-lib« nennt und gemeinsame Funktionen für alle Puppet-Module anbietet.
Gute Gründe hätte es für eine solche Funktionssammlung auch vor Juno schon gegeben, bis dato hat beispielsweise jedes Modul selbst dafür zu sorgen, dass es für einen Dienst in MySQL, PostgreSQL oder der jeweils eingesetzten Datenbank passend angelegt ist. Und jedes Modul hatte für diese Aufgabe auch den gleichen Codeblock, der somit etliche Male vorlag. Das war ineffizient und sorgte insbesondre dafür, dass Veränderungen stets an vielen Stellen in die Module zu integrieren waren. Mit Juno ist damit Schluss: Funktionen, die mehr als ein Open-Stack-Modul für Puppet benötigen, werden künftig als Meta-Funktion zur »openstack-lib« gehören und für alle Module nutzbar sein.
Wer bereits eine Puppet-basierte Open-Stack-Cloud besitzt, wird allerdings leiden, wenn er sie auf Juno updaten möchte. Die Veränderungen der Module machen je nach Ausführung der lokalen Site Manifests viele Änderungen notwendig. Wer ein solches Update plant, sollte den Punkt “Puppet” auf seiner To-do-Liste mit einem entsprechenden Zeitpolster versehen.
Anstehende Erweiterungen, die es nicht in die Juno-Version geschafft haben, etwa Trove oder der lokale Storagedienst, erläutert der Kasten “Noch nicht dabei: DNSaaS, Storage, Trove”.
Noch nicht dabei: DNSaaS, Storage, Trove
Damit sich eine Änderung ihren Weg durch den Releaseprozess bahnen kann, muss im Kreis der Entwickler Einigkeit bestehen, dass das vorgeschlagene Feature sinnvoll ist. Seit einigen Open-Stack-Releases gibt es Komponenten und Patches, die viele Admins für elementar halten, die aber aus verschiedenen Gründen noch immer keinen Eingang in Open Stack gefunden haben. In Juno vermissen Fans vor allem folgende Komponenten:
Designate – DNSaaS
Fast schon ein Klassiker unter den Komponenten ohne Lobby ist ein Dienst, der DNS as a Service für Open Stack anbietet. Weist der Nutzer einer VM eine so genannte Floating-IP zu, ist die VM anschließend öffentlich über diese VM erreichbar. Bisher fehlt allerdings jede Möglichkeit, eine Brücke von der Netzwerkkomponente Neutron zu irgendeinem DNS-Server zu schlagen. Wer mit Floating-IPs arbeitet, muss seine Domains in einem zweiten Arbeitsschritt also stets selbst aktualisieren.
Die gute Nachricht zuerst: Ein Projekt, das einen entsprechenden Dienst anbieten möchte, existiert bereits in Form von Designate (Abbildung 6). Die schlechte Nachricht ist allerdings, dass Designate erst vor ein paar Monaten richtig Fahrt aufgenommen hat und bis dato nicht mal als Aufnahmekandidat gilt, was die Core-Komponenten angeht. Entsprechend heftig fallen die Umbauten aus, die Designate gegenwärtig durchläuft; an einen stabilen Betrieb der Software ist im Augenblick jedenfalls nicht zu denken.
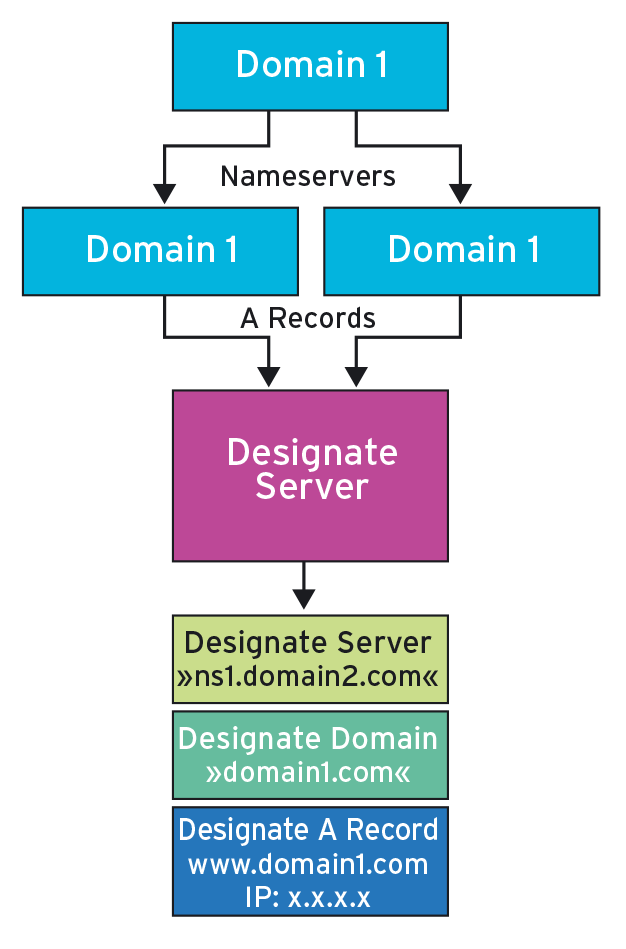
Abbildung 6: Designate alias DNS as a Service hat es leider nicht bis in Juno geschafft, ist aber ein heißer Kandidat für die K-Version, die auf Juno folgt.
Lokaler Storage
Ein weiterer Kandidat jener Features, die es gern bis in Juno geschafft hätten, ist der Cinder-Treiber für lokalen Storage. Grundsätzlich funktioniert Cinder auf Grundlage einer Netzwerkverbindung: Irgendwo läuft ein zentraler Dienst namens »cinder-volume« , der vorhandenen Storage kommissioniert und dann auf verschiedenen Wegen – per Fibre Channel, per I-SCSI oder direkt – den Speicher an die Hypervisor-Hosts ausliefert.
Diese Art Storage hat einen elementaren Nachteil, nimmt sie doch stets die vollständige Latenz mit, die sich auf der Netzwerkstrecke addiert. Im Falle von Fibre Channel oder auch Infiniband ist die Latenz gering, doch Ethernet hat eine inhärente, deutlich höhere Latenz – und die meisten Lösungen für verteiltes Speichern, an erster Stelle Ceph, nutzen Ethernet. Darunter leiden besonders Anwendungen, die über viele sequenzielle Writes funktionieren. Wer schon mal versucht hat, MySQL über Ethernet auf Ceph zu betreiben, kennt das Problem nur zu gut. Abhilfe schafft hier nur lokaler Storage. Bis jetzt fehlt allerdings ein Schalter in Open Stack, der dessen Nutzung ermöglicht. Startet ein Admin also eine VM, kann er Open Stack nicht sagen, dass diese auf einem Cinder-Volume kommissioniert werden soll, das lokal auf demselben Host verfügbar ist.
Auch hier gibt es wieder eine gute und eine schlechte Nachricht. Einerseits existiert im Git von Open Stack mittlerweile ein Patch [15], das in Cinder die Grundlagen für lokalen Storage schafft. Andererseits kam es für Juno zu spät, sodass sich Admins mindestens weitere sechs Monate gedulden müssen, bis die Funktion endlich zur Verfügung steht.
Trove, das Windei
Auch Trove kam dieses Mal nicht zum Zuge. Das Tool, das großspurig als “Database as a Service” für Open Stack gestartet ist und relativ schnell Core-Komponente wurde, hat sich seither kaum mit Ruhm bekleckert. Das liegt auch daran, dass die Lösung nicht ausgereift wirkt: Wer etwa ein Ubuntu-Image für den Betrieb mit Trove bauen will, sieht sich mit diversen Fehlermeldungen konfrontiert.
Damit nicht genug, so hat Trove doch auch offenkundige Designmängel, die die Lust an DBaaS empfindlich schmälern. Sinnvoll wäre zum Beispiel die Möglichkeit, in einer zentralen, schnellen Umgebung mit lokalem Storage (siehe oben) entsprechende Datenbankprozesse zu starten, die den Anwendern im Anschluss hochperformante Datenbanken liefern. Stattdessen ist Trove vorrangig ein Wrapper: Wenn es eine DBaaS starten soll, startet es eine normale VM, um anschließend mittels eigens konstruiertem Agenten innerhalb der VM eine Datenbank zu installieren und zu konfigurieren.
Trove tut also wenig mehr, als zu automatisieren – allerdings zuverlässiger. Auch dass Trove PostgreSQL sowie Mongo-DB-Cluster unterstützt, trägt kaum zur Verbesserung seines Ansehens bei. Wichtiger wäre es gewesen, das Trove-Design zu überarbeiten. Darauf werden Admins weiter warten müssen.
Insgesamt darf Juno damit wie die Vorgängerin als gelungene Release gelten. In der Community schmecken die Baby-Step-Releases übrigens nicht allen. Häufig finden sich auf den Mailinglisten kritische Kommentare, weil neue Features im aktuellen Schema eine ganze Weile und mehrere Releases brauchen, bis sie tatsächlich fertig sind. Dieser Konflikt könnte in Zukunft für Zündstoff in der Community sorgen – für Admins ist das aktuelle Modell deutlich sinnvoller.
Infos
- Open Stack: http://www.openstack.org
- Stefan Seyfried, Christian Behrendt, “Cactus im Anmarsch”: Linux-Magazin 05/11, S. 72
- Martin Loschwitz, “Dunkle Wolken”: Linux-Magazin 12/11, S. 22
- Razor: http://puppetlabs.com/solutions/next-generation-provisioning
- Foreman: http://theforeman.org
- Martin Loschwitz, “Dell-Werkzeug”: Linux-Magazin 01/13, S. 66
- Triple O: https://wiki.openstack.org/wiki/TripleO
- Martin Loschwitz, “Oh, Oh, Oh!”: Linux-Magazin 02/14, S. 76
- Vortrag von Monty Taylor auf dem Linuxtag 2013: http://www.linuxtag.org/2013/de/program/program/freitag-24-mai-2013/open-stack.html?eventid=305
- Rabbit MQ: http://www.rabbitmq.com
- Kristian Köhntopp, “Trust – there is none left”: http://www.netuse.de/ueber-uns/veranstaltungen/nubit-2014
- Ansible: http://www.ansible.com
- Saltstack: http://www.saltstack.com/
- Puppet-Openstack-Modul auf Github: https://github.com/puppetlabs/puppetlabs-openstack
- Cinder-Patch für lokalen Storage: https://review.openstack.org/#/c/118310/





