
© alphaspirit, 123RF
In fast jeder Software stecken Fehler, nicht wenige davon untergraben sogar die Sicherheit. Was können die Entwickler schon bei Beginn dagegen tun? Ein Überblick.
Programmierer sind Menschen, und Menschen machen Fehler. Interessanter als diese Binsenweisheit ist allerdings, dass sie offenbar immer wieder die gleichen machen. Das zeigt die Liste der 25 gefährlichsten Softwarefehler [1]. Sie beruht auf der Common Weakness Enumeration (CWE, Liste geläufiger Sicherheitsschwächen) der Non-Profit-Organisation Mitre, die für US-Bundesbehörden die Sicherheit von Programmen untersucht.
Übliche Verdächtige
Wer gegen diese Fehler vorgeht, kann die Sicherheit seiner Software deutlich verbessern, weshalb Mitre auch gleich einen Maßnahmenkatalog anbietet. Unter dem Posten M1 der so genannten Monster Mitigations findet sich die altbekannte Empfehlung, alle Eingaben zu kontrollieren. Dazu gehören auch Angaben zur Länge des Inputs, die Open SSL in Heartbeat zum Verhängnis wurden. Die CWE und ihre Begleitmaterialien gehören zur Kategorie Aufklärung, die eine der Maßnahmen für bessere Softwaresicherheit darstellt. Sie machen Entwickler mit häufigen Fehlerarten wie Buffer Overflow, SQL-Injection und Link Following vertraut, um sie für das Auftreten in ihrem eigenen Code zu sensibilisieren.
In diese Kerbe schlagen auch das Secure-Programming-Howto von David Wheeler [2] und die Linux-Magazin-Reihe “Sicheres Programmieren für Administratoren” von Dominik Vogt [3], die beide kostenlos online zugänglich sind.
Allerdings werden Software-Entwickler für das bezahlt, was ihre Programme tun, und nicht dafür, welche Sicherheitslücken sie vermeiden. Auch in Open-Source-Projekten, ob kommerziell oder ideell motiviert, stehen die erwünschten Features im Mittelpunkt. Daher trage auch Test Driven Development (TDD) wenig zur Sicherheit bei, kritisiert David Wheeler in einem Aufsatz, den er unter dem Eindruck von Heartbleed verfasst hat [4]: Sie denken vornehmlich an den so genannten Happy Path, den Programmablauf bei ordnungsgemäßer Benutzung des Programms. Sicherheitslecks dagegen treten auf, wenn der Anwender Software gegen den Strich bürstet und beispielsweise ungewöhnliche Eingaben macht. Daher fordert Wheeler negatives Testing, das sich auf ungültigen Input und Grenzfälle spezialisiert.
Fuzzing
Eine Sonderform beim negativen Testing, die sich leicht automatisieren lässt, ist das Fuzzing [5], das erstmals 1988 der Informatiker Barton Miller beschrieben hat. Hierbei bombardiert man die zu testende Software mit zufällig generierten Eingaben oder Mutationen von Eingabe- und Konfigurationsdateien – in der Hoffnung, auf eine bestehende Sicherheitsschwäche zu treffen. Im einfachsten Fall führt das zum Absturz des Programms.
Verfeinerte Varianten des Fuzz Testing verwenden einen Address Checker. Er prüft, ob sich das Programm durch die Eingaben dazu bringen lässt, über Speicherbereiche hinaus zu schreiben (Buffer Overflow) oder zu lesen (Out-of-Bounds Read). Zu diesem Zweck dient beispielsweise das Tool Address Sanitizer [6], das Speicherfehler in C- und C++-Programmen aufspürt. Es steht als Option in GCC ab Version 4.8 und in Clang ab 3.1 zur Verfügung. Zu seinen Anwendern zählen die Entwickler der Browser Chromium und Firefox. Address Sanitizer instrumentiert den Code, was zu Performance-Einbußen führt, die aber für Testzwecke akzeptabel sind.
Fuzzing kommt unter anderem bei der Arbeit am Linux-Kernel zum Einsatz. Das Tool Trinity [7] des Red-Hat-Entwicklers Dave Jones beackert Systemaufrufe und hat schon Dutzende Schwächen im Kernel offenbart, von denen allerdings noch nicht alle behoben sind.
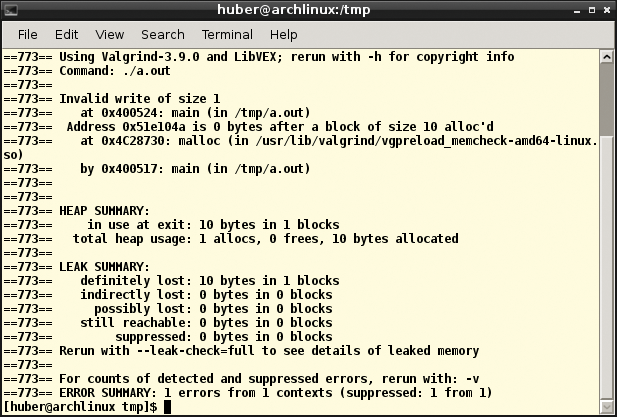
Probleme mit der Speicherverwaltung findet auch die freie Werkzeugsammlung Valgrind [8]. Das einfache C-Programm in Listing 1 greift auf nicht allozierten Heap-Speicher zu. Wer es kompiliert und das Executable mit »valgrind ./a.out« aufruft, bei dem bemängelt das Analyseprogramm den Fehler (Abbildung 1).
Listing 1
Speicherfehler
01 #include <stdlib.h>
02
03 int main(void)
04 {
05 char *x = malloc(10);
06 x[10] = 'a';
07 return 0;
08 }
Gefährliche Sprachen
Die Speicherverwaltung stellt eine häufige Fehlerquelle bei Programmen dar, die in C, C++ oder Objective-C geschrieben sind. David Wheeler geht sogar so weit, sie als “gefährliche Sprachen” zu bezeichnen: “Diese Sprachen besitzen keine eingebauten Beschränkungen beim Zugriff auf Speicherbereiche, ja, der Entwickler muss sogar nicht-triviale Anstrengungen unternehmen, um Over-Reads und Over-Writes zu vermeiden” [4]. Programmiersprachen wie Java, Perl oder PHP machen es dem Programmierer in dieser Hinsicht leichter.
C und Konsorten haben jedoch auch einiges für sich, und deshalb kommen sie häufig zum Einsatz. Sie sorgen für schnelle Programme und kommen auch mit geringen Ressourcen aus. Der Programmierer kann daneben einschätzen, wie sein Code die Performance beeinflussen wird. Mit dem Motto “Trust the Programmer” machen sie die Verantwortung des Entwicklers zum Prinzip. Daneben finden Entwickler über eine C-Schnittstelle Anschluss zu fast allen anderen Komponenten eines Systems.
Das heißt aber noch lange nicht, dass Programme in Java und Skriptsprachen frei von Sicherheitslücken wären. PHP-Software wie die Blog-Engine WordPress oder das Ruby-Webframework Rails tauchen regelmäßig mit sicherheitsrelevanten Bugs in den Advisories auf. Hier handelt es sich weniger um Probleme mit der Speicherverwaltung. Typisch sind besonders bei Webanwendungen Angriffe durch das Einschleusen von SQL-Code (SQL-Injection) oder Javascript (Cross-Site Scripting).
Schwächen in Websites lassen sich mit Spezialscannern wie Ratproxy [9] und [10] Nikto finden. Auch das Penetration-Testing-Framework Metasploit [11] bringt eine Vielzahl von Modulen für verschiedene Webanwendungen mit, die typische Lücken testen.
Die bisher geschilderten Ansätze arbeiten mit laufenden Programmen, die falls nötig vorher noch kompiliert werden. Diese Verfahren bezeichnet man daher als dynamisch. Eine ganze Gattung von Werkzeugen beschäftigt sich aber mit dem reinen Quellcode, der bei Open-Source-Software ja zur Verfügung steht. Da diese Tools mit den statischen Quelltextdateien arbeiten, bezeichnet man ihre Vorgehensweise als statische Analyse.
Statische Analyse
Für Ruby-on-Rails-Anwendungen gibt es das Analysetool Brakeman [12], zu dessen Anwendern die Internet-Unternehmen Github und Twitter zählen. Es benötigt keinen laufenden Server, sondern nur den Quelltext für seine Untersuchungen. Aus diesem Grund lässt es sich auch in Continuous-Integration-Systeme einbinden. Der Auswertung kommt entgegen, dass das Framework Rails sehr stark auf Konventionen setzt und die Fehler damit typische Muster hinterlassen.
Abbildung 2 zeigt einen Ausschnitt des Brakeman-Berichts über ein studentisches Rails-Projekt. Neben SQL-Injection entdeckt das Tool auch Cross-Site Scripting, Cross-Site Request Forgery, unsichere HTTP-Umleitungen und weitere Problemtypen. Seine Fähigkeiten sind dennoch begrenzt, weshalb die Entwickler empfehlen, Brakeman mit einem dynamischen Websecurity-Scanner zu kombinieren.
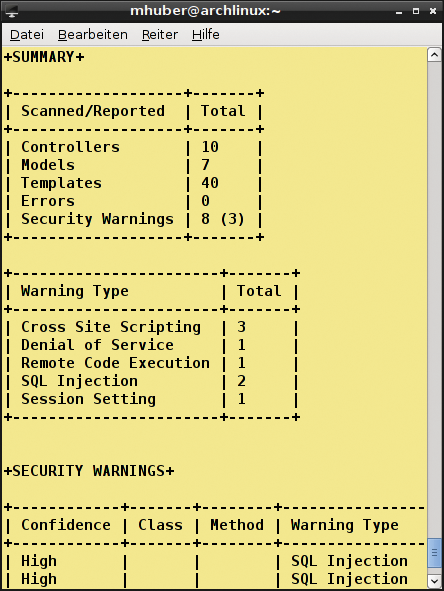
Abbildung 2: Brakeman findet SQL-Injections und weitere Fehler durch statische Analyse des Codes von Rails-Anwendungen.
Statische Analysetools sind mit PHP Code Sniffer sowie PHP Lint auch für PHP im Angebot [13]. Für Python existieren unter anderem Pylint [14] und Frosted [15]. Einen Überblick für zahlreiche Sprachen gibt ein online lesbarer Artikel aus dem Linux-Magazin [16].
Analysedienst
Auch bei kompilierten Sprachen kommt statische Analyse zum Einsatz. Rund 2200 Open-Source-Projekte nutzen die Dienste des Unternehmens Coverity [17], die C, C++ und Java unterstützen. Für die Projekte ist der ansonsten kommerzielle Service kostenlos. Langjährige Kunden sind der Python-Interpreter und der Linux-Kernel.
Regelmäßig berichtet Coverity über die Codequalität der teilnehmenden Projekte. Im Jahr 2013 schnitt Open Source bei C und C++ mit 0,59 Defekten pro 1000 Zeilen Code besser ab als proprietäre Software mit einer Quote von 0,72. Dabei ist nicht zu vergessen, dass diese Projekte schon durch die Teilnahme am Scanprogramm zeigen, dass sie sich besonders um Codequalität bemühen.
“Daneben muss ein Projekt auch geeignete Prozesse für den Umgang mit entdeckten Problemen schaffen. Dazu gehört es, offen mit Sicherheitslücken umzugehen und rasch Patches zur Verfügung zu stellen”, erklärt Zack Samocha von Coverity dem Linux-Magazin. Er lobt in diesem Zusammenhang den Linux-Kernel. Der Trinity-Autor Dave Jones fungiert dort als Verbindungsmann zwischen dem Scandienst und den Entwicklern.
Durchgerutscht
Wie alle in diesem Artikel vorgestellten Ansätze bringt auch die statische Analyse Schwächen und Einschränkungen mit sich. Auch das Open-SSL-Projekt nahm die Dienste von Coverity wahr, doch der Scanner erkannte Heartbleed zunächst nicht. Erst nach dem Bekanntwerden entwickelte das Unternehmen einen neuen Algorithmus, der diesen Fehlertyp aufspürt. Mittlerweile nutzen auch Dave Jones und die Kernelhacker das neue Feature und bemerken Heartbleed-ähnliche Defekte.
Viele Augenpaare
Was maschinelle Analysen, seien sie dynamisch oder statisch, nicht finden, muss der Mensch ausputzen. Im Jahr 2009 zeigten James Kupsch und Barton Miller von der Universität Wisconsin, dass Code Reviews durch Fachleute Softwaredefekte zu Tage fördern, die der Computer nicht findet [18]. Die menschlichen Reviewer fanden 15 ernsthafte Sicherheitslücken in der verwendeten Codebasis, die Tools von Coverity & Co. erkannten nicht einmal die Hälfte.
Diese Art der Fehlersuche ist selbstverständlich die in Arbeitsstunden aufwändigste. Zudem müssen die Untersuchenden erfahrene Software- und Security-Experten sein, die weder leicht zu finden noch preiswert anzustellen sind. Für wichtige Software wie etwa weit verbreitete Kryptographie-Bibliotheken kann das aber angebracht und lohnenswert sein. Daher investiert die Core Infrastructure Initiative [19] der Linux Foundation unter anderem in einen Audit des Open-SSL-Codes.
Den Code-Kritikern stehen bei ihrer Arbeit Tools wie das MIT-lizenzierte Review Board [20] zur Seite. Es integriert Syntax Highlighting, Diff-Ansichten, Versionskontrolle, Kommentare und Statistiken (Abbildung 3). Auf die beste Voraussetzung für Code Reviews weist David Wheeler am Ende seines Heartbleed-Aufsatzes hin: Quellcode, der unter einer gebräuchlichen Open-Source-Lizenz zur Verfügung steht.
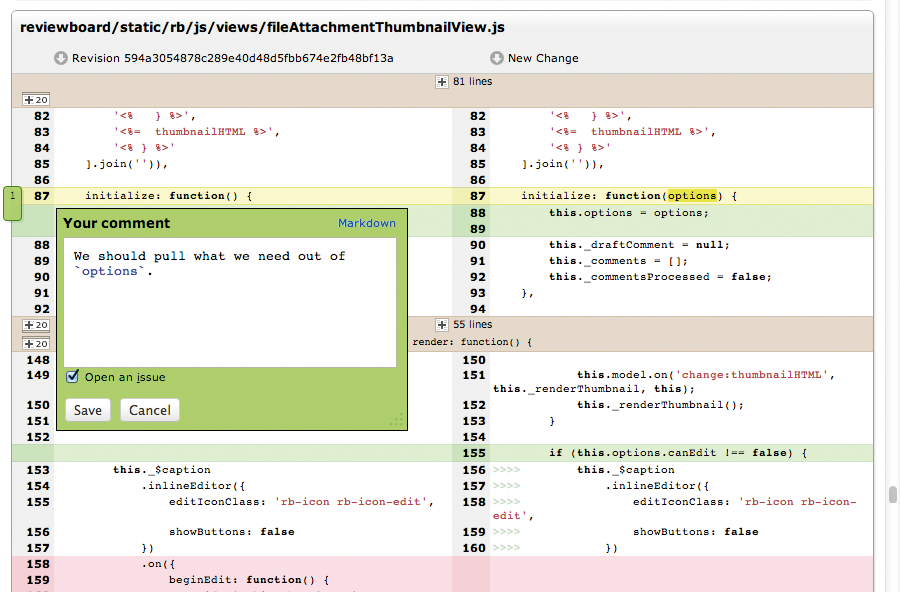
Abbildung 3: Review Board erleichtert die Code-Durchsicht mit Highlighting, Diffs und Kommentaren.
Infos
- CWE/SANS Top 25 Most Dangerous Software Errors: https://cwe.mitre.org/top25/
- David A. Wheeler, “Secure Programming for Linux and Unix HOWTO”: http://www.dwheeler.com/secure-programs/
- Dominik Vogt , Linux-Magazin-Reihe “Sicheres Programmieren für Administratoren”: https://www.linux-magazin.de/Ausgaben/2005/02/Umweltverschmutzung
- David A. Wheeler, “How to Prevent the next Heartbleed”: http://www.dwheeler.com/essays/heartbleed.html
- Fuzzing-Seite der Universität Wisconsin: http://pages.cs.wisc.edu/~bart/fuzz/
- Address Sanitizer: https://code.google.com/p/address-sanitizer/
- Trinity: http://codemonkey.org.uk/projects/trinity/
- Valgrind: http://www.valgrind.org
- Ratproxy: https://code.google.com/p/ratproxy/
- Nikto: http://cirt.net/nikto2
- Metasploit: http://metasploit.org
- Brakeman: http://brakemanscanner.org
- Tim Schürmann, “Statische Codeanalyse für PHP”: https://www.linux-magazin.de/Ausgaben/2012/08/plus/Statische-Codeanalyse-fuer-PHP
- Pylint: https://pypi.python.org/pypi/pylint
- Tim Schürmann, “Code-Korrektor”: Linux-Magazin 07/14, S. 92
- Tim Schürmann, “Fusselfreier Code”: https://www.linux-magazin.de/Ausgaben/2012/08/Statische-Analyse
- Coverity Scan: http://scan.coverity.com
- James A. Kupsch, Barton P. Miller, “Manual vs. Automated Vulnerability Assessment: A Case Study”: http://research.cs.wisc.edu/mist/papers/ManVsAutoVulnAssessment.pdf
- Core Infrastructure Initiative: http://www.linuxfoundation.org/programs/core-infrastructure-initiative
- Review Board: http://www.reviewboard.org





