
© Rostislav Zatonskiy / 123RF.com
ChatGPT ermöglicht einen Plausch mit dem Rechner. Aber wie können Maschinen mit uns reden? Wir werfen einen Blick hinter die Kulissen und erklären die Konzepte. Denn nur wer versteht, wie Sprachmodelle funktionieren, wendet sie erfolgreich an.
Informatiker kennen Modelle aus vielen Perspektiven – wer etwa beim Programmieren Entwurfsmuster verwendet, nutzt ein Modell für eine Lösungsvariante. Ähnlich gehen Ingenieure in anderen Disziplinen vor, zum Beispiel Architekten, bevor der Hausbau beginnt. Wie verhält es sich aber bei einem Sprachmodell?
Sprache als Modell
Linguisten, aber auch Mathematiker oder Informationswissenschaftler interessieren sich schon sehr lange für die Muster, die sich in menschlicher Sprache verbergen, ob geschrieben oder gesprochen. Schon 1913 probierte beispielsweise der Mathematiker Andrei Markow mit seinen als Markow-Ketten bekannten Modellen, Buchstabensequenzen zu vervollständigen – rein statistisch und ohne linguistisches Wissen zu integrieren. Im Laufe der Jahrzehnte machten sich weitere Forscher und Ingenieure daran, solche statistischen Methoden zu nutzen, darunter das berühmte Team um Alan Turing, das im Zweiten Weltkrieg die Verschlüsselungsmaschine Enigma der deutschen Kriegsmaschinerie knackte. Claude Shannon und Warren Weaver versuchten sich wenige Jahre später mit ähnlichen Methoden an der maschinellen Übersetzung russischer Texte, wenn auch mit sehr begrenztem Erfolg.
Dennoch stützten sich die meisten Weiterentwicklungen der darauffolgenden Jahrzehnte auf die Markow-Annahme: Buchstaben und Wörter lassen sich als Sequenzen von Zuständen interpretieren, aus denen sich wiederum Wahrscheinlichkeiten für den folgenden Zustand ergeben, also etwa das nächste Wort oder den nächsten Buchstaben. Sogenannte n-gram-Modelle erzielten bis vor einigen Jahren die besten Ergebnisse; n steht dabei für die Länge der Sequenz, ein 3-gram- oder Trigram-Modell verwendet beispielsweise Sequenzen aus drei Wörtern (n=3) zum Generieren oder Interpretieren von Texten.
Typische Anwendungsfälle sind die Klassifizierung und Analyse von Dokumenten, Suchmaschinen oder die Extraktion von Informationen. Zum Beispiel: “Handelt es sich bei dieser E-Mail um eine Support-Anfrage oder um einen Auftrag?” oder “Welchen Aspekt von Produkt A finden seine Benutzer besonders gut oder schlecht?” (Sentiment-Analyse). Das Generieren von Texten spielt dabei in der Praxis häufig nur eine Nebenrolle, doch spezielle Anwendungen wie automatische Übersetzung oder Chatbots wie ChatGPT benötigen Mechanismen, um Texte nicht nur zu verstehen, sondern auch zu erzeugen. Bei ihnen kommt der traditionelle Ansatz zum Modellieren von Sprache zum Tragen, den schon Andrej Markow verfolgte.
Um Wörter und Texte vor allem in einer maschinell zu verarbeitenden Form zu repräsentieren, hat sich eine andere Theorie als hilfreich erwiesen: die distributionelle Semantik. Frei nach dem Linguisten John Rupert Firth besagt sie, dass ein Wort sich durch seine Gesellschaft auszeichnet: Wörter, die häufig in ähnlichen Kontexten vorkommen, ähneln einander. Diese Erkenntnis ermöglicht es, mittels rein statistischer Eigenschaften Rückschlüsse darauf zu ziehen, welche Bedeutung Wörter haben und in welcher Beziehung sie zueinander stehen.
Allerdings sagt der gemeinsame Kontext wenig über die Art der Beziehung zwischen Wörtern aus. Es kann sich um Synonyme handeln, aber auch Gegensätze weisen gewisse Formen von Ähnlichkeit auf. Beispielsweise lässt sich darüber streiten, ob die Wörter “blau” und “gelb” einander ähneln. Einerseits beschreiben sie beide eine Farbe, andererseits handelt es sich um komplementäre Farben. Neben solchen inhaltlichen Beziehungen sorgen auch grammatikalische Faktoren dafür, dass Wörter in ähnlichen Kontexten auftauchen, beispielsweise Nomen im Genitiv oder Artikel.
Sprache, Verständnis und Intelligenz
Die Definition des Begriffs künstliche Intelligenz fällt mindestens ebenso unscharf aus wie die der Intelligenz im Allgemeinen. Beide haben im Laufe der Jahrzehnte erhebliche Veränderungen erfahren. Meistens fasst man unter künstlicher Intelligenz Algorithmen und Software zusammen, die aus unstrukturierten, nicht direkt maschinell les- und verarbeitbaren Daten weiterführende Rückschlüsse und Erkenntnisse liefern. Dabei spielt die Verarbeitung einerseits von Sprache in geschriebener und gesprochener Form und andererseits von Bildern und Videos die Hauptrolle – oder auch die Kombination aus beiden. Die wichtigsten Bausteine künstlicher Intelligenz bilden darum das Natural Language Processing (“Verarbeitung natürlicher Sprache”, abgekürzt als NLP oder NLProc) und Computer Vision (die Verarbeitung optischer Eingaben).
Die akademische Schwester von NLP ist die Computerlinguistik, die Methoden aus den Sprachwissenschaften, der Mathematik und den Informationswissenschaften vereint, um menschliche Sprache algorithmisch zu untersuchen. NLP und Computer Vision hingegen legen den Fokus auf praktische Ansätze: die Erforschung von Algorithmen und Softwarelösungen für die Verarbeitung von Sprache und Bildern zu bestimmten Zwecken. Methodisch stehen bei der künstlichen Intelligenz heute meist verschiedene Formen des maschinellen Lernens im Mittelpunkt, seit einigen Jahren vor allem künstliche neuronale Netze. Bis in die 2000er-Jahre bestanden diese aus wenigen Ebenen und relativ einfachen Architekturen, da Hardware und effiziente Algorithmen fehlten, um komplexere Netze zu optimieren.
Leistungsfähige Grafikprozessoren (GPUs) und ausgefeilte mathematische Methoden zum effizienten Trainieren solcher Netze mittels Backpropagation (Fehlerrückführung) und Stochastic Gradient Descent (stochastischer Gradientenabstieg) haben in den beiden vergangenen Jahrzehnten die Entwicklung komplexer neuronaler Netze ermöglicht. Man spricht hier von Deep Learning, weil “tiefe” Architekturen zahlreiche Ebenen in einem neuronalen Netz hintereinander schalten, aber auch weil sie ein anscheinend tieferes Verständnis der eingeführten Informationen erreichen. Die Frage, ob Maschinen ohne Bewusstsein auf Basis von Wahrscheinlichkeiten Texte verstehen können, behandelte der Sprachphilosoph John Searle bereits 1980 in seinem Aufsatz über das “Chinesische Zimmer”. Danach reicht ein Chinese einem Nichtchinesen in einem geschlossenen Raum durch einen Schlitz in der Tür Fragen auf Chinesisch herein. Der Mann im Raum versteht kein bisschen Chinesisch, verfügt aber über eine Anleitung, wie er rein mechanisch, allein anhand der Zeichen, deren Bedeutung er nicht kennt, andere Zeichen zu einer sinnvollen Antwort zusammensetzen kann. Die gibt er durch den Schlitz heraus. Der Chinese außerhalb des Raums schlussfolgert nun, im Raum müsse sich ein Landsmann befinden, der seine Fragen verstanden hat. Das Gedankenexperiment wirft Fragen auf wie: Was bedeutet Verständnis? Reicht es, Symbole nach Regeln zu manipulieren? Kann eine Maschine Text verstehen? Eine eindeutige Antwort bleibt allerdings aus, denn sie hängt von der Interpretation von Verständnis und Bewusstsein ab.
Die Wurzeln des Begriffs künstliche Intelligenz lassen sich bis in einen Forschungsantrag aus dem Jahr 1955 zurückverfolgen. Von Deep Learning war noch keine Rede, und viele Systeme setzten noch auf durch Experten manuell angelegte Regeln, etwa zum Interpretieren von Sätzen mittels grammatikalischer Regeln. Die schwammige Definition des Begriffs mit zugleich futuristischem Anklang erlaubt es, ihn für klar definierte Algorithmen ebenso wie für Prognosen über Maschinen mit unvorstellbaren Fähigkeiten zu verwenden.
Der Begriff Artificial General Intelligence (AGI; “künstliche allgemeine Intelligenz”) soll die Definition schärfen. Er umschreibt künftig zu entwickelnde Maschinen, deren Intelligenz praktisch alle Bereiche der realen Welt umfasst, sich also nicht auf spezifische Aufgaben oder Medien wie Texte oder Bilder beschränkt. Vor allem aber sollen diese Maschinen komplexe Entscheidungen treffen und dabei dem Menschen mindestens ebenbürtig sein. Bekannte Softwareentwickler und Investoren wie Geoffrey Hinton beziehungsweise Elon Musk prophezeien, dass es eine solche Supermaschine in naher Zukunft geben wird. Vertreter solcher Thesen sind sich jedoch uneins darüber, ob eine solche Technologie die Menschheit unterjochen oder all ihre Probleme lösen wird. Sie nehmen dabei vor allem an, dass die Geschwindigkeit der Entwicklung der letzten Jahre künftig weiter zunimmt. Ein sich selbst beschleunigender Prozess nimmt Fahrt auf, bei dem immer intelligentere Maschinen lernen, ihre eigenen Algorithmen zu verbessern – die sogenannte technologische Singularität. Konkrete Methoden kommen dabei allerdings nicht zur Sprache – schließlich sollen sich diese selbst entwickeln.
Kritiker merken an, dass sich trotz der enormen Investitionen in die Technologie, die nach dem Erscheinen von GPT-3 noch gestiegen sind, bisher keine Anzeichen für eine sich selbst weiterentwickelnde künstliche Intelligenz erkennen lassen. Vielmehr fragen sie, welche konkreten Ziele sich weitere Entwicklungen setzen sollten, und versuchen, die Aufmerksamkeit auf ganz reale Probleme von Large Language Models zu lenken. Darunter fallen unter anderem angelernte Vorurteile, fehlende Transparenz, ein enormer Energiebedarf, schlechte Arbeitsbedingungen der zahlreichen menschlichen Helfer sowie sogenannte Halluzinationen (siehe Kasten “Halluzination oder Fakt?”).
Rechnen mit Wörtern
Die Kombination aus linguistischer Theorie, effizienten Algorithmen und großen Textmengen führte seit den 2010er-Jahren zu Sprachmodellen einer neuen Generation. Statt Wortsequenzen – n-Gramme – zu zählen, weisen der Algorithmus Word2Vec aus dem Jahr 2013 und seine zahlreichen Varianten jedem Wort einen Vektor zu. Dessen numerische Werte passen sie, inspiriert durch die distributionelle Semantik, mittels eines künstlichen neuronalen Netzes so an, dass die Vektoren von Wörtern nahe beieinander liegen, wenn sie häufig in ähnlichen Kontexten vorkommen. Daraus resultiert ein semantischer Vektorraum, der durch die Wortvektoren die Beziehungen zwischen Wörtern so abbildet, dass diese sich mit mathematischen Operationen berechnen lassen.
Abbildung 1 illustriert die Idee mittels einer Projektion in den zweidimensionalen Raum. Zum Beispiel erhält das Wort “king” (König) einen Vektor, “queen” (Königin) einen anderen. Subtrahiert man nun von “king” den Vektor für “man” (Mann) und addiert jenen für “woman” (Frau), landet man wieder bei der “queen”. Der semantische Vektorraum hat indes Hunderte Dimensionen, die nur abstrakte Bedeutung tragen. Sie können in unterschiedlichen Kombinationen aber konkrete sprachliche Beziehungen abbilden, wie im Beispiel eine sprachliche Repräsentation des Geschlechts.
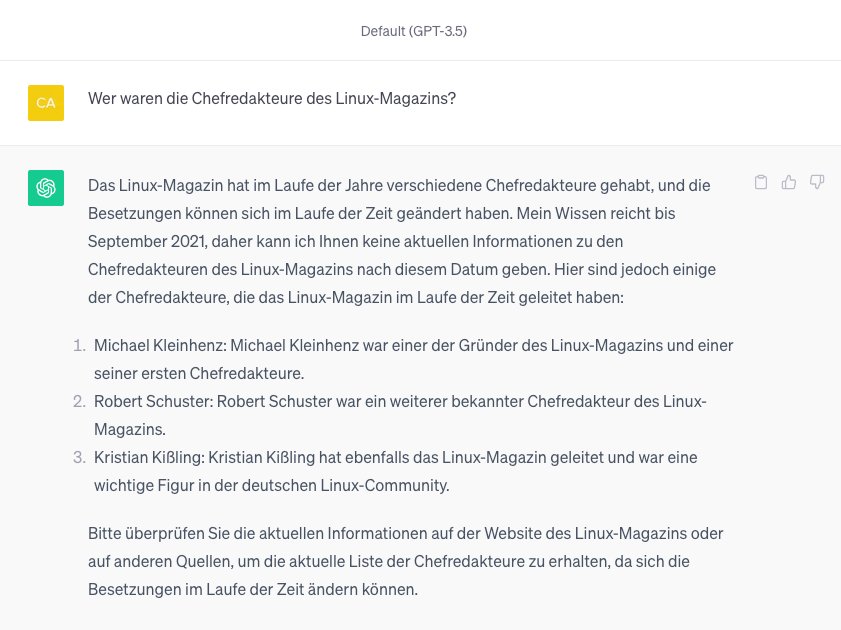
Abbildung 2: ChatGPT halluziniert Chefredakteure des Linux-Magazins. Keiner der genannten Namen stimmt, die echten Chefredakteure finden hingegen keine Erwähnung.

Abbildung 3: Neben Falschinformationen gehören auch innere Widersprüche zum Halluzinationsrepertoire von ChatGPT. Der Autor dieses Artikels wird fälschlich zum Chefredakteur erklärt, obwohl er in der zuvor erstellten Liste noch nicht vorkam.
Kein Wunder
Vor einem Jahr erreichte ChatGPT durch eine Mischung aus leistungsfähiger Technik, gutem Marketing und allgemeiner Zugänglichkeit ein enormes Publikum. Die Masse der Internet-Benutzer verwendete es auf teils sehr kreative Weise, und vielen schien es, als ob für ChatGPT kaum eine Aufgabe zu schwierig sei. Selbst seine Entwickler und andere Experten können nicht alle Fragen im Detail beantworten: Was genau steckt eigentlich in den Parametern eines solchen Modells, und woher nimmt es all sein Wissen? Die statistischen Methoden und die enorm umfangreichen Trainingsdaten lassen nicht nachvollziehen, wie die Parameterwerte eines neuronalen Netzes im Einzelnen zustande gekommen sind.
Diese Unklarheit öffnet die Tür für Spekulation. Moderne Sprachmodelle lassen sich mit ihren beeindruckenden Fähigkeiten dennoch nicht als bloße Matrizenmultiplikation abtun, auch wenn das den mathematischen Anteil korrekt beschreibt. Sie generieren noch nie dagewesene Sätze und Inhalte, weshalb sie augenscheinlich kreativ agieren. Andererseits folgen sie dennoch den gelernten Mustern – sei es auf sehr abstrakter Ebene – und scheitern folglich daran, beispielsweise Texte mit Fehlern oder künstlerisch motivierten Regelbrüchen zu schreiben. Abbildung 4 zeigt etwa ein durch Google Gemini erzeugtes dadaistisches Gedicht. Es beinhaltet den Aufruf zum Regelbruch, jedoch ausschließlich mit existierenden Wörtern und grammatikalisch korrekten Sätzen.

Abbildung 4: Ein Sprachmodell wie Google Gemini kann zwar zum Regelbruch aufrufen, bleibt aber auch dabei im Rahmen gelernter Muster.
Ungeachtet der Faszination für die Technologie, die linguistische Theorie und Informationswissenschaften, ausgefeiltes Software-Engineering und maschinelles Lernen zu einer fertigen Anwendung kombiniert, liefert der Blick auf die Vorgeschichte von ChatGPT interessanten Kontext. Spätestens seit Joseph Weizenbaum in den 1960ern seine “automatische Psychotherapeutin” namens Eliza vorstellte, wähnten sich Benutzer bei jedem neuen Durchbruch in der künstlichen Intelligenz in einem neuen Zeitalter – bis hin zur bevorstehenden Übernahme der Welt durch Maschinen. Als Google 2021 sein Konversationssystem namens Lambda vorstellte, kam es zu praktisch identischen Diskussionen wie in den vergangenen Monaten, wenn auch in kleineren Kreisen als bei ChatGPT. Lambda sowie Eliza sind inzwischen praktisch vergessen.
Dennoch eröffnet die neue Technologie bis vor Kurzem ungeahnte Möglichkeiten in vielen Feldern, die teilweise noch nicht erschlossen sind. Wer sie praktisch anwenden möchte, muss ihre Funktionsweise, Möglichkeiten und Beschränkungen verstehen. Wenn es um konkrete Aufgabenstellungen geht, gilt es, über beeindruckende Einzelbeispiele hinwegzusehen und die Aufgaben systematisch zu evaluieren. Eine formale Evaluierung ist unersetzbar und zeigt, dass Large Language Models oft, aber nicht immer die beste Wahl sind – wenn man sie richtig anwendet.
Infos
- Spacy: https://spacy.io
- Huggingface Transformers: https://huggingface.co/docs/transformers
- Huggingface Model Hub: https://huggingface.co






