(C) unter Verwendung eines Motivs von Andrei Suslov / 123RF.com
Die Firma Artificial Analysis vergleicht LLMs hinsichtlich der Kriterien Intelligenz, Geschwindigkeit und Preis und errechnet daraus einen Artificil Analysis Intelligence Index.
Diese Rangliste führt GPT-5.2 (xhigh) von OpenAI mit 51 Punkten knapp vor Claude Opus 4.5 von Anthropic (49) und Gemini 3 Pro von Google (48). Die Top Ten schließen mit Grok 4 (Meta) und DeepSeek V3.2 (DeepSeek), beide mit 41 Punkten. Die besten Modelle gehören durchweg zu den teuersten.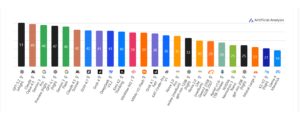
Der Bewertung zugrunde liegen Benchmarks in vier gleichgewichteten Kategorien: Agenten, Programmierung, wissenschaftliches Denken und Allgemeines. Dabei wurden nun drei bisher verwendete Benchmarks – AIME 2025, LiveCodeBench und MMLU-Pro – durch drei neue ersetzt: AA-Omniscience, der Wissen und Halluzinationen bei 40 Themen testet, GDPval-AA, der wirtschaftlich wertschöpfende Aufgaben prüft und CritPt, der auf Physikaufgaben spezialisiert ist.



