© Shawn Hempel, 123RF
Der Artikel zeigt, wie sich ein System mit Hardware-Raid in ein virtuelles System überführen lässt, wobei die Admins – gewissermaßen on the Fly – auch noch das Dateisystem verändern. Dafür kommen Bordmittel sowie Virtualisierungs- und Forensiktools zum Einsatz.
Seit der epidemischen Verbreitung von Virtualisierung in den Rechenzentren entstehen Serverdateisysteme immer seltener auf Partitionen und häufiger als Images. Für den Admin hat das Vorteile, lassen sich diese Dateien doch schneller verschieben oder auch manipulieren. Aber wer vorhandene echte Festplatten, die meist auf Blockdevices wie »/dev/sdx« hören, in der eigenen Cloud nutzen will, muss sie in die üblichen (Datei-)Formate ».vdi« oder ».vmdk« oder ähnliche umwandeln.
Die gängigen Konvertierungsprogramme wie »qemu-img –convert« (bei KVM) beherrschen das, stoßen aber bei komplexeren Ausgangssituationen immer wieder auf Probleme. Wer beispielsweise ein Raid-System aus mehreren Platten zusammenbauen und virtualisieren will, muss ein paar Tricks beherrschen, die dieser Artikel zeigt. Der im Folgenden beschriebene Ansatz greift nebenbei auch auf forensische Tools zurück, da die ursprünglich inspirierende Anforderung aus einem Kriminalfall entstand. Zur Virtualisierung benutzt er Virtualbox [1] in der Version 4.
Problemfall Raid-Controller
Dass es nicht immer einfach ist, physikalische Systeme zu virtualisieren, zeigte bereits ein Artikel im Linux-Magazin [2], wo der Härtefall einer Windows-XP-Version samt Blue Screen of Death (BSOD) aufgrund neuer virtueller Hardware dem Admin einen Strich durch die Rechnung machte.
Ähnliche (Treiber-)Probleme kann es auch unter Linux geben, etwa wenn die Festplatten aus Maschinen stammen, in denen Hardware-Controller Raid-Systeme steuern. Nicht immer lassen sich diese einfach so in das Gastsystem durchreichen. Zwar bietet KVM einige Möglichkeiten, um das hinzubiegen, andere Virtualisierungslösungen sind jedoch deutlich restriktiver. Wer auf Virtualbox setzt, wandelt eine Festplatte »/dev/sdb« beispielsweise problemlos mit »VBoxManage convertdd« um:
VBoxManage convertdd /dev/sdb test.vdi --format VDI
Der Befehl konvertiert die momentan eingebundene Festplatte, die der Admin vielleicht aus einem anderen Host ausgebaut hat, in eine virtuelle Festplatte »test.vdi« und das Virtualbox-eigene Virtual-Disk-Image-Format (VDI, [3]).
Solche Images lassen sich fast immer problemlos in jedes neue Gastsystem integrieren, auch andere Hypervisoren können mit ihnen umgehen. Ist dieser (gerne etwas langwierige) Prozess abgeschlossen, kann der Admin das gesamte System als Appliance im Open-Virtualization-Format (OVA, [4]) exportieren.
Komplexer Server
Ein typischer Server besteht aber nur selten aus einer einfachen Festplatte. Typischer ist ein Setup, in dem eine Festplatte das System und ein Raid-Verbund die eigentlichen Daten vorhält. Besteht oder bestand der ursprüngliche Host zum Beispiel aus drei Festplatten, beispielsweise einer 40-GByte-SATA-Platte und zwei 80-GByte-SATA-Platten an einem Raid-Controller, dann ist etwas mehr Aufwand notwendig, um dieses System zu virtualisieren.
Wer den alten Host noch zum Leben erwecken kann, hat dafür viele Optionen. Ist das jedoch nicht möglich (wie in dem ursprünglichen Fall, bei dem die Festplatten Bestandteil einer Sicherstellung bei Kriminellen waren), dann hilft das folgende Vorgehen. Um fremde Festplatten auszulesen, greifen Administratoren gern zum RAW-Format, schon weil es der einfachste mögliche Standard ist und praktisch jedes Linux geeignete Tools mitbringt.
Der Forensik-Experte jedoch bevorzugt das Expert Witness Format (EWF), das ein Artikel im Linux-Magazin vorgestellt hat [5]. Es bietet diverse Vorteile, die auch Admins bei komplizierteren Aufgaben hilfreich sein können. Das Programm Ewfacquire erzeugt Images im EWF-Format, der Administrator installiert es als Paket »ewf-tools« aus dem Repository der üblichen Distributionen.
Stripeset: Der Problemfall Raid 0
Der Einsatz eines Stripeset (Raid 0) ist zwar aus administrativer Sicht kaum mehr zu empfehlen, auf alten Servern ist es jedoch immer wieder anzutreffen. Weil das die meisten Probleme bereitet und im Originalsystem zum Einsatz kam, dient es hier als Beispiel. Mit ihm zeigt Fdisk (einen funktionierenden Controller vorausgesetzt) die Festplatten des Setups (Abbildung 1). Das forensische Pendant zu Fdisk aus dem Sleuthkit lautet »mmls« (Abbildung 2).
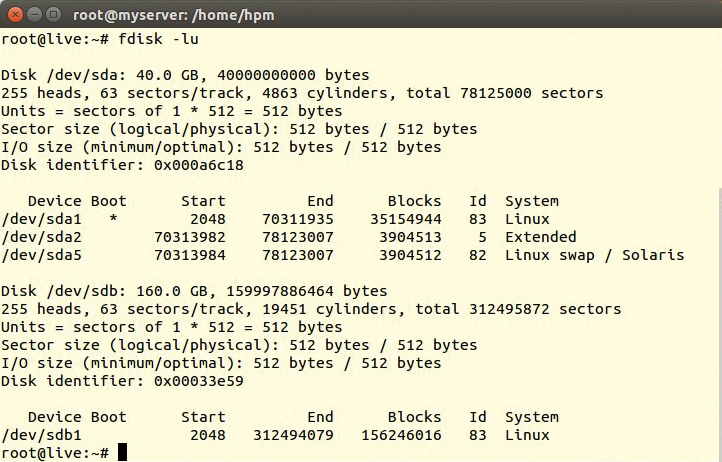
Abbildung 1: Die erste Festplatte ist 40 GByte groß, als zweite Disk präsentiert der Raid-Controller eine 160-GByte-Platte, die aber eigentlich ein Raid 0 aus zwei 80-GByte-Platten ist.
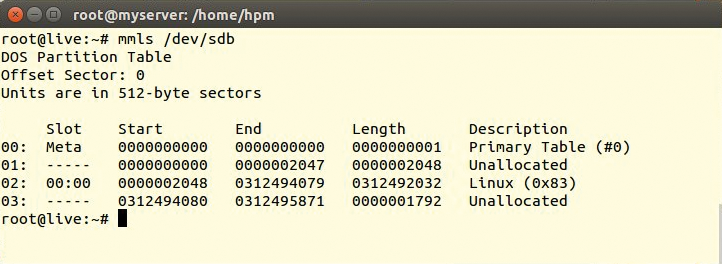
Abbildung 2: Auch Mmls aus dem Sleuthkit kann in die zweite Festplatte hineinsehen.
Ein anderes Bild präsentiert sich, wenn man die Festplatten aus dem alten System löst und ohne Raid-Controller in eine andere Maschine einbindet. Für die erste Festplatte ändert sich zwar nichts, aber wie Abbildung 3 zeigt, bilden die Festplatten 2 und 3 (die beiden 80-GByte-Speichermedien) kein System mehr, sie enthalten scheinbar nicht einmal eine Partitionstabelle – meldet Fdisk.
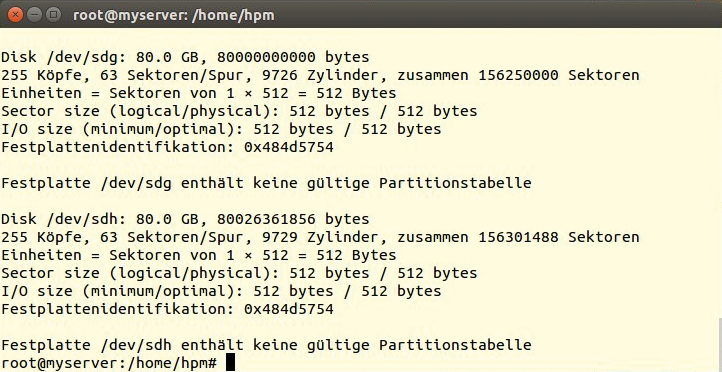
Abbildung 3: Ohne Raid-Controller sind die beiden 80-GByte-Platten zunächst nutzlos.
Keine Partitionstabelle?
Der Grund für deren Abwesenheit liegt in dem vorgelagerten Raid-Controller, der den Master Boot Record (MBR) in einen zunächst unbekannten Sektor nach hinten verschoben hat. Doch der lässt sich aufspüren, und dabei kommen die Forensiktools und ein wenig Grundlagenwissen ins Spiel.
Den prinzipiellen Aufbau eines MBR erklärt [6], für dieses Beispiel reicht es aus zu wissen, dass allen gängigen Systemen per Definition eines gemeinsam ist: Jeder MBR endet mit der Signatur »0x55« und »0xAA« , bei einer Null-indizierten Betrachtung die Bytes 510 und 511 (Abbildung 4). Gut, dass das Sleuthkit auch dafür genau den richtigen Befehl enthält: Sigfind (Listing 1).
Listing 1
sigfind -o
01 # sigfind -o 510 55AA /dev/sdb 02 03 Block size: 512 Offset: 510 Signature: 55AA 04 Block: 1024 (-) 05 Block: 47252 (+46228) 06 07 sigfind -o 510 55AA /dev/sdc 08 Block size: 512 Offset: 510 Signature: 55AA
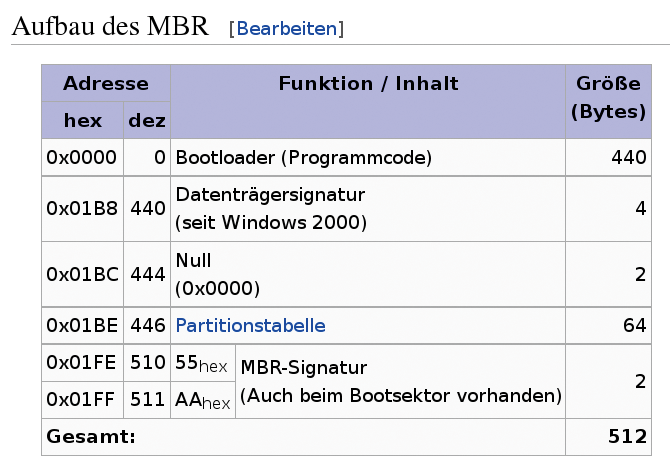
Abbildung 4: Jeder Master Boot Record endet mit der Signatur »0x55« und »0xAA«, daran lässt er sich aufspüren.
In den meisten Fällen liefert Sigfind bereits genug Informationen, um die Partitionen zu laden und den Raid-Verbund in Betrieb zu nehmen. Klar ist bereits jetzt, dass hier kein Raid-Mirror vorliegt, ein solcher hätte die gleichen Offsets auf beiden Platten geliefert. Die Partitionstabelle liegt allerdings 1024 Bytes weiter hinten als normal, was auch der Mmls-Befehl belegen kann (Listing 2). Achtung: Der tatsächliche Offset der Partition liegt somit bei 1024 plus 2048 Bytes.
Listing 2
mmls -o
01 #mmls -o 1024 /dev/sdg 02 DOS Partition Table 03 Offset Sector: 1024 04 Units are in 512-byte sectors 05 06 Slot Start End Length Description 07 00: Meta 0000000000 0000000000 0000000001 Primary Table (#0) 08 01: ----- 0000000000 0000002047 0000002048 Unallocated 09 02: 00:00 0000002048 0312494079 0312492032 Linux (0x83)
Kein MBR auf der zweiten Platte
Enttäuschenderweise findet sich in diesem Beispiel gar kein MBR auf der zweiten Festplatte – es handelt sich folglich wirklich um ein Raid 0, dass sich nicht ohne Weiteres rekonstruieren lässt. Ohne irgendeine Information zur zweiten Festplatte bleibt dem Admin nur, ein System mit eingebautem Controller zu benutzen (wie in Abbildung 1), um dort ein Image aus der 160-GByte-Platte zu erstellen. Mit Ewfacquire erzeugt er beispielsweise die Datei »help.E01« :
-rw-r--r-- 1 root root 443976036 Jun 21 15:09 image_source1.E01
Die Effizienz der Kompression, die EWF verwendet, ist zwar sehr gut, aber eine 160-GByte-Platte lässt sich nur auf 444 MByte komprimieren, wenn sehr wenig Daten auf ihr vorliegen.
Analyse der Systemdisk
Um weitere Informationen über den Raid-Verbund zu bekommen und um noch mehr Zugriff auf das EWF-Image zu erhalten, nimmt der Admin jetzt die Platte mit dem Linux-System unter die Lupe. Abbildung 1 zeigt die Partition »sda1« auf der 40-GByte-Platte »sda« , die jetzt näher untersucht werden soll. Im Auswertesystem wird sie zu »sdi« , »fls -o 2048 /dev/sdi« gibt mehr Aufschluss (Abbildung 5): Ja, auf dieser Platte liegt offensichtlich ein Linux-System.
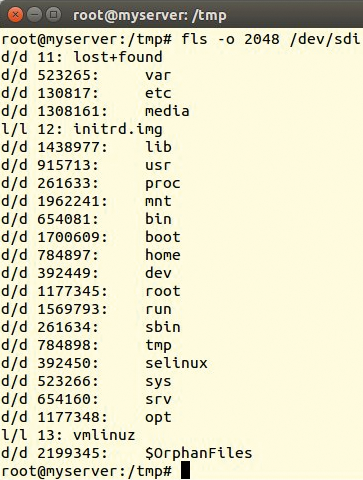
Abbildung 5: Eindeutig Linux – der Verzeichnisbaum, den Fls aus dem Sleuthkit ausspuckt, lässt keine Frage offen.
Um den Mountpoint der Raid-Platten zu ermitteln, befragt der Admin die Datei »/etc/fstab« (Listing 3). Die Pluszeichen im Listing deuten die Verzeichnistiefe an, also die Anzahl der Verzeichnisse im Pfad zum jeweiligen Ergebnis. Zeile 1 hat nur ein Pluszeichen am Anfang, somit eine Verzeichnistiefe von 1, was vermuten lässt, dass hier »/etc/fstab« vorliegt. Ein »icat -o 2048 /dev/sdi 130830« zeigt ihren Inhalt: »/dev/sdb1« mit dem Dateisystem XFS ist im Originalsystem auf »/var« gemountet (Abbildung 6), zumindest wenn man dem Kommentar glaubt.
Listing 3
fls -r -o
01 # fls -r -o 2048 /dev/sdi | grep fstab 02 + r/r 130830: fstab 03 + d/d 131075: fstab.d 04 ++ r/r 1439089: fstab 05 +++++ r/r 1046540: fstab 06 +++++ r/r * 1046540(realloc): fstab.dpkg-new 07 +++++ r/r * 1046549(realloc): fstab.dpkg-tmp 08 +++++ r/r 1046550: fstab.example2 09 +++++ r/r * 1046550(realloc): fstab.example2.dpkg-new 10 +++++ r/r * 1046558(realloc): fstab.example2.dpkg-tmp 11 ++++ r/r 920055: fstab.5.gz 12 ++++ r/r * 919981(realloc): fstab-decode.8.gz 13 ++++ r/r 919690: fstab-decode.8.gz 14 +++++ r/r * 1182160(realloc): fstab.vim.dpkg-new 15 +++++ r/r 1182160: fstab.vim 16 + r/r 261662: fstab-decode
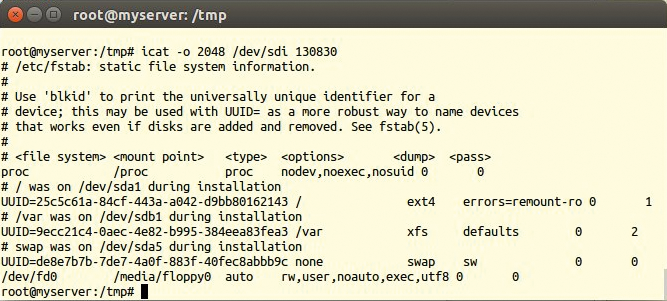
Abbildung 6: Icat gibt den Inhalt des Node 130830 aus, und siehe da, es handelt sich wie gewünscht um eine Datei »/etc/fstab«, die hilft den Raid-Verbund zu verstehen.
Wer das nicht einfach so hinnehmen will, checkt auf dem System noch die Ziele der symbolischen Links unter »/dev/disk/by-uuid/« und kontrolliert, welche UUID welcher Partition zugeordnet ist.
Für die Virtualisierung muss der Admin die 40 GByte große Festplatte sowie die beiden 80-GByte-Platten aus dem Raid-0-Verbund zusammenführen. Dazu synchronisiert er die Inhalte der beiden Images mittels Rsync in eine ».vdi« -Festplatte. Weil der Raid-Verbund ja fast leer war, reicht es, der neuen Virtualbox-Instanz eine leere Festplatte mit 20 GByte zu spendieren. Jetzt stehen fünf Schritte an:
- Partitionieren und Formatieren
- Aus der 40-GByte-Festplatte die Dateien mit Rsync nach »/« übertragen
- Aus dem 160-GByte-Raid die Dateien nach »/var« übertragen
- Das neue System bootfähig machen, also einen MBR erstellen
- »/etc/fstab« und »/boot/grub/grub.cfg« anpassen und ebenfalls bootfähig machen
Wer das der Reihe nach durchgearbeitet hat, sollte jetzt ein neues System mit den Daten der alten Maschine sein Eigen nennen und darf auf einen erfolgreichen Start hoffen.
Network Block Devices
Besonders handlich sind die Network Block Devices (NBD), weil sich virtuelle Festplatten auf ».vdi« -Basis so noch einfacher mounten lassen. Der Eintrag
modprobe nbd qemu-nbd -c /dev/nbd0 .vdi-Datei
erstellt ein Blockdevice, das von außen für die genannten Tätigkeiten benutzbar ist. Der Admin erstellt nun ein Dateisystem, das etwa die Partitionierung aus Listing 4 erhalten kann.
Listing 4
NBD-Partitionierung
01 Disk /dev/nbd0: 21.5 GB, 21474836480 bytes 02 255 Köpfe, 63 Sektoren/Spur, 2610 Zylinder, zusammen 41943040 Sektoren 03 Einheiten = Sektoren von 1 <> 512 = 512 Bytes 04 Sector size (logical/physical): 512 bytes / 512 bytes 05 I/O size (minimum/optimal): 512 bytes / 512 bytes 06 Festplattenidentifikation: 0x00000000 07 08 Gerät boot. Anfang Ende Blöcke Id System 09 /dev/nbd0p1 63 35150219 17575078+ 83 Linux 10 /dev/nbd0p2 35150220 41943039 3396410 82 Linux Swap/Solaris
Listing 5
/etc/fstab und grub.cfg
01 # cat /etc/fstab
02 # <file system> <mount point> <type> <options> <dump> <pass>
03 proc /proc proc nodev,noexec,nosuid 0 0
04 /dev/sda1 / ext4 errors=remount-ro 0 1
05 /dev/sda5 none swap sw 0 0
06
07 # cat /boot/grub/grub.cfg
08
09 #search --no-floppy --fs-uuid --set=root 25c5c61a-84cf-443a-a042-d9bb80162143
10 menuentry 'Ubuntu, mit Linux 3.2.0-29-generic-pae' --class ubuntu --class gnu-linux --class gnu --class os {
11 recordfail
12 gfxmode $linux_gfx_mode
13 insmod gzio
14 insmod part_msdos
15 insmod ext2
16 set root='(hd0,msdos1)'
17 # search --no-floppy --fs-uuid --set=root 25c5c61a-84cf-443a-a042-d9bb80162143
18 linux /boot/vmlinuz-3.2.0-29-generic-pae root=/dev/sda1 ro
19 initrd /boot/initrd.img-3.2.0-29-generic-pae
20 [...]
Das ehemalige Raid-System soll keine eigene Partition mehr bekommen, sondern unter »/var« direkt eingebunden werden. Die Befehle
mkfs.ext4 /dev/nbd0p1 mkswap /dev/nbd0p2
schreiben das Dateisystem für »/« und »swap« , ein MBR ist allerdings nur teilweise vorhanden, wie »dd if=/dev/nbd0 count=1 | xxd« beweist (Abbildung 7). Schwarz unterlegt sind hier zweimal 16 Byte zur Definition der Root- und Swap-Partition sowie die Ende-Sequenz 55AA zu erkennen.
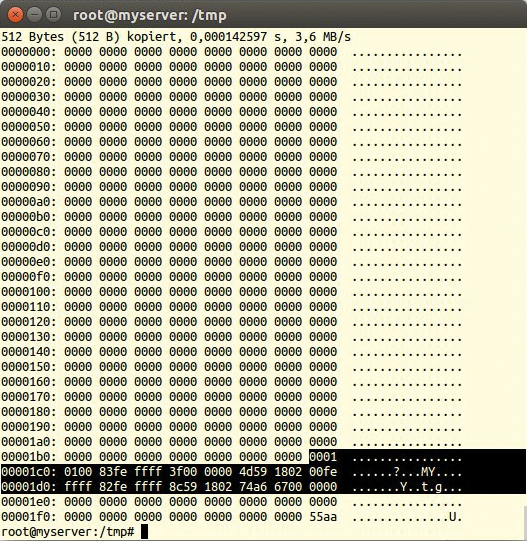
Abbildung 7: Zwei Partitionen und das Ende des MBR in der Ausgabe von Dd.
Drei Mountpoints für die Synchronisation
Zur Synchronisation sind jetzt drei Mountpoints nötig. Dazu sollen »/tmp/d« als Destination und »/tmp/s1« sowie »/tmp/s2« – also Source 1 und 2 – dienen, der Admin muss sie mit Mkdir erzeugen. Die Zielpartition kann er bereits mounten, und zwar mit »mount /dev/nbd0p1 /tmp/d« .
Die Quellpartitionen sind aber noch in den komprimierten Images verborgen und wollen erst noch aufbereitet sein. Dazu wandelt der Admin die Images vom komprimierten EWF-Format ins RAW-Format um, natürlich mit Xmount [7]. Die RAW-Images befinden sich anschließend in den (noch zu erstellenden) Verzeichnissen »/ewf« und »/ewf1« :
xmount --in ewf --out dd image_source1.E* /ewf xmount --in ewf --out dd image_source2.E* /ewf2
Um die RAW-Images mounten zu können, sind die beiden Loop-Devices »/dev/loop0« und »/dev/loop1« nötig. Loop0 zeigt in Partition 1 der 40-GByte-Platte, Loop1 in den Beginn des Stripesets. Beide Partitionen haben den üblichen Offset von 2048 Sektoren:
losetup -o $((2048*512)) /dev/loop0 /ewf/image_source1.dd losetup -o $((2048*512)) /dev/loop1 /ewf2/image_source2.dd mount /dev/loop0 /tmp/s1 mount /dev/loop1 /tmp/s2
Zwei Rsync-Befehle fügen die Partitionen zusammen:
cd /tmp/d rsync -av /tmp/s1/* . cd /tmp/d/var rsync -av /tmp/s2/* .
Jetzt gilt es nur noch, die Dateien »fstab« und »grub.cfg« anzupassen. Statt einer UUID-basierten Konfiguration sollte der Admin mit »/dev/sdax« arbeiten, weil dies die Migration erleichtert. Wer die UUID bevorzugt, muss diese Devices noch manuell neu anlegen.
Diese Übergangslösung in der Datei »grub.cfg« sollte nach erfolgreicher Virtualisierung sauber, dem Grub-Handbuch entsprechend korrigiert werden, doch für einen ersten erfolgreichen Bootvorgang mag dieser Ansatz genügen.
Grub und MBR
Schließlich bleibt noch der neue MBR zu erstellen. Auch den schreibt der Admin außerhalb der VDI mit Hilfe des NBD-Device in einer Chroot-Umgebung analog zu [8]:
mount -o bind /dev /tmp/d/dev mount -o bind /sys /tmp/d/sys mount -t proc /proc /tmp/d/proc cp /proc/mounts /tmp/d/etc/mtab chroot /tmp/d /bin/bash grub-install --root-directory=/tmp/d /dev/nbd0Installation finished. No error reported.
Abbildung 8 zeigt, dass der MBR erfolgreich geschrieben und ordentlich mit Informationen gefüllt ist. Vor dem – die Spannung steigt – ersten Bootvorgang sollte der ordnungsbewusste Admin noch etwas aufräumen:
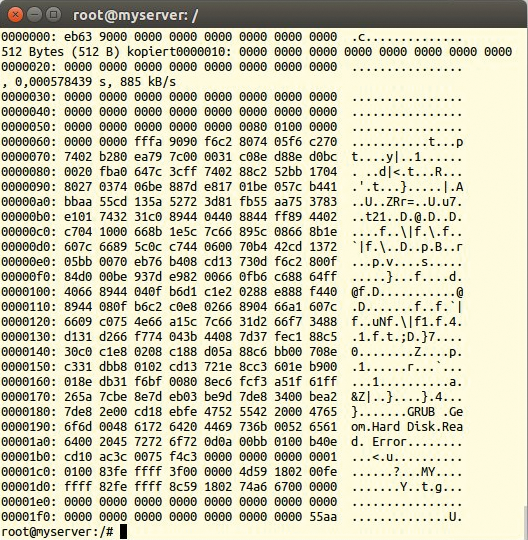
Abbildung 8: Jetzt finden sich mehr Informationen in den 512 Byte des MBR.
umount /tmp/d/proc umount /tmp/d/sys umount /tmp/d/dev umount /tmp/d/ qemu-nbd -d /dev/nbd0
Einem erfolgreichem Bootvorgang ins virtualisierte System steht nun nichts mehr im Wege. Wer Festplatten vorliegen hat, die im Mirror-Betrieb mit Hardware-Controller liefen, braucht – sofern sich der Mirror im synchronisierten Zustand befand – nur eine Festplatte wiederherzustellen. Diese konvertiert er mit Xmount ins Dd-Format. Sigfind liefert den Offset zum verlagerten MBR, Iosetup hilft jetzt weiter und verknüpft mit
losetup -o $(((1024+2048)*512)) /dev/loop0 image.dd
ein Loop-Device mit einem MBR-Offset von 1024 und dem Beginn der ersten Partition bei Sektor 2048, wo es der Admin mounten kann.
Infos
- Virtualbox: http://www.virtualbox.org
- Hans-Peter Merkel, Markus Feilner, “Richtig Einbürgern”: Linux-Magazin 11/09, S. 88
- Das Virtual-Disk-Image-Format (VDI): http://en.wikipedia.org/wiki/VDI_%28file_format
- Open Virtualization Format (OVA): http://de.wikipedia.org/wiki/Open_Virtualization_Format
- Hans-Peter Merkel, Markus Feilner, “Fenster-Kit”: Linux-Magazin 06/08, S. 38
- Master Boot Record: http://de.wikipedia.org/wiki/Master_Boot_Record
- Hans-Peter Merkel, Markus Feilner, “Kreuz und Quer”: Linux-Magazin 10/09, S. 90
- Chroot-Methode: http://wiki.ubuntuusers.de/GRUB_2/Reparatur#chroot-Methode
Der Autor

Hans-Peter Merkel ist mit dem Schwerpunkt Datenforensik seit vielen Jahren in der Open-Source-Community aktiv. Er bildet Mitarbeiter von Strafverfolgungsbehörden in Europa, Asien und Afrika aus und engagiert sich als Gründer und Vorsitzender bei Freioss und Linux4afrika.





