
RAM- und Temp-Filesysteme sparen Code, Hauptspeicher und Rechenzeit. Beste Voraussetzungen, um damit Linux beim Booten auf die Sprünge zu helfen.
Einen richtigen Namen hat die Technik nicht. Von Early Userland und RAM-Filesystem sprechen die Entwickler. Der eigentlich unkorrekte Begriff Ramdisk beschreibt aber am besten, wie sie funktioniert: Der Computer legt Dateien im Hauptspeicher ab, ist so unabhängig von einer Festplatte und hat schnellen Zugriff auf sie. Gerade Entwickler von eingebetteten Systemen setzen schon lange auf Ramdisks, da sie helfen – genügend RAM vorausgesetzt – die Zahl der Zugriffe auf empfindliche Flashspeicher zu verringern, die nur eine begrenzte Anzahl Schreiboperationen erlauben. Für den Nutzer beinahe unbemerkt bootet heute kein aktuelles Linux-System mehr ohne RAM-Filesystem [1].
Ein in viele Module aufgeteiltes Linux unterliegt einem Henne-Ei-Problem, das erst das Early Userland löst: Treiber und Gerätedateien wie »/dev/console« liegen auf dem Hintergrundspeicher, der Kern benötigt die Treiber jedoch, um auf das Dateisystem zuzugreifen. Mindestens zwei Module sind nötig: Ein Treiber für den Hintergrundspeicher und eines, um das Dateisystem zu interpretieren, beispielsweise »sata« und »ext3«. Dieses Dilemma löst Linux via Virtual File System (VFS) und RAM-FS.
Ohne Treiber
Der Trick ist simpel: Ein Filesystemtreiber ist im Grunde eine Software, die spezifische Eigenschaften der einzelnen Dateisysteme auf das intern verwendete Virtual-Filesystem abbildet und damit dem Kernel ein einheitliches Bild vermittelt. Erst so kann Linux unterschiedliche Dateisysteme homogen als gemeinsamen Dateibaum darstellen.
Die dem VFS zugrunde liegenden Strukturen vermag der Kernel aber auch direkt aufzubauen. Dieser Überlegung folgend erlaubt es das Kernel-Buildsystem, später notwendige Treiber, Gerätedateien und Bootprogramme in ein CPIO-Archiv zu packen und es quasi huckepack an das Kernelimage zu kleben. So schaufelt der Bootloader beides in den Hauptspeicher. Da er und nicht der Kernel diese Arbeit durchführt, benötigt der Datentransport den Kernel gar nicht.
Sobald der Bootloader die Kontrolle an den Kernel überträgt, initialisiert dieser das Prozess- und Memory-Management und konstruiert aus dem im Hauptspeicher befindlichen Archiv das für den Betrieb notwendige Root-Filesystem (Abbildung 1, rechts). Dieser Weg ist viel eleganter, als einen Umweg über eine Ramdisk zu nehmen, bei der der Kernel Hauptspeicher einer bestimmten Größe reserviert, darin ein Filesystem erzeugt und in dieses schließlich Daten aus einem Archiv kopiert (Abbildung 1, links). Dass er stattdessen die Dateien direkt in die Kernel-internen Datenstrukturen des VFS umsetzt, spart Code, Speicherplatz und Rechenzeit.
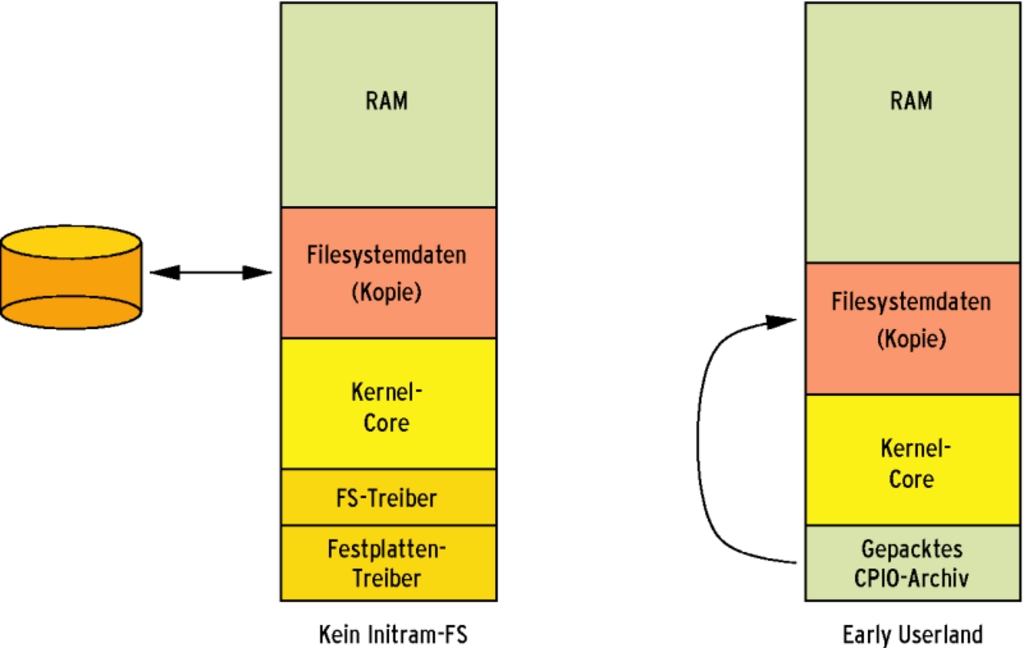
Abbildung 1: Das Early Userland (rechts) entnimmt die Daten seines Root-Filesystems einem komprimierten CPIO-Archiv. Den Speicher, den das Archiv belegt, gibt der Kernel wieder frei, sobald er sich vollständig initialisiert hat. Links ist im Vergleich ein herkömmlicher Filesystem-Zugriff auf die Ramdisk zu sehen.
Anders als eine Ramdisk, die immer eine feste Größe von 4, 8 oder 16 MByte hat, benötigt das RAM-Filesystem genau so viel Speicher wie die darin abgelegten Daten. Für eine Datei mit beispielsweise 12 KByte verwendet das Filesystem auch nur 12 KByte RAM. Legt der Anwender mehr Dateien an, wächst das RAM-Filesystem entsprechend mit. Sollten jedoch Amok laufende oder böswillige Threads ein solches Filesystem mit Daten fluten, kann das auch ein Nachteil sein.
Frühes Userland
Desktop- und Server-Linuxe nutzen das Early Userland, um dort Treiber für Festplatten- und Netzwerk-Controller und eventuell zugehörige Firmware abzulegen. Außerdem befindet sich dort ein Programm oder ein Shellskript mit dem Namen »init«, das der Kernel als ersten Prozess mit der PID 1 startet, wenn er das System hochfährt.
Dieses Gespann ermöglicht, zum Beispiel in einem festplattenlosen System, die Root-Partition über NFS per WLAN zu mounten. Der Init-Prozess lädt aus dem RAM-FS eventuell notwendige Firmware, den NFS- und den WLAN-Treiber. Damit ausgerüstet mountet er das neue Root-Filesystem mit Hilfe des Systemcalls »pivot_root«. Das kann durchaus auch wieder ein RAM-Filesystem sein (siehe Kasten “Schlanke Root-Filesysteme”). Jetzt darf er das RAM-Filesystem wieder aushängen und sich selbst per »excec()« in den neuen Init-Prozess verwandeln, dessen Programm auf dem neuen Root-Filesystem liegt (Abbildung 2). Das als Sprungbrett verwendete RAM-Filesystem ist für den Nutzer fortan unsichtbar.
|
Schlanke |
|---|
|
Root-Filesysteme, die der Kernel im Hauptspeicher instanziiert und die dort auch bleiben sollen, enthalten typischerweise nicht mehr Funktionalität als unbedingt notwendig. Schließlich steht jedes Byte, das das Root-Filesystem belegt, den Applikationen nicht mehr zur Verfügung. Wann immer es eine Auswahl gibt (etwa »ash« oder »bash«), empfiehlt sich die einfachere und schlankere Variante. Abgelegte Software lässt sich noch entrümpeln, denn oft braucht ein initiales Root-Filesystem nicht alle Funktionen. Besonders hoch ist das Einsparpotenzial bei Bibliotheken, vor allem der Standard-C-Bibliothek. Da Shared Librarys mit dem notwendigen Framework viel Speicher belegen, setzen einige Entwickler – back to the roots – auf statisch gelinkte Applikationen (siehe Abbildung 5). Da hierfür die »glibc« zu aufgebläht ist, haben die Kernelhacker eigene handliche Varianten entwickelt, die die wesentlichen Systemfunktionen beinhalten: Die »klibc« [4], »dietlibc« [5] und »newlib« [6] erfüllen auch ihren Zweck. Gerade Entwickler von Distributionen packen zusätzlich die notwendigsten Applikationen in ein Multi-Call-Binary wie beispielsweise »busybox«. Diese Applikation erledigt je nach dem Namen, mit dem sie der Anwender aufruft, unterschiedliche Aufgaben. Der Kernel übergibt jeder Anwendung ihren Aufrufnamen (zum Beispiel aus der Shell) als ersten Parameter »argv[0]«. Dank Links haben manche Programme viele Namen und der Entwickler muss die Standardbibliothek nur einmal statisch an den Code binden. Mehr dazu erläutert ein eigener Artikel in diesem Heft. |
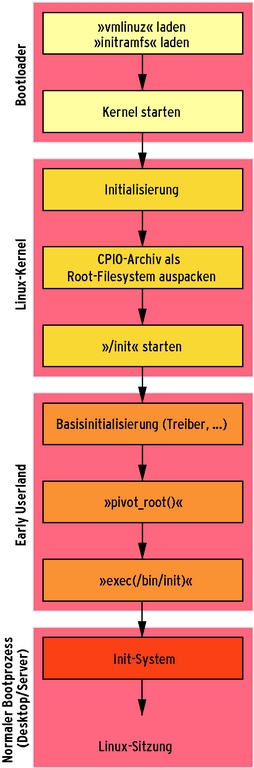
Abbildung 2: Desktop und Server nutzen das Early Userland als Zwischenstufe, bevor sie das eigentliche Init-System aktivieren.
Spezialfall: Embedded
Bei eingebetteten Systemen ist das Early Userland nicht das Mittel, sondern das Ziel. Embedded-Systeme müssen oft – der Einsatzumgebung geschuldet – ohne Festplatte auskommen und besitzen ersatzweise einen Flashspeicher. Auch moderne Flashsysteme lassen nur eine endliche Anzahl von Schreibzyklen zu. So erstaunt es manchen Architekten, wie leichtfertig viele Hersteller das Root-Filesystem auf dem Flashspeicher ablegen. Tatsächlich ist dies dank Early Userland nur in den Fällen notwendig, in denen Hauptspeicher Mangelware ist.
Stattdessen stellt der umsichtige Entwickler sein finales Root-Filesystem in Form eines Gzip-komprimierten CPIO-Archivs zusammen. Viele Bootloader sind in der Lage, es unabhängig vom Kernel in den Hauptspeicher zu laden. Besonders praktisch in der Embedded-Welt: Dieses Verfahren ermöglicht während der Entwicklung schnelle Testzyklen mit einfachen Buildverfahren.
Die Konfigurationsvariable »CONFIG_INITRAMFS_SOURCE« des Kernel-Buildsystems steuert, ob das Archiv vom Kernelimage separiert bleibt (Abbildung 3). Ist die Variable nicht belegt, erwartet der Kernel ein externes Archiv für das Root-Filesystem. Bei aktiviertem »CONFIG_BLK_DEV_INITRD« erzeugt der Kernel trotzdem ein Archiv, das aber leer bleibt. Der Kernel wächst dadurch nur um 157 Bytes gegenüber einem Kernel, der Initram-FS nicht unterstützt (Abbildung 4).
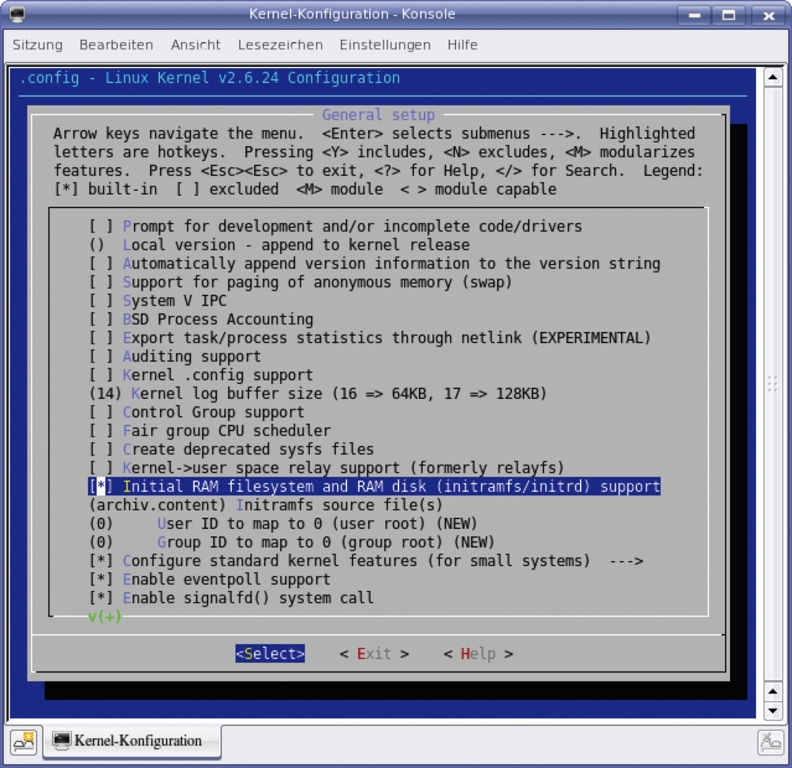
Abbildung 3: Mit aktivierter Option »Initial RAM filesystem…« unterstützt der Kernel das Root-Filesystem im RAM. Damit Linux ein generiertes CPIO-Archiv übernimmt, muss der Anwender zusätzliche »Initramfs source file(s)« – wie hier exemplarisch gezeigt – auswählen.
Kernel bauen
Unter Ubuntu und Debian erzeugt das Skript »update-initramfs« ein Archiv und legt es unter einem Namen wie »initrd.img-2.6.22-14-generic« in dem Verzeichnis »/boot« ab. Die Konfiguration ist in der Datei »/etc/initramfs-tools/initramfs.conf« zu finden. Wer beispielsweise die Anzahl der ins Archiv zu integrierenden Module reduzieren möchte, ist hier an der richtigen Stelle. Der Kasten “Initrd-Archiv ein- und auspacken” erläutert, wie man das so entstandene Archiv inspiziert und ändert.
|
Initrd-Archiv ein- und |
|---|
|
Beim Booten füllt der Kernel das initiale RAM-FS mit Daten. Das beim Übersetzen des Kernels erzeugte und komprimierte CPIO-Archiv findet sich in den Kernelquellen unter »…/usr/initramfs_data.cpio.gz«. Ubuntu und Debian legen das Archiv typischerweise im Verzeichnis »boot« ab (»/boot/initrd.img-2.6.22-14-generic«). Um es zu inspizieren, legt der Admin am besten ein eigenes Verzeichnis an und führt folgende Kommandos aus: mkdir /tmp/cpio cd /tmp/cpio zcat /usr/src/linux/usr/initramfs_data.cpio.gz | sudo cpio -i -d -H newc --no-absolute-filenames Das Archiv ist im neuen CPIO-Format gespeichert, das die Option »-H newc« erfordert. Da es Gerätedateien enthält, muss der Anwender Root-Rechte besitzen, um diese anzulegen. Weil »cpio« normalerweise absolute Pfadangaben verwendet, sollte der Admin es mit der Option »–no-absolute-filenames« aufrufen. Andernfalls könnte das Tool wesentliche Systemprogramme überschreiben und das System damit unbrauchbar machen. Archiv für die Initrd erstellenUm ein eigenes Archiv zusammenzustellen – wie es bei eingebetteten Systemen häufig notwendig ist -, hat Rob Landley Listing 1 »mkinitramfs« zur Verfügung gestellt, das aus einem Verzeichnis ein Archiv erzeugt. Wie er begleitend schreibt, ist das im Skript verwendete »find«-Kommando wichtig, damit der einfach gestrickte »cpio«-Code im Kernel das erzeugte Archiv auch richtig dekodiert. |
Alternativ gibt »CONFIG_INITRAMFS_SOURCE« an, welche Dateien ins initiale RAM-Filesystem gehören. Der Kernel erlaubt es, sie in einem Verzeichnis abzulegen oder sie per Liste anzugeben. Wer »CONFIG_INITRAMFS_SOURCE« mit einem Verzeichnisnamen belegt, überträgt beim Bau des Kernels den Inhalt des angegebenen Ordners ins Archiv. Andernfalls erwartet das Kernelskript »gen_init_cpio« eine Dateiliste. Sie hat den Vorteil, dass für diesen Weg keine Superuser-Rechte notwendig sind.
|
Listing 1: |
|---|
01 #!/bin/sh 02 # Copyright 2006 Rob Landley <rob@landley.net> and TimeSys Corporation. 03 # Licensed under GPL version 2 04 05 if [ $# -ne 2 ] 06 then 07 echo "usage: mkinitramfs directory imagename.cpio.gz" 08 exit 1 09 fi 10 11 if [ -d "$1" ] 12 then 13 echo "creating $2 from $1" 14 (cd "$1"; find . | cpio -o -H newc | gzip) > "$2" 15 else 16 echo "First argument must be a directory" 17 exit 1 18 fi |
Jede Zeile der Dateiliste bestimmt ein Element des Archivs. Die erste Spalte gibt dessen Typ an: »dir« für ein Verzeichnis, »nod« für ein Device-File, »slink« für symbolische Links und »file« für normale Dateien. Danach folgen der Name und bei Links und Files noch die Quelle. Die nächste Spalte listet die Zugriffsrechte in Oktal-Notation, danach Owner- und Gruppen-ID. Bei Device-Files stehen abschließend noch Gerätetyp (»b« oder »c«), Major- und Minor-Nummer.
Die Vorteile des RAM-Filesystems legen nahe, es auch für andere Zwecke zu nutzen, beispielsweise für temporäre Daten (»/tmp«). Dass das Filesystem keine Größenbegrenzung kennt, gerät jetzt allerdings zum Nachteil: Eine Denial-of-Service-Attacke flutet leicht den Hauptspeicher. Daher haben die Kernelentwickler mit dem »tmpfs« eine Variante programmiert, die ihre Größen überwacht. Standardmäßig beschränkt sie sich auf 50 Prozent des Hauptspeichers, per Mount-Option lassen sich aber auch andere Größen einstellen:
mount -t tmpfs -o size=512M,mode=1777 none /tmp
Die Ausgabe von »mount« zeigt, dass der 2.6er Kernel »tmpfs« fleißig verwendet. Ubuntu etwa nutzt es für Verzeichnisse mit temporären Daten, etwa »/var/run«, »/var/lock« und »/dev/shm«. Insbesondere das heute dynamisch mit Inhalt gefüllte Verzeichnis »/dev« legt der Geräte-Daemon »udev« als »tmpfs« an und füllt es mit Gerätedateien.
Mit »tmpfs« ist die Variantenvielfalt virtueller Dateisysteme im Linux-Kernel bei Weitem nicht erschöpft. Auf Basis von Cram-FS lassen sich beispielsweise Dateien komprimiert im Hauptspeicher ablegen. Für eingebettete Systeme mit wenig Hauptspeicher ist das attraktiv. Allerdings hat die Sache einen Haken: Die Daten lassen sich nur lesen, aber nicht verändern.
Dass sich virtuelle Dateisysteme mit spezifischen Eigenschaften auch sehr leicht selbst entwickeln lassen, hat bereits eine frühere Kerntechnik [2] demonstriert. Den dort entwickelten und auf einen aktuellen Kernel (2.6.24) angepassten Quelltext bietet der FTP-Server des Linux-Magazins [3] zum Download an.
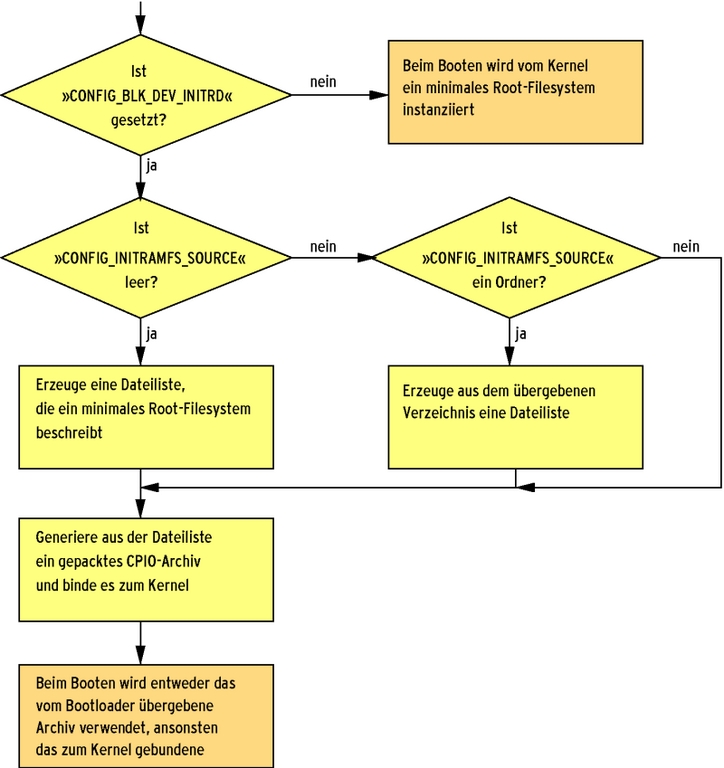
Abbildung 4: Die Kernelkonfiguration entscheidet durch die Variablen »CONFIG_BLK_DEV_INITRD« und »CONFIG_INITRAMFS_SOURCE«, ob sie ein gepacktes CPIO-Archiv erzeugt und mit welchen Inhalten sie es füllt.
Es war einmal
Neben diversen virtuellen Filesystemen existiert weiterhin die klassische Ramdisk im Linux-Kernel. Die Komponenten, die das Root-Filesystem im RAM ermöglichen, befinden sich in den Kernelquellen an den verschiedensten Stellen. Tabelle 1 dient als Wegweiser.
|
Tabelle 1: RAM-FS |
|
|---|---|
|
Datei |
Bedeutung |
|
fs/ramfs/* |
Quellcode zu »ramfs« |
|
fs/cramfs/* |
Quellcode zu »cramfs« |
|
drivers/block/rd.c |
Quellcode der Ramdisk |
|
init/initramfs.c |
Quellcode zum Auspacken des CPIO-Archivs |
|
scripts/gen_initramfs.sh |
Skript zum Erzeugen der Archiv-Dateiliste |
|
usr/gen_cpio.c |
Programm zum Erzeugen eines CPIO-Archivs aus einer |
|
Documentation/early-userspace |
Erläuterungen zum Kernelverzeichnis »usr« |
|
Documentation/initrd.txt |
Erläuterungen zu Initrd (1999/2000) |
|
Documentation/ramdisk.txt |
Erläuterungen zur alten Ramdisk (1995/2004) |
|
Documentation/filesystems/ramfs- |
Erläuterungen zu |
|
Documentation/filesystems/cramfs |
Erläuterungen zu »cramfs« |
|
Documentation/filesystems/tmpfs |
Erklärung zu »tmpfs« und dessen |
Die klassische Ramdisk lässt sich aktivieren, indem der Admin bei der Kernelkonfiguration unter »Block Devices« den Punkt »Ram Disk Support« auswählt. Damit setzt er die Variable »CONFIG_BLK_DEV_RAM«. Ein so übersetzter Kernel stellt Gerätedateien für Blockdevices wie »/dev/ram0« oder »/dev/ram1« bereit. Bekannte Werkzeuge erlauben es, Dateisysteme zu erzeugen (formatieren) und zu mounten:
mke2fs /dev/ram0 mount /dev/ram0 /mnt
Im Hinblick auf die Vorteile der anderen RAM-Filesysteme steht jedoch zur Diskussion, welche Vorteile dieser Ahnvater der moderneren Subsysteme noch hat.
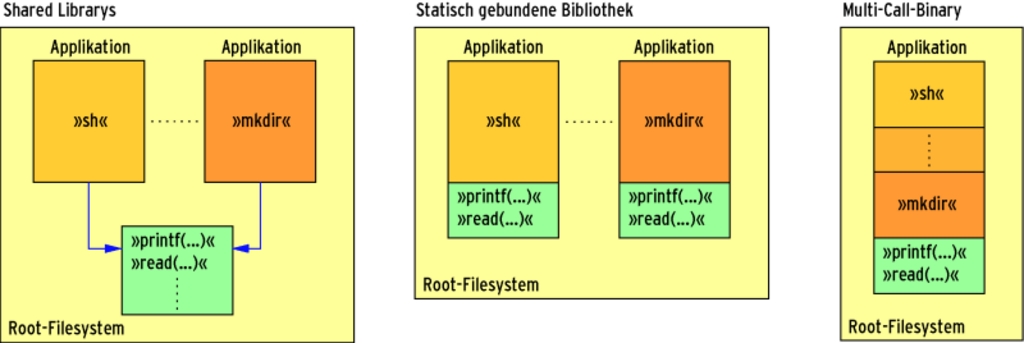
Abbildung 5: Für das Early Userland ist der mit Shared Librarys verbundene Speicherplatz-Overhead zu groß (links). Hier sind Mini-Applikationen gefragt, die schlanke Bibliotheken statisch linken (Mitte). Noch mehr Platz sparen Multi-Call-Binarys, die die Aufgabe mehrerer Programme in einem File vereinen.
Nützlicher Helfer
Auf den ersten Blick erscheint die Vielfalt der RAM-Filesysteme verwirrend. Dass dies dem Kernel erlaubt von nahezu jedem Gerät zu booten, ist mehr als nur eine Entschädigung. Gerade für volatile Daten, die nur eine kurze Lebensdauer im Filesystem haben, sind sie ein nützlicher Helfer. Der Zugriff auf den Hauptspeicher läuft viel schneller als auf eine Festplatte – wenn überhaupt eine vorhanden ist – oder auf einen sonstigen Hintergrundspeicher. (mg)
|
Infos: |
|---|
|
[1] Rob Landley, “Introducing initramfs, a new model for initial RAM disks”: [http://www.linuxdevices.com/articles/AT4017834659.html] [2] Eva-Katharina Kunst und Jürgen Quade: “Kerntechnik, Folge 23”: Linux-Magazin 10/05, S. 90 [3] Sourcecode: [ftp://ftp.linux-magazin.de/pub/magazin/2008/05/Kerntechnik] [4] Git-Archiv zu »klibc«: [http://git.kernel.org/?p=libs/klibc/klibc.git;a=summary] [5] Wikipedia-Artikel zur Dietlibc: [http://en.wikipedia.org/wiki/Dietlibc] [6] Newlib: [http://www.sourceware.org/newlib/] |
|
Die Autoren |
|---|
|
Eva-Katharina Kunst, Journalistin, und Jürgen Quade, Professor an der Hochschule Niederrhein, sind seit den Anfängen von Linux Fans von Open Source. Unter dem Titel “Linux Treiber entwickeln” haben sie zusammen ein Buch zum Kernel 2.6 veröffentlicht. |






