
Für Fehlersuche und Performance-Messungen brachte der Linux-Kernel bislang nur wenige praktische Instrumente mit. Mit KProbes und JProbes lassen sich bei Kernel 2.6 Halte- und Messpunkte ohne großen Aufwand in das laufende Betriebssystem einfügen.
Bösen Bugs rückt der Applikations-Programmierer mit einem Debugger zu Leibe. Kernelhackern steht diese Möglichkeit nicht ohne weiteres offen. Zwar gibt es auch für den Linux-Kernel einen Debugger – doch weigert sich Linus Torvalds bis heute standhaft ihn offiziell in den Kernel zu übernehmen. Sein Hauptargument: Der Debugger lenke von der eigentlichen Fehlerursache ab, was dazu führe, dass eben nur Symptome, nicht jedoch das eigentliche Problem gefixt würden. Da zudem der Umgang mit dem extra erhältlichen Kernel-Debugger umständlich ist, haben sich die Programmierer daran gewöhnt, mit »printk()« Debug-Ausgaben einzubauen.
Wenn es um ladbare Module geht, ist Printk praktisch und einfach zu benutzen. Neue Printk-Statements sind schnell eingebaut und wieder entfernt. Das Kompilieren und Neuladen eines Moduls geht ebenfalls sehr schnell. Anders sieht es jedoch bei Code aus, der fester Bestandteil des Kernels ist. Hier muss der Kernel neu generiert und installiert werden. Noch schlimmer: Ein zeitaufwändiger Neustart des Systems ist notwendig.
Automatisierte Breakpoints
Findige Programmierer haben sich bereits vor drei Jahren eine alternative Debug-Methode für den Kernel ausgedacht: so genannte Kernel Probes (KProbes), die aus Kernel-Sicht automatisierte Breakpoints darstellen (auch Probe Points genannt). Damit kann offensichtlich auch Linus Torvalds leben: Er hat die KProbes jedenfalls fest in Kernel 2.6 aufgenommen.
Stößt die CPU bei der Abarbeitung auf einen solchen Punkt, ruft der Kernel dem Probe Point zugeordnete, vom Programmierer zur Verfügung gestellte Funktionen auf. Diese Funktionen protokollieren zum Beispiel durchgeführte Aktionen per »printk()« oder geben per »dump_stack()« einen Stacktrace aus. Allerdings ist es nicht möglich, die von einem Debugger bekannten interaktiven Kommandos zu verwenden. Innerhalb des Kernels wäre das ohnehin problematisch, da das Zeitverhalten des Kernels massiv durcheinander geriete.
Der Informatiker betrachtet ein Kernel Probe als Objekt. Es beherbergt neben der Breakpoint-Adresse (dem Probe Point) vier Methoden (Abbildung 1): die Pre-, Post-, Fault- und Break-Handler. Mit der Instanziierung des Objekts durch die Funktion »register_kprobe()« tauscht der Kernel den Maschinenbefehl (Opcode) an der Probe-Point-Adresse gegen den eines Debugger-Breakpoint aus.
Einstieg über Debug-Interrupt
Auf einer x86-Architektur lautet dieser Maschinenbefehl »INT 3« mit dem Opcode »0xcc«. Es ist der übliche Interrupt, um in einen Debugger zu wechseln (siehe Abbildung 2). Sobald der Prozessor auf diesen Breakpoint trifft, ruft er die Kernelfunktion »do_int3()« auf (Abbildung 3). Diese aktiviert den »pre_handler()«, schaltet Single-Stepping ein und setzt den Instruction Pointer auf den zuvor geretteten Maschinenbefehl, damit nach Beendigung des INT-3-Interrupts der ursprüngliche Maschinenbefehl abgearbeitet wird.
Dank Single-Stepping ruft der Kernel direkt danach die Funktion »do_debug()« auf, die schließlich den »post_handler()« aktiviert. Dann schaltet er das Single- Stepping wieder aus und setzt den Instruction Pointer auf den nächsten Opcode der ursprünglich abgearbeiteten Funktion. Tritt während des Ablaufs von Pre- oder Post-Handler ein Page Fault auf, ruft der Kernel den zu KProbe gehörigen Fault-Handler auf. Damit der Kernel diesen Page Fault unbeachtet lässt, sollte »fault_handler()« den Wert »1« zurückgeben.
|
Bestimmen einer |
|---|
|
In [1] sind insgesamt vier Methoden beschrieben, die die Kerneladresse einer Funktion bestimmen (hier vorgeführt am Beispiel des Systemcall »sys_setuid«):
|
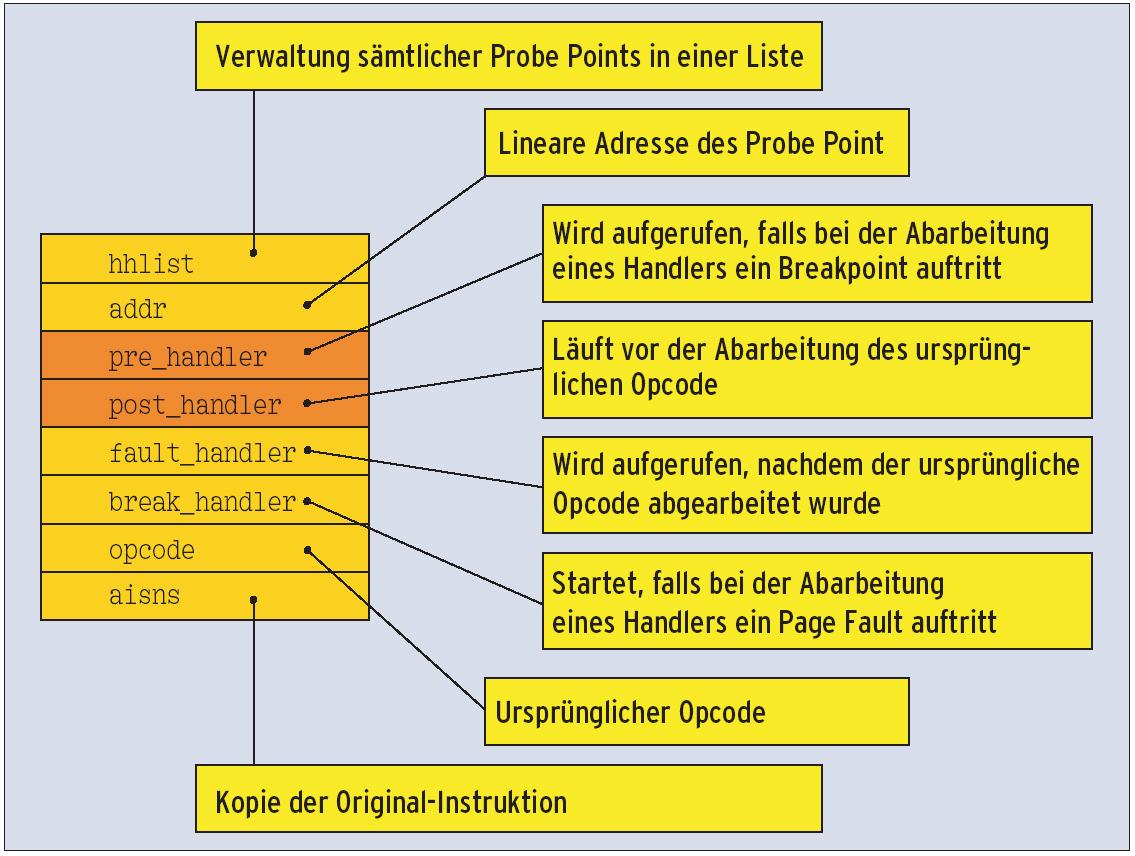
Abbildung 1: Das KProbe-Objekt speichert verschiedene Komponenten, die den Ablauf des Programms beeinflussen, zum Beispiel den »pre_handler« und den »post_handler«, die vor respektive nach der Unterbrechung ablaufen.
Die Break-Funktion »break_handler()« rundet die Methodensammlung ab. Stößt der Kernel innerhalb der Probe-Funktion auf einen weiteren Breakpoint, ruft er diese Funktion auf. Normalerweise gibt sie eine »1« zurück: das Zeichen für den Kernel, den Breakpoint unbeachtet zu lassen. Der Post-Handler besitzt übrigens keinen Rückgabewert (»void«). Dagegen sollte der Rückgabewert der Pre-Handler-Funktion grundsätzlich »0« sein.
Um als Entwickler oder als neugieriger Administrator KProbes zu nutzen, muss die entsprechende Option beim Kernel eingestellt sein. Ob dies der Fall ist, lässt sich – ist »Kernel .config support« vorhanden – mit Hilfe von »zcat /proc/config.gz | grep CONFIG_KPROBES« leicht feststellen: Wer als Ergebnis »CONFIG_KPROBES is not set« erhält, muss seinen Kernel neu bauen (Abbildung 4). Er sollte außerdem sicherstellen, dass die Option »CONFIG_CALLSYMS« eingeschaltet ist.
Speicheradressen finden
Sind KProbes einkompiliert, lässt sich bereits mit wenigen Zeilen Code ein Kernel-Probe implementieren. In Listing 1 ist zu sehen, wie man zu Beginn des Systemcall »sys_setuid« einen Pre-Handler installiert. Allerdings läuft der Code unverändert nur auf einem recht aktuellen Kernel (ab Version 2.6.12-rc1). Die Kerneladresse der zu überprüfenden Funktion erfragt das Modul nämlich durch den Aufruf von »kallsyms_lookup_name()«. Ab Version 2.6.12-rc1 exportiert der Kernel diese Funktion standardmäßig für GPL-konforme Module.
|
Listing 1: |
|---|
01 #include <linux/module.h>
02 #include <linux/kprobes.h>
03 #include <linux/kallsyms.h>
04
05 static int call_count = 0;
06
07 static int pre_probe(struct kprobe *p, struct pt_regs *regs)
08 {
09 ++call_count;
10 printk("pre_probe %dn", call_count);
11 return 0;
12 }
13
14 static struct kprobe kp = {
15 .pre_handler = pre_probe,
16 };
17
18 static int __init probe_init(void)
19 {
20 kp.addr = (kprobe_opcode_t *) kallsyms_lookup_name("sys_setuid");
21
22 if (kp.addr == NULL) {
23 printk("kallsyms_lookup_name could not find address"
24 "for the specified symbol namen");
25 return 1;
26 }
27 if( register_kprobe(&kp)==-ENOSYS ) {
28 printk("kprobes not supportedn");
29 return 1;
30 }
31 printk("kprobe registered address %pn", kp.addr);
32 return 0;
33 }
34
35 static void __exit probe_exit(void)
36 {
37 unregister_kprobe(&kp);
38 printk("probe-breakpoint called %d times.n", call_count);
39 }
40
41 module_init( probe_init );
42 module_exit( probe_exit );
43 MODULE_LICENSE("GPL");
|
Weitere Methoden, um die Kerneladresse zu bestimmen, beschreibt der Kasten “Bestimmen einer Kerneladresse”. Wer Kernel-Probes bei einem älteren Kernel einsetzen möchte, muss entweder auf eine dieser alternativen Methoden zurückgreifen oder den Kernel patchen: Dazu ist das Modul »/usr/src/linux/kernel/kallsyms.c« um die Zeile »EXPORT_SYMBOL_GPL(kallsyms_lookup_name)« zu ergänzen.
Ist für das übergebene Symbol keine Adresse bestimmbar, beendet sich das Modul mit einem Fehlercode. Andernfalls instanziiert der Kernel das Probe-Objekt. Jedes Mal, bevor er den Systemcall »sys_setuid« aufruft, kommt also die hier implementierte Funktion »pre_probe()« zum Zuge (siehe Listing 1). Sie meldet sich im Syslog und erhöht einen Zähler, dessen Stand das Modul beim Laden ausgibt. Dazu muss der Syslog-Daemon natürlich richtig konfiguriert sein, siehe [2].
Zum Test ist das Modul mit Hilfe des Makefile (Listing 2) zu übersetzen und danach mit »insmod ksetuid.ko« zu laden. Die kurze Beispielapplikation aus Listing 3 ruft zum Testen den Systemcall auf. Das Programm lässt sich mit »make setuid« kompilieren.
Ruft man das generierte Programm mit »./setuid 1000« auf, erscheint im Syslog eine entsprechende Nachricht:
tail -1 /var/log/messages May 17 21:22:37 mobil kernel: pre_probe 1
Unabhängig davon, ob es sich um die Pre- oder die Post-Funktion handelt, ist innerhalb der Kernel-Probe-Funktion der Zugriff auf alle globalen Daten möglich, auf lokale Variablen allerdings nicht. Immerhin erhält der Programmierer mit den JProbes Zugriff auf die Übergabeparameter einer Funktion. Dazu implementiert er nur einen einzigen Handler, dessen Übergabeparameter jenen der zu untersuchenden Funktion entsprechen. Einen Rückgabewert hat diese Handler- Funktion nicht. Stattdessen muss sie mit einem Aufruf von »jprobe_return()« abschließen.
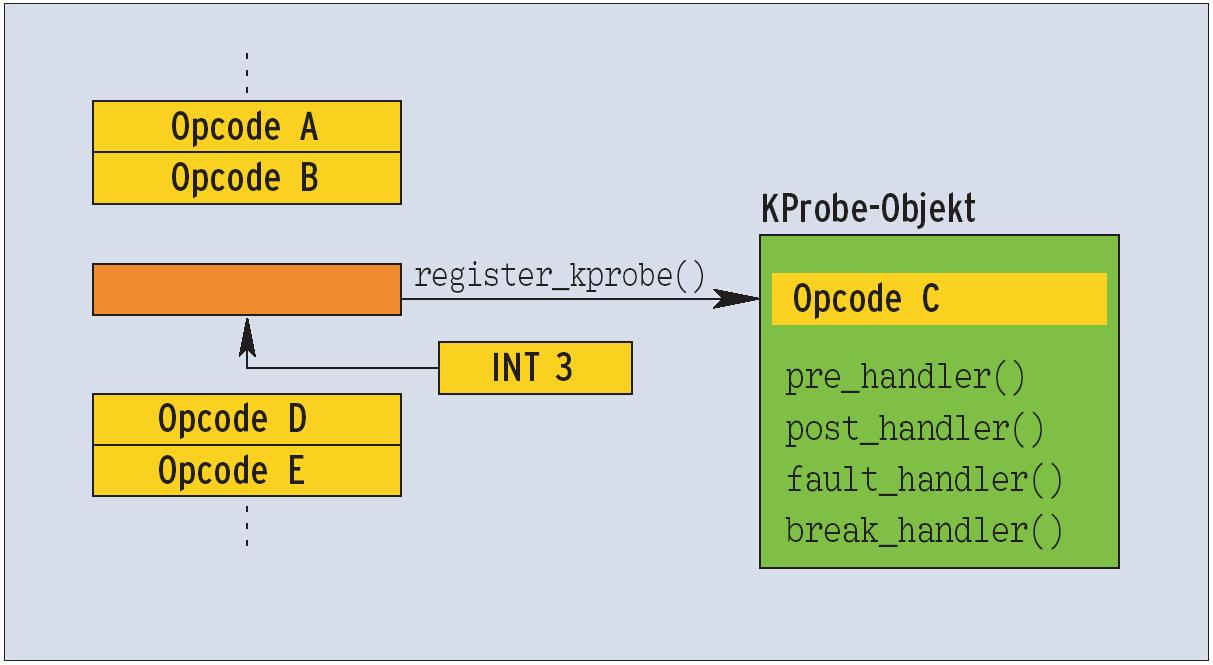
Abbildung 2: Der Maschinenbefehl an der zu untersuchenden Kernelcode-Adresse wird für KProbes mit dem Opcode »INT 3« ausgetauscht, der für einen Debugger-Breakpoint steht. Das KProbe-Objekt nimmt den alten Opcode auf.
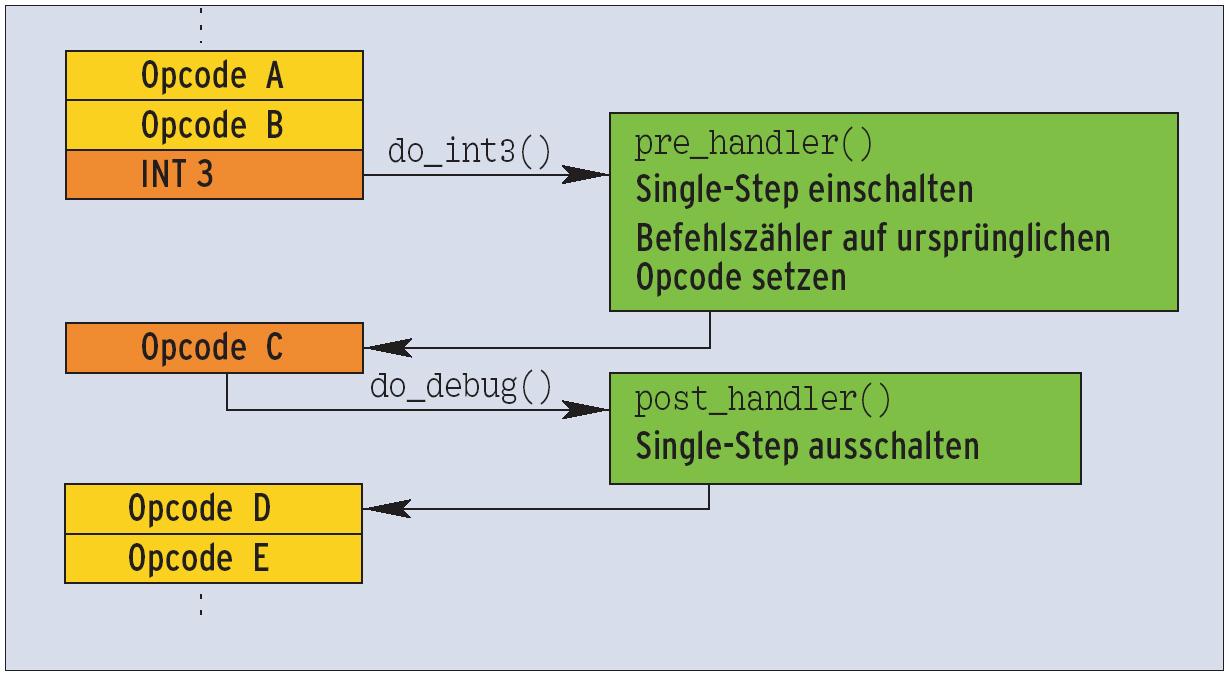
Abbildung 3: Ablauf bei Verwendung eines Kernel-Probe: Zu Beginn schaltet der Kernel im »pre_handler()« den Prozessor in den Einzelschrittmodus (Single- Step). Der »post_handler()« schaltet den Modus wieder aus.
|
Listing 2: Makefile zu |
|---|
01 ifneq ($(KERNELRELEASE),) 02 obj-m := ksetuid.o 03 else 04 KDIR := /lib/modules/$(shell uname -r)/build 05 PWD := $(shell pwd) 06 07 default: 08 $(MAKE) -C $(KDIR) SUBDIRS=$(PWD) modules 09 endif 10 11 clean: 12 rm -f *.mod.c *.o *.ko |
|
Listing 3: |
|---|
01 #include <stdio.h>
02
03 int main( int argc, char **argv )
04 {
05 int uid;
06
07 if( argc != 2 ) {
08 printf("usage: %s uidn", argv[0] );
09 return -1;
10 }
11 uid = atoi( argv[1] );
12 printf("setting to uid %dn", uid );
13 if( setuid( uid )!=0 )
14 perror("setuid");
15 return 0;
16 }
|
|
Listing 4: |
|---|
01 #include <linux/module.h>
02 #include <linux/fs.h>
03 #include <linux/kprobes.h>
04 #include <linux/kallsyms.h>
05
06 static void jsetuid( uid_t uid )
07 {
08 printk("jsetuid( %d )n", uid );
09 jprobe_return();
10 }
11
12 static struct jprobe jp = {
13 .entry = (kprobe_opcode_t *) jsetuid,
14 };
15
16 static int __init probe_init(void)
17 {
18 jp.kp.addr = (kprobe_opcode_t *) kallsyms_lookup_name("sys_setuid");
19 if( jp.kp.addr == NULL ) {
20 printk("kallsyms_lookup_name could not find address"
21 "for the specified symbol namen");
22 return 1;
23 }
24 register_jprobe(&jp);
25 printk("jprobe registeredn");
26 return 0;
27 }
28
29 static void __exit probe_exit(void)
30 {
31 unregister_jprobe(&jp);
32 printk("jprobe unregisteredn");
33 }
34
35 module_init( probe_init );
36 module_exit( probe_exit );
37 MODULE_LICENSE("GPL");
|
Test mit Systemcall
Als Beispiel für die auf den KProbes basierenden JProbes dient wieder »sys_setuid«. Diese Kernelfunktion bekommt die jeweils zu setzende UID als Integerwert übergeben. Listing 4 zeigt den Quellcode, der ein JProbe auf diesen Systemcall setzt. Ruft man nach dem Laden des Moduls mit »insmod jsetuid.ko« das Kommando »setuid« mehrmals mit unterschiedlichen Parametern auf, protokolliert Syslog das mit:
# ./setuid 1000 setting to uid 1000 # tail -1 /var/log/messages May 23 20:34:24 mobil kernel: jsetuid(1000) # setuid 1001 # tail -1 /var/log/messages May 23 20:34:57 mobil kernel: jsetuid(1001)
Während JProbes nur zu Beginn einer Funktion gesetzt werden können, lassen sich mit KProbes beliebige Codestellen instrumentieren. Die gesuchte Stelle zu lokalisieren erfordert – wenn auch nur in sehr beschränktem Umfang – Assembler-Kenntnisse: Man findet den Ort im disassemblierten Code der entsprechenden Funktion.
Ein bisschen Assembler
Auch dieses Verfahren ist am besten anhand eines Beispiels zu erklären: Ein Probe Point in »sys_setuid()« soll nur dann aufgerufen werden, wenn jemand ohne ausreichende Berechtigung diesen Systemcall ausführt.
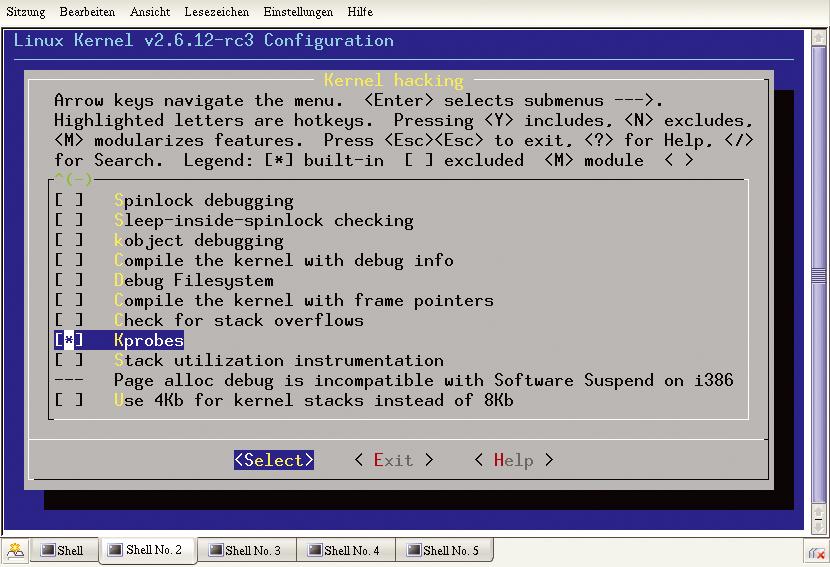
Abbildung 4: Um Kernel-Probes für eigene Zwecke zu nutzen, muss in der Kernelkonfiguration unter dem Menüpunkt »Kernel-Hacking« die Option »KProbes« aktiviert sein.
|
Probe Points in ladbaren |
|---|
|
Vorsicht ist bei Probe Points in dynamischen Kernelmodulen geboten. Entlädt man nämlich das zu untersuchende Modul vor dem Modul mit dem Probe Point (das Modul mit dem KProbe), kommt es unweigerlich zu einem Crash (Oops). Schließlich greift das Kernel-Probe-Modul auf Code zu, der schon längst wieder entladen ist. Doch Abhilfe ist möglich. Dazu muss das KProbe-Modul dem Kernel mitteilen, dass es auf das zu untersuchende Modul zugreift. Das geschieht mit der Funktion »try_module _get()«. Allerdings braucht man dazu die Adresse des Modulobjekts »struct file_operations«. Stammt das Modul aus der eigenen Feder, lässt sich diese Adresse am einfachsten per »EXPORT_SYMBOL_GPL()« exportieren. Das KProbe-Modul kann sie dann einfach wieder importieren. Natürlich müssen nach getaner Arbeit die Ressourcen wieder freigegeben werden. Das geschieht durch den Aufruf von »module_put()«. Listing 7 zeigt die wesentlichen Codestücke im KProbe-Modul. |
Der Quellcode der Funktion »sys_setuid()« findet sich in der Datei »kernel/sys.c«. Listing 5 zeigt den relevanten Ausschnitt daraus. Falls beim Aufruf der Funktion die Zugriffsreche nicht ausreichen, gibt der Kernel »-EPERM«, also »-1« zurück. In diesem Fall soll er den Pre-Handler ausführen. Zum Setzen des Probe Points muss der Entwickler die Adresse dieser markanten Stelle suchen, indem er das zugehörige Assembler-Listing zu Rate zieht. Folgender Befehl disassembliert das Objektfile:
objdump -d /usr/src/linux/kernel/sys.o >U /tmp/sys.asm
Listing 6 zeigt den relevanten Teil der dissassemblierten Funktion, wie er in der Datei »/tmp/sys.asm« zu finden ist. An Adresse »d9d« findet sich der Wert »-1« (Hexadezimal 0xffffffff): Das ist also die Adresse für den Probe Point.
|
Listing 5: Ausschnitt aus |
|---|
01 asmlinkage long sys_setuid(uid_t uid)
02 {
03 int old_euid = current->euid;
04 int old_ruid, old_suid, new_ruid, new_suid;
05 int retval;
06
07 ...
08 if (capable(CAP_SETUID)) {
09 if (uid != old_ruid && set_user(uid, old_euid != uid) < 0)
10 return -EAGAIN;
11 new_suid = uid;
12 } else if ((uid != current->uid) && (uid != new_suid))
13 return -EPERM;
14 ...
15 }
|
|
Listing 6: |
|---|
01 00000ce0 <sys_setuid>: 02 ce0: 55 push %ebp 03 ce1: b8 00 e0 ff ff mov $0xffffe000,%eax 04 ce6: 57 push %edi 05 ce7: 56 push %esi 06 ce8: 53 push %ebx 07 ce9: 83 ec 10 sub $0x10,%esp 08 cec: 8b 5c 24 24 mov 0x24(%esp),%ebx 09 ... 10 d95: 5d pop %ebp 11 d96: c3 ret 12 d97: 39 eb cmp %ebp,%ebx 13 d99: 74 a3 je d3e <sys_setuid+0x5e> 14 d9b: 39 f3 cmp %esi,%ebx 15 d9d: ba ff ff ff ff mov $0xffffffff,%edx 16 da2: 74 9a je d3e <sys_setuid+0x5e> 17 da4: eb e7 jmp d8d <sys_setuid+0xad> 18 da6: 8d 76 00 lea 0x0(%esi),%esi 19 da9: 8d bc 27 00 00 00 00 lea 0x0(%edi),%edi |
Der nächste Schritt bestimmt den Offset dieser Adresse gegenüber dem Anfang der Funktion »sys_setuid«. Dazu subtrahiert man von »0xd9d« die Anfangsadresse der Funktion »0xce0«. Das Ergebnis (»0xb7«) – also die Offsetadresse – wird zur Adresse von »sys_setuid« im Kernel (»kp.addr«) addiert. Der Anfang der Funktion »probe_init()« sieht dann so aus (Ausschnitt aus »ksetuid2.c«):
static int __init probe_init(void)
{
kp.addr = (kprobe_opcode_t *) U
kallsyms_lookup_name("sys_setuid");
kp.addr+= 0xb7;
if (kp.addr == NULL) {
Der vollständige Code des Moduls »ksetuid2.c« steht unter [9]. Wer das Modul ausprobieren möchte, sollte nicht vergessen im Quellcode die Offsetadresse »0xb7« der Funktion gegen jene des eigenen Systems auszutauschen.
Nach dem Kompilieren des modifizierten Moduls und dem Laden mit »insmod ksetuid2.ko« folgt der Test. Ruft der Superuser über den Befehl »su« intern den Systemcall »sys_setuid« auf, sind die Zugriffsrechte korrekt und der Probe Point wird nicht aufgerufen. Erst wer mit einer anderen UID versucht die User-ID zu verändern, erhält eine Meldung vom Probe Point:
# ./setuid 1000 setting to uid 1000 # su mail sh-3.00$ ./setuid 1000 setting to uid 1000 setuid: Operation not permitted ... # tail -1 /var/log/messages May 17 21:34:45 mobil kernel: pre_probe(1)
Die Beispiele zeigen, wie über KProbes bereits mit wenigen Zeilen Code wertvolle Debuginformationen zu gewinnen sind. Da die Technik – abhängig von der Anzahl und der Komplexität der eingesetzten Probe Points – im Normalfall kaum Performance-Einbußen mit sich bringt, eignet sie sich auch für den Einsatz in einem Produktivsystem.
In diesem Fall lassen sich auch statistische Informationen gewinnen, zum Beispiel die Aufrufreihenfolge und -häufigkeit von spezifischen Kernelfunktionen. So helfen KProbes auch bei der Optimierung von Kernelalgorithmen und Applikationen. Leider laufen KProbes und JProbes (noch) nicht auf jeder Hardware. Zu den unterstützten Plattformen zählen x86 (sowohl 32 als auch 64 Bit), Sparc und PowerPC (jeweils nur 64 Bit).
|
Listing 7: |
|---|
01 ...
02 #include <linux/fs.h>
03 ...
04 extern struct file_operations fops; // "fops" muss exportiert sein
05 ...
06
07 static int __init probe_init(void)
08 {
09 ...
10 kp.addr = (kprobe_opcode_t *) kallsyms_lookup_name("driver_read");
11 if (kp.addr == NULL) {
12 printk("kallsyms_lookup_name could not find address"
13 "for the specified symbol name
n");
14 return 1;
15 }
16 try_module_get( fops.owner );
17 register_kprobe(&kp);
18 printk("kprobe registeredn");
19 return 0;
20 }
21
22 static void __exit probe_exit(void)
23 {
24 module_put( fops.owner );
25 unregister_kprobe(&kp);
26 printk("kprobe unregisteredn");
27 printk("generic_make_request() called %d times.n", call_count);
28 }
29 ...
|
Ergänzungen zu KProbes
Inzwischen sind drei Projekte entstanden, die den Umgang mit den Kernel-Probes vereinfachen wollen: DProbes [5], System Tap [6] und das noch junge KProbes-HERE [7]. Während mit KProbes-HERE das Debugging direkt per Kommandozeile erfolgt, definiert der Entwickler bei den beiden anderen Projekten die Probe Points über eine eigene Skriptsprache. Diese übersetzt ein Compiler in ein ladbares Modul – eine Technik, die übrigens dem DTrace-Mechanismus in Solaris 10 ähnelt [8]. (ofr)
|
Infos |
|---|
|
[1] Prasanna Panchamukhi, “Kernel debugging with KProbes”: [http://www-106.ibm.com/developerworks/library/l-kprobes.html?ca=dgr-lnxw04Kprobe] [2] Eva-Katharina Kunst, Jürgen Quade, Kern-Technik, Folge 3: Linux-Magazin 10/03, S. 81 [3] William Cohen, “Gaining insight into the Linux kernel with KProbes”: [http://www.redhat.com/magazine/005mar05/features/kprobes/] [4] Sudhanshu Goswani, “An introduction to KProbes”: [http://lwn.net/Articles/132196/] [5] Linux Dynamics Probes: [http://dprobes.sf.net] [6] System Tap: [http://sources.redhat.com/systemtap] [7] Tejun Heo, KProbes-HERE [http://home-tj.org/kphere] [8] Suns DTrace: [http://www.sun.com/bigadmin/content/dtrace] [9] Listings und Makefile: [https://www.linux-magazin.de/Service/Listings/2005/08/Kern-Technik]. |
|
Die Autoren |
|---|
|
Eva-Katharina Kunst, Journalistin, und Jürgen Quade, Professor an der Hochschule Niederrhein, sind seit den Anfängen von Linux Fans von Open Source. Unter dem Titel “Linux Treiber entwickeln” haben sie zusammen ein Buch zum Kernel 2.6 veröffentlicht. |






