
© Kheng Ho Toh / 123rf.com
Jeder kennt Text-, Bild- und Audiodateien. Will man nun aber Wissen speichern, braucht man dafür nicht Wissensdateien? Und wie müssten die aussehen? Eine Antwort auf diese Frage gibt die Wissensrepräsentation, ein Teilgebiet der KI.
Haben Sie heute schon Wissen formal modelliert und in maschinenlesbarer Form kodiert? Tatsächlich stehen die Chancen dafür besser, als Sie womöglich denken, denn mit dem Einzug der Computer in unseren Alltag ist auch die Darstellung von Wissen zum alltäglichen Problem geworden. Schon die Aufteilung unserer Dateien in Verzeichnisse spiegelt eine Menge Wissen wider, das die Dateien selbst nicht enthalten. Wenn Sie sich also schon einmal gefragt haben, ob Ihre aktuelle Verzeichnisstruktur noch passt oder wo Sie eine neue Datei am besten speichern sollten, dann sind Sie mit einigen praktischen Problemen der formalen Wissensrepräsentation bereits vertraut. Der Weg zu den großen praktischen Anwendungen im Wissensmanagement wie zu Alexa, Siri und Co. ist dann gar nicht mehr so weit, denn auch deren Wissen gilt es letztlich irgendwie zu repräsentieren (Abbildung 1).

Abbildung 1: Woher weiß mein Smartphone das alles? Oftmals vom Wissensgraph Wikidata, wie hier in der Standardsuche der Android-Alternative /e/OS.
Was heißt formal?
Formale Wissensrepräsentation – das klingt im ersten Moment eher nach höherer Mathematik als nach alltäglicher Datenorganisation. Aber für den Computer ist letztlich alles formal, so auch das Dateisystem. Allerdings hält diese einfache Datenstruktur nur sehr wenige Ausdrucksmittel bereit, um Wissen zu modellieren. Im Wesentlichen stellen wir sie uns als eine Hierarchie vor, also als Baumstruktur, bei der sich die Bedeutung eines Knotens aus dem gesamten Pfad zur Wurzel hin ergibt.
Verzeichnisse sind aber nicht die einzige Möglichkeit, Dateien zu ordnen. Bei Bildern verwenden wir häufig Tags, die in der Regel nicht hierarchisch sind. Bei Audiodateien gibt es gleich eine ganze Reihe von benutzerdefinierten Metadaten. Und selbst das scheinbar einfache Verzeichniskonzept lässt sich unterschiedlich umsetzen: Unter Linux kann dieselbe Datei dank Hardlinks in mehreren Verzeichnissen liegen; bei Windows bekommt man stattdessen gleich eine ganze Menge an Bäumen (einen pro Laufwerk). Strukturen spielen in der Wissensrepräsentation eine große Rolle, und Sie sehen schon, dass es selbst bei einfachen Anwendungen sehr viele Möglichkeiten gibt.
Geteilte Ideen
Wenn wir den Anspruch haben, Wissen digital darzustellen, dann müssen wir über bloße Datenstrukturen hinausgehen und einen Bezug zu unserer Erfahrungswelt herstellen. Auch das tun wir routiniert und intuitiv, wenn wir mit Computern arbeiten. Schon Verzeichnisnamen wie »Studium«, »Rechnungen« oder »Urlaub_2022« bilden eine Brücke in die Welt außerhalb des Computers, die nicht aus Bits und Bytes besteht. Der mathematische, formale Teil bildet daher nur eine Seite der Wissensrepräsentation. Die andere – informelle – besteht in der Verbindung zu unseren Begriffen und Vorstellungen. Hierbei ist der Mensch das Maß aller Dinge. Auch wenn es einer smarten KI möglich ist, eine Audiodatei der Kategorie Post-Punk zuzuordnen, heißt das noch lange nicht, dass die Nutzer der Musiksammlung mit diesem Begriff etwas anfangen können. Begriffe zu bilden und sich mit anderen auf ihre Verwendung zu einigen, ist nicht einfach.
Damit kennen wir die beiden wesentlichen Aspekte der Darstellung von Wissen: Formalisierung und Begriffsbildung. Formalisierung liefert uns die mathematisch eindeutige Struktur, etwa den Verzeichnisbaum. Begriffsbildung verbindet diese Datenstruktur mit unserer komplexen, unsicheren und subjektiven Erfahrungswelt, beispielsweise wenn wir ein Verzeichnis »Privat« anlegen. Computer können im Wesentlichen nur mit dem formalen Teil arbeiten: Den meisten Programmen ist es egal, ob wir ein Verzeichnis »Urlaub_2022« oder »2147483647« nennen, aber sie können dank der Verzeichnisstruktur dennoch viele nützliche Funktionen anbieten.
Bei der Darstellung von Wissen kommt es also immer auf die Balance zwischen dem Formalen und dem Informellen an. Eine rein informelle Darstellung von medizinischem Wissen wäre zum Beispiel ein Lehrbuch über Krebsdiagnostik. Das ist zwar vielleicht detailliert und umfassend, aber für einen Computer ziemlich unbrauchbar. Das entgegengesetzte Extrem wäre der Maschinencode eines Programms zur Krebserkennung auf Röntgenbildern. Der ist zwar vollkommen formal, aber keine Darstellung von medizinischem Wissen, weil er sich nicht auf Begriffe dieses Fachs bezieht. So lässt sich zum Beispiel nicht sicherstellen, dass das Programm vertrauenswürdig arbeitet. Dagegen verlangt die Zulassung von Medizinsystemen in der EU umfangreiche, von Menschen nachvollziehbare Dokumentation.
Ontologien
Für die eingangs erwähnten Wissensdateien fehlt uns als letzte Zutat noch eine explizite Kodierung, also ein passendes Dateiformat. Zum Beispiel könnte man die Struktur eines Verzeichnisbaums in einer Textdatei darstellen, die für jeden vorhandenen Pfad eine Zeile enthält, ähnlich der Ausgabe des Linux-Kommandos »find . print«. Das Beispiel verdeutlicht, dass die Kodierung im Computer (die Syntax, hier eine Liste von Textzeilen) sich stark von der dargestellten Struktur (der Semantik, hier eine Baumstruktur) unterscheiden kann.
Kommt all das zusammen, dann sprechen wir von einer Ontologie: der formalen, expliziten Spezifikation einer gemeinsamen Begriffsbildung. Das Wort “gemeinsam” deutet hier darauf hin, dass Begriffe in vielen Anwendungen von mehreren Personen geteilt werden sollten, um praktischen Nutzen zu bieten. Explizit sind dabei immer nur die formale Struktur und die Symbole, die auf unsere Begriffe verweisen, zum Beispiel die Verzeichnisnamen. In den letzten Jahren hat sich daneben auch der Begriff Wissensgraph etabliert. Damit bezeichnet man (meist sehr große und stark normalisierte) Datenbanken, die die Merkmale einer Ontologie tragen. Ein typisches Beispiel ist Wikidata, die strukturierte Schwester von Wikipedia, auf die wir später noch zu sprechen kommen.
Obwohl wir jetzt die Bestandteile von Ontologien kennen, sagt uns das noch nicht, wie konkretes Wissen am besten dargestellt werden sollte. Sicherlich eignet sich auch nicht jede menschliche Kompetenz, die wir umgangssprachlich als Wissen bezeichnen, gleich gut für solch eine formale, explizite Spezifikation. Der Fakt “Dresden liegt in Sachsen” lässt sich einfacher formalisieren als das Wissen um die Fähigkeit des Radfahrens. Unser wichtigstes Ausdrucksmittel bleibt die formale Struktur, durch die wir Begriffe miteinander in Beziehungen setzten, die sich anschließend in Software nutzen lassen.
Standardformate
Glücklicherweise haben sich in der Praxis technische Standards für die Arbeit mit Ontologien und Wissensgraphen etabliert, die diese allgemeinen Ideen konkret machen. Federführend war hierbei das W3C (World Wide Web Consortium), dem wir auch die Standardisierung von HTML und XML verdanken. Eine erfreuliche Eigenschaft von W3C-Standards: Sie sind kostenlos und patentfrei, was auch die Implementierung in freie Software fördert.
Ausgangspunkt für die Entwicklung einheitlicher Standards ist die Einsicht, dass viele Ontologien letztlich über recht einfache Beziehungen zwischen Objekten sprechen: Dresden liegt in Sachsen, »/usr/bin/« ist ein Unterverzeichnis von »/usr«, Luca liebt Dominique. Solche Aussagen bestehen aus zweierlei Zutaten: Relationen (wie “liegt in” oder “liebt”) und einzelne Elementen (wie “Dresden” oder “Luca”). Eine Relation beschreibt die Art einer Beziehung und kann jeweils zwischen vielen verschiedenen Paaren von Elementen bestehen, wobei in der Regel deutlich mehr Elemente vorkommen als Relationen. Zum Beispiel könnten wir die gesamte Verzeichnisstruktur eines Dateisystems mit einer einzigen Relation Unterverzeichnis_von ausdrücken.
Solange wir nicht allzu viele Elemente betrachten, können wir solche Aussagen sehr gut grafisch darstellen. Die Abbildung 2 zeigt als Beispiel einige (teils mutmaßliche) Familienbeziehungen des Dichters George Gordon Byron. Jeder der zwölf Pfeile entspricht einer Beziehung zwischen zwei Elementen, wobei wir drei verschiedene Relationen verwenden.
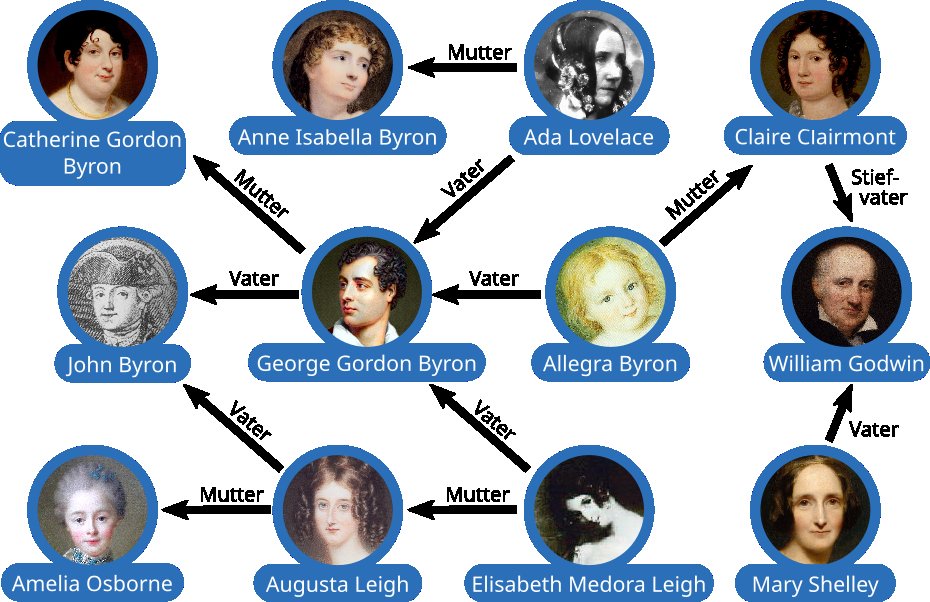
Abbildung 2: Ein Wissensgraph über Beziehungen von Lord Byron: Nicht jeder Stammbaum ist aus mathematischer Sicht eine Baumstruktur.
Zeichnerische Darstellungen von Graphen stoßen schnell an ihre Grenzen, weil schon etwas mehr Elemente zu einem undurchdringlichen Wirrwarr führen. Dennoch vermitteln sie uns die wichtige Idee, dass es hier nicht nur um die Merkmale einzelner Elemente geht, sondern um ihre Verbindungen untereinander. Dabei können auch längere Pfade von Interesse sein, zum Beispiel wenn wir uns fragen, was die Ur-Informatikerin Ada Lovelace mit der Science-Fiction-Pionierin Mary Shelley verbindet. Diese vernetzte Sicht ist es, die dem Begriff Wissensgraph zugrunde liegt.
Wissensgraphen kodieren
Für die Darstellung solcher Graphen wurde der W3C-Standard RDF (Resource Description Framework [1]) entwickelt. Dahinter steht die einfache Idee, einen Graphen als Menge seiner Pfeile darzustellen. Ein Pfeil entspricht hier einer Aussage wie “Luca liebt Dominique”, die die Form Subjekt, Prädikat, Objekt hat. In solchen Tripeln handelt es sich bei Subjekt und Objekt um einzelne Elemente, während das Prädikat auf eine Relation verweist (die RDF eine Property nennt). Die einfachste Darstellung von Graphen in RDF sind Textdateien, in der jede Zeile ein solches Tripel angibt, das N-Triples-Format. Es gibt noch viele andere Dateiformate, aber dahinter steht immer die Grundidee, eine Menge von Tripeln anzugeben.
Und was genau dürfen wir in RDF als Subjekt, Prädikat und Objekt verwenden? Im Prinzip alles, was wir wollen: Schließlich müssen hier alle Begriffe erlaubt sein, die wir für unsere Anwendung brauchen. Aber RDF ermuntert uns, dabei Bezeichner zu vergeben, die wie URLs aussehen. So würden wir vielleicht unser Element “Dresden” mit https://www.dresden.de/id bezeichnen.
Derartige URIs (Uniform Resource Identifier) sehen wie URLs aus, müssen aber im Browser nicht unbedingt zu einer Webseite führen. Das auf den ersten Blick unbequeme Format ist eine der größten Stärken von RDF (und anderen W3C-Standards). Schließlich dienen Ontologien und Wissensgraphen dem Austausch von Wissen, werden also auch übertragen, in neuen Anwendungen eingesetzt und mit anderen Daten kombiniert. Da kann es leicht zu Namenskonflikten zwischen Bezeichnern kommen, zum Beispiel bei Personen gleichen Namens. Die Verwendung von URIs macht zufällige Konflikte dieser Art praktisch unmöglich, sodass gleiche Bezeichner garantiert weltweit dasselbe bedeuten.
Umgekehrt kann es durchaus mehrere Bezeichner für die gleiche Sache geben. Das lässt sich nicht immer verhindern, aber es lohnt sich, nach Möglichkeit bereits etablierte URIs zu verwenden, statt neue zu erfinden. Wir kommen später darauf zurück, wie man dazu Wikidata einspannen kann. Wer dennoch eigene URIs erstellt, baut sie am besten auf einer selbst registrierten Domäne auf. Zum Beispiel sollten URIs unter http://dresden.de durch die Stadt Dresden vergeben werden.
Listing 1 zeigt ein Beispiel für eine RDF-Datei mit vier Tripeln. Das hier verwendete Turtle-Format erlaubt Abkürzungen von URIs (»@prefix«). RDF unterstützt neben diesen URIs auch Werte in konkreten Datentypen. Um die Aussage “Dresden hat 558 848 Einwohner” als RDF-Tripel darzustellen, müssen wir also nicht erst eine URI für »558:*848« finden, sondern können einfach den Datentyp Integer verwenden. Andere Datentypen erlauben uns, Texte zu speichern, was vor allem zur Angabe von Beschriftungen und Dokumentationen für menschliche Nutzer wichtig ist. In vielen RDF-Anwendungen bekommen wir daher überhaupt keine URIs zu Gesicht. Möchten Sie mehr über RDF und seine Verwendung erfahren, finden Sie dazu online Lehrmaterialien und Videos [2].
Listing 1
RDF-Beispiel
@prefix ex: <https://example.org/> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . ex:AdaLovelace ex:father ex:GeorgeGordonByron . ex:AdaLovelace ex:birthplace ex:London . ex:London ex:website <https://www.london.gov.uk> . ex:London rdfs:label "London" .
OWL-Ontologien
RDF-Graphen können bereits die wesentlichen Merkmale einer Ontologie erfüllen: Sie haben eine formale Struktur, lassen sich explizit kodieren und unterstützen die Verwendung gemeinsamer Begriffe, die wir dank URIs eindeutig bezeichnen können. Trotzdem sind sie aus technischer Sicht letztlich nur Graphdatenbanken, deren Fähigkeit zur Wissensrepräsentation sich auf die Darstellung eines Netzwerks aus Fakten beschränkt.
Um zu verstehen, warum das nicht ausreicht, betrachten wir noch einmal das Beispiel des Verzeichnisbaums im Dateisystem. Wie wir bereits bemerkt hatten, kann man so einen Baum leicht als RDF-Graph kodieren. Selbst die einfachsten Programme “verstehen” aber auch, dass Verzeichnisse eine Art von Mengen darstellen, die ineinander enthalten sein können. Wenn wir zum Beispiel ein Verzeichnis löschen, dann werden dabei auch (rekursiv) alle Unterverzeichnisse gelöscht. Dieses scheinbar banale Wissen lässt sich in RDF nicht formal darstellen: Dem Graph an sich sieht man nicht an, ob er einen Verzeichnisbaum, eine Hierarchie von Vorgesetzten oder ein Netzwerk von Routern darstellt.
Für einzelne Anwendungen lässt sich dieses Problem durch die Standardisierung des Vokabulars (also der verwendeten URIs) lösen. Wenn zum Beispiel allgemein bekannt wäre, dass die URI https://example.org/subdirectory die Unterverzeichnisrelation kodiert, dann könnten Programme das nutzen. Das Wissen, was ein Unterverzeichnis eigentlich ist, wäre dann impliziter Teil des Programmcodes und nicht in RDF dargestellt. Da Mengen und ihre Beziehungen in sehr vielen Anwendungen eine Rolle spielen, ist es sinnvoll, eine explizite Darstellung für solches Wissen einzuführen.
Hier setzt der W3C-Standard OWL (gesprochen “Aul”) an [3]. Das steht eigentlich für Web Ontology Language, aber die englische Eule (“Owl”) gefiel der Standardisierungsgruppe offenbar besser als WOL. Ein Kernkonzept von OWL sind sogenannte Klassen, die Mengen von Elementen beschreiben. Klassen können andere Klassen enthalten – wir sprechen dann von Subklassen – und so eine Hierarchie bilden. Wenn Sie jetzt wieder an unser Beispiel mit den Verzeichnissen denken, dann liegen Sie schon ganz richtig. OWL-Klassen bezeichnet man ebenfalls mit URIs, sodass sie sich wie selbstverständlich in die Welt von RDF einfügen.
Die Tabelle “OWL-Klassen” zeigt Beispiele für in OWL darstellbare Aussagen. OWL kann vielfältige Beziehungen zwischen Klassen, Properties und einzelnen Elementen kodieren. Die Beispiele aus der Tabelle geben uns eine erste Vorstellung, was dabei möglich ist. Wir verwenden hier die Standardsyntax OWL-FSS, allerdings mit lesbaren Namen statt der eigentlich verlangten URIs. Zuordnungen von Elementen zu Klassen klappen wie in Zeile 1. Zeile 2 gibt an, dass eine Klasse (»Dichter«) die Teilmenge einer anderen (»Autor«) ist. Die Zeilen 3 und 4 folgen demselben Muster, mit dem Unterschied, dass hier jeweils eine der Klassen durch einen komplizierteren Ausdruck ersetzt wurde.
|
|
informelle Aussage |
formale Kodierung |
|---|---|---|
|
1 |
Byron ist ein Dichter. |
»ClassAssertion( Dichter Byron )« |
|
2 |
Dichter sind Autoren. |
»SubClassOf( Dichter Autor )« |
|
3 |
Jeder Dichter hat irgendein Gedicht geschrieben. |
»SubClassOf( Dichter ObjectSomeValuesFrom( hatGeschrieben Gedicht ))« |
|
4 |
Autoren, die ein Gedicht geschrieben haben, sind Lyriker. |
»SubClassOf( ObjectIntersectionOf( Autor ObjectSomeValuesFrom( hatGeschrieben Gedicht )) Lyriker )« |
In Zeile 3 bilden wir mit »ObjectSomeValuesFrom« die Klasse aller Elemente, die über die Property »hatGeschrieben« eine Beziehung zu einem Element der Klasse »Gedicht« haben. Dieser Ausdruck kommt auch in Zeile 4 vor, wo wir aber zusätzlich mit »ObjectIntersectionOf« die Schnittmenge zur Klasse aller Autoren bilden. In OWL kann man auf vielerlei Arten Beschreibungen für Klassen konstruieren, die man dann mit »SubClassOf« in Beziehung setzt. Es gibt noch viele andere syntaktische Standardformate für OWL, aber in der Praxis bekommt man diese eher selten zu Gesicht, da freie Ontologie-Editoren wie Protégé [4] und WebProtégé [5] meist bequemer sind (Abbildung 3).
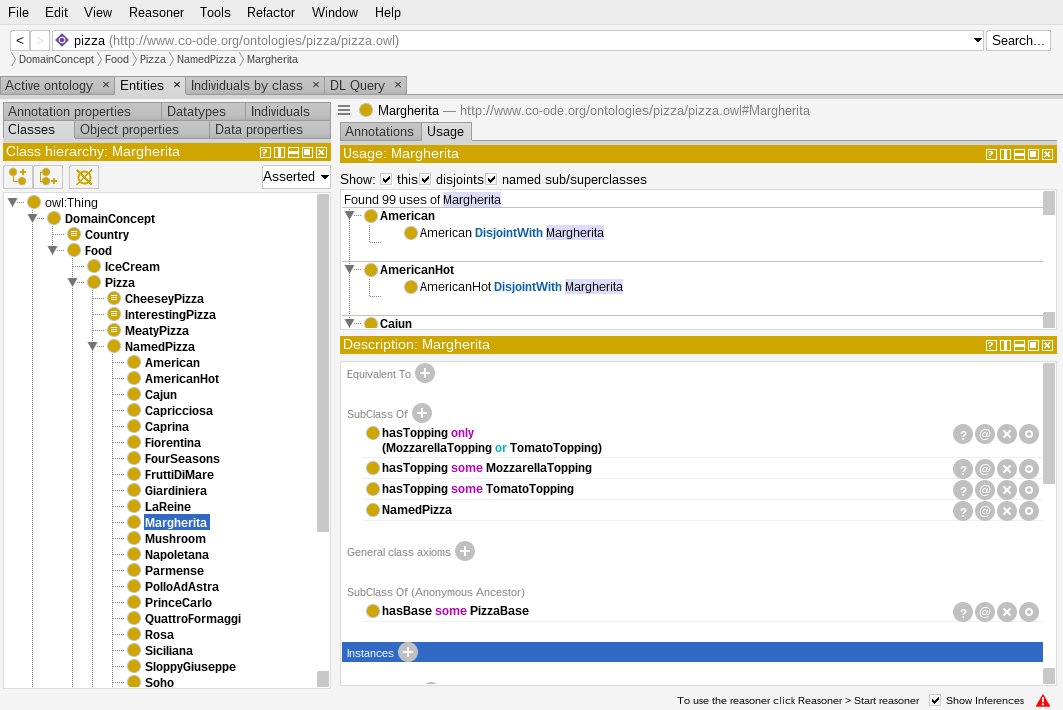
Abbildung 3: Der Ontologie-Editor Protégé erspart das direkte Editieren von OWL-Syntax.
Kunst der Deduktion
OWL-Ontologien lassen sich dazu nutzen, zusätzliche Informationen abzuleiten. Aus den ersten beiden Zeilen in der Tabelle “OWL-Klassen” folgt zum Beispiel, dass es sich bei Byron um einen Autor handelt. Dagegen kann man aus den Zeilen 2, 3 und 4 ableiten, dass jeder Lyriker ein Dichter ist. Wir können uns die Kodierung vieler Aussagen also sparen und stattdessen darauf vertrauen, dass sie automatisch abgeleitet werden. Diese Einsparung hilft bei der Pflege von Ontologien, denn das manuelle Speichern abgeleiteter Informationen ist fehleranfällig und erfordert ständige Anpassungen – zum Beispiel, wenn wir unsere Definition von »Lyriker« irgendwann ändern möchten.
Automatische Deduktion erweist sich vor allem dort als hilfreich, wo man sehr umfangreiche, exakte und systematische Wissensstrukturen benötigt. Ein Beispiel ist die International Classification of Diseases (ICD) der WHO, eine Hierarchie Zehntausender möglicher Ursachen für gesundheitliche Probleme, die in Deutschland und vielen anderen Ländern für Abrechnung und Statistik verwendet wird. Die detaillierte Klassifikation enthält Kuriositäten wie “Benutzer eines dreirädrigen Kraftfahrzeuges bei Zusammenstoß mit Fahrrad verletzt” (ICD-Code V31) und “Spätfolge des Gestoßenwerdens von einer nichtgiftigen Echse” (ICD-Code W59.02.XS). Das manuelle Erstellen einer Hierarchie solcher Begriffe ist sehr aufwendig, ihre formale Beschreibung dagegen recht naheliegend. Tatsächlich arbeitet ICD seit Version 11 mit OWL und veröffentlicht auch Verknüpfungen zu anderen medizinischen Ontologien.
Der OWL-Standard legt genau fest, welche Ableitungen aus einer OWL-Ontologie folgen. Diese exakt zu berechnen, stellt aber keine einfache Aufgabe dar, und es empfiehlt sich der Einsatz professioneller Software. Als leistungsfähige Open-Source-Tools bieten sich zum Beispiel ELK [6] und HermiT [7] an, die sich beide auch direkt in Protégé nutzen lassen.
Wikidata
Was Wissensrepräsentation in der Praxis von einfacher Datenverwaltung unterscheidet, ist letztlich nicht die Verwendung bestimmter Standards wie OWL oder RDF, sondern das Ziel, menschliches Wissen über die Grenzen einer bestimmten Anwendung hinaus zu teilen und technisch nutzbar zu machen. Diese Idee stand auch am Anfang von Wikidata, dem bisher größten gemeinschaftlich erstellten Wissensgraphen und einem der aktivsten Projekte der Wikipedia-Familie.
Wikidata wurde 2012 ins Leben gerufen und hat seitdem über 1,4 Billionen Aussagen zu nahezu 100 Millionen Objekten zusammengetragen. Die Repräsentation von Wissen in Wikidata wurde dabei stark von RDF inspiriert. Properties dienen der Darstellung von Beziehungen (inzwischen sind es über 10 000), und einzelne Aussagen ähneln RDF-Tripeln, die allerdings noch Zusatzinformationen tragen können. So lässt sich zum Beispiel angeben, in welchem Zeitraum eine Aussage gültig war oder welche Belege es für eine Behauptung gibt. Wikidata bietet alle Daten auch in einer RDF-Kodierung an, die aber pro Aussage mehrere Tripel benötigt. Als RDF-Graph umfasst Wikidata daher über 14 Billionen Tripel. Trotz dieser enormen Größe lassen sich Datenbankabfragen über diesem Wissensgraphen online ausführen [8]. Deshalb stellt Wikidata für viele Programme eine wichtige Datenquelle dar.
Nebenbei liefert Wikidata die Links zu Wikipedia-Artikeln in anderen Sprachen. Eine ausführliche Beschreibung dieser faszinierenden Ressource und ihrer Community würde einen weiteren Artikel benötigen. Hier sei daher nur noch erwähnt, dass sich Wikidata auch als nützliche Quelle von URIs für eigene Wissensgraphen und Ontologien anbietet. Jedes Element in Wikidata hat eine QID, zum Beispiel Q46 (der Kontinent Europa), Q3143 (der Jupitermond Europa) und Q1272879 (das Segelschiff Europa). Die QID findet man in der Suche auf Wikidata.org oder über den Wikidata-Link im jeweiligen Wikipedia-Artikel. Die zugehörige URI hat einen zusätzlichen vorderen Teil, zum Beispiel https://www.wikidata.org/entity/Q3143. Möchten Sie die RDF-Version der Daten im Browser sehen, hängen Sie an diese URI noch http://.nt an. Viele Wissensgraphen und Datenbanken nutzen QIDs beziehungsweise URIs, um sich nicht nur mit Wikidata zu vernetzen, sondern auch untereinander.
In Zukunft
Wissensrepräsentation ist heute eine wichtige Technologie mit vielen Anwendungen, vom künstlich intelligenten Assistenten auf unserem Smartphone bis zum klinischen Informationssystem im Krankenhaus. Offene Standards, leistungsfähige Open-Source-Tools und freie Wissensgraphen machen riesige Wissensmengen allgemein verfügbar.
Bei all diesen Erfolgen sollten wir jedoch nicht aus den Augen verlieren, wie weit wir noch von der Darstellbarkeit großer Teile menschlichen Wissens entfernt sind. Dazu zählt nicht nur das intuitive Wissen, das wir selbst kaum beschreiben können (etwa, wie man mit Stäbchen isst oder wie man das Alter einer Person am Klang ihrer Stimme abschätzt). Selbst das ziemlich förmliche Wissen im Text eines Wikipedia-Artikels geht weit über das hinaus, was sich heute in Wikidata darstellen lässt. Eines der spannendsten aktuellen Wikimedia-Projekte ist Abstract Wikipedia, das darauf abzielt, eine sprachunabhängige Darstellung solcher Texte zu entwickeln. Im ersten Schritt soll dafür eine Sammlung von Wissen über programmierte Funktionen entstehen, die später zur Texterzeugung dienen können.
Einen ganz anderen Ansatz verfolgt das traditionsreiche KI-Projekt Cyc. Mit seinen komplexen Formalismen zur logischen Darstellung von Wissen zielt es auf hohe Ausdrucksstärke ab, während für OWL die praktische Berechenbarkeit aller Deduktionen wichtiger war. Das Dilemma der formalen Wissensrepräsentation besteht darin, dass man nicht beides auf einmal haben kann. Die ultimative Darstellung von Wissen kann es daher wohl nicht geben, aber das stellt zumindest sicher, dass gute Ideen in Forschung und Anwendung auch in Zukunft gebraucht werden. (jcb/jlu)
Der Autor
Markus Krötzsch ist Professor für wissensbasierte Systeme an der TU Dresden und Direktor einer der drei deutschen Konrad Zuse Schools of Excellence in AI (https://secai.org). Er war an der Standardisierung von OWL sowie der Entwicklung von Wikidata beteiligt. Seine aktuelle Forschung widmet sich der formalen Wissensrepräsentation und ihrer Verbindung mit anderen KI-Methoden.
Infos
- RDF: https://www.w3.org/RDF
- Knowledge Graphs: https://iccl.inf.tu-dresden.de/w/images/b/bf/KG2018-Lecture-01-overlay.pdf
- OWL: https://www.w3.org/OWL
- Protégé: https://protege.stanford.edu/
- WebProtégé: https://webprotege.stanford.edu
- ELK: https://www.cs.ox.ac.uk/isg/tools/ELK
- HermiT: http://www.hermit-reasoner.com
- Wikidata-Hilfe zu Abfragen: https://www.wikidata.org/wiki/Wikidata:SPARQL_query_service/Wikidata_Query_Help/de





