
© Sergey Nivens / 123RF.com
Künstliche neuronale Netze bilden das Rückgrat vieler moderner KI-Systeme. Sie ahmen die Strukturen biologischer Gehirne nach, um Muster in Daten zu erkennen und Vorhersagen zu treffen. Ihre Fähigkeiten haben zu zahlreichen Durchbrüchen in der Bild- und Spracherkennung geführt.
Biologische Gehirne bestehen aus Milliarden von Neuronen, die durch Synapsen miteinander verbunden sind. Jedes Neuron empfängt Signale von seinen Dendriten und leitet sie, sobald eine bestimmte Schwelle überschritten ist, über das Axon weiter. Diese Übertragung und Verarbeitung von Signalen ermöglicht es, so komplexe Aufgaben zu lösen wie Wahrnehmung, Motorik oder kognitive Funktionen. Künstliche neuronale Netze sind von dem natürlichen System inspiriert und bauen ein Netz künstlicher Neuronen auf, das durch Anpassen der Gewichtung von Verbindungen lernen und komplexe Funktionen approximieren kann.
Künstliche Neuronen
Ein künstliches Neuron imitiert die Funktionsweise seines biologischen Pendants, allerdings in einer stark vereinfachten und abstrahierten Form. In der Biologie empfangen die Dendriten eines Neurons Signale von anderen Neuronen, die dann im Zellkörper integriert werden. Überschreitet die Summe dieser Signale einen bestimmten Schwellenwert, wird ein Aktionspotenzial entlang des Axons zu den Synapsen geleitet, wo chemische Botenstoffe, die Neurotransmitter, die Information an das nächste Neuron übertragen. Die Stärke dieser synaptischen Verbindungen ist veränderlich und ermöglicht das Lernen durch Plastizität.
In der Welt der künstlichen neuronalen Netze multipliziert man Eingangswerte, die den Dendriten ähneln, mit Gewichten, die die Synapsenstärke repräsentieren. Die gewichteten Eingänge werden dann summiert, ähnlich der Integration im Zellkörper eines biologischen Neurons. Eine Aktivierungsfunktion entscheidet anschließend, basierend auf dieser Summe, ob und wie das künstliche Neuron ein Signal aussendet. Der Ausgang des Neurons, der einem Aktionspotenzial gleichkommt, wird dann an nachfolgende Neuronen weitergeleitet. Das Lernen in künstlichen neuronalen Netzen findet statt, indem die Gewichte der Verbindungen zwischen den Neuronen während des Trainingsprozesses im Rahmen einer Optimierungsaufgabe angepasst werden.
Die genaue Struktur eines künstlichen Neurons zeigt Abbildung 1. Das j-te Neuron eines künstlichen neuronalen Netzes erhält Daten via Eingangsvariablen und verarbeitet diese intern durch lineare und nichtlineare Operationen. Das Neuron erhält n Eingabevariablen X1 bis Xn. Auf diese Eingangsdaten wird zuerst die Übertragungsfunktion angewandt. Hierbei wird eine Linearkombination der Eingangsvariablen mit den Gewichten Wij bis Wnj berechnet:
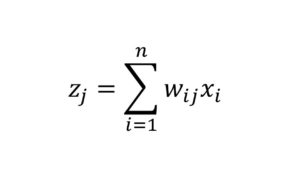
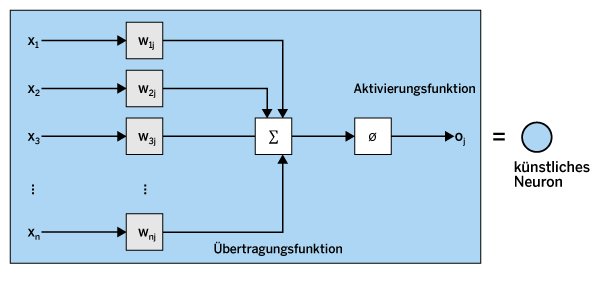
Abbildung 1: So sieht die Struktur eines künstlichen Neurons aus.
Die Gewichte sind freie Parameter des Neurons, die im Laufe des Trainingsprozesses nach einem Optimierungsschema so gewählt werden, dass sie die zugrunde liegende Aufgabe des Netzes optimal lösen. Nach der linearen Übertragungsfunktion wird die nichtlineare Aktivierungsfunktion auf das Ergebnis der Linearkombination angewendet:
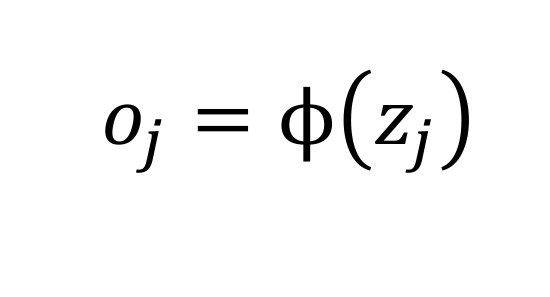
Die Aktivierungsfunktion kann verschiedene Formen annehmen. Am gebräuchlichsten sind die ReLU-Funktion (Rectified Linear Unit) oder die Sigmoid-Funktion (Abbildung 2). Entscheidend ist, dass es sich bei der Aktivierungsfunktion um eine nichtlineare Funktion handelt. Anderenfalls würde das gesamte neuronale Netz lediglich eine lineare Funktion darstellen. Damit wäre das Netz nur in der Lage, lineare Zusammenhänge zu beschreiben, und könnte keine komplexeren Probleme lösen. Die Nichtlinearität der Aktivierungsfunktion spielt somit eine entscheidende Rolle beim Aufbau neuronaler Netze. Ein einzelnes künstliches Neuron wird oftmals durch einen einfachen Kreis dargestellt.
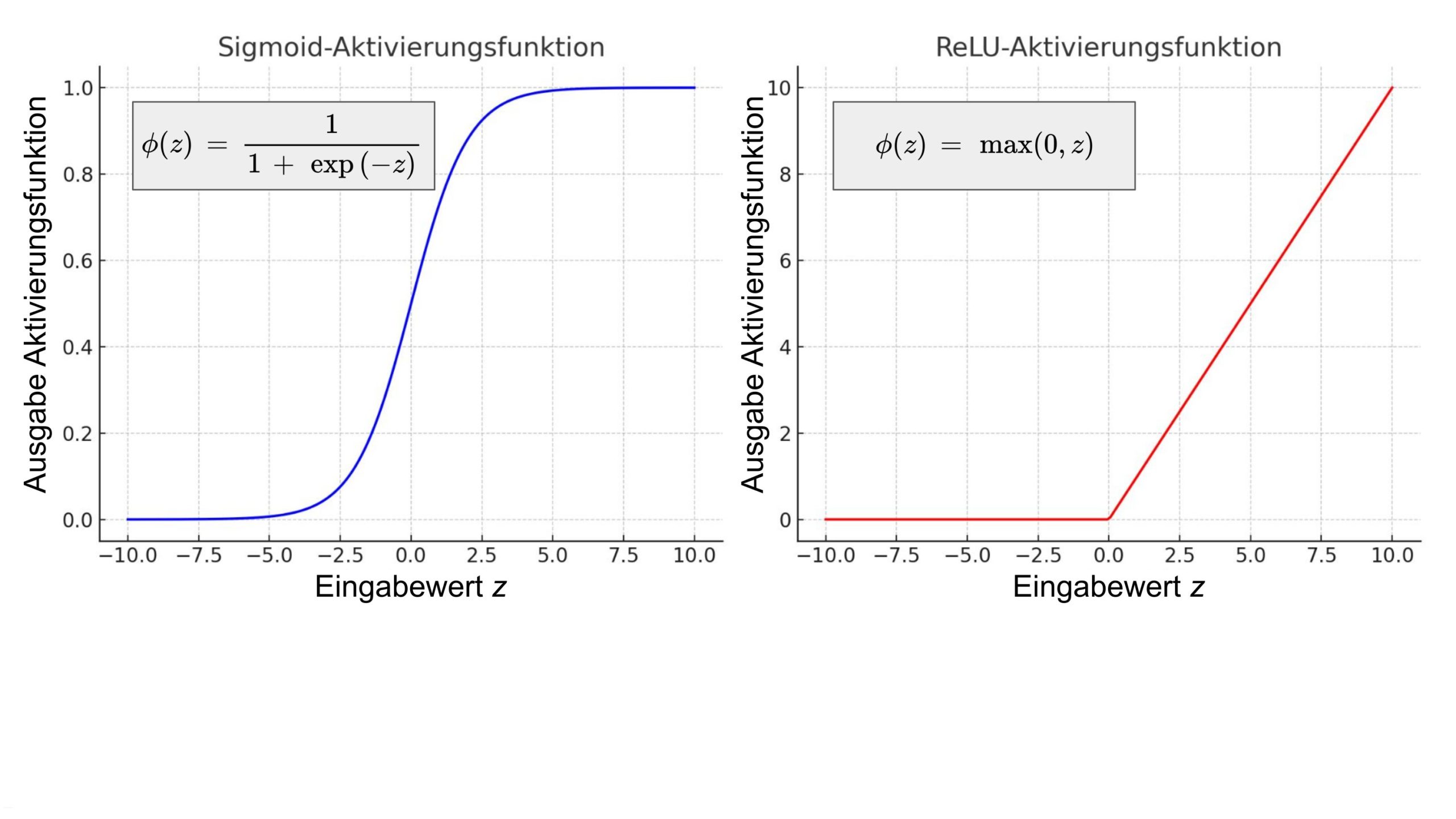
Abbildung 2: Die gebräuchlichsten Aktivierungsfunktionen.
Künstliche neuronale Netze
Ein einzelnes künstliches Neuron mit einer Sigmoid-Aktivierungsfunktion ähnelt stark der logistischen Regression zur binären Klassifikation. Entsprechend kann ein solches Neuron einfachste binäre Klassifikationsaufgaben ausführen. Durch das Zusammenschalten mehrerer Neuronen können allerdings auch komplexere Probleme gelöst werden. Ein solches einfaches neuronales Netz zeigt Abbildung 3.
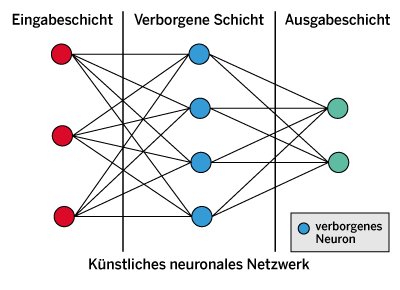
Abbildung 3: Ein einfaches neuronales Netz aus künstlichen Neuronen.
Die Eingabe in das neuronale Netz findet in der Eingabeschicht statt. Die Daten werden dann in einer verborgenen Schicht weiterverarbeitet, bevor sie in der Ausgabeschicht anlangen. Dies ist das einfachste neuronale Netz, das als vorwärts gerichtetes neuronales Netz bezeichnet wird und keinerlei Rückkopplungen aufweist. Die Daten laufen bei einem solchen Netz von der Eingangsschicht in Richtung Ausgangsschicht. Im Gegensatz zu solchen Netzen spricht man bei Netzen mit Rückkopplungen von rekurrenten Netzen.
Für solche vorwärts gerichteten neuronalen Netze gilt der sogenannte universelle Approximationssatz, ein fundamentales mathematisches Prinzip in der Theorie der neuronalen Netze. Dieser mathematische Satz besagt, dass ein vorwärts gerichtetes Netz mit einer verborgenen Schicht und einer endlichen Anzahl von Neuronen in der Lage ist, jede kontinuierliche Funktion auf einem kompakten Unterraum des Eingaberaums bis zu einem beliebigen Grad der Genauigkeit zu approximieren. Die ursprüngliche Version des Satzes basierte auf Sigmoid-Aktivierungsfunktionen. Allerdings gibt es zahlreiche weitere Varianten des Satzes und dessen Beweis. So konnte gezeigt werden, dass der Satz auch für andere Aktivierungsfunktionen wie ReLU gilt.
Abbildung 4 demonstriert den universellen Approximationssatz anhand eines praktischen Beispiels. Das neuronale Netz soll in diesem Beispiel eine binäre Klassifikation in einem zweidimensionalen Feature-Raum ausführen, der von den x- und y-Achsen aufgespannt wird. In diesem Raum gibt es rote und grüne Datenpunkte, die das neuronale Netz klassifizieren soll.
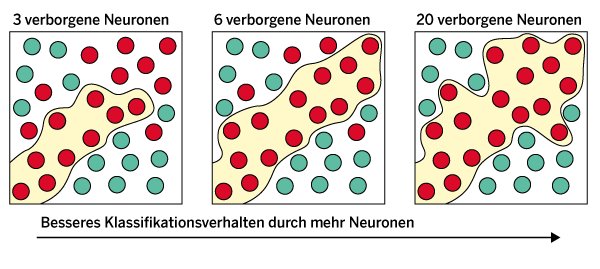
Abbildung 4: Klassifikationsresultate mit neuronalen Netzen verschiedener Größe.
Ganz links ist das Klassifikationsergebnis für ein neuronales Netz mit drei verborgenen Neuronen abgebildet. Das Gebiet mit der leicht gelblichen Hintergrundfarbe markiert den Bereich des Feature-Raums, den das neuronale Netz den roten Datenpunkten zuordnet. Mit drei verborgenen Neuronen ist das Netz noch nicht in der Lage, alle Datenpunkte korrekt zu klassifizieren. So erkennt es in diesem Fall beispielsweise nicht, dass sich im oberen rechten Bereich des Feature-Raums noch rote Datenpunkte befinden.
Wird die Anzahl der verborgenen Neuronen auf sechs erhöht, so erkennt das Netz, dass sich auch im oberen rechten Bereich rote Datenpunkte befinden. Allerdings gibt es immer noch rote Datenpunkte, die das Netz nicht richtig klassifiziert. Das gelingt erst, wenn man zwanzig verborgene Neuronen im Netz verwendet. Dann kann das neuronale Netz alle Datenpunkte korrekt klassifizieren.
Diese Verbesserung des Klassifikationsverhaltens des Netzes durch Erhöhen der Anzahl der verborgenen Neuronen ist die direkte Konsequenz des universellen Approximiationssatzes. Das Netz kann komplexere Aufgaben lösen, wenn man die Zahl der Neuronen in der verborgenen Schicht erhöht.
Deep Learning
Obwohl ein neuronales Netz mit einer verborgenen Schicht aufgrund des universellen Approximationssatzes bereits jedes Problem lösen kann, kommen in der Praxis mehrschichtige neuronale Netze zum Einsatz, die deutlich mehr als nur eine verborgene Schicht enthalten und sich dadurch effizienter trainieren lassen.
Deep Learning bezieht sich auf solche Algorithmen, die sogenannte tiefe neuronale Netze verwenden. Diese Netze bestehen aus mehreren verborgenen Schichten, durch die Daten transformiert werden, um komplexe Merkmale und Muster zu erkennen und zu lernen. Der Begriff der Tiefe bezieht sich in solchen neuronalen Netzen auf die Anzahl der verborgenen Schichten, durch die die Daten geführt werden. Jede Schicht kann man als eine Stufe des Lernens betrachten, bei der das Netz in der Lage ist, zunehmend abstraktere Merkmale der Eingabedaten zu erkennen. Tiefe Netze können aus Dutzenden oder sogar Hunderten solcher Schichten bestehen, jede mit einer Vielzahl von Neuronen.
Der Vorteil dieser tiefen neuronalen Netze besteht darin, dass die Eingabedaten von einer verborgenen Schicht zur nächsten immer weiter verarbeitet und transformiert werden. Dabei ändert sich die Darstellung (Repräsentation) der Daten so, dass die Aufgabe des neuronalen Netzes mit der endgültigen Repräsentation in der letzten verborgenen Schicht des Netzes gelöst wird. Abbildung 5 zeigt ein Beispiel dafür. Das neuronale Netz soll hier lernen, in dem zweidimensionalen Feature-Raum eine Klassifikation der blauen und roten Datenpunkte vorzunehmen.
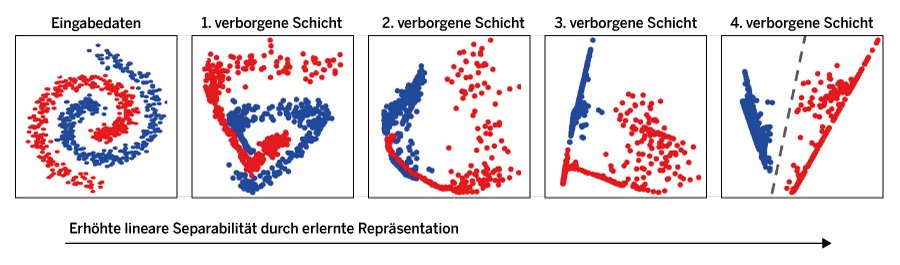
Abbildung 5: So lösen verschieden tiefe neuronale Netze eine Klassifikationsaufgabe.
Das hier verwendete neuronale Netz hat insgesamt vier verborgene Schichten sowie eine Ein- und Ausgabeschicht. Prinzipiell ließe sich dieses Problem ähnlich wie das Problem in Abbildung 4 durch eine verborgene Schicht mit sehr vielen Neuronen lösen. Allerdings ist es effizienter, hier mehrere verborgene Schichten zu verwenden, da diese Schichten eine optimale Darstellung der Daten erlernen. So sind die ursprünglichen Eingangsdaten in Abbildung 5 nicht linear separierbar. Man kann also keine Gerade durch den Feature-Raum ziehen, die die roten von den blauen Daten trennen würde. Nach der letzten verborgenen Schicht wurde die Darstellung der Daten allerdings so weit verändert, dass sie nun linear trennbar sind. Die binäre Klassifikation ist in dieser Darstellung trivial, da jetzt eine einfache Gerade die Daten trennt.
Hierin besteht der Vorteil des tiefen Lernens. Es wird eine effiziente Darstellung der Daten erlernt, sodass sich auch komplexeste Aufgaben effizient lösen lassen. Damit gelingt letztlich ein schnelleres Training der Netze.
Trainingsprozess
Zum Trainieren eines neuronalen Netzes für Aufgaben des überwachten Lernens muss man zunächst eine Verlustfunktion definieren, die misst, wie gut das neuronale Netz die Trainingsdaten beschreibt. Dabei kommt es darauf an, ob durch das neuronale Netz ein Regressions- oder ein Klassifikationsproblem gelöst werden soll. Bei Regressionsproblemen wird oftmals der mittlere quadratische Fehler als Verlustfunktion herangezogen. Für Klassifikationsprobleme wird hingegen meistens die Kreuzentropie verwendet.
Ziel des Trainings ist es, die Gewichte der einzelnen Neuronen des Netzes so zu wählen, dass die Verlustfunktion minimiert wird. Das geschieht bei neuronalen Netzen mithilfe der Methode der Fehlerrückführung. Fehlerrückführung, auch bekannt als Rückwärtspropagierung des Fehlers, ist ein fundamentales Konzept beim Training von neuronalen Netzen. Der Algorithmus dient dazu, die Gewichte eines neuronalen Netzes effizient zu aktualisieren, um den Output des Netzes den tatsächlichen Trainingsdaten besser anzupassen.
In einem Vorwärtsdurchlauf wird dazu zunächst eine Eingabe der Trainingsdaten durch das Netz geleitet, um eine Ausgabe zu erhalten. Die Ausgabe dient dann dazu, den Verlust mit der Verlustfunktion zu berechnen, indem sie mit der tatsächlichen, gewünschten Ausgabe der Trainingsdaten verglichen wird. Der Verlust gibt an, wie weit die Vorhersagen des Netzes von den tatsächlichen Werten der Trainingsdaten entfernt liegen. Diesen Fehler gilt es zu minimieren, damit das Netz präzisere Vorhersagen macht. Nach diesem Vorwärtsdurchlauf kommt der Rückwärtsdurchlauf. Hier beginnt die eigentliche Fehlerrückführung.
Dazu wird der berechnete Fehler vom Ausgang des Netzes durch das Netz zurück zum Eingang geführt. Dabei wird für jedes Gewicht im Netz bestimmt, wie viel es zum Gesamtfehler beiträgt. Dazu berechnet man die partiellen Ableitungen des Fehlers bezüglich jedes Gewichts mithilfe der Kettenregel. Nachdem der Beitrag jedes Gewichts zum Fehler bekannt ist, können die Gewichte aktualisiert werden, um den Verlust zu verringern. Das erfolgt in der Regel mit dem Gradientenverfahren. Die Gewichte werden hierzu in die entgegengesetzte Richtung des Gradienten des Fehlers aktualisiert, um den Fehler zu minimieren:
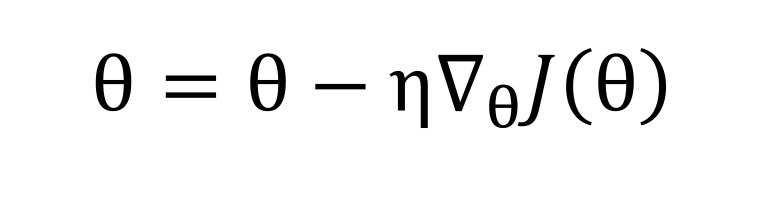
Dabei steht Theta für die verschiedenen Gewichte des Netzes und J(Theta) für die Verlustfunktion. Die Lernrate Eta des Algorithmus regelt die Schrittweite.
Das Gradientenverfahren kann in verschiedenen Modi ausgeführt werden. Beim Batch-Gradientenverfahren, auch als Stapelgradientenverfahren bekannt, berechnet man den Gradienten der Verlustfunktion in Bezug auf die Parameter für die gesamten Trainingsdaten. Dieser Ansatz gewährleistet eine stabile und präzise Konvergenzrichtung, kann jedoch bei großen Datensätzen rechenintensiv und langsam sein. Im Gegensatz dazu aktualisiert das stochastische Gradientenverfahren die Gewichte nach jedem einzelnen Trainingsbeispiel. Das führt zu einer viel schnelleren, aber auch unbeständigen Konvergenz, da die Richtung des Gradienten stark von jedem einzelnen Beispiel abhängt.
Das Mini-Batch-Gradientenverfahren bietet einen Mittelweg zwischen diesen beiden Extremen, indem es die Gewichte nach einer kleinen, zufällig ausgewählten Menge von Beispielen aktualisiert. Diese Methode vereint die Schnelligkeit des stochastischen Ansatzes mit der Stabilität des Batch-Verfahrens und wird häufig in der Praxis eingesetzt, um eine effiziente und effektive Konvergenz zu erreichen. Das alternierende Verfahren des Vorwärtsdurchlaufs und der Fehlerrückführung wird so lange wiederholt, bis das Verfahren konvergiert und sich der Verlust nicht weiter vermindert. Dann sind die Gewichte des neuronalen Netzes optimal eingestellt.
Zur weiteren Optimierung des Trainingsprozesses kommen bei neuronalen Netzen Optimierungsalgorithmen zum Einsatz. Diese Optimierer spielen eine entscheidende Rolle bei der effizienten Anpassung der Gewichte in den Netzen. Zu den bekanntesten Optimierungsalgorithmen gehören Momentum, Adagrad und Adam. Das Momentum-Verfahren zielt darauf ab, die Konvergenzgeschwindigkeit des Gradientenverfahrens zu beschleunigen, indem es die vorherige Richtung der Gewichtsaktualisierungen berücksichtigt. Das Adagrad-Verfahren passt die Lernrate dynamisch an. Das erhöht die Effizienz, indem es selten aktualisierte Parameter stärker anpasst und häufig aktualisierte weniger stark. Adam kombiniert die Vorteile von Adagrad und Momentum. Jeder dieser Optimierer hat spezifische Vorteile, die sich für verschiedene Arten von Problemen anbieten.
Ist das neuronale Netz anhand der Trainingsdaten entsprechend optimiert, kann man es auf neue bisher unbekannte Eingabedaten anwenden, um Regressions- oder Klassifikationsaufgaben auszuführen. Gerade beim Deep Learning mit seinen vielen Parametern ist es wichtig, darauf zu achten, dass es nicht zu einer Überanpassung der Trainingsdaten kommt. Deshalb werden hier während des Trainings verschiedene Regularisierungsmethoden eingesetzt, um eine Überanpassung zu verhindern und die Generalisierungsfähigkeit der Modelle zu verbessern.
Im Rahmen der L1- und L2-Regularisierung werden beispielsweise Strafterme zur Verlustfunktion hinzugefügt, um die Gewichte kleinzuhalten und so eine Überanpassung zu verhindern, die meist durch große Gewichte gekennzeichnet ist. Eine andere Regularisierungsmethode besteht darin, das Training frühzeitig abzubrechen, um nicht in die Parameterbereiche der Gewichte zu gelangen, die anfällig für Überanpassung sind.
Gerade bei größeren neuronalen Netzen kommt auch die Dropout-Methode zum Einsatz. Dabei werden zufällig ausgewählte Neuronen während des Trainings ignoriert. Diese zufällige Deaktivierung zwingt das Netz, sich nicht auf spezifische Neuronen zu verlassen, sondern robustere und redundante Repräsentationen der Daten zu lernen. Dadurch wird das Netzwerk weniger anfällig für kleine Schwankungen in den Eingabedaten und kann die zugrunde liegenden Muster besser generalisieren. Im Wesentlichen simuliert Dropout eine Vielzahl von dünn besetzten Netzen, was eine Art Ensemble-Lernmethode darstellt und das Modell robuster gegenüber Überanpassung macht.
Moderne neuronale Netze enthalten viele Milliarden von Neuronen, deren Gewichte es wie beschrieben zu trainieren gilt. Das erfordert entsprechend viele Trainingsdaten sowie schnelle Hardware. Diese Voraussetzungen waren erst zur Jahrtausendwende erfüllt. Zu diesem Zeitpunkt war es vergleichsweise einfach, an entsprechend große Datenmengen zu gelangen. Des Weiteren kamen vermehrt GPUs zum Training neuronaler Netze zum Einsatz.
GPUs können intern extrem effizient lineare Operationen ausführen, wie man sie zum Rendering in Computerspielen benötigt. Lineare Operationen sind aber auch die zentralen Operationen in künstlichen Neuronen in der Übertragungsfunktion. Deshalb lassen sich GPUs extrem effizient für das Trainieren von neuronalen Netzen anwenden. Seit vielen Jahren gibt es deshalb spezielle GPUs, die noch besser auf das Trainieren von neuronalen Netzen zugeschnitten sind.
Fazit
Zusammenfassend bieten neuronale Netze eine faszinierende und kraftvolle Methode des maschinellen Lernens. Von einfachen vorwärts gerichteten Netzen bis hin zu komplexen Systemen wie faltungsneuronalen Netzen für die Bildverarbeitung, rekurrenten neuronalen Netzen für sequenzielle Daten und generativen Netzen hat sich das Feld des tiefen Lernens rasant entwickelt.
Trotz dieser Erfolge bleibt die Erklärbarkeit solcher Systeme ein wichtiger Diskussionspunkt. Die Idee der erklärbaren künstlichen Intelligenz befasst sich mit der Schaffung von KI-Systemen, deren Entscheidungen und Handlungen nachvollziehbar und verständlich sind. Das ist besonders bei tiefen neuronalen Netzen wichtig, die oft als Black Boxes gelten, weil ihre internen Arbeitsweisen und Entscheidungsfindungsprozesse komplex und nicht transparent sind.
Die Erklärbarkeit solcher Netze ist aber entscheidend, um Vertrauen zu schaffen und Fehler zu beheben, gerade bei kritischen Anwendungen. Sie macht Systeme transparenter, was für ihre ethische Anwendung unerlässlich ist. (jcb)





