
© ArisCtur / 123RF.com
Beim Open-Source-Monitoring beansprucht neben Platzhirschen wie Icinga oder Checkmk auch die lettische Software Zabbix ihren Platz. Ihre Geschichte reicht zurück bis ins Jahr 2001. Gehört sie damit zum alten Eisen, oder hat sie noch immer alles im Blick?
Zabbix muss sich nicht verstecken. Zu seinen besonderen Stärken gehört, dass es stetig nach den Wünschen der Anwender weiterentwickelt wird, breit verwendbar ist und vielfältige Integrationsmöglichkeiten bietet. Ob beim klassischen Server-Monitoring, der Überwachung beliebiger Netzwerk-, OT- und IoT-Geräte oder bei der Überwachung moderner Container- und Cloud-basierter Infrastrukturen – überall spielt Zabbix seine Stärken aus. Dazu gehören zahlreiche Datensammelmethoden und eine einfach zu definierende, aber trotzdem extrem flexible Problemerkennung und Alarmierung. Hinzu kommen ansprechende Visualisierungen, ein grafisches Konfigurationswerkzeug sowie Funktionen wie Web-Monitoring oder das integrierte Business-Services-Monitoring mit SLA-Reports.
Der gleichnamige Hersteller vertreibt Zabbix vollständig unter der GPLv2. Jeder Anwender vom privaten Nutzer bis zum Großkonzern bekommt Zugriff auf dasselbe Produkt, es existieren keine Enterprise-Funktionen hinter einer Bezahlschranke. Das Geschäftsmodell des Unternehmens Zabbix gründet sich auf Support- und Consulting-Dienstleistungen sowie Schulungen. Darüber hinaus verfügt Zabbix über ein weltweites Partnernetzwerk.
Zabbix spendiert seinem Monitoring-Tool halbjährlich Major-Release-Updates. In hauseigenen Repositories stehen Softwarepakete für alle namhaften Linux-Distributionen wie Red Hat Enterprise Linux, CentOS Stream, Debian und Oracle bereit. Neben Linux unterstützt Zabbix auch andere Unix-Systeme wie HP-UX, Solaris und sogar MacOS. Der Hersteller empfiehlt allerdings, Linux zu verwenden. Daneben gibt es offizielle Pakete für den Raspberry Pi sowie Container-Images.
Das Grundsystem
Den Kern eines Zabbix-Monitoring-Systems bildet der Zabbix-Server, der als zentrale Steuerungseinheit die Daten sammelt, (vor)verarbeitet, bewertet und in einer relationalen Datenbank speichert. Hinzu kommt das Zabbix-Webinterface, eine PHP-Applikation, die auf die Zabbix-Datenbank zugreift, um die vom Server gesammelten Daten zu visualisieren. Es stellt die Schnittstelle zum Administrator dar, aber auch in Form der Zabbix-API zu eventuellen Integrations- und Automatisierungswerkzeugen. Die Weboberfläche dient außerdem der Konfiguration des Zabbix-Systems.
Bei den Datenbanken greift Zabbix auf Bewährtes zurück und unterstützt MySQL, dessen Abkömmlinge MariaDB und Percona, die populäre Open-Source-Datenbank PostgreSQL sowie die kommerzielle Oracle-Datenbank. Neben den Kernkomponenten gibt es noch zwei Varianten des Zabbix-Agenten. Diese Webservices-Komponente hat derzeit die einzige Aufgabe, wiederkehrende Reports aus Zabbix heraus via E-Mail zu versenden. Zu guter Letztlich ermöglicht der Zabbix-Proxy, verteiltes Monitoring mit dezentralen Datensammlern zu betreiben.
Die Installation
Die Basisinstallation geht schnell von der Hand: Nach dem Aufspielen aller Zabbix-Softwarekomponenten sowie des Datenbankmanagementsystems über das Paketmanagement der verwendeten Distribution legen Sie eine leere Datenbank an und initialisieren sie mit dem für Zabbix notwendigen Datenbankschema. Das legt die nötigen Tabellen für Konfigurations- und historische Daten an und erzeugt einige Grundeinstellungen sowie einen ersten Host. Im nächsten Schritt konfigurieren Sie noch den Zabbix-Server mit den Zugangsdaten der Datenbank und installieren die notwendigen Softwarekomponenten für den Betrieb einer PHP-basierten Webanwendung.
Die Softwarepakete von Zabbix machen die Inbetriebnahme dabei sehr einfach. Auf der Zabbix-Webseite finden sich klare Schritt-für-Schritt-Anleitungen für die am weitesten verbreiteten Linux-Distributionen. Im Prinzip lassen sich sämtliche Zabbix-Komponenten problemlos auf einem einzigen (physikalischen oder virtuellen) Linux-Server betreiben. Zabbix empfiehlt dennoch, in größeren und produktiven Umgebungen die einzelnen Bestandteile auf getrennten Servern unterzubringen.
Insbesondere die für Zabbix notwendige Datenbank sollte auf einem eigenen Server laufen, sobald die Menge der zu überwachenden Hosts eine gewisse Anzahl übersteigt oder der Betrieb der Monitoring-Lösung einen strategischen Baustein des IT-Betriebs bildet. Das DBMS muss eine große Menge an Schreibzugriffen verkraften, da Zabbix sämtliche gesammelten Daten in verschiedenen Tabellen der Datenbank ablegt. Ein Mechanismus sorgt dafür, dass der Datenbestand nicht ins Unermessliche wächst. In einer größeren Monitoring-Umgebung kann die Zabbix-Datenbank gut und gern mehrere Terabytes umfassen, je nach Menge und konfigurierter Vorhaltezeit der gesammelten Metriken, Events, Audit-Logs und so weiter.
Stattdessen lässt sich Zabbix auch in Containern ausrollen [1]. Der Hersteller bietet neben den offiziellen Container-Images für alle Zabbix-Softwarekomponenten auch vorgefertigte Docker-Compose-Manifeste an, um die Lösung schnell und einfach in Docker zu starten. Für den Betrieb in Kubernetes und OpenShift stehen von der Open-Source-Community entwickelte Helm-Charts sowie ein schlanker OpenShift-Operator bereit, den Zabbix zur Verfügung stellt. Empfohlen sei an dieser Stelle das Helm-Chart [2], an dem der Autor dieses Artikels als Maintainer mitarbeitet und das der Arbeitgeber des Autors in zahlreichen, auch größeren produktiven Umgebungen einsetzt.
Das Container-basierte Deployment ist eine sehr praktische Option: So können Sie beispielsweise auf einem lokalen Rechner in einem Minikube, in K3d oder mithilfe von Docker Desktop oder Rancher Desktop einen schnellen, kleinen Kubernetes-Cluster starten. Auf dem setzen Sie mit den ersten beiden Kommandos aus Listing 1 schnell und einfach einen vollständigen Zabbix-Monitoring-Stack auf.
Listing 1
Installation im Container
$ helm repo add zabbix-community \ https://github.com/zabbix-community/helm-zabbix $ helm install -n zabbix --create-namespace zabbix \ --set zabbix_image_tag: alpine-6.2-latest \ --set zabbixweb.service.type=NodePort \ zabbix-community/zabbix $ kubectl -n zabbix get service \ -l app.kubernetes.io/instance=zabbix-zabbix-web
Das Beispiel aus dem Listing setzt zusammen mit den Zabbix-Komponenten eine PostgreSQL-Datenbank (ohne persistenten Speicherplatz, alle Daten werden nach dem Herunterfahren gelöscht) auf und stellt den Port für das Zabbix-Webinterface als NodePort-Service bereit. Ein Ingress-Objekt und eventuell ein TLS-Zertifikat lässt dieses Beispiel außen vor. Entsprechende Dokumentation findet sich auf der Github-Seite des Helmchart-Projekts.
Der letzte Befehl aus Listing 1 zeigt den Service an, der das Webinterface von Zabbix zur Verfügung stellt, und nennt den Port, unter dem sich das Interface erreichen lässt. Nach der geglückten Installation begrüßt Sie das Zabbix-Webinterface und lädt zum Login ein. Nach der Anmeldung als Admin mit dem Passwort »zabbix« laden Sie in einem zentralen Dashboard (Abbildung 1).
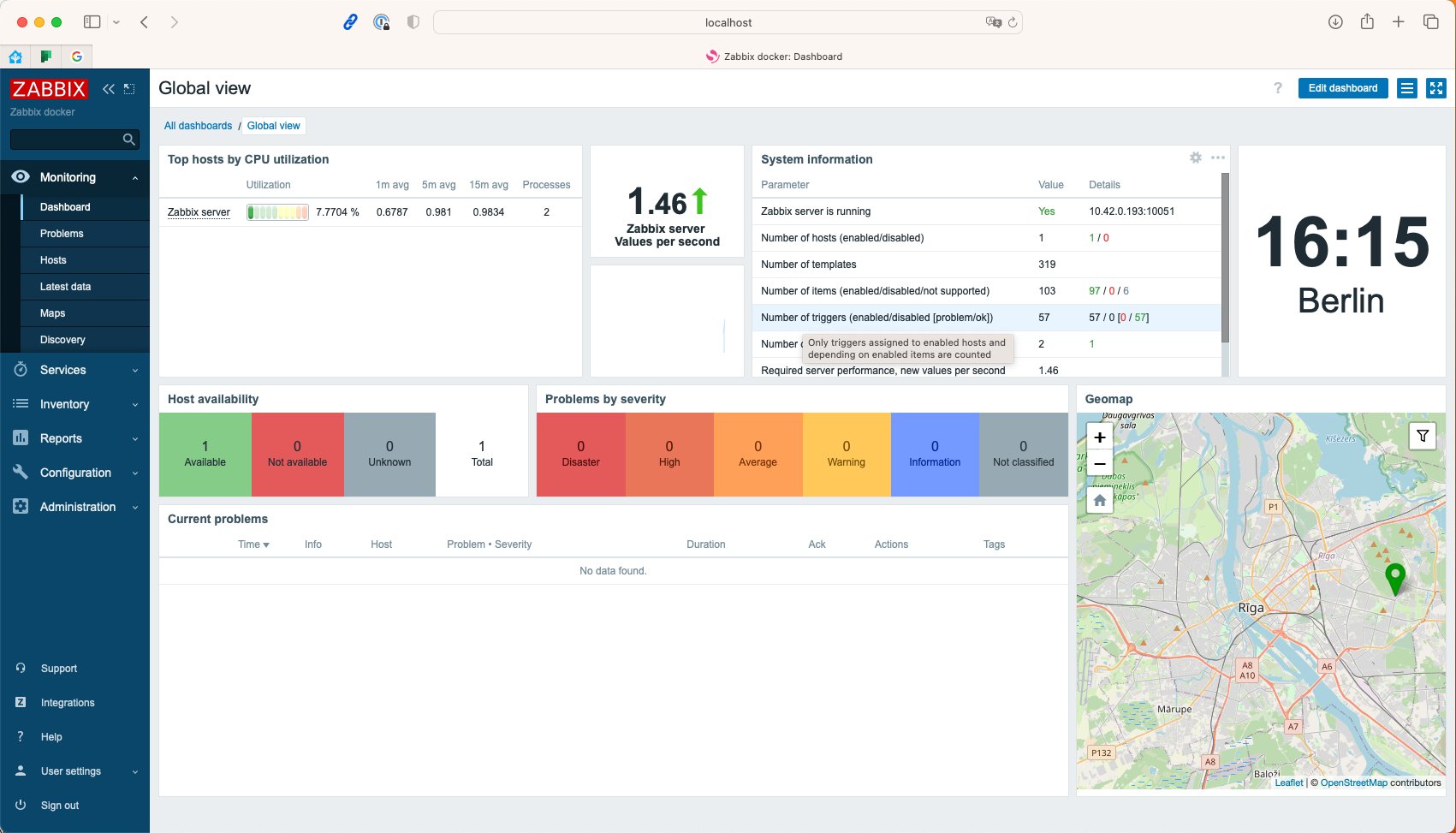
Abbildung 1: Das Default-Dashboard von Zabbix mit einigen Basisinformationen.
Webinterface
Das Webinterface von Zabbix gliedert sich in sechs verschiedene Bereiche. Hinzu kommen einige externe Links zur Zabbix-Dokumentation und der Zabbix-eigenen Integrationswebseite, auf der sich Monitoring-Templates und andere nützliche Dinge finden.
In den Abschnitten Monitoring, Services und Inventory des Interfaces sehen Sie Monitoring-Daten ein (Abbildung 2), um mit anfallenden Problemen zu arbeiten (Acknowledgement, Tickets erzeugen, etc.) sowie System- und Anwendungszustände nachträglich anhand von Graphen und anderen historischen Ansichten zu analysieren (Abbildung 3).
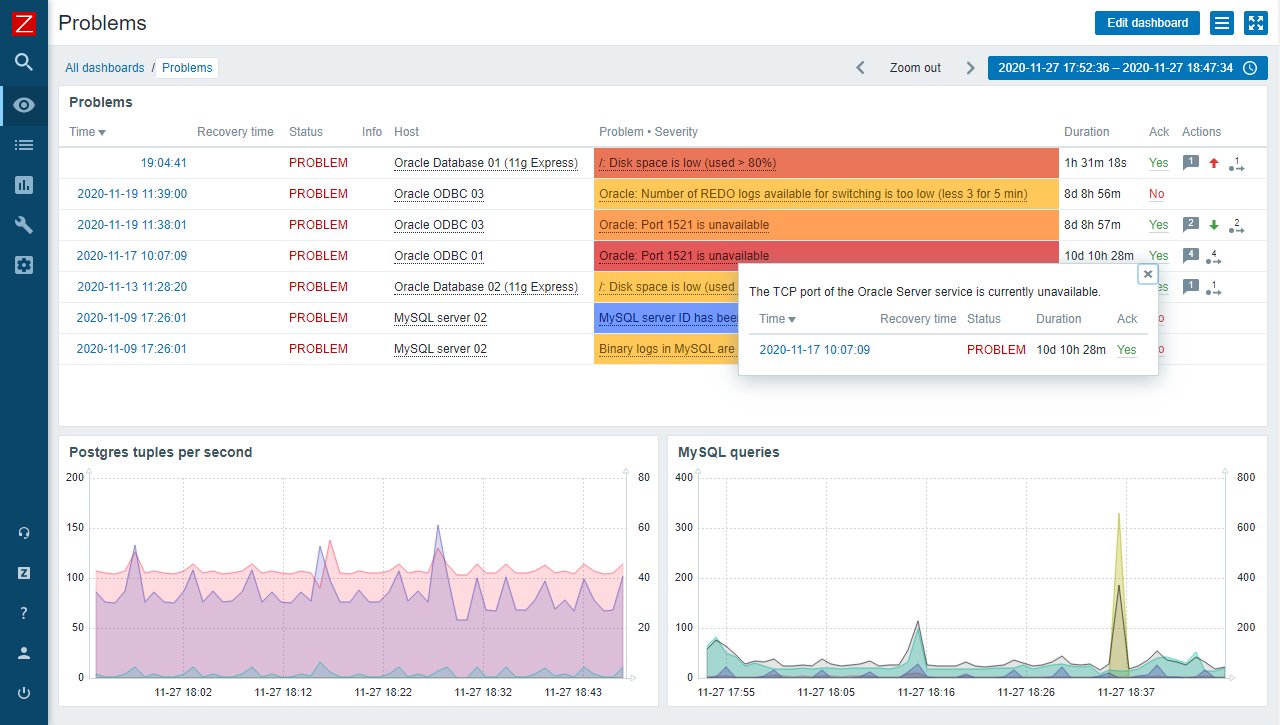
Abbildung 2: Das Zabbix-Dashboard zeigt historische Daten und verweist auf Probleme.
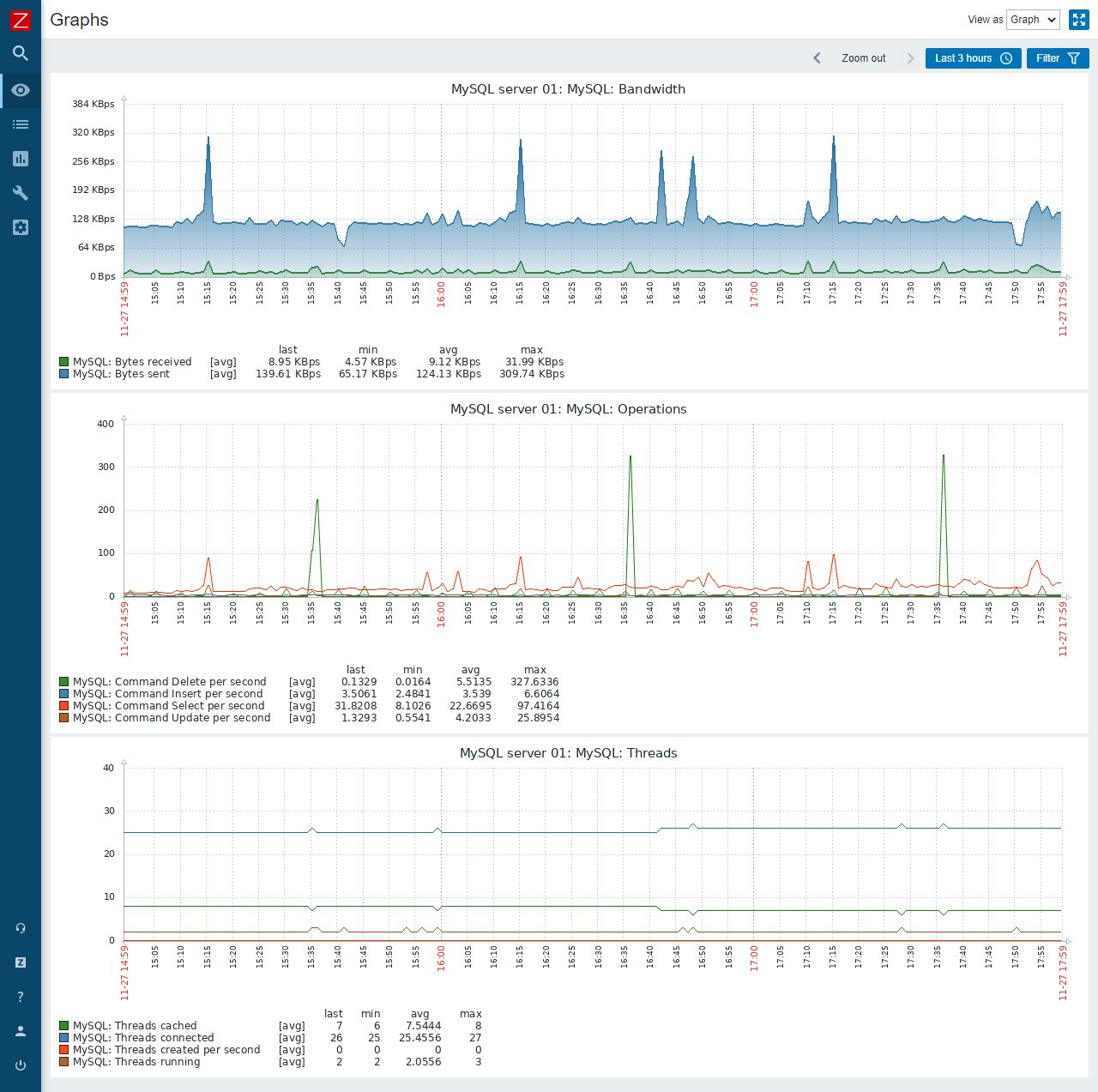
Abbildung 3: Graphen wie diese dienen der nachträglichen Problemanalyse.
Mit den Services steht in Zabbix 6.0 eine vollständig neu entwickelte und für die Überwachung und Alarmierung von mehr als 100 000 Business Services ausgelegte leistungsfähige Funktion zur Verfügung. Sie dient dazu, aus den erfassten Metrikdaten den Zustand von Betriebsprozessen abzuleiten. Weitere Neuerungen umfassen eine SLA-Reporting-Funktion sowie die Möglichkeit, aufgrund der Zustände von Business Services Alarme auszulösen. Scheduled Reports erlauben dem Zabbix-Administrator, auf Dashboards beruhende Reports zu definieren und in regelmäßigen Intervallen per E-Mail zu versenden. Die Scheduled Reports lassen sich zusammen mit dem SLA-Report-Dashboard-Widget auch dazu einsetzen, SLAs regelmäßig (etwa im Wochenturnus) an die Applikationsverantwortlichen zu reporten.
Auch bei den Dashboards hat sich in den letzten Zabbix-Versionen viel getan (Abbildung 4). In Zabbix können Sie nun moderne Dashboards bauen, die ebenso attraktiv aussehen wie die mit dedizierten Dashboard-Tools wie Grafana erstellten. Die Basis dafür wurde bereits in Zabbix 3.4 gelegt: Mit dieser Version hielt das neue, auf frei platzierbaren Widgets basierende Dashboarding-Framework Einzug in das Monitoring-Tool. In den letzten Jahren wurden diese Widgets kontinuierlich weiterentwickelt, sodass jetzt Service-Views, vektorbasierte und dynamische Graphenansichten, geografische Karten, Network-Maps und vieles mehr zur Verfügung stehen.
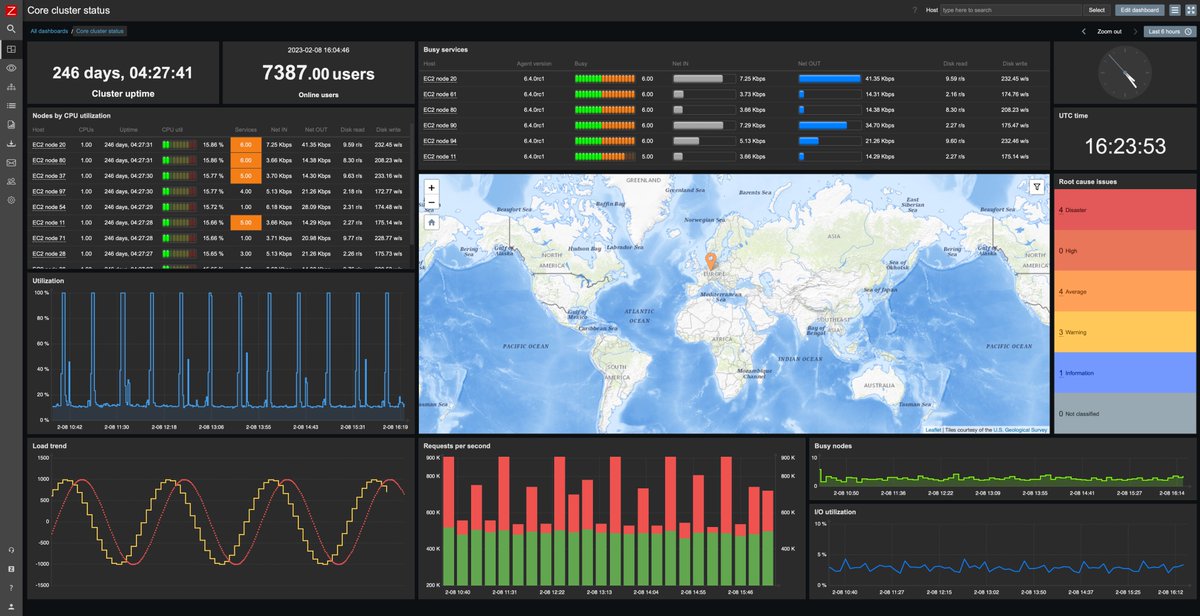
Abbildung 4: Ein Beispiel für ein modernes Zabbix-Dashboard im Dark Theme.
Auch unter der Haube hat Zabbix einiges zu bieten. Umfangreiche Permissions-Konfigurationen sowie das in Zabbix integrierte Rollenkonzept ermöglichen es, genau die Monitoring-Objekte anzuzeigen, die für den jeweiligen Job relevant sind (Abbildung 5). Zudem lassen sich Bereiche des Webinterfaces gezielt für einzelne Benutzer oder Benutzergruppen freigeben. Das ermöglicht, ausgewählten Usern die Sicht auf weite Teile der Infrastruktur zu erlauben, jedoch nur anhand einzelner, durch den Administrator vollständig konfigurierbarer Dashboards.
Abbildung 5: Zabbix bietet für Benutzer eine ganze Reihe von Authentifizierungsoptionen. Quelle: Zabbix
Wichtig für den Enterprise-Einsatz ist zudem die Möglichkeit, die Authentifizierung am Zabbix-System über einen oder mehrere LDAP/AD-Server zu realisieren. Daneben lässt sich Zabbix an ein modernes SAML-basiertes Identity-Management-System anbinden, zum Beispiel an die Open-Source-Lösung Keycloak oder einen der zahlreichen Cloud-basierten Provider wie Okta, OneLogin oder Microsoft Azure AD.
Derzeit muss noch ein Super-Administrator alle Benutzer und deren Zuordnung zu Rollen und Berechtigungsgruppen innerhalb von Zabbix manuell konfigurieren. Ein Blick auf die Roadmap [3] offenbart jedoch, dass die in Kürze anstehenden Version 6.4 von Zabbix voraussichtlich JIT enthalten wird, also ein Just-in-Time-User-Provisioning. Diese neue Funktion und viele weitere Features können Sie sich bei Interesse bereits in den Public-Beta-Releases von Zabbix ansehen. JIT wird es ermöglichen, anhand von LDAP- oder SAML-Attributen Benutzern bereits beim Login passende Gruppen- und Rollenzugehörigkeiten zuzuordnen und damit ein Berechtigungskonzept automatisiert durchzusetzen.
Die gesamte Konfiguration der Systemüberwachung erfolgt ebenfalls im Web-GUI von Zabbix. Dort erwartet Sie ein ausgeklügeltes, auf Templates basierendes System. Um Abläufe zu automatisieren und in Drittsysteme zu integrieren, steht eine JSON-RPC-API zur Verfügung, die sämtliche Funktionen von Zabbix bereitstellt [4]. Für diese Programmierschnittstelle gibt es unter anderem Module für Python und die Automatisierungs-Frameworks Ansible und Salt Stack sowie Integrationen in Ticket-Tools und vieles mehr.
Auch in Sachen Monitoring-Templates profitiert Zabbix von der vollständig freien Verfügbarkeit der Softwarelösung. Mehr als 300 Vorlagen für eine Vielzahl populärer Betriebssysteme, Netzwerkgeräte, Anwendungen und Cloud-Dienste liefert Zabbix bereits von Haus aus mit (Abbildung 6). Daneben stellt die Community für so gut wie jeden Anwendungsfall eine fertige oder für den Einsatzzweck einfach anpassbare Monitoring-Vorlage bereit.

Abbildung 6: Die Zabbix-Webseite veranschaulicht die vielfältigen Möglichkeiten einer Integration mit der Software Dritter.
Funktionsweise
Zabbix verfolgt einen auf Metriken basierenden Ansatz. Daten werden zunächst entweder durch den Zabbix-Server selbst oder durch einen Zabbix-Proxy erhoben und für Auswertungen zentral in der Server-Datenbank gespeichert.
Die Metriken – im Zabbix-Jargon heißen sie Items – sind zunächst zustandsfrei und stellen die Rohdaten für Visualisierungen und die Problemerkennung dar. Für die Problemidentifizierung kommen logische Ausdrücke, sogenannte Trigger Expressions, zum Einsatz. Der Server wertet sie bei jedem neuen Datensatz frisch aus, der Zabbix erreicht.
In Zabbix stehen eine Vielzahl von Item-Typen zur Verfügung, die unterschiedliche Datensammlungsmethoden implementieren. Dabei stellt sicherlich der Zabbix-Agent die effektivste und einfachste Möglichkeit für das klassische Betriebssystem- und Anwendungs-Monitoring dar.
Agenten
Der Zabbix-Agent steht für alle gängigen Betriebssysteme und Architekturen direkt auf der Zabbix-Webseite und in den Paket-Repositories zur Verfügung.
Seit Zabbix 5.0 gibt es zusätzliche einen moderneren, nur für Linux und Windows unterstützten Agent2. Er ist funktionskompatibel zum traditionellen, in C geschriebenen Zabbix-Agenten, wurde aber in Go implementiert und bietet dadurch erweiterte Funktionen wie das native Monitoring von MySQL-, PostgreSQL- und Oracle-Datenbanken, die Überwachung von TLS-Zertifikaten, eine Subscription für MQTT-Topics und vieles mehr. Besonders spannend: Seit Kurzem lässt er sich auch mit Go-Modulen erweitern, die unter anderem Features bieten wie persistente Verbindungen, dauerhaft mit dem Agenten laufenden, eigenen Programmcode oder die Möglichkeit, komplexe Business-Logik direkt im Agenten zu implementieren.
Beide Zabbix-Agenten können Daten sowohl aktiv als auch passiv an den Zabbix-Server respektive an einen Zabbix-Proxy übertragen. Das ermöglicht flexible, an die Netzwerksituation und die Performance-Anforderungen angepasste Einsatzszenarien. Zudem puffert der Agent2 bei Bedarf für den Fall, dass Proxy oder Server nicht erreichbar sein sollten, gesammelte Metrikdaten in einer lokalen SQLite-Datenbank. Das ist insbesondere für IoT-Anwendungen sinnvoll. Die native Funktionsvielfalt der Zabbix-Agenten umfasst das Überwachen [5] von CPU, Speicher und Festplatten sowie erweiterte Funktionen wie WMI-Queries, Inventory-Abfragen, Datei- und Verzeichnisfunktionen und vieles mehr.
Weitere Datenquellen
Neben den vielfältigen Möglichkeiten, Daten über Agenten zu sammeln, gibt es einfache ICMP- und TCP/UDP-Checks, die Verbindungen prüfen und Messdaten wie etwa Antwortzeiten erheben. SNMP-Items erlauben sowohl eine Abfrage von Werten via SNMP als auch den Empfang von SNMP-Traps. Dabei unterstützen sie alle SNMP-Protokolle sowie Security Level, Verschlüsselung und das Hashing von Passwörtern.
Zusätzlich gibt es die Möglichkeit, SSH/Telnet-Kommandos auszuführen und deren Ergebnisse zu speichern, Abfragen über beliebige ODBC-Datenbanken laufen zu lassen, Daten von Java-basierten Anwendungen via JMX (Java Management Extension) einzulesen sowie Sensordaten von Server-Hardware via IPMI zu erfassen. Internal-Items spiegeln Metriken wider, die den Zustand und die Performance der Zabbix-Monitoring-Engine selbst abbilden. Sie dienen dem Self-Monitoring sowohl des Zabbix-Servers als auch der Zabbix-Proxies.
In den letzten Jahren hat Zabbix sehr viel Entwicklungsarbeit in das erweiterte Data Gathering investiert. Damit will man dem selbst proklamierten All-in-one-Ansatz der Monitoring-Lösung gerecht werden und ohne den Einsatz externer Skripte möglichst auch spezielle Monitoring-Anforderungen umsetzen. Inzwischen gibt es erweiterte Item-Typen wie das HTTP-Item, das Daten von Status-Webseiten oder den API-Endpunkten von Anwendungen abfragt, oder das Script-Item, das anhand eines in Zabbix integrierten Javascript-Interpreters quasi beliebige Funktionsdefinitionen ermöglicht.
Für Anwendungsfälle, die über die mitgelieferten Item-Typen hinausgehen, kann man Zabbix selbst sowie die Zabbix-Agenten in vielfältiger Weise in ihren Funktionen erweitern. Die Möglichkeiten reichen hier vom Einbinden einfacher Skripte über Erweiterungen des C-basierten Monitoring-Kerns des Zabbix-Servers und -Proxys bis hin zu den bereits erwähnten Go-Plugins im Agent2.
Für Aggregationen und Ableitungen aus gemessenen Werten kommen Calculated-Items zum Einsatz. Auch sie erfuhren in der Version 6.0 der Monitoring-Lösung ein umfangreiches Feature-Update. So ist es jetzt beispielsweise möglich, anhand von Tag-Markierungen und sogenannten Aggregation Functions dynamische Berechnungen über beliebige, flexible Anzahlen von Items auszuführen und das Resultat wieder als Item speichern. Auf diese Weise lässt sich etwa herausfinden, bei wie vielen Systemen einer bestimmten Kategorie die CPU-Last über einen längeren Zeitraum einen vorgegebenen Schwellwert übersteigt. Auf demselben Weg kann man die Gesamtanzahl aktiver Nutzer über alle Nodes eines Applikations-Clusters hinweg zählen.
Ein weiterer wichtiger Baustein, der in den letzten Jahren das Data Gathering in Zabbix maßgeblich revolutioniert hat, ist die Kombination aus Dependent-Items und dem Preprocessing. Für diese Vorverarbeitung von Monitoring-Daten stehen eine Vielzahl von Funktionen zur Verfügung. Sie reichen von einfachen Textersetzungen via Suchen und Ersetzen oder reguläre Ausdrücke über erweiterte Datenextraktionen mit JSONPath und XMLPath und eine Validierung von Daten mit flexibler Problembehandlung bis hin zum Custom Preprocessing mit Javascript.
So lassen sich etwa aus JSON-Bruchstücken oder HTTP-Abfragen Werte extrahieren und für das Monitoring als Metriken weiterverarbeiten. Auch die Extraktion mehrerer Werte aus einem einzigen Datensatz anhand eines HTTP-Items und deren Verteilung auf mehrere Dependent-Items gelingt nun problemlos und ohne den Einsatz externer Skripte.
Problemerkennung
Ebenso flexibel wie die Möglichkeiten zur Datenerhebung sind die Funktionen zum Generieren von Events aus den gesammelten und historisierten Monitoring-Rohdaten und damit zur Darstellung von Problemen.
Bei den Trigger-Expressions stellt sicher die Einführung der neuen Trigger-Expression-Syntax mit Zabbix 5.4 die wichtigste Änderung der letzten Jahre dar. Der Hersteller hat die Schreibweise der Expressions auf ein neues Format umgestellt, das einfacher zu interpretieren und zu verstehen sein soll. Mit der neuen Syntax kamen zahlreiche neue Trigger-Funktionen [6] hinzu, die insgesamt rund 100 mathematische, logische, String-basierte sowie Iteratoren- und Aggregationsfunktionen umfassen.
Die Vielzahl der zur Verfügung stehenden Trigger-Funktionen mag auf den ersten Blick ein wenig unübersichtlich erscheinen. Mithilfe des grafischen Expression Builders (Abbildung 7) und des Add-Knopfs rechts neben dem Trigger-Expression-Fenster fällt es jedoch sehr leicht, Trigger zu erstellen. Man sucht einfach das Item aus, auf dessen Basis man einen Trigger setzen möchte, wählt dann eine passende Funktion und parametrisiert sie entsprechend der Kurzbeschreibung – fertig.
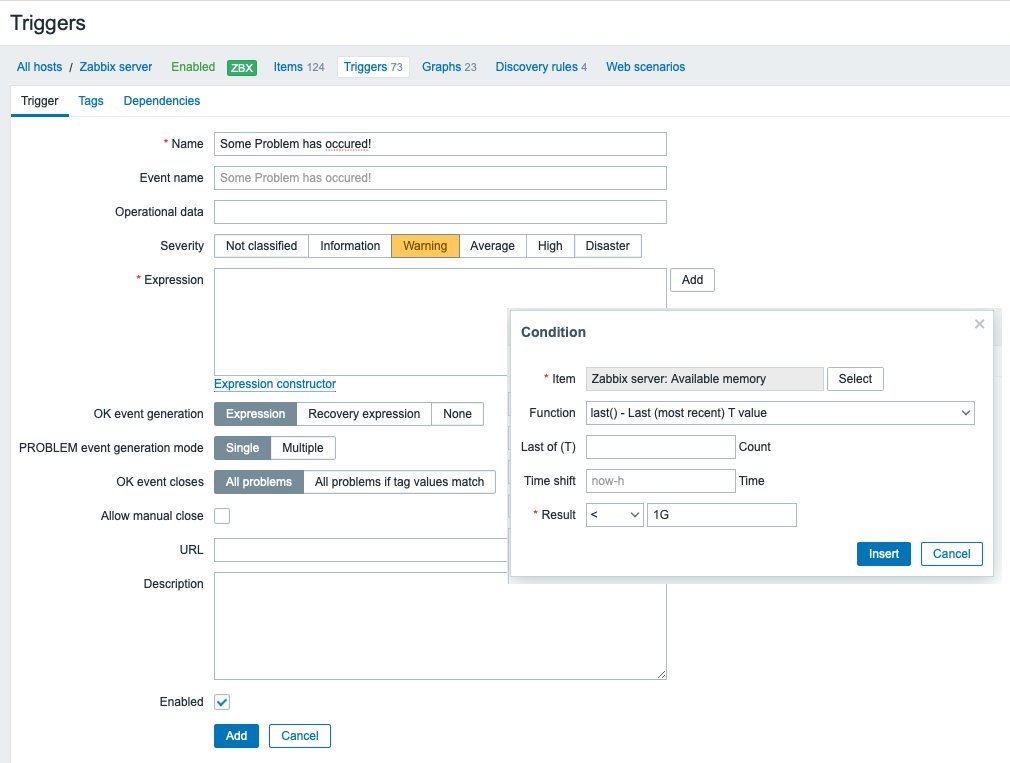
Abbildung 7: So gelingt die Definition eines Triggers im Konfigurations-Interface.
Statt Schwellwerte fest in einer Trigger-Definition zu hinterlegen, empfiehlt es sich, dafür sogenannte User Macros zu verwenden. Sie bieten noch eine zusätzliche Möglichkeit des Customizings: Mit ihnen hinterlegt man Trigger-Definitionen in Templates, die wiederum mehrere Hosts (und sogar andere Templates) verwenden können. Die User Macros lassen sich global oder in einem Template mit einem Host-weise überschreibbaren Vorgabewert belegen. Das ermöglicht es, die Trigger-Auslösung pro Host und Anwendungsfall zu individualisieren. Eine solche Trigger-Expression könnte folgendermaßen aussehen:
last(/Zabbix server/vm.memory.size[available])<{$MEMORY_LOW}
Für diese Trigger-Funktion definieren Sie das entsprechende User Macro, wie in Abbildung 8 gezeigt. Das in einer solchen Trigger-Definition referenzierte Item geben Sie stets anhand seines Item-Keys an. Er identifiziert jedes Item auf einem Host oder in einem Template eindeutig und darf im entsprechenden Kontext nur einmal vorkommen.
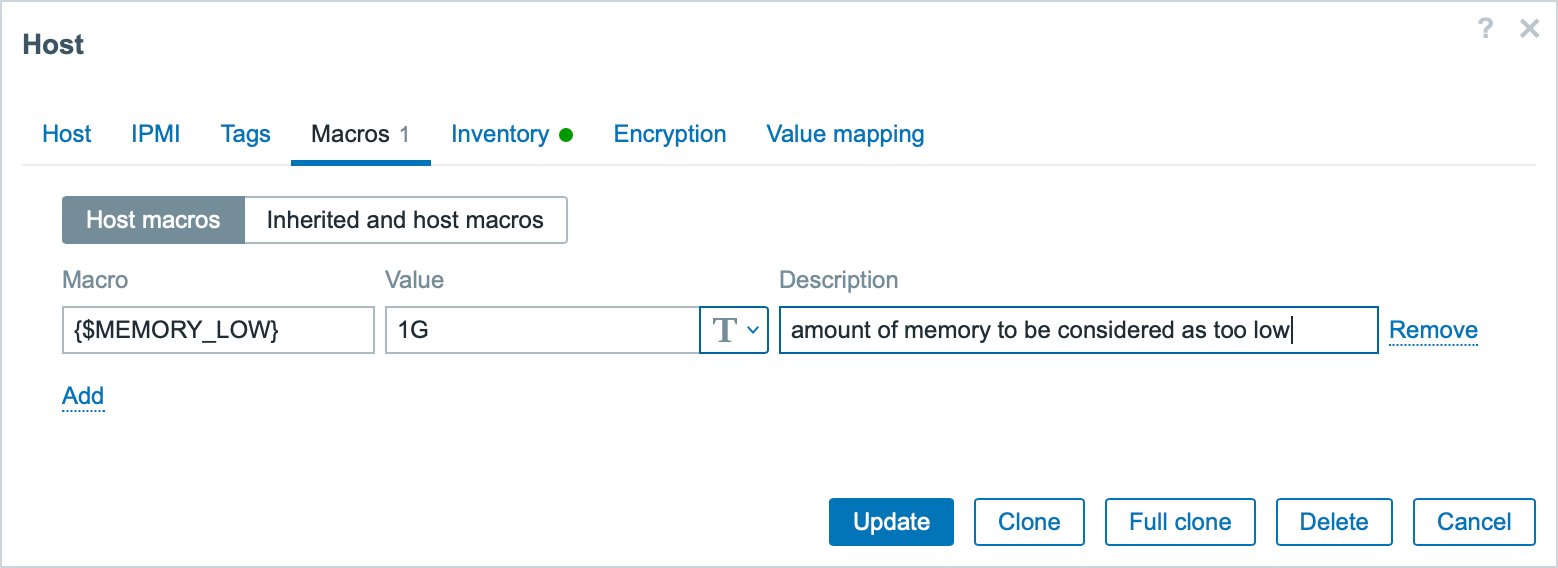
Abbildung 8: So einfach gelingt die Definition einer Trigger-Funktion für ein User Macro.
Trigger
Ein dicker Pluspunkt für Zabbix ist die immer für Trigger-Auswertungen verfügbare Historie der gemessenen Werte. Sie erlaubt, durch das Auswertung des Verlaufs statt einzelner Messwerte False Positives zu minimieren, also Monitoring-Alarme aufgrund kurzzeitig eintretender Zustände, die aber keine Fehlfunktion darstellen. Beispielsweise könnte man mit der einfachen Trigger-Expression »max(/Host/icmpping,3m)=0« nur dann reagieren, wenn ein Host seit mindestens drei Minuten nicht mehr via ICMP-Ping erreichbar ist.
Trigger können aber noch sehr viel komplexer ausfallen. Die Kombination mehrerer Teilausdrücke mit erweiterten Trigger-Funktionen ermöglicht, Werteänderungen über die Zeit zu berechnen oder Richtung und Kontinuität der Veränderung zu bestimmen. Denkbar wären sogar Auswertefunktionen auf der Grundlage von Machine Learning, die Langzeitdaten einbeziehen und Vorhersagefunktionen realisieren.
Als Beispiel eines erweiterten Trigger-Ausdrucks soll an dieser Stelle der in den mitgelieferten Templates verankerte Trigger für die Erkennung von zu wenig verfügbarem Speicherplatz auf einem Dateisystem dienen. Er kombiniert zwei Schwellwerte, die man setzen kann. Der eine bezieht sich auf den prozentualen Füllstand, der andere auf einen fixen Wert für den noch verfügbaren Platz. Hinzu kommt eine Vorhersagefunktion (Listing 2). Dieser Trigger löst erst dann aus, wenn der prozentual eingestellte Schwellwert überschritten wird, gleichzeitig aber entweder der fixe Megabyte-Wert unterschritten ist oder weniger als ein Tag Zeit bleibt, bis sich das Filesystem zu 100 Prozent füllt.
Listing 2
Komplexer Trigger
last(/Linux filesystems by Zabbix agent/vfs.fs.size[{#FSNAME},pused])>{$VFS.FS.PUSED.MAX.WARN:"{#FSNAME}"} and ((last(/Linux filesystems by Zabbix agent/vfs.fs.size[{#FSNAME},total])-last(/Linux filesystems by Zabbix agent/vfs.fs.size[{#FSNAME},used]))<{$VFS.FS.FREE.MIN.WARN:"{#FSNAME}"} or timeleft(/Linux filesystems by Zabbix agent/vfs.fs.size[{#FSNAME},pused],1h,100)<1d)
Durch die Trigger erkannte Probleme kann der Anwender auf der Problems-Seite des User-Interfaces sichten und bearbeiten. Hier stehen Möglichkeiten zum Filtern anhand von Problem-, Item-, Host- und Template-Tags, Host-Gruppen, Problem- und Host-Namen sowie nach Metainformationen der Monitoring-Hosts zur Verfügung. Sie lassen sich auch abspeichern, was jederzeit einen schnellen Zugriff erlaubt. Des Weiteren gibt es verschiedene Optionen, um die Darstellung der Seite Problems (Abbildung 9) zu beeinflussen. Die beliebte Kompaktansicht (Compact view) schafft dabei mehr Platz für die Darstellung.
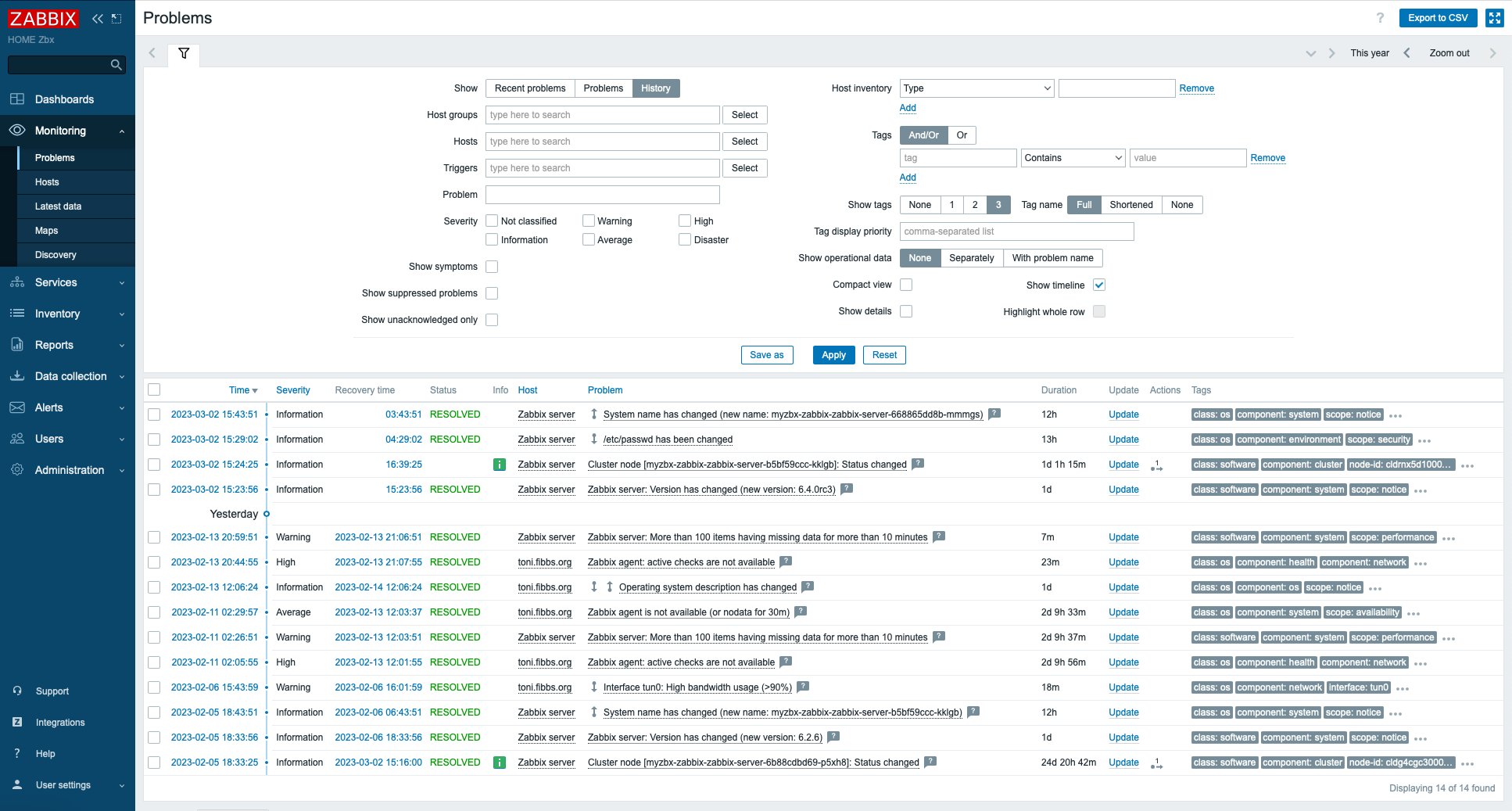
Abbildung 9: Die Problemansicht in Zabbix mit aktivierten Filtern.
Auf dieser Seite kann man Probleme bestätigen, um anderen Administratoren zu signalisieren, dass die Arbeit an der Lösung bereits begonnen hat. Stattdessen lässt sich aber auch einfach nur ein Kommentar hinterlegen oder – je nach Benutzerberechtigung – auch der Schweregrad (Severity) eines Problems verändern. Custom Commands im Kontext von Problemen ermöglichen es, zum Beispiel via Webhook im Ticket-System einen Eintrag für ein bestimmtes Problem zu erzeugen.
Ein Calculated-Item verwendet genau wie die Trigger-Definitionen die Trigger-Ausdrücke als Formel zur Berechnung. Auf diese Weise kann man die vielfältigen Trigger-Funktionen nicht nur zur Erkennung von Problemen verwenden, sondern auch zum Generieren abgeleiteter Metriken. Die lassen sich ihrerseits sammeln und wiederum in Trigger-Expressions als Datenbasis nutzen.
Automatisierte Konfiguration
Um gleichartige Entitäten im Kontext eines Hosts zu überwachen, kommt oft die Funktion Low Level Discovery [7] zum Einsatz. Sie basiert auf einem beliebigen Item-Typ, der entweder selbst eine bestimmte JSON-Datenstruktur ausgibt oder diese anhand von Preprocessing erstellt, beispielsweise aus dem Ergebnis einer API-Abfrage. Daraus lassen sich dann automatisiert anhand von Filtern und Regeln Items, Trigger, Graphen und auf Wunsch sogar Hosts generieren.
Beim Low Level Discovery handelt es sich um eine der umfassendsten Funktionen in Zabbix. Es wurde in den letzten Releases mit immer weiteren wichtigen Erweiterungen komplettiert und bildet die Basis für dynamisches Monitoring mit wenig manuellen Eingriffen. Die in Zabbix mitgelieferten Monitoring-Templates verwenden ein umfangreiches Low Level Discovery für das automatische Erkennen von Dateisystemen, CPUs und Netzwerkschnittstellen. Hinzu kommen erweiterte Monitoring-Szenarien wie das Überwachen von Cloud-Ressourcen oder Kubernetes-Clustern.
Wie alle anderen Funktionen in Zabbix lässt sich auch das Low Level Discovery umfangreich erweitern. Es lässt sich unter anderem für SNMP-basiertes Monitoring, WMI-Queries auf Windows, Datenbank-Queries via ODBC oder eigene Skripte verwenden.
Alarmierung
Die Alarmierung in Zabbix ist ähnlich flexibel und hochgradig anpassbar wie die Datensammlung und Problemerkennung. Actions verwenden Bedingungen, um Problem-Events anhand von Host-Name und -gruppe, Tags oder anderen Kriterien auszuwählen. Sie führen dann die sogenannten Operations für alle Events aus, die zu diesen Problemen gehören.
Operations können die Problembenachrichtigung in Eskalationen gliedern. So ließe sich etwa die erste Benachrichtigung an den Systemadministrator via E-Mail versenden, die zweite dann zehn Minuten später via SMS an die Rufbereitschaft. Auch zeitlich unabhängige unterschiedliche Alarmierungswege für Probleme stellen keinerlei Problem dar.
Alarmierungswege bezeichnet Zabbix als Media Types. Ein typischer Media Type ist beispielsweise E-Mail. Dafür bietet Zabbix native Integrationen für Microsoft Teams, Slack, Rocket.Chat, Jira, Github, Mattermost, Opsgenie und viele mehr. Insgesamt stehen 32 Benachrichtigungsmethoden zur Wahl, die man nur geringfügig an den Anwendungsfall anzupassen braucht.
Fehlt der gewünschte Service für eine Benachrichtigung noch, lässt er sich jederzeit anhand eines Skripts oder eines Webhooks mit Business-Logik auf der Grundlage von Javascript selbst definieren. Media-Type-Definitionen kann man wie viele andere Konfigurationsobjekte in Zabbix über das Webinterface exportieren und importieren. Das erleichtert den Austausch in der Community, aber auch den Konfigurationstransfer zwischen einzelnen Zabbix-Instanzen oder zwischen einer Entwicklungs- und einer Produktionsumgebung.
Fazit
Zabbix bietet ein umfangreiches, hochgradig konfigurierbares und doch einfach zu benutzendes System-Monitoring. Die Lösung lässt auf funktionaler Ebene so gut wie keine Wünsche offen und erlaubt eine schnelle und unkomplizierte Implementation in vielfältigen Umgebungen. Hinter der quelloffenen Software steht ein stabil aufgestelltes, wirtschaftlich erfolgreiches Unternehmen, das die an die Anforderungen des Markts angepasste Entwicklung des Produkts stetig vorantreibt.
Freilich fällt die Lernkurve mit Zabbix steil aus, denn die umfangreichen Konfigurationsmöglichkeiten und Zusammenhänge der einzelnen Komponenten erschließen sich nicht immer auf den ersten Blick. Unternehmen, die das Maximum aus der Lösung herausholen und auch von der Erfahrung von Experten profitieren möchten, tun deshalb gut daran, das Schulungs-, Beratungs-, Implementierungs- und Support-Angebot von erfahrenen, zertifizierten Experten zu nutzen. (jcb)
Der Autor
Christian Anton ist Leiter des Competence Centers Cloud Native Technologies und Technology Evangelist bei Enthus, einem Zusammenschluss von vier erfolgreichen Playern in der deutschen IT-Beratungs- und Systemhauslandschaft. Er bringt über 20 Jahre Expertise in Enterprise-Open-Source-Software mit, insbesondere in den Bereichen Monitoring, Automation, Netzwerk, Containerisierung und moderne IT-Infrastrukturen. @KE:
Infos
- Zabbix-Container: https://hub.docker.com/search?q=zabbix
- Helm-Chart: https://github.com/zabbix-community/helm-zabbix
- Zabbix-Roadmap: https://zabbix.com/roadmap
- API-Dokumentation: https://www.zabbix.com/documentation/current/en/manual/api
- Zabbix-Agent: https://www.zabbix.com/documentation/current/en/manual/config/items/itemtypes/zabbix_agent
- Trigger-Funktionen: https://www.zabbix.com/documentation/current/en/manual/appendix/functions
- Low Level Discovery: https://www.zabbix.com/documentation/current/en/manual/discovery/low_level_discovery






