
Mit jeder 64-Bit-Maschine, die über die Ladentheke geht, stehen die Kernelprogrammierer auf dem Prüfstand: Ist ihr eigener Code 64-Bit-tauglich oder nicht? Auch bei der Portierung auf exotische Prozessoren gibt es einiges zu beachten.
Bis vor kurzem war die Welt noch einfach: Alle gängigen PCs waren mit einem Prozessor der Pentium-Klasse bestückt, deren Registerbreite stets 32 Bit beträgt. Zwar unterstützt der Linux-Kernel schon seit Jahren auch andere Architekturen. Aber Hand aufs Herz: Auf der Mehrheit der Maschinen prangt ein Intel- oder ein AMD-Logo.
64 statt 32 Bit
Die Sache mit dem Logo hat sich seitdem nicht grundlegend geändert, doch bei der Registerbreite hat AMD mit der ursprünglich AMD64 genannten Technik einen Sprung getan. Intel folgte mit der kompatiblen Technik EMT64 nach, sodass neue Rechner heute problemlos mit 64 Bit rechnen.
Beim Datentyp »long« kommt der wesentliche Unterschied zwischen 32- und 64-Bit-Technik zum Tragen: Er umfasst auf einem 32-Bit-System tatsächlich 32 Bit, auf dem 64-Bit-System 64. Anders beim Datentyp »int«: Dass er auf einem 64-Bit-Rechner ebenfalls 64 Bit umfasst, ist ein weit verbreiteter Irrglaube. Auf beinahe allen Plattformen ist »int« 32 Bit breit.
Spürbar wird dieser Unterschied dann, wenn ein Programmierer sich unbedacht »unsigned int« als Datentyp für einen so genannte neutralen Parameter wählt, dessen wirklicher Typ sich erst beim Aufruf entscheidet. Die meisten Kernelprogrammierer setzen dafür entweder den Typ »unsigned long« oder »void *« ein. Der entscheidende Punkt ist, dass der Datentyp »unsigned int« mit seinen 32 Bit auf einem 64-Bit-System nicht der Breite des Adressbusses entspricht. Während auf einer 32-Bit-Maschine keine Probleme auftreten (siehe Abbildung 1), ist es fatal, unter einem 64-Bit-Linux die Warnung des Compilers zu übersehen (Abbildung 2).
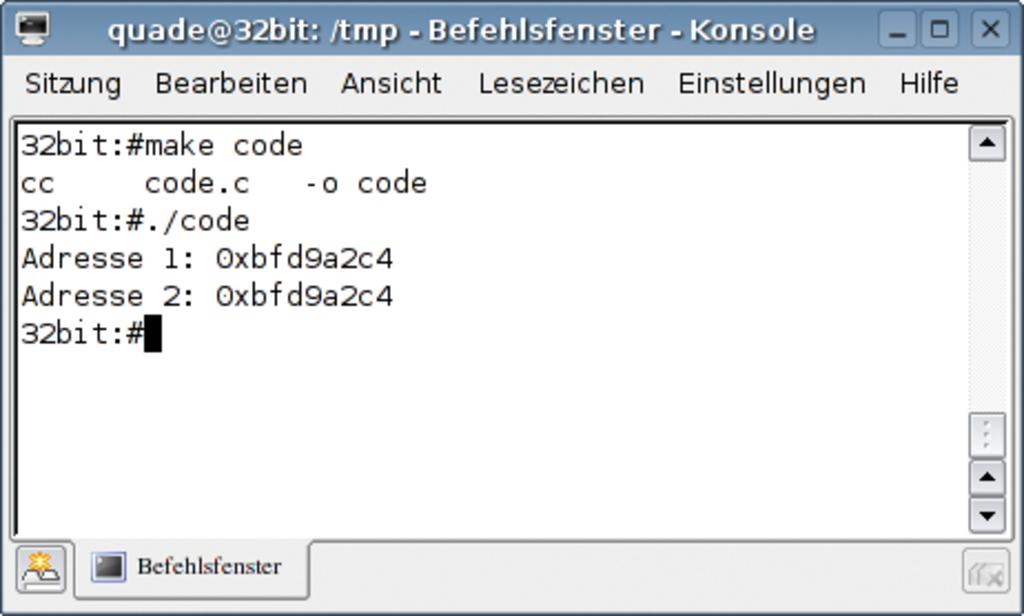
Abbildung 1: Ausgabe des Programms von Listing 1 auf einer 32-Bit-Maschine. Beide Adressen sind wie erwartet identisch.
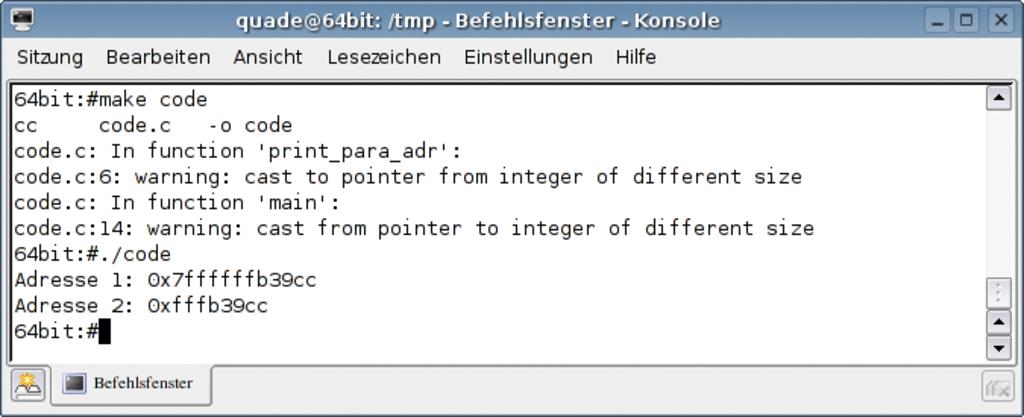
Abbildung 2: Ausgabe des Programms von Listing 1 auf einer 64-Bit-Maschine. Der Compiler warnt bereits bei der Übersetzung vor Problemen, die beim Ablauf auch prompt auftreten.
Listing 1 zeigt beispielhaft, wie ein derartiger, nicht portierbarer Code aussehen kann. Auf einem 64-Bit-System gehen beim Casting einer 8 Byte belegenden Adresse (»&var«) auf einen »int« (Zeile 14) die oberen 4 Bytes verloren. Die Abbildungen 1 und 2 zeigen die zugehörigen Ausgaben auf einer 32- und auf einer 64-Bit-Maschine. Während bei einer Portierung von 32 Bit auf 64 Bit das geschilderte Problem virulent ist, kann es im umgekehrten Fall zu Bereichsüberschreitungen kommen. Ein Beispiel ist der Jiffies-Zähler vom Typ »unsigned long«: Während die knapp 200 Tage bis zum Wrap-Around auf dem 32-Bit-System innerhalb der gesetzlichen Gewährleistungspflicht liegen, brauchen Besitzer von 64-Bit-Maschinen sich erst nach gut 2000 Milliarden Jahren Sorgen zu machen.
|
Listing 1: Typecast mit |
|---|
01 #include <stdio.h>
02
03 void print_para_adr( unsigned int neutraler_parameter )
04 {
05 printf("Adresse 2: %pn", (char *)neutraler_parameter);
06 }
07
08 int main( int argc, char **argv )
09 {
10 int var;
11
12 printf("Adresse 1: %pn", &var );
13 print_para_adr( (int)&var );
14 return 0;
15 }
|
Ein anderer Problemfall sind Signale: Auf der 32-Bit-Maschine braucht man zur Verarbeitung von 64 Signalen zwei Wörter, auf einem 64-Bit-System dagegen nur eines. Man sollte sich als Programmierer also lieber zweimal überlegen, ob der Wertebereich der definierten Variablen auch auf Maschinen unterschiedlicher Wortbreite ausreicht. Der geschickte Einsatz des Makros »BITS_PER_LONG« hilft im Übrigen – wie bei den Signalen – dabei, in der Länge begrenzte Datenfelder portabel zu beherrschen.
Portable Datentypen
Wer eine Speicherzelle mit definierter Wortbreite braucht, kann auf entsprechende Typedefs zurückgreifen. Die in der Headerdatei »asm/types.h« definierten Datentypen »u8«, »u16«, »u32«, »u64« sowie »s8«, »s16«, »s32« und »s64« stellen entsprechende vorzeichenfreie und vorzeichenbehaftete Speicherzellen zur Verfügung. Tauscht der Kernel solche Daten mit einer Applikation aus, zum Beispiel im Rahmen eines IO-Control, sollte man auch die im Userspace bekannten Versionen mit den zwei Unterstrichen verwenden: »__u8«, »__u16«, »__u32«, »__u64« und »__s8«, »__s16«, »__s32« und »__s64« (siehe Tabelle 1).
|
Tabelle 1: |
|
|---|---|
|
Format |
Datentypnamen |
|
Host-Format |
__u8, __u16, __u32, __u64 |
|
Little-Endian-Format |
__le16, __le32, __le64 |
|
Big-Endian-Format (Netzformat) |
__be16, __be32, __be64 |
Endianness
Doch selbst Prozessoren mit gleicher Wortbreite unterscheiden sich noch so grundlegend, dass es zu Portierungsproblemen kommt. Unterschiedliche Prozessoren legen Daten nämlich auch anders im Speicher ab. Denn unglücklicherweise gibt es gleich zwei Formate, um 16-, 32- oder 64-Bit-Wörter im Speicher zu repräsentieren.
Abbildung 3 zeigt, dass das Little-Endian-Format das niederwertige Byte eines Wortes auf die niederwertige Adresse legt. So macht es etwa der klassische PC mit x86-Prozessoren. Eine Sun-Workstation mit Sparc-Prozessor legt dagegen das niederwertige Byte an die höherwertige Adresse. Es gibt sogar Prozessoren, die beides können.
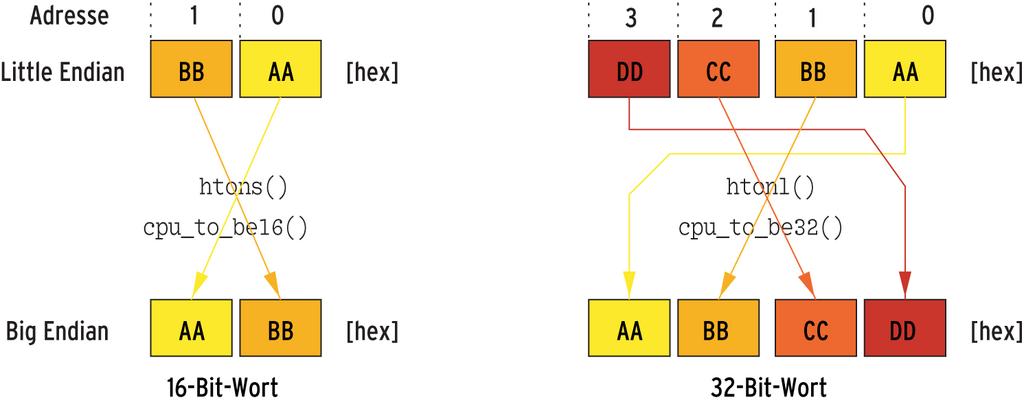
Abbildung 3: Prozessoren legen die einzelnen Bytes eines Datenwortes unterschiedlich im Speicher ab. Beim Little-Endian-Format steht das niederwertige Byte an der niederwertigen (»0«), bei Big Endian dagegen an der höherwertigen Adresse.
Der Endian-Unterschied wird dann zum Problem, wenn zwei oder mehr Prozessoren, die unterschiedliche Datenablageformate verwenden, auf denselben Datensatz zugreifen. Bei vernetzten Rechnersystemen ist das ohnehin oft der Fall. Das Problem kann aber auch beim Zugriff auf intelligente Hardware auftreten, deren Anbindung zumeist über ein Speicherinterface (Dual-Port-RAM, Shared Memory) realisiert ist. Gleiches gilt beim Speichern von Daten auf einer Festplatte – spätestens seit USB 2.0 und Firewire sind diese portabel und leicht von einem zum anderen Rechner zu transportieren.
Byte-Swapping sparen
Zur Lösung des Problems bietet Linux vom Ablageformat des Prozessors unabhängige Datentypen an: »__le16«,» __le32«, »__le64« und »__be16«, »__be32«, »__be64« (siehe Tabelle 1). Außerdem kann der Programmierer auf Makros zurückgreifen, die zwischen den Formaten konvertieren (siehe Tabelle 2).
|
Tabelle 2: |
|
|---|---|
|
Erklärung |
Funktionsnamen |
|
Umwandlung aus dem Host- ins Netzwerk-Format (Big Endian) |
__be16 htons( __u16 value ), __be32 htonl( __u32 value ) |
|
Umwandlung aus dem Netzwerk- (Big Endian) ins Host-Format |
__u16 ntohs( __be16 value ), __132 ntohl( __be32 value ); |
|
Umwandlung aus dem Host- ins Little-Endian-Format |
__le16 cpu_to_le16( __u16 value ), __le32 cpu_to_le32( __u32 |
|
Umwandlung aus dem Host- ins Little-Endian-Format, das der Wandlung wird in der ursprünglichen Variablen abgelegt (in |
void cpu_to_le16s( __u16 *value ), void cpu_to_le32s( __u32 |
|
Umwandlung aus dem Host- ins Big-Endian-Format |
__be16 cpu_to_be16( __u16 value ), __be32 cpu_to_be32( __u32 |
|
Umwandlung aus dem Host- ins Big-Endian-Format, das der Wandlung wird in der ursprünglichen Variablen abgelegt (in |
void cpu_to_be16s( __u16 *value ), void cpu_to_be32s( __u32 void cpu_to_be64s( __u64 *value ) |
|
Umwandlung einer Little-Endian-Variablen ins Host-Format |
__u16 le_to_cpu16( __le16 value ), __u32 le_to_cpu32( __le32 |
|
Umwandlung einer Little-Endian-Variablen ins Host-Format, das wird in der Variablen selbst abgelegt (in situ) |
void le_to_cpu16s( __le16 *value ), void le_to_cpu32s( __le32 void le_to_cpu64s( __le64 *value ) |
|
Umwandlung einer Big-Endian-Variablen ins Host-Format |
__u16 be_to_cpu16( __be16 value ), __u32 be_to_cpu32( __be32 |
|
Umwandlung einer Big-Endian-Variablen ins Host-Format, das wird in der Variablen selbst abgelegt (in situ) |
void be_to_cpu16s( __be16 *value ), void be_to_cpu32s( __be32 void be_to_cpu64s( __be64 *value ) |
Damit bei dieser Umwandlung nicht bereits vorher feststehen muss, ob der verwendete Prozessor ein Little- oder ein Big-Endian-Format unterstützt, wandeln sie immer in das CPU- oder Host-Format respektive aus dem CPU- oder dem Host-Format. Dabei ist natürlich berücksichtigt, ob die CPU selbst das Zielformat unterstützt. Dann wird beim Kompilieren der Wert ohne Byte-Swapping übernommen (siehe »__cpu_to_le32(x)« in Listing 2 , Zeile 2).
|
Listing 2: |
|---|
01 ... 02 #define __cpu_to_le32(x) ((__u32)(x)) 03 #define __le32_to_cpu(x) ((__u32)(x)) 04 #define __cpu_to_le16(x) ((__u16)(x)) 05 #define __le16_to_cpu(x) ((__u16)(x)) 06 #define __cpu_to_be64(x) __swab64((x)) 07 #define __be64_to_cpu(x) __swab64((x)) 08 #define __cpu_to_be32(x) __swab32((x)) 09 #define __be32_to_cpu(x) __swab32((x)) 10 ... |
Die Makros, die im Netzwerkbereich zum Einsatz kommen, heißen: »htons()« (host to network short), »htonl()« (host to network long), »ntohs()« (network to host short) und »ntohl()« (network to host long). Ein Makro »htonc()« (host to char) gibt es nicht, denn das Problem tritt nur bei Variablen auf, die 16, 32 oder 64 Bit umfassen. Der Name Htonl ist übrigens irreführend: Diese Funktion wandelt das Host-Format in ein 32-Bit-Wort (Integer). Wäre es wirklich ein »long«, käme es zu Problemen mit allen 64-Bit-Maschinen. Das Netzwerkformat ist traditionell vom Typ Big Endian. Auf dem x86-PC müssen daher alle Wörter in den Protokollheadern gedreht werden. Eine Sun-Workstation mit Sparc-Prozessor kann darauf verzichten.
Außerhalb der Netzwerkprogrammierung benutzt der Linux-Kernel die Makros »cpu_to_leX()«, »cpu_to_leXs()«, »cpu_to_beX()« und »cpu_to_beXs()« (siehe Tabelle 2), die auch 64 Bit breite Variablen unterstützen. Das angehängte »s« bei einigen der Makros steht für “in situ”. Diese Makros wandeln direkt die Variable selbst. Deshalb besitzen sie keinen Rückgabewert und bekommen nicht eine Kopie, sondern die Adresse der Variablen übergeben.
Das Makro »htons()« entspricht damit der Funktion »cpu_to_be16()«, »htonl()« entspricht »cpu_to_be32()«. Wie man mit Hilfe der Datentypen und Makros programmiert, demonstriert der Kernelcode, der das Ext-2-Filesystem realisiert. Einen Ausschnitt daraus zeigt Listing 3.
|
Listing 3: Ausschnitt aus |
|---|
01 ...
02 struct ext2_super_block {
03 __le32 s_inodes_count; /* Inodes count */
04 __le32 s_blocks_count; /* Blocks count */
05 __le32 s_r_blocks_count; /* Reserved blocks count */
06 __le32 s_free_blocks_count; /* Free blocks count */
07 __le32 s_free_inodes_count; /* Free inodes count */
08 __le32 s_first_data_block; /* First Data Block */
09 __le32 s_log_block_size; /* Block size */
10 __le32 s_log_frag_size; /* Fragment size */
11 __le32 s_blocks_per_group; /* # Blocks per group */
12 __le32 s_frags_per_group; /* # Fragments per group */
13 __le32 s_inodes_per_group; /* # Inodes per group */
14 __le32 s_mtime; /* Mount time */
15 __le32 s_wtime; /* Write time */
16 __le16 s_mnt_count; /* Mount count */
17 __le16 s_state; /* File system state */
18 ...
19 #define EXT2_HAS_COMPAT_FEATURE(sb,mask)
20 ( EXT2_SB(sb)->s_es->s_feature_compat & cpu_to_le32(mask) )
21 #define EXT2_HAS_RO_COMPAT_FEATURE(sb,mask)
22 ( EXT2_SB(sb)->s_es->s_feature_ro_compat & cpu_to_le32(mask) )
23 ...
|
Portable Hardware-Kommunikation
Gerade beim Zugriff auf Hardware muss der Programmierer die zwischen dem Hauptprozessor und der Peripherie ausgetauschten Daten mit Hilfe der vorgestellten Datentypen definieren und über die Makros umwandeln. Außerdem darf er die Zugriffe selbst nur über die bereitgestellten Funktionen »read[bwl]()« (read byte, word oder long) respektive »write[bwl]()« (write byte, word oder long) programmieren.
Unterstützt der Prozessor einen eigenen IO-Bereich (Portzugriff), kommen zusätzlich die Funktionen »in[bwl]()« respektive »out[bwl]()« in Frage. Die genaue Verwendung der Funktionen ist in einer früheren Kern-Technik-Folge [1] beschrieben. Dass die Breite des Port-Bereichs auf den Plattformen unterschiedlich ist (x86: 16 Bit, ARM: 32 Bit), bleibt für Programmierer transparent.
Allerdings ist darauf zu achten, ob die Hardware die über einen gemeinsamen Speicher ausgetauschten und in einer Datenstruktur zusammengefassten Variablen an spezifischen Adressen erwartet. Der Compiler legt nämlich einzelne Variablen einer Datenstruktur aus Gründen der Performance an so genannten ausgerichteten (aligned) Adressen ab.
Da ein 32-Bit-Prozessor ein anderes Alignment als ein 16-Bit-Prozessor aufweist, muss der Programmierer sicherstellen, dass die Variablen eine eindeutige Adressenlage besitzen. Das GCC-spezifische Schlüsselwort »__attribute__((packed))« hilft ihm dabei. Abbildung 4 stellt das Problem und die Verwendung des Schlüsselworts beispielhaft dar.

Abbildung 4: Mit Hilfe des Schlüsselworts »packed« kann der Programmierer Einfluss auf die Anordnung von Strukturelementen im Speicher nehmen.
Natürlich gibt es noch weitere Fallen. Doch der Linux-Kernel bemüht sich darum, dem Programmierer Portierungsfehler so schwer wie möglich zu machen. So sind im Kernel einige Datentypen über Typedefs abstrakt gehalten (»ssize_t«, »size_t«, »pid_t«, …). Der Typ »ssize_t« beispielsweise ist, abhängig von der Plattform, entweder auf den Datentyp »int« oder aber auf »long« abgebildet. Deshalb sollte man im eigenen Code grundsätzlich die vordefinierten Datentypen verwenden.
Seitengröße
Auch die Seitengröße (Pagesize) führt schließlich noch zu Portabilitätsproblemen. Tabelle 3 zeigt, dass sie zwischen den verschiedenen Plattformen stark variiert. Einige Kernelfunktionen – zum Beispiel Funktionen des Gerätemodells (Sys-Filesystem) – übergeben jeweils eine Speicherseite. Das Einzige, worauf sich der Programmierer hier verlassen kann, ist, dass sie eine Minimalgröße von 4 KByte aufweist.
|
Tabelle 3: |
||||
|---|---|---|---|---|
|
Name |
Bezeichnung |
Wortbreite |
Größe (»long«) |
Seitengröße |
|
x86 |
i386 |
32 Bit |
4 |
4 KByte |
|
AMD64/EMT64 |
x86-64 |
64 Bit |
8 |
4 KByte |
|
Alpha |
alpha |
64 Bit |
8 |
8 KByte |
|
Arm/Strong ARM |
arm26 |
32 Bit |
4 |
32, 16 KByte |
|
HP PA-Risc |
parisc |
32 oder 64 Bit |
4/8 |
4 KByte |
|
Etrax 100LX |
cris |
32 Bit |
4 |
8 KByte |
|
IA-64 |
ia64 |
64 Bit |
8 |
4, 8, 16, 64 KByte |
|
Mips |
mips |
32 oder 64 Bit |
4/8 |
4, 8, 16, 64 KByte |
|
Motorola 68xxx |
m68k |
32 Bit |
4 |
4, 8 KByte |
|
PowerPC |
ppc |
32 Bit |
4 |
4 KByte |
|
PowerPC64 |
ppc64 |
64 Bit |
8 |
4 KByte |
|
S390 |
s390 |
32 oder 64 Bit |
4/8 |
4 KByte |
|
Sun Sparc |
sparc |
32 Bit |
4 |
4, 8 KByte |
|
Ultra Sparc |
sparc64 |
64 Bit |
8 |
8, 64, 512, 4096 KByte |
|
User Mode Linux |
um |
32 oder 64 Bit |
4/8 |
4 KByte |
Zum Abschluss die drei wichtigsten Regeln für plattformunabhängigen Code zusammengefasst: Auf die Datentypen achten, an der richtigen Stelle konvertieren und auf Hardware über Kernelfunktionen zugreifen. (ofr)
|
Infos |
|---|
|
[1] Eva-Katharina Kunst, Jürgen Quade, “Kern-Technik”, Folge 3: Linux-Magazin 10/03, S. 81 [2] Greg Kroah-Hartman: Writing Portable Device Drivers, [http://www.linuxdevices.com/articles/AT5340618290.html] [3] Robert Love, ” Linux Kernel Development”, S. 321: Novell Press, 2. Auflage, 2005 [4] Corbet et.al., “Linux Device Drivers”, S. 288: O\’Reilly, 3. Auflage, 2005 |
|
Die Autoren |
|---|
|
Eva-Katharina Kunst, Journalistin, und Jürgen Quade, Professor an der Hochschule Niederrhein, sind seit den Anfängen von Linux Fans von Open Source. Unter dem Titel “Linux Treiber entwickeln” haben sie zusammen ein Buch zum Kernel 2.6 veröffentlicht. |






