
© tiero / 123RF.com
Aus großen Virtualisierungsumgebungen ist Software Defined Networking nicht mehr wegzudenken. Dessen einzige weitverbreitete freie Implementierung ist OpenFlow im Gespann mit Open vSwitch und Open Virtual Network.
Virtualisierung und Netzwerk – diese beiden Themen ließen sich lange Zeit nur schwer unter einen Hut bringen. Wer Mitte der 2000er erste Virtualisierungsversuche mit KVM oder Xen unternahm, betrieb eine virtuelle NIC (Network Interface Card), die im Hintergrund auf dem Host an eine Bridge gekoppelt war. Sie leitete ihre Pakete wiederum an die physische Netzwerkkarte weiter. Der virtuelle Teil war die virtuelle Netzwerkkarte innerhalb der VM, bei der man je nach genutztem Hypervisor sogar das Modell festlegen konnte. Damit wollten die Hersteller der damals gängigen Emulatoren es ihrer Nutzerschaft einfacher machen, die Boards in den virtuellen Systemen zu nutzen. Speziell für Intels e100, eine der am häufigsten emulierten NICs, gab es im Kernel bereits gut funktionierende Treiber.
Dass es sich bei diesem Modus Operandi tatsächlich um Netzwerkvirtualisierung handelte, redete man sich seinerzeit zwar gern ein, doch wirklich gestimmt hat das nie. Damit bei der virtuellen NIC im Gastsystem die passenden Pakete ankamen, war sowohl auf dem Host als auch auf den Switches, an die dieser angeschlossen war, einiges an Konfiguration notwendig. Das starre Netzwerkdesign konventioneller Umgebungen hatte sich schließlich nicht geändert: Eine sternartige Struktur mit immer geringeren Datenraten an den äußeren Gliedern galt auch deshalb als Königsweg, weil das Skalieren in die Breite auf der Netzwerkebene seinerzeit keine Voraussetzung war. Traffic-Trennung, Sicherheit und Compliance erreichte man entweder, indem man für einzelne Kunden autarke Setups mit eigener Hardware konstruierte oder VLANs baute, die für Abschottung sorgten.
Automation ist Pflicht
Das Konzept der Cloud macht vor keinem Bereich der IT halt, auch nicht vor Netzen und Netzwerkkonfigurationen (Abbildung 1). Es liegt auf der Hand: Wenn Firmen, die zuvor einzelne Setups im Kundenauftrag gebaut haben, mit einem Mal Plattformanbieter werden, muss sich die Art und Weise ändern, in der sie das Netz konzipieren. Skalierbarkeit ist in der Cloud schließlich das höchste Ziel. Die Economy of Scale stellt sich nur dann ein, wenn sich einerseits gut funktionierende Dienstleistungen möglichst automatisiert herstellen und andererseits so einfach wie möglich zahllose Male verkaufen lassen. Wer die Art und Weise, in der konventionelle Netze gewartet werden, im Licht der Cloud-Anforderungen betrachtet, merkt schnell, dass beides nicht zusammenpasst. Völlig undenkbar wäre es etwa, für neue Kunden in der Cloud erst einmal auf allen Switches VLANs anzulegen, bevor diese VMs starten können. Auch das manuelle Anlegen von Firewall-Regeln, das früher ebenso fixer Teil jedes Kunden-Onboardings war, skaliert in riesigen Umgebungen nicht.
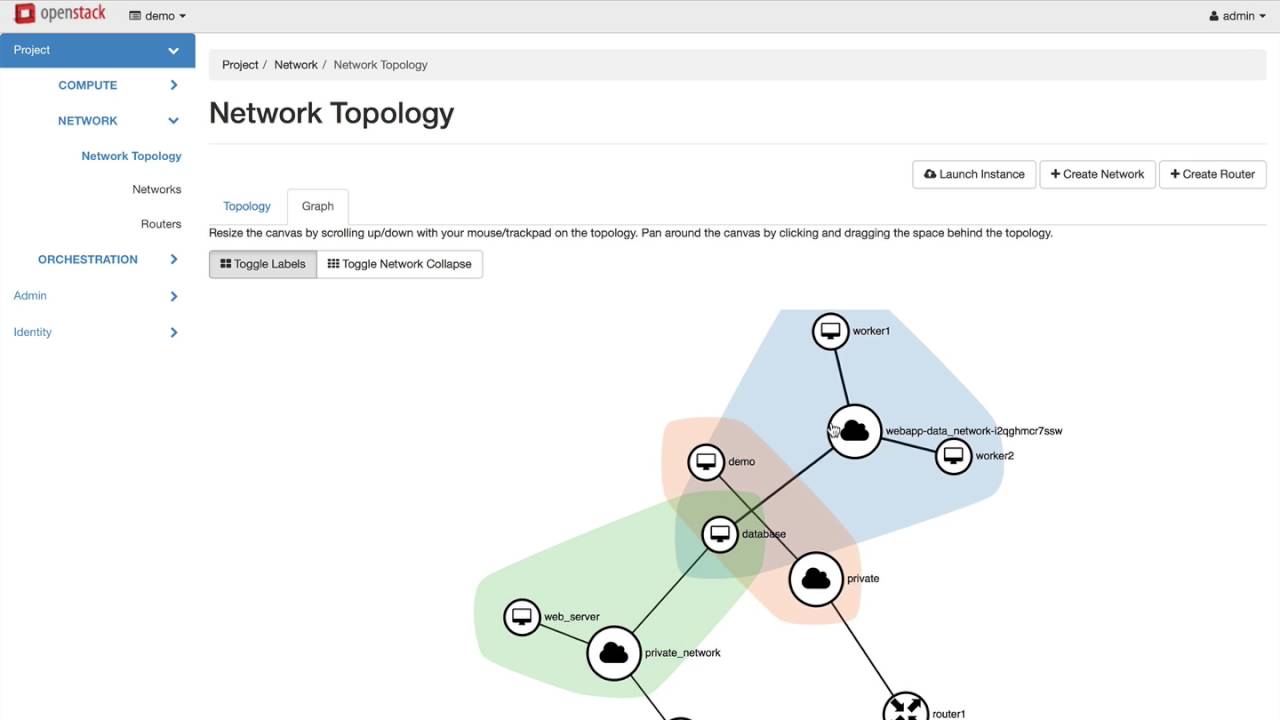
Abbildung 1: Konsequent zu Ende gedacht, bedeutet die Idee hinter Software Defined Networking nichts anderes, als dass wie heute bei OpenStack jeder Nutzer die komplette virtuelle Topologie seiner Umgebung selbst bestimmen kann.
Nun ist diese Herausforderung bekanntlich nicht neu, und technische Lösungen dafür liegen auf dem Tisch. Zahllose kommerzielle SDN-Implementierungen existieren, die Teilaspekte des Problems auf ihre ganz eigene Weise lösen. Wer sie nutzt, der legt sich allerdings fast immer zwangsläufig mit einem bestimmten Hersteller ins Bett, was die Sicherheit des Investments in vielen Fällen ebenso gefährdet wie die Wartbarkeit der Plattform. Die Open-Source-Community hat bis dato nur eine Lösung für Software Defined Networking hervorgebracht, die nennenswerte Verbreitung und kommerzielle Relevanz erreicht hat, nämlich Open vSwitch. Dieser Artikel geht auf die Grundlagen von Open vSwitch ein und klärt über aktuelle Entwicklungen auf.
Nicht nur Open vSwitch
Wir haben eben behauptet, Open vSwitch sei die einzige SDN-Lösung auf Basis freier Software. Das ist zumindest ungenau, denn Open vSwitch ist de facto “nur” eine Abstraktionsebene für eine andere Technologie, Open Flow. Um die Idee hinter Open Flow zu verstehen, ist ein kurzer Ausflug in die Netzwerktheorie hilfreich.
Klassische Netzwerkgeräte, etwa Switches, bestehen aus einer Control Plane und einer Forward Plane. Die Forward Plane leitet eingehende Pakete weiter. Die Control Plane implementiert Features wie VLANs oder Firewall- und Filterregeln. Wollte eine Computing-Plattform etwa auf Basis von OpenStack Switches so konfigurieren, dass neue Kunden problemlos virtuelle Netze anlegen können, müsste sie unmittelbar die Netzwerkgeräte umkonfigurieren, also deren Control Plane beeinflussen. Solche Ansätze gibt es zwar, doch den meisten Admins ist nicht wohl dabei, die Konfiguration von Hardware automatisiert durch eine Lösung wie OpenStack verändern zu lassen. Zu groß ist hier die Angst, den Überblick und die Kontrolle zu verlieren.
Praktisch bleibt damit nur eine Alternative: Die Funktionalität der Control Plane muss von den Switches in die Geräte wandern, die das Netzwerk bei den Zielinstanzen (also den VMs) bilden. In erster Linie virtualisiert das Konzept des Software Defined Networking also gar nicht die Netzwerkkarte, sondern die Control Plane der Switches. Ist die allerdings als Software auf allen Systemen implementiert, lässt sie sich dort auch problemlos durch laufende Software beeinflussen.
Open Flow kommt in diesem Konstrukt eine zentrale Rolle zu, denn es bietet quasi die Sprache auf der Systemebene an, um Anweisungen für den Verlauf (den Flow) von Paketen zwischen den virtuellen NICs auf unterschiedlichen Systemen zu implementieren. Open Flow ist ein standardisiertes Protokoll für Control-Plane-Anweisungen, das sich auf ganz regulären Linux-Servern zur Verwaltung von Paketflüssen einsetzen lässt. Formal handelt es sich um ein Transportprotokoll. Dass sich Open Flow freilich auch auf Netzwerkhardware wie Switches, Routern und Firewalls implementieren lässt, greift dieser Artikel weiter unten noch einmal auf.
Im Kernel verankert
Die Open-Flow-Implementierung des Linux-Kernels gilt aus heutiger Sicht als robust und stabil. In der Tat ist Open Flow unter Linux auf der Systemebene unmittelbar im Kernel verankert, aus Performance- und Effizienzgründen wäre das auch gar nicht anders möglich. Allerdings: Die In-Kernel-Implementierung von Open Flow in Linux taugt tatsächlich nur, um Pakete nach konfigurierten Regeln durch die Netzwerkgeräte und verschiedenen Stationen des Systems zu leiten. Sie selbst kann keine Regeln setzen. Das wirft freilich die Frage auf, wozu eine Control Plane ohne Regeln gut sein soll. Und wie lässt der Linux-Kernel sich mit Regeln versorgen?
An dieser Stelle kommt Open vSwitch ins Spiel. Open vSwitch siedelt sich in einem imaginären Stack aus Netzwerktechnologien eine Etage über Open Flow an. Es kann Regeln hinterlegen, die Open Flow dann nutzt. So erklärt sich auch der Name: Open vSwitch steht für Open Virtual Switch, weil Open vSwitch auf den Systemen auf Basis offener Standards eine vollständige Control Plane für Switches anlegt.
Die eigentliche Systemkonfiguration unterscheidet sich dabei gar nicht so sehr von jener, die man von Netzwerkvirtualisierung auf konventionellen Systemen kennt. Auch Open vSwitch setzt in der Regel voraus, mittels Bridge – allerdings einer Open vSwitch-Bridge – mit einer realen Netzwerkkarte verbunden zu sein. Virtuelle Instanzen, die auf den Systemen dann laufen, verbinden sich anders als in konventionellen Umgebungen allerdings nicht direkt mit der Bridge, sondern stattdessen mit einer virtuellen Brücke. Anders formuliert: Jede VM ist unmittelbar mit einem virtuellen Switch verbunden. Pakete, die dort ein- und ausgehen, durchlaufen auf Ebene des Linux-Kernels das gesamte Open-Flow-Regelwerk.
Was Open Flow kann
Das wirft freilich die Frage auf, welche Arten von Regeln sich denn mit Open Flow im Kernel hinterlegen lassen. Zweifelsohne zu den wichtigsten Features gehört das Tagging. Es bietet in Open-Flow-Setups eine ähnliche Funktionalität wie VLANs in konventionellen Control Planes. Es sorgt dafür, dass Pakete eines bestimmten Ursprungs oder für ein bestimmtes Ziel wirklich nur dort ankommen, wo sie hinsollen. Weil das Abarbeiten von Open-vSwitch-Regeln auf der Kernel-Ebene geschieht, gibt es für Gastsysteme auch keine Möglichkeit, das zu umgehen. Eine virtuelle Instanz, deren virtuelle Netzwerkkarte das Tag 25 hat, wird Pakete für NICs mit dem Tag 26 niemals sehen.
Um diese Features zu implementieren, bedient sich Open Flow verschiedener Techniken. Ein Klassiker ist die Verkapselung, wobei Open Flow mehrere Modi anbietet, darunter GRE (Generic Routing Encapsulation) oder VxLAN. Implizit wie explizit lassen sich mit Open Flow zudem Blockregeln definieren: Eingehende Pakete für Tags, zu denen es lokal keine passenden virtuellen NICs gibt, werden einfach verworfen.
Das Plus von Open vSwitch
In der Geschichte der SDN-Entwicklung für Linux war Open vSwitch so etwas wie der erste Versuch, Open-Flow-Regeln aus Software heraus steuerbar zu machen. Wie beschrieben hilft Open Flow alleine nicht weiter, weil es eine Engine ist, die selbstständig noch keine Regeln festlegt. Kommunikationsregeln in Open Flow brauchen skalierbare Plattformen wie OpenStack, um sinnvoll zu funktionieren, wie ein paar Beispiele zeigen.
Wenn das Motto der Economy of Scale gelten soll, bedeutet das für Clouds etwa, dass der Workload jedes einzelnen Kunden zu jedem Zeitpunkt auf jedem Compute-Knoten einer Plattform laufen können muss. Keine Rolle darf dabei spielen, welche VMs anderer Kunden zum Zeitpunkt X auf demselben System laufen. Und schon gar nicht darf der Traffic der beiden Systeme sich auch nur irgendwie ins Gehege kommen. Das wäre nicht nur ein riesiges Sicherheitsproblem, sondern auch ein eklatanter Compliance-Verstoß im Sinne der DSGVO, der schnell teuer werden kann.
In der Anfangszeit von OpenStack versuchten dessen Entwickler, sich mit einer Krücke zu behelfen: Nova-Network (Abbildung 2) gehörte zur Virtualisierungskomponente Nova und richtete ein rudimentäres SDN ein. Das war aber weder besonders reich an Features noch sonderlich schnell. Bald entstanden im Projekt deshalb Begehrlichkeiten, Open vSwitch sinnvoll in OpenStack zu integrieren, und im Kontext der SDN-Komponente Neutron nahm man eben dies in Angriff.
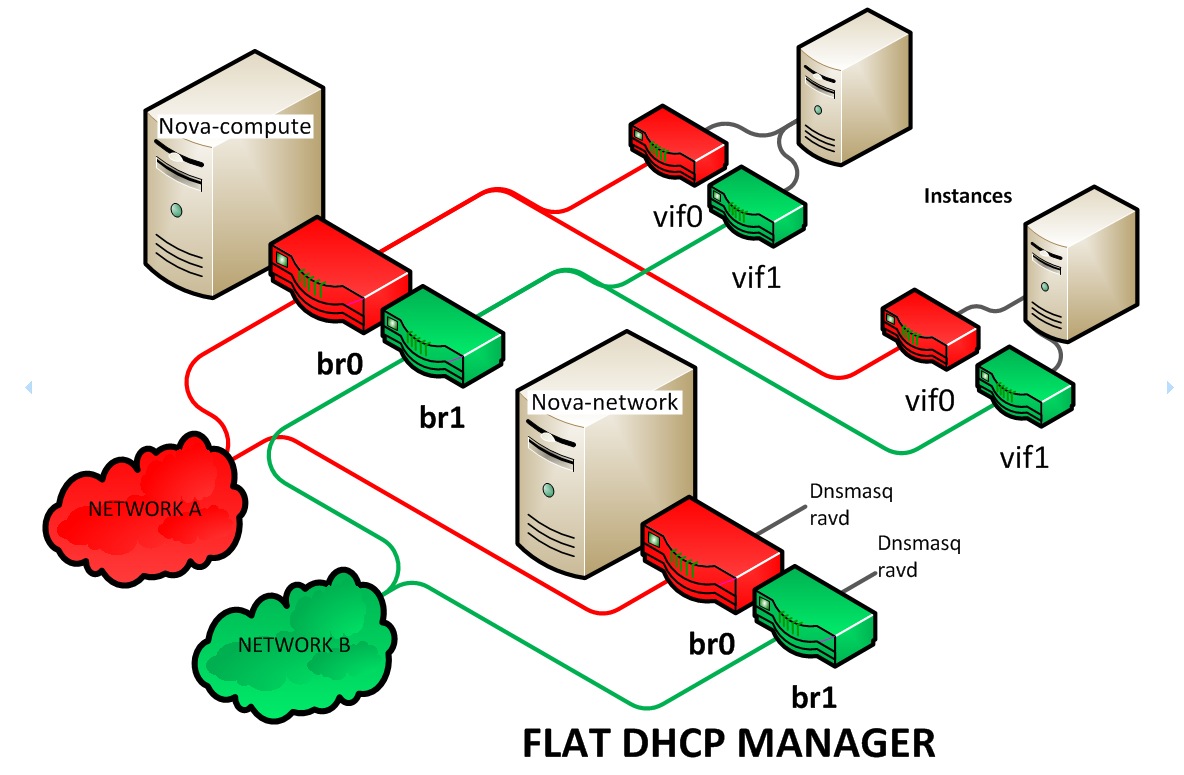
Abbildung 2: Nova-Network war OpenStacks erster Versuch virtueller Netze auf Basis von Bridges und VLANs. Mit SDN hatte das nicht viel zu tun, und es funktionierte auch nicht gut. Quelle: OpenStack
Neutron fußt auf einem Server-Agent-Modell. Auf den einzelnen Compute-Knoten lief also ein Agent (der sogenannte L2-Agent), der die zentral in Neutron hinterlegte Netzwerkkonfiguration in Open-vSwitch-Regeln konvertierte und per Open vSwitch lokal aktivierte. Open vSwitch selbst wiederum hinterlegte die passenden Open-Flow-Regeln im Kernel, sodass ein deutlich besseres und stabileres SDN möglich wurde.
Früh einigten sich die Entwickler auf etliche Konventionen. Traffic zwischen den Compute-Knoten etwa war entweder per GRE verkapselt oder in VxLANs sortiert, um eine Trennung zu ermöglichen. Der L2-Agent auf den Hosts sorgte dafür, dass jede VM nur Ports mit solchen Tags hatte, die zu ihrem lokalen Netzwerk gehörten. Nicht zu unterschätzen war zudem die Notwendigkeit, für VMs eine Verbindung zur Außenwelt herzustellen. In den frühen OpenStack-Jahren gab es dafür die Network Nodes. Mittlerweile hat sich der Ansatz durchgesetzt, dass jeder Knoten mit Netzwerkanbindung ein solcher Network Node sein kann. Open vSwitch kümmert sich im Hintergrund darum, dass Pakete aus den virtuellen Switches per Bridge den Weg ins echte Internet finden.
Alles gut? Eher nicht …
Der beschriebene Mechanismus klingt im ersten Moment vollständig und scheint geeignet, ganze Switch-Architekturen durch SDNs auf Basis von Open Flow und Open vSwitch zu ersetzen. Unternehmen, die mit dieser Technik versuchten, große skalierte Netze zu bauen, merkten jedoch schnell, dass der Ansatz alles andere als perfekt war. Gerade beim so wichtigen Thema Performance ergaben sich eklatante Probleme. Retrospektiv betrachtet ist heute völlig klar, warum, doch hinterher weiß man bekanntlich immer mehr.
Was die Open-vSwitch-Entwickler etwa nicht hinreichend bedacht hatten, war die Art und Weise, wie diverse Netzwerkprotokolle im Netzwerk-Stack oberhalb von SDN funktionieren. Ein banales Beispiel ist TCP/IP: Wollen zwei Systeme per IPv4 miteinander kommunizieren, kommt vorher fast immer ARP zum Einsatz, um die passenden MAC-Adressen zu ermitteln. MAC-Adressen gibt es freilich auch bei virtuellen Netzwerkkarten von virtuellen Maschinen. Wie bei echtem Blech müssen zwei VMs auf zwei verschiedenen Compute-Knoten, die miteinander reden wollen, zunächst die MAC-Adressen der Gegenseite herausfinden.
Allerdings hat Open vSwitch keine übergeordnete Datenbank oder Lookup-Funktion, die auf den einzelnen Systemen einen ARP-Request abfangen und beantworten könnte. Stattdessen muss in einem reinen Open-vSwitch-Setup tatsächlich jede Instanz, die mit einer anderen Instanz sprechen will, eine ARP-Anfrage stellen und erfolgreich eine Antwort erhalten. Kombiniert man diese Eigenschaft nun mit den zuvor beschriebenen GRE- oder VxLAN-Tunneln, die zwischen allen Compute-Knoten, den Controllern und den Netzwerkknoten existieren, wird einem schnell die Dimension der Katastrophe bewusst: Jede ARP-Abfrage in OpenStack erzeugte einen regelrechten Wust an Overhead-Traffic innerhalb der gesamten Installation.
Schlimmer noch: Das Design von Open vSwitch ließ kaum einen schnellen oder einfachen Fix zu. Obendrein war absehbar, dass die Technik auf diese Weise kaum für ihren eigentlichen Einsatzzweck nutzbar war, nämlich die Schaffung großer, skalierter Netze. Jede zusätzliche VM und jedes neue virtuelle Kundennetz würde den Overhead schließlich weiter erhöhen, sodass die physischen Grenzen der Netzwerk-Links irgendwann erreicht werden.
Open Virtual Network
Für die Open-Source-SDN-Gemeinde hieß es entsprechend: zurück ans Zeichenbrett. Durchaus nützlich dürfte für die Entwickler der Umstand gewesen sein, dass etliche Unternehmen in kommerziellen Produkten bereits vorgemacht hatten, wie das Problem sich in den Griff bekommen lässt. Nicira beispielsweise war selbst lange eine Triebfeder hinter Open vSwitch, vermarktete das eigene Produkt Nicira NVP allerdings mit einigen proprietären Zusatz-Features, bis schließlich VMware die gesamte Firma schluckte.
Kurzerhand begann man damit, quasi eine Art Aufsatz für den Aufsatz zu bauen – an der grundsätzlichen Funktionalität von Open vSwitch gab es schließlich nichts zu meckern. Das Produkt sollte also auch der Kern einer neuen Lösung bleiben. Ab Werk war es lediglich etwas zu minderbemittelt, sodass die Entwickler es schlauer machen mussten. Den neuen Ansatz taufte man auf den Namen Open Virtual Network oder kurz OVN. Architektonisch ist OVN so konzipiert, dass es Open vSwitch zwar als Werkzeug verwendet, um auf den einzelnen Systemen SDN-Konfigurationen zu hinterlegen. Dabei greift es allerdings auf deutlich mehr Informationen zurück als Open vSwitch selbst und erzeugt implizit ein viel komplexeres Open-Flow-Regelwerk.
Zu diesem Zweck spielen mehrere Komponenten zusammen: Auf den Compute-Knoten einer mit OVN vernetzten Plattform läuft neben dem OVS-Switch-Daemon der Ovsdb-Server, der die gesamte Open-vSwitch-Konfiguration über den ganzen Cluster hinweg enthält. Open Ovsdb unterstützt einen Cluster-Modus, ist also implizit hochverfügbar. Das hilft, falls ein Netzwerkcontroller ausfällt und ein anderer dessen Aufgaben übernehmen muss.
Auf den einzelnen Compute-Knoten folgt die OVN-Implementierung der klassischen Einteilung in North- und Southbound-Traffic, und genau hier passiert der magische Teil, der Open vSwitch fehlt (Abbildung 3): Die Southbound Database kennt nämlich systemweit alle logischen Ports, alle physischen Endpunkte auf den Maschinen und die notwendige Pipelines für Pakete, die sich aus diesen Informationen ergeben. In OVN-Setups müssen sich zwei VMs also nicht mehr suchen, sondern dank implizit gesetzter Open-Flow-Regeln ist klar, wo der Traffic hingehört. Das ist gegenüber Open vSwitch im Solo-Betrieb eine erhebliche Verbesserung.
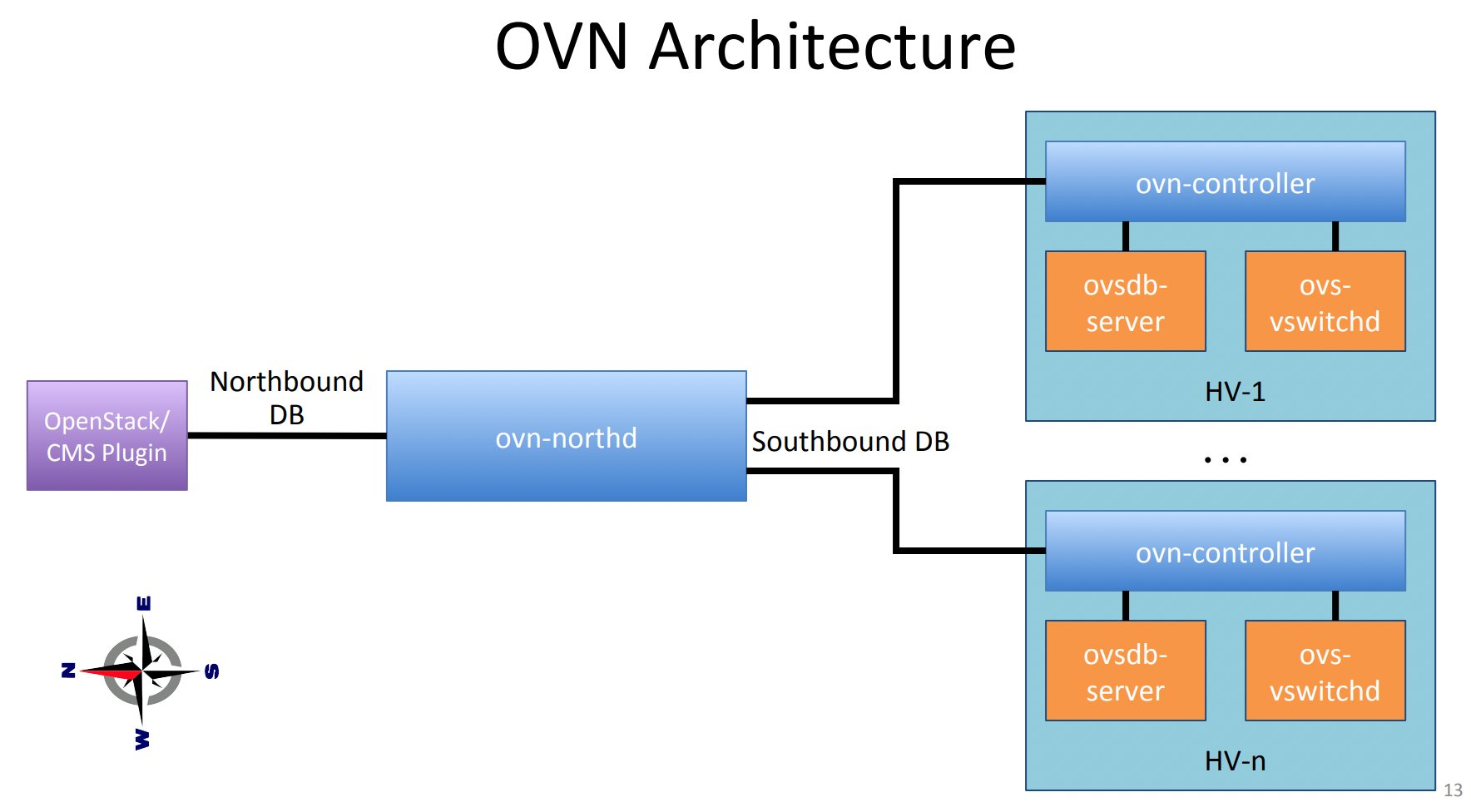
Abbildung 3: Open Virtual Network erweitert Open vSwitch um einen North- und einen Southbound-Controller, die alle logischen Elemente im gesamten Netz kennen und entsprechende OpenFlow-Regeln setzen. Quelle: Open Virtual Network
Erhöhte Komplexität
Umsonst gibt es die verbesserte Funktionalität von Open Virtual Network allerdings nicht. Bereits auf den ersten Blick fällt auf, dass Admins es mit mehr Komponenten zu tun bekommen, nämlich dem Virtual Switch Daemon von OVN sowie den North- und den Southbound-Daemons auf den einzelnen Hypervisor-Systemen. Obendrein bietet OVN eigene Tools an, um durch OVN hinterlegte Open-Flow-Regeln zu durchforsten und Traffic durch diese zu verfolgen.
So absurd es auch klingen mag: Weil die Kommunikation der Werkzeuge wie »ovn-sbctl« und »ovn-nbctl« mit ihrem jeweiligen Daemon SSL-verschlüsselt erfolgt, wird es bereits zur Herausforderung, eine Kommandozeile mit den passenden SSL-Parametern zu bauen. Hinzu kommt die Notwendigkeit, die passenden Flows in einer endlos langen Liste zunächst zu identifizieren, um sie anschließend genauer zu untersuchen. Wer OVN im produktiven Alltag also ernsthaft benutzen möchte, muss viel lernen.
Der Kreis schließt sich
Am Ende dieser Übersicht zu Open Flow, Open vSwitch und Open Virtual Network darf der Schwenk zurück zu klassischer Netzwerkhardware nicht fehlen. Wie eingangs bereits erwähnt wäre Open vSwitch im Gespann mit Open Flow durchaus geeignet, Kontrollregeln auch auf ganz klassischer Netzwerkhardware wie Switches und Routern zu etablieren. Hersteller wie Cisco oder Juniper könnten diese Funktionalität sogar ganz leicht implementieren, denn Open Flow ist schließlich ein offener Standard.
Allerdings: Alle großen Netzwerkanbieter waren es bisher gewohnt, ihre Kunden per Technik fest an sich zu binden. Ein klassischer Cisco-Shop tauscht seine Hardware nicht mal eben gegen Geräte von Juniper aus, wenn er nicht ein groß angelegtes Migrationsprojekt am Hals haben will. Eben dieser Vendor Lock-in fiele indes weg, kämen Netzwerkgeräte mit Control Plane auf Basis von Open Flow und Open vSwitch zum Einsatz – zumindest dann, wenn diese zugleich die Standardschnittstellen von Open vSwitch exponieren. Ebenso wichtig wie Open vSwitch selbst ist es ja, wie beschrieben, diesem Regeln mit auf den Weg geben zu können.
Dass dieses Szenario bei den großen Herstellern kaum auf Gegenliebe stößt, heißt nicht, dass es nicht heute bereits umsetzbar wäre. Einmal mehr rücken hier die Geräte mit ONIE-Schnittstelle in den Fokus. Das Kürzel steht für Open Networking Installation Environment und beschreibt einen Standard, der Linux auf Netzwerkhardware lauffähig macht. Geräte von Mellanox (heute Nvidia) sind ein gutes Beispiel (Abbildung 4): Auf ihnen lässt sich etwa Cumulus Linux installieren, das auf Debian GNU/Linux basiert und eine normale Kommandozeilenumgebung für Linux bietet.

Abbildung 4: ONIE-Switches wie der Mellanox SN3700C können in der Theorie bereits heute als aktive Open-Flow-Elemente im Netz zum Einsatz kommen, benötigen allerdings dafür ein Betriebssystem, das Open Flow unterstützt. Quelle: Nvidia
Der Cumulus-Kernel ist zwar um einige proprietäre Module angereichert, die die Kommunikation mit Mellanox’ Spectrum-ASIC ermöglichen, aus Administratorensicht läuft die Konfiguration eines Cumulus-Switches aber so ab, wie es bei einem RHEL, SLES oder Ubuntu auch der Fall wäre. Zudem lässt sich auf einem solchen System dann auch Open vSwitch samt Open Flow und Open Virtual Network nutzen. Das einzige Problem hier könnte die manchmal etwas beschränkte Hardware der Geräte sein, doch dürfte sich dieses Problem in Zukunft ob der zunehmenden Ressourcen von Netzwerkhardware erledigen.
Alles fein, könnte man denken – doch hat die Sache einen unschönen Haken. Denn der Switch muss softwareseitig so gebaut sein, dass er Open Flow unter Verwendung des eigenen Chips auch wirklich unterstützt. Kann er für seine Regelkalkulation nicht das eigene ASIC nutzen, sondern muss sie auf der naturgemäß eher schwachen CPU des Switches komplett in Software rechnen, lässt sich keine gute Performance erzielen. Obendrein wird zumindest ein Teil der Open-Virtual-Network-Features obsolet, wenn man diese wieder – wie bisher – über das ASIC der Netzwerkhardware erledigen kann.
Support auch bei NICs
Nicht nur bei Switches schließt sich übrigens der Kreis, was den Hardware-Support von Open vSwitch und Open Flow angeht. Seit einigen Jahren nimmt auch die Zahl der physischen Netzwerkkarten stetig zu, die verschiedene Offloading-Kapazitäten haben und der Host-CPU mithin etliche Aufgaben abnehmen können.
Open vSwitch-Offloading (Abbildung 5) etwa sorgt dafür, dass die Kalkulation von VxLAN-Regeln für Open vSwitch und Open Flow nicht mehr durch die Host-CPU ausgeführt wird, sondern unmittelbar auf der Netzwerkkarte. Je nach Art und Umfang des fließenden Traffics kann das die Latenz deutlich reduzieren und zugleich den erreichten Durchsatz drastisch erhöhen. In Kauf nehmen muss der Administrator im Gegenzug aber meist ein deutlich komplexeres Setup auf Ebene des Host-Systems.

Abbildung 5: Deutlich leichter als Infrastrukturgeräte lassen sich heute bereits NICs wie die Connect X6 von Nvidia einbinden. Sie unterstützt Dpdk und ab Werk das Offloading von Open-vSwitch-Paketen. Quelle: Nvidia
Fazit
In Form von Open Flow, Open vSwitch und Open Virtual Network steht erstmals ein Gespann auf Open-Source-Basis zur Verfügung, das konventionellen Switches und Routern tatsächlich gefährlich zu werden vermag. OVN erweitert OVS um die übergeordnete Control Plane, die diesem historisch fehlte. Das macht aus einer halb fertigen eine Komplettlösung, die nahtlos skalierbare Umgebungen bemerkenswerter Größe ermöglicht.
Administratoren seien allerdings gewarnt: Wer bis dato nur mit konventionellen Netzwerklayouts gearbeitet hat, sieht sich bei Open Flow, OVS und OVN einem hohen Lernaufwand sowie einer Reihe organisatorischer Herausforderungen gegenüber. Klassische Netzwerkexperten für Geräte einzelner Hersteller etwa werden in Open-Flow-Umgebungen kaum noch benötigt. Gute Generalisten, also Sysadmins mit dem Willen, sich in das Thema Netz einzuarbeiten, sind deutlich wichtiger. Von heute auf morgen erfolgt eine SDN-Migration deshalb eher nicht. Wer virtuelle Systeme und Plattformen betreibt, sollte das Thema dennoch auf dem Schirm haben.
Infos
- Open Virtual Network: https://www.ovn.org/en/





