
© Sudok1, 123RF
Wer erzeugt dauernd neue Prozesse, die den Rechner lahmlegen? Welcher Prozess öffnet die meisten Dateien und wie viele Bytes liest oder schreibt er dabei? Mit BPFtrace und seinen Sonden im Code beantwortet Mike Schilli solche Fragen.
Wer vor der Aufgabe steht, auf einem schleppend dahinkriechenden Linux-Rechner die Ursache eines Performance-Problems aufzuspüren, greift üblicherweise zu Werkzeugen wie Iostat, Top oder Mpstat [1] und sieht nach, was genau den Betrieb aufhält: Zu wenig RAM? Lahme Festplatte? CPU überlastet? Netzwerkdurchsatz als Mauer?
Ein Tool wie Top zeigt zwar die laufenden Prozesse an, kann aber kurzlebige Störer nicht aufspüren, die starten und sich gleich wieder beenden: Das periodische Abfragen der Prozessliste taugt nur zur Visualisierung von Langläufern.
Online PLUS
Im Screencast demonstriert Michael Schilli das vorgestellte Programmierbeispiel: http://www.linux-magazin.de/videos/
Zum Glück enthält der Linux-Kernel Tausende von Testsonden, genannt Kprobes und Tracepoints. Dort kann der User Code einschleusen, der Ereignisse protokolliert oder Statistiken erstellt. Ein brandheißes Tool dafür ist BPFtrace. Mit simplen Einzeilern jubelt es dem Kernel Skripte unter, die etwa in Echtzeit mitzählen, wie viele Bytes ins Netzwerk oder auf die Festplatte wandern oder welche Prozesse welche Dateien öffnen.
Die Abkürzung BPF steht für Berkeley Package Filter und zeugt von der Herkunft des entsprechenden Werkzeugs aus der BSD-Welt als Tracing-Tool für Netzwerkpakete. Die Praxis, Sonden im Code zu verstreuen, die im Normalfall stillschweigen, aber bei Aktivierung kleine Programmstücke ausführen, stellte sich als so praktisch heraus, dass sie bald als eBPF in die Linux-Welt einzog.
Dort verlor sie den Bezug zu Netzwerkpaketen vollends und übernahm als generisches Tracing-Konzept weite Bereiche des Kernelcodes. Gute Namensgebung ist harte Arbeit, die Ingenieure oft scheuen, und deswegen benannte der Autor von eBPF sein nun an Popularität gewinnendes Werk wieder in BPF um. Autoren von Tutorials sind deshalb in Erklärungsnot, warum der Name gänzlich sinnlos geworden ist.
Der Ansatz, dynamisch aktivierbare Sonden im Kernelcode zu verteilen, stammt aus der Sun-Welt. Solaris war lange das einzige Betriebssystem, das Administratoren mittels Dtrace erlaubte, an strategischen Stellen wie dem Einsprungspunkt von Systemcalls kleine in der Sprache D verfasste Codestücke zu aktivieren und Zähler oder Zeitmessungen für die Performance-Analyse abzufeuern.
BPF auf neueren Linux-Kerneln funktioniert ähnlich wie Dtrace, wurde aber – auch aus Patentgründen – neu geschrieben. Es führt den Sonden zugewiesene, in der BPF-Sprache verfasste Instruktionen entweder in einem Interpreter oder per JIT-Compiler in nativem Code aus, und zwar direkt im Kernel.
Zustand: Hanebüchen
Die BPFtrace-Programmiersprache erinnert stark an das Unix-Urgestein Awk, kommt allerdings so ungeschliffen daher, dass sich Programmierer die Haare raufen, wenn sie nur einfachste Arbeiten erledigen wollen.
Der Parser von BPFtrace (mit den Unix-Urgesteinen Lex und Yacc implementiert) befindet sich in einem hanebüchenen Zustand, der noch nicht einmal annähernd an die Funktionalität von Awk heranreicht – aber vielleicht wird’s ja noch. Der Netflixer Brandan Gregg strickt mit einigen Open-Source-Freunden mit heißer Nadel daran. Sein Buch zum Thema BPF [2] soll im November 2019 erscheinen, eine Preview liegt bereits vor.
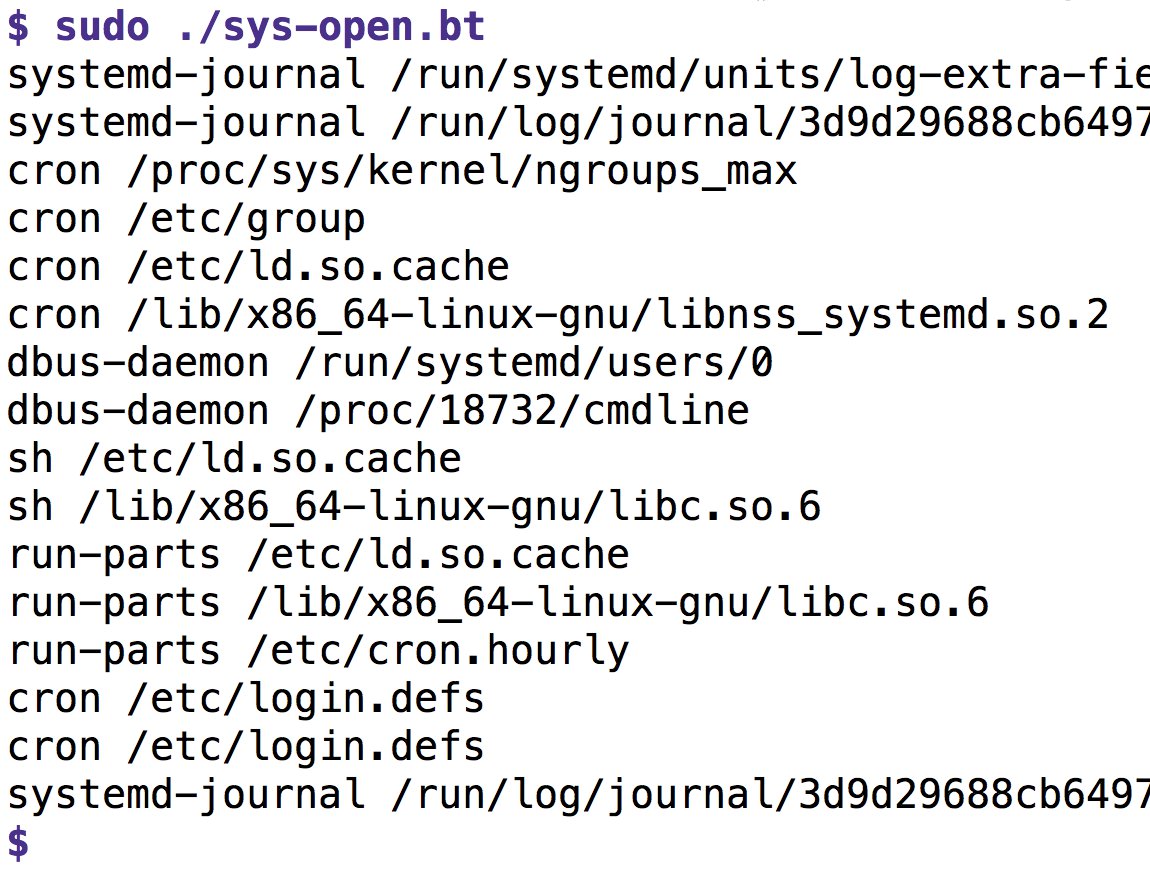
Abbildung 1: Der Code aus Listing 1 meldet in Echtzeit, welche Prozesse gerade welche Dateien zu öffnen versuchen.
Aber zurück zur Aufgabe: Wie wäre es, im Kernel eine Sonde zu aktivieren, die jedes Mal eine Nachricht ausgibt, wenn ein Userspace-Programm die Funktion »open()« zum Öffnen einer Datei anspringt? Man könnte dann in Echtzeit sehen, welche Prozesse welche Dateien öffnen. Listing 1 zeigt den Programmcode, Abbildung 1 die Ausgabe des Programms.
Listing 1
sys-open.bt
01 #!/usr/bin/bpftrace
02
03 interval:s:5
04 {
05 exit();
06 }
07
08 kprobe:do_sys_open
09 {
10 printf("%s %s\n", comm, str(arg1));
11 }
Kompakter Code
Die eigentliche Arbeit erfolgt ab Zeile 8 mit der Sonde »kprobe:do_sys_open«, die der folgende Block mit Instruktionen bestückt. Der Kernel signalisiert ihr, welche Datei der Syscall »open()« öffnen soll. Im Block gibt die »printf()«-Anweisung das in der Variablen »comm« gespeicherte Kommando des auslösenden Unix-Prozesses aus sowie das erste Argument »arg1« mit dem Namen der zu öffnenden Datei. Da »printf()« einen String erwartet, BPF aber »arg1« als Char-Pointer sichert, konvertiert die vordefinierte Funktion »str()« den Pointer entsprechend.
Der Code zum Event »interval:s:5« ab Zeile 3 ist nur optionaler Firlefanz, der das Programm nach 5 Sekunden abbricht. Das Event definiert ein Intervall von 5 Sekunden, in dem BPFtrace den Codeblock anspringt. Hier steht der Aufruf »exit()«, der das Programm abbricht, sobald der Block zum ersten Mal angesprungen wird. Oft nutzen Tracing-Tools solche Intervalle, um alle paar Sekunden konsolidierte Statistiken auszugeben. Ist BPFtrace mittels
$ sudo apt-get update $ sudo apt-get install bpftrace
auf einem Ubuntu-System installiert, genügt es, Listing 1 ausführbar zu machen und mit »sudo« aufzurufen. Es startet blitzschnell und zeigt laufend an, welche Prozesse im System gerade welche Datei zu öffnen versuchen. Das Verfahren läuft allerdings nur auf relativ neuen Kerneln. Die Macher empfehlen mindestens Version 4.9, besser aber die 5er Serie.
Der erstaunte User reibt sich verwundert die Augen, wenn er überlegt, was bei dem unscheinbaren Aufruf gerade hinter den Kulissen abgelaufen ist: BPFtrace hat die »kprobe«-Sonde »do_sys_open« im Kernel aktiviert und den Code mit der »printf()«-Anweisung in ein internes Format übersetzt. Dann hat es ihn auf der Sonde installiert, sodass diese jedes Mal eine Meldung ausgibt, wenn der Kernel an der Sonde vorbeirauscht. Beendet sich BPFtrace, deaktiviert es die Sonde und befreit sie wieder vom eingeschleusten Code.
Volle Kanne im Leerlauf
Wie funktioniert das Ganze im Detail? Es wäre offensichtlich verheerend für die Performance des Kernels, wenn er für jede Sonde prüfen müsste, ob sie gerade aktiv ist, um anschließend in fast 100 Prozent der Fälle ganz normal im Programm fortzuschreiten. Es sind ja immer nur ganz wenige, wenn überhaupt irgendwelche Sonden von Tausenden möglichen aktiv.
Stattdessen bedient sich die BPF-Technik, ähnlich wie Dtrace unter Solaris, eines Tricks und setzt im Normalfall, also bei abgeschalteter Sonde, eine 5 Byte lange No-Op-Instruktion in den Code, die der Prozessor zur Laufzeit praktisch verlustlos überspringt. Aktiviert der User die Sonde, etwa durch den Aufruf von BPFtrace, ersetzt BPF im Kernel die No-Op-Instruktion mit einer Sprungadresse zum Interpreter, der den gewünschten Code ausführt.
Dort verbrät die CPU beim Ausführen der BPF-Instruktionen zwar CPU-Zeit und bremst damit den Kernel etwas. Da aber der Prozessor im Kernel-Modus bleibt und nicht aufwändig jedes Mal ins Userland wechseln muss, kann die Sonde zügig die gewünschten Statistiken auffrischen – dann geht es weiter im Text mit dem eigentlichen Kernelcode.
Würde der eingeschleuste Code den Kernel jedoch blockieren, wäre das Ergebnis verheerend: Ein Hänger des gesamten Systems wäre die Folge und käme einem Absturz des Rechners gleich. Deshalb prüft BPF den Code vor dem Einschleusen auf Herz und Nieren und fügt ihn nur ein, falls die Analyse ergibt, dass er sich zügig beenden wird. Darum bietet BPFtrace auch keine For-Schleifen oder ähnliche Konstrukte an, von denen sich nicht sicher vorhersagen lässt, ob sie in absehbarer Zeit aufhören zu laufen.
Reichlich Auswahl
Es gibt reichlich Auswahl an Sonden im Kernel. Von »vfs_read«, der Funktion, die Bytes von der Festplatte liest und einer Sonde deren Anzahl mitgeben kann, über »do_exe_cve« fürs Überwachen neu erzeugter Unix-Prozesse bis »trace_pagefault_reg«, das beim Nachladen einer Memory-Seite auslöst, kann der User dem Kernel nach Belieben auf die Finger schauen und in Echtzeit sehen, was gerade läuft und wo die Engpässe liegen.
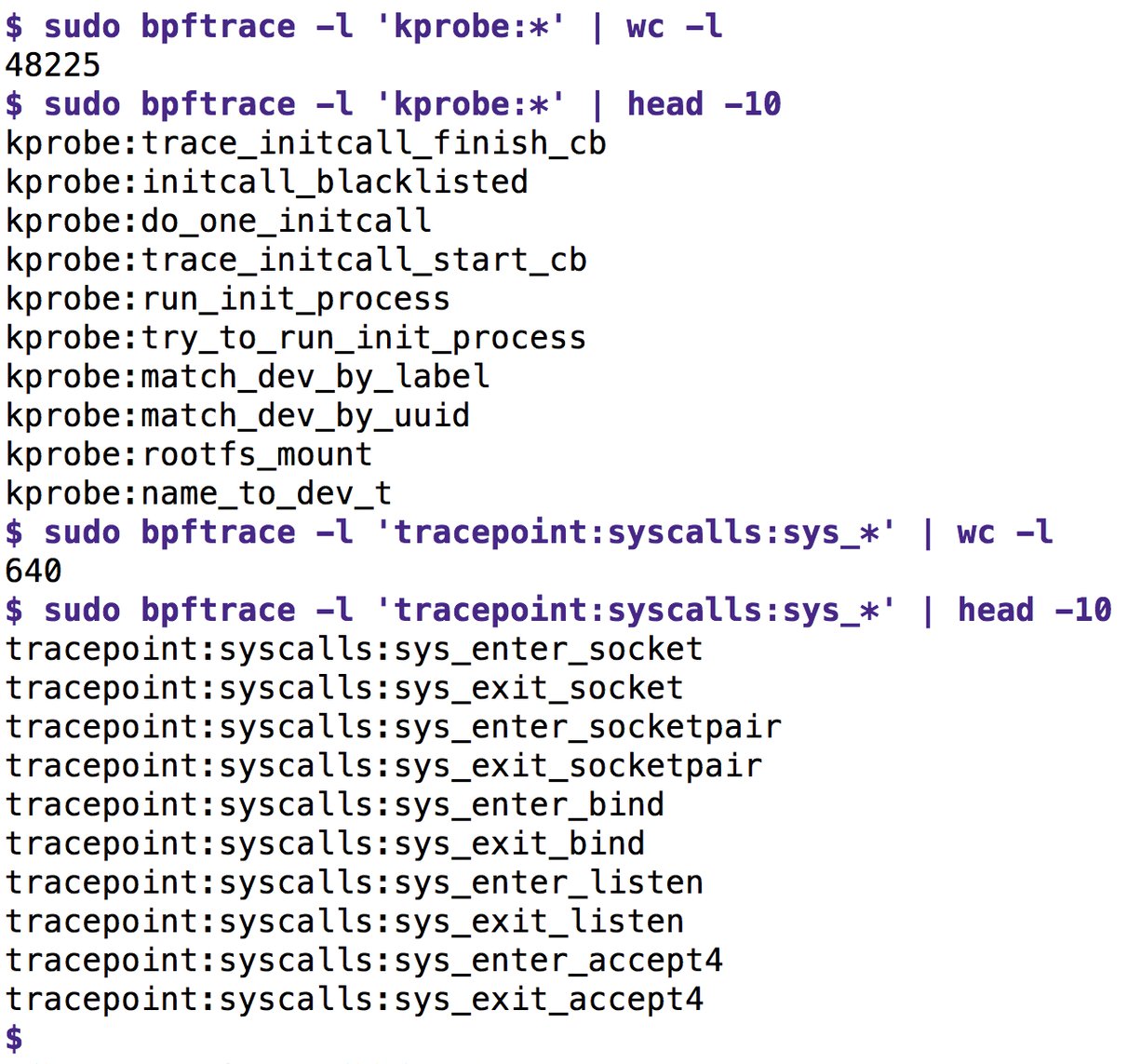
Abbildung 2: Eine Auswahl von Tracepoints und Kprobes im Linux-Kernel, die BPFtrace anzapfen kann.
Abbildung 2 listet die Sonden auf, die BPFtrace bei einem Aufruf mit der Option »-l« ausgibt. Dabei unterscheidet BPF zwischen den »kprobe«-Sonden, die wichtige Kernelfunktionen dem Namen nach verfolgen, und »tracepoint«-Sonden, die die Kernelentwickler auf etwas höherer logischer Ebene von Hand warten und die deswegen resistenter gegen Änderungen des Kernels sind. Im Gegensatz zur Kernel-ABI in Richtung Userland sind ja Kernel-interne Funktionen keineswegs garantiert stabil.
Luft nach oben
Wie wäre es mit einem Skript, das alle auf dem System neu erzeugten Prozesse in Echtzeit ausgibt, samt Kommando und dessen Parametern? Listing 2 zeigt den entsprechenden Einzeiler, der den Tracepoint »sys_enter_execve« aktiviert und dessen Argumenteliste »argv« in der Struktur »args« zusammenfasst.
Hier zeigt sich, dass das Angebot an Funktionen in BPFtrace noch Luft nach oben hat: So gibt es die Funktion »join()«, die Elemente einer Kommandozeile in »args->argv« mittels Leerzeichen aneinanderreiht und ausgibt. Sie kann das Ergebnis aber nicht als String zurückgeben, sodass man es mit »printf()« formatiert ausgeben könnte. Eine kommende Version soll Abhilfe schaffen.
Listing 2
procs-new.bt
01 #!/usr/bin/bpftrace
02
03 BEGIN
04 {
05 printf("New processes with arguments\n");
06 }
07
08 tracepoint:syscalls:sys_enter_execve
09 {
10 join(args->argv);
11 }
Der »BEGIN«-Block ab Zeile 3 dient der Unterhaltung des Users. Soll das Skript nach dem Start eine Meldung ausgeben oder eine Variable initialisieren, erfolgt das wie in Listing 2 im »BEGIN«-Block, ganz nach dem Vorbild Awk.
Mittendrin
Komplizierter wird es aber, wenn eine Sonde, die ein Problem feststellt, die gewünschten Daten nicht ausgeben kann, weil sie woanders liegen. Um etwa den Blick auf Prozesse zu werfen, die versuchen Dateien zu öffnen, die es gar nicht gibt (oder auf die sie keinen Zugriff haben), zapft Listing 3 den Tracepoint »sys_exit_openat« an. Den springt der Kernel an, wenn der Syscall »open()«-zurückkehrt.
Listing 3
opens-failed.bt
01 #!/usr/bin/bpftrace
02
03 tracepoint:syscalls:sys_enter_openat
04 {
05 @filename[tid] = args->filename
06 }
07
08 tracepoint:syscalls:sys_exit_openat
09 / @filename[tid] /
10 {
11 if ( args->ret < 0 ) {
12 printf("%s %s\n", comm, str(@filename[tid]));
13 };
14 delete(@filename[tid]);
15 }
Mit der Bedingung »args->ret < 0« prüft BPFtrace, ob der Return-Code kleiner null war, also die gewünschte Datei nicht geöffnet werden konnte. Falls ja, sollte der Code an diesem Punkt den betroffenen Prozess und den Namen der Datei ausgeben. Allerdings verfügt der »exit«-Tracepoint nicht über den Dateinamen: Der lag lediglich beim Eintritt in die »open()«-Funktion vor, den der Tracepoint »sys_enter_openat« (»enter« statt »exit«) abgehandelt hat.
Die Lösung besteht in diesem Fall darin, die Namen aller Dateien beim Einstieg in »open()«, also im Tracepoint »sys_enter_openat«, in einer Datenstruktur vom Typ Map zwischenzuspeichern, und zwar unter dem Schlüssel der aktuellen Kernel-Thread-ID, die in der vorbesetzten Variablen »tid« vorliegt. Schlägt das Öffnen der Datei später fehl, kann der Tracepoint »sys_exit_openat« in der Map nachsehen, wie der Name der betroffenen Datei lautet, und diesen zusammen mit dem Kommando des betroffenen Prozesses in »comm« dem interessierten User mitteilen.
Der in Zeile 9 gesetzte Filter »/ @filename[tid] /« der Sonde stellt sicher, dass der nachfolgende Code nur dann zur Ausführung gelangt, falls der Kernel-Thread vorher den Dateinamen gesetzt hat. Kam der Aufruf von woanders her als dem oben definierten »sys_enter_openat«, bleibt der Map-Eintrag leer und der Filter sperrt.
Nach getaner Arbeit löscht Zeile 14 mit »delete« den Map-Eintrag wieder. Unterbliebe dies, würde die Map ungebremst wachsen und bei längerer Laufzeit des BPFtrace-Skripts irgendwann zu viel Speicherplatz verschlingen.
Wer schreibt wie viel?
Um herauszufinden, welche Prozesse die meisten Daten auf die Festplatte schreiben, hängt sich Listing 4 in den Tracepoint »sys_exit_write« ein und legt mit dem Filter »/ args->ret > 0 /« fest, dass die Sonde nur erfolgreiche Schreibvorgänge erfasst.
Listing 4
bytes-by-process.bt
01 #!/usr/bin/bpftrace
02
03 tracepoint:syscalls:sys_exit_write
04 /args->ret > 0/
05 {
06 @[comm] = sum(args->ret)
07 }
Das Codekonstrukt in Zeile 6 schnappt sich die Anzahl der geschriebenen Bytes aus »args->ret«, weist sie dann der unbenannten Map »@« unter dem Schlüssel des Prozessnamens zu und bestimmt mittels »sum()«, dass neue Werte zu eventuell vorher dort liegenden noch addiert werden.
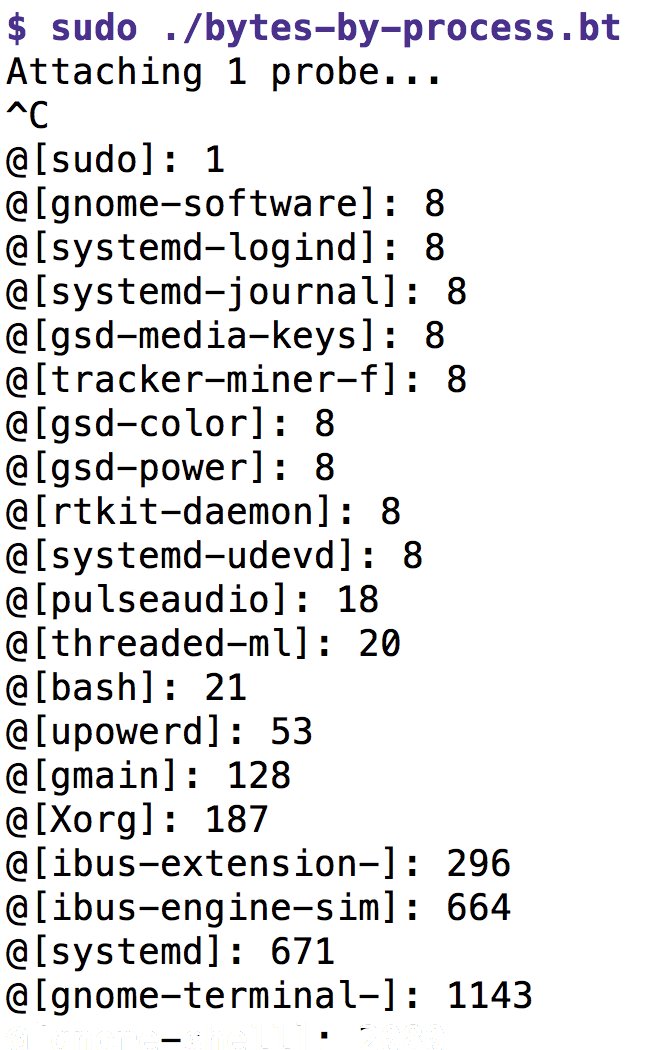
Abbildung 3: Listing 4 zählt für jeden Prozess die Anzahl der geschriebenen Bytes.
BPFtrace gibt bei Programmende – in diesem Fall, nachdem der Benutzer die Tastenkombination [Strg]+[C] gedrückt hat – alle Maps mit Inhalt aus. Entsprechend zeigt Abbildung 3 alle gerade schreibwütig tätigen Prozesse sowie die Anzahl der dabei geschriebenen Bytes an. Alternativ dazu könnte auch ein »END«-Block die Map ohne Namen mit »print(@)« ausgeben.
Scheibchenweise
Wie steht es mit der Länge der geschriebenen Datenblöcke? BPFtrace könnte zwar die Byte-Länge jedes Schreibvorgangs protokollieren, doch das Resultat wäre wegen der Masse der Einzeldaten unlesbar. Hinzu kommt, dass jede »printf()«-Anweisung warten muss, bis das langsame Terminal den geschriebenen Text absorbiert hat. Das dauert nach Kernel-Maßstäben eine Ewigkeit. Um die Verzögerung in vertretbarem Rahmen zu halten, lässt die Sonde dann gelegentlich ein Ereignis unverarbeitet passieren und druckt »Skipped xxx events« aus. Zum Glück bietet BPF schon auf Kernelebene statistische Verarbeitungsroutinen an, etwa »hist()« in Listing 5.
Listing 5
writes-by-size.bt
01 #!/usr/bin/bpftrace
02
03 tracepoint:syscalls:sys_exit_write
04 /args->ret > 0/
05 {
06 @ = hist(args->ret)
07 }
Es weist den hereinkommenden Blockgrößen der Schreibvorgänge Eimer von wachsender Größe zu und druckt die speichernde Variable vom Typ Map am Ende des Programms als Histogramm aus. Abbildung 4 zeigt, dass die Länge der geschriebenen Datenblöcke von 1 Byte bis 256 KByte variiert, dass aber die häufigsten Blocklängen zwischen 8 und 16 Bytes sowie 128 und 256 KByte liegen. Ganz links steht jeweils das Intervall von der minimalen bis zur maximalen Größe des Eimers, in der Mitte die Zahl der Einträge im Eimer, rechts die grafische Animation des Zählers.
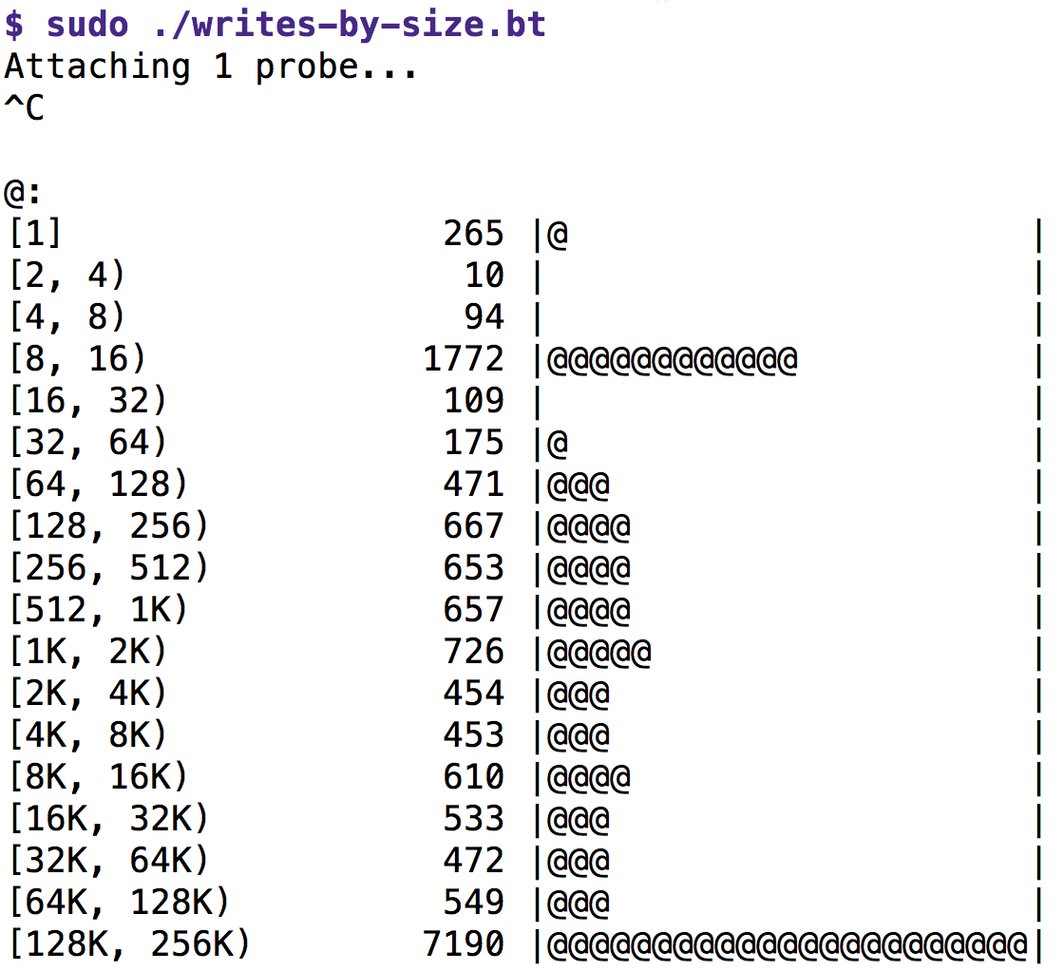
Abbildung 4: Listing 5 sortiert die Schreibvorgänge nach Blockgrößen.
Solche Histogramme eignen sich außerdem dazu, Mittelwerte und eventuelle Ausreißer bei Zeitmessungen darzustellen, etwa bei Paketlaufzeiten im Netzwerk. Hier ermittelt BPFtrace ähnlich wie in Listing 3 die Zeitdifferenz zwischen einem »enter«-»exit«-Tracepoint-Paar, indem es beim Eintritt den aktuellen Nanosekunden-Wert mit der Variablen »nsecs« zwischenspeichert, um ihn später beim »exit«-Tracepoint vom aktuellen »nsecs«-Wert zu subtrahieren.
Anhand der grafischen Darstellung lässt sich ermitteln, ob Service Level Agreements eingehalten und wie häufig dort gesteckte Ziele verfehlt wurden. Weitere Variablen und Kommandos für BPFtrace stehen in der Dokumentation [3] und auf einem praktischen Spickzettel [4].
Wer einen neuen Kernel fährt und vor entwicklungsbedingten Schwachstellen des Tracers nicht zurückschreckt, der hat ein mächtiges Werkzeug zur Hand. Es stellt so ziemlich alles bisher Dagewesene in den Schatten, wenn es darum geht, systembedingten Engpässen von Linux-Servern schnell auf die Schliche zu kommen.
Infos
-
Mpstat: Paul Menzel, “Insider-Job”: LM 02/2019, S. 24, https://www.linux-magazin.de/ausgaben/2019/02/perf
-
Buch zu BPF: Brendan Gregg “BPF Performance Tools”: Addison-Wesley, 2019, https://www.amazon.com/BPF-Performance-Tools-Brendan-Gregg/dp/0136554822
-
BPFtrace Reference Guide: https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md
-
BPF Cheat Sheet: http://brendangregg.com/BPF/bpftrace-cheat-sheet.html
-
Listings zum Artikel: http://www.linux-magazin.de/static/listings/magazin/2019/11/snapshot/
Der Autor

Michael Schilli arbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





