
© Mohd Azrin / 123RF.com
Transformer haben sich in den letzten Jahren bei vielen Aufgaben als leistungsfähige Architektur zum Umwandeln von Ein- in Ausgabesequenzen durchgesetzt. Vor allem bei der Sprachverarbeitung führten sie zu großen Fortschritten.
Eine typische Aufgabe der Sprachverarbeitung stellt das Übersetzen von Texten dar. Dabei soll beispielsweise ein Satz auf Englisch (Eingabesequenz) in die deutsche Übersetzung (Ausgabesequenz) transformiert werden. Der englische Satz “The puppy is very cute.” müsste dann nach der Transformation die Ausgabe “Der Welpe ist sehr niedlich.” ergeben. Am Anfang jeder Aufgabe der Sprachverarbeitung (Natural Language Processing, kurz NLP) steht das Embedding.
Die Grenzen von RNNs
Im Bereich des NLP dient das Embedding als Methode, um Wörter in hochdimensionale, kontinuierliche Vektorräume zu transformieren (Abbildung 1). Es stellt Wörter als Vektoren dar, statt ihnen eindeutige numerische Werte zuzuweisen, wobei semantisch ähnliche Wörter ähnliche Vektoren haben.
Abbildung 1: Embeddings übertragen die Wortbedeutung in hochdimensionale Vektoren, die.
Zum Beispiel platziert ein Embedding-Modell Wörter, die in ähnlichen Kontexten auftreten, im Vektorraum nahe beieinander. Dadurch kann es die Bedeutung eines Worts und die Beziehungen zwischen Wörtern besser erfassen und verarbeiten. Diese kompakten, dichten Vektoren erleichtern es Maschinen, die natürliche Sprache effizient zu analysieren und zu verstehen. Praktisch alle NLP-Aufgaben erfordern ein Embedding, da die Verarbeitung von Texten mit Algorithmen immer eine mathematische Beschreibung voraussetzt.
Die Aufgabe des maschinellen Übersetzens besteht darin, die Embeddings einer Sprache in Embeddings einer anderen Sprache zu überführen. Das bloße Übersetzen Wort für Wort in der Reihenfolge des Erscheinens in der Eingabesequenz kann allerdings zu einem Ergebnis führen, das ein Muttersprachler als ungrammatisch betrachten würde. Ein solcher reiner Wort-für-Wort-Ansatz kann also keine vernünftige Übersetzung hervorbringen.
Eine populäre Methode, dieses Problem zu lösen, stellt die Verwendung von rekurrenten neuronalen Netzen (RNNs) dar. Im Gegensatz zur einfachen Wort-für-Wort-Übersetzung hängt die Ausgabe eines RNNs von den vorherigen Elementen einer Sequenz ab. RNNs haben also eine Art Gedächtnis, was beim Übersetzen von Texten wichtig ist. Ein RNN kodiert die gesamte Eingabesequenz in einen versteckten Zustand eines neuronalen Netzes und gibt diesen an einen Decoder weiter, der daraus dann die Übersetzung des Texts generiert. So beeindruckend die Ergebnisse von RNNs auch ausfallen mögen, gibt es dennoch Einschränkungen bei ihrer Anwendung. Sie verarbeiten Sequenzen schrittweise, was langsamer vonstattengeht und eine effiziente Parallelisierung erschwert. Zudem haben sie Schwierigkeiten, Langzeitabhängigkeiten zu erfassen, wodurch Informationen in langen Sequenzen oft verloren gehen.
Hier schaffen Transformer Abhilfe. Die maschinelle Übersetzung mit Transformern basiert auf zwei Hauptkomponenten: einem Encoder und einem Decoder (Abbildung 2). Ersterer empfängt wie beim RNN jedes Element der Eingabesequenz. Er kodiert diese Informationen in einen Vektor, der die Kontextinformationen über die gesamte Sequenz enthält. Diesen Vektor leitet er dann an den Decoder weiter, dessen Aufgabe darin besteht, diesen Kontext zu interpretieren und die Ausgabesequenz darauf basierend sinnvoll zu generieren.
Abbildung 2: Eine zu übersetzende Phrase durchläuft die Komponenten Encoder und Decoder.
Attention-Mechanismus
Bei der Transformer-Architektur übergibt der Encoder nicht nur (wie bei RNNs) den letzten versteckten Zustand an den Decoder, sondern alle versteckten Zustände. Das bedeutet, dass der Decoder nun deutlich mehr zu tun hat, da er nicht nur einen versteckten Zustand, sondern alle Zustände beachten und verarbeiten muss. In unserem Beispielsatz “The puppy is very cute.” ist der erste versteckte Zustand mit dem Wort “the” verbunden, der zweite mit dem Wort “puppy”, der dritte mit “is” und so weiter. Auf diese Weise stehen dem Decoder deutlich mehr Informationen zur Verfügung als bei RNNs.
Diese Vorgehensweise ähnelt der eines menschlichen Übersetzers. Auch er merkt sich einen ganzen Satz im Kontext des gesamten Texts, um seine Übersetzung zu erstellen. Allerdings gewichtet der menschliche Übersetzer dabei einige Teile von Sätzen oder Texten höher als andere. Diese Aufgabe erfüllt bei einem Transformer der sogenannte Attention-Mechanismus. Um zu erkennen, welcher Teil der Sequenz wichtiger ist als andere, verwenden Transformer ein mathematisches Gewichtungsverfahren. Die Idee des Attention-Mechanismus besteht dann darin, jedem Teil einer Sequenz unterschiedliche Gewichtungen zuzuweisen. So kann das Modell erkennen, welche Teile für die aktuelle Vorhersage am wichtigsten sind. Auf diese Weise lässt sich der Kontext des Texts besser erfassen, indem die relevanten Informationen mehr Aufmerksamkeit erhalten.
Es ist die Aufgabe des Decoders, das Gewicht für jeden vom Encoder empfangenen versteckten Zustand aus der Eingabesequenz zu berechnen. Das erfolgt mithilfe des eigenen versteckten Zustands des Decoders, also der Ausgabe des vorherigen Zeitschritts im Modell. Die so bestimmte und angewandte Gewichtung führt dann zu einem neuen Kontextvektor, den der Decoder dann für die weitere Verarbeitung verwendet. Anschließend lässt sich dieser Kontext als Eingabe für ein Feedforward-Netz des Decoders verwenden, um die gewünschte Ausgabesequenz zu erhalten. Im Gegenzug dient die Ausgabesequenz als versteckter Zustand des Decoders zur Berechnung der Gewichte im nächsten Zeitschritt.
Self Attention
Der Attention-Mechanismus bildet also einen wichtigen Bestandteil des Decoders. Bei Transformer kommt jedoch noch ein weiterer wichtiger Attention-Mechanismus vor allem im Encoder zum Einsatz: Ein sogenannter Self-Attention-Mechanismus sorgt für ein besseres Verständnis der Eingabesequenz.
Ähnlich wie der normale Attention-Mechanismus verfolgt Self Attention Verknüpfungen innerhalb der Sequenz, um eine bessere Kodierung zu erreichen. Nehmen wir zum Beispiel einen etwas komplexeren Eingabesatz: “The puppy finds some fun toys and plays happily with them.” Ein Encoder, der darauf fokussiert, die Beziehungen zwischen direkt nebeneinander stehenden Wörtern zu erfassen, erkennt hier zwar problemlos, dass sich das Wort “fun” auf das Wort “toys” bezieht. Er würde allerdings nicht erfassen, dass das Wort “them” am Ende des Satzes sich ebenfalls auf “toys” bezieht, da die Wörter “them” und “toys” nicht nebeneinander stehen. Ein derartiger Encoder mit nur wenig Self Attention wäre also nicht in der Lage, den komplexeren Satz korrekt zu erfassen. Der Self-Attention-Mechanismus schafft hier Abhilfe.
Mit dem Self-Attention-Mechanismus sucht der Encoder nach Hinweisen in den anderen Elementen des Satzes, während er sie verarbeitet. Auf diese Weise lässt sich Self Attention nutzen, um das Verständnis jedes der verarbeiteten Elemente in der Eingabesequenz zu extrahieren. Dazu kommen drei Hauptkomponenten zum Einsatz: Queries (Anfragen), Keys (Schlüssel) und Values (Werte). Jedes Wort in der Eingabesequenz wird in diese drei Vektoren umgewandelt.
Die Query repräsentiert, wonach ein bestimmtes Wort fragt, also welche Informationen aus der Sequenz es zur besseren Interpretation benötigt. Der Key repräsentiert das Schlüsselelement jedes Worts, das anderen Worten signalisiert, wie wichtig es ist. Der Value enthält die tatsächlichen Informationen, die von dem Wort getragen und weitergegeben werden sollen. Es gibt verschiedene mathematische Vorgehensweisen, um diese Größen zu berechnen. Im Ergebnis führt die Verarbeitung aber immer dazu, dass der Encoder eine bessere Einsicht in die Eingabesequenz erlangt. Auf diese Weise kann jedes Wort relevante Informationen aus der gesamten Sequenz extrahieren und erhält eine verbesserte Repräsentation, basierend auf den Kontexten der anderen Wörter.
Allgemein lässt sich die mathematische Vorgehensweise wie folgt beschreiben: Jedes Wort oder allgemein Token in der Eingabesequenz wird durch drei verschiedene lineare Transformationen in einen Query-, einen Key- und einen Value-Vektor umgewandelt. Diese mathematischen Repräsentationen helfen zu bestimmen, wie stark die einzelnen Token aufeinander achten sollen. Für jedes Token vergleicht der Algorithmus den Query-Vektor mit den Key-Vektoren aller anderen Tokens in der Sequenz, indem er das Skalarprodukt zwischen den Vektoren der Query eines Tokens und den Keys der anderen Tokens berechnet. Das Ergebnis dieses Produkts zeigt, wie ähnlich oder relevant die Tokens zueinander sind.
Diese Ähnlichkeitswerte werden anschließend skaliert, um Stabilität bei der Berechnung zu gewährleisten, und dann durch eine Softmax-Funktion normalisiert. Diese Funktion erzeugt Wahrscheinlichkeitsverteilungen, die bestimmen, wie viel Aufmerksamkeit ein Token jedem anderen Token schenken soll. Die resultierenden Aufmerksamkeitswerte dienen dann dazu, die zugehörigen Value-Vektoren für die Verarbeitung zu gewichten. Ein hoher Aufmerksamkeitswert bedeutet, dass der entsprechende Value-Vektor mehr Gewicht erhält, ein niedriger Wert hat eine geringere Gewichtung zur Folge. Alle gewichteten Value-Vektoren werden summiert, um einen neuen, “aufmerksamen” Repräsentationsvektor für das jeweilige Token zu erhalten. Der Vektor enthält nun Informationen über die gesamte Eingabesequenz, wobei der Fokus auf den wichtigsten Teilen der Sequenz liegt.
Angenommen, die Eingabesequenz des Encoders lautet “The puppy is very cute”. Für das Wort “puppy” könnte der Query-Vektor herausfinden, dass es wichtig ist, auf den Artikel (“The”) und die Handlung (“is”) zu achten, um den Kontext besser zu verstehen. Der Key-Vektor von “The” und “is” hilft, diese Relevanz zu bestätigen. Die entsprechenden Value-Vektoren dieser Wörter liefern die eigentliche Information, die die Query von “puppy” sucht. Mithilfe der Self Attention erkennt das Modell also die starke Verbindung zwischen “puppy” und “is”, während “very” etwas weniger Relevanz besitzt.
Am Ende hilft der Self-Attention-Mechanismus auf diese Weise dabei, dass jedes Token eine verbesserte, kontextualisierte Repräsentation erhält. Dazu berücksichtigt er zwar die gesamte Sequenz, schenkt aber nur den relevanten Teilen besondere Beachtung. Der Self-Attention-Mechanismus kommt übrigens nicht nur im Encoder, sondern auch im Decoder zum Einsatz (Abbildung 3).
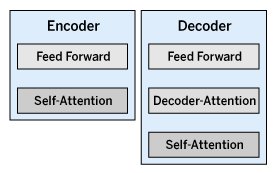
Abbildung 3: Sowohl im Encoder wie im Decoder sorgt ein Self-Attention-Mechanismus für einen gewichteten Aufmerksamkeitswert je Token.
Multi-Head Attention
Transformer können selbst große Textmengen effizient verarbeiten. Dazu verwenden sie Multi-Head Attention als Erweiterung des Self-Attention-Mechanismus. Statt nur eine Self Attention zu berechnen, erfolgt diese Berechnung bei Multi-Head Attention mehrfach parallel, wobei man jeden Berechnungskanal als Head bezeichnet. Die Eingabesequenz wird dabei in verschiedene Subräume projiziert, in denen jede Berechnung auf unterschiedliche Weise erfolgt.
Diese verschiedenen Heads ermöglichen es dem Modell, unterschiedliche Aspekte der Sequenz gleichzeitig zu betrachten. So kann etwa ein Head syntaktische Beziehungen und ein anderer semantische Zusammenhänge analysieren. Am Ende werden die Ergebnisse der verschiedenen Heads kombiniert und durch eine lineare Transformation wieder zusammengeführt. Multi-Head Attention erlaubt dem Modell, auf vielfältigere Weise Informationen zu verarbeiten und den Kontext einer Sequenz umfassender zu erfassen, als es mit einem einzigen Self-Attention-Mechanismus möglich wäre.
Multi-Head Attention kommt auch für die Decoder-Attention zum Einsatz, dort allerdings als Masked Multi-Head Attention. Die Maskierung soll vor allem sicherstellen, dass das Modell beim Vorhersagen des nächsten Tokens in einer Sequenz nur Informationen aus vorhergehenden Tokens berücksichtigt und nicht auf zukünftige Tokens zugreifen kann.
Beide Formen der Multi-Head Attention erhöhen durch das parallele Verarbeiten die Effizienz der Transformer drastisch. Erst dadurch wurde es in den letzten Jahren möglich, auf dieser Architektur basierende Large Language Models (LLMs) zu entwickeln.
Positional Encoding
Die Parallelverarbeitung ist ein entscheidender Vorteil von Transformern gegenüber RNNs, die die Token einer Sequenz nur hintereinander abarbeiten können. Allerdings führt die Parallelität auch zu neuen Herausforderungen, denn dadurch geht die Information über die Reihenfolge der Tokens in einer Sequenz verloren. Die ist allerdings wichtig, um den Text zu verstehen.
Aus diesem Grund speichern Transformer die Informationen über die Reihenfolge im sogenannten Positional Encoding ab. Diese entscheidende Komponente erfasst Informationen über die Reihenfolge der Tokens in einer Eingabesequenz. Die resultierenden Encodings werden zu den Token-Embeddings addiert, sodass jedes Token neben seiner Bedeutung auch seine Position in der Sequenz hat. Dadurch kann das Modell sowohl den Inhalt als auch die Anordnung der Tokens berücksichtigen.
Ohne Positional Encoding würden identische Tokens an verschiedenen Positionen in der Eingabesequenz als gleichwertig angesehen, was Verwirrung stiften könnte. Positional Encoding stellt also sicher, dass das Modell zwischen identischen Tokens an unterschiedlichen Positionen unterscheidet. Darüber hinaus ermöglicht die Verwendung von sinusförmigen Funktionen für Positional Encodings eine flexible Handhabung längerer Sequenzen: Aufgrund der Kontinuität dieser Funktionen können neue Positionen flexibel berücksichtigt werden.
Insgesamt hat das Positional Encoding entscheidenden Einfluss darauf, dass das Transformer-Modell die Reihenfolge von Tokens korrekt versteht und verarbeitet. Damit ist es für viele Aufgaben in der natürlichen Sprachverarbeitung und anderen KI-Bereichen von zentraler Bedeutung.
Optimierung
In einem Transformer-Modell arbeiten alle bisher beschrieben Komponenten zusammen, um Sequenzen effizient zu verarbeiten. Der Encoder nimmt die Eingabesequenz auf und verwendet Multi-Head Attention, um zu bestimmen, welche Teile für jedes Token wichtig sind. Dabei kommt Positional Encoding zum Einsatz, um die Reihenfolge der Tokens zu berücksichtigen, da der Transformer diese Information nicht von Natur aus verarbeitet. Anschließend durchlaufen die Informationen Feedforward-Netze, um die Ausgabe des Encoders zu verfeinern.
Der Decoder generiert basierend auf den Encoder-Ausgaben einen Output, zum Beispiel eine Übersetzung. Hier nutzt er ebenfalls Multi-Head Attention, um den Kontext der gesamten Eingabesequenz zu berücksichtigen. Zusätzlich enthält der Decoder Masked Multi-Head Attention, um zu verhindern, dass beim Vorhersagen des nächsten Tokens zukünftigen Tokens einbezogen werden. Auch im Decoder folgt der Attention eine Feedforward-Schicht, um die Ausgabe weiter zu verbessern.
Zusätzlich verwenden Transformer zur Erhöhung der Stabilität und der Effizienz auch noch Residual Connections und Layer Normalization. Beide Techniken verbessern die Trainingsstabilität und -effizienz. Die Residual Connection fügt die Eingabe einer Schicht direkt der Ausgabe hinzu, sodass wichtige Informationen erhalten bleiben. Das erleichtert während des Trainings den Gradiententransport und hilft, Probleme wie das Verschwinden von Gradienten zu vermeiden.
Layer Normalization stabilisiert die Ausgaben einer Schicht, indem sie die Werte auf einen Mittelwert von null und eine Varianz von eins normalisiert. Das sorgt dafür, dass die Aktivierungen in einem konsistenten Bereich bleiben, was das Training effizienter und stabiler macht. Zusammen ermöglichen diese Techniken dem Modell, schneller zu lernen, und machen es robuster. Durch dieses Zusammenspiel der Komponenten kann der Transformer komplexe Sequenzen effizienter verarbeiten und genauere Vorhersagen treffen.
Fazit
Die Transformer-Architektur hat die Landschaft des maschinellen Lernens revolutioniert, insbesondere in der Sprachverarbeitung. Durch den Einsatz des Attention-Mechanismus ermöglicht sie es Modellen, Kontextinformationen effizient zu erfassen. Das führt zu besseren Ergebnissen bei Übersetzungen, Textgenerierung und anderen Aufgaben.
Die Fähigkeit von Transformern, parallele Berechnungen auszuführen, sorgt für kürzere Trainingszeiten und eine verbesserte Skalierbarkeit. Insgesamt ist die Transformer-Architektur ein entscheidender Fortschritt, der die Entwicklung leistungsstarker KI-Anwendungen vorantreibt.
Transformer haben jedoch auch einige Schwachstellen. Eine der größten Herausforderungen stellt der hohe Rechenaufwand dar. Transformer-Modelle erfordern signifikante Rechenressourcen und Speicherplatz, insbesondere wenn sie mit großen Datensätzen oder komplexen Aufgaben arbeiten. Das kann die Implementierung in ressourcenbeschränkten Umgebungen oder auf mobilen Geräten erheblich erschweren.
Ein weiteres Problem ist die Datenintensität. Um eine adäquate Leistung zu erzielen, benötigen Transformer große Mengen an qualitativ hochwertigen Trainingsdaten. In vielen Anwendungsbereichen stehen solche Daten jedoch nicht ohne Weiteres zur Verfügung, was die Effektivität der Modelle einschränken kann.
Neben der Rechenlast und Datenanforderung entpuppt sich die Interpretierbarkeit von Transformer-Modellen oft als Hindernis. Die Entscheidungen, die diese Modelle treffen, basieren auf komplexen mathematischen Operationen, die für Menschen schwer nachzuvollziehen sind. Diese mangelnde Transparenz kann das Vertrauen in die Ergebnisse beeinträchtigen, insbesondere in sensiblen Bereichen wie Medizin oder Finanzen.
Ein weiteres Limit liegt im Fehlen von Domänenwissen. Transformer-Modelle lernen hauptsächlich aus den Mustern in den Trainingsdaten. Sie können jedoch Schwierigkeiten haben, spezifisches Fachwissen oder kontextuelle Informationen zu integrieren, die für bestimmte Anwendungen entscheidend sind. Daraus resultieren suboptimale Ergebnisse, wenn man die Modelle auf realistische Szenarien anwendet.
Insgesamt stellen diese Limitierungen wichtige Faktoren dar, die bei der Entwicklung und Implementierung von Transformers-basierten Lösungen zu berücksichtigen gilt. (jcb)





