Mozilla hat mit Common Voice ein Projekt gestartet, das frei zugängliche und verwendbare Sprachdaten umfasst. Jetzt hat Mozilla einen weiteren Datensatz mit menschlichen Stimmen veröffentlicht. Erstmals sind die Daten mehrsprachig.
Der neue mehrsprachige Datensatz umfasse 18 verschiedene Sprachen und die aufgezeichneten Sprachdaten summierten sich auf rund 1400 Stunden. Zu den Sprachen zählt Mozilla etwa Englisch, Französisch, Deutsch, Mandarin (traditionell) und auch Walisisch. Mehr als 42.000 Mitwirkenden verzeichnet Mozilla bei diesem Datenprojekt.
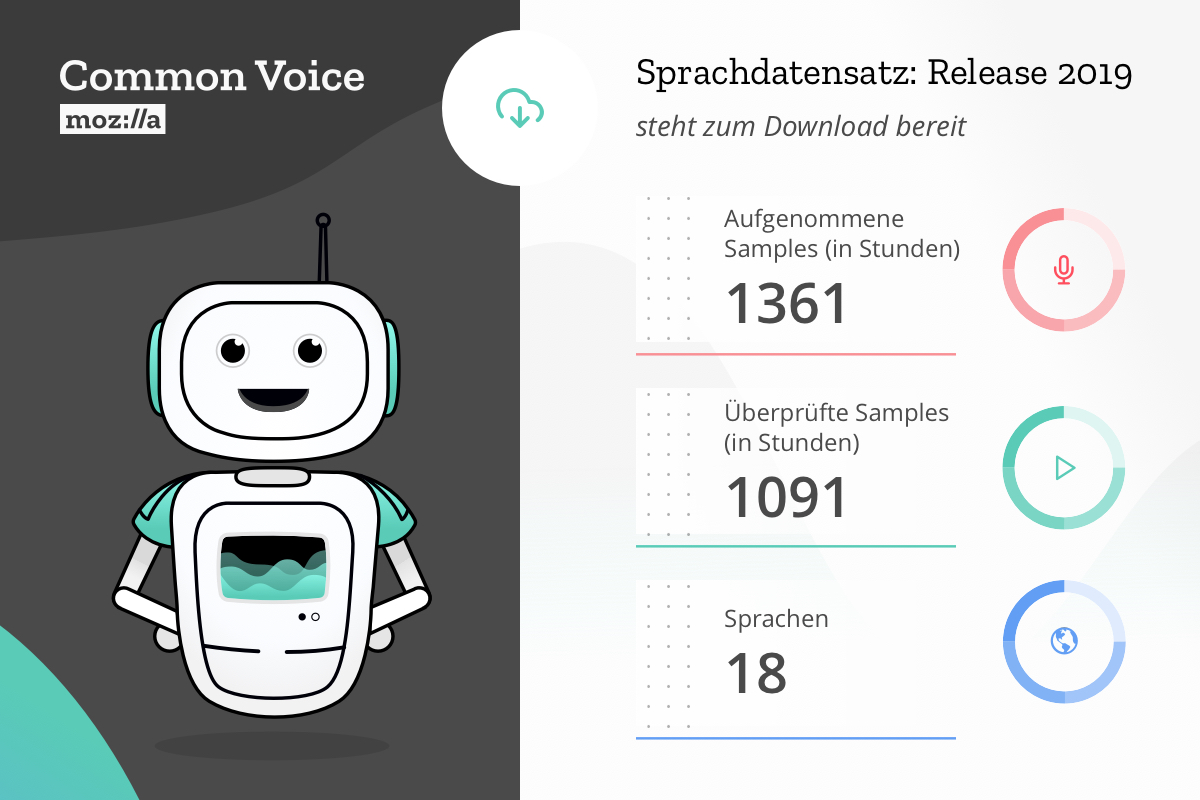
Mozillas Datensatz wächst. Quelle: Mozilla
Für Entwickler, die mit Spracherkennung und ähnlichen Technologien experimentieren, ist dieser Datensatz ein unschätzbarer Vorteil, wenn es darum geht ihre Anwendungen in den Bereichen KI und Machine Learning zu trainieren. Für einzelne Entwickler oder kleine Studios ist es ansonsten schwer, an geeignete Trainingdaten zu kommen. Mozilla betont, dass bei der Erfassung der Daten auch freiwillig Metadaten wie Alter, Geschlecht und Akzent angegeben werden können. Damit seien teils weitere Informationen gespeichert, mit denen sich Sprach-Engines noch exakter trainieren lassen. Ein Blogpost nennt weitere Details.
Der nun vorhandene deutsche Datensatz umfasst vier GByte an Daten mit rund 2250 Stimmen und umfasst eine Dauer von rund 140 Stunden. Mozilla plant neben den bestehenden Sätzen für derzeit 22 Sprachen noch 70 weitere aufzunehmen. Common Voice sei der größte öffentlich verfügbare Sprachdatensatz seiner Art, lässt Mozilla wissen. Der Download mit Auswahlmöglichkeiten für die Sprachen ist hier zu finden.



