
© primopiano / 123RF.com
Datensätze mit vielen Attributen machen die Methoden der Dimensionsreduktion übersichtlicher und einfacher zu analysieren. Diverse Verfahren versuchen, die Anzahl der Attribute zu verringern, dabei aber die wichtigsten Merkmale zu erhalten.
In der Statistik und beim maschinellen Lernen bezeichnet man die Anzahl der Attribute eines Datensatzes auch als dessen Dimensionen. Ein Datensatz, der Farbe und Motorleistung eines Autos umfasst, weist zwei Dimensionen auf. Meist finden sich in Datensätzen allerdings sehr viel mehr Dimensionen. Das erweist sich bei der Datenanalyse, beim Visualisieren und beim Training von Modellen des maschinellen Lernens nicht selten als hinderlich.
Dimensionsreduktion bezeichnet einen Prozess, der die Anzahl der Attribute in einem Datensatz senkt und gleichzeitig so viel wie möglich von der ursprünglichen Information beibehält. Es handelt sich dabei um einen Verarbeitungsschritt, der typischerweise vor dem eigentlichen Training eines Modells beziehungsweise vor einer Datenanalyse oder Visualisierung abläuft.
Das maschinelle Lernen aus Datensätzen, die viele Attribute enthalten, führt zu extrem langsamen Trainingsprozessen, da in einem hochdimensionalen Datensatz die meisten Datenpunkte weit voneinander entfernt sind. Die Trainingsalgorithmen können unter diesen Bedingungen den hochdimensionalen Feature-Raum nicht effizient erkunden. In der Welt des Maschinenlernens heißt dieses Problem “Fluch der Dimensionalität”. Auch das Visualisieren von hochdimensionalen Daten oder das Erkennen von Trends funktionieren häufig nur nach einer Dimensionsreduktion.
Die Dimensionsreduktion versucht, eine den Daten innewohnende niedrigere Dimensionalität zu identifizieren und zu nutzen. Bei den beiden in einem zweidimensionalen Feature-Raum verteilten Datensätze aus Abbildung 1 erkennt man leicht, dass die Daten in beiden Beispielen größtenteils einer eindimensionalen Parametrisierung folgen. Eine Dimensionsreduktion sollte diese Dimension ebenfalls erkennen (in Abbildung 1 als Linien dargestellt).
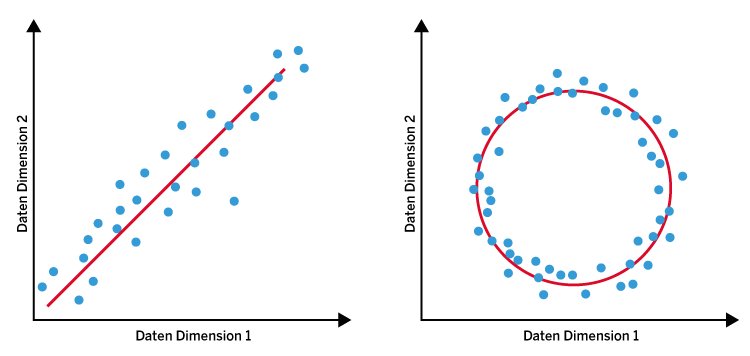
Abbildung 1: Jeder Punkt des Kreises ist gleich weit vom Mittelpunkt entfernt. Daher genügt der Radius, um einen Punkt auf dem Kreis zu bestimmen. Der Kreis hat also die Dimension 1, auf die sich die zweidimensionale Punktwolke (rechts) reduzieren lässt.
Alle Techniken zur Dimensionsreduktion basieren auf der impliziten Annahme, dass die Daten in einem hochdimensionalen Raum entlang einer niedrigdimensionalen Mannigfaltigkeit liegen. Genau darin besteht die Kernaufgabe der Dimensionsreduktion.
Zwei Wege
Es gibt hauptsächlich zwei Arten von Methoden zur Dimensionsreduktion (Abbildung 2). Beide erreichen ihr gemeinsames Ziel auf unterschiedlichen Wegen. Die erste Methode behält nur die wichtigsten Attribute im Datensatz bei und entfernt die überflüssigen Merkmale (Feature Selection). Die Daten beziehungsweise ihre Attribute transformiert sie dabei nicht. Die zweite Art findet eine Kombination der vorhandenen Attribute, die zu einer geringeren Anzahl neuer und effektiver Attribute führt (Feature Extraction). Dabei kombiniert sie die vorhandenen Attribute so, dass sich ein neuer Feature-Raum mit einer niedrigeren Dimension aufspannen lässt. Hier handelt es sich um eine Koordinatentransformation im Feature-Raum.
Solche Transformationen unterteilen sich in lineare und nicht lineare Abbildungen. Eine lineare Abbildung ist eine mathematische Transformation, bei der die Superpositionsregel gilt. Das bedeutet, dass die Summe zweier transformierter Vektoren der Transformation der Summe der ursprünglichen Vektoren entspricht. Solche Abbildungen lassen sich durch Matrizen darstellen und besitzen einfache mathematische Eigenschaften. Eine nicht lineare Abbildung dagegen erfüllt die Superpositionsregel nicht. Bei ihr fällt die Transformation komplexer aus, und sie lässt sich nicht einfach durch Matrizen oder lineare Gleichungen beschreiben. Eine solche Transformation kann verschiedene Formen und Strukturen aufweisen und ist nicht linear in Bezug auf die Eingangsdaten der Abbildung.
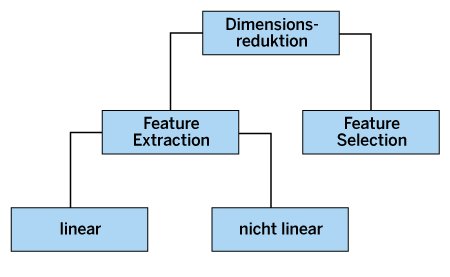
Abbildung 2: Feature Extraction und Feature Selection sind die beiden grundsätzlichen Methoden der Dimensionsreduktion.
Hauptkomponentenanalyse
Mit der Hauptkomponentenanalyse (Principal Component Analysis, PCA) gibt es eine einfache und weitverbreitete lineare Feature-Extraction-Methode. PCA projiziert als lineare Dimensionsreduktionsmethode einen Datensatz in einem D-dimensionalen Feature-Raum in einen d-dimensionalen Raum mit d < D. Dabei sollten die Basisvektoren des neuen Feature-Raums so gewählt sein, dass die Varianz der Daten entlang des ersten Basisvektors am größten ist, entlang des zweiten Basisvektors am zweitgrößten und so weiter. Zusätzlich sollen die Basisvektoren orthogonal aufeinander stehen.
Das PCA-Verfahren nimmt letztlich eine linear orthogonale Transformation der Daten vor, wie Abbildung 3 exemplarisch zeigt. Das Ursprungskoordinatensystem wird hier durch eine Drehung in das PCA-Koordinatensystem übertragen. Das Beispiel ist stark vereinfacht, da es sich lediglich um einen zweidimensionalen Feature-Raum handelt. Im Allgemeinen liegen deutlich höherdimensionale Feature-Räume vor, die sich nicht visualisieren lassen.
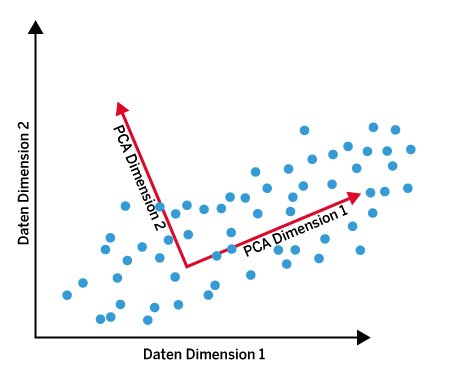
Abbildung 3: Das PCA-Koordinatensystem entsteht durch Rotation des ursprünglichen Koordinatensystems. Wenn Sie danach nur noch die Varianz der Daten entlang der ersten PCA-Dimension betrachten, haben Sie die Dimensionalität reduziert.
Im Beispiel zeigt sich, dass die Varianz der Daten entlang der ersten PCA-Dimension deutlich größer ausfällt als entlang der zweiten PCA-Dimension. Zudem sind die Daten im Zielraum unkorreliert, während im Ursprungsraum eine positive Korrelation der beiden Attribute vorliegt. Im Rahmen einer Dimensionsreduktion könnten Sie hier also nur die Varianz der Daten entlang der ersten PCA-Dimension betrachten. Damit würde der ursprünglich zweidimensionale Feature-Raum auf einen effektiv eindimensionalen Raum reduziert, wodurch sich die Analyse und Verarbeitung entsprechend vereinfachen.
Die Eingabedaten des PCA-Algorithmus bildet ein Datensatz mit N Daten in einem D-dimensionalen Feature-Raum, das heißt die einzelnen Feature-Vektoren haben D Attribute. Da es sich bei der PCA um eine lineare Transformation handelt, lässt sich die Abbildung in den d-dimensionalen Raum in Form einer Matrix-Vektor-Multiplikation darstellen. Konkret beschreibt der PCA-Algorithmus, wie die zugehörige Transformationsmatrix bestimmt werden muss. Dazu gilt es, die Kovarianzmatrix der ursprünglichen D-dimensionalen Daten zu berechnen:
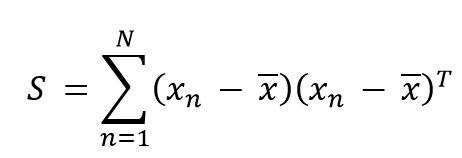
Die Summe läuft in dieser Gleichung über alle Feature-Vektoren des Datensatzes, wobei von jedem Vektor zunächst der Mittelwert abzuziehen ist. Anschließend gilt es, das dyadische Produkt zu berechnen. Das Ergebnis ist eine symmetrische DxD-Matrix. Die Elemente auf der Hauptdiagonalen der Kovarianzmatrix bilden die jeweiligen Varianzen ab, alle übrigen Elemente Kovarianzen.
Die Forderung nach möglichst geringer Korrelation und maximaler Varianz der neuen Feature-Vektoren müssen Sie durch eine passende Wahl der Transformationsmatrix gewährleisten. Mathematisch lässt sich zeigen, dass die Einträge der Transformationsmatrix aus Eigenvektoren der Kovarianzmatrix bestehen müssen: Sie spannen den Hauptachsenellipsoiden der Daten auf. Die Eigenvektoren bestimmen Sie als Lösungen der sogenannten Eigenwertgleichung:
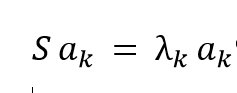
Die Besonderheit von Eigenvektoren besteht demnach darin, dass sich die Matrix-Vektor-Multiplikation zwischen S-Matrix und Eigenvektor als Skalarmultiplikation zwischen Eigenwert und Eigenvektor darstellen lässt. Die Lösung der Eigenwertgleichungen gehört zu den Standardproblemen der linearen Algebra, wofür zahlreiche numerische Implementationen beispielsweise in der SciPy-Bibliothek von Python bereitstehen. Damit lassen sich die Eigenwerte und die zugehörigen Eigenvektoren der NxN-S-Matrix berechnen.
Nun kann man die Transformationsmatrix aus den Eigenvektoren zusammensetzen. Das erfordert im ersten Schritt eine Sortierung der Eigenvektoren in absteigender Folge der Eigenwerte. Die zu den d größten Eigenwerten gehörenden Eigenvektoren ziehen Sie dann heran, um die Transformationsmatrix zu bestimmen, da diese Richtungen den Dimensionen mit der größten Varianz entsprechen. Konkret bilden diese Eigenvektoren die d Zeilenvektoren der dxD-dimensionalen Transformationsmatrix.
In einem letzten Schritt multiplizieren Sie die ursprünglichen Feature-Vektoren der Daten mit der so erhaltenen Transformationsmatrix. Dadurch entstehen N neue Feature-Vektoren in einem d-dimensionalen Feature-Raum. Die lineare Transformation auf den d-dimensionalen Feature-Raum ist damit abgeschlossen, und die Daten wurden effektiv in einen niedrigerdimensionalen Raum projiziert.
Rekonstruktionsfehler
Allgemein lassen sich Feature-Extraction-Methoden durch eine funktionale Abbildung von einem D– in einen d-dimensionalen Raum folgendermaßen beschreiben:
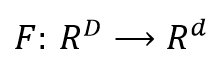
Hinter jeder Feature-Extraction-Methode steckt also eine Funktion, die den D-dimensionalen Ursprungs-Feature-Raum auf einen d-dimensionalen latenten Ziel-Feature-Raum abbildet, wobei d < D gilt. Die Funktion F ist hierbei im Prinzip beliebig. Bei der PCA-Methode handelt es sich bei F um eine lineare Funktion und damit um einen Spezialfall.
Selbstverständlich sollten Sie die Abbildung F so wählen, dass die Information im Ursprungs-Feature-Raum beim Übergang in den latenten Ziel-Feature-Raum möglichst vollständig erhalten bleibt. Anders ausgedrückt, sollte der Übergang von Ursprungs- zu Ziel-Raum und wieder zurück einen möglichst kleinen Rekonstruktionsfehler aufweisen:
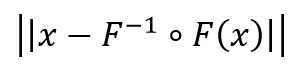
Dabei ist F-1 die inverse Funktion zu F.
Der Rekonstruktionsfehler hängt von der gewählten Funktion F ab. Mathematisch lässt sich zeigen, dass das lineare PCA-Verfahren den kleinsten Rekonstruktionsfehler unter allen linearen Feature-Extraction-Verfahren besitzt. In dieser bemerkenswerten Eigenschaft der Hauptkomponentenanalyse liegt der Grund für die Beliebtheit des Verfahrens, das sich zudem aufgrund der Linearität algorithmisch einfach und effizient implementieren lässt. Es bietet aber zugleich den Vorteil eines kleinen Rekonstruktionsfehlers, genauer gesagt sogar des minimalen Fehlers unter allen denkbaren linearen Verfahren.
Nicht linear
Die Funktion F muss nicht zwangsläufig linear sein. Es gibt unendlich viele Funktionen, die Sie hier einsetzen können. Allerdings existieren ebenso unendlich viele Funktionen, die bei der Dimensionsreduktion nichts nützen.
So ergibt die Identität F(x) = x nur wenig Sinn, da Ursprungs- und Zielraum dann übereinstimmen. Ebenso erweist es sich als unsinnig, wenn die Funktion F sämtliche Eingabedaten auf 0 abbildet. Der Zielraum hat so zwar die kleinstmögliche Dimension, aber gleichzeitig gehen bei dieser Abbildung alle Daten und damit die gesamte Information der ursprünglichen Daten verloren.
Die PCA-Methode ist aufgrund des minimalen Rekonstruktionsfehlers bereits die optimale lineare Feature-Extraction-Methode. Allerdings darf F auch eine nichtlineare Funktion sein. Derartige Funktionen lassen sich nicht durch eine Matrix-Vektor-Multiplikation darstellen.
Im maschinellen Lernen zur nicht linearen Dimensionsreduktion kommt oft die Kernel-Principal-Component-Analyse (KPCA) zum Einsatz, eine Erweiterung des klassischen Algorithmus der Hauptkomponentenanalyse (PCA). Sie hilft dann weiter, wenn eine lineare Transformation die Dimensionalität der Daten nicht vernünftig reduzieren kann, weil sich die Daten nicht linear verteilen.
In Abbildung 2 weisen die Datenpunkte im rechten Beispiel eine solche nicht lineare Verteilung auf. Sie liegen auf einem eindimensionalen Kreis, also einer klar nicht linearen Struktur. Eine Dimensionsreduktionsmethode sollte das erkennen, eine linear orthogonale Transformation kann das allerdings nicht. So ist es beispielsweise nicht möglich, das Koordinatensystem wie bei einer linearen PCA einfach zu rotieren, um eine bessere Darstellung der Daten zu finden. Bei einem Kreis ergibt es mehr Sinn, eine nicht lineare Transformation von kartesischen Koordinaten (x,y) in polare Koordinaten (Radius, Winkel) vorzunehmen. Folgende zwei Gleichungen beschreiben diese Transformation:
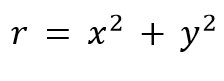
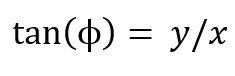
Bei den hier auftretenden trigonometrischen Funktionen und Polynomen handelt es sich um nicht lineare Funktionen, sodass die gesamte Abbildung nicht linear ist.
Abbildung 4 zeigt die Transformation. In der polaren Darstellung liegen die Daten nun entlang einer geraden Linie, sodass Sie darauf in einem zweiten Schritt eine gewöhnliche lineare PCA anwenden können. Die KPCA-Methode wendet allgemein eine nicht lineare Abbildungsfunktion auf die Daten an, bevor die PCA stattfindet. Dadurch lassen sich komplexere und nicht lineare Beziehungen zwischen den Datenpunkten erfassen.
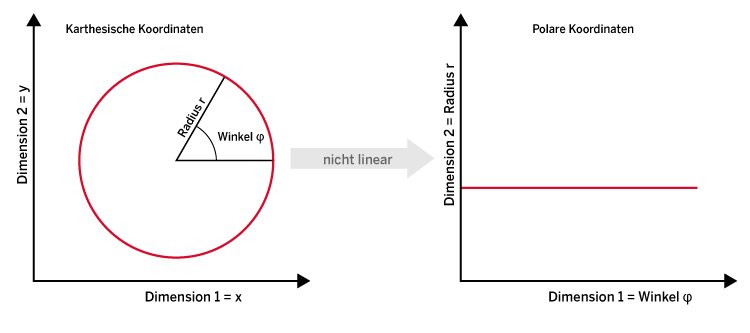
Abbildung 4: Eine nicht lineare Transformation von einem kartesischen Koordinatensystem in eines mit Polar-Koordinaten.
Der Name KPCA rührt daher, dass man Methode der nicht linearen Transformation mitunter Kernel-Methode nennt. Sie findet sich auch bei anderen Methoden des maschinellen Lernens wie Support-Vektor-Maschinen. Als Kernel bezeichnet man das innere Produkt aus der nicht linearen Koordinatentransformation, das in der mathematischen Formulierung der KPCA-Methode vorkommt.
Fazit
Dimensionsreduktionsmethoden, insbesondere PCA und KPCA, sowie Feature-Selection-Techniken kommt eine entscheidende Bedeutung beim Umgang mit hochdimensionalen Daten zu.
PCA, eine lineare Methode, ermöglicht die Transformation von Daten in einen Raum, in dem die Hauptkomponenten die größte Varianz aufweisen. PCA ist allerdings nicht in der Lage, nicht lineare Beziehungen in den Daten zu erfassen. Deswegen sollten Sie nur vorsichtig Gebrauch davon machen. Im Gegensatz dazu eröffnet KPCA die Möglichkeit, nicht lineare Dimensionsreduktion zu erreichen. Das macht KPCA besonders wertvoll in Anwendungen, in denen die Beziehungen zwischen Merkmalen komplex ausfallen.
Zusätzlich zu diesen Feature-Extraction-Methoden spielen Feature-Selection-Techniken eine entscheidende Rolle. Die Methoden helfen, die wichtigsten Attribute auszuwählen, was dazu beitragen kann, den Datenraum effizienter zu gestalten und gleichzeitig die Interpretierbarkeit der Modelle zu verbessern.
Die Wahl zwischen PCA, KPCA und Feature Selection hängt von unterschiedlichen Faktoren ab, etwa von der Beschaffenheit der Daten, den Datenanalysezielen und den zur Verfügung stehenden Rechenressourcen. Es gibt keine universelle Methode, die sich für alle Szenarien eignet. Stattdessen erfordert die effektive Dimensionsreduktion eine sorgfältige Betrachtung der spezifischen Anforderungen und Gegebenheiten jedes Projekts. (jcb)





