
© Nattana Srisut / 123RF.com
Serverless Workloads erleichtern Entwicklern und Admins die Arbeit, indem sie den Betrieb von Infrastrukturressourcen an einen Plattformbetreiber auslagern. KNative überträgt das Prinzip auf Kubernetes und liefert alle Container-Komponenten für die Konstruktion von Serverless-Anwendungen, PaaS und FaaS.
Ein häufiges Bonmot am Stammtisch gestandener Admins lautet: “Wir betreiben die Server, die Sie brauchen, um serverless sein zu können.” Doch wer sich über das Konzept des Serverless Computing lustig macht, unterschätzt, welchen großen Einfluss es tatsächlich hat. Wäre Serverless ein Hirngespinst, investierte etwa AWS nicht riesige Summen in die Entwicklung immer neuer As-a-Service-Angebote, die der eigenen Klientel den Betrieb und die Wartung von IT-Ressourcen erleichtern. Nicht zuletzt im Kontext der Orchestrierung hat Serverless Computing zudem heute einen festen Platz: Wer eine Datenbank für die eigene virtuelle Umgebung über drei Zeilen in einem Template anlegen kann, erspart sich Dutzende Zeilen Code, wenn nicht Hunderte, und erzielt letztlich fast immer ein besseres Ergebnis als zu Fuß.
Blickt man auf den unangefochtenen Star der Container-Szene und dessen Serverless-Fähigkeiten, ist man im ersten Augenblick allerdings etwas enttäuscht: In diesem Bereich schlägt sich Kubernetes ab Werk gar nicht so gut. Das leuchtet auch durchaus ein: Schließlich versteht sich K8s als Orchestrierer für Container-Workloads über die Grenzen einzelner Compute-Knoten hinweg. Das Stichwort an dieser Stelle ist Orchestrierer: Kubernetes will bestehende Container verwalten und sieht exakt darin seine Stärken. Passende Workloads zu erstellen, betrachtet es eher nicht als seinen Job.
Das hat aus Anwendersicht zum Teil verheerende Folgen: Wer auf die K8s Landscape der Cloud Native Computing Foundation (CNCF) schaut, findet dort zahllose Lösungen, aus denen man sich das eigene Setup irgendwie kompilieren soll. CI/CD-Werkzeuge, die das Erstellen von Serverless Workloads für Kubernetes ermöglichen, gibt es dabei etliche. Trotzdem gestaltet sich der Kubernetes quasi aufgepfropfte Betrieb von externen Ressourcen für den Serverless-Betrieb oft holprig.
KNative nennt sich das Projekt sowie das Werkzeug, das genau das ändern will. Das K in KNative steht dabei – man ahnt es – für Kubernetes; es geht also um die native Integration von Workloads in K8s. Wie etliche Komponenten aus dem Kubernetes-Universum gibt KNative sich für Neulinge dabei nicht sonderlich offen oder flexibel. Wer allerdings im FaaS- oder PaaS-Umfeld unterwegs ist, dem kommen die Vorteile des Betriebs von Serverless Workloads mit KNative zugute. Dieser Artikel bietet deshalb eine Einführung in KNative inklusive der Erklärung der wichtigsten Begriffe und Einrichtungen.
Aller Anfang
Wer mit Serverless Computing oder KNative noch nicht viel zu tun hatte, sitzt am Anfang mit einiger Wahrscheinlichkeit eher verwirrt vor der KNative-Dokumentation. Die liest sich zum Teil wie von einer Marketing-Abteilung geschrieben: Serverless hier, Cloud Native dort. Viel Wortgeklingel also, das gerade erfahrenen Administratoren klassischer Workloads eher Sorgen macht als Zuversicht einflößt.
Tatsächlich empfiehlt es sich, ein paar Begriffe klar zu definieren, bevor man sich in das Abenteuer KNative stürzt. Wie andere Lösungen auch leidet KNative mittlerweile stark darunter, dass Begriffe wie Serverless oder Cloud Native zwar überall und ständig genutzt werden, aber entweder gar nicht definiert sind oder die vorhandene zentrale Definition niemanden schert. Was es mit Serverless auf sich hat, hat der Artikel ja eingangs schon beschrieben: Gemeint ist, auf Dienste wie Datenbanken oder Load Balancer zugreifen zu können, ohne den klassischen Weg einer virtuellen Instanz mit entsprechend darin installiertem Dienst und entsprechender Konfiguration zu gehen.
Was aus Sicht des Profi-Admins nach Kinkerlitzchen klingt, ist für Entwickler ein Faktor größter Bedeutung: Wenn der Entwickler sich über eine standardisierte API eine Datenbank zusammenklicken kann, um deren Wartung er sich hinterher nicht mehr kümmern muss, ist das für ihn ein großer Vorteil. Der Hauptgedanke hinter Serverless Computing besteht also darin, Faktoren wie Hardware und Betriebssysteme sowie deren Wartung vor den Augen des Anwenders einer Umgebung zu verstecken. Stattdessen erledigen diese Aufgaben die Plattformbetreiber, die sich dafür eigene Werkzeuge bauen und spezifische Prozesse für diese Aufgaben vorhalten.
Im KNative-Kontext ergeben sich aber noch ein paar weitere Fachbegriffe, die der Klärung bedürfen. Die sind besonders für jene Administratoren interessant, die mit Kubernetes noch nicht jeden Tag zu tun haben. Sie hängen unmittelbar mit der Art und Weise zusammen, wie Kubernetes Ressourcen verwaltet und wie KNative sich in diese Symphonie integriert. Einer dieser Begriffe heißt Custom Resource Definition oder kurz CRD. K8s selbst steuert ein Administrator oder Entwickler bekanntlich mittels einer ReST-API. Befehle an Kubernetes gehen also immer im HTTP-Format vom Client zum Server.
Kubernetes selbst hantiert intern mit Objekten, und ein Objekttyp sind Ressourcen. Bei Kubernetes umfasst das ab Werk Container, Pods, virtuelle IP-Adressen und andere Einrichtungen. Custom Resource Definitions sind eine Brücke hin zu externen Anwendungen: Sie erlauben es Entwicklern und Admins, eigene Ressourcentypen in Kubernetes anzulegen, die sich hinterher ebenso wie jene nutzen und verwalten lassen, die ab Werk zu K8s gehören. KNative macht von CRDs beinahe schon exzessiven Gebrauch, denn es erweitert einen bestehenden Kubernetes-Cluster um etliche CRDs, die KNative-spezifische Ressourcen auf der Ebene des K8s-Clusters etablieren.
KNative nutzt CRDs also als Andockpunkt beim Container-Orchestrierer. Das ist auch absolut notwendig: Nur so kann KNative nämlich das eigene Versprechen erfüllen, der Betrieb von Serverless-Anwendungen sei der Betrieb von First Class Citizens in K8s. Unter First Class Citizen versteht man in der Cloud-Native-Welt Ressourcen, die sich über die ohnehin vorhandene API des Orchestrierers oder Flottenmanagers vollständig steuern lassen.
Zwei Funktionen
Sucht man im Netz nach KNative, stößt man regelmäßig auf ältere Dokumentationen und Vorträge, die drei Kernkomponenten von KNative beschreiben: Serving, Eventing und Building. Hier ist jedoch Vorsicht geboten. Die Building-Komponente zählt mittlerweile nicht mehr zu KNative. Sie wird stattdessen unter dem Namen Tekton Pipelines als eigenständiges Projekt fortgeführt, zum Teil unter Beteiligung anderer Entwickler. KNative hat sich sozusagen auf seine Wurzeln besonnen und besteht nun noch aus den Serving- und Eventing-Teilen. Auf Tekton geht dieser Text später noch etwas ausführlicher ein. Im Augenblick jedoch soll KNative im Mittelpunkt stehen, denn dessen Verständnis ist für den Anfang kompliziert genug. Um hinter das KNative-Konzept zu steigen, hilft es, sich die grundlegenden Aufgaben zu vergegenwärtigen, die KNative aus Sicht des Entwicklers leisten soll.
Am Anfang aller Überlegungen steht dabei wie üblich der Begriff der App. Auch der Betrieb von Serverless-Anwendungen in KNative zielt letztlich darauf ab, eine bestimmte Anwendung (App) automatisiert und ohne externes Eingreifen auszurollen und zu betreiben. Eine App kann allerdings aus mehreren Diensten bestehen, sodass KNative intern den Begriff Services nutzt, der eher einer Funktion als einem bestimmten Dienst entspricht. Ein Service ist in einem um KNative erweiterten K8s-Cluster ein zentrales Objekt: Von ihm hängen alle anderen innerhalb von Kubernetes anzulegenden Ressourcen ab, die sicherstellen, dass ein Dienst die von ihm erwartete Aufgabe gut erledigen kann. Bei MariaDB etwa wäre zum Beispiel der Service die laufende Instanz von »mysqld« – nicht, weil sie ein einzelner Prozess ist, sondern weil eben dieser Dienst die zentrale Funktion der Datenbank erfüllt. Es können durchaus mehrere Prozesse nötig sein, um als Teil eines Gesamtgefüges eine Funktion zu erbringen.
An einem Service hängen üblicherweise mehrere Ressourcen, im Normalfall zumindest eine Route sowie eine dienstespezifische Konfiguration. Die Route ist dabei ein Verweis auf das Element eines virtuellen Netzwerks, über das sich die eigentliche Funktion erreichen lässt. Neben Services, Routen und Konfigurationen gibt es zudem einen vierten Ressourcentyp in KNative, nämlich die Revision. Sie bezeichnet eine spezifische Konfiguration aus Dienst, Route und Konfiguration und kann nicht nur einmal pro Serverless-Dienst vorkommen, sondern beliebig oft. Bei einer Revision handelt es sich um eine Art statisches Mapping auf die Kombination aus den drei zuvor genannten Faktoren.
Stellt man sich die vier zur Serving-Komponente (Abbildung 1) gehörenden Aspekte vor, entsteht schnell ein valides Gesamtbild: Der Begriff Services beschreibt logische Funktionen von KNative in Kubernetes, die sich um die Verwaltung des gesamten Lifecycles einer Anwendung kümmern. Die Services-Komponente legt also alle für ein virtuelles Setup benötigten Dienste an, versorgt sie mit einer validen Route sowie Konfiguration und legt dafür in der eigenen Datenbank auch eine Revision an. Wie die für den Service benötigten Teile zusammenkommen, entscheidet der Administrator oder Entwickler per Konfiguration: Er kann über KNative Konfigurationen hinterlegen und Routen definieren oder stattdessen festlegen, dass KNative sich die bestmögliche Route für den Zugriff auf ein Netzwerkelement selbst suchen soll.
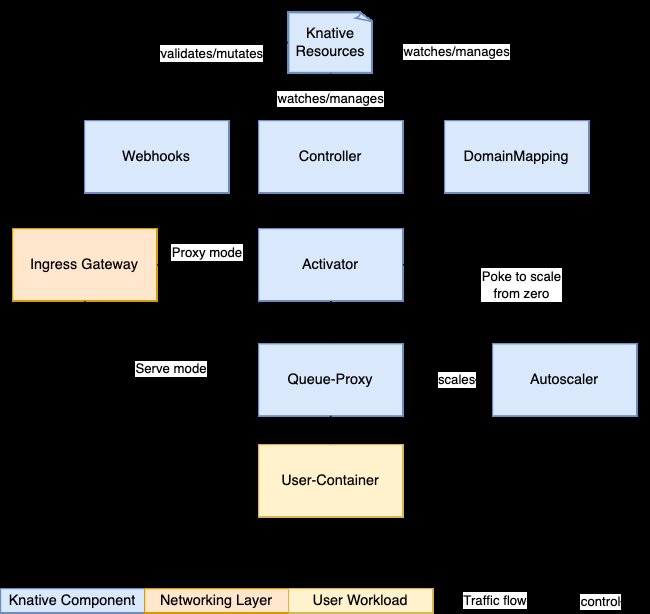
Abbildung 1: KNative Serving nimmt einen fertigen Container und rollt diesen zusammen mit allen benötigten Diensten aus. Dazu bringt es etliche eigene Infrastruktur-Dienste mit, wie ein Ingress-Gateway. Quelle: KNative
An dieser Stelle tritt KNative indirekt auch in Konkurrenz zu anderen Lösungen wie Istio und Konsorten, die zwar Kubernetes-native Ressourcen verwenden, einen Teil der Aufgaben aber dann doch wieder an K8s vorbei abwickeln.
Auch Events zählen
Die andere große Teilkomponente von KNative beschäftigt sich weniger mit dem Was und dem Wie, sondern viel mehr mit dem Wann. Hier gilt es erneut, sich zunächst mit einem Fachbegriff zu beschäftigen, nämlich jenem der ereignisgetriebenen Architektur (Event-driven Architecture). In der Informationstechnologie versteht man darunter einen Architekturansatz in der Softwareentwicklung, der einem Ereignis A innerhalb einer Umgebung eine Reaktion B folgen lässt. Vereinfacht ausgedrückt beruht eine Event-basierte Architektur in Kubernetes auf dem Prinzip, dass Änderungen an bestehenden Ressourcen (oder die Erstellung neuer Ressourcen) automatisch andere Aktionen auslösen. Sie werden als Ereignis erkannt, auf das eine übergeordnete Instanz entsprechend reagiert. In unserem Beispiel ist die übergeordnete Instanz KNative Eventing. Für das Übermitteln von Ereignissen im Cloud-nativen Kontext gibt es sogar einen eigenen Standard namens CloudEvents, den die CNCF unter ihren Fittichen hat.
Eine funktionale Eventing-Architektur erfordert einen Sender sowie einen Empfänger des Events. Vereinfacht ausgedrückt muss das laufende Setup also eine Benachrichtigung versenden, wenn sich etwas an seinem Zustand ändert, und eine andere Komponente muss das Ereignis empfangen und daraufhin Maßnahmen einleiten. Im Kontext Event-basierter Architekturen spricht man dabei auch von einem Agenten, der Ereignisse ausgibt sowie einem Sink, das die Ereignisse empfängt und passend reagiert. Wieder gilt, dass KNative Eventing ausschließlich innerhalb von Kubernetes arbeitet und keine externen Ressourcen benötigt. Wie KNative Serving erweitert Eventing dabei die Kubernetes-API um etliche CRDs, die sich anschließend aus laufenden Programmen heraus verwenden lassen.
Aus der Praxis
Damit wären die Hintergründe und Funktionsweisen von KNative grundsätzlich beschrieben. Wer in der Cloud-native-Welt nicht zu Hause ist, dem erschließen sich die zentralen Konzepte der Lösung aber möglicherweise noch immer nicht vollständig. Ein paar praktische Beispiele sollen dabei helfen, die Ideen hinter KNative insgesamt besser zu verstehen. Praktischerweise stellen die KNative-Entwickler etliche Beispiele für verschiedene Funktionen auf ihrer Website zur Verfügung [1], sodass Interessierte nicht lange suchen müssen. Eines dieser Beispiele ist eines der gängigsten aus der Entwicklerwelt überhaupt, nämlich ein Webserver, der “Hello World” ausgibt [2].
Das Beispiel besteht aus zwei Komponenten und ist in Go geschrieben. Die Datei »helloworld.go« enthält den eigentlichen Dienst, der auf Port 80 lauscht und in HTTP-kompatibler Form “Hello World” ausgibt (Abbildung 2), sobald jemand den Dienst kontaktiert. Viel wichtiger als diese Datei allerdings ist die Service-Definition »service.yaml« für KNative, denn sie macht die Anwendung für KNative überhaupt erst konsumierbar (Listing 1).
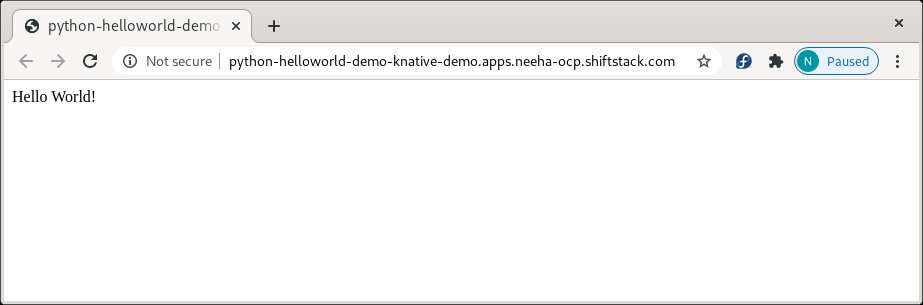
Abbildung 2: Das “Hello-World”-Beispiel kratzt zwar nur an der Oberfläche dessen, was KNative leistet. Die Pod-Definition für den Dienst ist trotzdem schon deutlich einfacher als dieselben Schritte zu Fuß in Kubernetes. Quelle: Neeharika Kompala / GitConnected
Listing 1
service.yaml für “Hello World”
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: default
spec:
template:
spec:
containers:
- image: docker.io/{username}/helloworld-go
env:
- name: TARGET
value: "Go Sample v1"
Wer schon einmal zumindest mit Code-Snippets für Kubernetes zu tun hatte, sieht schnell, worum es geht: Zunächst nutzt das Codebeispiel die KNative-Ressource »serving.knative.dev«, um einen Dienst des Namens »helloworld-go« im Default-Namespace anzulegen. Die Spezifikation des Diensts besagt, dass das Image »helloworld-go« von »docker.io« (also vom Docker-Hub) zum Einsatz kommt, um den Dienst zu betreiben. Weiter wird noch die Umgebungsvariable »TARGET« mit dem Inhalt »Go Sample v1« eingerichtet.
Wendet man diese Datei auf Kubernetes mit KNative an, startet Letzteres den entsprechenden Container in einem Pod durch K8s hindurch und sorgt dafür, dass er von außen erreichbar ist. Hier wird auch deutlich, warum KNative sich als Lösung für den Betrieb von Serverless-Architekturen versteht: Viele der Parameter, die der Administrator in Kubernetes für einen normalen Container ohne KNative-Unterstützung angeben müsste, implementiert KNative selbst und auf eigene Faust ohne Zutun des Anwenders. Der kann sich auf seine Anwendung konzentrieren, ohne sich mit den Details von Kubernetes oder dem Betrieb von Containern darin zu befassen. Das gilt auch für betriebliche Aufgaben: Ab Werk etwa skaliert KNative den Pod je nach eingehender Last so weit hoch oder herunter, dass angemessen viele oder gar keine Instanzen des jeweiligen Pods laufen. Das Verhalten beim Skalieren lässt sich dabei vollständig vorgeben.
Ein zweites Beispiel zeigt, wie sich Events in KNative abfangen und verarbeiten lassen (Abbildung 3). Dabei steht die gesamte Fülle der KNative-Funktionen zur Verfügung, etwa das automatische Skalieren in die Breite oder das spezifische Routing zwischen K8s und Dienst bis hin zur Verwendung externer Routing-Dienste.
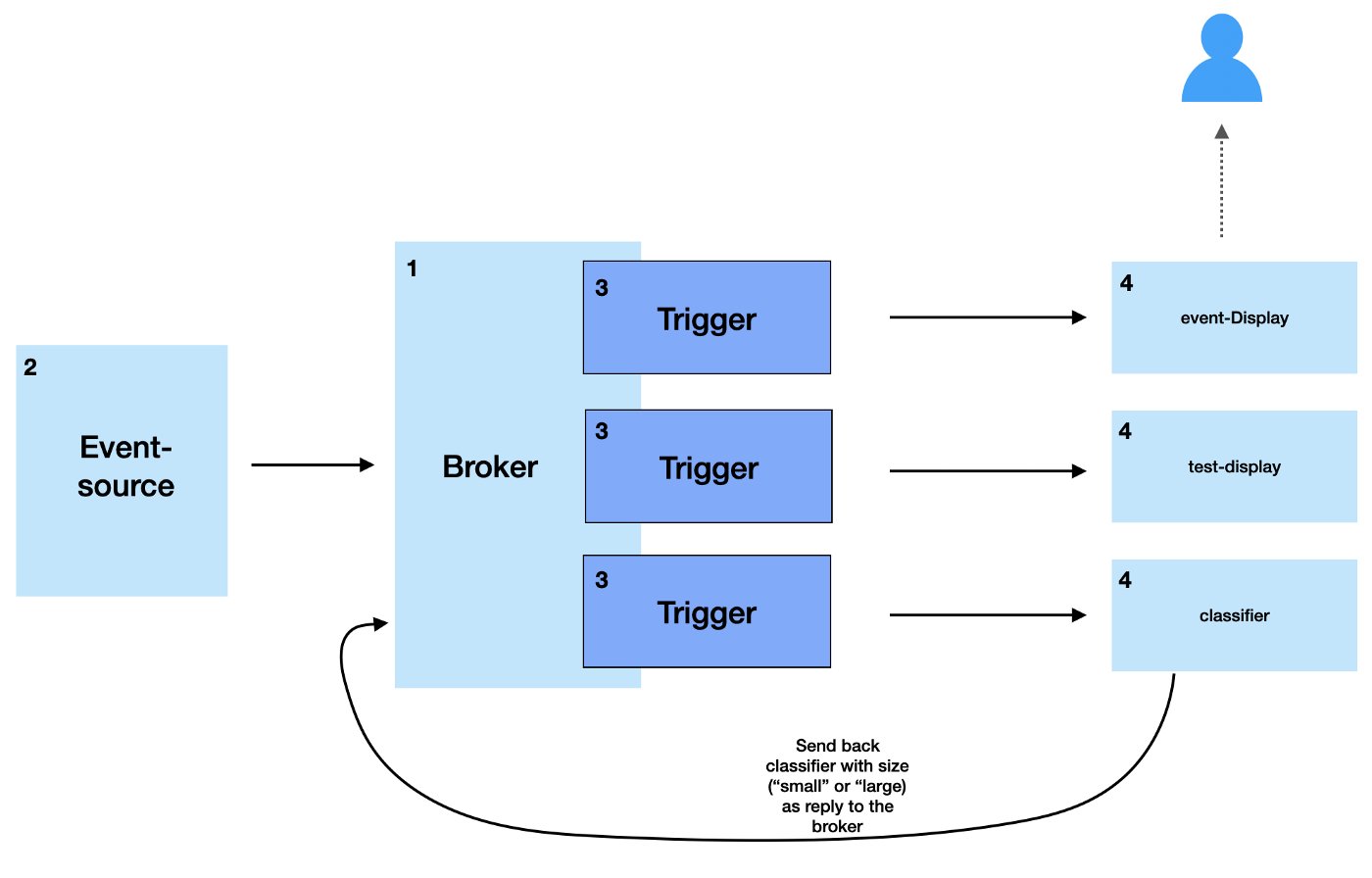
Abbildung 3: KNative Serving bietet einen Broker-Dienst für Events, der eingehende Events als Sink empfängt und an definierte Ziele weiterleitet. Entwickler können auf diese Weise ein System aus Ereignissen und Reaktionen in ihren Diensten bauen. Quelle: KNative
Das Standard-Beispiel ist allerdings etwas einfacher gestrickt. Es basiert wieder auf Go und implementiert einen HTTP-Dienst, der einen Port öffnet und dort auf eingehende Nachrichten wartet. Die Implementation dient rein akademischen Zwecken und denkt deshalb um die Ecke: Schickt man dem laufenden Dienst aus eben diesem Beispiel einen Namen im Body eines HTTP-Requests, bekommt man ein »>Hallo Name« zurück, aber – und das ist der springende Punkt – nicht, weil der Dienst selbst über eine Funktion entsprechend antwortet. Stattdessen löst eine Anfrage an den beschriebenen Dienst ein Event in der KNative-API aus, die das Werkzeug zu einem eigens definierten Sink durchreicht. Als Sink dient im Beispiel die laufende Anwendung selbst. Die reagiert dann auf codeseitig, indem sie beim Empfang eines KNative-Events eben mit dem entsprechenden HTTP-Body wie beschrieben ein “Hallo” zurückschickt.
Der springende Punkt ist dabei die Integration von Event-Agent und Event-Sink in Kubernetes selbst. K8s fehlt die gesamte Infrastruktur für das Management von Events – die stellt stattdessen KNative zur Verfügung. Das Beispiel aus Listing 2 zeigt die komplette Umsetzung für den Beispieldienst.
Listing 2
service.yaml für Dienste
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: cloudevents-go
namespace: default
spec:
template:
spec:
containers:
- image: ko://github.com/knative/docs/code-samples/serving/cloudevents/cloudevents-go
- name: K_SINK
value: http://default-broker.default.svc.cluster.local
Diese beiden Exempel demonstrieren freilich nicht annähernd die Leistungsfähigkeit, die KNative mit seinen Funktionen bietet. Das Projekt listet in seiner Dokumentation noch etliche weitere Beispiele auf, die sowohl den Code zur Integration in Kubernetes als auch den eigentlichen Anwendungscode enthalten. Das vermittelt Entwicklern einen besseren Eindruck von den Fähigkeiten der Lösung. Es finden sich auch konkrete Beispiele für das automatische Skalieren von Anwendungen.
Durchaus bemerkenswert ist obendrein, dass KNative alle benötigten Funktionen auf Basis von Kubernetes-Bordmitteln selbst implementiert. Autoscaling etwa setzt ausschließlich auf grundlegende Features, die Kubernetes ohnehin mitbringt. Wer KNative mit externen Erweiterungen wie Istio verwenden möchte, weil er die schon kennt, findet im Netz Anleitungen, die diesen Vorgang beschreiben. KNative ist extrem leistungsstark, aber auch sehr kontaktfreudig mit internen wie externen Lösungen.
Nicht unerwähnt bleiben soll an dieser Stelle, dass KNative für den eigenen Betrieb in einem laufenden K8s-Cluster etliche eigene Dienste startet. Eine zentrale Rolle dabei spielt der Activator, der über KNative-CRDs die meisten Anfragen entgegennimmt und so etwas wie die zentrale Vermittlungsstelle darstellt (Abbildung 4).
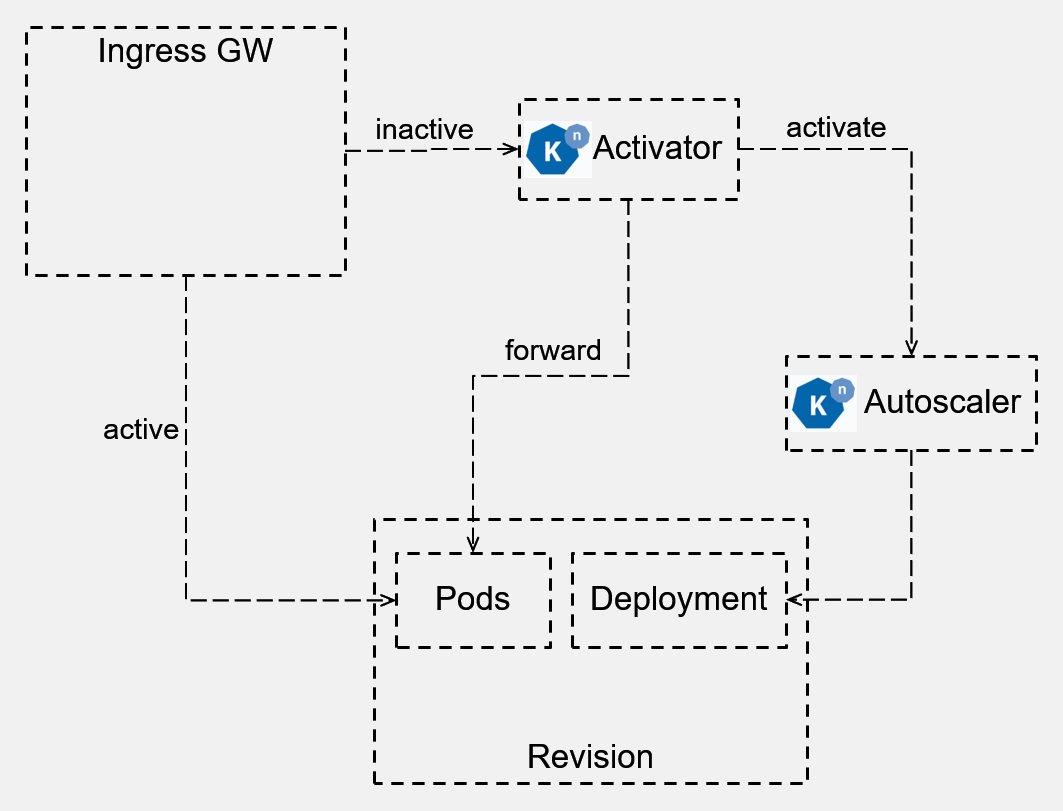
Abbildung 4: Der Activator spielt in KNative eine entscheidende Rolle. Er nimmt die meisten eingehenden Befehle entgegen und verarbeitet sie oder leitet sie an die zuständigen Dienste von KNative weiter. Quelle: KNative
Der abtrünnige Sohn
Wie eingangs erwähnt bestand KNative ursprünglich aus drei Komponenten: Serving, Eventing und Building. Die Building-Komponente allerdings stand von Anfang an quasi etwas außerhalb. Stets haben die KNative-Entwickler gedanklich zwischen dem Betrieb von Anwendungen und dem Bauprozess unterschieden. Das ist logisch nachvollziehbar und in der Sache völlig korrekt: Während die Serving- und Eventing-Schichten von KNative losgelöst voneinander nicht zu verwenden sind, spielt es für KNative selbst im Grunde keine Rolle, auf welchem Weg und mittels welcher Methode die zu betreibenden Artefakte entstehen. Vor einiger Zeit machte man dann Nägel mit Köpfen und lagerte die Building-Komponente in ein eigenes Projekt aus, das seither unter dem Namen Tekton firmiert.
Seine Verwandtschaft mit KNative kann Tekton bis heute allerdings nicht so recht verhehlen. Unter der Haube ist die Komponente architektonisch ähnlich aufgebaut wie das Serving und Eventing aus KNative. Wie KNative erweitert Tekton einen bestehenden Kubernetes-Cluster um etliche CRDs, die speziell für das Erstellen und Bauen von Anwendungen dienen. Damit man der Konkurrenz in Sachen Marketing nicht nachsteht, beschreiben die Tekton-Entwickler diese Integration mittlerweile als CI/CD-Pipeline für Cloud-native Umgebungen.
Im Fokus stehen noch immer Serverless-Anwendungen. Mittlerweile lässt Tekton sich aber auch hervorragend dazu verwenden, andere Anwendungen innerhalb von Kubernetes zu erstellen. Dazu setzt es auf Pipelines, die es in K8s selbst anlegt und konfiguriert (Abbildung 5). ArgoCD beispielsweise ist eigentlich ein eigenes CI/CD-System und hat mit Tekton nicht viel zu tun. Mittlerweile lassen sich das Tool und Tekton aber im Gespann verwenden, um in ArgoCD erstellte Artefakte direkt in Kubernetes zu integrieren.
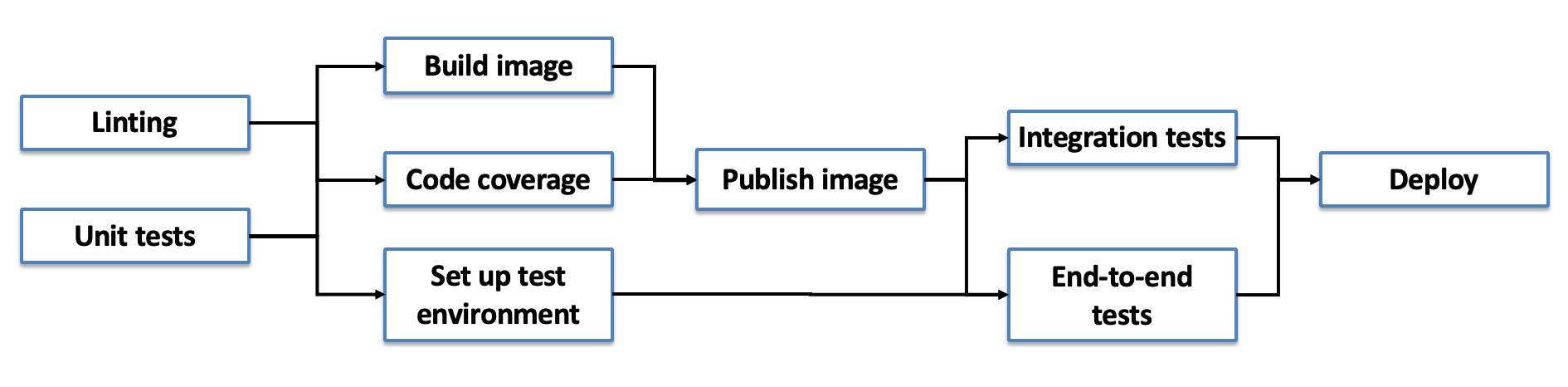
Abbildung 5: Tekton implementiert auf der Ebene der K8s-APIs Pipelines und die Infrastruktur, um Anwendungsabbilder für den Betrieb in Kubernetes zu bauen. Quelle: IBM
Kommt dann noch KNative hinzu, erlaubt das die üblichen Tricks und Spielereien, etwa ein auf Zuruf durch einen Commit in einem Git-Verzeichnis gebautes Abbild, das dann automatisch in die Produktion ausgerollt wird. Der zentrale Faktor, der Tekton von etlichen Konkurrenzprodukten unterscheidet, ist das Bauen des Containers über einen Befehl an die Kubernetes-API. Anders als ArgoCD provisioniert Tekton alle Ressourcen und die Infrastruktur für anstehende Build-Aufgaben autark und autonom in Kubernetes. Hinterher räumt es auf Wunsch auch wieder auf.
Damit schließt Tekton eine Lücke. So mancher erfahrene Kubernetes-Jockey dürfte sich bei der Lektüre der Absätze zu Serving und Eventing bereits daran gestört haben, dass dafür jeweils ein fertiger Docker-Container samt Anwendung vorhanden sein muss, den KNative dann als Instanz im laufenden Cluster startet. Mit CI/CD hat das wenig zu tun, aber gerade der Faktor CI/CD spielt in Kubernetes eine bedeutende Rolle. Tekton baut aus den Quellen eines Docker-Abbilds dann den laufenden Container, den Serving und Eventing anschließend weiterverarbeiten.
Fazit
KNative erweist sich als mächtiges Werkzeug und dreht im Gespann mit Tekton dann so richtig auf. Echte CI/CD direkt in Kubernetes lässt sich im Moment nur über diese Kombination überhaupt erreichen. Andere Lösungen führen letztlich möglicherweise zum gleichen Ergebnis, betreiben aber Infrastruktur auf eigene Faust außerhalb von Kubernetes und lassen sich auch nicht über dessen API ansteuern. Wer also auf eine Lösung aus einem Guss Wert legt, der ist bei KNative und Tekton genau richtig.
Grenzenlos Euphorie ist allerdings dennoch nicht angesagt: Viele externe Werkzeuge warten mit Funktionen auf, die KNative systembedingt innerhalb von Kubernetes gar nicht implementieren kann. An dieser Stelle sind Admins und Entwickler in der Pflicht, verfügbare Alternativen auszutesten und das Werkzeug auszuwählen, das am besten zu den eigenen Anforderungen passt. In vielen Fällen dürfte das tatsächlich KNative sein, aber eben nicht in allen. (jcb/jlu)
Infos
- KNative-Beispiele: https://knative.dev/docs/samples/serving/
- “Hello World” mit KNative: https://github.com/knative/docs/tree/main/code-samples/serving/hello-world/helloworld-go






