
© foottoo / 123rf.com
Flussbasierte generative Modelle nutzen invertierbare Transformationen, um komplexe Datenverteilungen zu erzeugen. Verwendung finden sie in Bereichen wie Bildgenerierung, Dichteschätzung und Anomalieerkennung.
Flussbasierte generative Modelle oder kurz Flussmodelle (Flow-based Models) sind eine bestimmte Klasse von generativen Modellen im Bereich des maschinellen Lernens. Neben flussbasierten Modellen gibt es noch weitere populäre generative Modelle (Abbildung 1), beispielsweise Variational Autoencoders (VAEs) oder Generative Adversarial Networks (GANs).
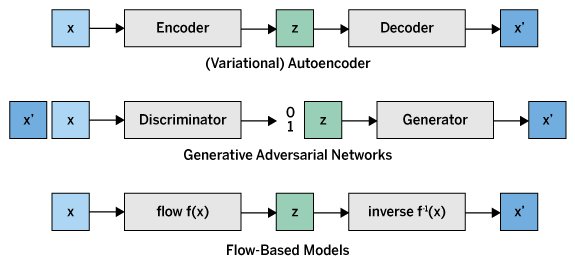
Abbildung 1: Prinzipielle Funktionsweise verschiedener generativer Modelle.
Bei Variational Autoencoders handelt es sich um probabilistische Modelle auf der Basis von Autoencodern. Sie bestehen aus einem Encoder, der die Eingabedaten in eine latente Repräsentation komprimiert, und einem Decoder, der aus dieser latenten Repräsentation die ursprünglichen Daten wieder rekonstruiert. Der entscheidende Unterschied zu klassischen Autoencodern liegt in der Annahme, dass die latente Repräsentation einer bekannten Verteilung folgt, meist einer Normalverteilung. Durch die Einführung von Stochastizität, also der Vorhersage von Wahrscheinlichkeiten, können VAEs realistische und zugleich vielfältige Daten generieren.
Generative Adversarial Networks bestehen aus zwei neuronalen Netzwerken: einem Generator und einem Diskriminator. Der Generator erzeugt Daten, während der Diskriminator zu unterscheiden versucht, ob die Daten echt sind oder vom Generator erstellt wurden. Diese beiden Netzwerke werden in einem Minimax-Spiel gegeneinander trainiert: Der Generator versucht, den Diskriminator zu täuschen, während der Diskriminator versucht, Fälschungen zu erkennen. Dieser Wettbewerb führt zu einem Generator, der extrem realistische Daten zu erzeugen vermag. GANs sind bekannt für ihre Fähigkeit, hochqualitative Bilder zu erzeugen.
Im Gegensatz zu VAEs und GANs nutzen flussbasierte Modelle invertierbare Transformationen, um Daten von einer einfachen Verteilung wie einer Normalverteilung in eine komplexere Verteilung zu transformieren, die die realen Daten besser beschreibt. Diese Transformationen gestaltet man so, dass sie invertierbar und differenzierbar sind, was die Berechnung der Wahrscheinlichkeitsdichtefunktion ermöglicht. Dadurch können flussbasierte Modelle sowohl Daten generieren als auch deren Dichtefunktion explizit modellieren.
Ein Vergleich der drei Ansätze zeigt, dass VAEs eine solide probabilistische Grundlage bieten und vielfältige Daten erzeugen, was allerdings manchmal zu unscharfen Bildern führt. Die Stärke von GANs liegt in der Erzeugung realistisch aussehender Bilder, sie haben aber Probleme mit der Stabilität des Trainings und der fehlenden expliziten Wahrscheinlichkeitsmodellierung. Flussbasierte Modelle hingegen bieten eine exakte Wahrscheinlichkeitsdichtefunktion und lassen sich vielseitig einsetzen, sie bleiben jedoch in der Bildqualität oft hinter GANs zurück. Die Wahl des Modells hängt stark von der spezifischen Anwendung und den Anforderungen an die Datenqualität und die Interpretation der Daten ab.
Flussbasierte Modelle
Die Grundidee flussbasierter Modelle ist es, eine Sequenz invertierbarer und differenzierbarer Transformationen anzuwenden. Sie ermöglichen es, sowohl die Vorwärtsrichtung (von den Daten zur latenten Repräsentation) als auch die Rückwärtsrichtung (von der latenten Repräsentation zu den Daten) zu berechnen (Abbildung 2).
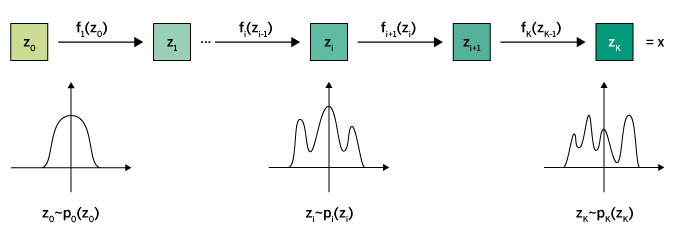
Abbildung 2: Aufeinanderfolgende einfache Transformationen nähern die Wahrscheinlichkeitsverteilung des Ziels immer genauer an.
Die generierten Daten x werden durch die Serie an Transformationen/Funktionen fk ausgehend von einer einfach verteilten Variable z0 erzeugt:
x = f -> (z0) = fk -> fk-1 -> -> -> f1(z0)
Alle Funktionen sind hierbei invertierbar (also bijektiv) und differenzierbar. Eine komplexe Funktion f-> wird so durch eine Aneinanderreihung einfacher Funktionen dargestellt, deren Parameter erlernt werden. Dadurch können die Modelle die Wahrscheinlichkeitsdichte der Daten explizit modellieren und neue Datenpunkte effizient generieren. Die Wahrscheinlichkeitsdichte berechnet man, indem man während der Transformation die Variablen ändert und dabei darauf achtet, dass das Wahrscheinlichkeitsmaß erhalten bleibt:
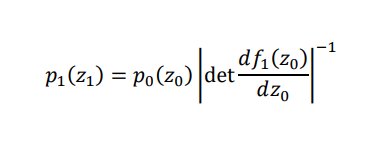
Der Ausdruck det(…) beschreibt hier die Determinante der Jacobi-Matrix, die die partiellen Ableitungen der Transformationen enthält. Bei der Jacobi-Matrix handelt es sich um ein mathematisches Werkzeug aus der Mathematik und Ingenieurwissenschaft, das insbesondere in der Differentialrechnung und bei der Untersuchung von Funktionen mehrerer Variablen zum Einsatz kommt. Sie hilft zu verstehen, wie sich die Ausgaben einer Funktion verändern, wenn man die Eingaben modifiziert. Durch Anwendung der Kettenregel ergibt sich daraus:
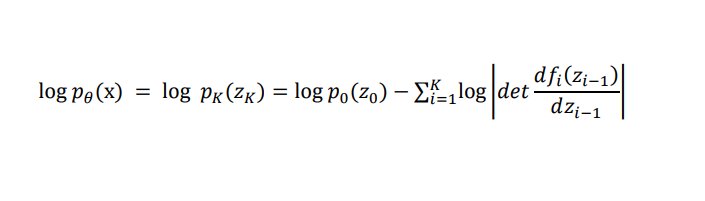
Wie beim Training generativer Modelle allgemein üblich, besteht das Ziel bei flussbasierten Modellen darin, die Kullback-Leibler-Divergenz (KL-Divergenz) zwischen der Verteilung des Modells und der zu schätzenden Zielverteilung zu minimieren. Die KL-Divergenz bietet ein Maß dafür, wie eine Wahrscheinlichkeitsverteilung von einer anderen abweicht: Je kleiner die Divergenz, umso ähnlich sind die Verteilungen einander. Es lässt sich mathematisch zeigen, dass das Minimieren der KL-Divergenz äquivalent dazu ist, die Likelihood-Funktion des Modells unter den Trainingsdaten zu maximieren:
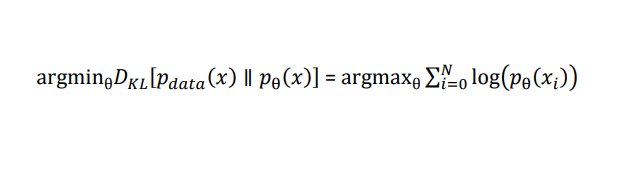
Hier steht DKL[…] für die KL-Divergenz zwischen der generierten und der gewünschten Verteilung. Die Maximierung der Likelihood-Funktion kann man dann mit dem Gradientenverfahren berechnen und darüber die optimalen Parameter des Modells bestimmen. Nach dem Training ist das Modell in der Lage, Daten zu generieren, die einer vorgegebenen Verteilung folgen.
Konstruktion des Flusses
Der Fluss in flussbasierten Netzen baut sich aus den hintereinander folgenden Transformationen auf. Die müssen mehrere wichtige Anforderungen erfüllen. Zunächst müssen sie invertierbar sein, sodass jede Transformation eine eindeutige Umkehrfunktion hat. Diese Invertierbarkeit spielt eine entscheidende Rolle, da nur so die Wahrscheinlichkeiten der Daten berechnet und neue Daten generiert werden können. Ohne diese Eigenschaft wäre es unmöglich, die Transformationen rückgängig zu machen, um von der latenten Raumdarstellung zurück zur Datenraumdarstellung zu gelangen.
Ein weiterer wichtiger Aspekt ist die Berechenbarkeit der Jacobi-Determinante. Die Determinante der Jacobi-Matrix, die die Ableitungen der Transformation darstellt, muss sich effizient berechnen lassen. Diese Determinante ist ein zentraler Bestandteil bei der Berechnung der Wahrscheinlichkeitsdichtefunktion der Daten, und nur eine effiziente Berechnung ermöglicht, das Modell in akzeptabler Zeit zu trainieren und zu evaluieren. Zudem müssen die Transformationen differenzierbar sein, was bedeutet, dass kontinuierliche Ableitungen existieren. Die Differenzierbarkeit ist essenziell für die Anwendung gradientenbasierter Optimierungsverfahren. Ohne differenzierbare Transformationen wäre das Training der Modelle nicht möglich.
Darüber hinaus müssen die Transformationen flexibel und komplex genug sein, um die Verteilung der Daten akkurat zu modellieren. Nur bei einer ausreichenden Modellkapazität lassen sich die tatsächlichen Datenverteilungen realistisch nachbilden. Ein Modell mit zu geringer Komplexität könnte wichtige Merkmale der Daten übersehen und somit ungenaue oder verzerrte Ergebnisse liefern. Schließlich sollten die Transformationen numerisch stabil sein, insbesondere bei der Inversion und der Berechnung der Jacobi-Determinante. Die numerische Stabilität stellt sicher, dass das Modell robust ist und sich nicht durch kleine numerische Fehler oder Instabilitäten beeinträchtigen lässt. Das vermeidet schlechte Modellergebnisse oder Trainingsabbrüche.
Basierend auf diesen Kriterien haben sich in den letzten Jahren einige Verfahren zur Konstruktion des Flusses etabliert. NICE (Non-linear Independent Components Estimation), eines der ersten Modelle, verwendete eine Serie additiver Coupling Layers, die die Daten in zwei Hälften aufteilen und eine Hälfte bedingt auf die andere transformieren. Diese Transformationen lassen sich invertieren und ermöglichen eine einfache Berechnung der Jacobi-Determinante, da sie entweder 1 oder -1 ist.
RealNVP (Real-valued Non-Volume Preserving) erweitert NICE, indem es affine Coupling Layers einführt, bei denen nicht nur additive, sondern auch skalierende Transformationen angewendet werden. Das erhöht die Flexibilität und Ausdruckskraft des Modells. Glow baut auf RealNVP auf und führt 1×1-volumenerhaltende Convolutions ein, die die Permutation von Kanälen ermöglichen. Das steigert die Flexibilität der Modellierung weiter und ermöglicht eine effizientere Repräsentation komplexer Verteilungen.
Insgesamt gibt es mittlerweile eine ganze Reihe von Transformationen, die bei flussbasierten generativen Modellen zum Einsatz kommen. Mit derartigen und noch weiteren Flüssen lassen sich flussbasierte Modelle aufbauen und entsprechend ihren Parametern trainieren. Im Anschluss daran können Sie die gewünschte Verteilung generieren.
Fazit
Flussbasierte generative Modelle haben sich als leistungsfähige Werkzeuge zur Generierung hochqualitativer Daten erwiesen, die durch ihre genaue Wahrscheinlichkeitsdichtefunktion und die einfache Umkehrbarkeit hervorstechen. Im Vergleich mit anderen generativen Modellen wie GANs und VAEs bieten sie den Vorteil einer exakten und effizienten Likelihood-Schätzung. Das macht sie besonders nützlich für Anwendungen, die auf eine präzise Modellierung der Datenverteilung angewiesen sind.
Ein wesentlicher Vorteil flussbasierter Modelle liegt in ihrer Fähigkeit, komplexe Datenverteilungen durch eine Abfolge invertierbarer Transformationen abzubilden. Das ermöglicht nicht nur das Generieren neuer Datenpunkte, sondern auch ein direktes Berechnen der Wahrscheinlichkeiten bestehender Datenpunkte. Dank der Reversibilität der Transformationskette arbeiten flussbasierte Modelle sowohl bei der Vor- als auch bei der Rückwärtsabbildung effizient. Das macht sie zur attraktiven Wahl für diverse Anwendungen in der Bild-, Audio- und Textgenerierung.
Trotz ihrer Stärken gibt es im Bereich der flussbasierten generativen Modelle noch Herausforderungen und offene Forschungsfragen. Insbesondere die Skalierbarkeit auf sehr hochdimensionale Daten und die Effizienz der Trainingsprozesse bleiben Bereiche, die weitere Optimierungen erfordern. Darüber hinaus ist die Wahl geeigneter Transformationen und Architekturen entscheidend für die Leistungsfähigkeit dieser Modelle. (jcb)





